
文章目录
Kafka简介
- Kafka是一个分布式的流媒体平台。早期只是消息队列,慢慢扩充,可以进行很多其他操作,功能很综合,因此称为一个分布式的流媒体平台
- 应用:消息系统(核心) 日志收集 用户行为追踪 流式处理。
- kafka是目前来说性能最好的消息队列服务器,能处理TB级别的数据.作用:点赞、评论时,服务器会自动给某个用户发送通知
Kafka特点
- 高吞吐量: 处理数据能力强,能处理TB级别数据)、消息持久化。
- 消息持久化: 将数据永久保存到某一种介质上,如硬盘.Kafka就将数据存在了硬盘里,因此可以处理海量数据读写硬盘效率高与低取决于对硬盘的使用, 对硬盘的顺序读写性能甚至高于对内存的随机读写
- 高可靠性: kafka是一个分布式的服务器,可以做集群部署,一台服务器坏了还有另一台,靠分布式保证高可靠性,有容错能力
- 高扩展性: 服务器不够用了,可以再加一台
Kafka术语
- Broker: kafka集群中的任意一台服务器都被称为broker
- Zookeeper: 是一个独立的软件/应用,能够管理其他集群.kafka也要用很多其他集群,就用zookeeper管理.可以单独按一个zookeeper,也可以使用kafka内置的zookeeper
消息队列实现方式大致有两种:
- 点对点: 每个数据只被一个消费者消费,如blockingqueue
- 发布订阅模式: 生产者将消息/数据放到某个位置,可以同时有很多消费者关注这个位置,读取消息.此时,消息可以被多个消费者先后读到
kafka采取发布订阅模式实现消息队列
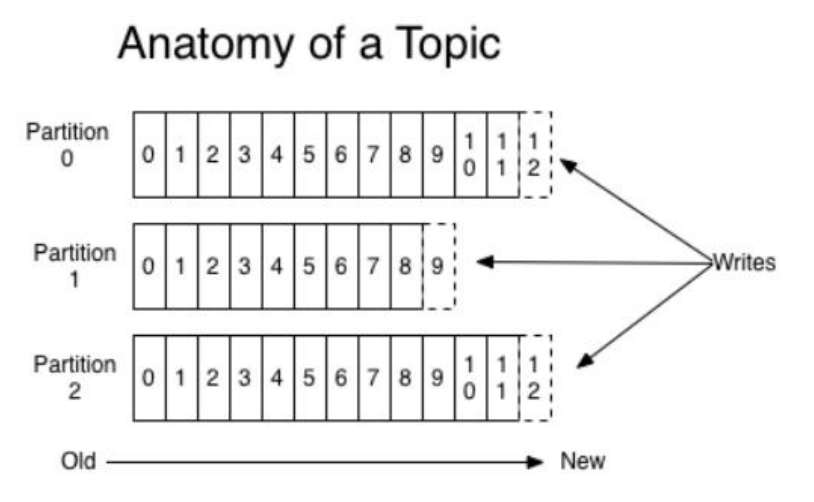
- Topic: 生产者将消息发布到的空间/位置就叫主题, 即topic可看作一个文件夹,用于存放消息
- Partition: 对topic的分区,便于同时写入多个消息一个主题(topic)可以分为多个分区(partition)每一个分区按照从前往后的顺序往里追加写入数据
- Offset: 消息在分区内存放的索引/序列读消息时要按照索引去读, 如索引9-10合起来是一个消息,读消息时要按照先9后10的顺序去读
宏观:
微观
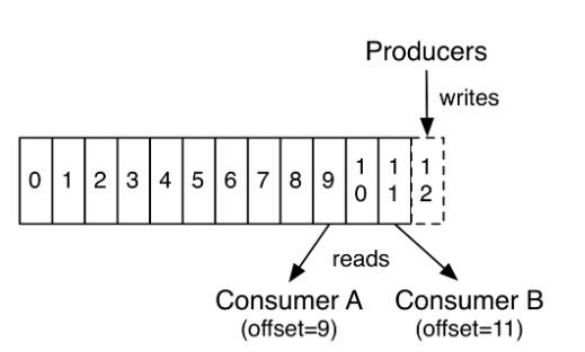
- Replica: 副本,对数据的备份每一个分区都有多个副本,可以提高容错率
- Leader Replica: 主副本,消费者尝试从分区获取数据时,主副本可以处理请求,做出响应,提供数据
- Follower Replica: 从副本,只是从主副本备份数据,不做响应万一主副本坏了,集群会从众多从副本中选一个,成为新的主副本
安装Kafka
kafka不分操作系统,是一个包,包里既有支持linux的命令,又有支持windows的命令
修改配置
zookeeper.properties文件
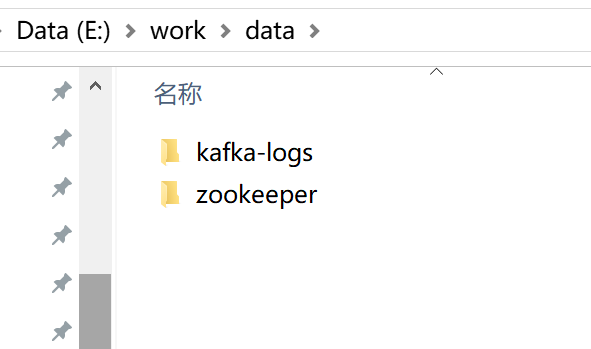
修改数据存放路径: dataDir=/tmp/zookeeper 是linux系统下的存放路径, 要修改成windows系统下的路径 dataDir=E:/work/data/zookeeper
server.properties文件
kafka日志文件存放位置: log.dirs=/tmp/kafka-logs 修改为 log.dirs=E:/work/data/kafka-logs
使用Kafka
官网使用手册1.3 quick start 有常见操作命令
启动zookeeper
打开第一个cmd窗口,进入Kafka所在文件
cd D:\LenovoSoftstore\Install\kafka_2.12-2.2.0
用配置文件启动zookeeper,去执行bin中windows系统的命令
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
https://blog.csdn.net/qq_36480179/article/details/102956271
启动Kafka
打开第二个cmd窗口(之前的不关),进入Kafka所在文件后,执行命令:
bin\windows\kafka-server-start.bat config\server.properties
刚刚配置的数据存放路径下出现如下两个文件,即为启动zookeeper和Kafka成功
启动Kafka命令行工具
打开第三个cmd窗口(之前的不关),进入Kafka中包含命令行工具的目录下
cd D:\LenovoSoftstore\Install\kafka_2.12-2.2.0\bin\windows
开始使用命令
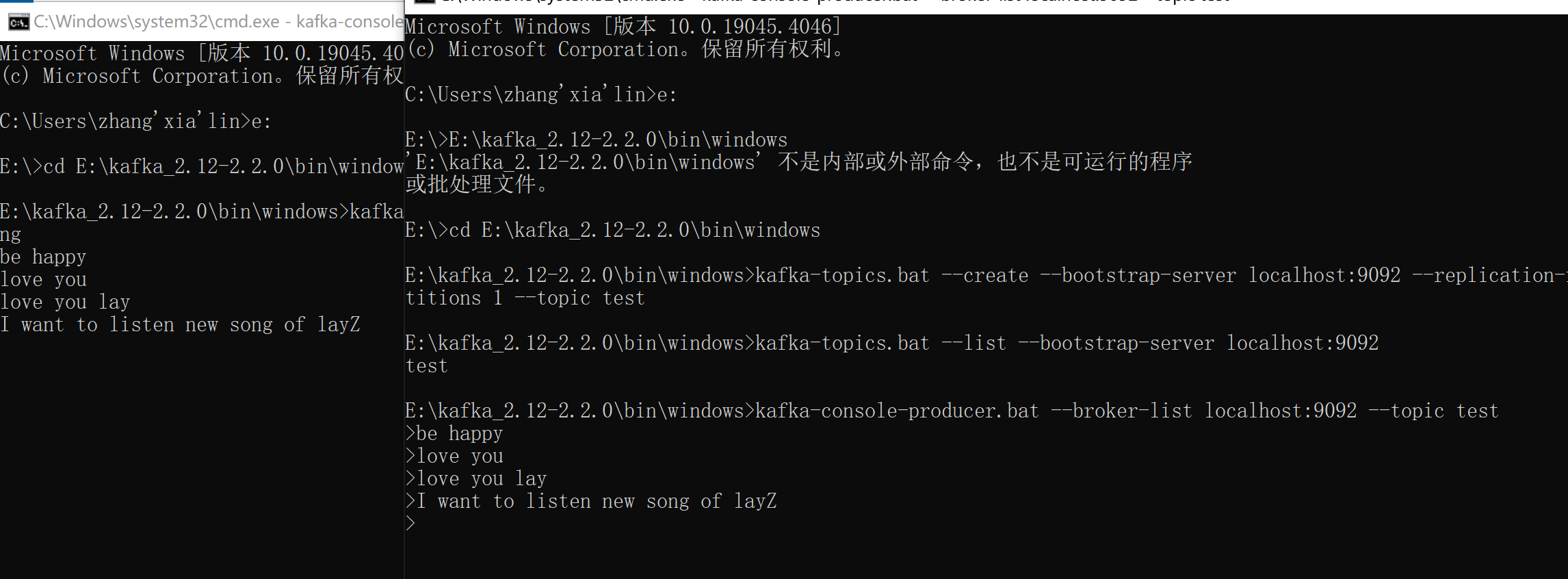
创建Topic
利用创建主题工具kafka-topics.bat, --bootstrap-servers指定使用的服务器,使用本机Kafka的默认端口9092为服务器, --replication-factor创建副本数为1, --partitions分区数为1, --topic主题名为test
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
没有提示即为创建成功

查看Topic
指定看哪个服务器上的topic
kafka可以搭建成一个集群,有多个服务器,因此操作时要指定服务器
kafka-topics.bat --list --bootstrap-server localhost:9092

发送消息
以生产者模式向topic上发送消息
–broker-list 服务器列表,用于指定往哪些服务器上发送消息
kafka-console-producer.bat --broker-list localhost:9092 --topic test
每点击一次回车,发送一条消息

获取消息
再启动一个cmd窗口代表消费者
进入Kafka命令行工具内
以消费者身份,从指定服务器的指定主题上,从头开始读所有的消息
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning

当生产者继续传数据时,消费者也会自动获取
Spring整合Kafka
引入依赖
spring-kafka
<dependencyorg="org.springframework.kafka"name="spring-kafka"rev="3.1.1"/><!-- 使用父pom中声明的版本,不用子pom中的版本version --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
配置Kafka
配置server、consumer
# KafkaProperties
# 使用的服务器
spring.kafka.bootstrap-servers=localhost:9092
# 消费者分组id(在kafka的消费者配置文件consumer.properties中可以找到)
spring.kafka.consumer.group-id=community-consumer-group
# 是否自动提交消费者的偏移量(消费者读取消息是按偏移量来读取的,在读取完后,偏移量发生改变,是否需要自动提交)
spring.kafka.consumer.enable-auto-commit=true
# 自动提交频率:3000毫秒
spring.kafka.consumer.auto-commit-interval=3000
要修改 消费者配置文件consumer.properties中 grop.id=community-consumer-group,需要重启服务才能生效

访问Kafka
- 生产者:利用spring整合好的类KafkaTemplate,发布数据:> kafkaTemplate.send(topic, data);
- 消费者:通过注解 @KafkaListener实现> @KafkaListener用在方法上,表示该方法会监听指定主题,一旦主题上有消息,就会调用方法处理这些消息> > 注解通过“{ }”指定一个或多个topic,消息会封装成ConsumerRecord传入给方法> > 一个方法可以消费多个Topic,一个Topic也可以被多个方法消费服务一旦启动,spring会自动监听指定topic,即有一个线程一直处于阻塞状态,试图去读取topic下的消息,当有消息时,线程自动去读取数据,并交给我们定义的方法来处理
@KafkaListener(topics ={"test"})publicvoidhandleMessage(ConsumerRecord record){......}
注意:
生产者是主动发送消息,依赖KafkaTemplate,希望什么时候发送消息,就什么时候调用 发数据的方法
消费者是被动的处理消息,不依赖KafkaTemplate。一旦监听到有数据,就会自动调用方法处理。这个过程可能有些延迟,但不会很久,因为队列中有很多消息,处理到目标消息需要时间
代码实例
测试生产者发送消息,消费者能否自动收到并打印
生产者
// 生产者类@ComponentclassKafkaProducer{// 注入spring整合好的类KafkaTemplate@AutowiredprivateKafkaTemplate kafkaTemplate;// 增加一个方法,供外界调用,用来给topic发送数据publicvoidsendMessage(String topic,String content){
kafkaTemplate.send(topic, content);}}
消费者
// 消费者类@ComponentclassKafkaConsumer{@KafkaListener(topics ={"test"})publicvoidhandleMessage(ConsumerRecord record){System.out.println(record.value());}}
测试
@RunWith(SpringRunner.class)@SpringBootTest@ContextConfiguration(classes =CommunityApplication.class)publicclassKafkaTests{@AutowiredprivateKafkaProducer kafkaProducer;@TestpublicvoidtestKafka(){// 生产者发消息
kafkaProducer.sendMessage("test","你好");
kafkaProducer.sendMessage("test","在吗");try{// 要令程序等一下,因为消费者消费有个过程// 如果不等,程序立刻结束,就看不到消费者消费数据的过程了// 阻塞当前线程,从而令程序等待Thread.sleep(1000*10);// 阻塞10s}catch(InterruptedException e){
e.printStackTrace();}}}
一些选择题
版权归原作者 啊夏同学 所有, 如有侵权,请联系我们删除。