
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
在本文中,我们将研究时间序列数据并探索一种生成合成时间序列数据的方法。
时间序列数据 — 简要概述
时间序列数据与常规表格数据有什么不同呢?时间序列数据集有一个额外的维度——时间。我们可以将其视为 3D 数据集。比如说,我们有一个包含 5 个特征和 5 个输入实例的数据集。
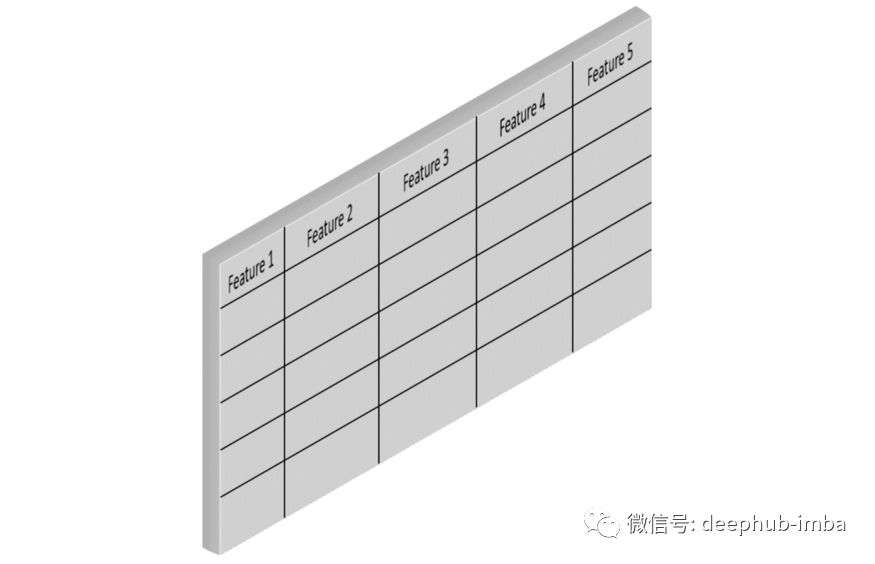
那么时间序列数据基本上是该表在第 3 维的扩展,其中每个新表只是新时间步长的另一个数据集。

主要的区别是时间序列数据与表格数据相比有更多的数据点实例。
能源数据集的案例研究
如果我们看一下能源数据集,它实际上看起来只是一个常规的表格数据集,每一行都意味着一个新的时间步长,并以特性的形式具有相应的数据点。根据数据列,每个条目在持续10分钟后被记录。

但是我们在前一节中看到它看起来像一个3D表格数据集。在这里,我们可以使用一种采样数据点的方法来创建第三维。
我们取一个大小为24的窗口,并沿着数据集的行运行它,每次移动一个位置,从而获得一定数量的2D矩阵,每个矩阵的长度为24,并具有所有列特征。

在这个数据集中,有19736行。通过每24行移位采样,我们得到19712个条目,每个条目有24行和28个特征。当然,我们可以随机混合它们,使它们成为独立和同分布(IID)。因此,我们得到了一个维度(19712,(24,28))的数据集,其中每个19712实例有24行(即时间步)和28个特性。
使用TimeGAN生成时间序列数据
TimeGAN(时间序列生成对抗网络)是一种合成时间序列数据的实现。论文的作者也提供了相应的Python实现,在本文中,我们将使用0.3.0版本,这是撰写本文时的最新版本。
pip install ydata-synthetic==0.3.0
有关这方面的更多细节请参阅ydata-synthetic的github源代码。在本节中,我们将查看如何使用能量数据集作为输入源来生成时间序列数据集。
我们首先读取数据集,然后以数据转换的形式进行预处理。这个预处理实质上是在[0,1]范围内缩放数据。
from ydata_synthetic.preprocessing.timeseries.utils import real_data_loading
file_path = "./data/energy_data.csv"
energy_df = pd.read_csv(file_path)
try:
energy_df = energy_df.set_index('Date').sort_index()
except:
energy_df=energy_df
# Data transformations to be applied prior to be used with the synthesizer model
energy_data = real_data_loading(energy_df.values, seq_len=seq_len)
print(len(energy_data), energy_data[0].shape)
现在,从这个时间序列数据(energy_data)生成实际的合成数据是最简单的部分。我们在energy_data上训练TimeGAN模型,然后使用这个训练过的模型生成更多的数据。
from ydata_synthetic.synthesizers.timeseries import TimeGAN
synth = TimeGAN(model_parameters=gan_args, hidden_dim=hidden_dim, seq_len=seq_len, n_seq=n_seq, gamma=1)
synth.train(energy_data, train_steps=500)
synth.save('synth_energy.pkl')
synth_data = synth.sample(len(energy_data))
这里我们根据需求适当地定义要提供给TimeGAN构造器的参数。我们将n_seq定义为28(特性),seq_len定义为24(时间步骤)。其余参数定义如下:
seq_len = 24 # Timesteps
n_seq = 28 # Features
hidden_dim = 24 # Hidden units for generator (GRU & LSTM).
# Also decides output_units for generator
gamma = 1 # Used for discriminator loss
noise_dim = 32 # Used by generator as a starter dimension
dim = 128 # UNUSED
batch_size = 128
learning_rate = 5e-4
beta_1 = 0 # UNUSED
beta_2 = 1 # UNUSED
data_dim = 28 # UNUSED
# batch_size, lr, beta_1, beta_2, noise_dim, data_dim, layers_dim
gan_args = [batch_size, learning_rate, beta_1, beta_2, noise_dim, data_dim, dim]
现在我们已经生成了synth_data,让我们看看它与原始数据对比可视化。我们可以为28个特征中的每一个做一个图,看看它们随时间步长的变化。

由于这些图只是粗略的展示,可能对比较没有什么特别帮助。但是我们看到,合成数据肯定与原始(真实)数据不同。考虑到数据集有如此多的特性,也很难直观地将它们可视化和解释在一起。现在我们更深入的比较数据集,这样可以让我们进行更深入的理解二者之间的关系。
评估和可视化
我们可以利用以下两种大家都知道的可视化技术:
- PCA——主成分分析
- t-SNE — t-分布式随机邻居嵌入
这些技术背后的基本思想是应用降维来可视化那些具有大量维度(即大量特征)的数据集。PCA 和 t-SNE 都能够实现这些,它们之间的主要区别在于 PCA 试图保留数据的全局结构(因为它着眼于在整个数据集中保留全局数据集方差的方式 ),而 t-SNE 试图保留局部结构(通过确保原始数据中靠近的点的邻居在降维空间中也靠近在一起)。
对于我们的用例,我们将使用来自 sklearn 的 PCA 和 TSNE 对象。
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
sample_size = 250
idx = np.random.permutation(len(energy_data))[:sample_size]
# Convert list to array, but taking only 250 random samples
# energy_data: (list(19711(ndarray(24, 28)))) -> real_sample: ndarray(250, 24, 28)
real_sample = np.asarray(energy_data)[idx]
synthetic_sample = np.asarray(synth_data)[idx]
# For the purpose of comparison we need the data to be 2-Dimensional.
# For that reason we are going to use only two components for both the PCA and TSNE.
# synth_data_reduced: {ndarray: (7000, 24)}
# energy_data_reduced: {ndarray: (7000, 24)}
synth_data_reduced = real_sample.reshape(-1, seq_len)
energy_data_reduced = np.asarray(synthetic_sample).reshape(-1,seq_len)
n_components = 2
pca = PCA(n_components=n_components)
tsne = TSNE(n_components=n_components, n_iter=300)
# The fit of the methods must be done only using the real sequential data
pca.fit(energy_data_reduced)
# pca_real: {DataFrame: (7000, 2)}
# pca_synth: {DataFrame: (7000, 2)}
pca_real = pd.DataFrame(pca.transform(energy_data_reduced))
pca_synth = pd.DataFrame(pca.transform(synth_data_reduced))
# data_reduced: {ndarray: (14000, 24)}
data_reduced = np.concatenate((energy_data_reduced, synth_data_reduced), axis=0)
# tsne_results: {DataFrame: (14000, 2)}
tsne_results = pd.DataFrame(tsne.fit_transform(data_reduced))
现在要绘制的数据已经准备好了,我们可以使用matplotlib绘制原始转换和合成转换。pca_real和pca_synth一起给出了PCA结果,而tsne_results包含了原始和合成t-SNE转换。

这些图告诉我们什么?它们向我们展示了如果将整个数据集转换为具有较少特征的数据集(两个轴对应于两个特征),那么整个数据集可能是这样的。PCA图可能不足以得出一个正确的结论,但t-SNE图似乎告诉我们,原始数据(黑色)和合成数据(红色)似乎遵循类似的分布。此外,一个对特定数据集的观察是,在整个数据集中有7组(集群),它们的数据点(明显)彼此相似(因此聚在一起)。
总结
我们简要地看了一下时间序列数据以及它与表格数据的区别。为了生成更多的时间序列数据,我们通过ydata-synthetic库使用了TimeGAN架构。
可以在这里找到本文的完整代码:https://github.com/archity/synthetic-data-gan/blob/main/timeseries-data/energy-data-synthesize.ipynb
作者:Archit Yadav
喜欢就关注一下吧:
点个 在看 你最好看!********** **********