
一、自动化相关理论知识
1.1自动化
说明:让机器设各代替人为完成指定目标的而过程优点;
1.准少劳动力
2.提高效车批量生产
3.提高产品质曼
4.规格统一标准
1.2自动化测试
说明:让程序或工具代替人为对程序功能验证的
过程解决:
1.回归测试[重点](分为bug回归测试,新版本回归测试)
2.压力测试(多用户同时操作的临界点)
3.兼容性(浏览器、分辨率、操作系统)
4.提高测试效率
优点
1.较少的时间内运行更多的测试用例;
2.自动化脚本可重复运行;
3.减少人为的错误;
4.克服手工测试的局限性;
误区
1.自动化测试可以完全替代手工测试;
2.自动化测试一定比手工测试厉害;
3.自动化测试可以发掘更多的BUG;
4、自动化测试适用于所有功能;
web自动化测试
概述:让程序代替人为对web项目进功能验证过程
什么web项目适合自动化?
1.需求变动不频繁
2.需要回归测试项目
3. 项目周期长
web自动化开始进行阶段?
手工测试之后(1.时间问题2.功能不完善)
web自动化所属分类
1.黑盒测试(功能测试)
2、灰盒测试(接口测试)
3.白盒测试(单元测试)
提示;
1.以上分类为站在代码可见度上划分
2. web自动化司试属于黑盒测试
二.主流的Web自动化测试工具
1.QTP
QTP是一个商业化的功能测试工具,收费,支持web,桌面自动化测试。
2. Selenium(本阶段学习)
Selenium是一个开源的web自动化测试工具,免费,主要做功能测试。
3. Robot framework
Robot Framework是一个基于Python可扩展地关键字驱动的测试自动化框架。
4 Selenium特点
1.开源软件:源代码开放可以根据需要来增加工具的某些功能2.跨平台: linux、 windows、mac
3.支持多种浏览器:Firefox、Chrome、IE、Edge、opera、Safari等
4.支持多种语言:Python、Java、C#、JavaScript、Ruby、PHP等
5.成熟稳定:目前已经被google、百度、腾讯等公司广泛使用
6.功能强大:能够实现类似商业工具的大部分功能,因为开源性,可实现定制化功能
5 安装selenium包
前提:Python3安装完毕且能正常运行PIP工具
pip是一个通用的 Python包管理工具,提供了对Python包的查找、下载、安装、卸载的功能。
安装
pip install selenium==3.14.1
卸载
pip uninstall selenium
查看是否安装和版本
pip show selenium
下载浏览器驱动
谷歌:http://chromedriver.storage.googleapis.com/index.html?
将下载的对应版本的驱动的路径放到系统变量path中
Firefox 48以上版本
selenium 3.x + Firefox驱动(geckodriver)
驱动下载地址: https://github.com/mozilla/geckodriver/ releases
科普path
说明:指定系统搜案的目录dos命令默认搜索顺序:
1.检测是香为内部命令
2.检测是否为当前目录下可执行文件,检测path环境变量指定的目录
简单案例
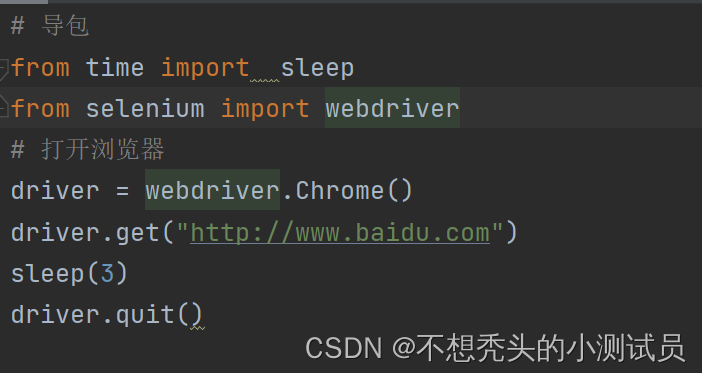
三.元素定位
3.1为什么要使用元素定位?
要使里rb自动化换作元素,必须首先找到此元素
3.2定位工具
谷歌:f12性(开发者工具
3.3定位元素时依赖于件么?
1.标签名
2.属性
3.层级
4.路轻
3.4定位方式
- id
- name
- class_name(使用元素的class属性定位)
- teg_ name(标签名称<标签名…/ > )
- link text(定位超连接a标签)
- partial_link_text(定位超链接a标签模糊;
- xpath(基于元素路径)
- css (元素选择器)
3.5汇总:
1.基于元素属性特有定位方式(idinamelclass_name)
2.基于元素标签名称定位: tag_name
3.定位超链接文本(1ink_text.partial_link_text)
4.基于元素路径定位(xpath)l
5.基于选择器(css)
id定位:
说明:
1.通过元素的id属性定位,id一般情况下在当前页面中是唯一。
方法:
driver.find_element_by_id(id)
提示:元素必扬要有id属性。
name定位:
说明:
1.通过元素的name属性定位,一般为重复
方法:
driver.find_element_by_name(name)
提示:元素必扬要有name属性。
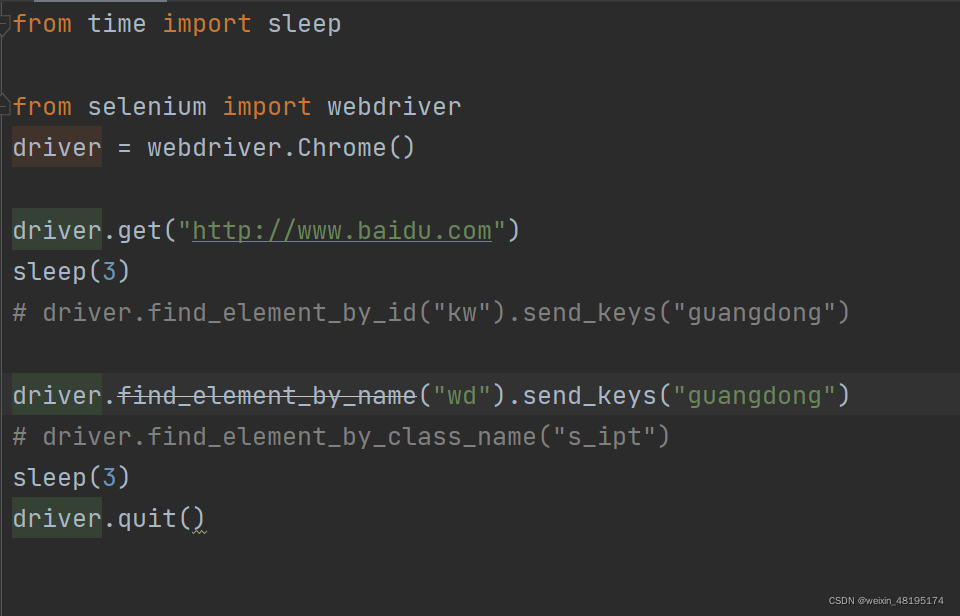
class_name定位:
说明:
1.通过元素的class_name属性定位,一般有多个
方法:
driver.find_element_by_class_name(name)
提示:元素必扬要有 class_name属性。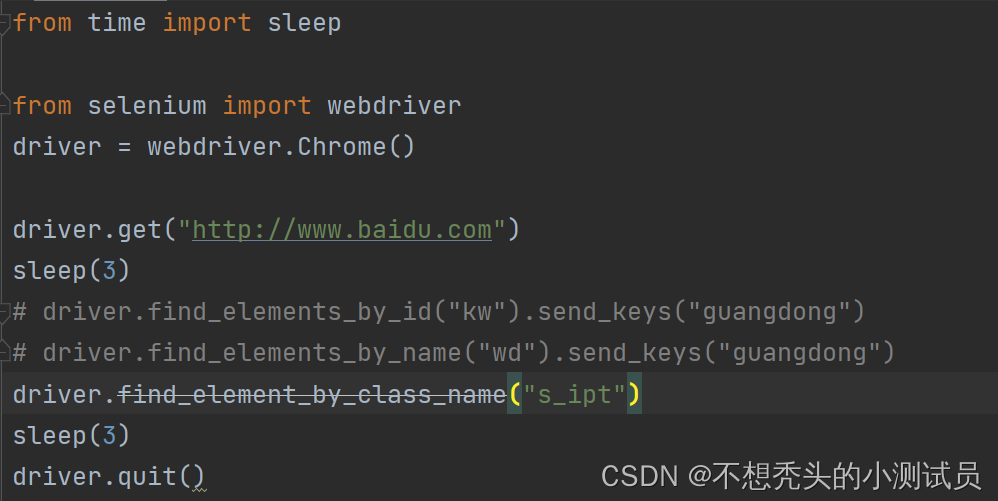
tag name定位
说明:是通过元素的标签名称来定位,标签名(查看元素时尖括号(<)紧挨着的单词或字母就是标签名)
标签名也就是元素名)
方法: driver.find_element_by_tag_name (“标签名”)注意:
1.如果页面中存在多个相同标签,默认返回第一个标签元素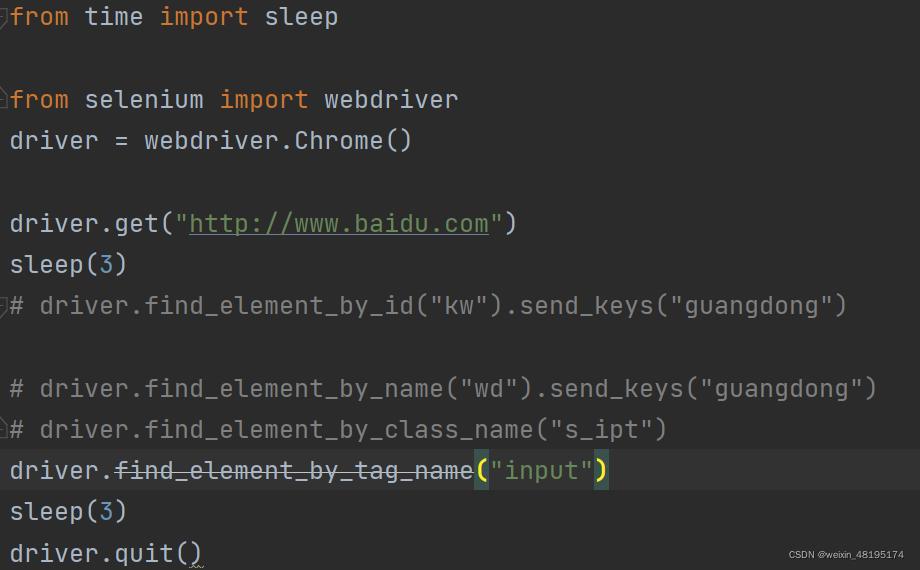
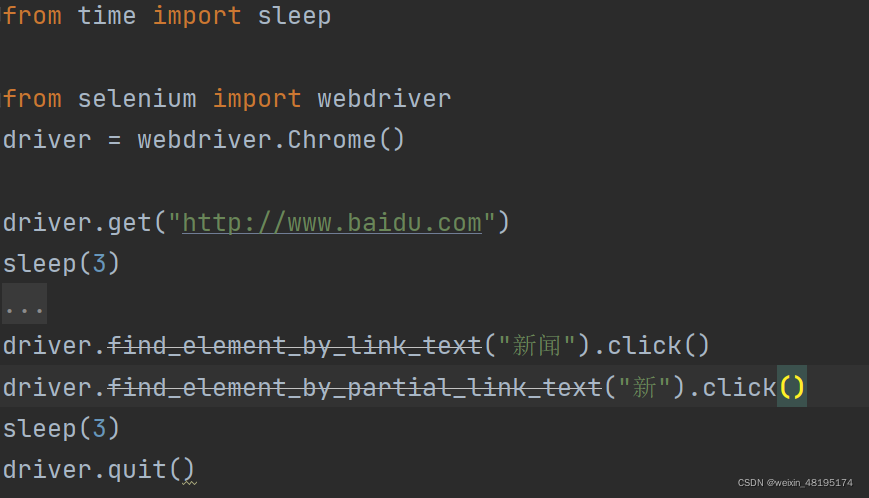
link text
说明:定位超链接标签
方法: driver.find_element_by_link_text ()
注意:
- link_text:只能使相精准匹配(a标签的全部文本内容) partial_link text 说明:定位超链接标签 方法: driver.find_element_by_partial_link_text()注意: 1.可以使用精准或模糊匹配,如果使用模糊匹配最好使用能代表唯一的关键词2.如果有多个值,默认返回第一个值
Xpath
driver.find_element_by_xpath()
Xpath常用的定位策略:
1.路径
1).绝对路径:
语法:以单斜杠开头逐级开始编写,不能跳级。如: /htm1/body/div/p[1]/input
2).相对路径
语法:以双斜杠开头,双斜杠后边跟元素名称,不知元素名称可以使用 * 代替。
如: //input
// *
2.路径结合属性
语法:在xpath中,所有的属性必须使用@符号修饰如://* [@id='id值"]
3.路径结合逻辑(多个属性)
语法://* [ Gid=“id值” and 属性=·属性值]
4.路径结合层级
语法:// * [@id='父级id属性值"]/input
提示:
1.一般见识使用指定标签名称,不使用* 代替,效率比较慢。
2.无论是绝对路径和相对路径,/后面必须为元素的名称或者*
3.扩展:在工作中,如果能使用相对路径绝对不使用绝对路径
Xpath扩展
- //* [ text ()=‘xxx’]#定位文本值等于xxx的元素提示:—般适合p标签,a标签
- //* [ contains (@属性,‘xxx’)]#定位属性包含xxx的元素提示: contains为关键字,不可更改。
- //* [starts-with(@属性, ‘xxx’) ]#定位属性以xxx开头的元素 提示: starts-with为关键字不可更改
css定位说明:
1.css一种标记语言,焦点:数据的样式。控制元素的显示样式,就必须先找到元素,在css标记语言中找元素使用css选择器;
2. css定位就是通过css选择器工具进行定位。
3.极力推荐使用,查找元素的效率比xpath高,语法比xpath更简单。方法:
driver.find element by_css_selector ()常用测试略:
1.id选择器
前提:元素是必须有id属性语法:#id如: #passwordA
2.class 选择器
前提:元素是必须有class属性语法:.class如: .telA
3.元素选择器
语法:element如: input
4.属性选择器
语法:[属性名=属性值]
5.层级选择器
语法:
1.p>input
2. p input
提示:>与空格的区别,大于号必须为子元素,空格则不用。
css定位扩展:
1.[属性^=‘开头的字母’]#获取指定属性以指定字母开头的元素
2.[属性$=‘结束的字母’]#获取指定属性以指定字母结束的元素
3.[属性*='包含的字母’j#获取指定属性包含指定字母的元素
定位一组元素
方法: driver.find elements_ by xxx ()
返回结果:类型为列表,要对列表进行访问和操作必须指定下标或进行遍历,〔下标从0开始]
扩展8种元素定位的底层实现
方式:driver.find_element (By.xxx,‘value’)参数说明:
By.xxx :为By类的类型如:By.ID
value:元素的定位值如: “userA”
By类:需要导包位置:from selenium.webdriver.common.by import By
版权归原作者 不想秃头的小测试员 所有, 如有侵权,请联系我们删除。