
1.Hadoop生态圈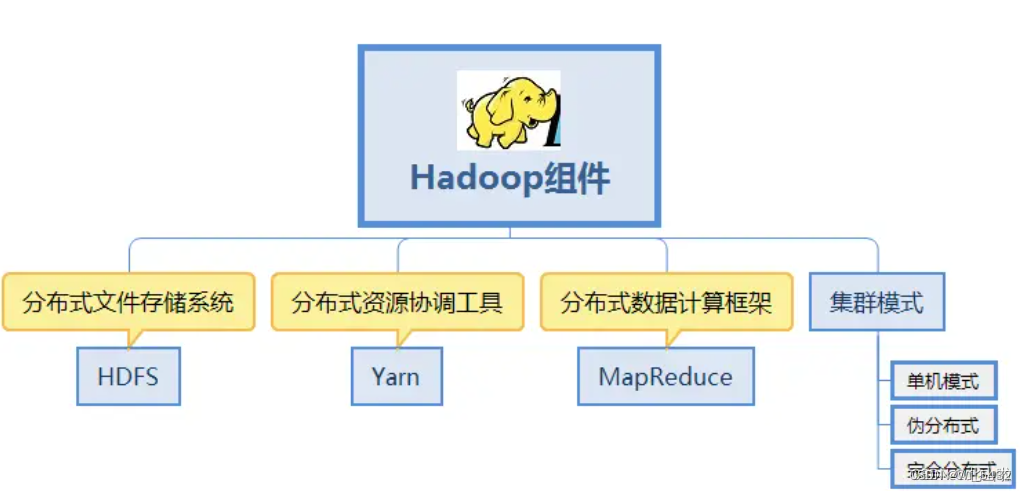
1.Hadoop概念
Hadoop是一个分布式系统基础架构,主要是为了解决海量数据的存储和海量数据的分析计算问题。
2.Hadoop特性
三点: 高扩展性 高效性 高容错性
2.认识Spark
1.Spark故事
Spark支持多种运行方式,包括在Hadoop和Mesos上,也支持Standalone的独立运行模式,同时也可以运行在云Kubernets(Spark2.3开始支持)上 对于数据源而言,Spark支持从HDFS、HBase、Cassandra及Kafka等多种途径获取和数据
2.Spark生态圈
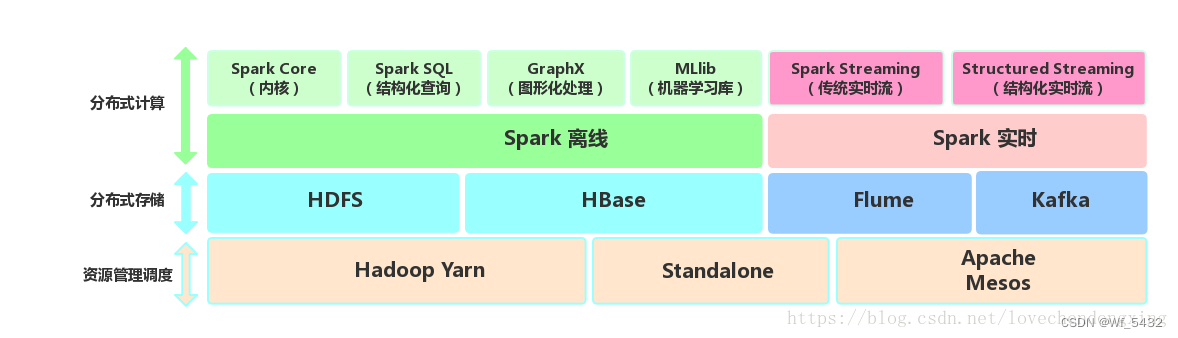
##(具有可靠、高效、可伸缩的特点)
3.Spark概述
Spark在2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。

3.Spark 特点
1.快速
Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。所以说,Spark是一个更加快速、高效的大数据计算平台。
##(spark 基于内存 | MapReduce 基于磁盘)
2.易用
Spark的版本已经更新到了Spark3.1.2(截止日期2021.06.01),支持了包括Java、Scala、Python、R和SQL语言在内的多种语言。为了兼容Spark2.x企业级应用场景,Spark仍然持续更新Spark2版本
3.通用
在Spark的基础上,Spark还提供了包括Spark SQL、Spark Streaming、MLib及GraphX在内的多个工具库,我们可以在一个应用中无缝的使用这些工具库
4.随处运行
Spark支持多种运行方式,包括在Hadoop和Mesos上,也支持Standalone的独立运行模式,同时也可以运行在云Kubernets(Spark2.3开始支持)上 对于数据源而言,Spark支持从HDFS、HBase、Cassandra及Kafka等多种途径获取和数据

5.代码简洁
Spark支持支持Scala,Python等编码代码。
4.代码回顾
1.基础命令
1)命令
#(pwd cd cat mkidr rm cp mv )#
- ls 命令 格式:ls [选项] [文件|目录] 功能:显示指定目录中的文件或子目录信息。当不指定文件或目录时,显示 当前工作目录中的文件或子目录信息。 命令常用选项如下: -a :全部的档案,连同隐藏档( 开头为 . 的档案) 一起列出来。 -l :长格式显示,包含文件和目录的详细信息。 -R :连同子目录内容一起列出来。 说明:命令“ls –l”设置了别名:ll,即输入 ll 命令,执行的是 ls –l
- chown 命令 格式:chown [选项] 功能:将文件或目录的拥有者改为指定的用户或组,用户可以是用户名或者 用户 ID,组可以是组名或者组 ID,文件是以空格分开的要改变权限的文件 列表支持通配符。选项“-R”表示对目前目录下的所有文件与子目录进行相同 的拥有者变更。
- chmod 命令 格式:chmod [-R] 模式 文件或目录 功能:修改文件或目录的访问权限。选项“-R”表示递归设置指定目录下的所 有文件和目录的权限。 模式为文件或目录的权限表示,有三种表示方法。((1) 数字表示 用 3 个数字表示文件或目录的权限,第 1 个数字表示所有者的权限,第 2个 数字表示与所有者同组用户的权限,第 3 个数字表示其他用户的权限。每类 用户都有 3 类权限:读、写、执行,对应的数字分别是 4、2、1。一个用户 的权限数字表示为三类权限的数字之和,如一个用户对 A 文件拥有读写权 限,则这个用户的权限数字为 6(4+2=6)。(2)字符赋值 用字符 u 表示所有者,用字符 g 表示与所有者同组用户,用字符 o 表示其他 用户。用字符 r、w、x 分别表示读、写、执行权限。用等号“=”来给用户赋 权限。3)字符加减权限 用字符 u 表示所有者,用字符 g 表示与所有者同组用户,用字符 o 表示其他 用户。用字符 r、w、x 分别表示读、写、执行权限。用加号“+”来给用户加 权限,加号“-”来给用户减权限。)
- tar 命令 格式:tar [选项] [档案名] [文件或目录] 功能:为文件和目录创建档案。利用 tar 命令,可以把一大堆的文件和目录 全部打包成一个文件,这对于备份文件或将几个文件组合成为一个文件以便 于网络传输是非常有用的。该命令还可以反过来,将档案文件中的文件和目 录释放出来。 常用选项: -c 建立新的备份文件。 -C 切换工作目录,先进入指定目录再执行压缩/解压缩操作,可用于 仅压缩特定目录里的内容或解压缩到特定目录。 -x 从归档文件中提取文件。 -z 通过 gzip 指令压缩/解压缩文件,文件名为*.tar.gz。 -f 指定备份文件。 -v 显示命令执行过程。
2)文本编辑
1.vim.或vi
2.tail
2.图片
1)演示

5.结构化数据和非结构化数据
1.概念解释
结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。
非结构化数据:不方便用数据库二维逻辑表来表现的数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
半结构化数据:就是介于完全结构化数据(如关系型数据库、面向对象数据库中的数据)和完全无结构的数据(如声音、图像文件等)之间的数据,HTML文档就属于半结构化数据。它一般是自描述的,数据的结构和内容混在一起,没有明显的区分。
2.应用位置
结构化数据的应用:企业数据管理 报表生成和分析 数据挖掘和预测建模
6.冷备,热备和温备
1.概念
热备(在线备份):在数据库运行时直接备份,对数据库操作没有任何影响。
冷备(离线备份):在数据库停止时进行备份。
温备:在数据库运行时加全局读锁备份,保证了备份数据的一致性,但对性能有影响。
2.热备流程
- 备份开始时,记录重做日志的日志序号(LSN)。
- 复制共享表空间和独立表空间的文件。
- 复制完后,再次记录重做日志的日志序号(LSN)。
- 通过前面记录的日志序号来复制在备份时产生的重做日志。
3.冷备优点
- 备份简单恢复快
版权归原作者 Wf_5432 所有, 如有侵权,请联系我们删除。