
一、概述:
Zookeeper的选举机制是它的一项核心功能,用于在分布式系统中选择一个领导者(leader)来处理各种请求和操作。以下是Zookeeper选举机制的一些关键方面:
- 服务器ID(Server ID):每个Zookeeper服务器在启动时都会被分配一个唯一的服务器ID(SID)。这个ID用于标识服务器在集群中的位置和角色。
- 选举状态(Election State):在选举过程中,Zookeeper服务器有四种状态:LOOKING(寻找状态)、FOLLOWING(跟随状态)、OBSERVING(观察状态)和LEADING(领导状态)。
- 选举算法:Zookeeper使用FastLeaderElection(FLE)算法来进行选举。该算法基于过半数原则,即只有获得超过半数以上服务器投票的服务器才能成为领导者。
- 投票(Vote):在选举过程中,每个Zookeeper服务器都会投出一票。投票内容包含了该服务器的SID、ZXID(包含Epoch和计数)以及其他必要的信息。
- 心跳(Heartbeat):Zookeeper服务器之间通过心跳消息来保持彼此的连接和状态信息。当一个服务器收到心跳消息时,它会确认对方的存活状态,并在需要时重新进行选举。
- 确认(Confirmation):当一个Zookeeper服务器收到来自领导者的请求时,它会向领导者发送确认消息,表示自己已经接收到了该请求。
- 重新选举(Re-Election):如果当前的领导者出现故障或者无法继续服务,Zookeeper会重新进行选举。在重新选举过程中,所有服务器都会根据最新的ZXID和Epoch值来参与投票,并选出一个新的领导者。
通过这种选举机制,Zookeeper能够在分布式系统中保证数据的可靠性、一致性和高可用性。无论是在新节点加入集群、节点故障还是在负载均衡等情况下,Zookeeper都能够迅速地选择出一个新的领导者来处理各种请求和操作。
二、选举流程
如图: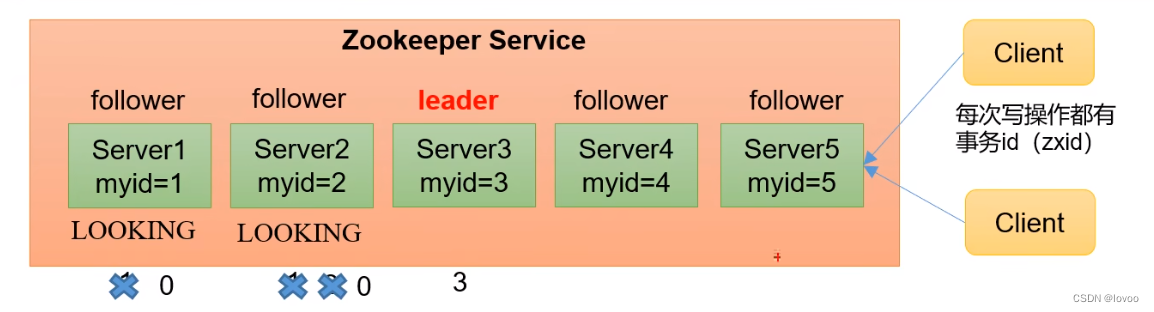
- 服务器1启动,发起一次选举。服务器1投自己一票。此时服务器票数一票,不够半数以上 (3票),选举无法完成,服务器1状态保持为LOOKING:
- 服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的mid比自己目 前投票推举的(服务器1大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
- 服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器10票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING。服务器3更改状态为LEADING
- 服务器4启动,发起一次选举。此时服务器1,23已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING:
- 服务器5启动,同4一样当小弟。
三、集群中SID、ZXID、Epoch的作用
ZXID(Zookeeper Transaction ID)是Zookeeper中用于标识和排序事务的唯一ID。它是一个64位的数字,其中高32位是Epoch(时代),低32位用于递增计数。
SID(Server ID)是Zookeeper中每个服务器的唯一标识符。它是一个整数,用于标识服务器在Zookeeper集群中的位置和角色。
Epoch(时代)是一个用于标识Zookeeper集群中领导者(leader)和追随者(follower)之间关系的值。每当一个新的领导者被选出来,就会有一个新的Epoch值被分配,用于标识当前领导者。Epoch值通过ZXID的高32位来表示。
通过使用Epoch和递增计数值,ZXID确保了事务在Zookeeper集群中的顺序一致性。这种机制对于保证数据的一致性和可靠性非常重要,因为它确保了所有事务都能按照正确的顺序被处理和提交。
本文转载自: https://blog.csdn.net/lovoo/article/details/131495661
版权归原作者 lovoo 所有, 如有侵权,请联系我们删除。
版权归原作者 lovoo 所有, 如有侵权,请联系我们删除。