
什么是 Kafka
Kafka
是一个分布式流式平台,它有三个关键能力
- 订阅发布记录流,它类似于企业中的
消息队列或企业消息传递系统 - 以容错的方式存储记录流
- 实时记录流
Kafka 的应用
作为消息系统- 三个基本组件- Producer : 发布消息的客户端- Broker:一个从生产者接受并存储消息的客户端- Consumer : 消费者从 Broker 中读取消息
作为存储系统- Kafka 运行在一个或多个数据中心的服务器上作为集群运行- Kafka 集群存储消息记录的目录被称为**
topics- 每一条消息记录包含三个要素:键(key)、值(value)、时间戳(Timestamp)**作为流处理器- Kafka 可以建立流数据管道,可靠性的在系统或应用之间获取数据。- 建立流式应用传输和响应数据。
Kafka 系统架构
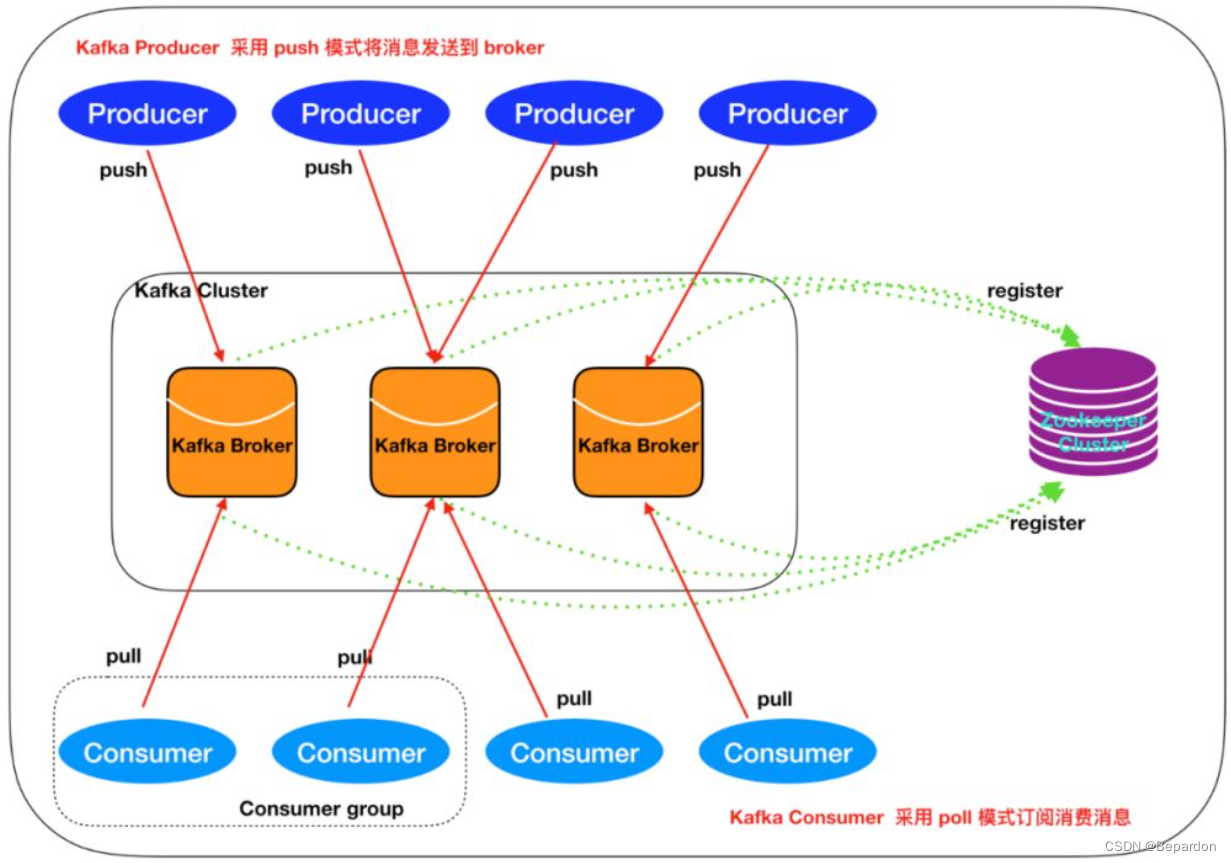
如上图所示,一个典型的 Kafka 集群中包含
- 若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),
- 若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),
- 若干Consumer Group,
- 以及一个Zookeeper集群。 - Kafka通过Zookeeper管理集群配置,选举leader,- 以及在Consumer Group发生变化时进行rebalance。- Producer使用push模式将消息发布到broker,- Consumer使用pull模式从broker订阅并消费消息。
核心 API
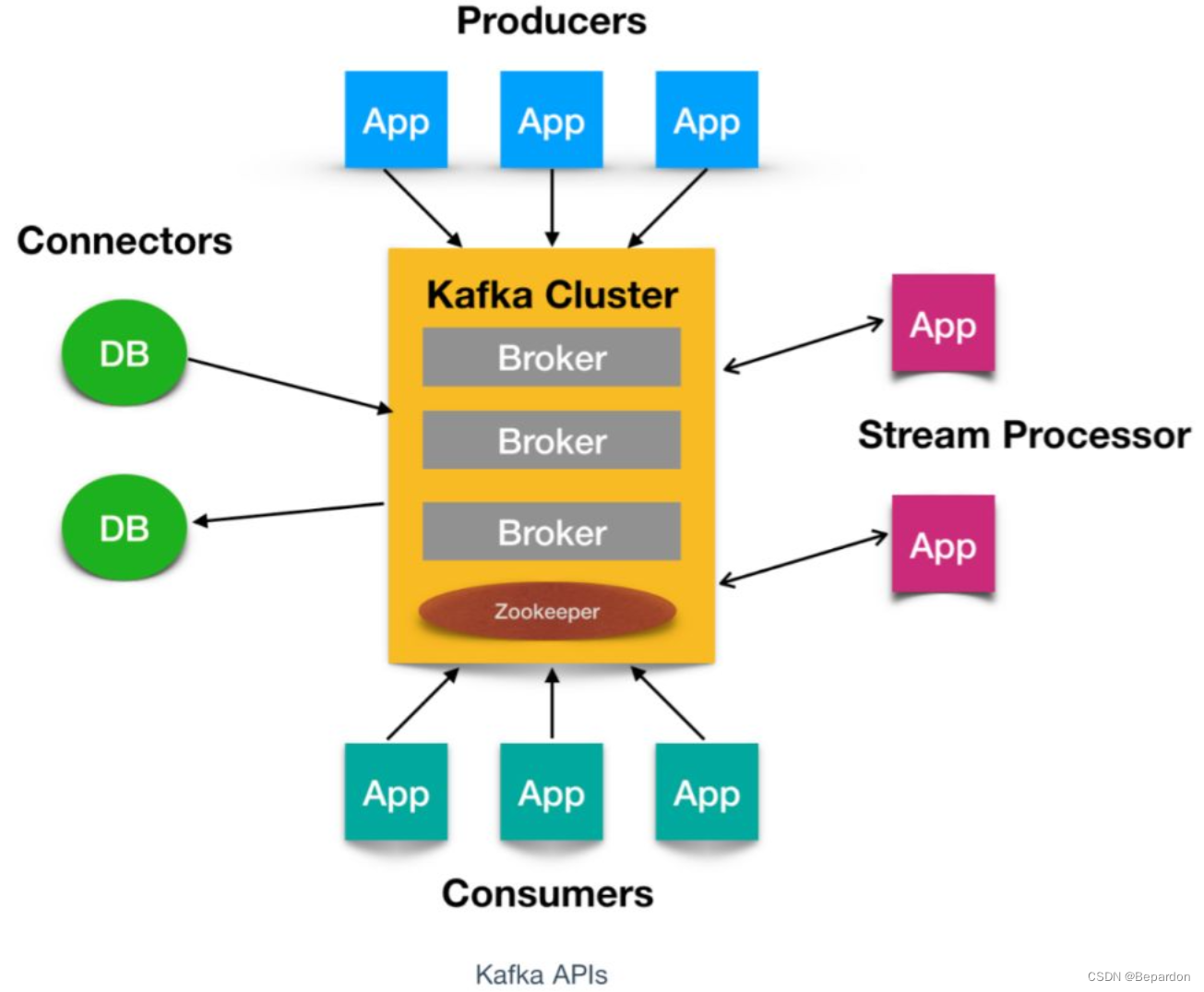
Kafka 有四个核心API,它们分别是
- Producer API,它允许应用程序向一个或多个 topics 上发送消息记录
- Consumer API,允许应用程序订阅一个或多个 topics 并处理为其生成的记录流
- Streams API,它允许应用程序作为流处理器,从一个或多个主题中消费输入流并为其生成输出流,有效的将输入流转换为输出流。
- Connector API,它允许构建和运行将 Kafka 主题连接到现有应用程序或数据系统的可用生产者和消费者。例如,关系数据库的连接器可能会捕获对表的所有更改
Kafka 为何如此之快
零拷贝- Kafka 实现了零拷贝原理来快速移动数据,避免了内核之间的切换。
消息压缩- 批处理能够进行更有效的数据压缩并减少 I/O 延迟
顺序读写- Kafka 采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费。
分批发送- Kafka 可以将数据记录分批发送,从生产者到文件系统(Kafka 主题日志)到消费者,可以端到端的查看这些批次的数据。
Kafka 基本概念
broker- Kafka 集群包含一个或多个服务器,每个 Kafka 集群中服务器被称为 broker。- broker 是集群的组成部分,每个集群中都会有一个 broker 同时充当了
集群控制器(**Leader**)的角色,它是由集群中的活跃成员选举出来的。- 每个集群中的成员都有可能充当 Leader,Leader 负责管理工作,包括将分区分配给 broker 和监控 broker。- 集群中,一个分区从属于一个 Leader,但是一个分区可以分配给多个 broker(非Leader),这时候会发生分区复制。这种复制的机制为分区提供了消息冗余,如果一个 broker 失效,那么其他活跃用户会重新选举一个 Leader 接管。- broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。- broker 为消费者提供服务,对读取分区请求作出响应,返回已经提交到磁盘上的消息。

producer 生产者- 消息的发布者,会将某 topic 的消息发布到相应的 partition 中。- 生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。- 不过,在某些情况下,生产者会把消息直接写到指定的分区。
consumer 消费者- 消息的使用者,一个消费者可以消费多个 topic 的消息,- 对于某一个 topic 的消息,其只会消费同一个 partition 中的消息
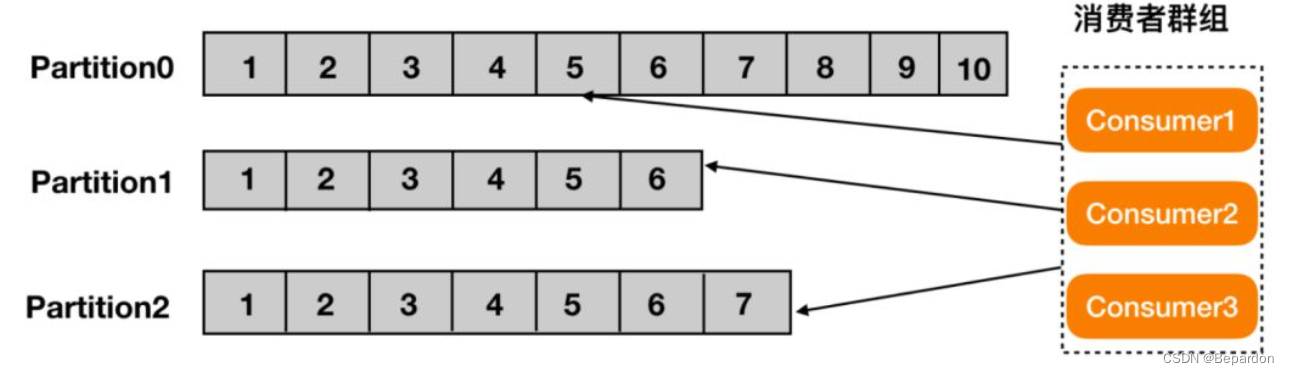
疑问:一条消息划分topic后,topic(主题) 中的消息会被分割为一个或多个的 partition(分区),并且在默认情况下把消息均衡地分布到主题的所有分区上,以追加的形式写入分区,那么如果消费者对于某一个 topic 的消息,其只会消费同一个 partition 中的消息,那么只得到了消息的一部分信息?
在消费者组的概念下,单一消费者并不需要获取全部的消息
实际运用中可以指定生产者将消息写入指定分区,同时消费者可以决定消费指定分区的消息,消费者组中的消费者不会消费同一分区:
Topic 主题- kafka 使用一个类别属性来划分消息的所属类,划分消息的这个类称为 topic。- topic 相当于消息的分配标签,是一个逻辑概念。主题好比是数据库的表,或者文件系统中的文件夹
partition 分区 - topic 中的消息被分割为一个或多个的 partition,它是一个物理概念,对应到系统上的就是一个或若干个目录,一个分区就是一个
提交日志。- 消息以追加的形式写入分区,先后以顺序的方式读取。- 单个 Partition 分区可以保证有序

- 由于一个主题包含无数个分区,因此无法保证在整个 topic 中有序,
- 但是单个 Partition 分区可以保证有序。 - 消息被迫加写入每个分区的尾部。- Kafka 通过分区来实现数据冗余和伸缩性
- 分区可以分布在不同的服务器上 - 既一个主题可以跨越多个服务器,以此来提供比单个服务器更强大的性能。
segment 段- 将 Partition 进一步细分为若干个 segment,每个 segment 文件的大小相等。
本文转载自: https://blog.csdn.net/randou_/article/details/136625006
版权归原作者 Bepardon 所有, 如有侵权,请联系我们删除。
版权归原作者 Bepardon 所有, 如有侵权,请联系我们删除。