
我们将在本文中介绍的模型属于称为高斯判别分析(GDA)模型的类别。 请注意,高斯判别分析模型是生成模型!尽管它的名字叫做判别模型,但是他是生成模型。给定N个输入变量x和相应的目标变量t的训练数据集,GDA模型假设类条件密度是正态分布的
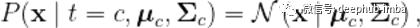
其中μ为类特有的均值向量,σ为类特有的协方差矩阵。利用贝叶斯定理,我们现在可以计算类后验
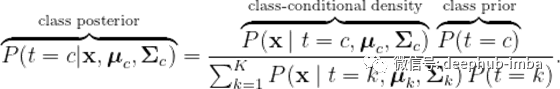
然后我们将把x分类
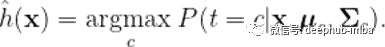
数学推导
对于每个输入变量,我们定义k个二元指标变量。此外,让t表示所有的目标变量,π表示先验,用下标表示类。假设数据点是独立绘制的,似然函数为
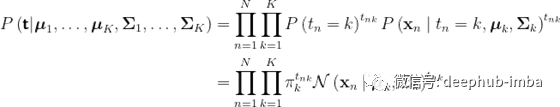
为了简化符号,让θ表示所有的类先验、类特定的平均向量和协方差矩阵。我们知道,最大化可能性等于最大化对数可能性。对数似是
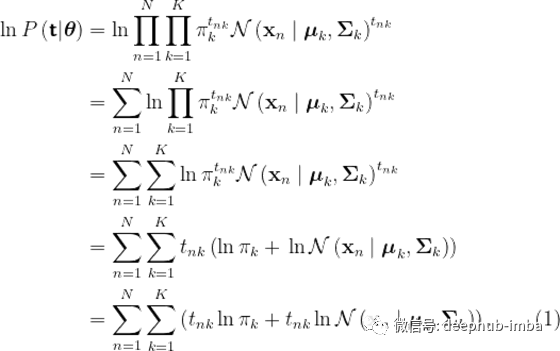
扩展(1)将极大地帮助我们在接下来的推导:
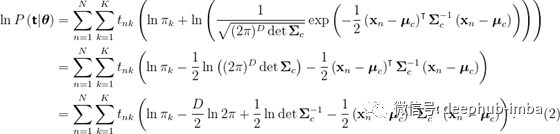
我们必须找到类特定的先验、均值和协方差矩阵的最大似然解。从先验开始,我们需要对(2)求导,让它等于0,然后解出先验。然而,我们必须保持约束
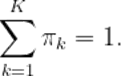
这是通过使用拉格朗日乘数λ来实现的
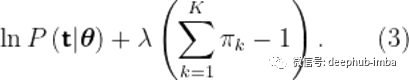
利用(2)的结果,然后对(3)求关于类特定先验的导数,使其等于0,求解
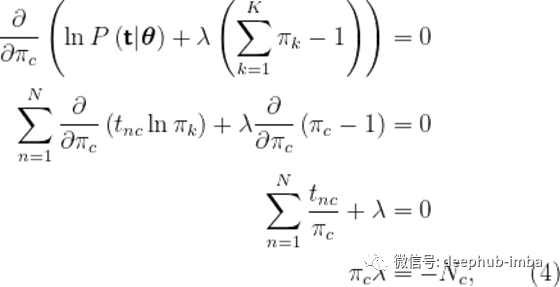
其中Nc是c类中数据点的个数。利用约束知识,我们可以求出λ
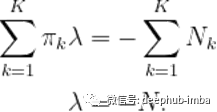
将λ=−N代回(4)得到
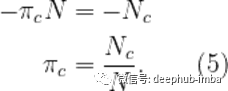
(5)告诉我们类先验只是属于类的数据点的比例,直观上也有意义。
现在我们转向最大化关于类特定的平均值的对数可能性。再一次,利用(2)的结果让我们很容易求导,让它等于0,然后求解
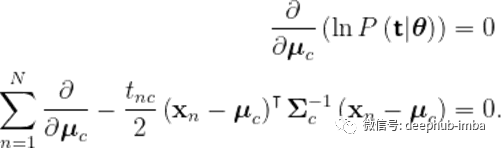
为了计算这个导数,我们使用矩阵演算单位,然后,我们得到
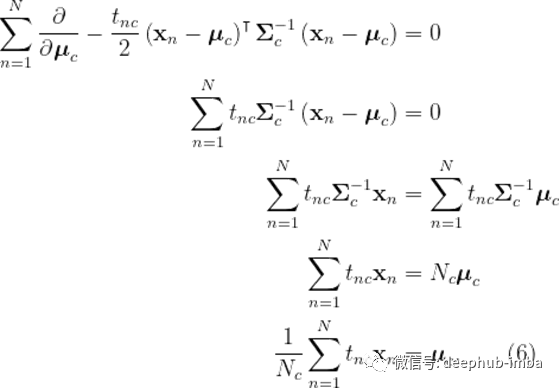
让我们花点时间来理解(6)说的是什么。(6)左边的和只包括属于c类的输入变量x。然后,我们用这些向量的和除以类中的数据点的个数,这和取这些向量的平均值是一样的。这意味着特定于类的平均向量是属于类的输入变量的平均值。
最后,我们必须最大化关于类特定协方差矩阵的对数似然。再一次,我们用(2)的结果求导,让它等于0,然后解
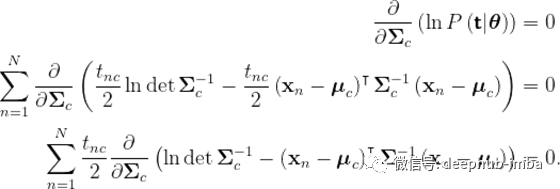
然后,我们得到
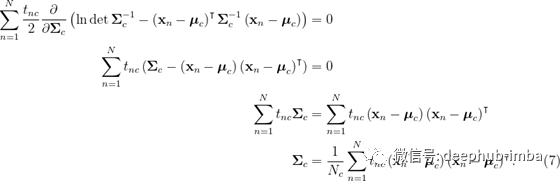
就像特定于类别的均值向量只是该类别的向量的均值一样,特定于类别的协方差矩阵只是该类别的向量的协方差,因此我们得出了最大似然解(5),( 6)和(7)。因此,我们可以使用以下方法进行分类
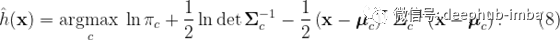
Python实现
让我们从一些数据开始-您可以在下面的图中看到它们。您可以在此处下载数据。
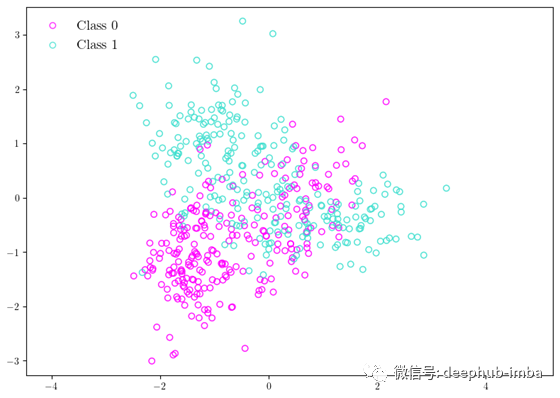
下面的代码是我们刚刚讨论过的QDA的一个简单实现。
import numpy
class QDA:
def fit(self, X, t):
self.priors = dict()
self.means = dict()
self.covs = dict()
self.classes = np.unique(t)
for c in self.classes:
X_c = X[t == c]
self.priors[c] = X_c.shape[0] / X.shape[0]
self.means[c] = np.mean(X_c, axis=0)
self.covs[c] = np.cov(X_c, rowvar=False)
def predict(self, X):
preds = list()
for x in X:
posts = list()
for c in self.classes:
prior = np.log(self.priors[c])
inv_cov = np.linalg.inv(self.covs[c])
inv_cov_det = np.linalg.det(inv_cov)
diff = x-self.means[c]
likelihood = 0.5*np.log(inv_cov_det) - 0.5*diff.T @ inv_cov @ diff
post = prior + likelihood
posts.append(post)
pred = self.classes[np.argmax(posts)]
preds.append(pred)
return np.array(preds)
现在我们可以用下面的代码进行预测。
data = np.loadtxt("../data.csv", delimiter=",", skiprows=1)
X = data[:, 0:2]
t = data[:, 2]
qda = QDA()
qda.fit(X, t)
preds = qda.predict(X)
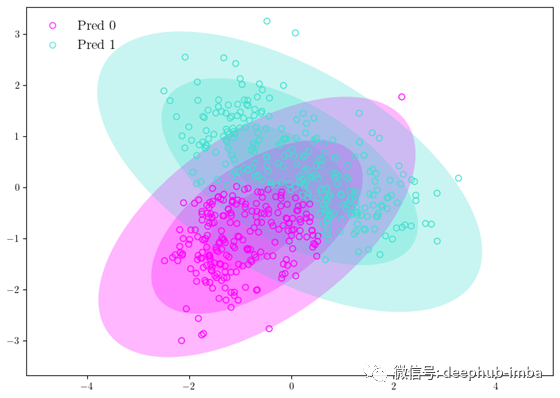
这给了我们高斯分布以及如下所示的预测。
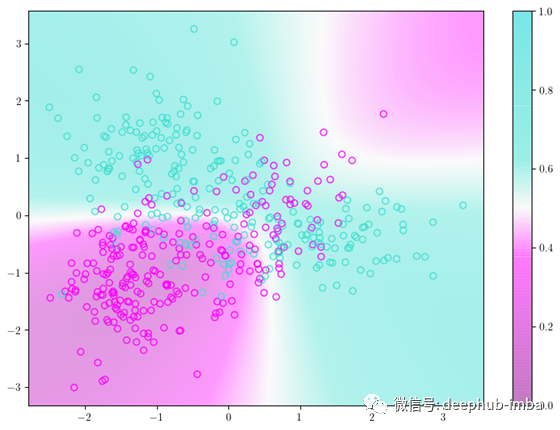
为了便于说明QDA的工作原理和工作效果,我们可以在决策边界上绘制数据点的原始类。这是下面显示的。
总结
二次判别分析(QDA)是一种生成模型。
QDA假设每个类服从高斯分布。
特定于类的先验只是属于该类的数据点的比例
特定于类的平均向量只是该类的输入变量的平均值
特定于类的协方差矩阵只是该类的向量的协方差。
作者:Stefan Hrouda-Rasmussen
原文地址:https://towardsdatascience.com/quadratic-discriminant-analysis-ae55d8a8148a
deephub翻译组