
文章目录
1.了解磁盘的物理结构
磁盘计算机上唯一的一个机械设备,同时它还是外设
机械磁盘很便宜,虽然效率会慢一些,所以企业一般使用机械磁盘,因为便宜
磁盘不仅仅外设,还是一个机械设备(盘片、磁头),所以磁盘一定非常慢

盘片:一片两面,有一摞盘片

磁头:一面一个磁头
一个磁头负责一面的读取

马达比如说剃须刀,或者手机的震动等
所以盘片就可以 以顺时针的方式高速旋转
同时在磁头位置也存在一个马达,控制磁头左右来回摆动
磁头是共进退的,要不一块过去,要不就一块不去
磁盘盘片上有无数个基本单元,每一个基本单元按照特定的空间排布好的,每一个单元就是磁铁
南极表示1,北极表示0,
向磁盘写入:把北极改成南极 (N->S)对内容做磁化
删除磁盘数据:把数据从南极设置为北极 (S->N)
这样就可以完成微观上 一个比特位的读和写
磁头本质上 是对数据做写入和读取,更改基本元素的南北极,读取南北极
磁盘的具体物理存储结构

整体结构

抽象的一面结构

磁盘中存储的基本单元是扇区,一般扇区的大小为512字节或者4KB字节
一般磁盘所有的扇区都是512字节大小
同半径的所有的扇区即为磁道
在一面上,如何在硬件上定位一个扇区?
1.先定位在哪一个磁道—由半径决定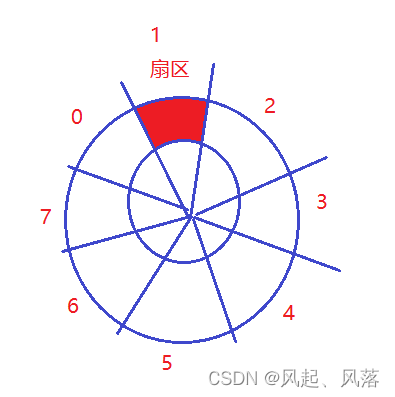
2.再确定在该磁道,在哪一个扇区,根据扇区的编号,来定位一个扇区
所以首先要定位哪一个面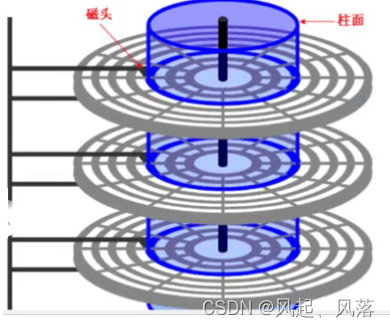
磁头是共进退的,半径相同的每一个面上的磁道共同在抽象上就会形成一个柱面
只需要确定用哪一个磁头读取,磁头的编号就表示哪一个面
所以定位任意一个扇区,需要确定 磁头head 、柱面 cylinder、扇区 sector 即CHS定位法
普通文件中包含属性和数据,都可以看做数据(0,1),占用一个或者多个扇区,来进行自己的数据存储
既然能用CHS定位为任意一个扇区,就能定位任意多个扇区,从而将文件从硬件角度进行读取或者写入
2.逻辑抽象
OS内部是不是直接使用CHS地址?不是
第一点:因为OS是软件,磁盘是硬件,硬件定位一个地址,用的是CHS,但是如果OS直接用了这个地址,万一硬件改变,OS也要发生变化,所以OS要和硬件做好解耦工作
第二点:即便是扇区512字节,单位IO的基本数据量也是很小的,所以硬件是按照512字节处理,
操作系统实际进行IO,基本单位是4KB
操作系统和磁盘进行交互时,基本以4KB为单位,
基本大小:进行磁盘读取和磁盘写入时,必须以基本单位为基本大小,来与外设进行交互
哪怕只修改一个比特位,也要把一个比特位所在的4KB全部读到内存,
把一个比特位改完,再把4KB内容全部写到目标文件中,要以块的方式整体与外设进行交互
所以一般把磁盘称为 块设备
所以OS需要有一套新的地址,来进行块级别的访问

把盘面抽象成一种线性结构
以一个盘面举例
相同磁道的东西一定放在一起的
整体可以看作是数组,设置数组名为 sector_disk1
初步完成了从物理逻辑到线性逻辑抽象的过程
因为看作是一个数组,而数组都是有下标的
假设数组下标为n,定位一个扇区,只需要数组下标就可以定位一个扇区了
OS是以4KB为单位进行IO的,一个操作系统对应的文件块要包括8个扇区
计算机常规访问方式:采用起始地址+偏移量的方式
只需要知道数据块起始位置的地址,即第一个扇区的下标地址 + 4KB(块的类型)
可以把数据块看作一种类型
所以块的地址本质就是数组的一个下标N
N的地址在OS中被叫做LBA,即逻辑块地址
磁盘只认CHS,LBA如何跟磁盘地址互相转化?
假设LBA地址为6500 ,单片大小为5000
首先确定在那一面,也就相当于在哪一个磁头上
H(磁头): int n=6500/5000=1 说明H的地址在第2面上
C(柱面):6500/1000=6 1000为磁道的大小,对应的H就在6号磁道上
S(扇区): 6500 %1000=500
所求扇区 就在 2号面中的6号磁道的第500个扇区
连续读取8个扇区,就能得到块
3.文件系统
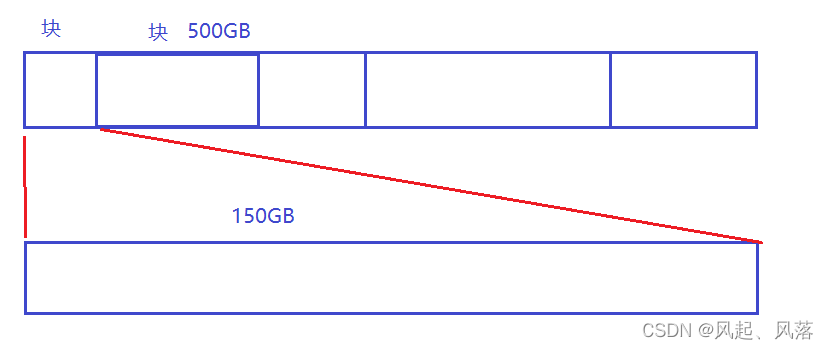
为了方便管理,就把数组拆分为一个个的区域
若感觉管理500GB太难了,就减少管理,从而管理150GB,将管理小的经验复制,从而使每一个小的都管理好
从而使500GB整体管理好 ,这种思想就叫做分区

虽然分完区小了很多,但依旧很大,所以操作系统对整个分区还会在做分组
假设每个区为150GB,就把15GB为一组,把其中一个组管理好了,按照一个组的管理方式就把所有组管理好了
由于每个区都可以分组,就有了 Block group

一个分区当中最开始有一个Boot Block
会保存与操作系统启动相关的内容,如分区表和操作系统镜像地址
一个组的结构
一个组中分为 Super Block(超级块) 、Group Descriptor Table(组描述符)、Block Bitmap、inode Bitmap(位图)、inode Table (inode表)、Data blocks(数据块)
Super Block 保存的是文件系统的所有属性信息 如文件系统的类型、整个分组的情况
Super Block在各个分组里面可能都会存在,而且是统一更新的
为了防止Super Block区域坏掉,如果出现故障,整个分区不可以被使用,所以要做好备份
Group Descriptor Table
GDT:组描述符 – 改组内的详细统计等属性信息,用来描述整个
一般而言,一个文件内部所有属性的集合,被称为inode节点 ,大小一般为128字节
一个文件,一个inode,一个分区内部也会存在大量的文件即会存在大量的inode节点,一个group,需要有一个区域专门保存该group的所有文件的inode节点 即 inode table -----inode表
文件的内容是变化的,用数据块对文件内容保存的,所以一个有效文件要保存内容就需要1/n数据块
若有多个文件就需要更多的数据块,数据块称为 Data blocks
linux查找一个文件,是要根据inode编号,来进行文件查找到,包括读取内容
一个inode对应一个文件,而该文件inode属性和该文件的数据块是由映射关系的
inode Bitmap
共有4096*8个比特位,按照从低向高扫描位图时,比特位的位置对应inode表中的inode
为1表示inode正常工作,为0表示inode不正常工作
每一个比特位表示 一个inode是否空闲可用
Block Bitmap
每一个bit位表示data block是否空闲可用
细节问题
1.inode与文件名
Linux系统只认inode编号,文件的inode属性中,并不存在文件名
文件名是给用户用的
2.目录是文件么?
是的,目录有inode和内容
3.任何一个文件,一定在目录内部,所以目录的内容是什么?
目录要有内容就需要数据块,目录的数据块里面保存的是该目录下 文件名和inode编号对应的映射关系
在目录内,文件名和inode编号互为key值
4.当我们访问一个文件的时候,是在特定目录下访问的 cat log.txt
1.先要在当前目录下,找到log.txt 的 inode编号
2.一个目录也是一个文件,也一定属于 一个分区,在该分区中找到分组,在该分组中对应的inode table中,找到文件的inode
3. 通过inode与 对应的data block的映射关系,找到该文件的数据块 ,并加载到OS,并完成到显示器
版权归原作者 风起、风落 所有, 如有侵权,请联系我们删除。