
💁 个人主页:黄小黄的博客主页
❤️ 支持我:👍 点赞 🌷 收藏 🤘关注
🎏 格言:一步一个脚印才能承接所谓的幸运本文来自专栏:MySQL8.0学习笔记
本文参考视频:MySQL数据库全套教程
欢迎点击支持订阅专栏 ❤️

写在前面
本文为上一篇函数通关教程的下篇,主要讲述了mysql8.0新提供的特性:窗口函数。通过例子讲述了包含了常用的窗口函数如序号函数、开窗聚合函数、分布函数、前后函数与头尾函数的相关知识。而如聚合函数、数学函数、字符串函数、日期函数、控制流函数等均在上篇进行总结,文章链接附上:【MySQL】数据库函数通关教程上篇(聚合、数学、字符串、日期、控制流函数)
文章目录
6 窗口函数
6.1 窗口函数概述
🆔 介绍:
- MySQL 8.0新增窗口函数,又被称为开窗函数,与 Oracle 窗口函数类似,属于 MySQL 的一大特点;
- 非聚合窗口函数是相对于聚合函数来说的。聚合函数是对一组数据计算后返回单个值(即分组),非聚合函数一次只会处理一行数据。窗口聚合函数在行记录某个字段的结果时,可将窗口范围内的数据输入到聚合函数中,并不改变行数。
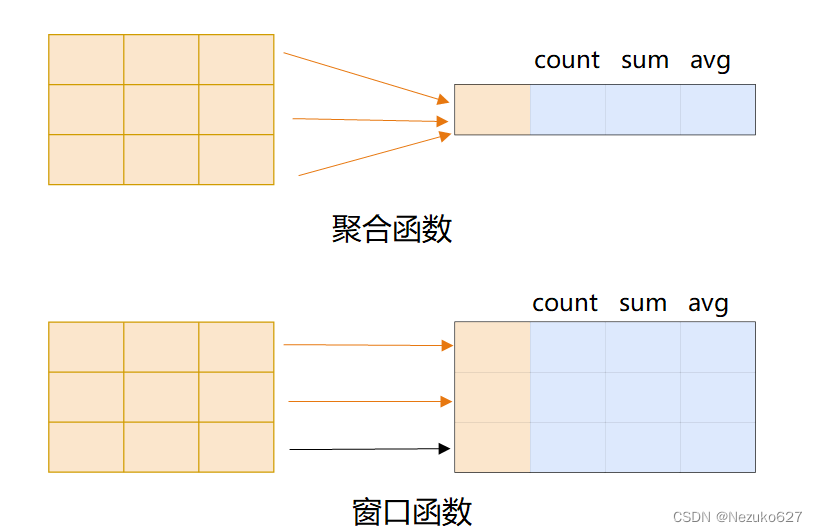
🍌 语法结构:
WINDOW_FUNCATION(EXPRESSION)OVER(PARTITIONBY...ORDERBY...
FRAME_CLAUSE
)
其中,
WINDOW_FUNCATION
是窗口函数的名称,
EXPRESSION
是参数,
OVER
子句包含三个选项:
** 1. 分区(PARTITION BY)**
PARTITION BY
选项用于将数据行拆分成多个分区(组)。如果省略了
PARTITION BY
,所有的数据将会作为一个组计算。
** 2. 排序(ORDER BY)**
ORDER BY
用于指定分区内的排序方式。
** 3. 窗口大小(FRAME_CLAUSE)**
FRAME_CLAUSE
用于在当前分区内指定一个计算窗口,也就是一个与当前计算行相关的数据子集。
6.2 序号函数
序号函数有三种,分别为
ROW_NUMBER()
、
RANK()
、
DENSE_RANK()
,可以实现分组排序,并添加序号。
🍌 语法结构:
ROW_NUMBER|RANK()|DENSE_RANK()OVER(PARTITIONBY...ORDERBY...)
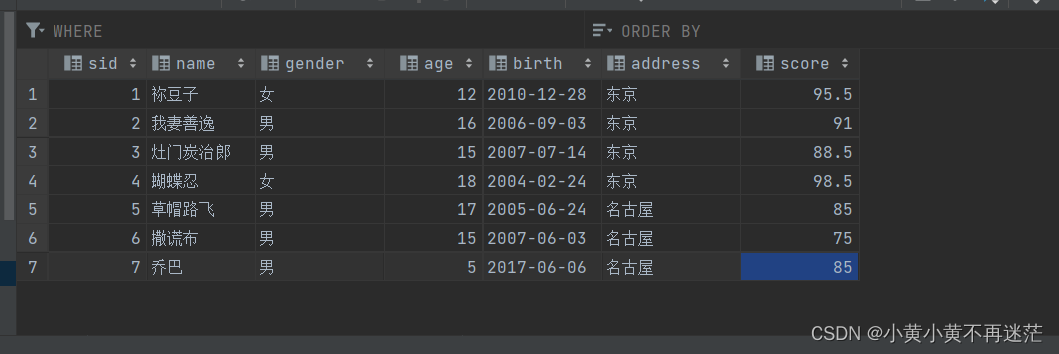
🐱 操作数据准备:
先使用下面的 SQL 语句创建一个表,表中的数据如图所示。
createtable student
(
sid intnull,
name varchar(20)null,
gender varchar(20)null,
age intnull,
birth datenull,
address varchar(20)null,
score doublenull);
6.2.1 ROW_NUMBER()
🐰 下面这段代码中,实现了根据地点分组并按照成绩排序查询(逆序)的操作,该函数会自动标上序号ano:
SELECT name, address, score, ROW_NUMBER()OVER(PARTITIONBY address ORDERBY score DESC)AS ano
FROM student
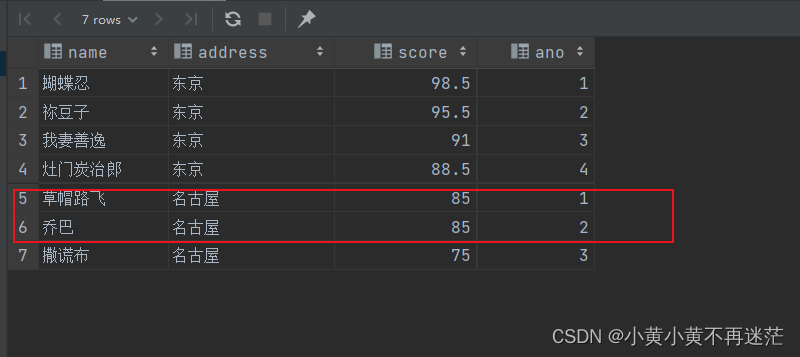
观察上方结果,我们可以发现,
ROW_NUMBER()
函数在实现标注序号时并不会把相同排名的行标号为同一序号,如上图红圈中,乔巴和路飞均为85分,但是序号并不相同!
6.2.2 RANK()
🐯 在该函数的示例中,同样 实现了根据地点分组并按照成绩排序查询(逆序)的操作,该函数会自动标上序号ano:
SELECT name, address, score, RANK()OVER(PARTITIONBY address ORDERBY score DESC)AS ano
FROM student
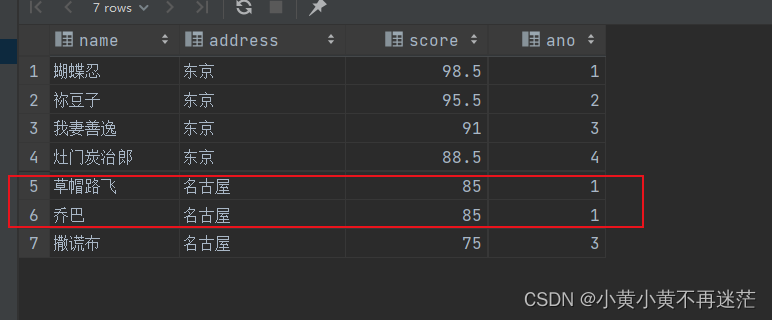
与
ROW_NUMBER()
的标号方式不同的是,相同排名该函数会标注上相同序号!且序号可能不连续,如图中路飞、乔巴的序号均为1,而撒谎布为3
6.2.3 DENSE_RANK()
🐱 与
RANK()
函数不同的是,该函数在进行标号时 虽然也将相同排名的行标号为同一序号,但是后面的序号依然连续!
SELECT name, address, score, DENSE_RANK()OVER(PARTITIONBY address ORDERBY score DESC)AS ano
FROM student
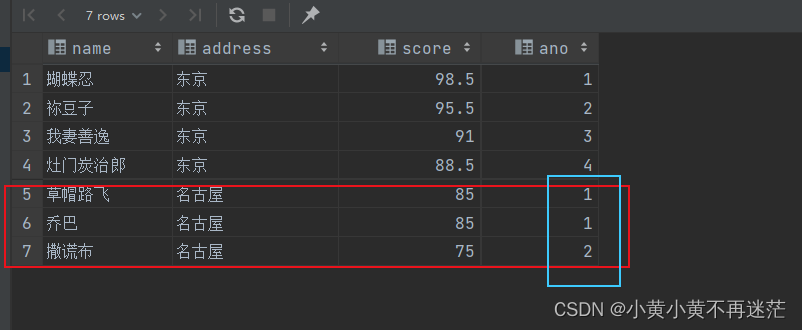
在上图中,路飞和乔巴的成绩相同,因此序号都为1。但是本应该排名为3的撒谎布被标号为了2!
6.3 开窗聚合函数
🆔 简介:
- 在窗口中每条记录动态地应用聚合函数(SUM()、AVG()、MAX()、MIN()、COUNT()),可以 动态计算在指定窗口内的各种聚合函数的值。
🐰 操作示例:
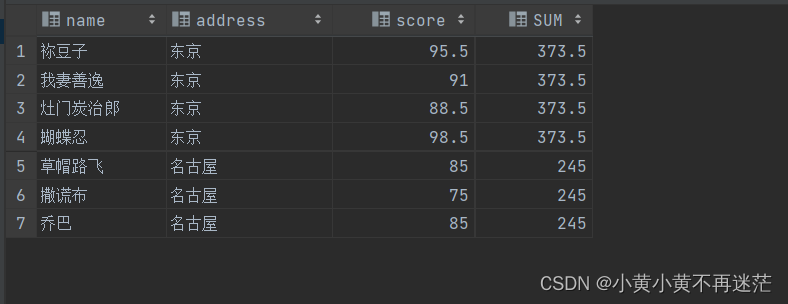
根据地点进行分组,使用SUM()计算总成绩,在该案例中,可以理解为根据地点分的每一组均为一个小窗口,而在这个窗口中计算了和:
SELECT name, address, score,SUM(score)OVER(PARTITIONBY address)AS SUM
FROM student
需要注意的是,如果指定了排序方式,结果会有比较大的区别, 如下代码:
SELECT name, address, score,SUM(score)OVER(PARTITIONBY address ORDERBY score)AS SUM
FROM student
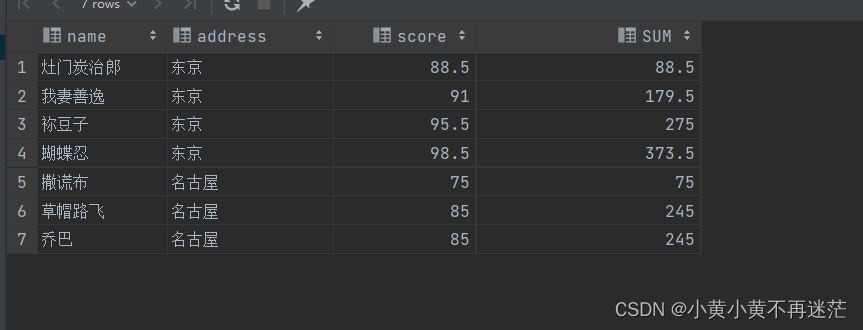
可以发现,当指定了排序方式,窗口则会调整为每组的当前行。比如,第一行的SUM为第一个人的成绩,第二行的SUM则为第一个人与第二个人成绩的和,以此类推… …
如果希望对各分组中每行的前2行到后1行的数据进行计算,则可以使用下面的语句:
SELECT name,
address,
score,SUM(score)OVER(PARTITIONBY address ORDERBY score rowsBETWEEN2PRECEDINGAND1FOLLOWING)AS SUM
FROM student
下图结果中的373.5则为第三行的前两行、当前行与后一行的成绩之和: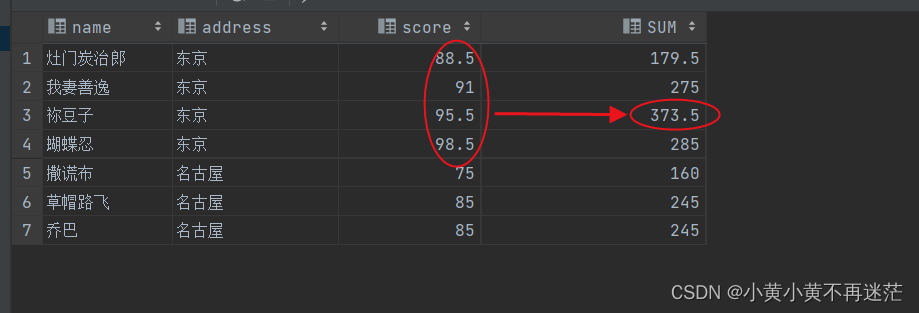
6.4 分布函数
6.4.1 CUME_DIST()
🆔 介绍:
- 用途:分组内小于、等于当前 rank 值的行数/分组内的总行数;
- 应用场景:查询小于等于当前数据项的行数比例。
🐱 操作示例:
SELECT name,
address,
score,
CUME_DIST()OVER(ORDERBY score)AS RESULT
FROM student
在下图中,成绩小于等于85的行数一共有3行,总行数为7行,因此result的值为3/7=0.42857… …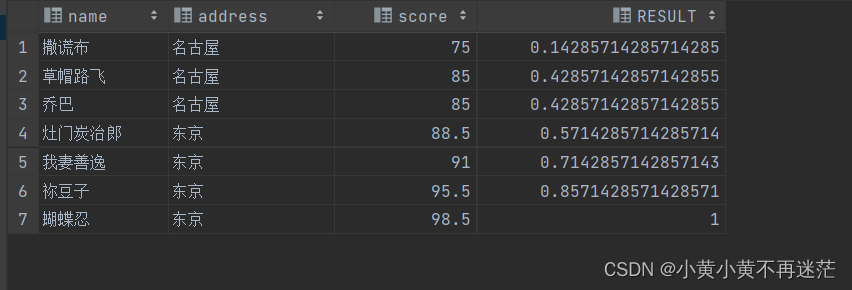
6.4.2 PERCENT_RANK()
🆔 介绍:
- 用途:每行按照公式(rank-1)/(rows-1)进行计算。其中,rank为RANK() 函数产生的序号,rows为当前窗口记录的总行数;
- 该方法不常用,简单了解即可。
🐱 操作示例:
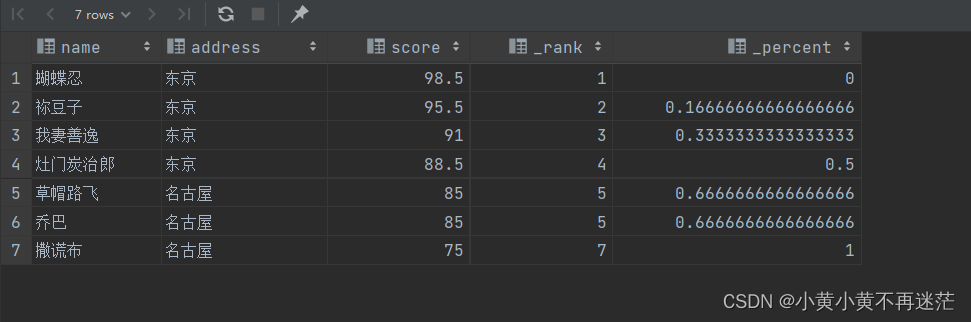
SELECT name,
address,
score,
RANK()OVER(ORDERBY score DESC)AS _rank,
PERCENT_RANK()OVER(ORDERBY score DESC)AS _percent
FROM student
6.5 前后函数-LAG与LEAD
🆔 介绍:
- 用途:返回位于当前行的前 n 行(LAG(expr,n)) 或者后 n 行(LEAD(expr,n)) 的 expr 的值;
- 应用场景:查询前一位同学的成绩和当前同学成绩的差值
🐰 操作示例:
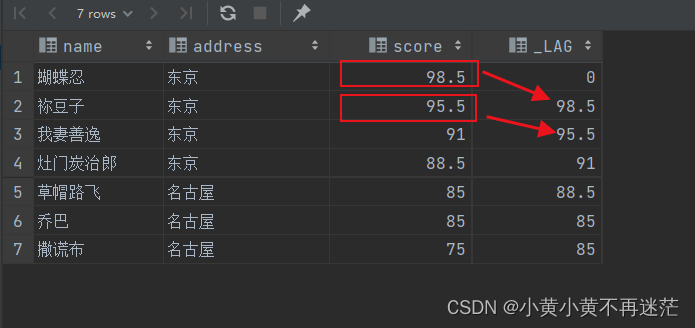
在示例中使用LAG查询结果每行显示上一名同学的成绩,命名为 _LAG,如果没有上一行,则默认显示0:
SELECT name,
address,
score,
LAG(score,1,0)OVER(ORDERBY score DESC)AS _LAG
FROM student
6.6 头尾函数
🆔 介绍:
- 用途:返回第一个(FIRST_VALUE(expr)) 或者最后一个 (LAST_VALUE(expr)) expr的值;
- 应用场景:截至当前,按照日期排序查询第一个生日的人的成绩和最后一个人的成绩;
🐰 操作示例:
分别使用FIRST_VALUE与LAST_VALUE查询到目前为止第一个和最后一个生日人的成绩。
SELECT name,
address,
score,
birth,
FIRST_VALUE(score)OVER(ORDERBY birth)ASFIRST,
LAST_VALUE(score)OVER(ORDERBY birth)ASLASTFROM student
对于查询结果,我们关注FIRST与LAST两列。需要特别注意到目前为止的条件,即结果为到当前行第一个出生或者最后一个出生的成绩!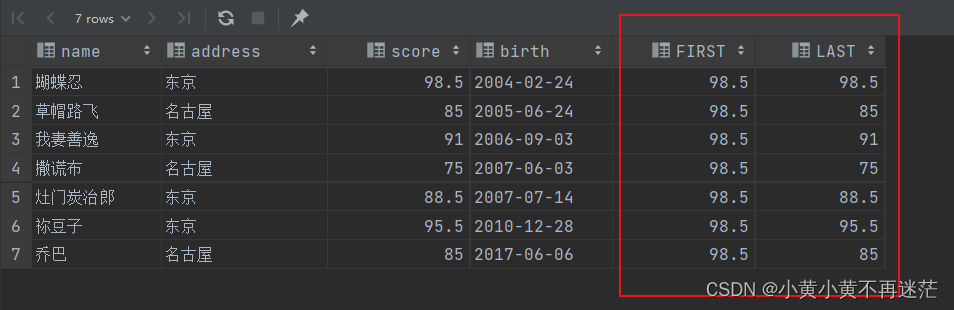
写在最后
🌟以上便是本文的全部内容啦,后续内容将会持续免费更新,如果文章对你有所帮助,麻烦动动小手点个赞 + 关注,非常感谢 ❤️ ❤️ ❤️ !
如果有问题,欢迎私信或者评论区!
共勉:“你间歇性的努力和蒙混过日子,都是对之前努力的清零。”
版权归原作者 小黄小黄不再迷茫 所有, 如有侵权,请联系我们删除。