
Iceberg从入门到精通系列之二十一:Spark集成Iceberg
Iceberg的最新版本是1.4.3。
Spark 是目前用于 Iceberg 操作的功能最丰富的计算引擎。建议您开始使用 Spark,通过示例了解 Iceberg 概念和功能。您还可以在多引擎支持页面下查看将 Iceberg 与其他计算引擎结合使用的文档。
一、在 Spark 3 中使用 Iceberg
要在 Spark shell 中使用 Iceberg,请使用 --packages 选项:
spark-shell --packages org.apache.iceberg:iceberg-spark-runtime-3.2_2.12:1.4.3
如果想在 Spark 安装中包含 Iceberg,请将iceberg-spark-runtime-3.2_2.12 Jar 添加到 Spark 的 jars 文件夹中。
二、添加目录
Iceberg 附带了目录,使 SQL 命令能够管理表并按名称加载它们。使用spark.sql.catalog.(catalog_name)下的属性配置目录。
此命令为 $PWD/warehouse 下的表创建一个名为 local 的基于路径的目录,并向 Spark 的内置目录添加对 Iceberg 表的支持:
spark-sql--packages org.apache.iceberg:iceberg-spark-runtime-3.2_2.12:1.4.3\--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \--conf spark.sql.catalog.spark_catalog.type=hive \--conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog \--conf spark.sql.catalog.local.type=hadoop \--conf spark.sql.catalog.local.warehouse=$PWD/warehouse
三、创建表
要在 Spark 中创建第一个 Iceberg 表,请使用 Spark-sql shell 或 Spark.sql(…) 运行 CREATE TABLE 命令:
CREATETABLElocal.db.table(id bigint,data string)USING iceberg
Iceberg 目录支持全系列 SQL DDL 命令,包括:
- CREATE TABLE … PARTITIONED BY
- CREATE TABLE … AS SELECT
- ALTER TABLE
- DROP TABLE
四、写
创建表后,使用 INSERT INTO 插入数据:
INSERTINTOlocal.db.tableVALUES(1,'a'),(2,'b'),(3,'c');INSERTINTOlocal.db.tableSELECT id,dataFROM source WHERE length(data)=1;
Iceberg 还向 Spark、MERGE INTO 和 DELETE FROM 添加了行级 SQL 更新:
MERGEINTOlocal.db.target t USING(SELECT*FROM updates) u ON t.id = u.id
WHENMATCHEDTHENUPDATESET t.count = t.count + u.count
WHENNOTMATCHEDTHENINSERT*
这段代码是一个使用 MERGE INTO 语句进行数据合并的示例。它将来自更新表的数据合并到目标表中。具体的操作如下:
- 使用子查询
(SELECT * FROM updates) u获取更新表的数据,并将其作为源表使用。 - 使用目标表
local.db.target作为目标表进行更新。 - 使用
ON t.id = u.id来指定源表和目标表之间的连接条件。这里使用了id列作为连接条件。 - 当连接条件匹配时,执行
WHEN MATCHED分支的操作。这里使用UPDATE SET t.count = t.count + u.count将目标表中的count列的值增加源表中对应行的count值。 - 当连接条件不匹配时,执行
WHEN NOT MATCHED分支的操作。这里使用INSERT *将源表中的数据插入到目标表中。
总之,这段代码通过 MERGE INTO 语句将更新表的数据合并到目标表中,根据连接条件进行更新或插入操作。
Iceberg 支持使用新的 v2 DataFrame 写入 API 写入 DataFrame:
spark.table("source").select("id","data").writeTo("local.db.table").append()
支持旧的写入 API,但不推荐。
五、读
要使用 SQL 读取,请在 SELECT 查询中使用 Iceberg 表名称:
SELECTcount(1)as count,dataFROMlocal.db.tableGROUPBYdata
SQL 也是检查表的推荐方法。要查看表中的所有快照,请使用快照元数据表:
SELECT*FROMlocal.db.table.snapshots
+-------------------------+----------------+-----------+-----------+----------------------------------------------------+-----+
| committed_at | snapshot_id | parent_id | operation | manifest_list |... |
+-------------------------+----------------+-----------+-----------+----------------------------------------------------+-----+
|2019-02-08 03:29:51.215 |57897183625154| null | append | s3://.../table/metadata/snap-57897183625154-1.avro |... |||||||... |||||||... ||... |... |... |... |... |... |
+-------------------------+----------------+-----------+-----------+----------------------------------------------------+-----+
支持 DataFrame 读取,现在可以使用 Spark.table 按名称引用表:
val df= spark.table("local.db.table")
df.count()
六、Catalogs
Spark 添加了一个 API 来插入用于加载、创建和管理 Iceberg 表的表目录。 Spark 目录是通过在spark.sql.catalog 下设置Spark 属性来配置的。
这将创建一个名为 hive_prod 的 Iceberg 目录,该目录从 Hive 元存储加载表:
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://metastore-host:port
# omit uri to use the same URI as Spark: hive.metastore.uris in hive-site.xml
以下是名为rest_prod 的 REST 目录示例,该目录从 REST URL http://localhost:8080 加载表:
spark.sql.catalog.rest_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.rest_prod.type = rest
spark.sql.catalog.rest_prod.uri = http://localhost:8080
Iceberg 还支持 HDFS 中基于目录的目录,可以使用 type=hadoop 进行配置:
spark.sql.catalog.hadoop_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hadoop_prod.type = hadoop
spark.sql.catalog.hadoop_prod.warehouse = hdfs://nn:8020/warehouse/path
基于 Hive 的目录仅加载 Iceberg 表。要在同一 Hive 元存储中加载非 Iceberg 表,请使用会话目录。
七、目录配置
通过添加属性spark.sql.catalog.(catalog-name) 及其值的实现类来创建和命名目录。
Iceberg 提供了两种实现:
- org.apache.iceberg.spark.SparkCatalog 支持 Hive Metastore 或 Hadoop 仓库作为目录
- org.apache.iceberg.spark.SparkSessionCatalog 在 Spark 的内置目录中添加了对 Iceberg 表的支持,并将非 Iceberg 表委托给内置目录
两个目录均使用嵌套在目录名称下的属性进行配置。 Hive 和 Hadoop 的常见配置属性有:
属性值描述spark.sql.catalog.catalog-name.typehive, hadoop or rest底层 Iceberg 目录实现、HiveCatalog、HadoopCatalog、RESTCatalog 或在使用自定义目录时保持未设置spark.sql.catalog.catalog-name.catalog-impl自定义 Iceberg 目录实现。如果 type 为 null,则 Catalog-impl 不得为 null。spark.sql.catalog.catalog-name.io-impl自定义 FileIO 实现。spark.sql.catalog.catalog-name.metrics-reporter-impl自定义 MetricsReporter 实现。spark.sql.catalog.catalog-name.default-namespacedefault目录的默认当前命名空间spark.sql.catalog.catalog-name.urithrift://host:portHive 类型目录的 Hive 元存储 URL、REST 类型目录的 REST URLspark.sql.catalog.catalog-name.warehousehdfs://nn:8020/warehouse/path仓库目录的基本路径Spark.sql.catalog.catalog-name.cache-enabledtrue or false是否启用目录缓存,默认值为truespark.sql.catalog.catalog-name.cache.expiration-interval-ms30000 (30 seconds)缓存的目录条目过期的持续时间;仅当启用缓存为 true 时才有效。 -1 禁用缓存过期,0 完全禁用缓存,无论是否启用缓存。默认值为 30000(30 秒)spark.sql.catalog.catalog-name.table-default.propertyKey属性键 propertyKey 的默认 Iceberg 表属性值,如果未覆盖,将在此目录创建的表上设置该值Spark.sql.catalog.catalog-name.table-override.propertyKey属性键 propertyKey 的强制 Iceberg 表属性值,用户无法覆盖该值
八、使用目录
目录名称在 SQL 查询中用于标识表。在上面的示例中, hive_prod 和 hadoop_prod 可用于为将从这些目录加载的数据库和表名称添加前缀。
SELECT*FROM hive_prod.db.table
Spark 3 跟踪当前目录和命名空间,表名称中可以省略它们。
USE hive_prod.db;SELECT*FROMtable
要查看当前目录和命名空间,请运行 SHOW CURRENT NAMESPACE。
九、替换会话目录
要将 Iceberg 表支持添加到 Spark 的内置目录,请配置 Spark_catalog 以使用 Iceberg 的 SparkSessionCatalog。
spark.sql.catalog.spark_catalog = org.apache.iceberg.spark.SparkSessionCatalog
spark.sql.catalog.spark_catalog.type= hive
Spark 的内置目录支持 Hive Metastore 中跟踪的现有 v1 和 v2 表。这将 Spark 配置为使用 Iceberg 的 SparkSessionCatalog 作为该会话目录的包装器。当表不是 Iceberg 表时,将使用内置目录来加载它。
此配置可以对 Iceberg 和非 Iceberg 表使用相同的 Hive Metastore。
十、使用目录特定的 Hadoop 配置值
与使用 Spark.hadoop.* 配置 Hadoop 属性类似,在使用 Spark 时,可以通过添加带有前缀 Spark.sql.catalog.(catalog-name).hadoop 的目录属性来设置每个目录的 Hadoop 配置值。 *。这些属性将优先于使用spark.hadoop.*全局配置的值,并且仅影响Iceberg表。
spark.sql.catalog.hadoop_prod.hadoop.fs.s3a.endpoint = http://aws-local:9000
十一、加载自定义目录
Spark 支持通过指定catalog-impl 属性来加载自定义Iceberg Catalog 实现。这是一个例子:
spark.sql.catalog.custom_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.custom_prod.catalog-impl = com.my.custom.CatalogImpl
spark.sql.catalog.custom_prod.my-additional-catalog-config = my-value
十二、SQL 扩展
Iceberg 0.11.0 及更高版本向 Spark 添加了一个扩展模块,以添加新的 SQL 命令,例如存储过程的 CALL 或 ALTER TABLE … WRITE ORDERED BY。
使用这些 SQL 命令需要使用以下 Spark 属性将 Iceberg 扩展添加到您的 Spark 环境:
Spark 扩展属性Iceberg扩展实施spark.sql.extensionsorg.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
十三、运行时配置-读选项
配置 DataFrameReader 时会传递 Spark 读取选项,如下所示:
// time travel
spark.read.option("snapshot-id",10963874102873L).table("catalog.db.table")
Spark选项默认值描述snapshot-id(latest)要读取的表快照的快照 IDas-of-timestamp(latest)以毫秒为单位的时间戳;使用的快照将是此时的当前快照。split-size根据表属性覆盖此表的 read.split.target-size 和 read.split.metadata-target-sizelookback根据表属性覆盖此表的 read.split.planning-lookbackfile-open-cost根据表属性覆盖此表的 read.split.open-file-costvectorization-enabled根据表属性覆盖此表的 read.parquet.vectorization.enabledbatch-size根据表属性覆盖此表的 read.parquet.vectorization.batch-sizestream-from-timestamp(none)流式传输的时间戳(以毫秒为单位);如果在最旧的已知祖先快照之前,则将使用最旧的
十四、运行时配置-写选项
配置 DataFrameWriter 时会传递 Spark 写入选项,如下所示:
df.write
.option("write-format", "avro")
.option("snapshot-property.key", "value")
.insertInto("catalog.db.table")
Spark选项默认值描述write-format表 write.format.default用于此写入操作的文件格式;parquet, avro, or orctarget-file-size-bytes根据表属性覆盖此表的 write.target-file-size-bytescheck-nullabilitytrue设置字段可空检查snapshot-property.custom-keynull在快照摘要中添加具有自定义键和相应值的条目(仅 DSv2 需要快照属性。前缀)fanout-enabledfalse覆盖此表的 write.spark.fanout.enabledcheck-orderingtrue检查输入模式和表模式是否相同isolation-levelnull数据帧覆盖操作所需的隔离级别。 null => 不检查(对于幂等写入),serializable => 检查目标分区中的并发插入或删除,snapshot => 检查目标分区中的并发删除。validate-from-snapshot-idnull如果设置了隔离级别,则为用于检查表中并发写入冲突的基本快照的 ID。应该是从表中进行任何读取之前的快照。可以通过 Table API 或 Snapshots 表获取。如果为空,则使用表中最旧的已知快照。compression-codecTable write.(fileformat).compression-codec覆盖此写入的此表的压缩编解码器compression-levelTable write.(fileformat).compression-level对于此写入,覆盖此表的 Parquet 和 Avro 表的压缩级别compression-strategyTable write.orc.compression-strategy针对此写入覆盖此表的 ORC 表压缩策略
CommitMetadata 提供了一个接口,用于在 SQL 执行期间将自定义元数据添加到快照摘要中,这对于审计或更改跟踪等目的非常有用。如果属性以 snapshot-property. 开头,则该前缀将从每个属性中删除。这是一个例子:
import org.apache.iceberg.spark.CommitMetadata;
Map<String, String> properties = Maps.newHashMap();
properties.put("property_key","property_value");
CommitMetadata.withCommitProperties(properties,()-> {
spark.sql("DELETE FROM "+ tableName +" where id = 1");return0;
},
RuntimeException.class);
十五、Spark Procedures
要在 Spark 中使用 Iceberg,请首先配置 Spark 目录。存储过程仅在 Spark 3 中使用 Iceberg SQL 扩展时可用。
可以通过 CALL 从任何配置的 Iceberg 目录中使用过程。所有过程都在命名空间系统中。
CALL 支持按名称(推荐)或按位置传递参数。不支持混合位置参数和命名参数。
命名参数
所有过程参数均已命名。按名称传递参数时,参数可以按任何顺序,并且可以省略任何可选参数
CALL catalog_name.system.procedure_name(arg_name_2 => arg_2, arg_name_1 => arg_1)
位置参数
按位置传递参数时,只有结尾参数可以省略(如果它们是可选的)。
CALL catalog_name.system.procedure_name(arg_1, arg_2,... arg_n)
快照管理
rollback_to_snapshot
将表回滚到特定快照 ID。
要回滚到特定时间,请使用 rollback_to_timestamp。
此过程会使所有引用受影响表的缓存 Spark 计划失效。
参数名称RequiredType描述table✔️string要更新的表的名称snapshot_id✔️long要回滚到的快照 IDOutput NameType描述previous_snapshot_idlong回滚前当前快照IDcurrent_snapshot_idlong新的当前快照 ID
将表 db.sample 回滚到快照 ID 1:
CALL catalog_name.system.rollback_to_snapshot('db.sample',1)
rollback_to_timestamp
将表回滚到某个时间的当前快照。
参数名称RequiredType描述table✔️string要更新的表的名称timestamp✔️timestamp要回滚到的时间戳Output NameType描述previous_snapshot_idlong回滚前当前快照IDcurrent_snapshot_idlong新的当前快照 ID
将 db.sample 回滚到特定的日期和时间。
CALL catalog_name.system.rollback_to_timestamp('db.sample',TIMESTAMP'2021-06-30 00:00:00.000')
set_current_snapshot
设置表的当前快照 ID。
与回滚不同,快照不需要是当前表状态的祖先。
CALL catalog_name.system.set_current_snapshot('db.sample',1)
cherrypick_snapshot
从现有快照创建新快照,而不更改或删除原始快照。
只能选择追加和动态覆盖快照。
CALL catalog_name.system.cherrypick_snapshot('my_table',1)CALL catalog_name.system.cherrypick_snapshot(snapshot_id =>1,table=>'my_table')
fast_forward
将一个分支的当前快照快进到另一个分支的最新快照。
CALL catalog_name.system.fast_forward('my_table','main','audit-branch')
十六、元数据管理
许多维护操作可以使用 Iceberg 存储过程来执行。
过期快照
Iceberg 中的每次写入/更新/删除/更新插入/压缩都会生成一个新快照,同时保留旧数据和元数据以进行快照隔离和时间旅行。 expire_snapshots 过程可用于删除不再需要的旧快照及其文件。
此过程将删除旧快照以及这些旧快照唯一需要的数据文件。这意味着expire_snapshots过程永远不会删除未过期快照仍然需要的文件。
参数名称RequiredType描述table✔️string要更新的表的名称older_thantimestamp删除快照之前的时间戳(默认:5 天前)retain_lastint无论old_than如何,要保留的祖先快照数量(默认为1)max_concurrent_deletesint用于删除文件操作的线程池的大小(默认情况下,不使用线程池)stream_resultsboolean当为true时,删除文件将通过RDD分区发送到Spark驱动程序(默认情况下,所有文件将发送到Spark驱动程序)。建议将此选项设置为 true,以防止 Spark 驱动程序因文件大小而导致 OOMsnapshot_idsarray of long即将过期的快照 ID 数组。
如果省略old_than和retain_last,则将使用表的过期属性。仍被分支或标签引用的快照将不会被删除。默认情况下,分支和标签永远不会过期,但可以使用表属性history.expire.max-ref-age-ms更改它们的保留策略。主分支永远不会过期。
输出名称类型描述deleted_data_files_countlong该操作删除的数据文件数量deleted_position_delete_files_countlong本次操作删除的位置删除文件数量deleted_equality_delete_files_countlong本次操作删除的等式删除文件数量deleted_manifest_files_countlong此操作删除的清单文件数deleted_manifest_lists_countlong此操作删除的清单列表文件数
删除早于特定日期和时间的快照,但保留最后 100 个快照:
CALL hive_prod.system.expire_snapshots('db.sample',TIMESTAMP'2021-06-30 00:00:00.000',100)
删除快照 ID 为 123 的快照(注意该快照 ID 不应该是当前快照):
CALL hive_prod.system.expire_snapshots(table=>'db.sample', snapshot_ids => ARRAY(123))
删除孤立文件
用于删除 Iceberg 表的任何元数据文件中未引用的文件,因此可以被视为“孤立”文件。
通过在此表上执行remove_orphan_files 命令的试运行而不实际删除它们,列出所有要删除的候选文件:
CALL catalog_name.system.remove_orphan_files(table=>'db.sample', dry_run =>true)
删除 tablelocation/data 文件夹中表 db.sample 未知的所有文件。
CALL catalog_name.system.remove_orphan_files(table=>'db.sample', location =>'tablelocation/data')
重写数据文件
Iceberg 跟踪表中的每个数据文件。更多的数据文件会导致更多的元数据存储在清单文件中,而小数据文件会导致不必要的元数据量和文件打开成本的低效查询。
Iceberg 可以使用 Spark 和 rewriteDataFiles 操作并行压缩数据文件。这会将小文件组合成较大的文件,以减少元数据开销和运行时文件打开成本。
参数名称RequiredType描述table✔️string要更新的表的名称strategystring策略的名称 - binpack 或 sort。默认为 binpack 策略sort_orderstring对于 Zorder,请在 zorder() 中使用逗号分隔的列列表。 (Spark 3.2 及以上版本支持)示例:zorder(c1,c2,c3)。否则,以逗号分隔排序顺序,格式为 (ColumnName SortDirection NullOrder)。其中 SortDirection 可以是 ASC 或 DESC。 NullOrder 可以是 NULLS FIRST 或 NULLS LAST。默认为表的排序顺序optionsmap<string, string>用于操作的选项wherestring谓词作为用于过滤文件的字符串。请注意,所有可能包含与过滤器匹配的数据的文件都将被选择进行重写
常规选项
名称默认值描述max-concurrent-file-group-rewrites5同时重写的最大文件组数partial-progress.enabledfalse启用在整个重写完成之前提交文件组partial-progress.max-commits10如果启用部分进度,则允许此重写产生的最大提交量use-starting-sequence-numbertrue使用压缩开始时快照的序列号,而不是新生成的快照的序列号rewrite-job-ordernone根据该值强制重写作业顺序。如果 rewrite-job-order=bytes-asc,则先重写最小的作业组。如果 rewrite-job-order=bytes-desc,则先重写最大的作业组。如果 rewrite-job-order=files-asc,则首先重写文件最少的作业组。如果 rewrite-job-order=files-desc,则首先重写文件最多的作业组。如果 rewrite-job-order=none,则按照它们的顺序重写作业组已计划(无特定顺序)。target-file-size-bytes536870912(512 MB,表属性中 write.target-file-size-bytes 的默认值)目标输出文件大小min-file-size-bytes目标文件大小的 75%无论任何其他标准如何,低于此阈值的文件都将被考虑重写max-file-size-bytes目标文件大小的 180%无论任何其他条件如何,大小高于此阈值的文件都将被考虑重写min-input-files5无论其他条件如何,超过此文件数量的任何文件组都将被重写rewrite-allfalse强制重写所有提供的文件,覆盖其他选项max-file-group-size-bytes107374182400 (100GB)单个文件组中应重写的最大数据量。整个重写操作根据分区被分解为多个部分,并根据文件组的大小在分区内分解。这有助于分解非常大的分区的重写,否则由于集群的资源限制,这些分区可能无法重写。delete-file-threshold2147483647需要与数据文件关联才能考虑重写的最小删除次数
排序策略选项
名称默认值描述compression-factor1.0Shuffle 分区的数量以及 Spark 排序创建的输出文件的数量取决于此文件重写器中使用的输入数据文件的大小。由于压缩,磁盘文件大小可能无法准确表示输出中文件的大小。此参数允许用户调整用于估计实际输出数据大小的文件大小。大于 1.0 的系数将生成比我们根据磁盘文件大小预期的更多的文件。小于 1.0 的值将创建比我们基于磁盘大小预期的文件少的文件。shuffle-partitions-per-file1用于每个输出文件的随机分区数。 Iceberg 将使用自定义合并操作将这些已排序的分区重新拼接成单个已排序的文件。
使用 zorder sort_order 的排序策略选项
名称默认值描述var-length-contribution8从可变长度类型的输入列考虑的字节数(字符串、二进制)max-output-size2147483647ZOrder 算法中交织的字节数
Output
名称默认值描述rewritten_data_files_countint通过该命令重写的数据数added_data_files_countint此命令写入的新数据文件的数量rewritten_bytes_countlong该命令写入的字节数failed_data_files_countintpartial-progress.enabled为true时重写失败的数据文件数量
例子
使用默认的bin-packing重写算法重写表db.sample中的数据文件,合并小文件,同时根据表的默认写入大小拆分大文件。
CALL catalog_name.system.rewrite_data_files('db.sample')
通过使用与 bin-pack 相同的默认值对 id 和 name 上的所有数据进行排序来重写表 db.sample 中的数据文件,以确定要重写的文件。
CALL catalog_name.system.rewrite_data_files(table=>'db.sample', strategy =>'sort', sort_order =>'id DESC NULLS LAST,name ASC NULLS FIRST')
通过 zOrdering 在 c1 和 c2 列上重写表 db.sample 中的数据文件。使用与 bin-pack 相同的默认值来确定要重写哪些文件。
CALL catalog_name.system.rewrite_data_files(table=>'db.sample', strategy =>'sort', sort_order =>'zorder(c1,c2)')
在任何需要重写的文件超过 2 个或更多的分区中,使用 bin-pack 策略重写表 db.sample 中的数据文件。
CALL catalog_name.system.rewrite_data_files(table=>'db.sample', options => map('min-input-files','2'))
重写表db.sample中的数据文件,并选择可能包含与过滤器(id = 3且name =“foo”)匹配的数据的文件进行重写。
CALL catalog_name.system.rewrite_data_files(table=>'db.sample',where=>'id = 3 and name = "foo"')
重写清单
重写表的清单以优化扫描计划。
清单中的数据文件按分区规范中的字段排序。此过程使用 Spark 作业并行运行。
参数说明RequiredType说明table✔️string要更新的表的名称use_cachingboolean运行期间使用Spark缓存(默认为true)
输出
参数说明Type说明rewritten_manifests_countint由该命令重写的清单数量added_mainfests_countint此命令写入的新清单文件的数量
重写表 db.sample 中的清单,并将清单文件与表分区对齐。
CALL catalog_name.system.rewrite_manifests('db.sample')
重写表 db.sample 中的清单并禁用 Spark 缓存。这样做可以避免执行器上的内存问题。
CALL catalog_name.system.rewrite_manifests('db.sample',false)
重写位置删除文件
Iceberg可以重写位置删除文件,这有两个目的:
- 小压缩:将小位置的删除文件压缩为较大的文件。这减少了清单文件中存储的元数据的大小以及打开小删除文件的开销。
- 删除悬空删除:过滤掉引用不再有效的数据文件的位置删除记录。在 rewrite_data_files 之后,指向重写数据文件的位置删除记录并不总是被标记为删除,并且可以通过表的实时快照元数据保持跟踪。这称为“悬空删除”问题。
参数说明RequiredType说明table✔️string要更新的表的名称optionsmap<string, string>程序使用的选项
重写期间,悬空删除始终会被过滤掉。
名称默认值描述max-concurrent-file-group-rewrites5同时重写的最大文件组数partial-progress.enabledfalse启用在整个重写完成之前提交文件组partial-progress.max-commits10如果启用部分进度,则允许此重写产生的最大提交量rewrite-job-ordernone根据该值强制重写作业顺序。如果 rewrite-job-order=bytes-asc,则先重写最小的作业组。如果 rewrite-job-order=bytes-desc,则先重写最大的作业组。如果 rewrite-job-order=files-asc,则首先重写文件最少的作业组。如果 rewrite-job-order=files-desc,则首先重写文件最多的作业组。如果 rewrite-job-order=none,则按照它们的顺序重写作业组已计划(无特定顺序)。target-file-size-bytes67108864(64MB,表属性中 write.delete.target-file-size-bytes 的默认值)目标输出文件大小min-file-size-bytes目标文件大小的 75%无论任何其他标准如何,低于此阈值的文件都将被考虑重写max-file-size-bytes目标文件大小的 180%无论任何其他条件如何,大小高于此阈值的文件都将被考虑重写min-input-files5无论其他条件如何,超过此文件数量的任何文件组都将被重写rewrite-allfalse强制重写所有提供的文件,覆盖其他选项max-file-group-size-bytes107374182400 (100GB)单个文件组中应重写的最大数据量。整个重写操作根据分区被分解为多个部分,并根据文件组的大小在分区内分解。这有助于分解非常大的分区的重写,否则由于集群的资源限制,这些分区可能无法重写。
Output
输出名称Type描述rewritten_delete_files_countint通过此命令删除的删除文件数added_delete_files_countint通过此命令添加的删除文件数rewritten_bytes_countlong通过此命令删除的删除文件的字节数added_bytes_countlong通过此命令添加的所有新删除文件的字节数
重写位置删除表db.sample中的文件。这会选择符合默认重写标准的位置删除文件,并写入目标大小 target-file-size-bytes 的新文件。悬空删除将从重写的删除文件中删除。
CALL catalog_name.system.rewrite_position_delete_files('db.sample')
重写表 db.sample 中的所有位置删除文件,写入新文件 target-file-size-bytes。悬空删除将从重写的删除文件中删除。
CALL catalog_name.system.rewrite_position_delete_files(table=>'db.sample', options => map('rewrite-all','true'))
重写位置删除表db.sample中的文件。这会选择分区中的位置删除文件,其中需要根据大小标准重写 2 个或更多位置删除文件。悬空删除将从重写的删除文件中删除。
CALL catalog_name.system.rewrite_position_delete_files(table=>'db.sample', options => map('min-input-files','2'))
migrate
将表替换为加载了源数据文件的 Iceberg 表。
表架构、分区、属性和位置将从源表复制。
如果任何表分区使用不支持的格式,迁移将会失败。支持的格式有 Avro、Parquet 和 ORC。现有数据文件被添加到 Iceberg 表的元数据中,并且可以使用从原始表架构创建的名称到 ID 映射来读取。
要在测试时保持原始表完整,请使用快照创建共享源数据文件和架构的新临时表。
默认情况下,原始表保留为名称 table_BACKUP_。
参数说明RequiredType说明table✔️string要迁移的表的名称propertiesmap<string, string>新 Iceberg 表的属性drop_backupboolean当 true 时,原始表将不会保留作为备份(默认为 false)backup_table_namestring将保留作为备份的表的名称(默认为 table_BACKUP_)
输出:
输出名称Type描述migrated_files_countlong附加到 Iceberg 表的文件数
例子
将 Spark 默认目录中的表 db.sample 迁移到 Iceberg 表,并添加属性“foo”设置为“bar”:
CALL catalog_name.system.migrate('spark_catalog.db.sample', map('foo','bar'))
将当前目录中的 db.sample 迁移到 Iceberg 表,而不添加任何其他属性:
CALL catalog_name.system.migrate('db.sample')
add_files
尝试直接将文件从 Hive 或基于文件的表添加到给定的 Iceberg 表中。与 migrate 或 snapshot 不同,add_files 可以从一个或多个特定分区导入文件,并且不会创建新的 Iceberg 表。此命令将为新文件创建元数据,但不会移动它们。此过程不会分析文件的架构来确定它们是否确实与 Iceberg 表的架构匹配。完成后,Iceberg 表将把这些文件视为 Iceberg 拥有的文件集的一部分。这意味着任何后续的 expire_snapshot 调用都将能够物理删除添加的文件。如果可以进行迁移或快照,则不应使用此方法。
请记住,add_files 过程将从仅添加一次的每个文件中获取 Parquet 元数据。如果您使用分层存储(例如 Amazon S3 智能分层存储类),将从存档中检索底层文件,并将在设定的时间段内保留在较高层上。
register_table
为已存在但没有相应目录标识符的metadata.json 文件创建目录条目。
将新表注册为 db.tbl 到spark_catalog,指向metadata.json文件路径/to/metadata/file.json。
CALL spark_catalog.system.register_table(table=>'db.tbl',
metadata_file =>'path/to/metadata/file.json')
元数据信息
ancestors_of
报告指定快照的父级实时快照ID
获取当前快照的所有快照祖先(默认)
CALL spark_catalog.system.ancestors_of('db.tbl')
获取特定快照的所有快照祖先
CALL spark_catalog.system.ancestors_of('db.tbl',1)CALL spark_catalog.system.ancestors_of(snapshot_id =>1,table=>'db.tbl')
Change Data Capture
创建变更日志视图
创建一个包含给定表中的更改的视图。
参数名称RequiredType说明table✔️string变更日志的源表的名称changelog_viewstring要创建的视图的名称optionsmap<string, string>要使用的 Spark 读取选项图net_changesboolean是否输出净变化(更多信息见下文)。默认为 false。compute_updatesboolean是否计算更新前/更新后图像(有关详细信息,请参阅下文)。默认为 false。identifier_columnsarray用于计算更新的标识符列的列表。如果参数compute_updates设置为true并且未提供identifier_columns,则将使用表的当前标识符字段。remove_carryoversboolean是否删除结转行(有关详细信息,请参阅下文)。默认为 true。自 1.4.0 起已弃用,将在 1.5.0 中删除;请查询 SparkChangelogTable 以查看结转行
以下是常用的 Spark 读取选项列表:
- start-snapshot-id:独占的启动快照ID。如果未提供,它将从表的第一个快照中读取。
- end-snapshot-id:包含的结束快照id,默认为表的当前快照。
- start-timestamp:唯一的开始时间戳。如果未提供,它将从表的第一个快照中读取。
- end-timestamp:包含的结束时间戳,默认为表的当前快照。
输出:
输出名称Type描述changelog_viewstring创建的变更日志视图的名称
根据快照 1(不包括)和快照 2(包括)之间发生的更改创建变更日志视图 tbl_changes。
CALL spark_catalog.system.create_changelog_view(table=>'db.tbl',
options => map('start-snapshot-id','1','end-snapshot-id','2'))
根据时间戳 1678335750489(不包括)和 1678992105265(包括)之间发生的更改创建变更日志视图 my_changelog_view。
CALL spark_catalog.system.create_changelog_view(table=>'db.tbl',
options => map('start-timestamp','1678335750489','end-timestamp','1678992105265'),
changelog_view =>'my_changelog_view')
创建一个更改日志视图,根据标识符列 id 和 name 计算更新。
CALL spark_catalog.system.create_changelog_view(table=>'db.tbl',
options => map('start-snapshot-id','1','end-snapshot-id','2'),
identifier_columns => array('id','name'))
创建变更日志视图后,您可以查询该视图以查看快照之间发生的更改。
SELECT*FROM tbl_changes
SELECT*FROM tbl_changes where _change_type ='INSERT'AND id =3ORDERBY _change_ordinal
请注意,更改日志视图包括更改数据捕获 (CDC) 元数据列,这些列提供有关正在跟踪的更改的附加信息。这些列是:
- _change_type:更改的类型。它具有以下值之一:INSERT、DELETE、UPDATE_BEFORE 或 UPDATE_AFTER。
- _change_ordinal:更改的顺序
- _commit_snapshot_id:发生更改的快照 ID
这是相应结果的示例。显示第一个快照插入了2条记录,第二个快照删除了1条记录。
创建计算净更改的变更日志视图。它删除中间更改并仅输出净更改。
CALL spark_catalog.system.create_changelog_view(table=>'db.tbl',
options => map('end-snapshot-id','87647489814522183702'),
net_changes =>true)
对于净更改,上述更改日志视图仅包含以下行,因为 Alice 被插入到第一个快照中并在第二个快照中被删除。
Carry-over Rows
该过程默认删除结转行。结转行是使用写时复制时行级操作(MERGE、UPDATE 和 DELETE)的结果。例如,给定一个包含 row1 (id=1, name=‘Alice’) 和 row2 (id=2, name=‘Bob’) 的文件。对 row2 进行写时复制删除需要擦除该文件并将 row1 保留在新文件中。更改日志表将其报告为以下两行,尽管这不是对该表的实际更改。
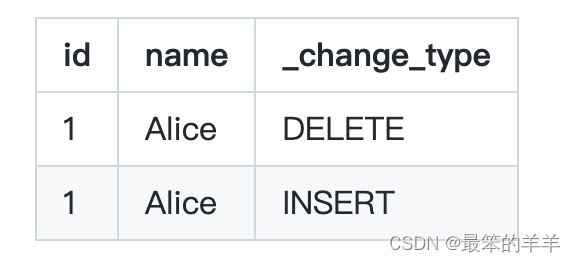
要查看结转行,请按如下方式查询 SparkChangelogTable:
SELECT*FROM spark_catalog.db.tbl.changes
更新前/后图像
该过程计算更新前/更新后图像(如果已配置)。更新前/更新后图像是从一对删除行和插入行转换而来的。标识符列用于确定插入和删除记录是否引用同一行。如果两条记录共享相同的标识列值,则它们被视为同一行的之前和之后状态。您可以在表模式中设置标识符字段,也可以将它们作为过程参数输入。
以下示例显示了使用标识符列 (id) 进行更新前/更新后图像计算,其中具有相同 id 的行删除和插入被视为单个更新操作。具体来说,假设我们有以下两行:

在这种情况下,该过程将更新之前的行标记为 UPDATE_BEFORE 图像,将更新之后的行标记为 UPDATE_AFTER 图像,从而产生以下更新前/更新后图像:

版权归原作者 最笨的羊羊 所有, 如有侵权,请联系我们删除。