
一、创建虚拟机
1.选择自定义创建
2.选择稍后安装系统
3.处理器数量2,单个处理器内核4个
4.分配内存量4g
5.新建虚拟磁盘:master40g,slave20g
4..其余选项按默认确定
二、安装选项页面
1.软件安装选择最小安装
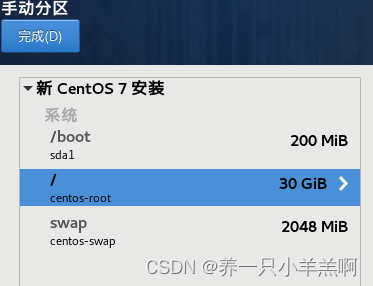
2.安装位置选择我要配置分区(/目录尽量大)
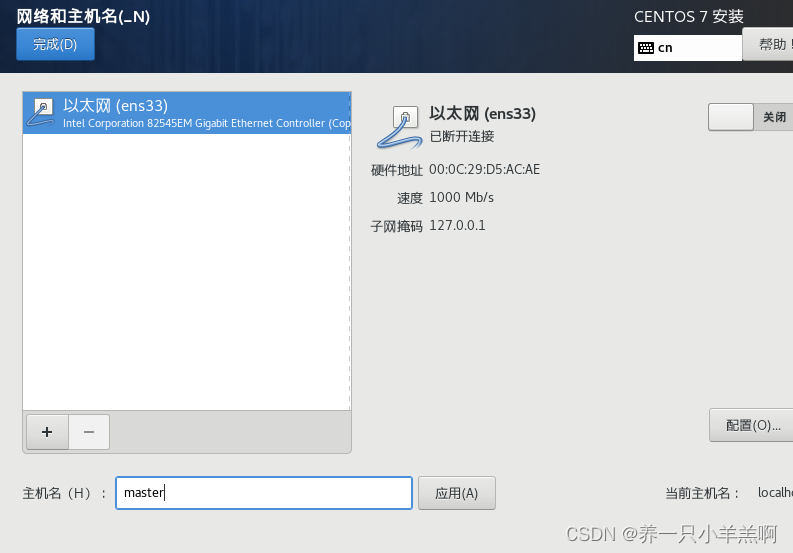
3.更改主机名
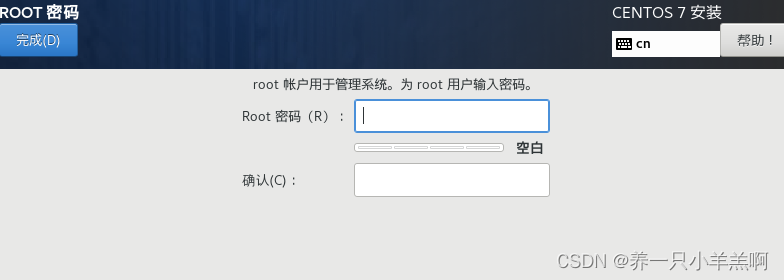
4.设置root密码(建议学习者设置123456)
三、克隆主机
Hadoop平台的搭建需要一个主节点,多个副节点。在centos7中创建主机Master后,克隆主机为slave1与slave2,为保证从Hadoop平台的稳定选择完整克隆。

四、修改节点名
克隆机slave1、slave2后的主机名依旧是Master,所以要修改主机名。
以root用户执行hostnamectl命令。重启生效(reboot)
hostnamectl set-hostname slave1
五、配置静态ip
主机ip默认为动态,为保持Hadoop平台稳定故使用静态ip。
以root用户修改网卡配置文件,所在路径为 /etc/sysconfig/network-scripts
使用vi编辑器打开ifcfg-ens32文件
vi /etc/sysconfig/network-scripts/ifcfg-ens32
改动如下:
修改:
(网络状态)BOOTPROT="static"
(启动) ONBOOT=YES
添加:
(ip地址) IPADDR=(与原IP为同一网段)
(子网掩码)NETMASK=255.255.255.0 0主机地址
(网关) GATEWAY=(与原IP为同一网段,桥接为1,net为2)
(域名) DNS1=(与网关一致)
DNS2=8.8.8.8
重启网络
systemctl restart network
六、关闭防火墙
在后续的工作中需要以Master控制slave1,slave2两台机器需要关闭防火墙进行操控
查看防火墙,此时Active为active状态(开启状态)
systemctl status firewalld.service
关闭防火墙确保Active为dead状态(关闭状态)
Active: inactive (dead)
关闭防火墙前一定要先停止防火墙
systemctl stop firewalld.service
关闭防火墙
systemctl disable firewalld.service
七、连接远程操控软件
为方便对Hadoop平台的操控,故连接远程操控软件。(这里以mobaXterm为示例)
点击session
点击SSH,输入slave的ip,选中用户输入root
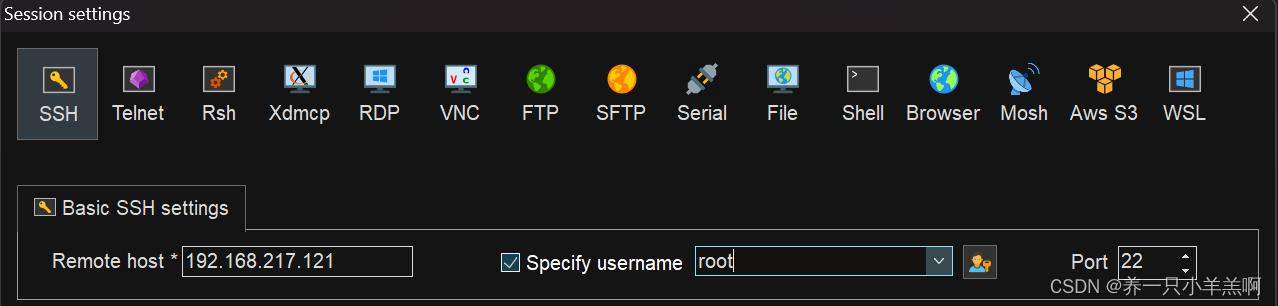
输入用户密码,连接成功

八、更改UUID
由于slave1为Master的克隆机故uuid号与Master一致,需要更改
输入uuidgen获取新的uuid号
[root@slave1 ~]# uuidgen
894525cf-6edc-41bb-a185-8fd6b88f46f7
使用vi编辑器替换uuid
vi /etc/sysconfig/network-scripts/ifcfg-ens32
九、ip地址和主机名映射
为方便远程连接设置映射
打开master使用root修改映射文件,所在地址为 /etc
使用vi编辑器打开hosts文件,删除文件原有内容,添加内容如下
192.xxx.xxx.xxx master
192.xxx.xxx.xxx slave1
192.xxx.xxx.xxx slave2
注:master,slave1,slave2同样操作
十、免密登入
密钥获取
ssh-keygen
使用copy命令将密钥拷贝到其他主机与本机中实现免密登录
ssh-copy-id master
注:master,slave1,slave2同样操作
十一、配置jdk环境
使用mkdir命令选择-p属性递归创建文件
/opt/software 用来存放安装包的压缩包
mkdir -p /opt/software
/opt/module用来存放解压后的软件
mkdir -p /opt/module
1.上传安装包于/opt/software 目录下
2.解压到指定的目录下
**3.tar -C的作用是切换到解压文件的目录**
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module/
tar -zxvf hadoop-3.1.4.tar.gz -C /opt/module/
3.环境变量的配置S
vi /etc/profile.d/my_env.sh
使用export调出
#新建系统变量
JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0 161
再将JAVA_HOME引用到path环境变量中export PATH=$JAVA_HOME/bin:$PATH
4.生效环境变量的配置:
source /etc/profile
5.验证环境是否安装成功
java -version
出现以下内容证明安装成功

十二、移除NetworkManager
1.查看NetworkManager服务状态
systemctl status NetworkManager
2.停止NetworkManager服务
systemctl stop NetworkManager
3.移除NetworkManager服务
systemctl disable NetworkManager
十三、配置Hadoop环境变量
1.使用cd命令进入hadoop-3.1.4目录
cd /opt/module/hadoop-3.1.4
2.使用pwd命令打印当前工作目录的路径,并复制打印结果。在增添hadoop环境变量时使用。
3.使用vi命令编辑环境变量文件(前提是确保文件的绝对路径正确)
vi /etc/profile.d/my_env.sh
4.添加以下内容
#hadoop环境变量
export HADOOP_HOME=/opt/module/hadoop-3.1.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
** export HADOOP_HOME=(将刚才复制的打印结果粘贴到此处)**
5.生效环境变量的配置
source /etc/profile
6.验证环境是否安装成功
hadoop version
出现以下内容证明安装成功

7.将配置文件拷贝到其他节点机中
使用scp命令选择-r属性将/etc/profile.d目录下的my_eny.sh文件拷贝到其他节点机中
scp -r /etc/profile/my_eny.sh slave:/etc/profile/my_eny.sh
十四、集群配置文件
hdfs分布式文件系统namenode datanodeMapReduce分布式计算框架yarn资源调度管理平台esourcemanager nodemanagersecondarynamenode
节点配置
master slave1 slave2 namenode datanode datanode datanode resourcemanager nodemanager nodemanager odemanager secondarynamenode 配置文件 功能描述hadoop.env.sh 配置Hadoop运行所需的环境变量 yarn.env.sh 配置yarn运行所需的环境变量 core-site.xml Hadoop核心全局配置文件,可以在其他配置 文件中引用此文件 hdfs-site.xml HDFS配置文件,继承core-site.xml配置文件
mapred- site.xml
MapReduce配置文件,继承core-site.xml配置文件 yarn-site.xml yarn配置文件,继承core-site.xml配置文件
1.修改core-site.xml文件
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.4/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
2.修改hdfs-site.xml文件
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
3.修改mapred-site.xml文件
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
4.修改yarn-site.xml文件
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
5.修改workers文件
master
slave1
slave2
6.修改环境变量相关设置
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
文件系统的格式化:
hadoop namenode -format
启动hdfs
start-dfs.sh
本文转载自: https://blog.csdn.net/2301_80640837/article/details/136716614
版权归原作者 养一只小羊羔啊 所有, 如有侵权,请联系我们删除。
版权归原作者 养一只小羊羔啊 所有, 如有侵权,请联系我们删除。