
一、前言
使用 FastAPI 可以帮助我们更简单高效地部署 AI 交互业务。FastAPI 提供了快速构建 API 的能力,开发者可以轻松地定义模型需要的输入和输出格式,并编写好相应的业务逻辑。
FastAPI 的异步高性能架构,可以有效支持大量并发的预测请求,为用户提供流畅的交互体验。此外,FastAPI 还提供了容器化部署能力,开发者可以轻松打包 AI 模型为 Docker 镜像,实现跨环境的部署和扩展。
总之,使用 FastAPI 可以大大提高 AI 应用程序的开发效率和用户体验,为 AI 模型的部署和交互提供全方位的支持。
在上一篇开源模型应用落地-FastAPI-助力模型交互-WebSocket篇(三)-CSDN博客学习了FastAPI集成LangChain与openai的api服务进行交互,本篇学习如何*如何通过FastAPI与本地部署的qwen2-7b-instruct模型进行交互*
二、术语
2.1. vLLM
vLLM是一个开源的大模型推理加速框架,通过PagedAttention高效地管理attention中缓存的张量,实现了比HuggingFace Transformers高14-24倍的吞吐量。
2.2. OpenAI-Compatible Server
遵循 OpenAI API 的接口规范,让开发者可以使用OpenAI API相同的方式和方法来调用这些服务,从而利用它们的语言模型功能。
2.3. Qwen2-7B-Instruct
是通义千问 Qwen2 系列中的一个指令微调模型。它在 Qwen2-7B 的基础上进行了指令微调,以提高模型在特定任务上的性能。
Qwen2-7B-Instruct 具有以下特点:
- 强大的性能:在多个基准测试中,Qwen2-7B-Instruct 的性能可与 Llama-3-70B-Instruct 相匹敌。
- 代码和数学能力提升:得益于高质量的数据和指令微调,Qwen2-7B-Instruct 在数学和代码能力上实现了飞升。
- 多语言能力:模型训练过程中增加了 27 种语言相关的高质量数据,提升了多语言能力。
- 上下文长度支持:Qwen2 系列中的所有 Instruct 模型均在 32k 上下文中进行训练,Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 还支持最高可达 128k token 的上下文长度。
2.4. context length
模型的上下文长度是指在生成文本时,模型所能看到的输入文本的长度范围。在生成文本的过程中,模型会根据前面的上下文来预测下一个词或字符。上下文长度决定了模型能够考虑到的历史信息的数量。
2.5. system prompt(系统提示)
是指在生成对话或文本的任务中,为了引导模型产生合适的响应或输出,对模型进行输入的开头部分或系统提供的指令。系统提示通常包含一些关键信息,如对话的背景、任务的要求或期望的回答风格等,以帮助模型理解上下文并生成相关的响应。通过精心设计和调整系统提示,可以引导模型产生更准确、连贯且符合预期的输出。
2.6. temperature(温度)
是用于控制生成模型输出的多样性和随机性的一个参数。当温度较高时,模型会更加随机地选择输出,使得生成结果更加多样化和创造性,但可能会牺牲一些准确性和一致性。相反,当温度较低时,模型会更加确定性地选择输出,使得生成结果更加集中和可控。较低的温度值会使概率分布更尖峰,使得高概率的词或标记更容易被选中。
2.7. top_p
是一种用于控制生成模型输出的参数。在生成文本或对话的任务中,模型通常会输出一个概率分布,表示每个可能的词或标记的概率。top_p参数用于指定一个概率的阈值,模型将从概率累积最高的词开始逐步选择,直到累积概率超过阈值为止。通过设置top_p参数,我们可以控制生成模型输出的多样性和可控性。较小的top_p值会限制模型选择的候选词的数量,使得模型的输出更加集中和可控。较大的top_p值会增加模型选择的候选词的数量,使得模型的输出更加多样化和创造性。
2.8. repetition_penalty
是一种用于控制生成模型输出中重复内容的参数。在生成文本或对话的任务中,模型有时候可能会倾向于产生重复的词语、短语或句子,导致生成结果的质量下降或显得不够自然。为了解决这个问题,可以使用重复惩罚机制。重复惩罚参数可以调整模型对已经生成过的内容的偏好程度。较高的重复惩罚值会使模型更加抑制生成已经出现过的内容,以鼓励生成更多新颖的内容。较低的重复惩罚值则会相对宽容,允许模型生成一定程度的重复内容。
2.9. history
"历史上下文"是指在处理当前文本或对话时,与之前的文本或对话相关的信息和语境。历史上下文包括了之前的句子、段落或对话中的内容,以及前文中提到的实体、事件和语义关系等。它提供了理解当前文本的重要背景信息,帮助我们更准确地解释和推断文本的含义。处理历史上下文时,模型需要能够捕捉并记忆之前的信息,并将其与当前文本进行关联,以产生有意义的输出。
2.10.流式输出
是模型推理过程中逐步生成输出结果,而非一次性生成整个输出,从而实现更低的延迟和更好的实时性。
三、前置条件
3.1. 创建虚拟环境&安装依赖
增加openai的依赖包
conda create -n fastapi_test python=3.10
conda activate fastapi_test
pip install fastapi websockets uvicorn
pip install openai
3.2. 创建本地AI服务
开源模型应用落地-Qwen2-7B-Instruct与vllm实现推理加速的正确姿势(十)
四、技术实现
4.1. 集成本地构建的AI服务
服务端:
# -*- coding:utf-8 -*-
import traceback
import uvicorn
from typing import Annotated
from fastapi import (
Depends,
FastAPI,
WebSocket,
WebSocketException,
WebSocketDisconnect,
status,
)
from openai import OpenAI
DEFAULT_IP='127.0.0.1'
DEFAULT_PORT=9000
DEFAULT_MODEL = "/model/qwen2-7b-instruct"
DEFAULT_MAX_TOKENS = 10240
DEFAULT_SYSTEM_PROMPT = '你是一位得力的助手。'
openai_api_key = "EMPTY"
openai_api_base = f"http://{DEFAULT_IP}:{DEFAULT_PORT}/v1"
class ConnectionManager:
def __init__(self):
self.active_connections: list[WebSocket] = []
async def connect(self, websocket: WebSocket):
await websocket.accept()
self.active_connections.append(websocket)
def disconnect(self, websocket: WebSocket):
self.active_connections.remove(websocket)
async def send_personal_message(self, message: str, websocket: WebSocket):
await websocket.send_text(message)
async def broadcast(self, message: str):
for connection in self.active_connections:
await connection.send_text(message)
manager = ConnectionManager()
app = FastAPI()
async def authenticate(
websocket: WebSocket,
userid: str,
secret: str,
):
if userid is None or secret is None:
raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION)
print(f'userid: {userid},secret: {secret}')
if '12345' == userid and 'xxxxxxxxxxxxxxxxxxxxxxxxxx' == secret:
return 'pass'
else:
return 'fail'
async def chat(message, history=None, system=None, config=None, stream=True):
global client
if config is None:
config = {'temperature': 0.45, 'top_p': 0.9, 'repetition_penalty': 1.2, 'max_tokens': DEFAULT_MAX_TOKENS,'n':1}
size = 0
messages = []
if system is not None:
messages.append({"role": "system", "content": system})
size = size+len(system)
if history is not None:
if len(history) > 0:
for his in history:
user,assistant = his
user_obj = {"role": "user", "content": user}
assistant_obj = {"role": "assistant", "content": assistant}
messages.append(user_obj)
messages.append(assistant_obj)
size = size + len(user)
size = size + len(assistant)
if message is None:
raise RuntimeError("prompt不能为空!")
else:
messages.append({"role": "user", "content": message})
size = size + len(message)+100
try:
chat_response = client.chat.completions.create(
model=DEFAULT_MODEL,
messages=messages,
stream=stream,
temperature=config['temperature'],
top_p=config['top_p'],
max_tokens=config['max_tokens']-size,
frequency_penalty=config['repetition_penalty'],
# presence_penalty=config['repetition_penalty']
)
for chunk in chat_response:
msg = chunk.choices[0].delta.content
if msg is not None:
yield msg
except Exception:
traceback.print_exc()
@app.websocket("/ws")
async def websocket_endpoint(*,websocket: WebSocket,userid: str,permission: Annotated[str, Depends(authenticate)],):
await manager.connect(websocket)
try:
while True:
text = await websocket.receive_text()
if 'fail' == permission:
await manager.send_personal_message(
f"authentication failed", websocket
)
else:
if text is not None and len(text) > 0:
async for msg in chat(text,None,DEFAULT_SYSTEM_PROMPT,None):
await manager.send_personal_message(msg, websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)
print(f"Client #{userid} left the chat")
await manager.broadcast(f"Client #{userid} left the chat")
if __name__ == '__main__':
client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)
uvicorn.run(app, host='0.0.0.0',port=7777)
客户端:
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>USERID: <input type="text" id="userid" autocomplete="off" value="12345"/></label>
<label>SECRET: <input type="text" id="secret" autocomplete="off" value="xxxxxxxxxxxxxxxxxxxxxxxxxx"/></label>
<br/>
<button onclick="connect(event)">Connect</button>
<hr>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
var userid = document.getElementById("userid")
var secret = document.getElementById("secret")
ws = new WebSocket("ws://localhost:7777/ws?userid="+userid.value+"&secret=" + secret.value);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
event.preventDefault()
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
调用结果:
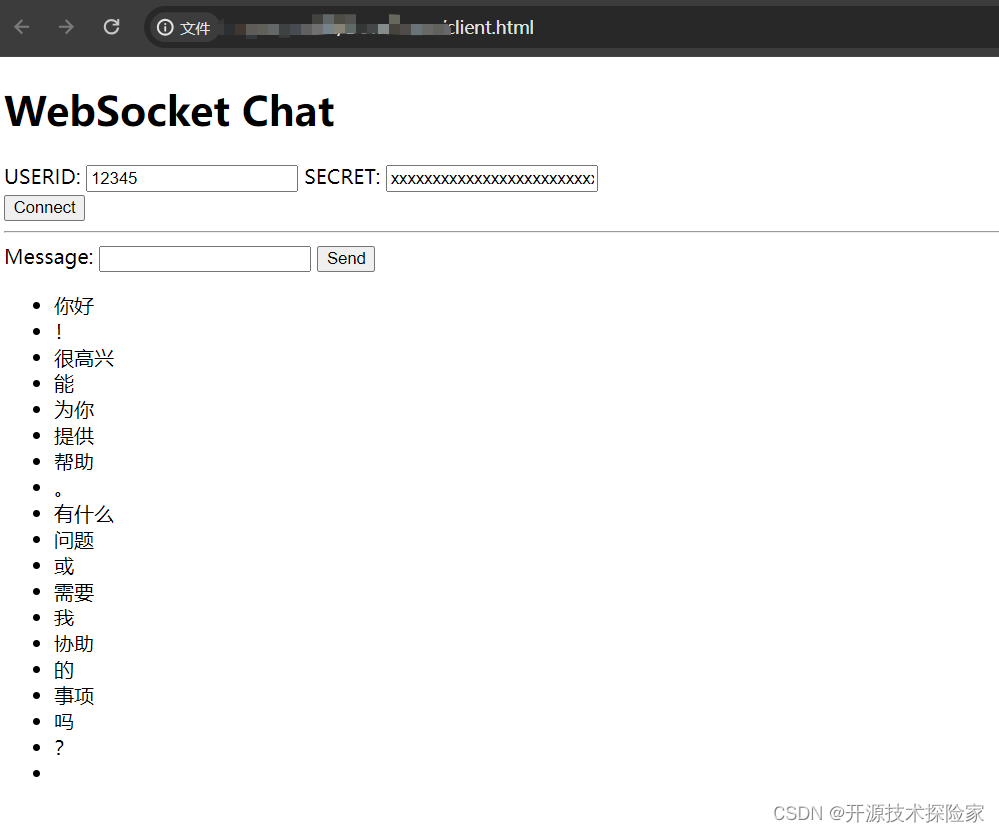
用户输入:你好
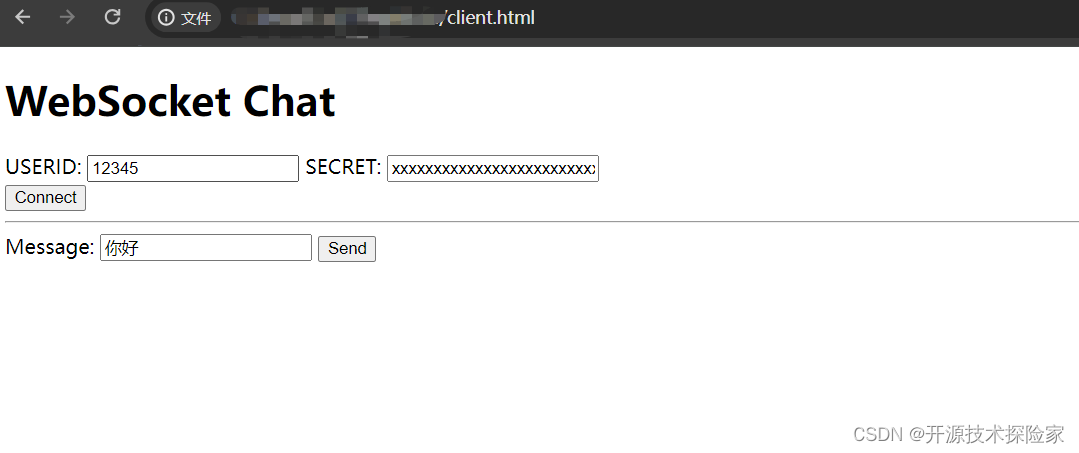
模型输出:你好!很高兴能为你提供帮助。有什么问题或需要我协助的事项吗?
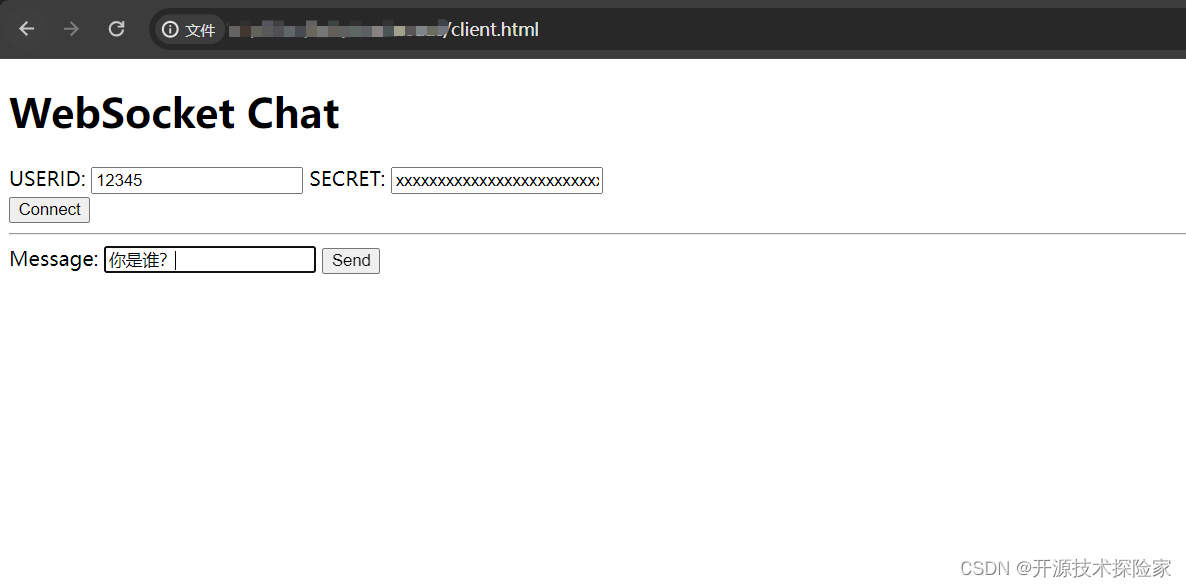
用户输入:你是谁?
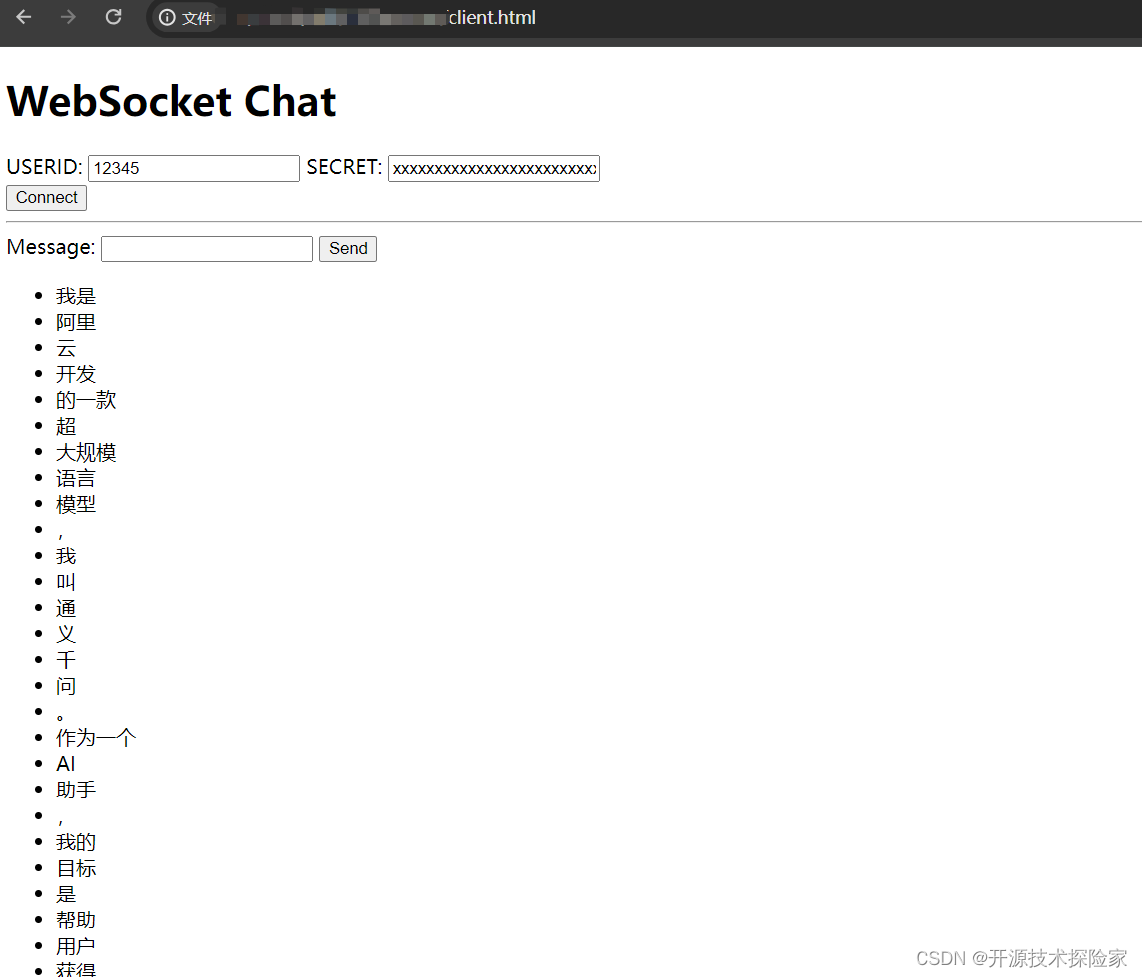
模型输出:我是阿里云开发的一款超大规模语言模型,我叫通义千问。作为一个AI助手,我的目标是帮助用户获得准确、有用的信息,解决他们的问题和困惑。无论是提供知识解答、创意启发,还是进行对话交流,我都将全力以赴提供高质量的服务。
PS:
此处服务端采用OpenAI-Compatible Server,非唯一实现方式
页面输出的样式可以根据实际需要进行调整,此处仅用于演示效果。
本文转载自: https://blog.csdn.net/qq839019311/article/details/140041882
版权归原作者 开源技术探险家 所有, 如有侵权,请联系我们删除。
版权归原作者 开源技术探险家 所有, 如有侵权,请联系我们删除。