
前言:
本文采用的进程调度算法有:先来先服务,短作业优先,优先级调度算法和时间片轮转调度算法。
针对这四种算法,我采用的是建立数组结构体,如:
struct job {
char name[10]; //作业的名字
int starttime; //作业到达系统时间
int needtime; //作业服务时间
int runtime; //作业周转时间
int endtime; //作业结束时间
double dqzz_time; //带权周转时间
};
一,先来先服务算法:
1,算法思想:
先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。采用FCFS算法,每次从后备队列中选择一个或多个最先进入该队列的作业,将他们调入内存,为他们分配资源,创建进程,然后放入就绪队列。在进程调度中采用FCFS算法时,则每次调度是从就绪队列中选择一个最先进入该队列的进程,为之分配处理机,使之投入运行。该进程一直运行到完成或发生某事件而阻塞后才放弃处理机。
2,算法实例:
首先,先对运行函数进行声明:
void FCFS(struct job jobs[50], int n);//先来先服务算法
其中n为进程个数。
其次,按照进程到达时间进行排序:
for (i = 0; i < n; i++) //按作业到达系统时间进行排序,最早到达的排在最前面
{
for (j = i; j < n; j++) //按作业到达系统时间进行排序,最早到达的排在最前面
{
if (jobs[j].starttime < jobs[i].starttime)
{ //把到达时间早的赋值到t_time
t_time = jobs[j].starttime;
jobs[j].starttime = jobs[i].starttime;
jobs[i].starttime = t_time;
//把到达时间早的赋值到t_time
t_time = jobs[j].needtime;
jobs[j].needtime = jobs[i].needtime;
jobs[i].needtime = t_time;
strcpy(t_name, jobs[j].name);//这里用strcpy函数是由于name变量为字符串类型,不能用=赋值
strcpy(jobs[j].name, jobs[i].name);
strcpy(jobs[i].name, t_name);//利用t_name数组进行交换排序
}
}
}
二,短作业优先算法
1,算法思想:
短作业优先(SJF, Shortest Job First)又称为“短进程优先”SPN(Shortest Process Next);是对FCFS算法的改进,其目标是减少平均周转时间。
短作业优先调度算法基于这样一种思想:
运行时间短的优先调度;
如果运行时间相同则调度最先发起请求的进程。
等待时间:一个进程从发起请求到开始执行的时间间隔。
现在有n个进程请求cpu,每个进程用一个二元组表示:(p,q),p代表该进程发起请求的时间,p代表需要占用cpu的时间。
请计算n个进程的平均等待时间。
2,算法实例:
首先,先对运行函数进行声明:
void SJF(struct job jobs[50], int n);//短作业优先算法
其中n为进程个数。
其次,按照最短运行时间排序:
for (i = 1; i < n; i++)
{
for (j = i; j < n; j++)
{
//按最短运行时间排序
//关于jobs[i - 1].endtime > jobs[j].starttime如果到达时间太迟于上一轮的结束时间,会造成浪费时间资源用以等待
if (jobs[i - 1].endtime > jobs[j].starttime && jobs[j].needtime < jobs[i].needtime)
{
t_time = jobs[i].starttime;
jobs[i].starttime = jobs[j].starttime;
jobs[j].starttime = t_time;
//把短的赋值到临时变量t_time中
t_time = jobs[i].needtime;
jobs[i].needtime = jobs[j].needtime;
jobs[j].needtime = t_time;
strcpy(t_name, jobs[i].name); //将第二个参数的值复制给第一个参数,返回第一个参数
strcpy(jobs[i].name, jobs[j].name);
strcpy(jobs[j].name, t_name);
} //按最短运行时间排序
}
if (jobs[i].starttime > jobs[i - 1].endtime)
{ //第i个进程到达系统时,第i-1个进程已运行完毕
jobs[i].endtime = jobs[i].starttime + jobs[i].needtime;//结束时间=到达时间+服务时间
jobs[i].runtime = jobs[i].needtime;//周转时间=服务时间
}
else
{
jobs[i].endtime = jobs[i - 1].endtime + jobs[i].needtime;//结束时间=上一个的结束时间+服务时间
jobs[i].runtime = jobs[i].endtime - jobs[i].starttime;//周转时间=结束时间-到达时间
}
jobs[i].dqzz_time = jobs[i].runtime * 1.0 / jobs[i].needtime;
}
三,优先级调度算法
1,算法思想:
优先级调度的含义
当该算法用于作业调度时,系统从后备作业队列中选择若干个优先级最高的,且系统能满足资源要求的作业装入内存运行。
当该算法用于进程调度时,将把处理机分配给就绪进程队列中优先级最高的进程。
调度算法的两种方式
优先级调度算法细分成如下两种方式:
非抢占式优先级算法
在这种调度方式下,系统一旦把处理机分配给就绪队列中优先级最高的进程后,该进程就能一直执行下去,直至完成;或因等待某事件的发生使该进程不得不放弃处理机时,系统才能将处理机分配给另一个优先级高的就绪进程。
抢占式优先级调度算法
在这种调度方式下,进程调度程序把处理机分配给当时优先级最高的就绪进程,使之执行。一旦出现了另一个优先级更高的就绪进程时,进程调度程序就停止正在执行的进程,将处理机分配给新出现的优先级最高的就绪进程。
优先级的类型
进程的优先级可采用静态优先级和动态优先级两种,优先级可由用户自定或由系统确定。
2,算法实例:
首先,先对运行函数进行声明:
void HRRN(struct job jobs[50],int n);//优先调度算法
其中n为进程个数。
其次,设计优先级:
double hrrn[10];//动态优先级
然后,按照优先级进行比较并排序:
for (i = 1; i < n; i++)
{
for (j = i; j < n; j++)
{
//优先级=(等待时间+要求服务时间)/ 要求服务时间
hrrn[j] = static_cast<double>(jobs[i - 1].endtime - jobs[j].starttime + jobs[j].needtime) / jobs[j].needtime;
}//这是此时第i个进程结束后的所有进程的优先级
for (int t = i + 1; t < n; t++) {
if (hrrn[t] > hrrn[i]) {
t_time = jobs[t].starttime;
jobs[t].starttime = jobs[i].starttime;
jobs[i].starttime = t_time;
//把短的赋值到临时变量t_time中
t_time = jobs[t].needtime;
jobs[t].needtime = jobs[i].needtime;
jobs[i].needtime = t_time;
strcpy(t_name, jobs[t].name);
strcpy(jobs[t].name, jobs[i].name);
strcpy(jobs[i].name, t_name);
}//按优先级进行比较并排序
}
jobs[i].endtime = jobs[i - 1].endtime + jobs[i].needtime;//第i个进程的结束时间=上一个的结束时间+服务时间
}
四,时间片轮转调度算法
1,算法思想:
时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程。如果进程在时间片结束前阻塞或结束,则CPU当即进行切换。调度程序所要做的就是维护一张就绪进程列表,当进程用完它的时间片后,它被移到队列的末尾。
2,算法实例:
首先,先对运行函数进行声明:
void RR(struct job jobs[50],int n);//时间片轮转算法
其中n为进程个数。
其次,以scanf函数从键盘得到一个时间片长度:
printf("请输入时间片的大小:");
scanf("%d",&t);
这里由于我用以运行结果显示方便,因此直接用周转时间和带权周转时间的结果表示:
for (i = 0; i < n; i++) {
s += jobs[i].needtime;//s是用来确认所有进程全部结束
f[i] = jobs[i].needtime;//f[i]用以存储单个进程剩余所需运行时间
}
do {
for (i = 0; i < n; i++) {
if (f[i]) { //若f[i] == 0,则说明本进程的运行已全部结束
//如果本进程剩余时间比时间片大,则总运行时间加一个时间片,本进程剩余运行时间减一个时间片,并将s减一个时间片
if (f[i] > t) {
time += t;
f[i] -= t;
s -= t;
}
//如果本进程剩余时间比时间片小,则总运行时间加一个时间片,s减一个本进程剩余运行时间,并将本进程剩余运行时间归零
else {
time += t;
jobs[i].endtime = time;
s -= f[i];
f[i] = 0;
}
}
}
} while (s);
for (i = 0; i < n; i++) {
jobs[i].runtime = jobs[i].endtime - jobs[i].starttime;//周转时间 = 结束时间 - 到达时间
jobs[i].dqzz_time = jobs[i].runtime * 1.0 / jobs[i].needtime;//带权周转时间=周转时间/服务时间
}
其中time为总运行时间。
五,对每个进程的最终结果进行输出
声明:
void print(struct job jobs[50], int n);
代码如下:
void print(struct job jobs[50], int n)
{
int i;
double avertime;
double dqzz_avertime;
int sum_runtime = 0;
double sum_time = 0.00;
printf("作业名 到达时间 运行时间 完成时间 周转时间 带权周转时间\n");
for (i = 0; i < n; i++)
{
printf("%s %2d %2d %2d %2d %.2f\n", jobs[i].name, jobs[i].starttime, jobs[i].needtime, jobs[i].endtime, jobs[i].runtime, jobs[i].dqzz_time);
sum_runtime = sum_runtime + jobs[i].runtime;
sum_time = sum_time + jobs[i].dqzz_time;
}
avertime = sum_runtime * 1.0 / n;
dqzz_avertime = sum_time * 1.000 / n;
printf("平均周转时间:%.2f \n", avertime);
printf("平均带权周转时间:%.3f \n", dqzz_avertime);
printf("\n");
}
六,运行结果
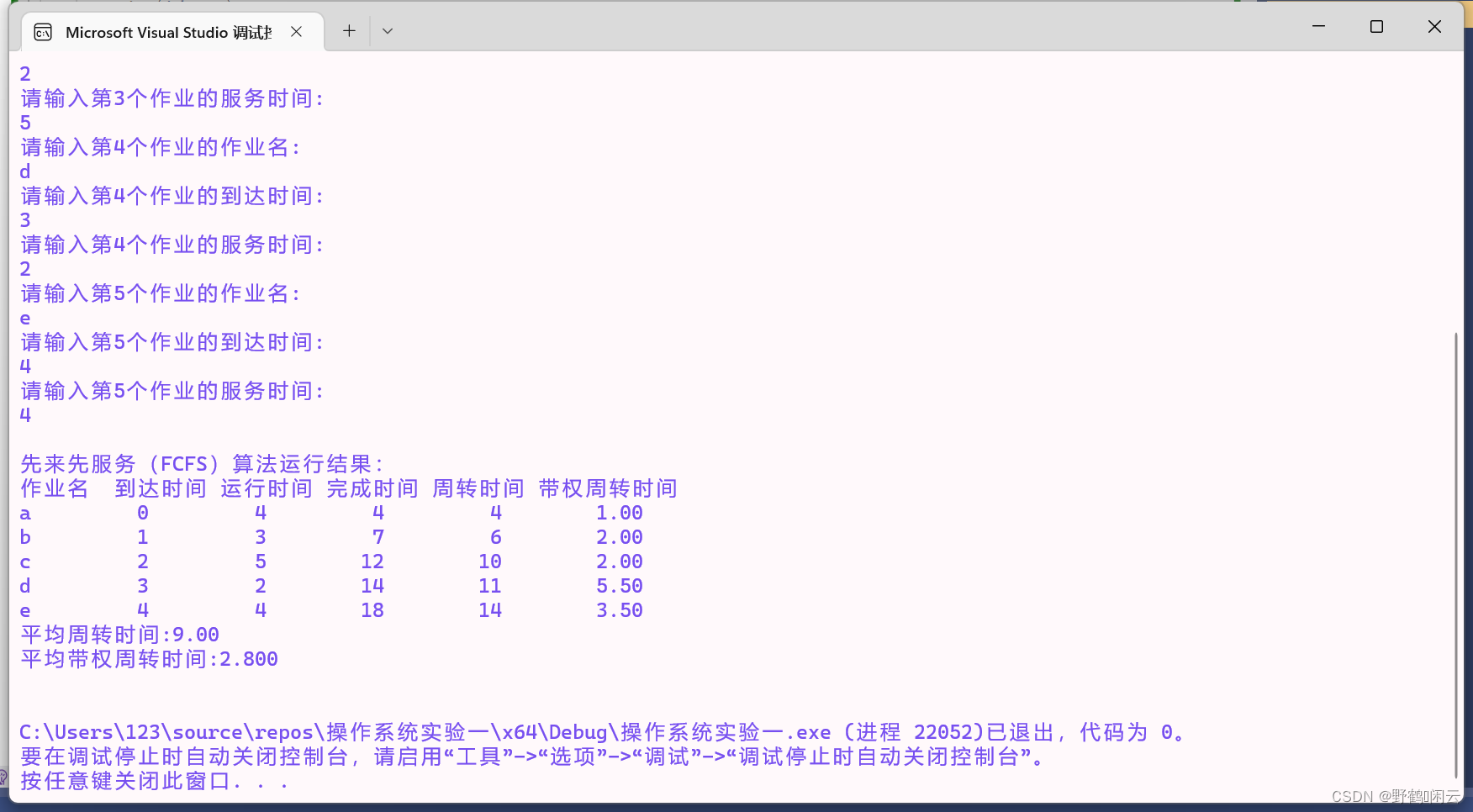
1,先来先服务算法:
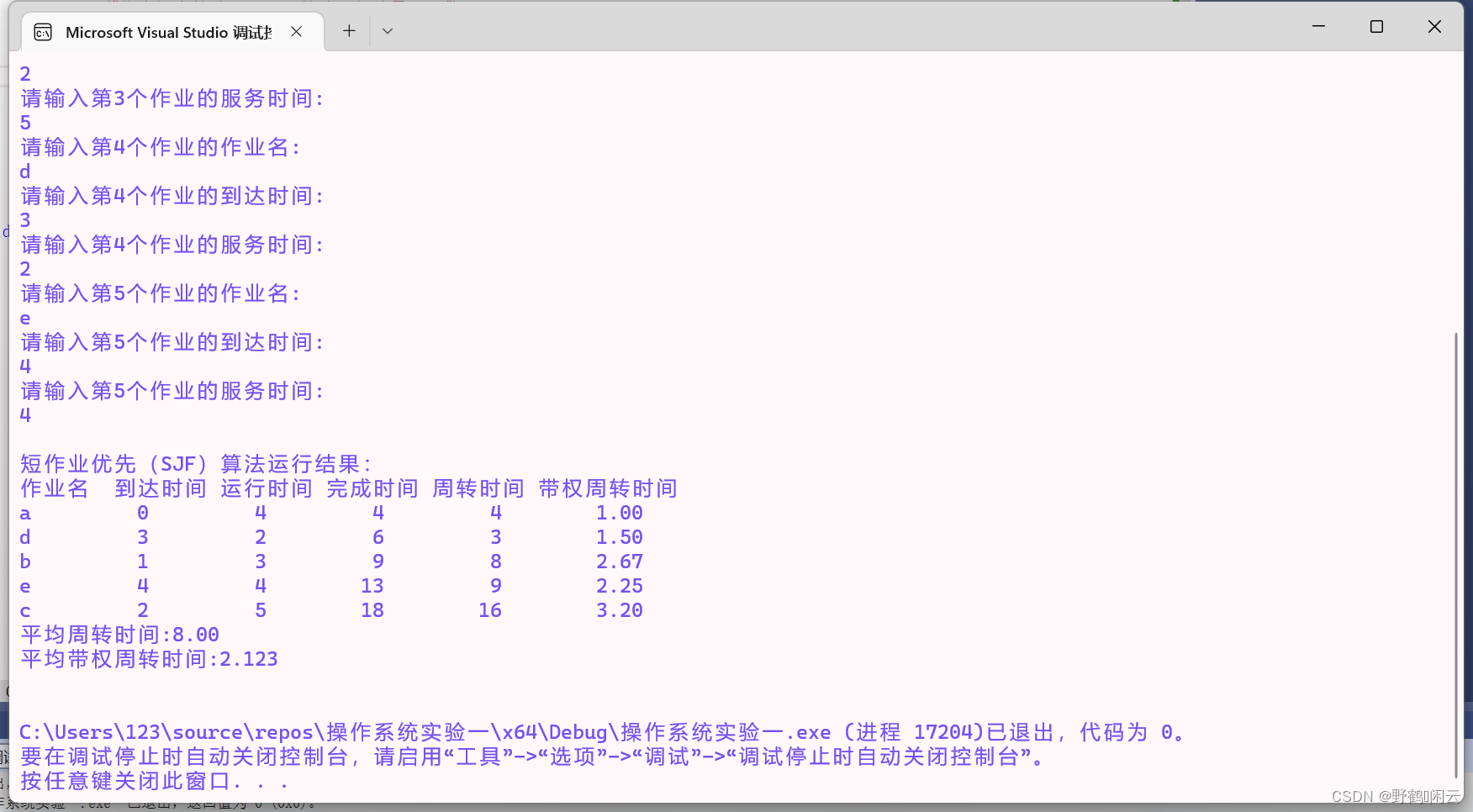
2,短作业优先算法:
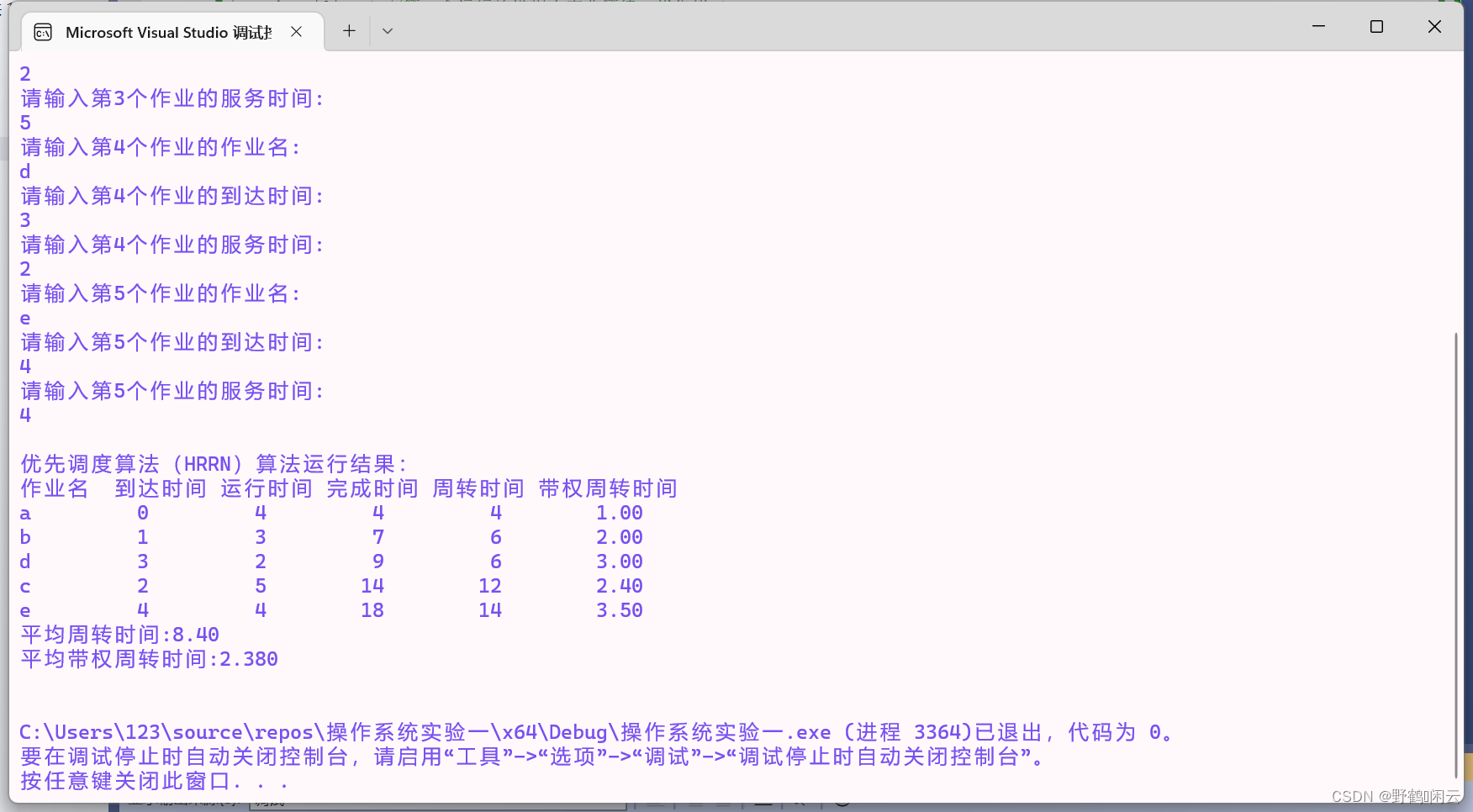
3,优先级调度算法:
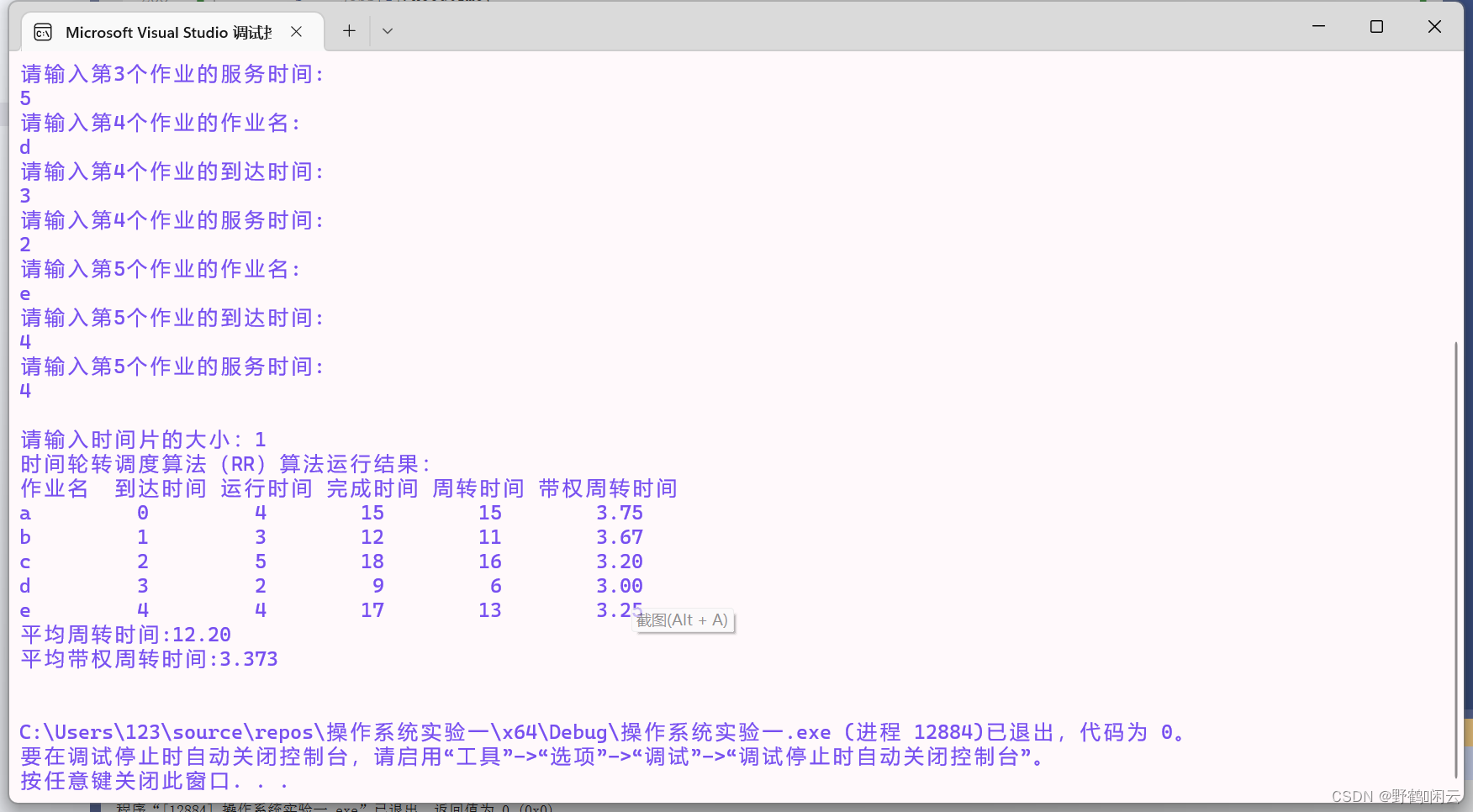
4,时间片轮转算法:
七,总结
每个算法都有自己的优缺点,我个人的话,则更倾向于优先级调度算法,既考虑到了长进程的等待时间,也考虑到了短作业稍稍优先的模式。
全部运行代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
struct job {
char name[10]; //作业的名字
int starttime; //作业到达系统时间
int needtime; //作业服务时间
int runtime; //作业周转时间
int endtime; //作业结束时间
double dqzz_time; //带权周转时间
};
void FCFS(struct job jobs[50], int n);//先来先服务算法
void SJF(struct job jobs[50], int n);//短作业优先算法
void HRRN(struct job jobs[50],int n);//优先调度算法
void RR(struct job jobs[50],int n);//时间片轮转算法
void print(struct job jobs[50], int n);
int main() {
struct job jobs[50];
int n, i; //n个作业
int flag;
printf("请选择调度算法,1:先来先服务 2:短作业优先 3:优先调度算法 4:时间轮转调度算法");
scanf("%d", &flag);
printf("请输入作业个数:");
scanf("%d", &n);
for (i = 0; i < n; i++)
{
printf("请输入第%d个作业的作业名:\n",i + 1);
scanf("%s", jobs[i].name); //作业名
printf("请输入第%d个作业的到达时间:\n",i + 1);
scanf("%d", &jobs[i].starttime);//到达时间
printf("请输入第%d个作业的服务时间:\n",i + 1);
scanf("%d", &jobs[i].needtime);//运行(服务时间)时间
}
printf("\n");
switch (flag){
case 1:
FCFS(jobs, n);
printf("先来先服务(FCFS)算法运行结果:\n");
print(jobs, n);
break;
case 2:
SJF(jobs, n);
printf("短作业优先(SJF)算法运行结果:\n");
print(jobs, n);
break;
case 3:
HRRN(jobs, n);
printf("优先调度算法(HRRN)算法运行结果:\n");
print(jobs, n);
break;
case 4:
RR(jobs, n);
printf("时间轮转调度算法(RR)算法运行结果:\n");
print(jobs, n);
break;
}
}
void FCFS(struct job jobs[50], int n){
int i = 0, j = 0;
char t_name[10];//用于交换的临时变量
int t_time;//用于交换的临时变量
for (i = 0; i < n; i++) //按作业到达系统时间进行排序,最早到达的排在最前面
{
for (j = i; j < n; j++) //按作业到达系统时间进行排序,最早到达的排在最前面
{
if (jobs[j].starttime < jobs[i].starttime)
{ //把到达时间早的赋值到t_time
t_time = jobs[j].starttime;
jobs[j].starttime = jobs[i].starttime;
jobs[i].starttime = t_time;
//把到达时间早的赋值到t_time
t_time = jobs[j].needtime;
jobs[j].needtime = jobs[i].needtime;
jobs[i].needtime = t_time;
strcpy(t_name, jobs[j].name);//这里用strcpy函数是由于name变量为字符串类型,不能用=赋值
strcpy(jobs[j].name, jobs[i].name);
strcpy(jobs[i].name, t_name);//利用t_name数组进行交换排序
}
}
}
for (i = 0; i < n; i++)
{
if (i == 0)
{ //第一个进程
jobs[i].runtime = jobs[i].needtime; //周转时间=服务时间
jobs[i].endtime = jobs[i].starttime + jobs[i].needtime; //结束时间=到达时间+服务时间
}
else if (jobs[i].starttime > jobs[i - 1].endtime)
{ //第i个进程到达系统时,第i-1个进程已运行完毕
jobs[i].runtime = jobs[i].needtime;
jobs[i].endtime = jobs[i].starttime + jobs[i].needtime;
}
else
{ //第i个进程到达系统时,第i-1个进程未运行完毕
jobs[i].runtime = jobs[i].needtime + jobs[i - 1].endtime - jobs[i].starttime;
//周转时间 = 服务时间 + 前一个的结束时间 - 到达时间(结束时间 = 服务时间 + 前一个的结束时间)
jobs[i].endtime = jobs[i].starttime + jobs[i].runtime; //结束时间 = 到达时间 + 周转时间
}
jobs[i].dqzz_time = jobs[i].runtime * 1.0 / jobs[i].needtime;//带权周转时间=周转时间/服务时间
}
}
void SJF(struct job jobs[50], int n)
{
int i = 0, j = 0;
char t_name[10];//用于交换的临时变量
int t_time;//用于交换的临时变量
for (i = 0; i < n; i++) //按作业到达系统时间进行排序,最早到达的排在最前面
{
for (j = i; j < n; j++) //按作业到达系统时间进行排序,最早到达的排在最前面
{
if (jobs[j].starttime < jobs[i].starttime)
{ //把到达时间早的赋值到t_time
t_time = jobs[j].starttime;
jobs[j].starttime = jobs[i].starttime;
jobs[i].starttime = t_time;
//把到达时间早的赋值到t_time
t_time = jobs[j].needtime;
jobs[j].needtime = jobs[i].needtime;
jobs[i].needtime = t_time;
strcpy(t_name, jobs[j].name);//这里用strcpy函数是由于name变量为字符串类型,不能用=赋值
strcpy(jobs[j].name, jobs[i].name);
strcpy(jobs[i].name, t_name);//利用t_name数组进行交换排序
}
}
}
jobs[0].endtime = jobs[0].starttime + jobs[0].needtime;//结束时间=到达时间+服务时间
jobs[0].runtime = jobs[0].needtime;//周转时间=服务时间
jobs[0].dqzz_time = jobs[0].runtime * 1.0 / jobs[0].needtime;//带权周转时间=周转时间/服务时间
for (i = 1; i < n; i++)
{
for (j = i; j < n; j++)
{
//按最短运行时间排序
//关于jobs[i - 1].endtime > jobs[j].starttime如果到达时间太迟于上一轮的结束时间,会造成浪费时间资源用以等待
if (jobs[i - 1].endtime > jobs[j].starttime && jobs[j].needtime < jobs[i].needtime)
{
t_time = jobs[i].starttime;
jobs[i].starttime = jobs[j].starttime;
jobs[j].starttime = t_time;
//把短的赋值到临时变量t_time中
t_time = jobs[i].needtime;
jobs[i].needtime = jobs[j].needtime;
jobs[j].needtime = t_time;
strcpy(t_name, jobs[i].name); //将第二个参数的值复制给第一个参数,返回第一个参数
strcpy(jobs[i].name, jobs[j].name);
strcpy(jobs[j].name, t_name);
} //按最短运行时间排序
}
if (jobs[i].starttime > jobs[i - 1].endtime)
{ //第i个进程到达系统时,第i-1个进程已运行完毕
jobs[i].endtime = jobs[i].starttime + jobs[i].needtime;//结束时间=到达时间+服务时间
jobs[i].runtime = jobs[i].needtime;//周转时间=服务时间
}
else
{
jobs[i].endtime = jobs[i - 1].endtime + jobs[i].needtime;//结束时间=上一个的结束时间+服务时间
jobs[i].runtime = jobs[i].endtime - jobs[i].starttime;//周转时间=结束时间-到达时间
}
jobs[i].dqzz_time = jobs[i].runtime * 1.0 / jobs[i].needtime;
}
}
void HRRN(struct job jobs[50], int n) {
int i = 0, j = 0;
double hrrn[10];//动态优先级
char t_name[10];//用于交换的临时变量
int t_time;//用于交换的临时变量
for (i = 0; i < n; i++) {
if (jobs[i].starttime == 0) {
t_time = jobs[0].starttime;
jobs[0].starttime = jobs[i].starttime;
jobs[i].starttime = t_time;
//把第一个到达的放入临时变量t_time中
t_time = jobs[0].needtime;
jobs[0].needtime = jobs[i].needtime;
jobs[i].needtime = t_time;
strcpy(t_name, jobs[0].name);
strcpy(jobs[0].name, jobs[i].name);
strcpy(jobs[i].name, t_name);
}
}
hrrn[0] = 1;//第一个运行的进程不需要等待,优先级=1
jobs[0].endtime = jobs[0].needtime;//第一个进程的结束时间即其服务时间
for (i = 1; i < n; i++)
{
for (j = i; j < n; j++)
{
//优先级=(等待时间+要求服务时间)/ 要求服务时间
hrrn[j] = static_cast<double>(jobs[i - 1].endtime - jobs[j].starttime + jobs[j].needtime) / jobs[j].needtime;
}//这是此时第i个进程结束后的所有进程的优先级
for (int t = i + 1; t < n; t++) {
if (hrrn[t] > hrrn[i]) {
t_time = jobs[t].starttime;
jobs[t].starttime = jobs[i].starttime;
jobs[i].starttime = t_time;
//把短的赋值到临时变量t_time中
t_time = jobs[t].needtime;
jobs[t].needtime = jobs[i].needtime;
jobs[i].needtime = t_time;
strcpy(t_name, jobs[t].name);
strcpy(jobs[t].name, jobs[i].name);
strcpy(jobs[i].name, t_name);
}//按优先级进行比较并排序
}
jobs[i].endtime = jobs[i - 1].endtime + jobs[i].needtime;//第i个进程的结束时间=上一个的结束时间+服务时间
}
for (i = 0; i < n; i++)
{
if (i == 0)
{ //第一个进程
jobs[i].runtime = jobs[i].needtime; //周转时间=服务时间
jobs[i].endtime = jobs[i].starttime + jobs[i].needtime; //结束时间=到达时间+服务时间
}
else if (jobs[i].starttime > jobs[i - 1].endtime)
{ //第i个进程到达系统时,第i-1个进程已运行完毕
jobs[i].runtime = jobs[i].needtime;
jobs[i].endtime = jobs[i].starttime + jobs[i].needtime;
}
else
{ //第i个进程到达系统时,第i-1个进程未运行完毕
jobs[i].runtime = jobs[i].needtime + jobs[i - 1].endtime - jobs[i].starttime;
//周转时间 = 服务时间 + 前一个的结束时间 - 到达时间(结束时间 = 服务时间 + 前一个的结束时间)
jobs[i].endtime = jobs[i].starttime + jobs[i].runtime; //结束时间 = 到达时间 + 周转时间
}
jobs[i].dqzz_time = jobs[i].runtime * 1.0 / jobs[i].needtime;//带权周转时间=周转时间/服务时间
}
}
void RR(struct job jobs[50], int n) {
int t, s = 0, time = 0;
int f[1000];
printf("请输入时间片的大小:");
scanf("%d",&t);
int i = 0, j = 0;
for (i = 0; i < 1000; i++) {
f[i] = 0;
}
char t_name[10];//用于交换的临时变量
int t_time;//用于交换的临时变量
for (i = 0; i < n; i++) //按作业到达系统时间进行排序,最早到达的排在最前面
{
for (j = i; j < n; j++) //按作业到达系统时间进行排序,最早到达的排在最前面
{
if (jobs[j].starttime < jobs[i].starttime)
{ //把到达时间早的赋值到t_time
t_time = jobs[j].starttime;
jobs[j].starttime = jobs[i].starttime;
jobs[i].starttime = t_time;
//把到达时间早的赋值到t_time
t_time = jobs[j].needtime;
jobs[j].needtime = jobs[i].needtime;
jobs[i].needtime = t_time;
strcpy(t_name, jobs[j].name);//这里用strcpy函数是由于name变量为字符串类型,不能用=赋值
strcpy(jobs[j].name, jobs[i].name);
strcpy(jobs[i].name, t_name);//利用t_name数组进行交换排序
}
}
}
for (i = 0; i < n; i++) {
s += jobs[i].needtime;//s是用来确认所有进程全部结束
f[i] = jobs[i].needtime;//f[i]用以存储单个进程剩余所需运行时间
}
do {
for (i = 0; i < n; i++) {
if (f[i]) { //若f[i] == 0,则说明本进程的运行已全部结束
//如果本进程剩余时间比时间片大,则总运行时间加一个时间片,本进程剩余运行时间减一个时间片,并将s减一个时间片
if (f[i] > t) {
time += t;
f[i] -= t;
s -= t;
}
//如果本进程剩余时间比时间片小,则总运行时间加一个时间片,s减一个本进程剩余运行时间,并将本进程剩余运行时间归零
else {
time += t;
jobs[i].endtime = time;
s -= f[i];
f[i] = 0;
}
}
}
} while (s);
for (i = 0; i < n; i++) {
jobs[i].runtime = jobs[i].endtime - jobs[i].starttime;//周转时间 = 结束时间 - 到达时间
jobs[i].dqzz_time = jobs[i].runtime * 1.0 / jobs[i].needtime;//带权周转时间=周转时间/服务时间
}
}
void print(struct job jobs[50], int n)
{
int i;
double avertime;
double dqzz_avertime;
int sum_runtime = 0;
double sum_time = 0.00;
printf("作业名 到达时间 运行时间 完成时间 周转时间 带权周转时间\n");
for (i = 0; i < n; i++)
{
printf("%s %2d %2d %2d %2d %.2f\n", jobs[i].name, jobs[i].starttime, jobs[i].needtime, jobs[i].endtime, jobs[i].runtime, jobs[i].dqzz_time);
sum_runtime = sum_runtime + jobs[i].runtime;
sum_time = sum_time + jobs[i].dqzz_time;
}
avertime = sum_runtime * 1.0 / n;
dqzz_avertime = sum_time * 1.000 / n;
printf("平均周转时间:%.2f \n", avertime);
printf("平均带权周转时间:%.3f \n", dqzz_avertime);
printf("\n");
}
(本文仅供学习时参考,如有错误,纯属作者技术不到位,不足之处请多指教,谢谢)
版权归原作者 倦鸟馀生 所有, 如有侵权,请联系我们删除。