
一、大数据的特征
大数据的4v主要包含规模性(Volume)、多样性(Variety)、高速性(Velocity)、价值性(Value)
1、规模性(Volume)
大数据中的数据计量单位是PB(1千个T)、EB(1百万个T)或ZB(10亿个T)。
2、多样性(Variety)
多样性主要体现在数据来源多、数据类型多和数据之间关联性强这三个方面。
①数据来源多,互联网和物联网的发展,带来了诸如社交网站、传感器等多种来源的数据。 而由于数据来源于不同的应用系统和不同的设备,决定了大数据形式的多样性。
②数据类型多,并且以非结构化数据为主。大数据中有70%-85%的数据是如图片、音频、视频、网络日志、链接信息等非结构化和半结构化的数据。
③数据之间关联性强,频繁交互,如游客在旅游途中上传的照片和日志,就与游客的位置、行程等信息有很强的关联性。
3、高速性(Velocity)
大数据对处理数据的响应速度有更严格的要求。实时分析而非批量分析,数据输入、处理与丢弃立刻见效,几乎无延迟。数据的增长速度和处理速度是大数据高速性的重要体现。
4、价值性(Value)
大数据背后潜藏的价值巨大。由于大数据中有价值的数据所占比例很小,而大数据真正的价值体现在从大量不相关的各种类型的数据中。挖掘出对未来趋势与模式预测分析有价值的数据,并通过机器学习方法、人工智能方法或数据挖掘方法深度分析,并运用于农业、金融、医疗等各个领域,以期创造更大的价值。
二、结构化数据与非结构化数据
结构化数据:
简单来说就是数据库。结合到典型场景中更容易理解,比如企业ERP、财务系统;医疗HIS数据库;教育一卡通;政府行政审批;其他核心数据库等。这些应用需要哪些存储方案呢?基本包括高速存储应用需求、数据备份需求、数据共享需求以及数据容灾需求。
非结构化数据:
相对于结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)而言,不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、标准通用标记语言下的子集XML、HTML、各类报表、图像和音频/视频信息等等。
非结构化数据库是指其字段长度不等,并且每个字段的记录又可以由可重复或不可重复的子字段构成的数据库,用它不仅可以处理结构化数据(如数字、符号等信息)而且更适合处理非结构化数据(全文文本、图象、声音、影视、超媒体等信息)。
三、Hadoop生态圈
Hadoop的核心组件是HDFS、MapReduce。随着处理任务不同,各种组件相继出现,丰富Hadoop生态圈,目前生态圈结构大致如图所示:

四、Hadoop HDFS架构
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利
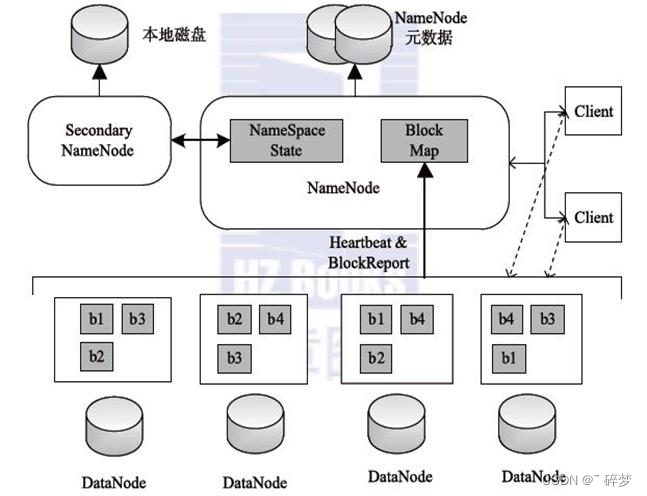
1.Client(客户端)
(1)文件切分,文件上传 HDFS 的时候,Client 将文件切分成一个一个的Block,然后进行存储
(2)与 NameNode 交互,获取文件的位置信息
(3)与 DataNode 交互,读取或者写入数据
(4)Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS
2.NameNode(master,它是一个主管、管理者)
(1)管理 HDFS 的名称空间
(2)管理数据块(Block)映射信息
(3)配置副本策略
(4)处理客户端读写请求
3.DataNode(slave,NameNode 下达命令,DataNode 执行实际的操作)
(1)存储实际的数据块
(2)执行数据块的读/写操作
4.Secondary NameNode(辅助者,并非 NameNode 的热备)
(1)辅助 NameNode,分担其工作量
(2)定期合并 fsimage和fsedits,并推送给NameNode
(3)在紧急情况下,可辅助恢复 NameNode
五、HDFS读取文件流程
当客户端需要读取文件时,首先向NameNode发起读请求, NameNode收到请求后,会将请求文件的数据块在DataNode中的具体位置(元数据信息)返回给客户端,客户端根据文件数据块的位置,直接找到相应的DataNode发起读请求
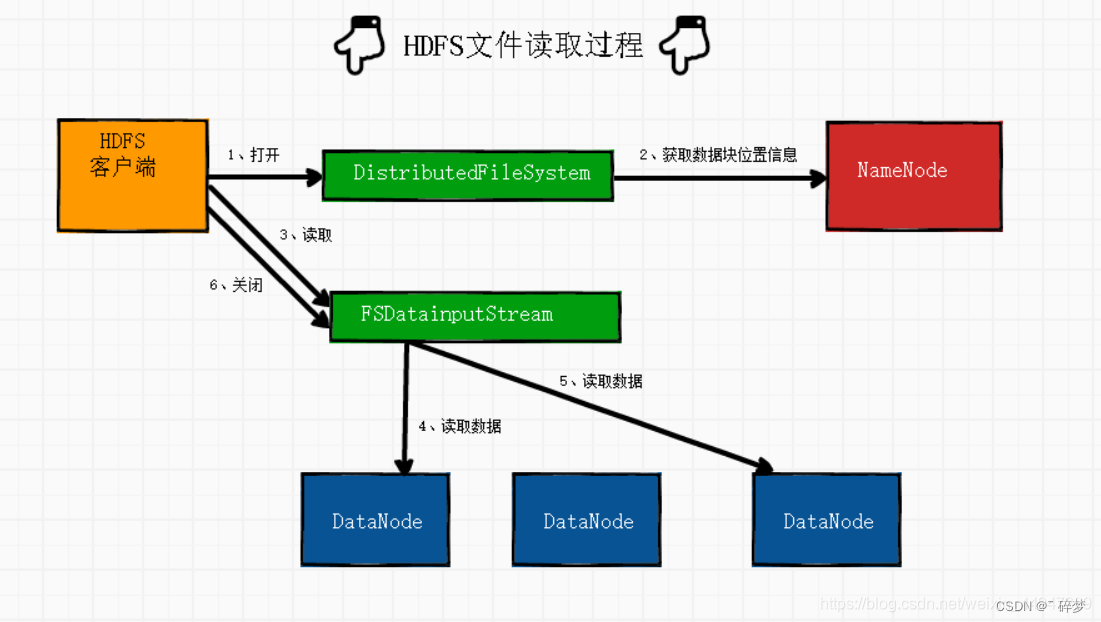
流程图的说明:
HDFS客户端通过DistributedFileSystem对象的open(方法打开要读取的文件。
DistributedFileSystem负责向远程的名称节点( NameNode)发起RPC调用,得到文件的数据块信息,返回数据块列表。对于每个数据块,NameNode返回该数据块的DataNode地址。
DistributedFileSystem返回-一个FSDatalnputStream对象给客户端,客户端调用FSData-InputSream 对象的read0方法开始读取数据。
通过对数据流反复调用read()方法,把数据从数据节点传输到客户端。
当一个节点的数据读取完毕时,DFSInputStream 对象会关闭与此数据节点的连接,连接此文件下一个数据块的最近数据节点。
当客户端读取完数据时,调用FSDataInputStream 对象的close()方法关闭输入流
六、Hadoop的优势
- 高可靠性:
Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或者存储出现故障,也不会导致数据的丢失。
2.高扩展性:
在集群间分配任务数据,可方便的扩展数以千计的节点。
3.高效性:
在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4.高容错性:
能够自动将失效的任务重新分配。
版权归原作者 ˉ 碎梦 所有, 如有侵权,请联系我们删除。