
关于 Git 的一些常识和我的一些零言碎语
《工欲善其事,必先利其器》—— 既然点进来了,麻烦你看下去,希望你有不一样的收获~

(图片取自百度,侵删。)
Hello 大家好,好久不见,我是 vk!今天我们来学习工作中比较常用的一些 git 常识。由于文章内容比较多,各位看官老爷可以在右侧的分栏选择自己感兴趣的段落!
这篇文章并不会介绍常用指令,我相信网上也有很多文章写的更加全面,这里给大家推荐一篇个人认为介绍指令非常不错的文章 —— 《女朋友说 Git 玩不明白,怎么办?安排!》
《前言》
掐指一算,过完国庆就是年了,时间过得真的很快。。不知不觉我的工龄也已经来到了2岁。自从大二那年,也就是2018年,即将面临实习的我,也不得不开始收心操心起学业来。也就是那一年,我接触到了CSDN,也写下了人生中的第一篇文章。现在看起来也是有够无知hhh…
关于计算机,我非科班,没有老师、前辈指导。甚至身边为数不多学计算机的朋友,也纷纷开始从事后端的实习工作。作为小白,从学校出来的我,回到深圳,开始了为期长达3个月的自学。其中学习的内容,就包含了 SVN 和 Git。后来实在找不到工作,迫不得已也接受了其他行业的工作。。。直到2020年,我才被之前那个后端朋友,介绍到了他公司和他搭档。也是非常感谢这位朋友,我才能开始我的前端生涯。
工作第1年,由于公司不大,开发组就两个固定的人,我时不时的有使用到 git。导致我用完就忘,根本记不住它的用法和精髓。
2021年底,我决定开发一个属于自己的个人博客网站,那时我在网上搜索了很多关于建站的工具,最后选择了 Hexo。一开始部署在 GitHub.io 上面,后来我嫌弃它速度太慢了,索性就自己购买了一台服务器,搭建了自己的私人代码库,将网站部署到了自己的云 Ecs 上。
也是在这一年,由于疫情的原因,开发组更是惨淡,最后只剩下我一个人,前后端全包,这就导致了我没有办法专注在前端领域上。后端代码基本上也是百花齐放,有 PHP、Java,又有python和go。。那段时间的我压力很大,而我也不敢轻易辞职。上班基本靠百度,回了家就是躺,没有多余的想法。
也是那一段时间,我开始尝试自己应用 workflow 工作流,但结果也是非常不尽人意,毕竟我没有团队。。后来后端趋于稳定,我也慢慢意识到自己不能再继续躺平,我需要继续开始学习了。。。

一、Git 的原理
当你选择用 git 来管理你的项目,就需要使用
git init
初始化你的项目。这条命令会在你的目录生成一个正常状态下隐藏的
.git
文件,里面包含了
branches
—— 分支目录、
hooks
—— 生命钩子目录、
objects
—— 节点目录 和
refs
—— 指针目录等等配置文件。
git add .做了什么?
git add
命令是
git hash-object -w 文件名称
和
git update-index --add --cacheinfo 权限 \ 节点哈希值 文件名称
这两条指令的合并。前者把当前文件压缩成二进制文件,压缩后的二进制文件,称为一个 git 对象,保存在.git/objects目录。
并且这个命令还会计算当前内容的 SHA1 哈希值(长度40的字符串),作为该对象的文件名。目录名是哈希值的前2个字符,该文件目录下面有一个文件,文件名是哈希值的后38个字符。
文件保存成二进制对象以后,通过第二条命令,通知 git 哪些是有变动的文件。所有变动的文件,git 都记录在一个区域,叫做"暂存区"(英文叫做 index 或者 stage)。
git commit -m又做了什么?
git commit
命令是
git write-tree
和
git commit-tree
这两条指令的合并。前者用于构建关系树,也可以叫目录树,是描述文件之间的交叉关系的这么一个树形结构,这也属于一个节点对象,会被存到
objects
文件夹之中。
后者用于将目录树对象写入到版本历史。这个命令将元数据和目录树,一起生成一个 Git 对象,然后提交到版本历史之中。
branch分支的概念是什么?
分支可以理解为文件的快照备份。正常的工作中我们需要有一个稳定的代码版本,提供给线上用户,也就是
master
分支。这个分支我们不可以直接拿来更改开发,这样一不小心可能会造成不可逆的后果。
当我们日常的开发需要代码时候,我们通常会复制一份,即命令 git 执行一次快照备份,创建一个新的分支,也就是
dev
分支。这种分支的概念就是为了保证线上代码的稳定,预防线上bug的一种手段。
二、利用 Git 搭建私人代码仓库
之所以有私人代码库的概念,,无非就是公司项目的代码不想托管到公共的平台上,或者满足一些私人网站的独立部署而已。而我们利用 git 也很好实现,只需要执行
git init --bare 仓库名.git
即可。
--bare
示新仓库不需要工作目录,只建立 git 数据目录。具体的执行步骤如下:
- 首先你需要有一台服务器,云服务器或者本地 Windows 服务器都可以,我们就以常见的云服务器 centos 为例;
- 创建 git 用户,这一步其实是可选的,但是有条件呢,还是建议要创建,因为需要考虑到后期团队共享仓库的安全性,所以需要针对 git 做一定的权限限制;关于创建用户,使用
adduser git即可生成; - 切换回本地电脑,创建密钥,通过
ssh-keygen -t rsa -C "你的邮箱"生成你本机的专属密钥,紧接着打开生成的.pub文件,复制到云服务器上。在云服务器的~/.ssh/目录下创建一个authorized_keys文件,然后把刚刚复制的内容粘贴上去。这一步主要是为了打通本地和云端的 SSH 链接; - 为 git 用户创建密码,后续你所有的本地 git 操作,都需要先登录才可以继续。执行
sudo passwd git即可为账户设置密码; - 切换回本地电脑,执行
ssh -T git@你的服务器IP或者域名测试是否登录连接成功。如果连接成功,就可以像平常工作一样在本地使用 git 提交代码了。

(累了吗?看一会风景继续战斗吧。)
接下来要学习的就是日常工作中用的比较多的知识点了,关于这些知识的规划,我会从比较宏观的角度(工作流)开始讲,接着就是微观的角度(分支管理策略)和使用规范(提交管理)来循序渐进的展开。
因为我觉得这个顺序可能比从原始的概念开始讲,更会贴近你的日常开发,使你产生共鸣,从而会更加牢记。努力从应用切入到原理让你学懂。
三、Workflow 工作流选择
这里主要介绍3种工作流:
- Git 工作流
- GitHub 工作流
- Gitlab 工作流
1. Git 工作流(Git flow)
这是最简单也是最基础的工作流,分为 master 和 dev 分支。master 分支提供给线上对外发布的版本,任何时候在这个分支拿到的,都是稳定的分布版。而 dev 用于日常开发,存放最新的开发版,就没了。
另外还会存在其他短期分支,例如 feature 功能分支、release 预发分支 和 hotfix 补丁分支。这三个都是应对不同情况而产生的分支,一旦处理完相应的功能或者问题,就会被删除。
其次我认为这种短期分支是在每种工作流中都会存在的,所以就不再做过多的描述。
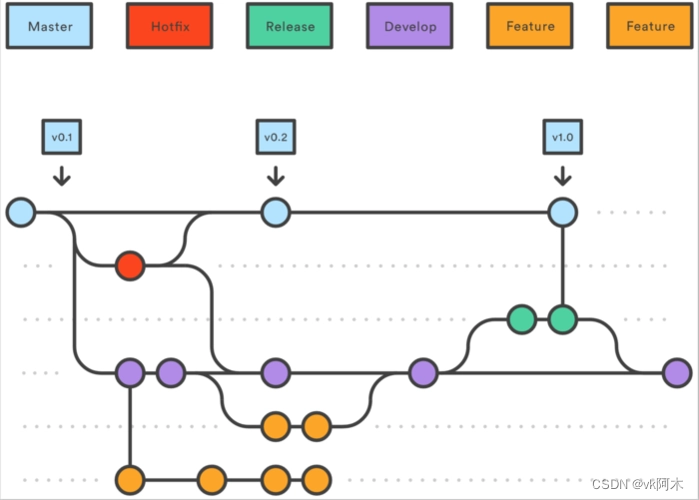
(图片取自百度,侵删。)
- Git flow的优点是清晰可控,问题在于,它需要维护两个长期分支。另外,这个模式是基于"版本发布"的,目标是一段时间以后产出一个新版本。但是,很多网站项目是"持续发布",代码一有变动,就部署一次。这时,master分支和develop分支的差别不大,没必要维护两个长期分支。
- 总而言之策略还是相对简单了些,稳定性好,但弹性不够大,不能很好的应付复杂情景,但个人开发也足够满足。
2. Github 工作流(Github flow)
这种工作流相比于第一种,又简化了,但却比第一种更加有效,那就是它只存在一个长期分支 master。
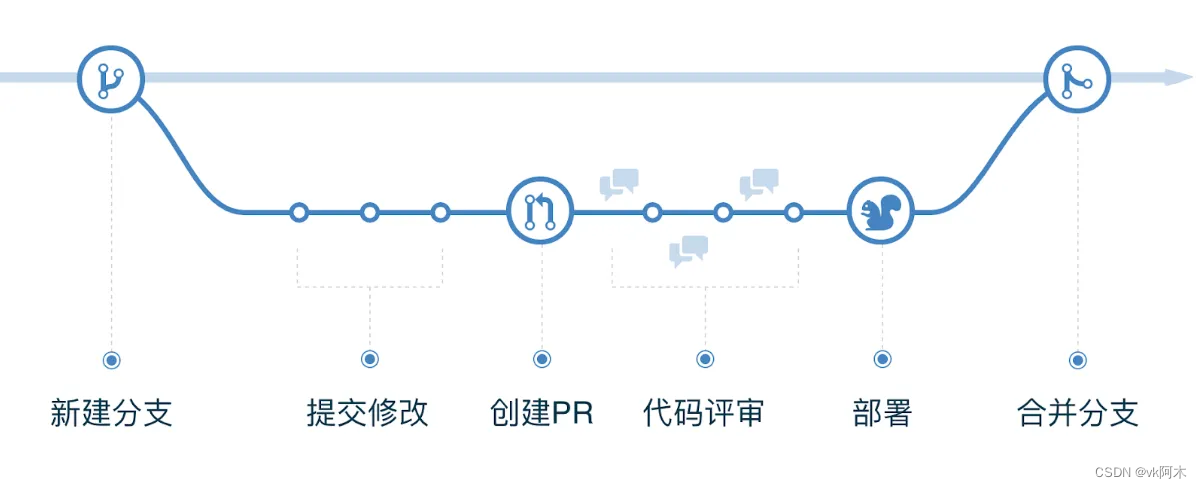
(图片取自百度,侵删。)
从上图我们可以看到,每次需要开发新功能,都会从master直接拉出来一个分支,然后经过一系列的提交修改,代码评审和部署,最终合并到 master 分支上。
特点是它拥有一个
pull request
机制,这是一种对话机制,意思就是告诉主分支我请求合并给你,你来看看我。大家一起评审和讨论你的代码。对话过程中,你还可以不断提交代码。一旦你的Pull Request被接受,合并进master,重新部署后,原来你拉出来的那个分支就被删除。
- Github flow 的最大优点就是简单,对于"持续发布"的产品,可以说是最合适的流程。
- 问题在于它的假设:master分支的更新与产品的发布是一致的。也就是说,master分支的最新代码,默认就是当前的线上代码。可是,有些时候并非如此,代码合并进入master分支,并不代表它就能立刻发布。比如,苹果商店的APP提交审核以后,等一段时间才能上架。这时,如果还有新的代码提交,master分支就会与刚发布的版本不一致。另一个例子是,有些公司有发布窗口,只有指定时间才能发布,这也会导致线上版本落后于master分支。
- 上面这种情况,只有master一个主分支就不够用了。相对于第一种工作流,github flow 其实已经在分支管理的策略上做出了一定程度的优化。但是,选择这种策略反而牺牲了对于版本精准的控制。因此,你不得不在master分支以外,另外新建一个
production分支跟踪线上版本。
3. Gitlab 工作流(Gitlab flow)
而 gitlab flow 则是吸取了前两者的优点所诞生的一种工作流,它最大原则叫做"上游优先"(
upsteam first
),即只存在一个主分支master,它是所有其他分支的"上游"。只有上游分支采纳的代码变化,才能应用到其他分支。
Gitlab flow 完美的适应了两种不同的发布情况:
- 持续发布
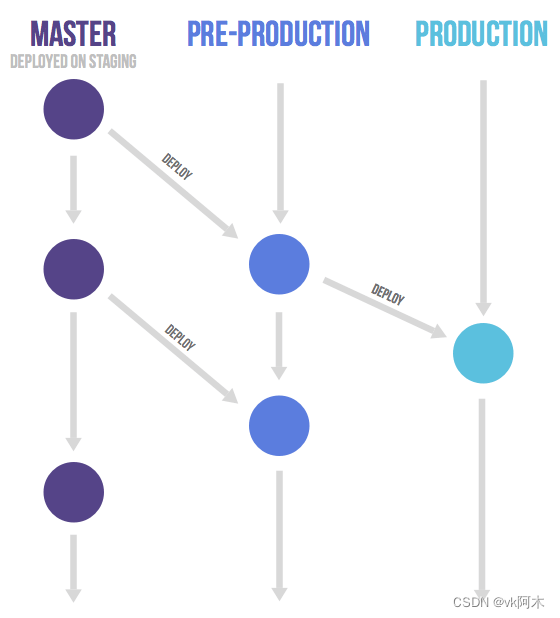
(图片取自阮一峰老师的文章,文末已注明参考来源。)
对于"持续发布"的项目,它建议在master分支以外,再建立不同的环境分支。比如,"开发环境"的分支是master,"预发环境"的分支是
pre-production
,"生产环境"的分支是
production
。
开发分支是预发分支的"上游",预发分支又是生产分支的"上游"。代码的变化,必须由"上游"向"下游"发展。比如,新增了一个功能需求,这时就要新建一个功能分支,先把它合并到master,确认没有问题,再
cherry-pick
到pre-production,这一步也没有问题,才进入production。
只有紧急情况,才允许跳过上游,直接合并到下游分支。
- 版本发布
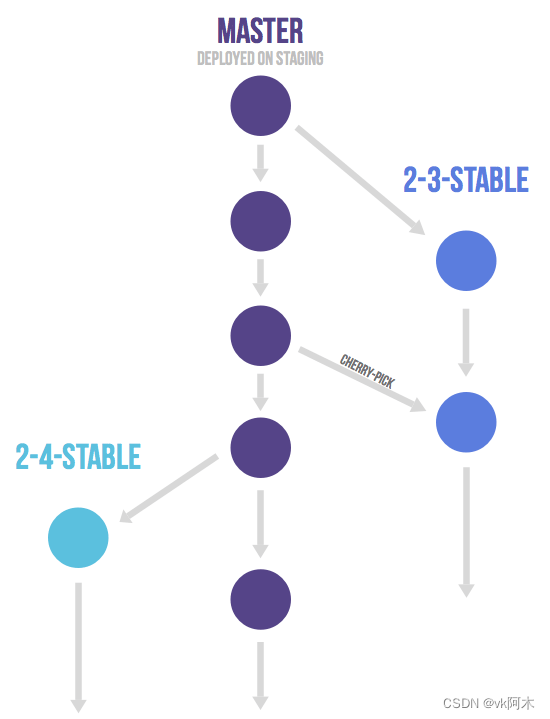
(图片取自阮一峰老师的文章,文末已注明参考来源。)
对于"版本发布"的项目,建议的做法是每一个稳定版本,都要从master分支拉出一个分支,比如
2-3-stable
、
2-4-stable
等等。以后,只有修补bug,才允许将代码合并到这些分支,并且此时要更新小版本号。
四、Branch 分支管理策略
这里讲3个主要分支,分别介绍它们的意义和应用:
- master 主分支
- dev 开发分支
- feature 功能分支
1. master 主分支
这是最原始也是最基本的一个分支,每一个代码库都应该有且仅有一个主分支。所有提供给用户使用的正式版本,都在这个主分支上发布。
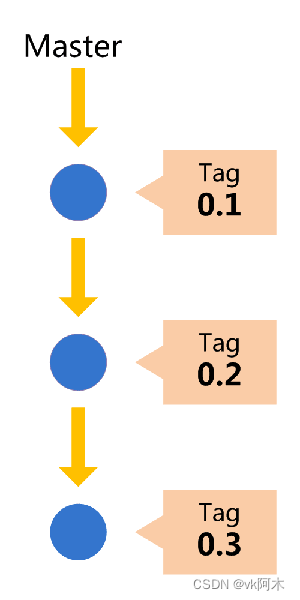
(图片取自阮一峰老师的文章,文末已注明参考来源。)
master 分支在仓库创建之后就会自动生成,在不同的工作流中它扮演着不同的角色。例如在 git、github 工作流内, 它是主分支;在 gitlab 工作流内,它又是开发分支。作为主分支时,它一般都是用来发布重大版本。
2. dev 开发分支
在 git 工作流中,我们通常都会新建一个开发分支 dev,目的是不影响线上版本获取稳定可用的代码,保证 master 分支的稳定性,做到开发和发布互不影响。
当我们需要开发新功能时,只需要从 dev 拉出一个新分支,用于开发新的功能模块。等开发结束之后,申请合并到 dev 分支,dev 分支合并没问题之后,再提交合并到 master 分支,从而发布一个包含新功能模块的版本。
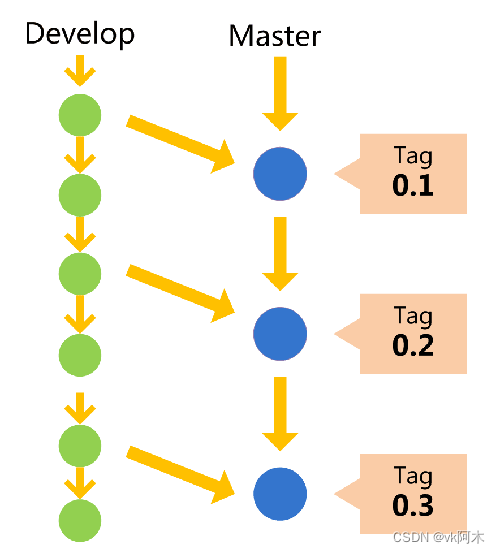
(图片取自阮一峰老师的文章,文末已注明参考来源。)
但一般这样就需要维护两个长期分支,dev 分支和 master 分支都有频繁的互动,开发者必须要保证两个分支的同步,否则就GG。
3. feature 功能分支
这个分支属于是临时性分支。临时性分支的意思就是在它完成自己的使命之后,就会被剔除。feature 功能分支的生命周期一般是新功能需求确定下来之后,拉出新的功能分支。等功能开发自测完毕之后,提交申请合并到 dev 分支,做进一步的测试。合并完成之后,feature 功能分支就会被删除掉了。
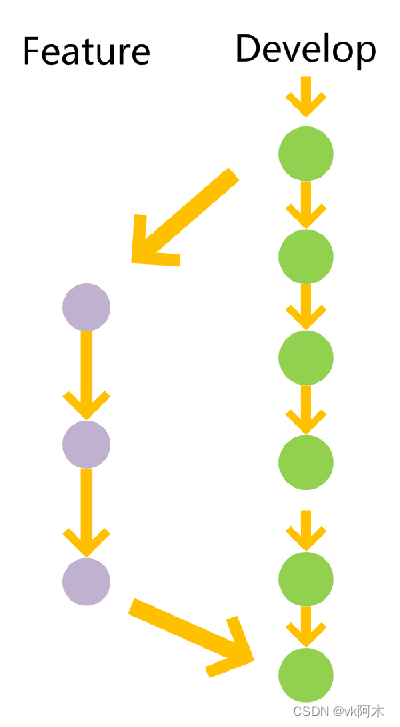
(图片取自阮一峰老师的文章,文末已注明参考来源。)
同属于临时性分支的还有预发分支(release)、紧急分支(hotfix)。这些分支都是跟 feature 功能分支一样,完成自己的职责之后就会被删除,因此后面就不再赘述。
临时性分支的特点是在任何工作流都会有可能存在。
如上图所示,选择一个好的分支管理策略,能够完整的保存下来它的 git 历史脉络,每一条分支的走向都非常清晰,对于我们后期追本溯源有很大的帮助。就算你不需要回退版本,这样子看着也会非常的舒适!
五、Git 使用规范 (Commit 提交管理)
延续上图的示例,你可以看到每一次拉出新的分支,提交请求合并时,我都会写跟其他功能分支一样的备注。因此,除了分支管理之外,我们在日常开发中还需要做好 git 的
提交使用规范
。
在团队开发中,一定要遵循合理且清晰的提交规范。假如团队有20-30个人,每个人提交时,都备注不同的信息,那么很快项目也会变得难以查看和维护。
因此,好的 git 使用规范对于我们日常的开发也是非常重要的。另外我也推荐使用提交管理工具,例如 Commitizen。
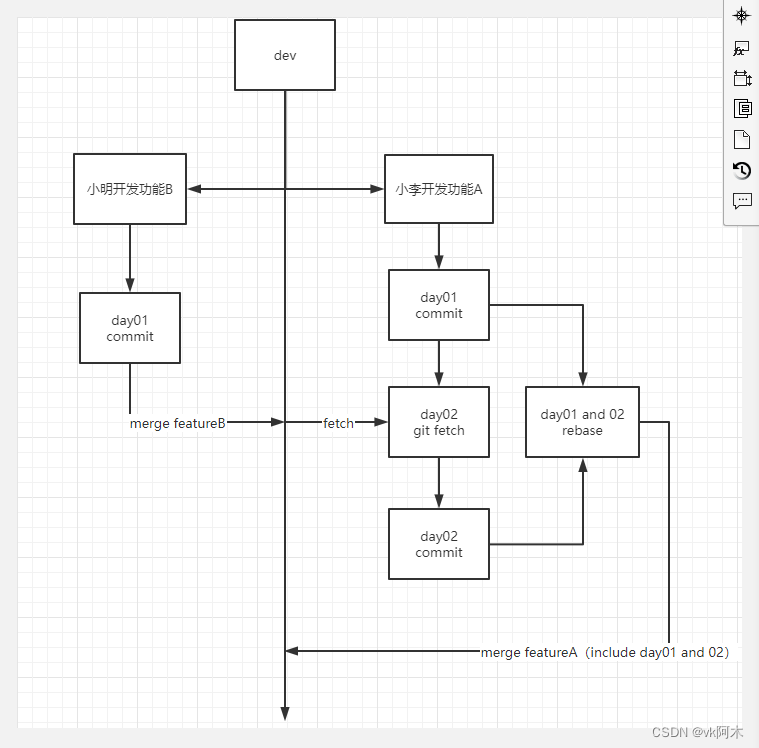
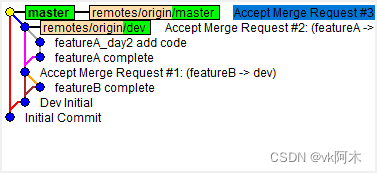
如上图所示,我们以 dev 分支为基础,给小李和小明分别分配开发不同的功能点。
小明的功能比较轻松,只用了一天就提交合并了,备注为
featureB complete
。
小李的任务比较重,总共花了两天,第一天下班之前它把今天的代码提交推送了一次。但是这个时候他还不能提交合并(PR),因为他的功能还没有完成。
第二天来的时候,小明说自己的功能昨晚已经提交合并了,你更新一下本地的分支。
然后小李就回来
git fetch origin dev
更新一下,保持最新进度。此时我们只是想把远端仓库对应分支的变更拉到本地而已,并不想自动合并到我的工作区(你当前正在进行代码变更的工作区)。等晚些时候我写完了某部分的代码之后再考虑合并,那么你就可以先使用 git fetch 而不是 git pull,因为 git pull 会直接合并你们的工作区,这就意味着合并了小明的代码了。
第二天快结束的时候,小李终于把功能做完提交了。此时他准备提交自己的代码了,前提就需要先更新自己的本地仓库。前面说了,我们只 git fetch 拉取了更新,但未合并,因此现在需要先合并。执行
git rebase origin/dev
即可合并小明的代码。
但是小李两天提交的内容不一样,他又想和小明的提交保持一致,此时需要执行合并提交指令。执行
git rebase -i origin/dev
开启互动界面,从而编辑、合并 commit 信息,把 commit 信息改为
featureA complete
,跟小明保持一致。
然后在托管平台它们的老大 review 代码的时候,就点开小李的 commit 查看,里面就包含着他分为两天提交的信息。
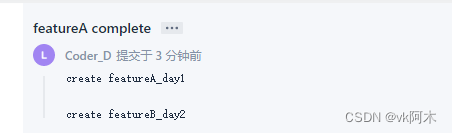
这里就包含着小李合并起来的提交信息。可见良好的使用规范,提交规范,给它们的团队的合作带来了不少便利!
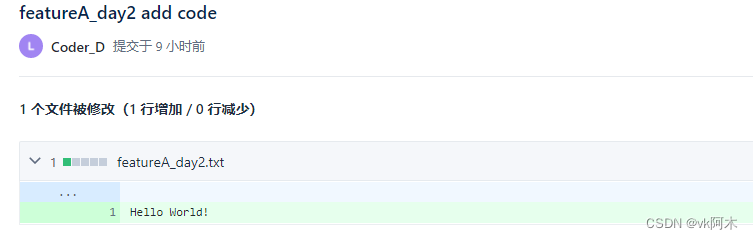
当然在提 PR 时,团队也可以对小李的代码进行评审和讨论,例如我们还需要小李对
featureA_day2.txt
添加一行代码。小李改完后,就再次提交合并:
最后的效果也是显而易见的清晰明了。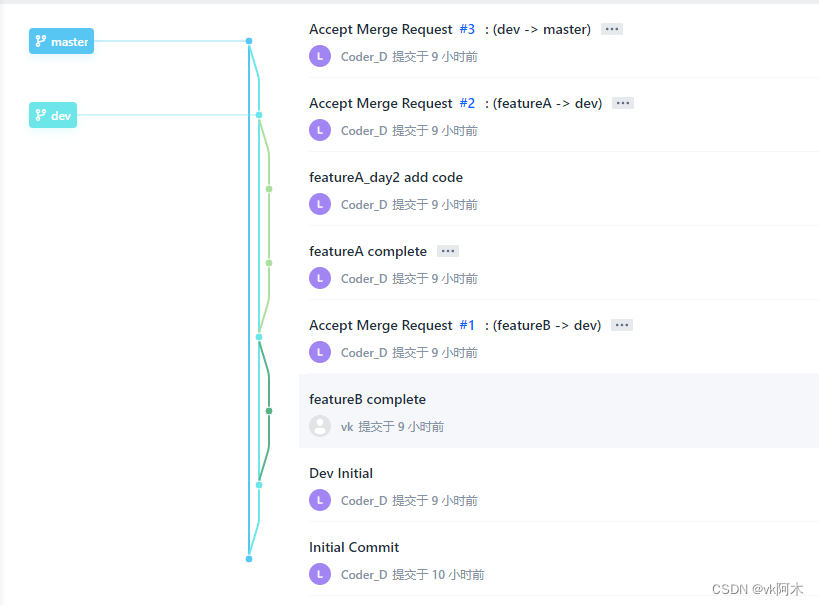
至于使用 rebase 而不是 merge 的原因:git 在执行 merge 指令时,默认情况下,“快进式合并”(
fast-farward merge
),会直接将dev分支指向feature分支。
如果我们需要保存这次提交历史,我们可以加上
--no-ff
参数进行 merge。这种情况下feature的最新节点和dev的最新节点会合并,且进行一次新的提交,这次提交的历史就是我们需要保留下来的。
当然你可以在安装 git 时,就有选项供你选择是否采用 fast-farward 模式了,你也可以在那时候就决定好策略。
另外一种情况则相反,如果这些提交历史的保存是没有意义的,这就意味着我们可以折叠 commit ,只需要加上
--squash
参数合并 commit 即可。
但是,执行
merge --squash
,并不能编辑合并提交信息,而是由 parent 分支重新 commit 一次,这次 commit 才是你想要的。这也就意味着,我们不仅多执行了一次提交,而且还需要拉起一条分支来,供 parent 分支再次提交 commit 。
遗憾的是,
--squash
和
--no-ff
这两个参数并不能一起使用,所以,merge 指令并不能实现即记录历史又合并commit。
但也不完全是没有办法,我们可以撤销前面几次的 commit,使用
git reset HEAD^次数
。然后重新 add 、commit 为一次新的提交,接着再使用
merge --no-ff
以此来保留这次提交历史,这样我们就可以不用拉起一条新分支。可我总觉得这样处理我们的 commit 有些欠佳,因为我们没办法保证前面几次的 commit 是否也需要保留。
而
rebase
只是在合并 commit 提交信息的前提下,在 dev 分支上把他们的 feature 分支合并上去,并没有产生多余的提交,最后 dev 的分支是一条直线,也就是我们上面看到的那样。用法就是
git rebase -i origin/dev
,
-i
的意思就是开启对话,让我们可以自由选择合并的处理方式和编辑提交的信息。
然而
rebase
也有缺点。当我们执行完 rebase 指令,要再次推送时:由于本地的分支历史已经和远端的分支历史不同了,因此你正常推送是推不上去的,需要加上
--force
强制推送,即
git push --force origin dev
。
如果这条分支只有你一个人开发,那么这么做没有太大的问题。如果是多人开发,那么就一定要慎重了!因为强制推送的风险实在是太大了,搞不好可能就会把其他同事的远端代码搞没。
总结
- 如果分支上仅有自己开发,那么选择 rebase 还是 merge 并没有太大的区别,只是用法上有所不同。
- 如果分支上还有其他同事开发,那么上面当小明叫你更新本地代码时,即执行完
git fetch指令之后,就要选择使用 merge 了,后面的提交也一定要使用 merge。
可能你也注意到了,我在使用规范时:
- 对于工作流,我选择了 Git flow;
- 对于分支管理,我由 dev 分支,根据功能需求,创建了两个临时分支 featureA 和 featureB,功能完成就删除;
- 对于使用规范,我将 featureA 和 featureB 的提交信息保持一致,其中 featureA 的2次提交信息被我合并到了一起。
这也就是为什么我选择从工作流开始讲起,到这里,我们相当于把日常工作中的情况模拟了一遍,我也希望能帮助你更好的理解。
六、Remote 远程管理
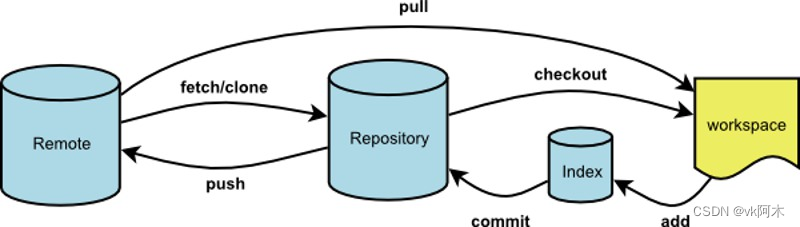
(图片取自阮一峰老师的文章,文末已注明参考来源。)
这里讲4个远程控制命令:
git remote
git remote 用于管理查看远程主机名称。git remote add 用于添加远程主机,例如 git remote add origin <git 地址>。git remote -v 可以查看你的 git 地址。git remote rm origin 可以删除远程主机,一旦删除,本地与远程主机的链接就意味着断开了,之后的任何远程操作都不会成功。
git fetch
git fetch 可以把远程的代码库拉回本地,保持本地最新的代码,使用 git fetch <主机名称> 就会把全部分支都更新。如果想拉回指定分支的代码,那么可以使用 git fetch <主机名称> <分支名称>,例如 git fetch origin dev。
注意:拉回最新代码之后,本地主机还需要读取合并,才会更新本地主机的代码库。这时候就需要使用到
merge
或者
rebase
。
git pull
git pull 和 git fetch 有些类似,它相当于是 git fetch 和 git merge 的合并命令。这条指令作用是拉取指定分支的最新节点,然后合并分支。
用法是
git pull <远程主机名称> <远程分支名称>:<本地分支名称>
。如果你正处于需要合并的本地分支上,那么后面的本地分支名称可以省略不写。
在你首次拉取远程代码到本地时,git 是会自动生成追踪关系的,即
git branch --set-upstream master origin/master
(此命令可用于改写追踪关系)。当你的本地分支与远程分支只有一个追踪关系,也就是只有一个分支关系时,直接 git pull 就可以更新代码。
另外,git pull 也可以选择采用
rebase
模式,用法是
git pull --rebase <远程主机名> <远程分支名称>:<本地分支名称>
,效果和 git fetch + git rebase 是一样的。
git push
这个命令用于推送本地代码到远程仓库上,如果远程分支不存在,则会被新建。用法是
git push <远程主机名> <本地分支名称>:<远程分支名称>
,如果不写远程分支名称,git 则会根据追踪关系,推送到相对应的远程分支上。
相反的,如果不写本地分支名称且带有冒号,则表示删除远程分支,用法是
git push <远程主机名称> :<远程分支名称>
。例如
git push origin :dev
。
跟 pull 一样,当你处于所需要推送的分支上时,则可以省略后面的分支名称不写,直接
git push orgin
即可。同样,如果只存在一个追踪关系,即只有一个分支关系时,直接 git push 即可。
七、撤销提交、代码回滚
1. 撤销提交
git revert [--no-edit | --no-commit] [HEAD | SHAid1 SHAid2...]
该命令的作用是,
根据你的 commit 信息,撤销你的缓存区和工作区的改动。当你选择的 commit 是在当前 commit 的前2个时,只撤销缓存区,工作区不会被撤销,同时形成一次新的提交
。第二个参数不是必填,第三个参数是必填的。用法是
git revert HEAD
,即把当前的提交撤销。
HEAD^
把上一个提交撤销。
git revert HEAD^^
,撤销前面两个的提交,形成一次新提交。但此时选择的 commit 和当前 commit 超过2个,因此,效果只是,撤销缓存区,不撤销工作区(也就是你前面两次提交的文件还存在),并形成一次新提交。
注意:执行
git revert --no-commit HEAD
时,会进入 Reverting 互动区,git 会让你自行选择继续生成提交(–continue),还是取消这次撤销(–abort)。如果继续提交,则会进入互动界面编辑提交信息。
个人认为如果没有超过2次提交执行这个指令,会很危险,因为 git 把我的工作区文件都弄没了。
git reset [--soft | --mixed | --hard] [last SHAid | HEAD HEAD^^ HEAD~n]
这条命令也用于撤销提交,但与上一条指令不同的地方是,我们执行之后,不需要重新执行一次提交,
git log
也找不到我们之前的提交信息。
--soft
是撤销提交(commit),不撤销缓存区和工作区;
--mixed
是撤销提交和缓存区,不撤销工作区;
--hard
是撤销所有提交内容,工作区也会消失。不添加这个参数时 git 默认执行
--mixed
指令。
reset 的好处就是只要不是刻意删除,我的工作区的文件就不会被误删,虽然丢失了 commit ,但还是可以通过 git reflog 查看之前的提交历史。
git commit -amend -m "msg"
这条指令的作用是,生成一个新的提交,然后把上一次的提交完整的替换掉。期间,如果缓存区有新的变化,也会被一并提交。通常使用的场景是:例如我们写了bug但是自己发现了,为了不让别人发现,可以覆盖掉;或者是提交之后,感觉写的不完美,优化之后产生了一个新文件,此时可以先添加新文件到缓存区,然后执行这条命令,把新的文件和老的文件一并替换为上一次提交的内容。
直接覆盖: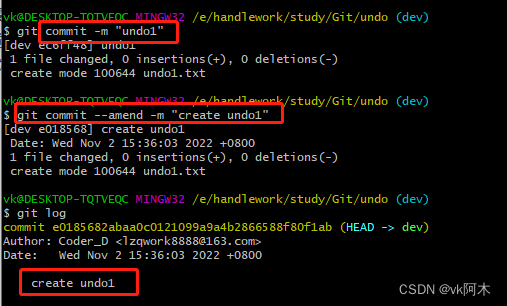
添加新文件覆盖:
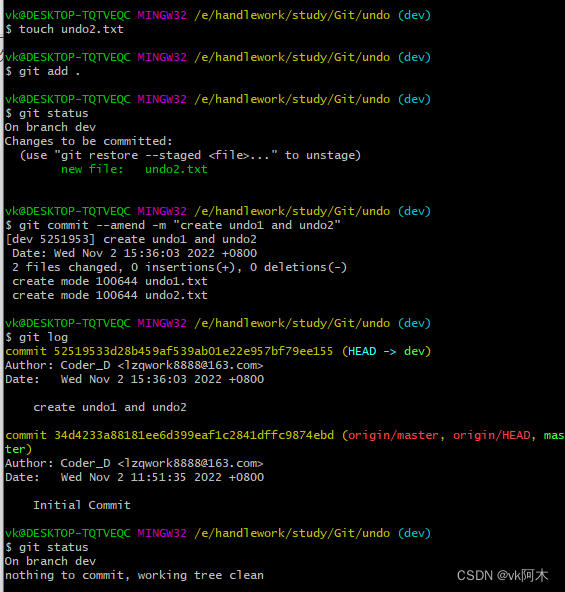
2. 撤销文件
- 撤销缓存区的文件
由于缓存区文件的特性,因此如果我们不想提交或者是提交错误,可以及时清除,或者重新缓存其他文件都可以。用法是:
git rm --cached [filename]
- 撤销工作区的文件
操作工作区的文件一定要慎重!一旦撤销就再也找不回来了!!! 我们可以执行
git checkout -- [filename]
来找回之前的文件。它的原理是:先找暂存区,如果该文件有暂存的版本,则恢复该版本,否则恢复上一次提交的版本。
3. 撤销分支
你在当前分支上做了几次提交,突然发现放错了分支,这几个提交本应该放到另一个分支。
# 新建一个 feature 分支,指向当前最新的提交# 注意,这时依然停留在当前分支git branch feature
# 切换到这几次提交之前的状态git reset --hard [当前分支此前的最后一次提交]# 切换到 feature 分支git checkout feature
上面的操作等于是撤销当前分支的变化,将这些变化放到一个新建的分支。
总结
- 不要轻易使用 revert;
- 工作区的文件不要轻易撤销;
- 每次开发前可以基于当前分支新建一个分支,开发完可以考虑
merge或者cherry-pick;- 如果需要回滚版本,最好是基于当前分支新建一个分支,进行回滚。
(调整休息一下,继续战斗~)
八、Cherry-pick 单节点操作
git cherry-pick命令的作用,就是将指定的提交(commit)应用于其他分支。例如执行:
git cherry-pick dev <commitHash>
,就会将对应SHA值的节点给应用到 dev 分支上。
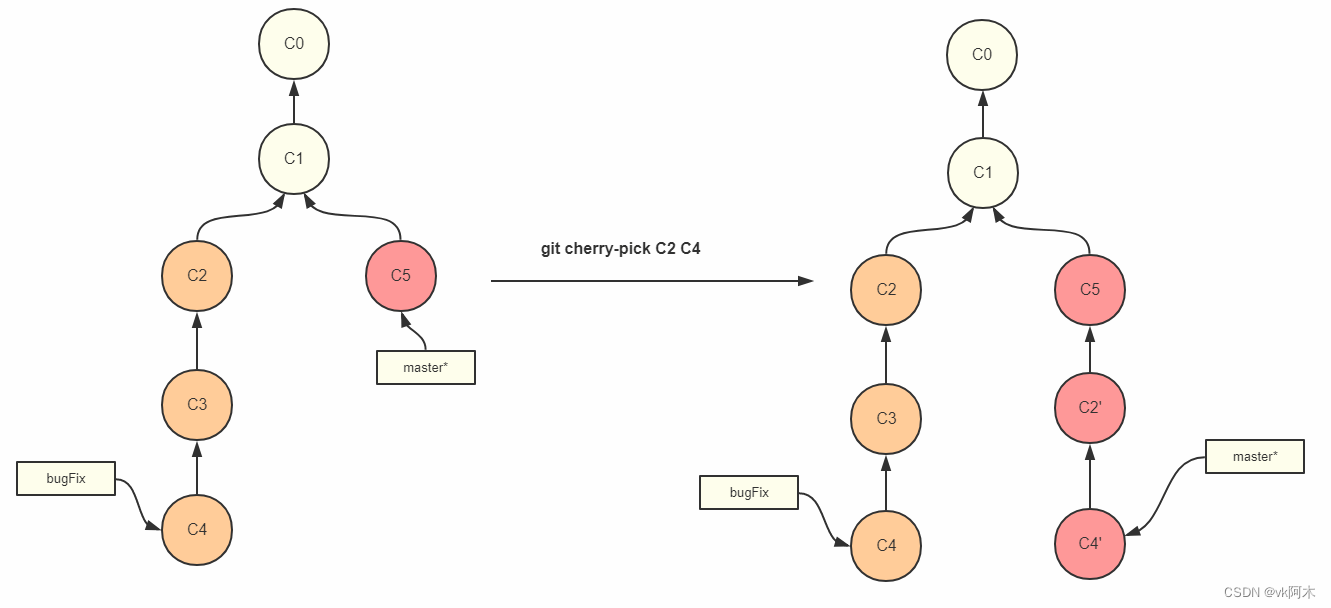
(图片取自百度,侵删。)
它的用法是:
git cherry-pick [-e | -n | -x | -s | -m] [commitHash1 commitHash2... | commitHashA^..commitHashC | branch]
。
第一个参数:
-e
指打开外部编辑器,编辑提交信息;
-n
是指
--no-commit
,执行完之后和 revert 一样, 只变更缓存和工作区,不提交。然后进入互动区,由用户继续操作;
-x
会在提交信息的末尾追加一行(
cherry picked from commit ...
),方便以后查到这个提交是如何产生的;
-s
是
--signoff
的缩写,会在提交信息的末尾追加一行操作者的签名,表示是谁进行了这个操作;
-m
会告诉 git,应该采用哪个分支的变动。它的参数
parent-number
是一个从1开始的整数,代表原始提交的父分支编号。
因为如果原始提交是一个合并节点,来自于两个分支的合并,那么 Cherry pick 默认将失败,因为它不知道应该采用哪个分支的代码变动。所以我们需要使用
-m
指令,例如:
git cherry-pick -m 1 <commitHash>
。
以下模拟几种场景,我们利用 cherry-pick 来处理:
- 当我们提交了多次以后,发现提交错分支了怎么办?
- 可以使用
reset回退之后,携带被回退的 commit,checkout 转移到其他分支;
- 可以使用
- 可以使用
cherry-pick批量选择 commit 转移到其他分支上,然后再reset回退原分支。
- 可以使用
- 当我提交完之后还未推送,不小心把分支删了怎么办?
- 可以使用
cherry-pick选择指定 commit 转移到其他分支上。
- 可以使用
- 当我发现昨天的提交的代码提PR时被冲掉了,导致我的文件缺失怎么办?
- 可以先 reset 回退到昨天的 commit,然后把需要的文件复制一份,再执行 git reflog,找到今天的 commitHash,往前滚到今天的代码版本,然后粘贴即可。
九、Bisect 错误排查(二分法)
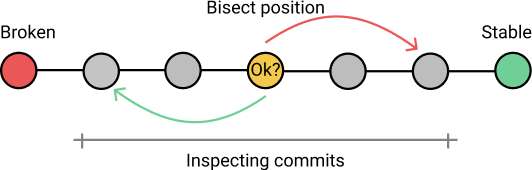
(图片取自阮一峰老师的文章,文末已注明参考来源。)
git bisect
用于排查哪一次代码提交引入了错误。
假设您在代码库中遇到了一个错误,并且不确定何时引入该错误。如果您可以找到某次代码可以正常工作的提交,而不可以找到代码无法正常工作的提交,则不必手动一次一次查找有问题的提交;使用git-bisect可以快速定位到错误的提交。
它的用法是:
git bisect start end
。
十、使用工具
常见的工具有
husky
、
commitlint
和
commitizen
。前者是操作 git 声明钩子的工具,后两者则是对于 commit 的校验和配置工具。当然,如果你愿意,你完全可以实现一个
cli
脚手架配置属于你自己的提交规范,推荐的有 icon-commit。
至此,本篇文章就写完了,写这篇文章陆陆续续花了我3天的时间。不过最后看见自己整理的成果还是挺满足的,希望我的文章对你有所帮助吧。
感谢你的阅读~ 愿你的未来一片光明。
参考文章
[ 开发者手册 ] —— 阮一峰
[ 女朋友说 Git 玩不明白,怎么办?安排!] —— 陌小路
版权归原作者 vk阿木 所有, 如有侵权,请联系我们删除。