
🧸🧸🧸各位大佬大家好,我是猪皮兄弟🧸🧸🧸
文章目录
在string类的模拟实现当中,我觉得最后的\0是很重要的,不管是push_back后的调整,还是开辟空间考虑+1,这些都很容易忘记\0
一、string拷贝构造模拟
1.无参的默认构造模拟
//无参classstring{public:string():_str(newchar[1])//主要是为了与delete[] 匹配,_size(0),_capacity(0){
_str[0]=0;//'\0'}private:char*_str;
size_t _size;
size_t _capacity;};
2.缺省的默认构造模拟
注意:"“空串是默认有\0的,所以缺省值给”"也行
classstring{public:string(constchar*str ="")//空串里面默认有\0:_str(newchar[strlen(str)+1])//主要是为了与delete[] 匹配,_size(strlen(str)),_capacity(strlen(str)){strcpy(_str,str);}private:char*_str;
size_t _size;
size_t _capacity;};
优化写法:
因为初始化列表初始化的顺序是按照成员变量的声明顺序来的,所以这里不建议用初始化列表去初始化
classstring{public:string(constchar*str ="")//空串里面默认有\0{
_size=strlen(str);
_capacity = _size;
_str =newchar[_size+1];//+1存放\0strcpy(_str,str);}private:char*_str;
size_t _size;
size_t _capacity;};
二、string拷贝构造模拟
1.默认生成的拷贝构造 深浅拷贝 问题
当我们不去显示写拷贝构造函数,编译器会自己生成,对于内置类型,完成值拷贝(浅拷贝),对于自定义类型,去调用该自定义类型的拷贝构造函数,那么,对于指针这种内置类型,它拷贝的是地址,所以拷贝出来的string指向的是同一块空间
问题:
1.两个字符串可以互相修改,因为是同一个地址
2.析构的时候会降同一个地址析构两次 ,直接崩溃(野指针问题)
3.中途 改变了指向的话还会出现内存泄漏的问题
2.拷贝构造模拟(普通写法)
classstring{public:string(const string&s)//构造函数是char*,拷贝构造是用的同类型 string:_str(newchar[s._capacity+1]),_size(s._size),_capacity(s._capacity){strcpy(_str,s._str);}private:char*_str;
size_t _size;
size_t _capacity;};
3.拷贝构造模拟(现代写法,复用构造函数)
现代写法的优势在于:对于以后更加复杂的类,复用是一种很好的办法
classstring{public://库里提供的swap交换代价极高,会先深拷贝出来一个字符进行交换//所以对深拷贝的类,绝对不能不用库里的swapvoidswap(string&s){::swap(_str,s._str);::swap(_size,s._size);::swap(_capacity,s._capacity);}string(const string&s)//构造函数是char*,拷贝构造是用的同类型 string:_str(nullptr)//这里是对_str指针进行一个初始化,我们都知道,随即指针是不能被使用的,也不能被释放,直接交换的话会崩溃。因为空间可能不属于我们,_size(0),_capacity(0){
string tmp = s._str;swap(tmp);//交换this和tmp的数据}private:char*_str;
size_t _size;
size_t _capacity;};
浅拷贝也就是逐字节进行值拷贝,遇到指针的时候拷贝过来的就是起始的地址,所以会出现深浅拷贝的问题,那么对于深拷贝,深拷贝也就是自己开辟一块空间
三、赋值运算符重载模拟
默认得赋值运算符重载也非常粗暴,也是浅拷贝
1.operator=(普通写法)
string &operator=(const string &s){if(&s!=this){char*tmp =newchar[s._capacity+1];strcpy(tmp,s._str);delete[] _str;
_str =tmp;
_size = s._size;
_capacity = s._capacity;}return*this;}
1.如果不delete原来的而直接进行拷贝
a.原来的空间不够,扩容或者重新开辟
b.原来的空间非常大,现在需要的非常小
那不如直接释放了开空间
/
2.如果说需要new出来的空间很大,虽然说new是抛异常,会跳到catch去处理异常,但是把原对象破坏掉了,所以,需要需要先用一个临时的来试试水。
2.operator=(现代写法)
string&operator=(const string&s){if(this!=&s){
string tmp(s);/*
利用拷贝构造,拷贝构造是构造函数的一种函数重载
构造函数传递的是char*的字符串
拷贝构造传递的是string同类型的字符串
*/swap(tmp);}return*this;}
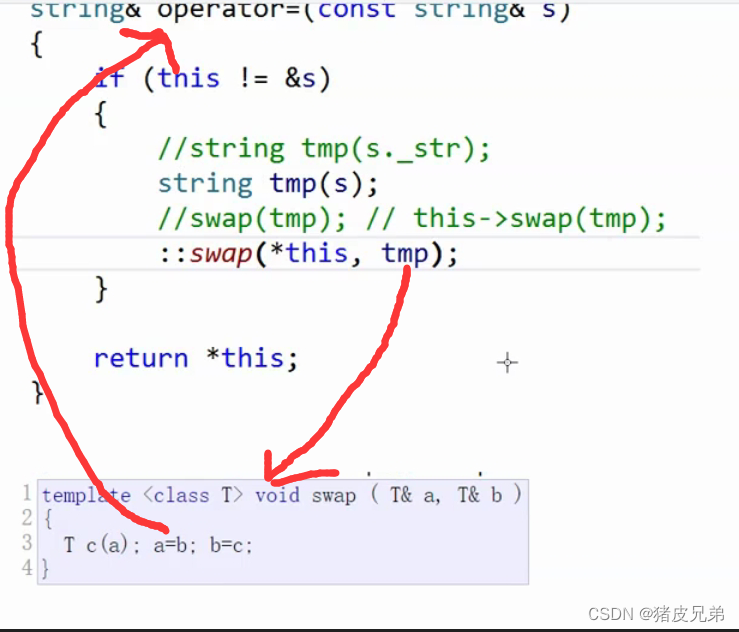
对于深拷贝的类不要去用全局的swap,首先,代价极大,而且在其过程中又会存在赋值运算符,所以会出现一直循环调用,最后栈溢出
string&operator=(string s){//更简洁swap(s);//上面写的swap
rerturn *s;}
四、其他部分的模拟实现
1.reserve模拟
voidreserve(size_t n){if(n>_capacity){char*tmp =newchar[n+1];//注意n+1,给\0留位置strcpy(tmp,_str);delete[] _str;
_str = tmp;
_capacity = n;}}
2.push_back模拟
voidpush_back(char ch){if(_size==_capacity){//扩容reserve(_capacity==0?4:_capacity*2);}
_str[_size]=ch;++_size;
_str[_size]=0;//\0}
3.append模拟实现
voidappend(constchar* str){int len =strlen(str);if(_size+len<_capacity){reserve(_size+len+1);//reserve里面会 修改capacity}strcpy(_str+_size,str);
_size+=len;
_str[_size++]=0;}
4.strcat相比之下的缺点
strcat追加的缺点
1.strcat是从头开始找的,所以效率会低很多
2.strcat是找到\0就开始追加,然而string是以size为准的,中间可能也会有\0,所以可能错误追加
5.operator+=模拟
string&operator+=(char ch){push_back(ch);return*this;}
string&operator+=(char* str){append(str);return*this;}
6.insert模拟
string&insert(size_t pos,char ch){assert(pos<=_size);//因为size_t,不用>=0if(_size==_capacity){reserve(_capacity ==0?4:2*_capacity);}int end = _size+1;//将\0也移走while(end>pos){
_str[end]= _str[end-1];--end;}
_str[pos]= ch;
_size++;return*this;}
string&insert(size_t pos,constchar*str){assert(pos<=_size);int len =strlen(str);if(_size+len > _capacity){reserve(_size+len);}int end = _size+len;while(end>pos+len){
_str[end]=_str[end-len];--end;}strncpy(_str+pos,str,len);
_size +=len;return*this;}
push_back()可以复用insert
7.operator<<与operator>>
因为需要保证<<两边的操作数的顺序,所以需要在类外去写流插入和流提取的重载,类里写的话左边都是this
//在string类中友元这两个函数
ostream&operator<<(ostream&out,const string &str){//因为string中可能有\0,所以不能直接用cout,//cout碰到\0就停止了,所以for(int i=0;i<str.size();i++){out<<str[i];}return out;}
istream&operator>>(istream&in,string&str){
str.clear();char ch;
ch=in.get();//不会忽略换行和空格const size_t N=32;char buff[N];
size_t i=0;//优化频繁扩容while(ch!=' '&&ch!='\n'){
buff[i++]=ch;if(i==N-1){
buff[i]='\0';
s+=buff;
i=0;}
ch=in.get();}
buff[i]=0;
s+=buff;return in;}
1.关于流插入平凡扩容的问题,用一个buff数组来做缓冲,这是一个临时的,出了作用域就销毁了,设计的思路类似与缓冲区
2.其次,在流提取之前还要先clear一下内容
3.C++允许const的数去做一个定长数组
在vs下对于string也有一个优化,是加了一个buff[16]的缓冲,作为成员变量,所以在sizeof(string)的时候,发现标准库里的string大小并不是12而是28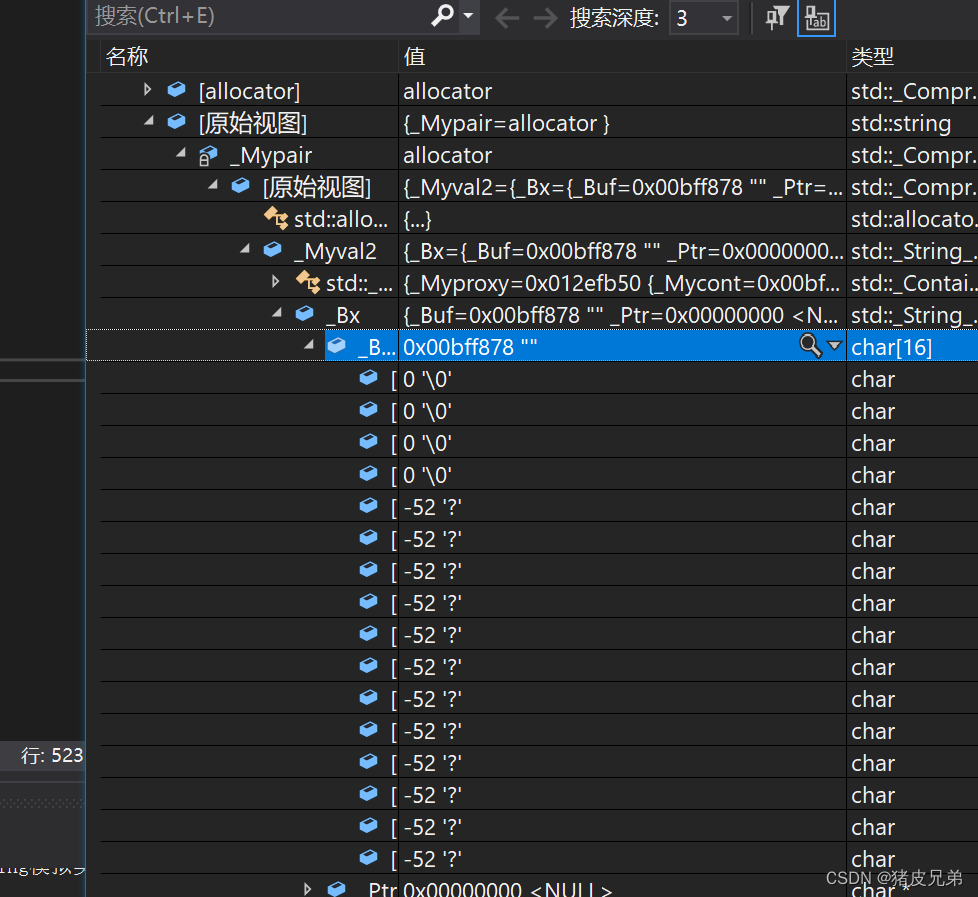
8.resize模拟
voidresize(size_t n,char ch=0){if(n>_size){reserve(n);for(size_t i=_size;i<n;i++){
_str[i]=ch;}
_str[n]='\0';
_size=n;}else{
_str[n]='\0'
_size = n;}}
9.string类型中的排序
这里需要利用到仿函数,后面再说,先简单带过一下
五、优化 Copy-On-Write
有人觉得深拷贝代价太大,就提出了 引用计数+写时拷贝 的方法
1.增加一个引用计数,多少个引用指向浅拷贝的哪个空间,就计数多少,计数器减到1的时候才去析构,不然不析构
2.写时拷贝,去写的时候才去深拷贝(延迟拷贝动作)
六、总结
上面对部分string类中的东西进行了模拟实现,希望能帮助大家,也希望能和大家一起学到东西,下一篇更新vector相关内容,谢谢大家支持!!
版权归原作者 猪皮兄弟 所有, 如有侵权,请联系我们删除。