
Kafka学习笔记(一)-名词解释模块,我们简单的提到了kafka的一些相关名词和它们之间的关系。这一章将详细的记录kafka的架构组成
kafka架构图
单节点架构
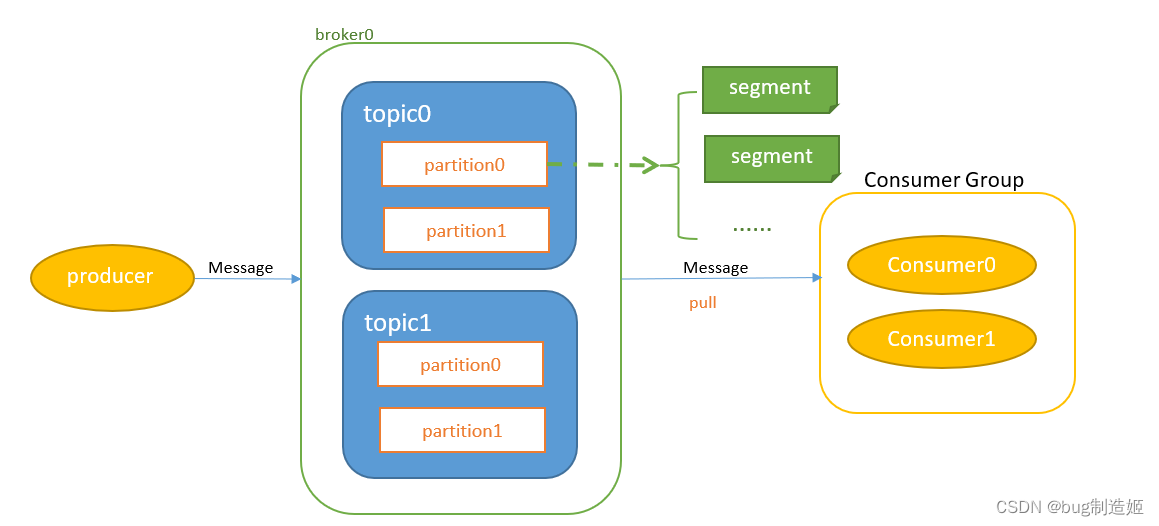
在kafka集群中,一个运行kafka服务的节点,我们称之为Broker,它负责接收producer发送的消息,并存储在磁盘上。
Kafka中消息的生产者被称为Producer,生产者在生产消息时,并非逐条发送,而是按照设定的参数进行批量发送:如
batch.size
,表示多少数据时进行发送,默认16k;
linger.ms
表示批量发送的等待时间,超过多少秒,进行发送;
buffer.memory
客户端缓冲区,满了也会触发消息发送。
在消息中间件中,消费者获取消息的方式有两种:pull和push。
pull
是指消息存储在broker上,消费者需要时去拿。
push
指broker拿到消息之后立即发送给消费组,存储在消费者的服务器上。Kafka用的
Pull
,RabbitMQ两种方式都有,但主要是用
Push
。Consumer和producer通过指Topic进行关联。
一个Borker节点上会有多个Topic,它可以理解为文件夹,用来表示一组相关的消息。需要注意的是,Topic只是一个逻辑概念,在磁盘上,消息并非按照Topic进行存储。
Partition是Topic的基础组成部分,它将一个topic拆分成多个逻辑单元。是一个有序的不可变的消息队列。一个Topic上会有若干个partition。是生产者和消费者操作的最小单位。
一个partition中包含多个segment。一个segment是物理存储消息的最小单元,每个segment包含一定量的消息数据。配置文件中
log.segment.bytes
就定义了segment文件的最大值。segment文件的文件名,是根据下一条消息的偏移量命名的,从而实现了消息的有序性。消息数据会依次、按顺序的追加写入文件,不需要在磁盘上寻址,保证了kafka的高吞吐量。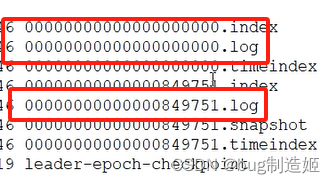
集群架构
Leader-Follower模型
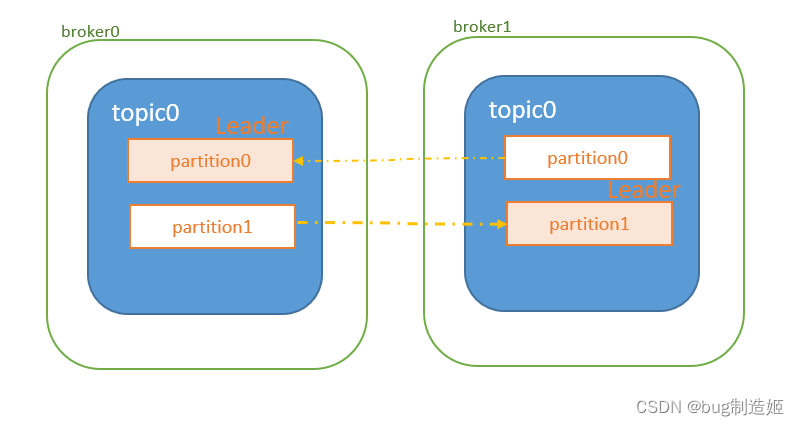
为提高数据可用性和容错性的目的,kafka集群用了和Redis类似的主从复制。不过,Kafka的复制粒度是Partition,每个Partition都有一个Leader和若干个Follwer。通过异步的方式机制复制,只是采用了简单的备份策略。而Redis的复制粒度是Redis整个节点,采用同步复制机制,且具有复杂的高可用策略。
当消息写入时,topic会根据预定义的消息分区策略,将消息分配到不同的Partition中。Kafka提供了三种默认的消息分区策略:
1.Round-robin Strategy:将消息均匀的分配到所有可用的partition中,实现简单,但是无法保证消息的顺序性。
2.Range Strategy:根据消息的Key值范围,将消息分配到不同的partition中。类似于给定一个区间,相同key值的消息都会被分配到同一个partition中,可以保证相同key值的消息被顺序处理。
3.Hash Strategy:将消息的key值进行hash计算,根据hash值将消息分配到不同的partition。同一个key值的消息总是被分配到同一个partition中,可以保证相同key值的消息被顺序处理。
也可以自定义消息分区策略,只需要实现Partitioner接口即可。自定义消息分区策略可以应用于特定的业务场景,比如需要把一些特定的消息分配到指定的partition中,或者需要根据特定的业务逻辑进行分区选择。
Leader的选举
Leader的选举是通过一个Broker进行的,Kafka会先在集群中选出一个Broker作为Controller,由这个Controller执行选举的流程。并使用ZooKeeper来协调Leader选举过程。ZooKeeper是Kafka选举的重要保障,因为它保证了选举算法的正确性和一致性。
partition对消费者访问的分配
partition不允许同一个Consumer Group中的两个消费者同时消费。如果想要实现一个partition的消息被重复消费,只能另外建一个消费组。且消费者和生产者只会对Leader进行操作。
kafka的partition.assignment.strategy是用来指定Partition分配策略的参数。
1.RangeAssignor:该分配器将Toic中所有的Partition的id范围均匀分配给各个Consumer Group中的Consumer,以实现负载均衡。
2.RoundRobinAssignor:该分配器将Topic中所有Partition依次分配给各个Consumer Group中的Consumer,以实现轮询分配。保证消息的顺序性。
3.StickyAssignor:该分配器将在RangAssignor和RoundRobin之间权衡,以实现当某个Consumer Group发生增删时,尽可能减少Partition的重分配。
Partition中被消费的数据不会被删除,所以 ,需要维护一个消费者和其读取数消息的offset的数据。早期,该数据被保存在zookeeper中,后来,Kafka直接将数据保存在了Broker上。
kafka会将groupID的hash值对50取模,获得存储的文件分区。将当前消费者的相关消费信息存入。
Kafka中Zookeeper的作用
Kafka中Zookeeper的作用主要有以下几个方面:
- 管理Kafka的元数据:Zookeeper维护了Kafka集群的元数据,包括Kafka broker的列表、分区的分配方案、消费者的消费位置、各个主题的配置信息等,这些信息对Kafka集群的正常运行至关重要。
- 协调Kafka集群中的各个节点:Kafka集群中的每个节点通过Zookeeper协调彼此之间的工作,例如Kafka broker的加入、离开、分区分配、leader选举等等,这些都需要Zookeeper来协调。
- 提供可靠的消息存储:Zookeeper本身也是一个分布式系统,它提供了可靠的数据存储和读写保持一致的机制,这一特性也被Kafka利用来存储消息的生产者和消费者的偏移量。
综上所述,可以看出Zookeeper在Kafka集群中扮演了非常重要的角色,它是Kafka集群的中枢神经系统。
版权归原作者 bug制造姬 所有, 如有侵权,请联系我们删除。