
写在前面
本小节主要说明了FlinkSQL在定义表时候的一些基本规则,其中包括:
1、Catalog为核心的临时表、永久表、视图的关系
2、Table对象和SQL定义表的方式
3、表定义过程中的schema、format、watermark、connector的基本使用方式
4、以kafka connector为例,详细说明了如何建表并获取元数据的过程
【这边并没有按照视频推导,而是按照官方文档自己一步步完成的,这个可以点个赞】
【遇到问题要学会看日志,无论是否为SQL,日志很重要】
难度本身不大,主要在于如何灵活运用,其实本质上在于对于官方文档的使用。
1、表的概述以及类别
- 表的表示结构 catalog name:元数据空间,常用于标识不同的“源”,比如hive catalog,inner catalog等;使得Flink里面创建的表hive中能查到,但是不一定可以取数,原因在于这里不同的“源”的定义在hive中没有,不一定可以查到。更多细节参考补充说明。 database name:通常语义中的“库” table name:通常语义中的“表”
- 表与视图 FlinkSQL中的表,可以是Virtual的(view视图)和regular的(table常规表) table描述了一个物理上的外部数据源,如文件、数据库表、kafka消息topic view则基于表创建,代表一个或多个表上的一段计算逻辑(就是对一段查询计划的逻辑封装) (不管是table还是view,在tableAPI中得到的都是table对象)
- 临时表与永久表 临时表(视图):创建时带temporary关键字(create temporary view,create temporary table);表 schema 只维护在所属 flink session 运行时内存中;当所属的 flink session 结束后表信息将不复存在;且该表无法在 flink session 间共享; 永久表(视图):创建时不带temporary关键字(create view,create table);表 schema 可记录在外部持久化的元数据管理器中(比如 hive 的 metastore);当所属 flink session 结束后,该表信息不会丢失;且在不同 flink session 中都可访问到该表的信息。注:永久表的元数据如果不持久化,也没有办法持久。
2、表的的定义概述
下面内容简单了解即可,本质上还是对建表API的使用,实际运用过程中注意Stream、Table、SQL之间的切换方式即可。
2.1、基于TableAPI创建[Table对象]
- 从已存在的表
Table table = tableEnv.from("test-table");//通过在env的catalog中注册的表名,获取Table对象//通过在env的catalog中注册的表名,获取Table对象
- 从 TableDescriptor(连接器/format/schema/options),本质上还是from方法
Table table = tableEnv.from(TableDescriptor.forConnector("kafka").schema(Schema.newBuilder().column("id",DataTypes.INT()).column("name",DataTypes.STRING()).column("age",DataTypes.INT()).column("gender",DataTypes.STRING()).build()).format("json").option("topic","testTopic").option("properties.bootstrap.servers","192.168.247.129:9092").option("properties.group.id","testGroup").option("scan.startup.mode","earliest-offset").option("json.fail-on-missing-field","false").option("json.ignore-parse-errors","true").build());
- 从 DataStream获取 这里 自动推断 schema(反射手段),如果需要自定义的话,看看
Schema的使用或许是一个很不错的选择,通过SQL创建的篇章里面给了一个简单的例子。
DataBean bean1 =newDataBean(1,"s1","e1","pg1",1000);DataBean bean2 =newDataBean(2,"s2","e3","pg1",1000);DataStreamSource<DataBean> dataStream1 = env.fromElements(bean1, bean2);
- 从 Table对象上的查询 api生成 通过 Table上调用查询 api,生成新的 Table对象(本质上就是 view)
Table table = table3.select($("guid"), $("uuid"));
- 从测试数据
Table table2 = tableEnv.fromValues(DataTypes.ROW(DataTypes.FIELD("id",DataTypes.INT()),DataTypes.FIELD("name",DataTypes.STRING())),Row.of(1,"jack"));
2.2、基于TableSQL创建[不返回Table对象]
- 从已存在的dataStream注册
tableEnv.createTemporaryView("t1",table2);
- 从已存在的Table对象注册
tableEnv.createTemporaryView("t1",table2);
- 从TableDescriptor(连接器)注册
DataBean bean1 =newDataBean(1,"s1","e1","pg1",1000);DataBean bean2 =newDataBean(1,"s1","e1","pg1",1000);DataStreamSource<DataBean> dataStream1 = tableEnv.fromElements(bean1, bean2);Schema schema =Schema.Builder.column...build();
tenv.createTemporaryView("t1",dataStream1,schema);
- 通过Connector注册
tenv.createTable("t1",TableDescriptor.forConnector("filesystem").option("path","file:///d:/a.txt").format("csv").schema(Schema.newBuilder().column("guid",DataTypes.STRING()).column("name",DataTypes.STRING()).column("age",DataTypes.STRING()).build()).build());
- 执行SQL的DDL语句注册
tableEnv.executeSql(" CREATE TABLE KafkaTable ( "+" `user_id` BIGINT, "+" `item_id` BIGINT, "+" `behavior` STRING, "+" `ts` TIMESTAMP(3) METADATA FROM 'timestamp' "+" ) WITH ( "+" 'connector' = 'kafka', "+" 'topic' = 'user_behavior', "+" 'properties.bootstrap.servers' = 'localhost:9092', "+" 'properties.group.id' = 'testGroup', "+" 'scan.startup.mode' = 'earliest-offset', "+" 'format' = 'csv' "+" ) ");
3、catalog详解
3.1、什么是catalog
一句话:catalog就是一个元数据空间,简单说就是记录、获取元数据(表定义信息)的实体;
flinkSQL在运行时,可以拥有多个catalog,它们由catalogManager模块来注册、管理;
CatalogManager中可以注册多个元数据空间;
flinkSQL环境创建之初,就会初始化一个默认的元数据空间
空间名称:default_catalog
空间实现类:GenericInMemoryCatalog,默认的元数据空间对象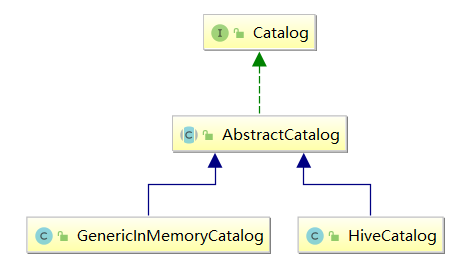
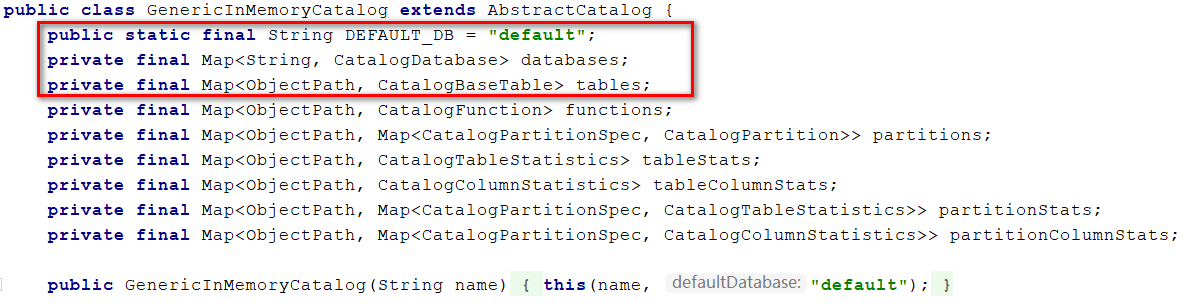
元数据空间管理对象:CatalogManager
①:用于记录Session中所有的Catalog
②:初始化一个默认的Catalog
③:初始化用于记录Session中注册的临时表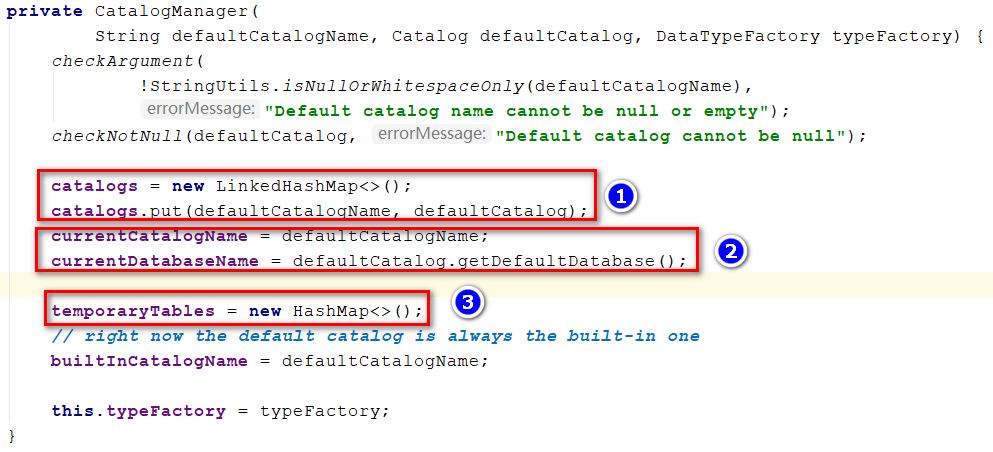
3.2、深入测试catalog
- 注册一个HiveCatalog
// 创建一个hive元数据空间的实现对象HiveCatalog hiveCatalog =newHiveCatalog("hive","default","conf");// 将hive元数据空间对象注册到环境中
tableEnv.registerCatalog("myHiveCatalog",hiveCatalog);
- 尝试分别在不同的Catalog中创建表、视图、临时表
//1、尝试在HiveCatalog中建表
tableEnv.executeSql("CREATE TABLE IF NOT EXISTS myHiveCatalog.`default`.t_kafka (...)");//2、默认在DefaultCatalog中建表
tableEnv.executeSql("CREATE TABLE t_kafka2 (...) ");//3、在HiveCatalog中创建视图
tableEnv.executeSql("CREATE VIEW IF NOT EXISTS myHiveCatalog.`default`.t_kafka_view ...");//4、创建临时表,指定HiveCatalog
tableEnv.executeSql("create temporary table myHiveCatalog.`default`.test_temporary_hive...");
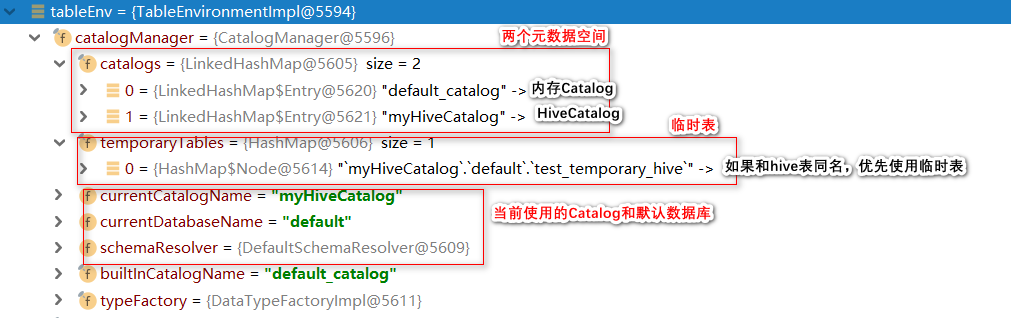
- 查看CatalogManager,得到Catalog的结果,临时表单独存在在temporaryTables
3.3、临时表与永久表的底层差异
结论1:如果使用hive元数据空间窗口表、视图,则:
- 永久表(视图)的元信息,都会被写入 hive的元数据管理器中,从而可以实现永久存在
- 临时表(视图)的元信息,并不会写入 hive的元数据管理其中,而是放在 catalogManager的一个 temporaryTables的内存 hashmap中记录
- 临时表空间中的表名(全名)如果与 hive空间中的表名相同,则查询时会优先选择临时表空间的表
结论 2:如果选择 GenericInMemoryCatalog元数据空间来创建表、视图,则:
- 永久表(视图)的元信息,都会被写入 GenericInMemoryCatalog的元数据管理器中(内存中)
- 临时表(视图)的元信息,放在 catalogManager的一个 temporaryTables的内存 hashmap中记录
- 无论永久还是临时,当 flink的运行 session结束后,所创建的表(永久、临时)都将不复存在
3.4、如何理解hive catalog
注:本质区别,这也说明之前为啥有的时候进行查询的时候需要切换查询引擎
flinksql利用 hive catalog来建表(查询、修改、删除表),本质上只是利用了 hive的 metastore服务;
更具体来说,flinksql只是把 flinksql的表定义信息,按照 hive元数据的形式,托管到 hive的 metastore中而已!
当然,hive中也能看到这些托管的表信息,但是,并不能利用它底层的 mapreduce或者 spark引擎来查询这些表;
因为 mapreduce或者 spark引擎,并不能理解 flinksql表定义中的信息,也无法为这些定义信息提供相应的组件去读取数据(比如,mr或者 spark就没有 flinksql中的各种 connector组件)
4、表定义详解
4.1、schema字段定义详解
- physical column,物理字段:源自于“外部存储”系统本身 schema中的字段 如 kafka消息的 key、value(json格式)中的字段;mysql表中的字段;hive表中的字段;parquet文件中的字段……
- computed column,表达式字段(逻辑字段):在物理字段上施加一个 sql表达式,并将表达式结果定义为一个字段
- metadata column,
元数据字段:来源于 connector从外部存储系统中获取到的“外部系统元信息”。比如,kafka的消息,通常意义上的数据内容是在 record的 key和 value中的,而实质上(底层角度来看),kafka中的每一条 record,不光带了 key和 value数据内容,还带了这条 record所属的 topic,所属的 partition,所在的 offset,以及 record的 timetamp和 timestamp类型等“元信息”,而 flink的 connector可以获取并暴露这些元信息,并允许用户将这些信息定义成 flinksql表中的字段; - 主键约束:flinkSQL本身也支持主键约束,这个目前没有用到,感觉应该可以类别Mysql的主键约束理解。
4.2、format组件
connector连接器在对接外部存储时,根据外部存储中的数据格式不同,需要用到不同的 format组件;
format组件的作用就是:告诉连接器,如何解析外部存储中的数据及映射到表 schema
这里列举常见的两种format
json
- flink官网文档:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/table/formats/json/
- 假定有如下的json格式的数据:
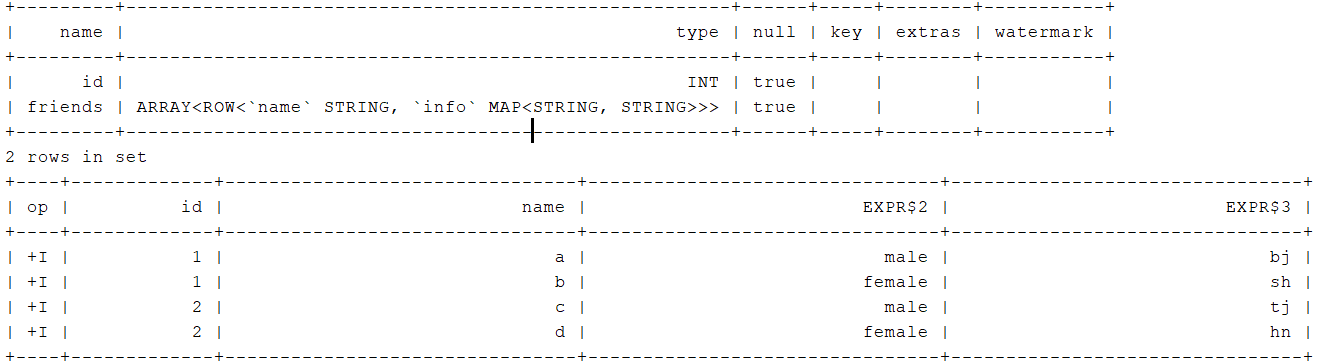
{"id":1,"friends":[{"name":"a","info":{"addr":"bj","gender":"male"}},{"name":"b","info":{"addr":"sh","gender":"female"}}]} - flinkSQL语句
tableEnvironment.executeSql(" CREATE TABLE t_json( "+" id INT, "+" friends ARRAY<ROW<name STRING,info MAP<STRING,STRING>>> "+" "+" )WITH( "+" 'connector' = 'filesystem', "+" 'path' = 'input/json', "+" 'format' = 'json' "+" ) ");
tableEnvironment.executeSql("DESC t_json").print();
tableEnvironment.executeSql(" SELECT id "+" , friend.name "+" , friend.info['gender'] "+" , friend.info['addr'] "+" FROM t_json, "+" UNNEST(friends) AS friend ").print();
- 控制台输出
csv
- flink官网文档:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/table/formats/csv/
- 假定数据格式如下:
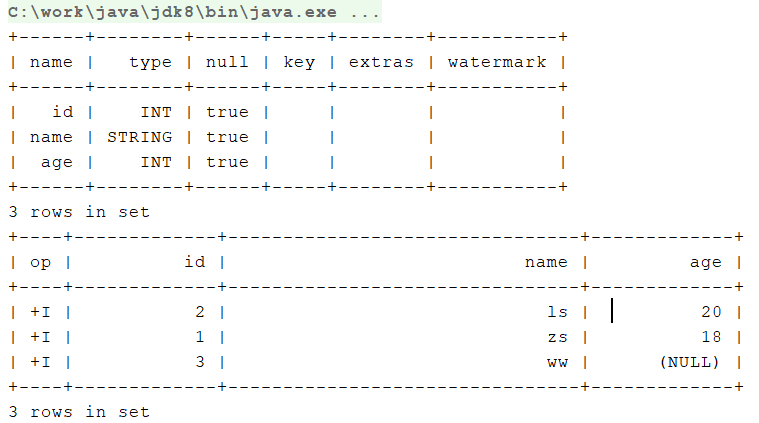
|1|,|zs|,|18|``````#哈哈哈哈``````|2|,|ls|,|20|``````|3|,|ww|,\N - flinkSQL语句
tableEnvironment.executeSql(" CREATE TABLE t_csv ( "+" id INT, "+" name STRING, "+" age INT "+" "+" )WITH( "+" 'connector' = 'filesystem', "+" 'path' = 'input/csv', "+" 'format' = 'csv', "+" 'csv.quote-character' = '|', "+" 'csv.ignore-parse-errors' = 'true', "+" 'csv.allow-comments' = 'true', "+" 'csv.null-literal' = '\\N', "+" 'format' = 'csv' "+" ) ");
tableEnvironment.executeSql("DESC t_csv").print();
tableEnvironment.executeSql(" SELECT id "+" , name "+" , age "+" FROM t_csv ").print();
- 控制台输出
4.3、 watermark与time属性详解
时间属性定义,主要是用于各类基于时间的运算操作(如基于时间窗口的查询计算)
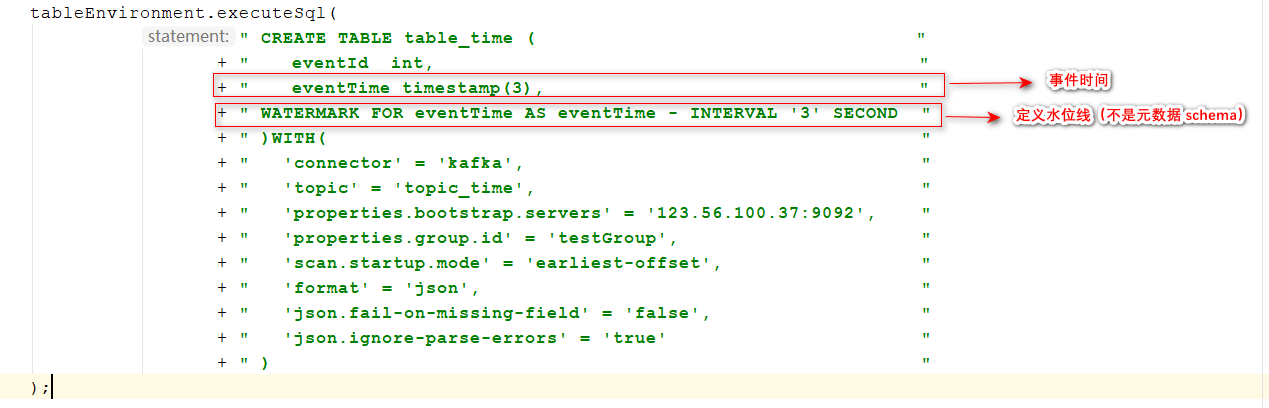
4.3.1、定义水位线
- 表定义 注:这里的时间类型必须为Timestamp
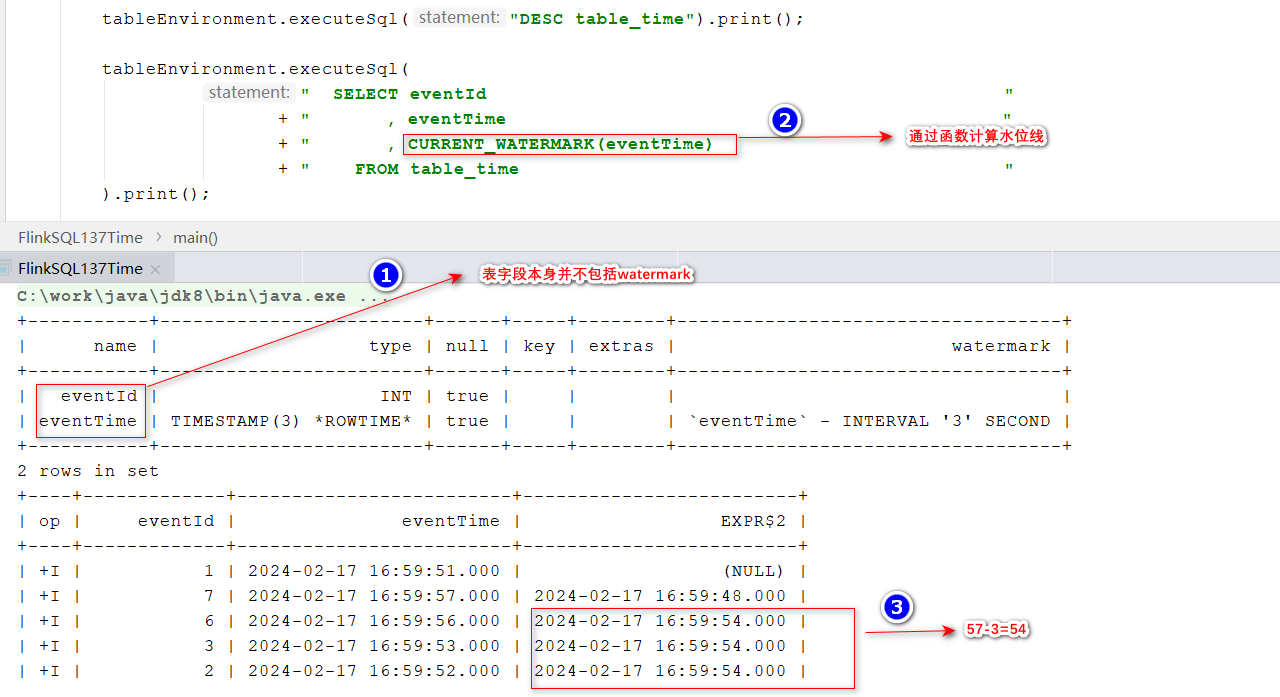
- 查询结果
4.3.2、表与流之间 WaterMark
WaterMark和转换之前的WaterMark计算规则保持一致
- 流转表 流转表的过程中,无论“源流”是否存在 watermark,都不会自动传递 watermark 如需时间运算(如时间窗口等),
需要在转换定义中显式声明 watermark策略1. 先设法定义一个 timestamp(3)或者 timestamp_ltz(3)类型的字段(可以来自于数据字段,也可以来自于一个元数据: rowtime 2. 然后基于该字段,用 watermarkExpression声明 watermark策略
2. 然后基于该字段,用 watermarkExpression声明 watermark策略
- 表转流
前提:源表定义了 wartermark策略;则将表转成流时,将会自动传递源表的 watermark;
4.4、connector详解
connector常是用于对接外部存储建表(源表或目标表)时的映射器、桥接器;
connector本质上是对 flink的 table source /table sink算子的封装;
参考链接:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/connectors/table/overview/
连机器使用的核心要素:
- 导入连接器 jar包依赖
- 指定连接器类型名
- 指定连接器所需的参数(不同连接器有不同的参数配置),如:format
- 获取连接器所提供的元数据,如:schema
Flink支持的连接器有很多种,包括:Filesystem、Elasticsearch、MongoDB、Apache Kafka、Apache HBase…
以kafka连接器举例说明其在FlinkSQL中的过程:
- 可以获取的元数据

- 假定kafka中存在如下数据
// 创建生产者实例Producer<String,String> producer =newKafkaProducer(props);// 创建消息,并添加头部信息ProducerRecord<String,String> record =newProducerRecord("connector_test","{\"k1\":13,\"k2\":23}","{\"k1\":\"value_1\",\"k2\":\"value_2\",\"eventID\":\"002\",\"eventTime\":1708759402246}");
record.headers().add("head1","headValue1".getBytes());// 发送消息
producer.send(record);System.out.println(record);// 关闭生产者
producer.close();
存在的问题:
- kafka的消息中有 json格式的 key(key内容需要映射到表 schema中)
- kafka的消息中有 json格式的 value(value内容需要映射到表 schema中)
- key和 value的 json数据内容中还有同名的字段
- kafka的消息中有 header(header内容需要映射到表 schema中)
- 创建FlinkSQL表 不带key开头的format默认只对value生效:

CREATETABLE KafkaSourceTable (`meta_time`TIMESTAMP(3) METADATA FROM'timestamp',`partition`BIGINT METADATA VIRTUAL,`offset`BIGINT METADATA VIRTUAL,`headers` MAP<STRING,BYTES> METADATA FROM'headers'`inKey_k1` STRING,`inKey_k2` STRING,`k1` STRING,`K2` STRING,`eventTime`BIGINT,`eventID`BIGINT)WITH('connector'='kafka','topic'='connector_test','properties.bootstrap.servers'='123.56.100.37:9092','properties.group.id'='testGroup','scan.startup.mode'='earliest-offset','format'='json','json.ignore-parse-errors'='true','json.fail-on-missing-field'='true','key.fields'='inKey_k1;inKey_k2','key.fields-prefix'='inKey_','value.fields-include'='EXCEPT_KEY');
- 执行结果
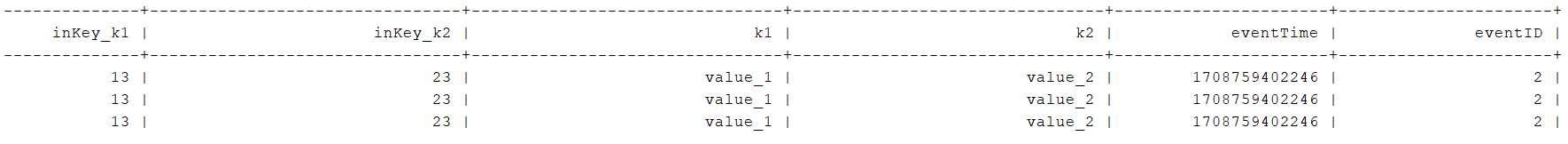
版权归原作者 星星点灯1966 所有, 如有侵权,请联系我们删除。