
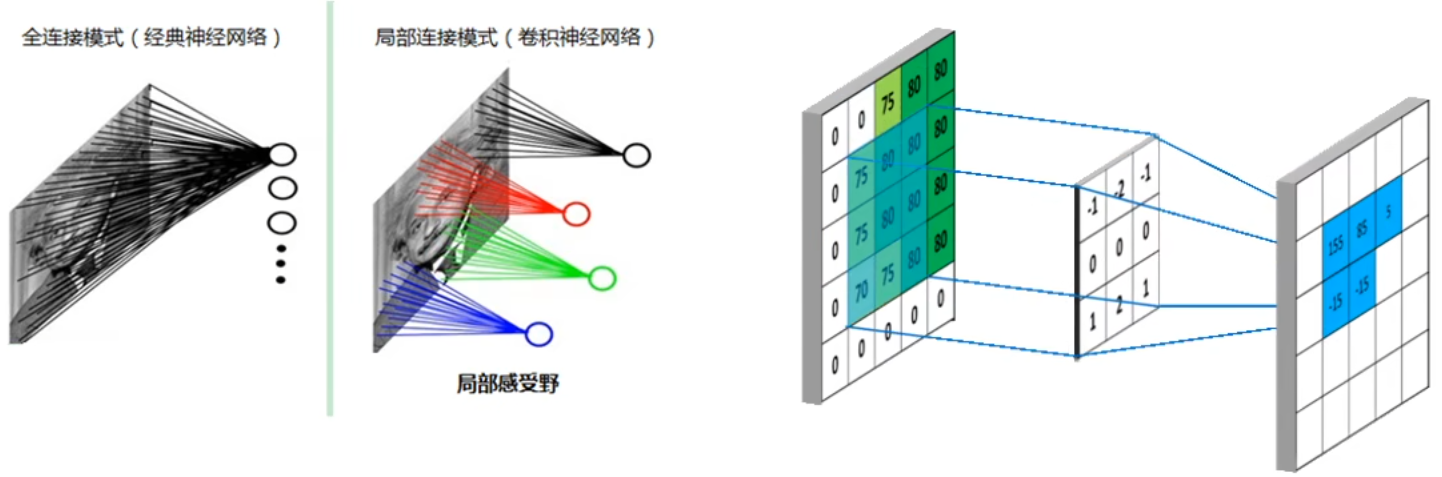
一般的DNN直接将全部信息拉成一维进行全连接,会丢失图像的位置等信息。
CNN(卷积神经网络)更适合计算机视觉领域。下面总结从1998年至今的优秀CNN模型,包括LeNet、AlexNet、ZFNet、VGG、GoogLeNet、ResNet、DenseNet、SENet、SqueezeNet、MobileNet。在了解巨佬们的智慧结晶,学习算法上的思路和技巧,便于我们自己构建模型,也便于我们做迁移学习。
在观看了斯坦福的CS231n课程视频和同济子豪兄的视频后很有感悟,但在csdn发现没有类似详细的总结,希望帮到一些小白,搭配子豪兄的视频食用更佳哦。
- 卷积可以 提取原图中符合卷积核特征的特征,赋予神经网络 局部感受野,权值共享(卷积核是共享的)。
- 池化(下采样)目的是 减少参数量、防止过拟合、平移不变性(原图像平移不改变模型判断结果)
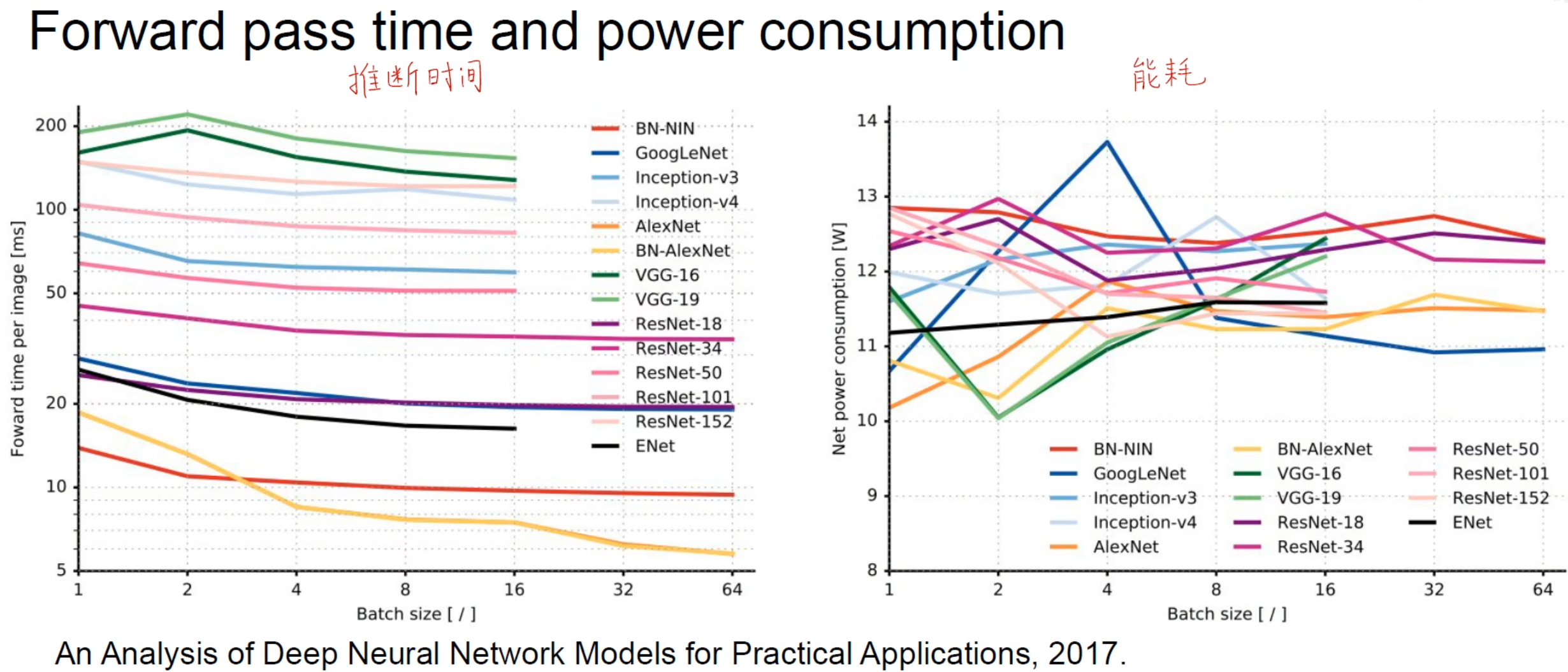
模型总结的主线以历年ImageNet竞赛的优秀模型为主。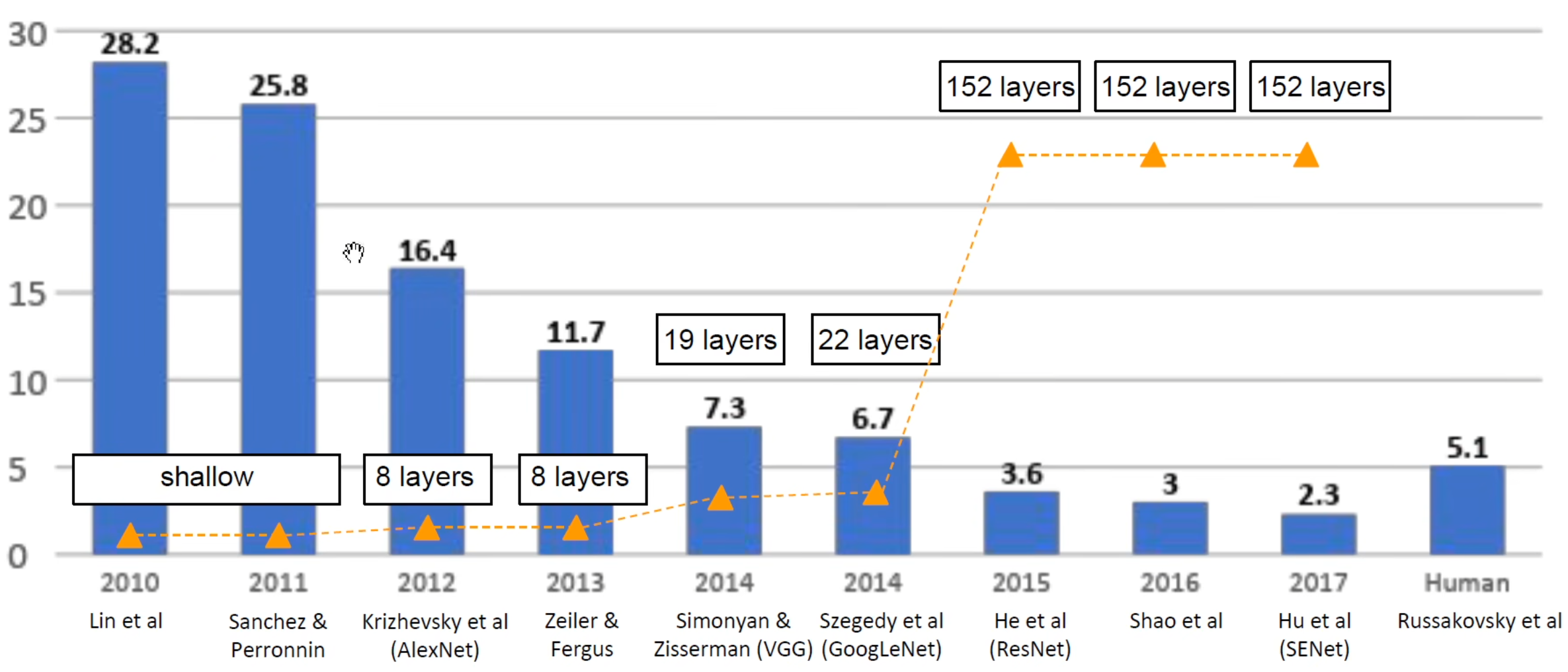
想高效入门深度学习的童鞋可以康康这篇哦:
《一文极速理解深度学习》
其中一些经典模型的代码实现可以康康这篇!
《经典卷积神经网络Python,TensorFlow全代码实现》
目录
LeNet
1998年提出的模型,为了识别手写数字。7层CNN,网络结构就是 卷积池化+卷积池化+3层全连接
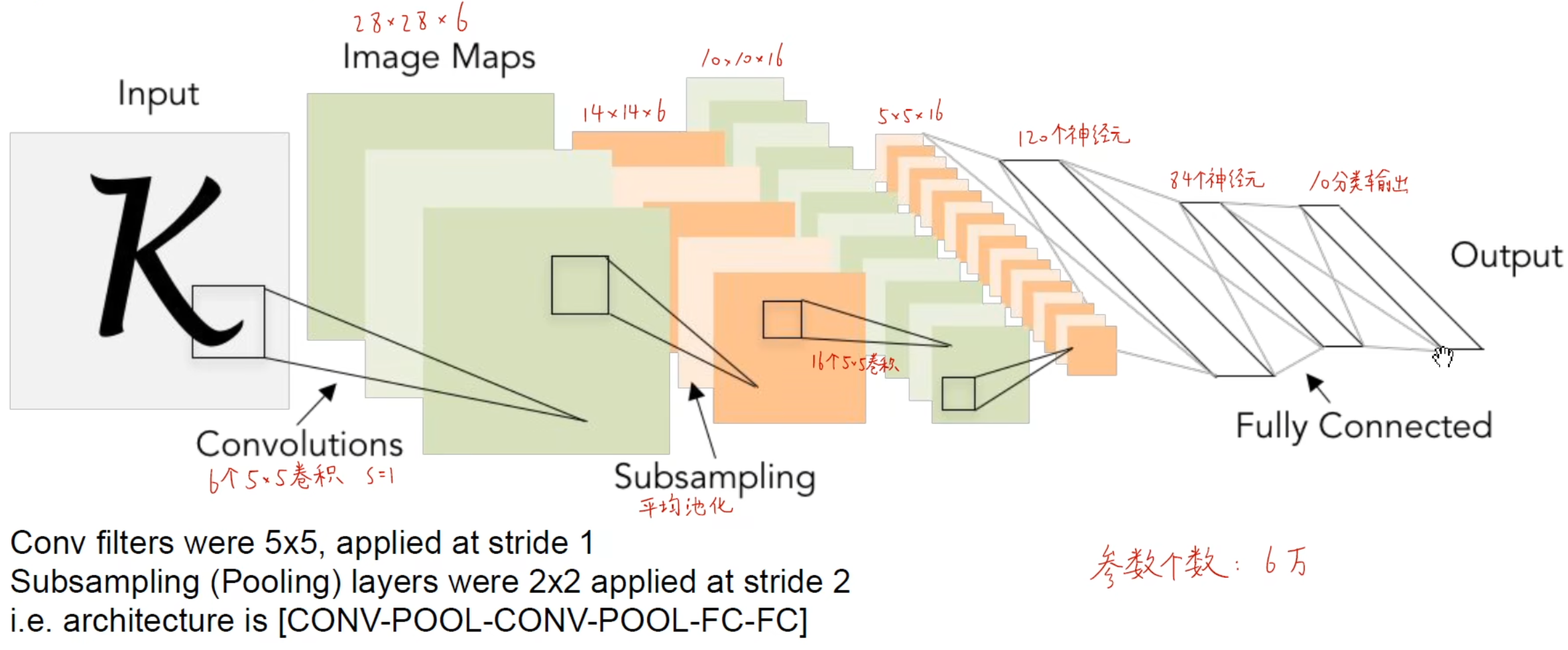
为了节省运算,不是所有通道都参与下一个卷积运算。
输出层不是用softmax,而是用了高斯连接。
采用了 Sigmoid / tanh 激活函数。
AlexNet
总结网络结构与LeNet差不多,但有更深的模型,更多卷积核,且处理的是自然图像,而不是手写数字。是ImageNet 2012年的winner,首次使用CNN,精度大幅提升,具有跨时代意义,之后所有CV领域的模型都是基于卷积神经网络。
原论文图中输入应该是2272273,原论文有误。
因为当时GPU内存不够,所以用2个GPU,每个GPU有48个卷积核,将模型并行计算。
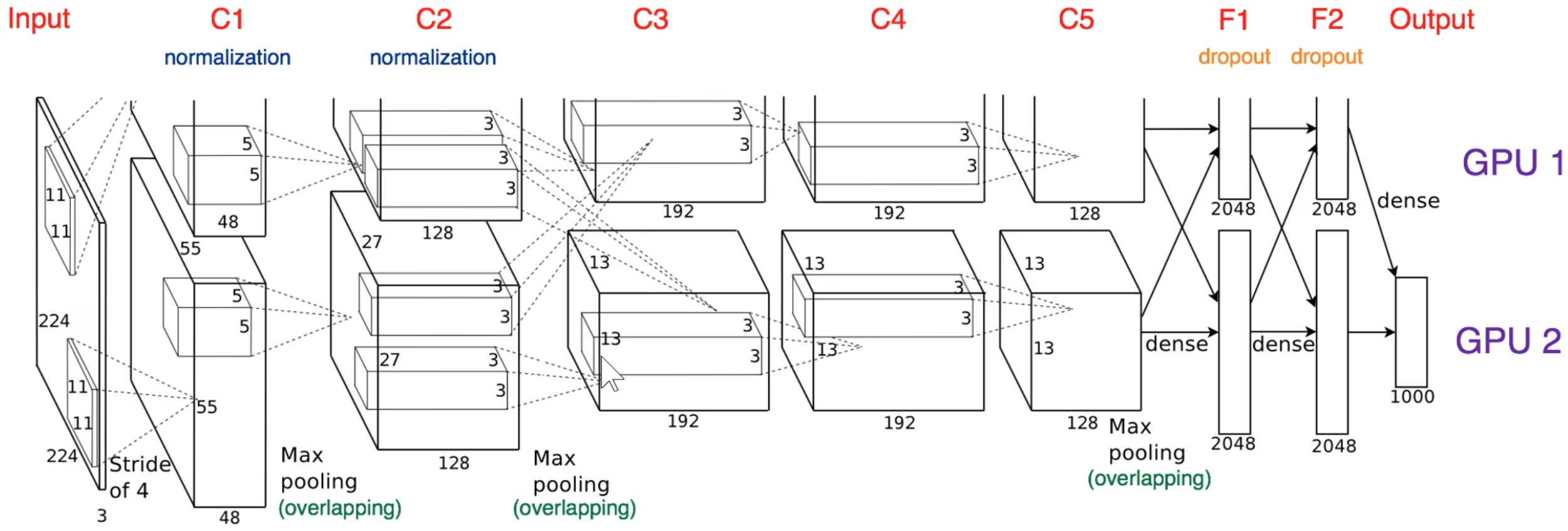

卷积池化归一化统一算一层卷积层,因为池化和归一化没有参数,所以是8层CNN。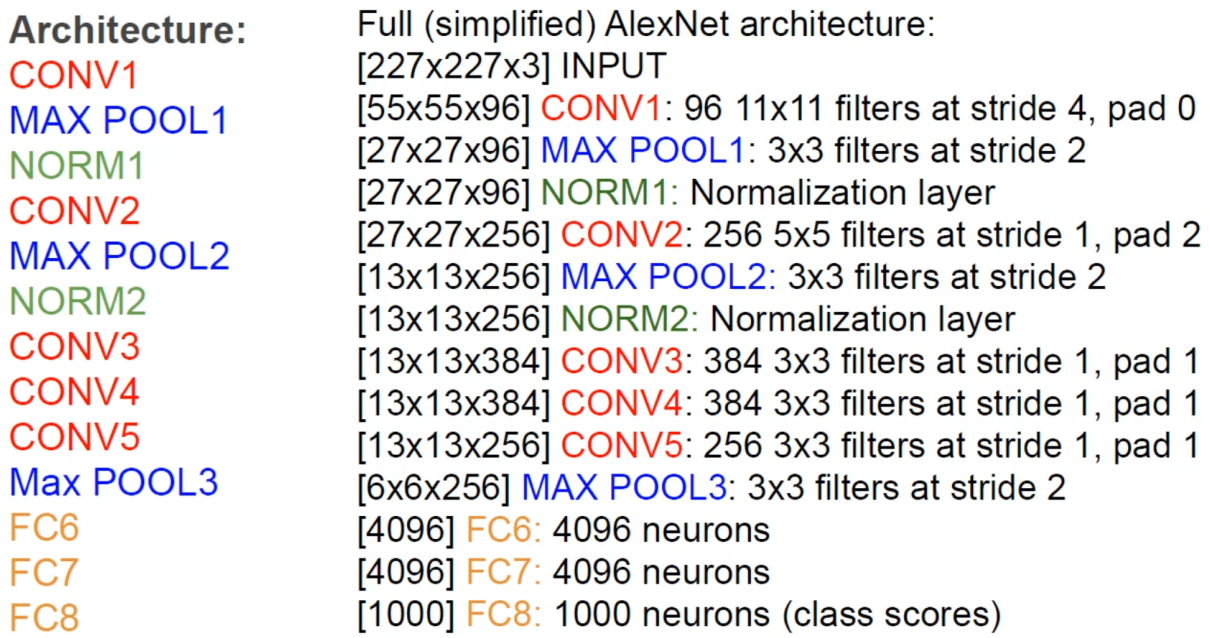
参数量有6千万,比LeNet多了3个数量级。
NORM层是局部响应归一化层,现在很少用了,现在用Batch Normalization挺好的。
AlexNet使用了ReLU激活函数,Softmax输出层,最大池化,使用了图像数据增强,使用了Dropout(0.5),还用7个类似的模型进行了模型集成(精度提高了2.8%)。
核心创新点:
ZFNet
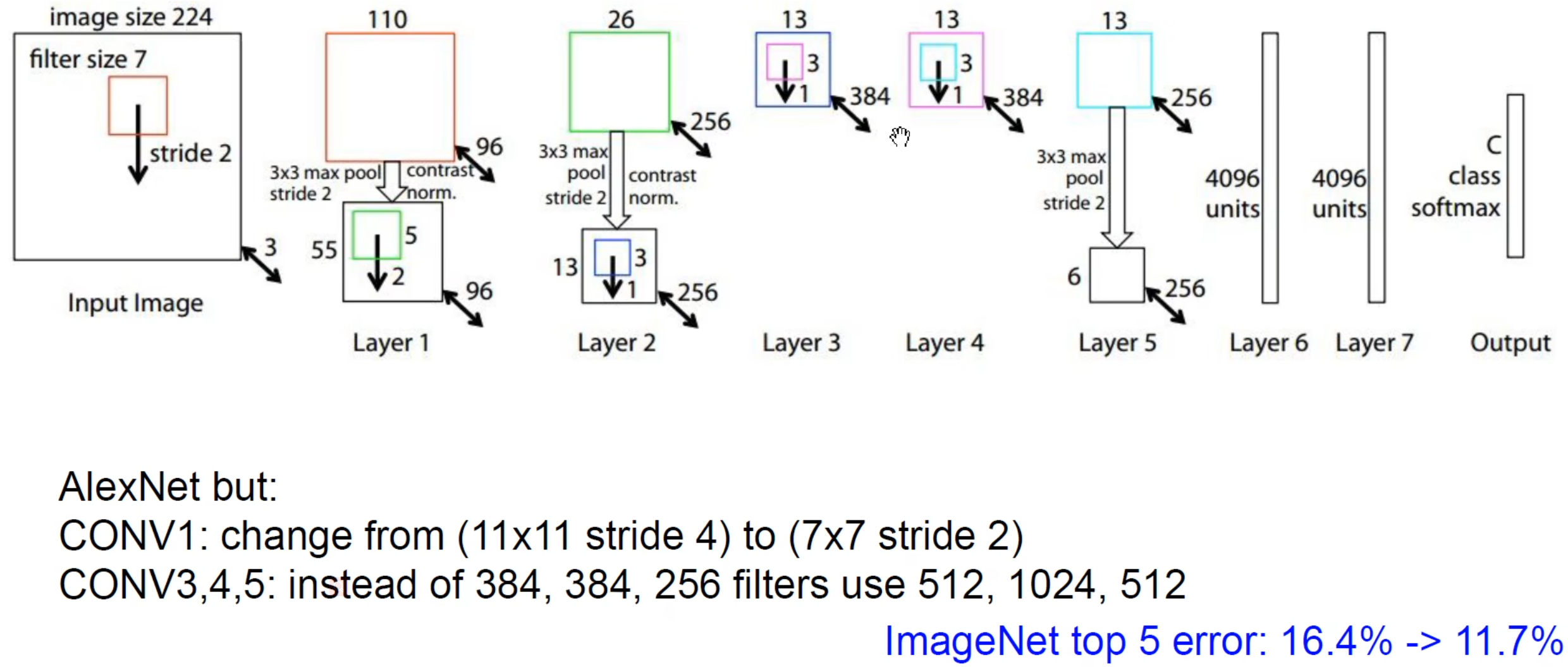
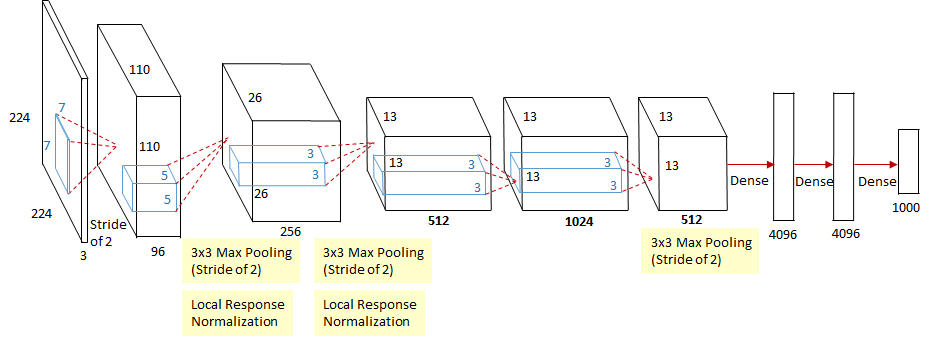
ImageNet竞赛2013年冠军。结构跟AlexNet没有本质区别,也是8层CNN,主要进行了超参数的优化,就是改改卷积的大小和步长。
但是他们这篇论文的核心贡献点是可视化神经网络,提出了反卷积、反池化、反激活,把feature map重构回原始输入空间,从而我们能直观看到底层的卷积核提取底层的边缘、颜色,越到高层卷积核提取的特征就越抽象和复杂,直观地理解CNN提取了哪些特征和特征的重要些。
VGG
2014年ImageNe分类竞赛亚军,但是在一个定位竞赛中是冠军。
VGG创新地只用了3*3卷积核,并将网络加深。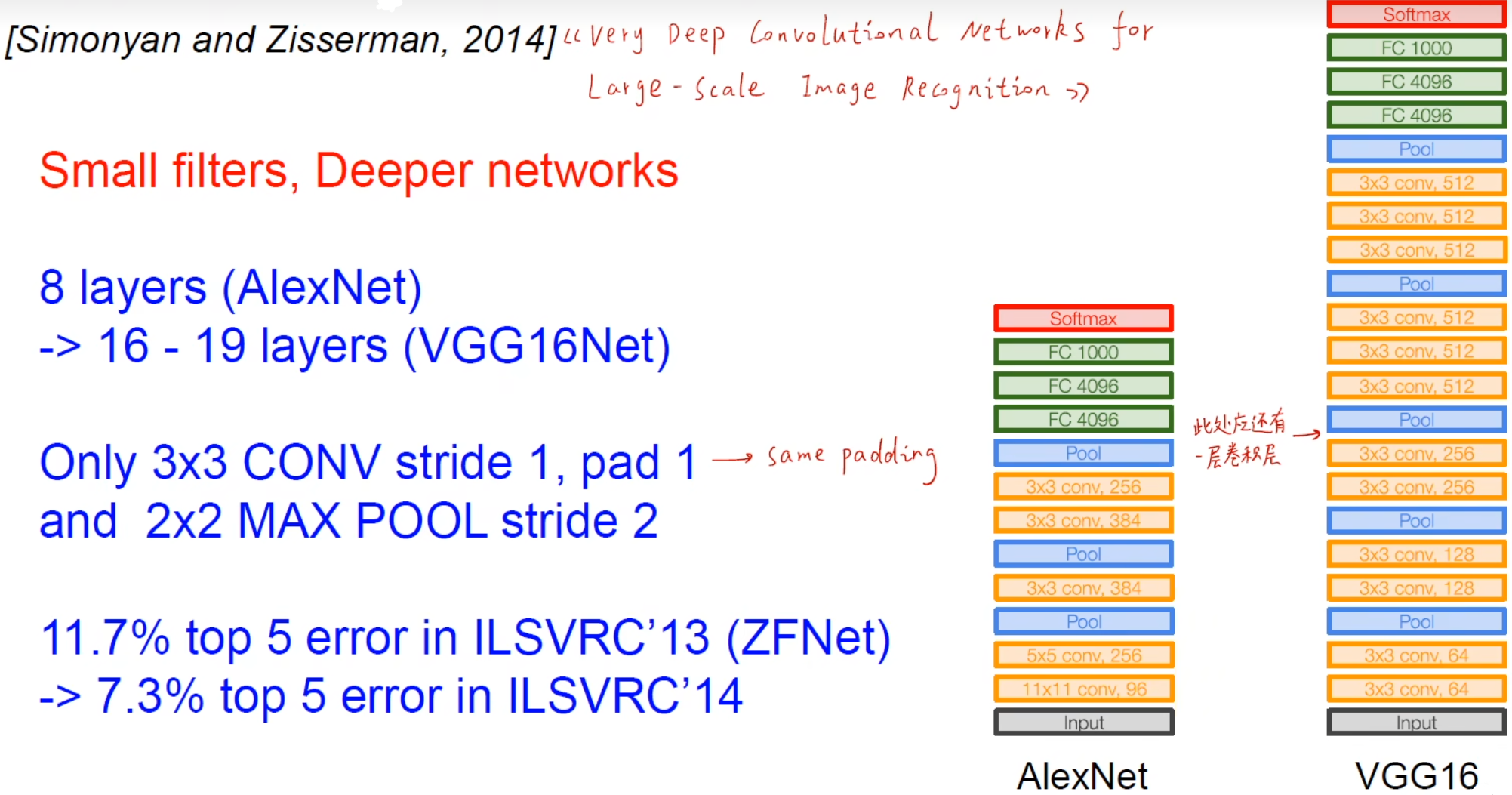
一共5个block,每个block有卷积和池化。VGG16表示共16个带参数的层,还有个VGG19,只是在最后3个block分别加了一个卷积层。
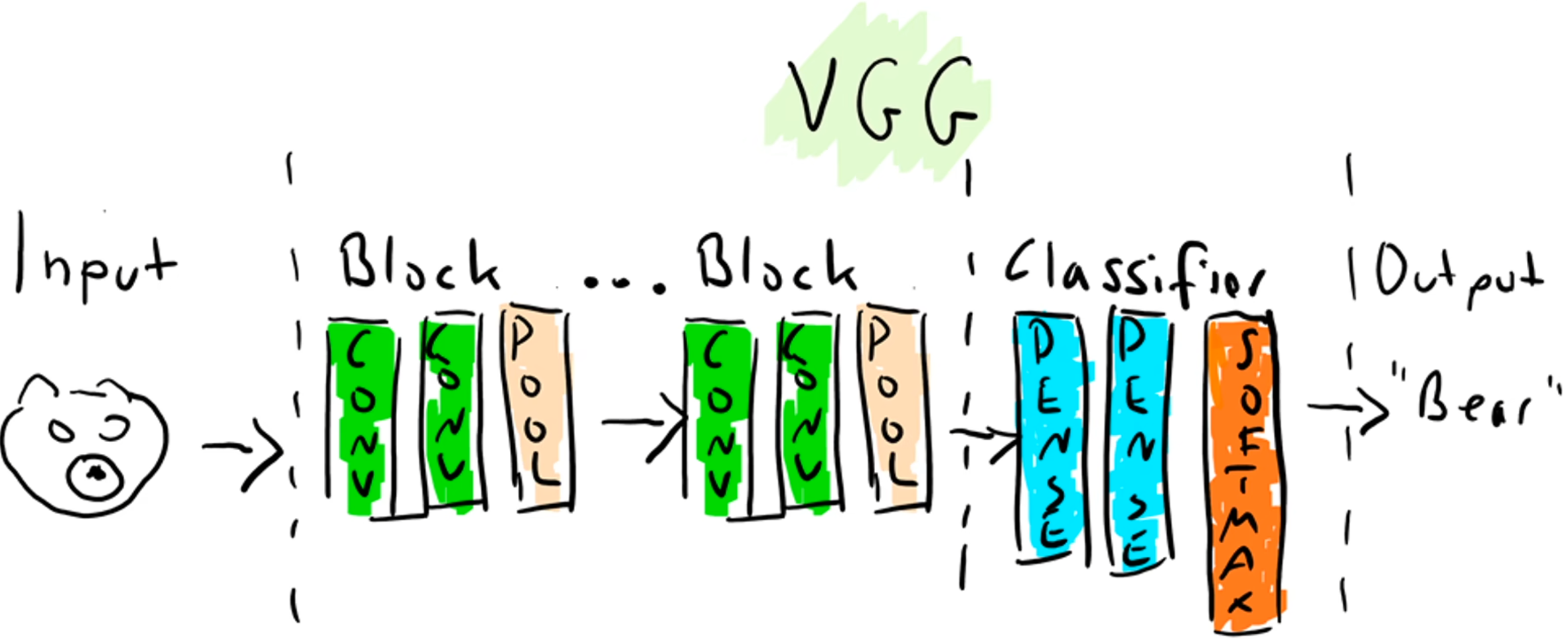
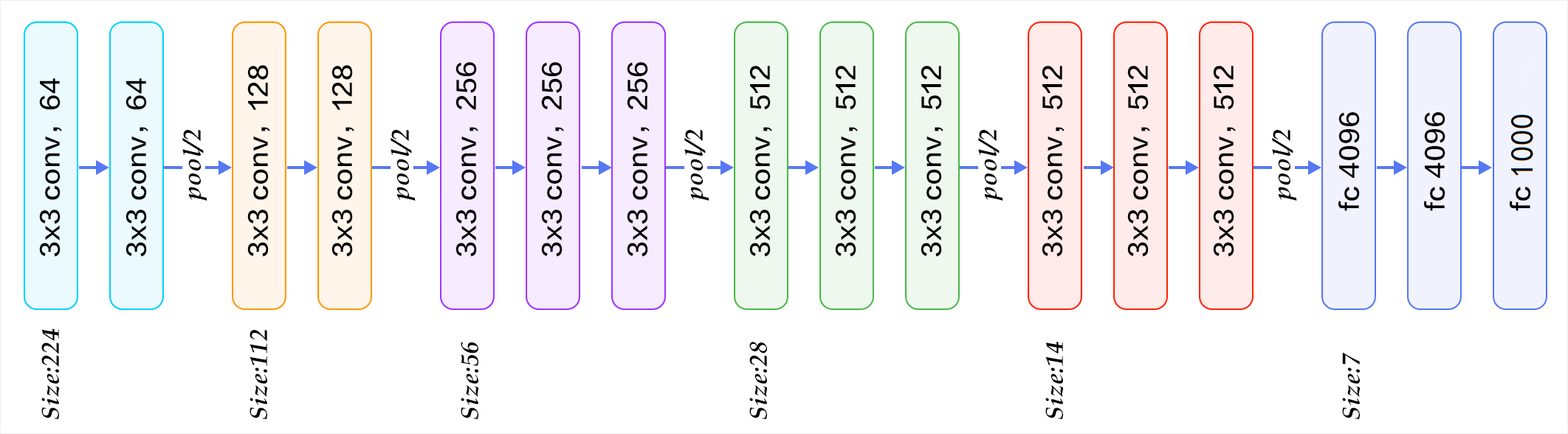
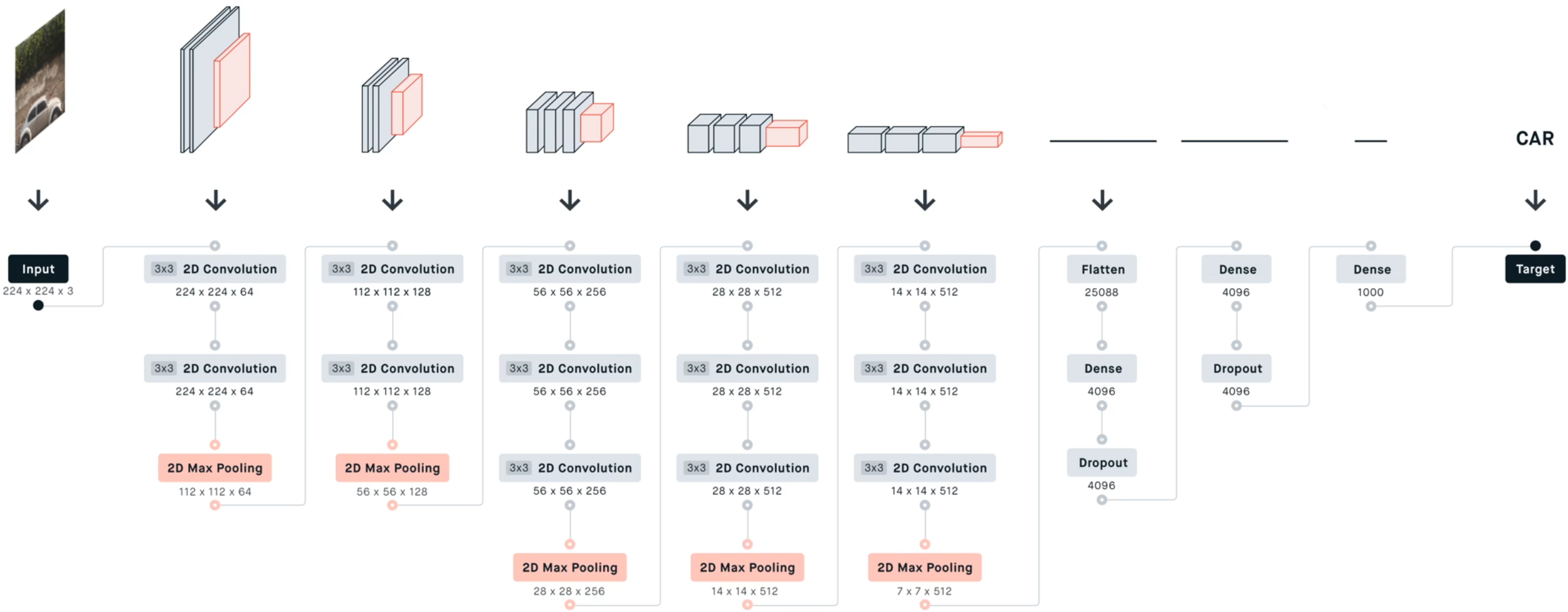
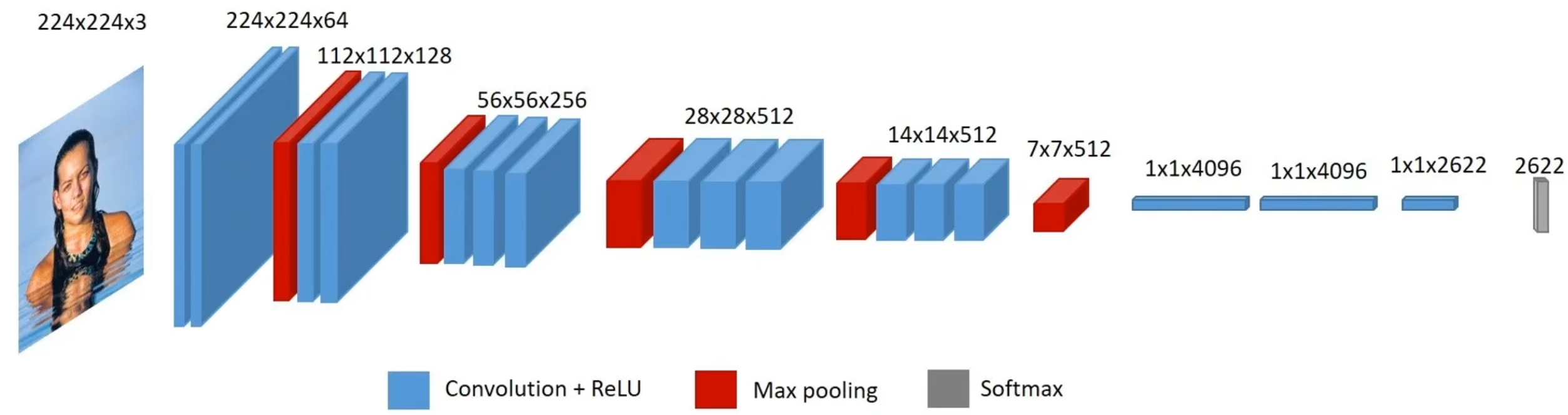
主要的点是发挥了感受野的重要性,因为3层33卷积的感受野与1层77的卷积的感受野相同(2层33卷积的感受野与1层55的卷积的感受野相同),但3层3*3卷积会带来更少的参数、更深的网络、更多非线性变换。
但参数有点臃肿
GoogLeNet (InceptionNet)
2014年ImageNe分类竞赛冠军。
之前的网络结构主要是堆叠卷积池化,GoogLeNet网络创新提出Inception module,主要堆叠这个 Inception module。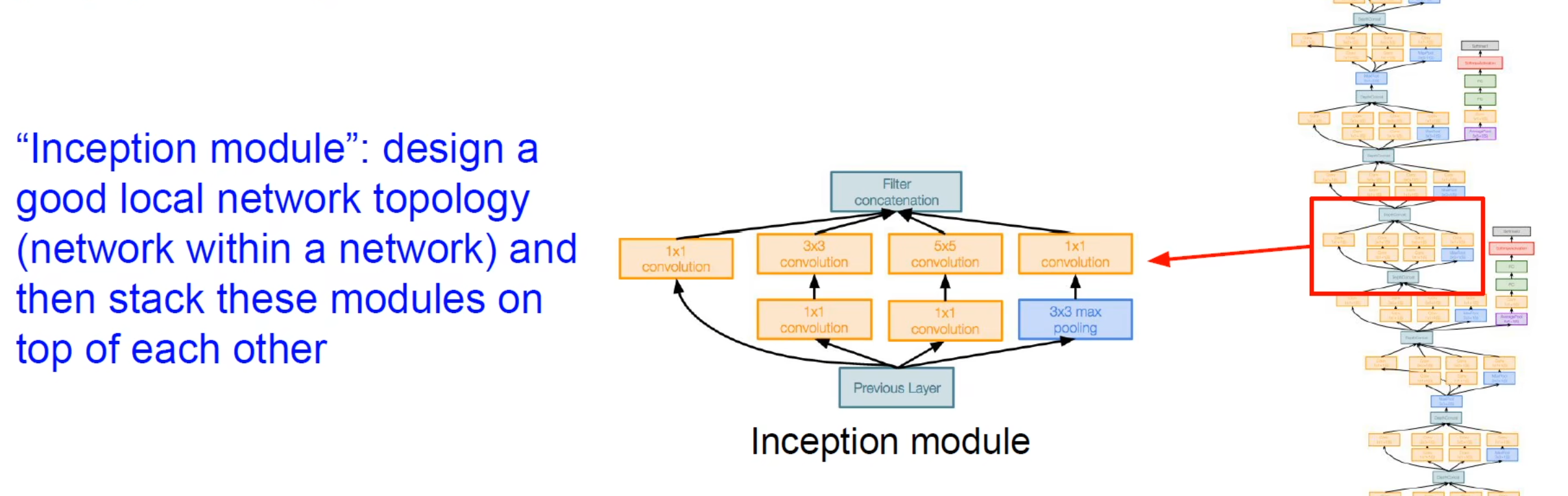
本质是多尺度并行卷积和池化(11,33,5*5).因为有时图像中重点区域大小不一样(比如小狗的近照和远照),多个卷积核运算赋予同一张图不同感受野,充分地提取出图像特征。

问题来了,这样子将feature map直接摞起来,会越来越厚,计算量会非常大。
解决方法:1*1卷积
好处:升维或降维、跨通道信息交融、减少参数量、增加模型深度(提高非线性能力)。


子豪兄的这页PPT总结得非常好:
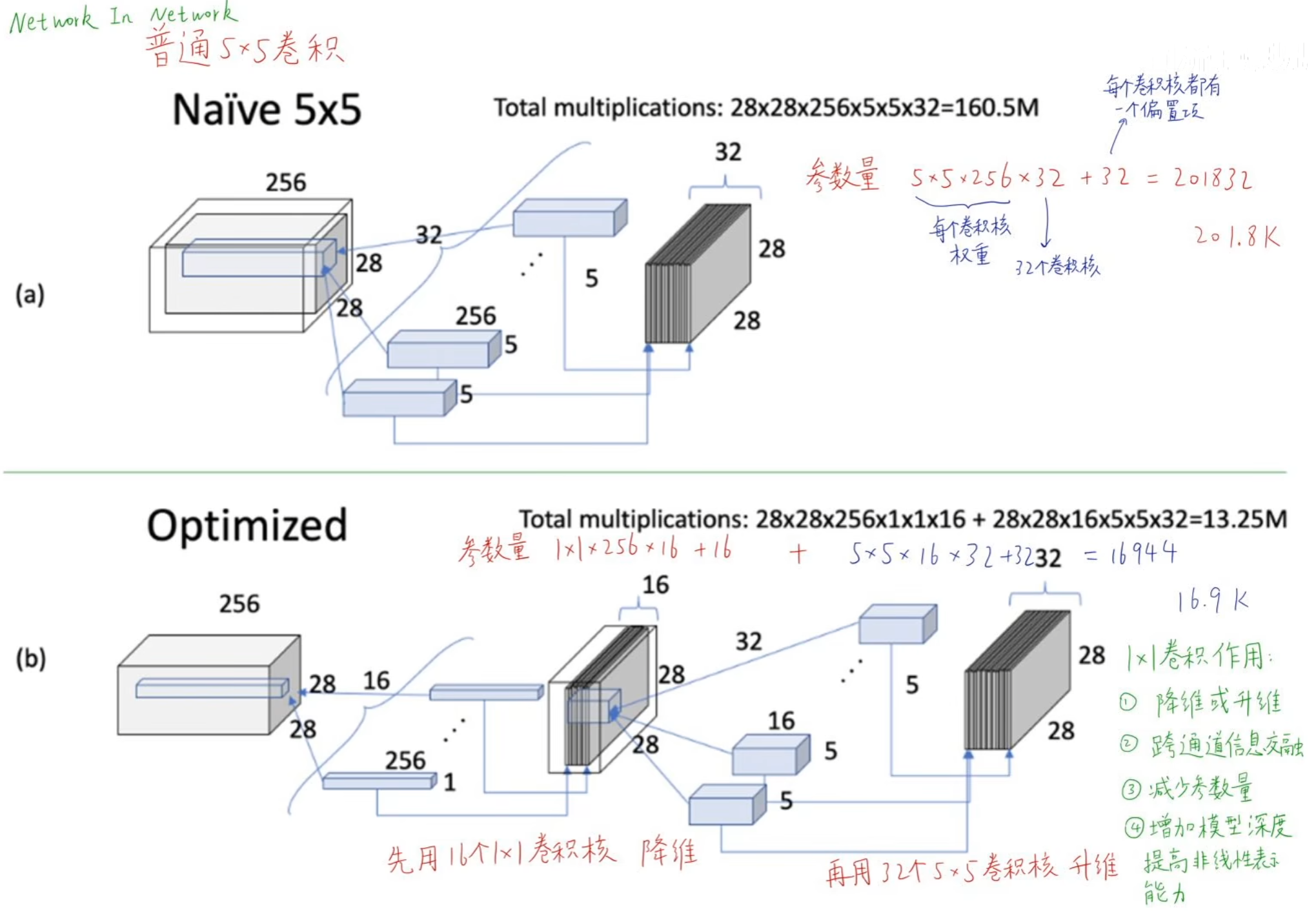
在 network in network 这篇论文中提出11卷积的重要性,(a)说明了2828256的输入经过32个55卷积,共需要201.8K个参数;(b)说明了2828256的输入先经过16个11卷积降维,再经过32个55卷积升维,得到同样大小的输出,但是只需要16.9K个参数,且增加了模型深度,充分说明了1*1卷积的好处。
经过改进: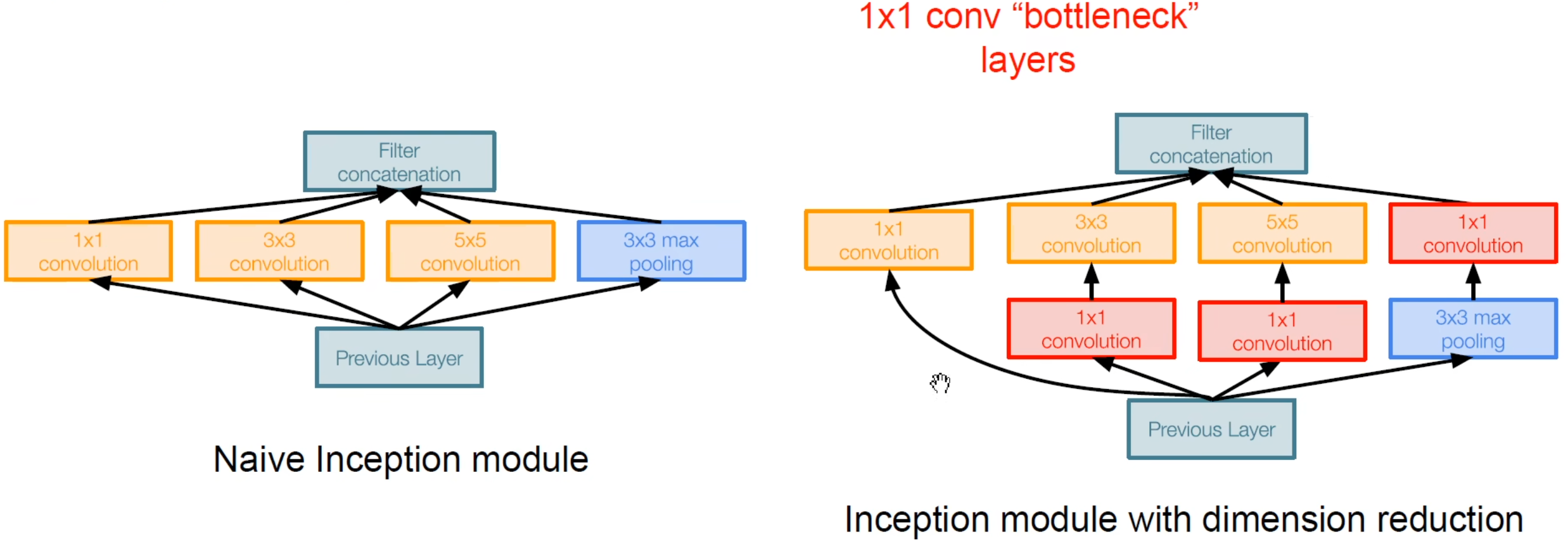
参数少了很多,不错。
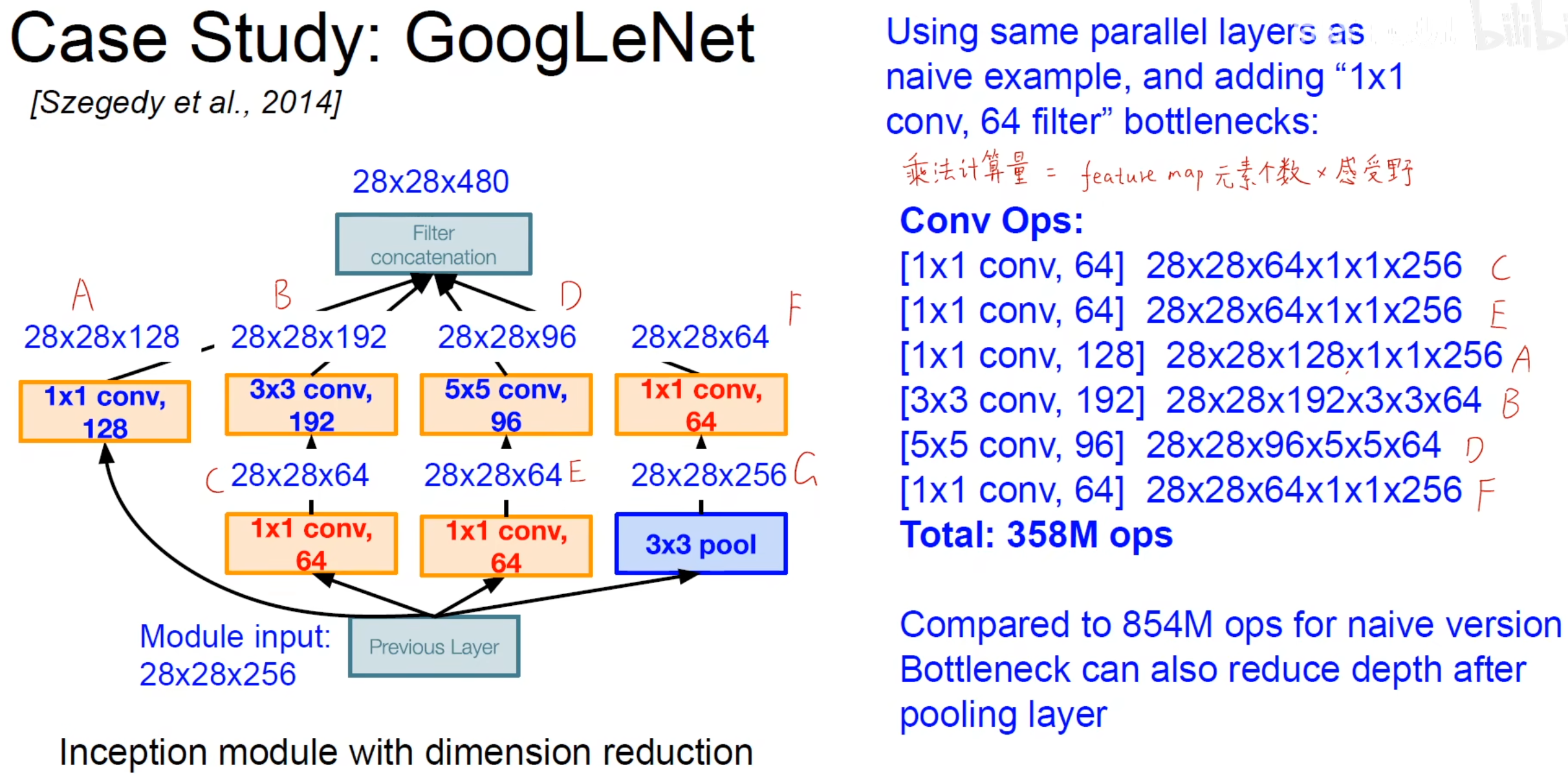
最终GoogLeNet网络结构(Deeper networks, with computational efficiency):
总共22个带参数的层 (并行的算1层)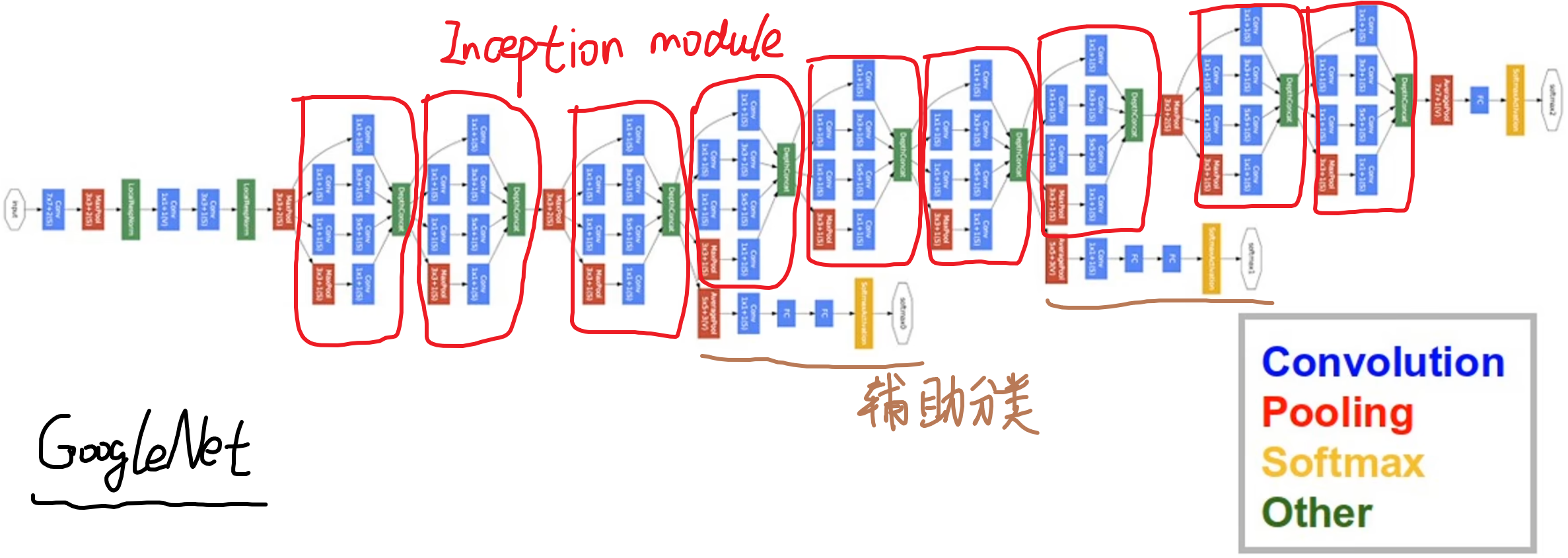
ResNet
2015年是神仙打架的一年,真正开启了深度神经网络,CNN也是这一年超越了人类图像分类的水平。ResNet就是2015年ImageNet竞赛的冠军,由何凯明团队提出,当时在图像分类、语义分隔、定位等方面均战胜了历年来所有的模型,大喊一声:还有谁!
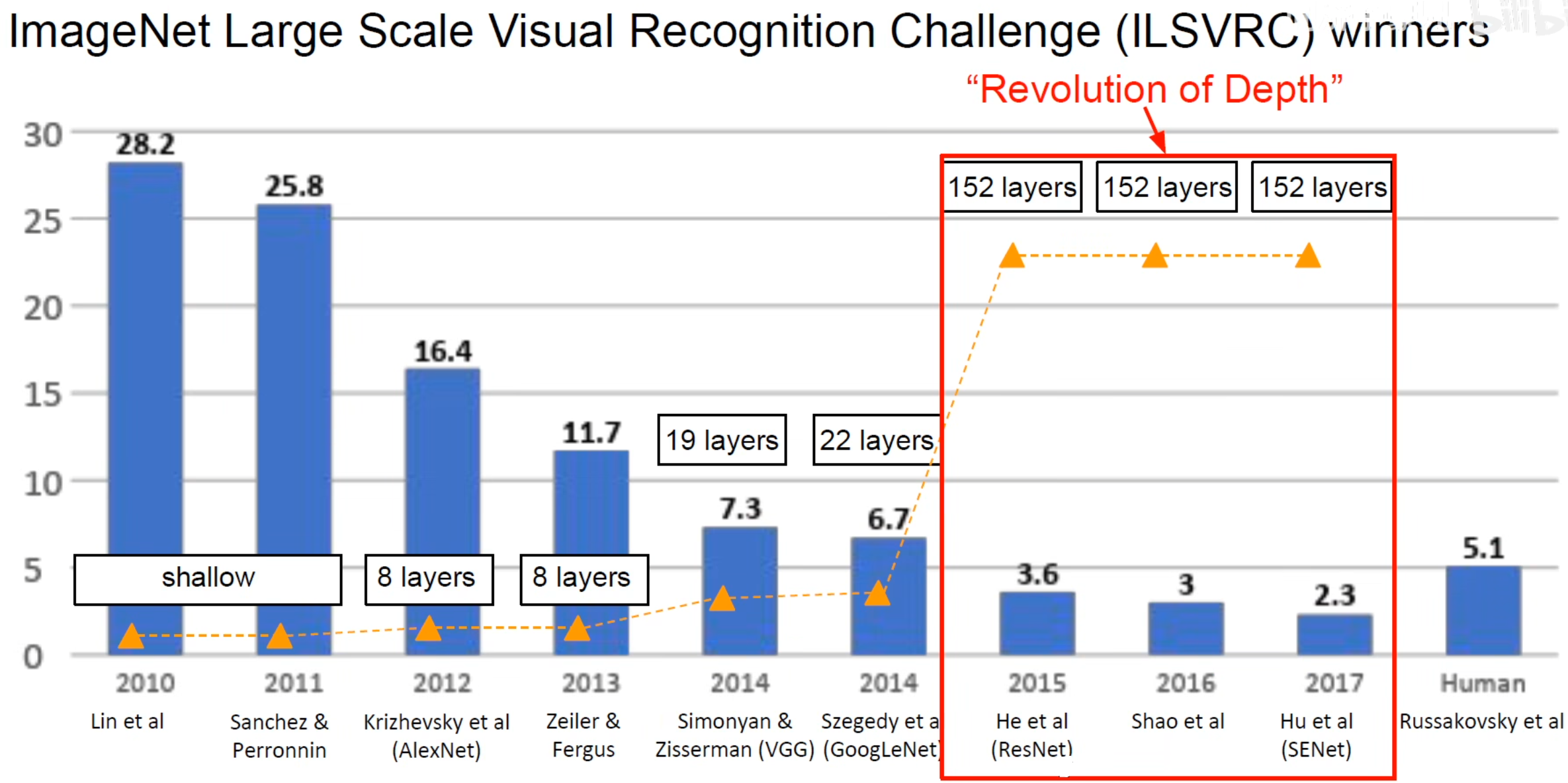
下面好好了解一下这个masterpiece。
首先当时的理念是网络层数不是越深越好。主要是梯度消失和网络退化现象
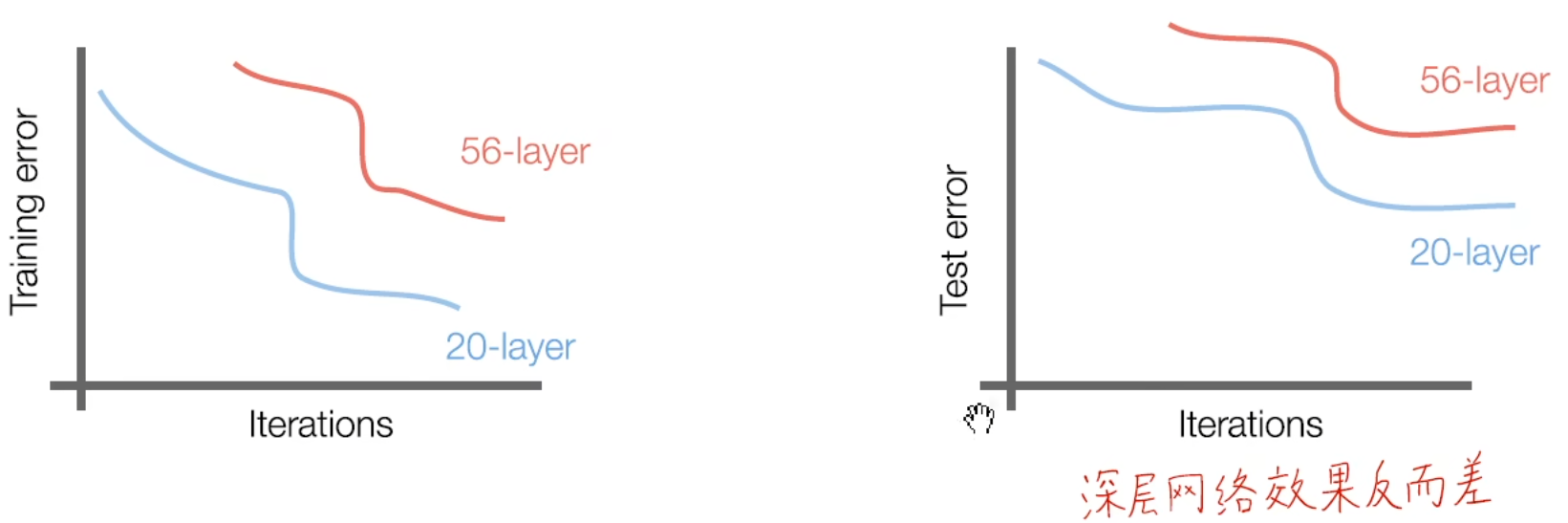
ResNet创新地提出 残差模块(Residual block):
核心思想就是在深层网络中卷积的输出等于浅层网络的结果加上残差,残差就是经过深层网络训练的结果,如果经过深层网络训练得到0,那么输出也是浅层网络的结果,至少模型不会变差,所以堆叠多个残差模块的结果必然是比浅层模型更好的。
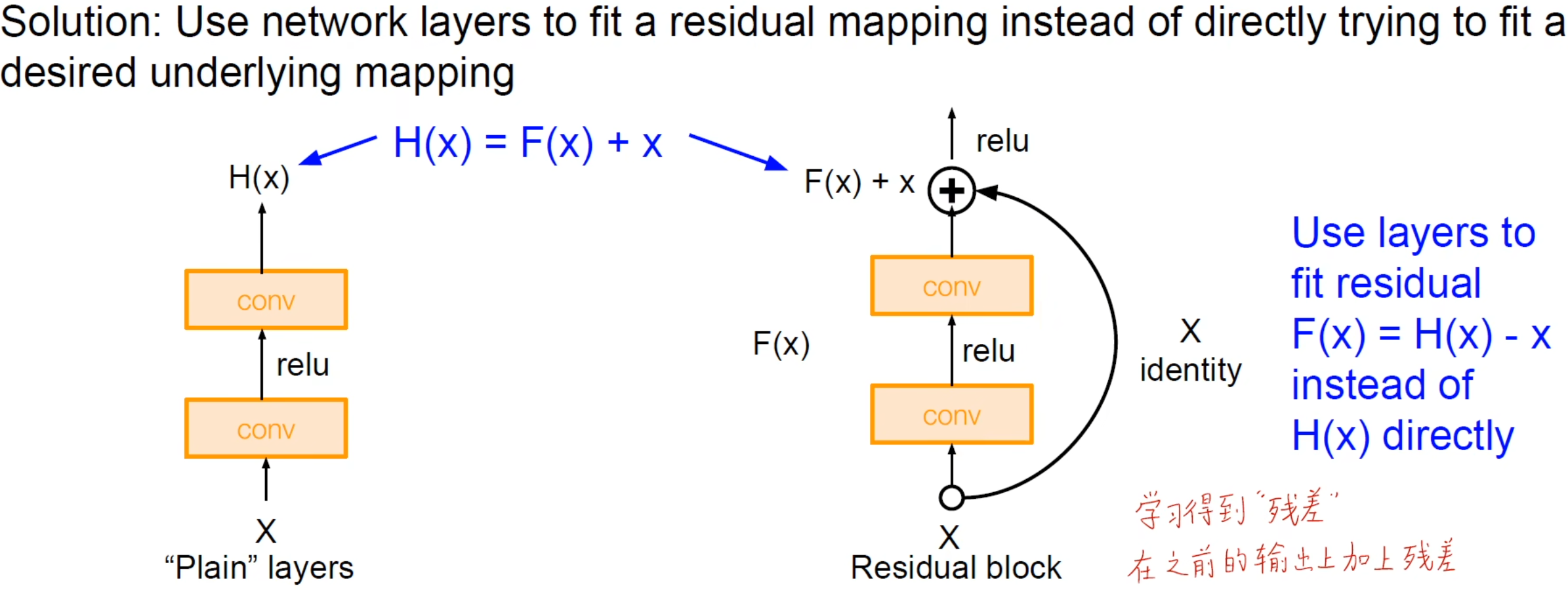

所以ResNet网络可以疯狂加深,总层数可以为34、50、101或152层。

- 用了步长为2的卷积代替池化。
- 用了MSRA初始化
- 用了Batch normalization,激活函数是 SGD+Momentum(0.9)
- 用了Global Average Pooling(GAP),大量节省了参数。
DenseNet
2017 CVPR最佳paper。
Dense Block(每一层都与前面层相连):


SENet
2017年(最后一届)ImageNet竞赛冠军,由胡杰团队提出。
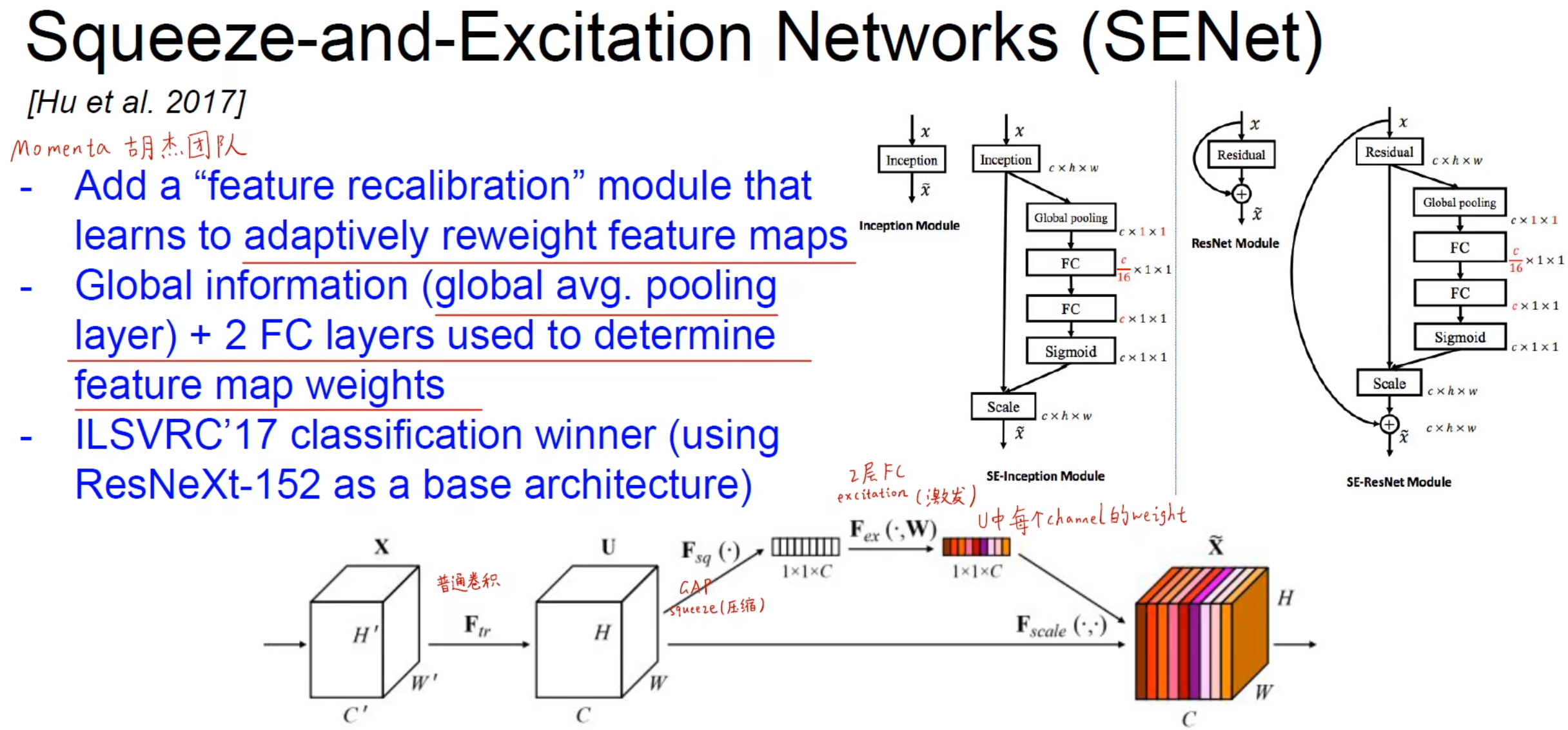
SENet的核心就是自适应学习得到每个feature map通道的权重。
基于GAP(Global Average Pooling)去提取U中每个通道的权重,然后再把U和权重乘起来。它可以集成在任何网络的后面(Inception、resnet等)。
SqueezeNet
由巨佬Song Han提出,主要为了保持精度的同时压缩模型。
MobileNet
重点也是压缩模型,为了使AI模型在边缘的移动设备上运行(边缘计算)。
核心是让每个通道分别用不同的卷积核卷积,再用1*1卷积跨通道融合特征。

小总结
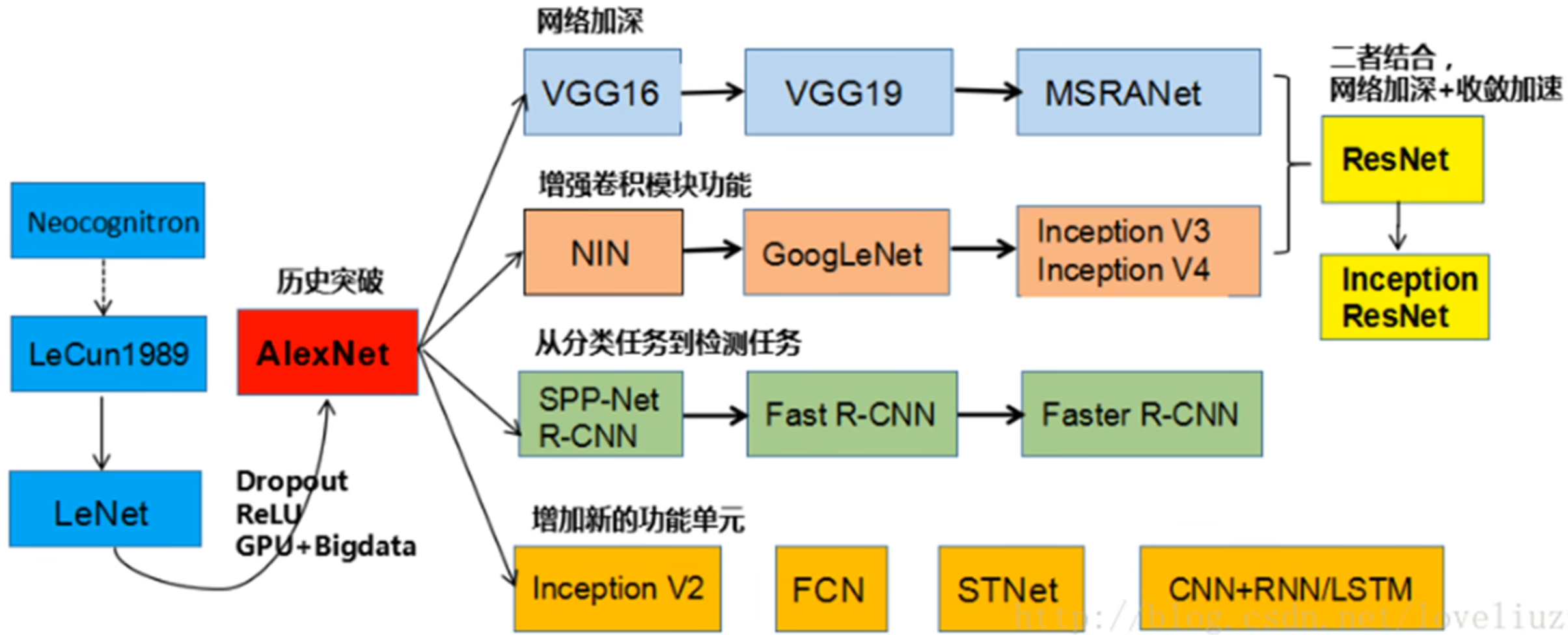
很好的模型总结图!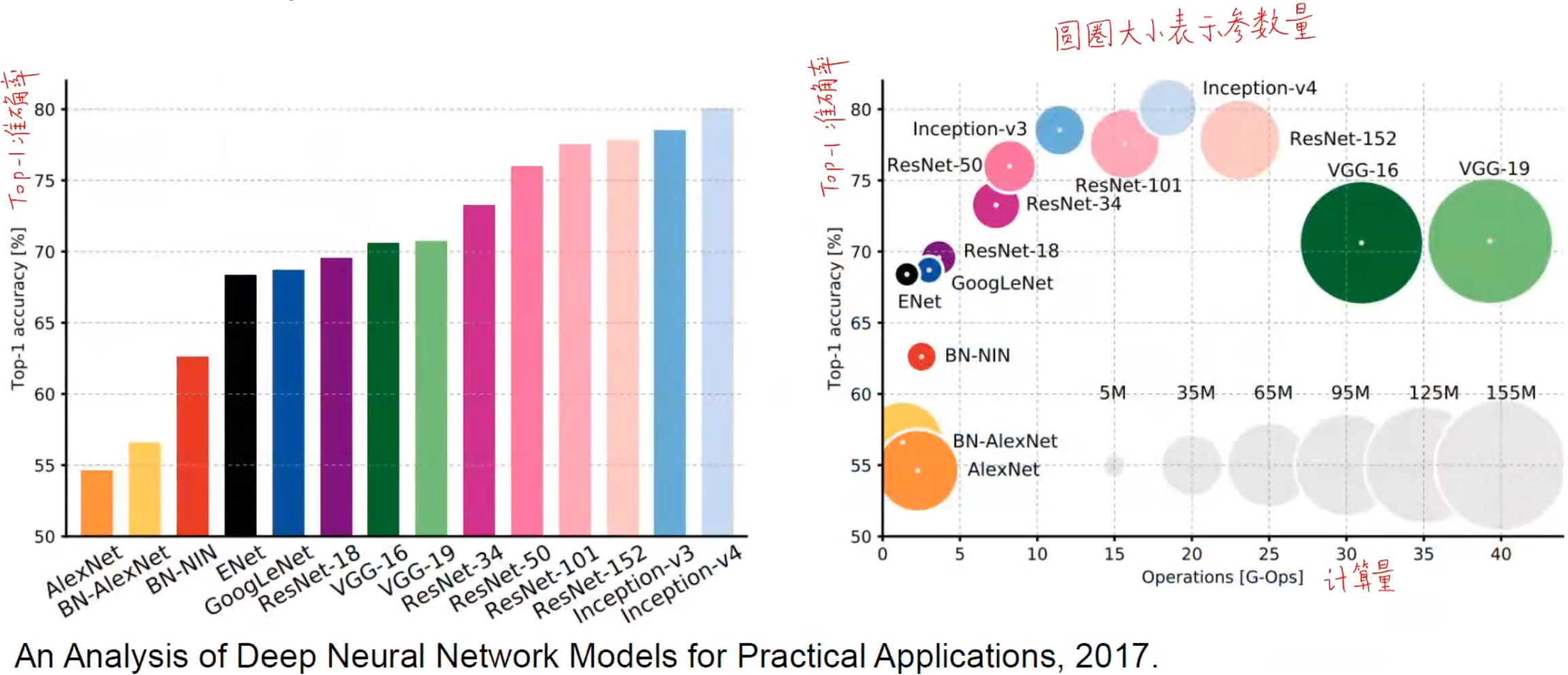
版权归原作者 全栈O-Jay 所有, 如有侵权,请联系我们删除。