
一. 大数据基础概论
1.1 何为大数据
大数据(Big Data)是解决对海量数据进行采集,存储与分析计算的问题。
大数据存储单位顺序:bit,Byte,KB,MB,GB, TB ,PB, EB, ZB ,YB, BB ,NB, DB,每个单位之间都是1024的换算。
对于大数据的例子,最现实简单的就是在某音,假如你喜欢看美女,大数据就会记住你这个爱好然后就会精准推荐美女给你。
大数据的应用场景还有人工智能,无人驾驶。虚拟现实,远程医疗,物联网等。
2.1 大数据特点(4V)
2.1.1 Volume(大量)
如何是大量的,看这些数据,截止2021年以前人类的所有印刷总的数据量大约是200PB,全人类说过话的数据量大约为5EB,有些大企业的数据量达到了EB量级。
2.2.2 Velocity(高速)
在海量的数据面前,处理数据的效率就是企业的生命。比如2020年96秒,天猫天猫双十一交易额超过100亿,简简单单先完成一个小目标。
2.2.3 Varity(多样)
数据多样性可以分为结构化数据和非结构化数据。相比数据库和文本等结构化数据存储来说,对非结构化数据,例如网络日志、音频、视频、图片、地理位置信息等,这些多类型数据的处理能力提出了更高要求。
2.2.4 Value(低价值密度)
价值密度的高低与数据总量的大小成反比,比如,在一天监控视频中,我们只关心某一分钟的操作,因此如何快速对有价值数据“提纯”成为目前大数据背景上有待解决的难题。
二. hadoop入门概述
2.1 什么是hadoop
2.1.1 概念
hadoop是一个分布式系统基础架构,主要解决数据存储与海量分析计算的问题,广泛来说,hadoop通常指的是Hadoop生态圈。
2.1.2 hadoop优势
主要分为4个方面。
- 高可靠性:hadoop底层维护多个数据副本,即使当hadoop某个计算元素或存储出现故障,也不会导致数据丢失。
- 高扩展性:集群间分配任务数据,可方便扩展数以千计的节点。就是动态的增加服务器的节点,保证每个节点正常运行,不会宕机。
- 高效性:在MapReduce的思想下,hadoop是并行工作的。可以加快任务处理速度。
- 高容错性:能够将失败的任务重新分配。
2.1.3 hadoop不同版本区别
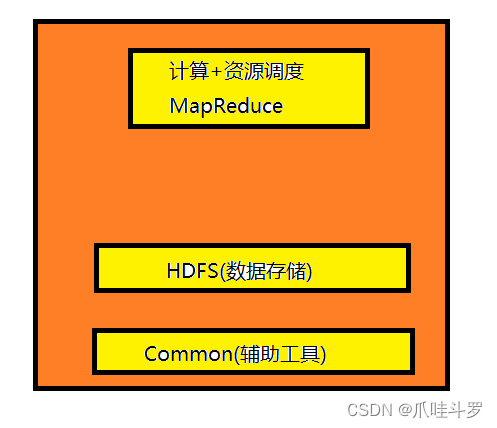
对于hadoop系列主要有1.x,2.x,3.x的版本。组成结构也是不同的,对于1.x组成主要是MapReduce(计算+资源调度),HDFS(数据存储),Common(辅助工具),如下图:
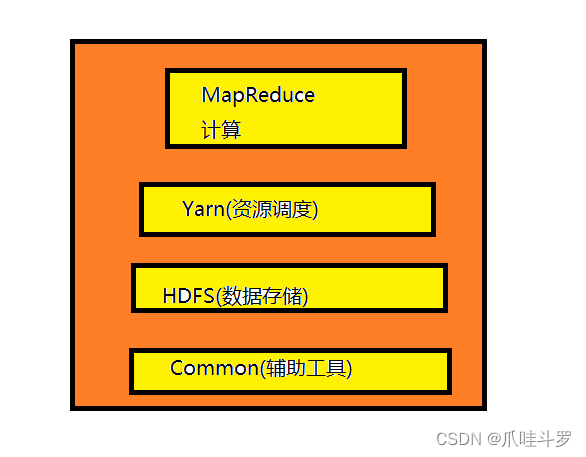
对于2.x与3.x组成主要是MapReduce(计算),Yarn(资源调度),HDFS(数据存储),Common(辅助工具),如下图:
2.2 HDFS架构概述
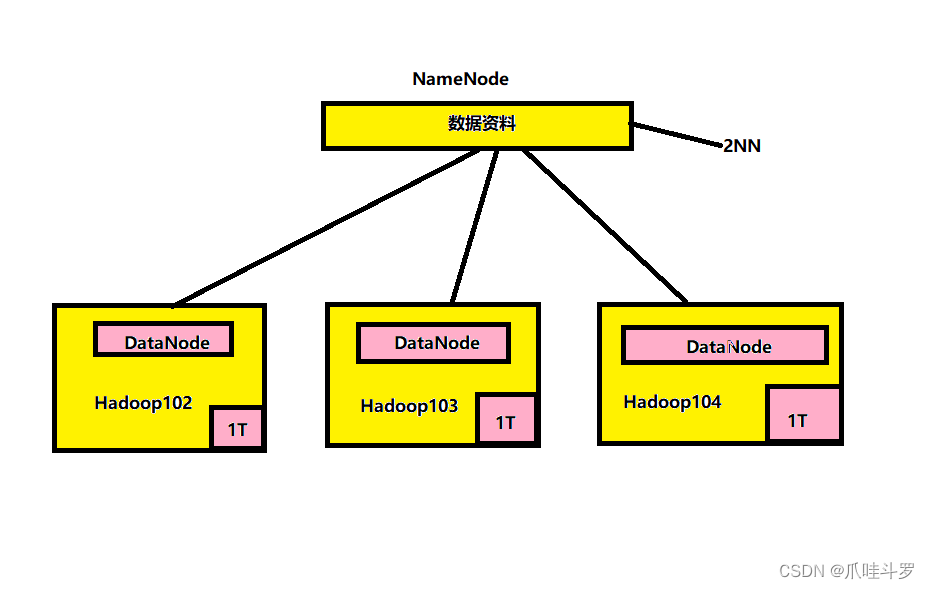
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。对于HDFS主要有以下几个概念。
NameNode(nn):存储文件的元数据,比如文件名,目录结构等,以及每个文件的块列表与块所在的DataNode,表示数据存在什么位置。
**DataNode(dn):**在本地文件系统存储文件块数据,以及块数据的校验和,表示具体的存储数据。
3.**Secondary NameNode(2nn):**每隔一段时间对NameNode元数据备份。防止NameNode宕机后集群瘫痪。
2.3 Yarn架构概述
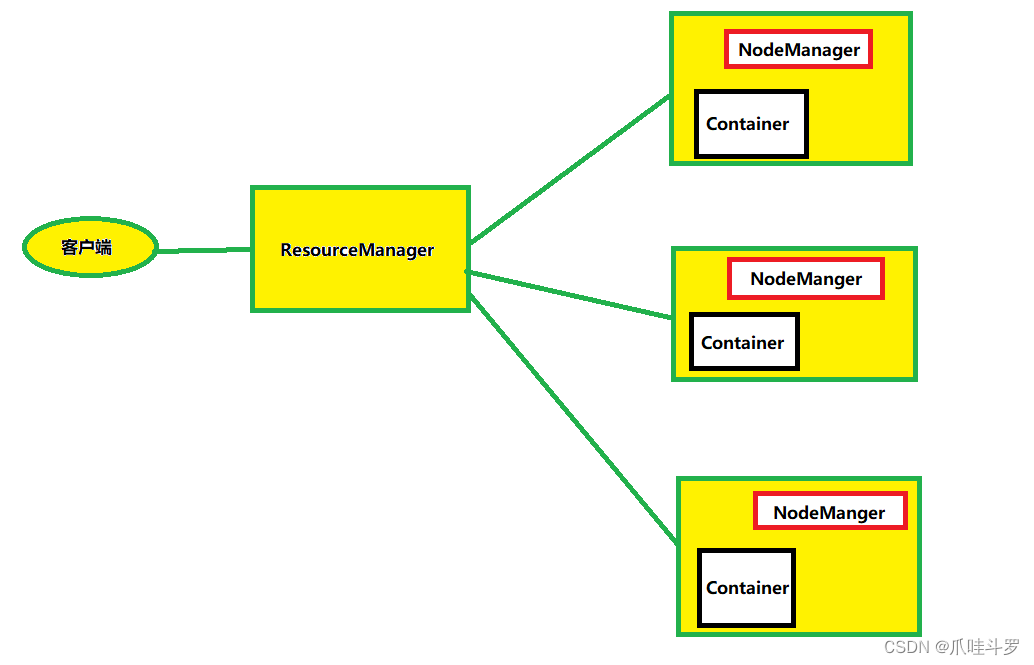
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器,主要管理CPU与内存。有以下几个概念:
ResourceManager(RM): 整个集群资源(CPU,内存)的老大。
NodeManager(NM): 单个节点服务器资源老大。
3.ApplicationMaster(AM):单个任务运行的老大。
- **Container:**容器相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存,CPU,磁盘网络等。
2.4 MapReduce架构概述
MapReduce将计算过程分两个阶段,Map与Reduce,Map阶段用于并行处理输入数据,Reduce阶段对Map结果进行汇总。
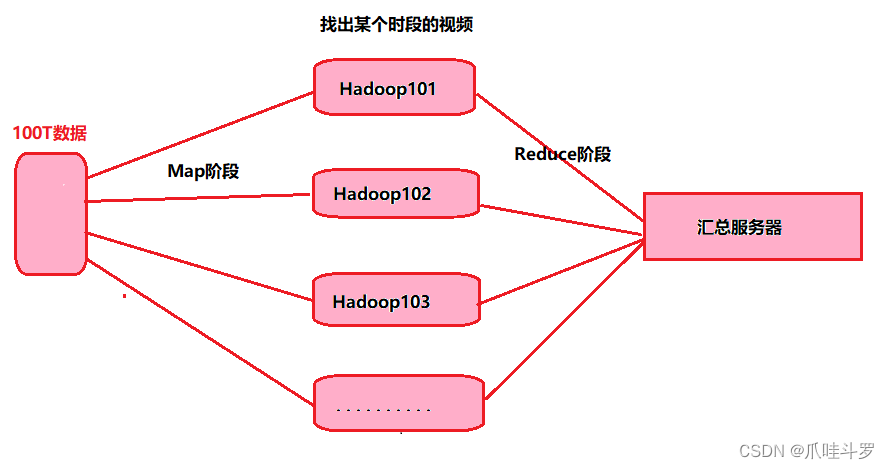
2.5 三者关系
上面将三者(MapReduce,HDFS,Yarn)拆出进行了一个说明,如下图所示,下面将三者进行结合起来说明一下看看Hadoop到底是如何工作的。
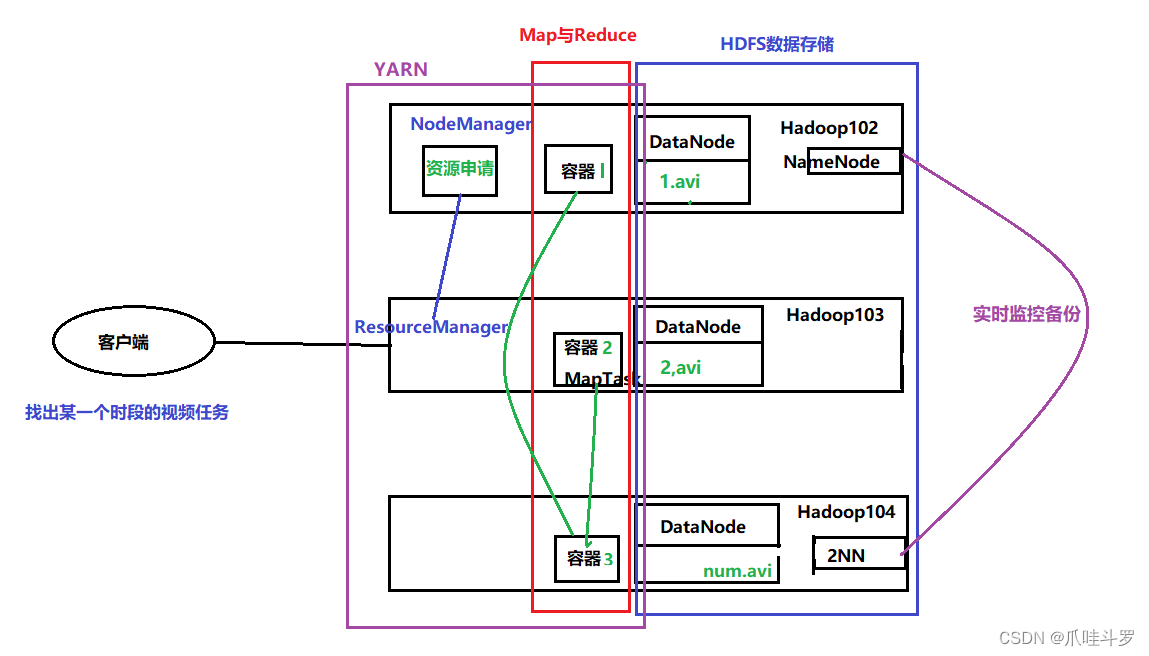
假设现需在100T数据中找找出某一时段视频数据,这时YARN接收到客户端请求后每个Hadoop节点NM会向RM(上述已提到)申请资源。
开启子任务后在HDFS文件系统中找到匹配的数据(这一阶段由MapReduce完成)计算过后将数据存储在Hadoop中,同时2NN也会做出相应的备份。
三. Hadoop运行环境搭建
搭建Hadoop基本的环境前需要下载Vmware虚拟机与Centos7镜像(此操作请自行完成)
3.1 固定IP地址与主机名称配置
对于NAT网络环境的改变的情况,需要将每台虚拟机节点的IP地址进行固定,如下操作:
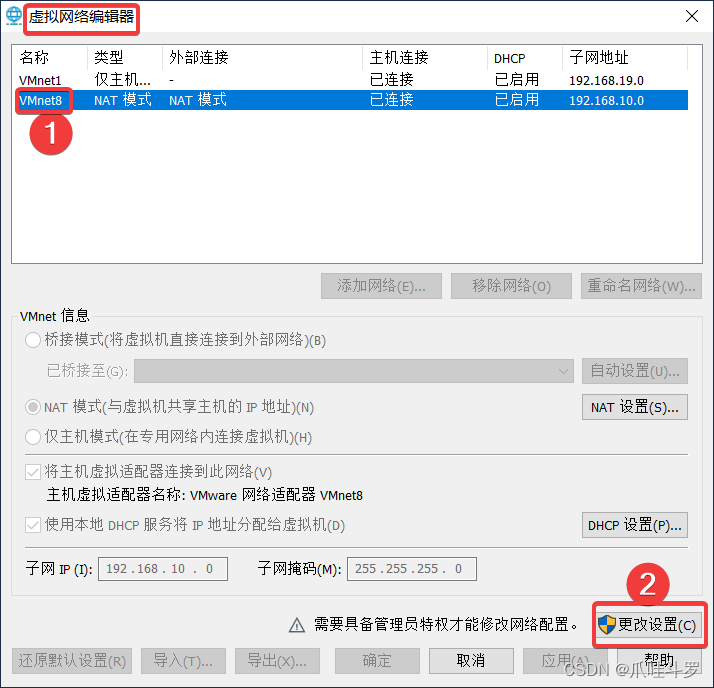
首先找到Vmware中的虚拟网络编辑器打开后进行上图的操作后出现下图:
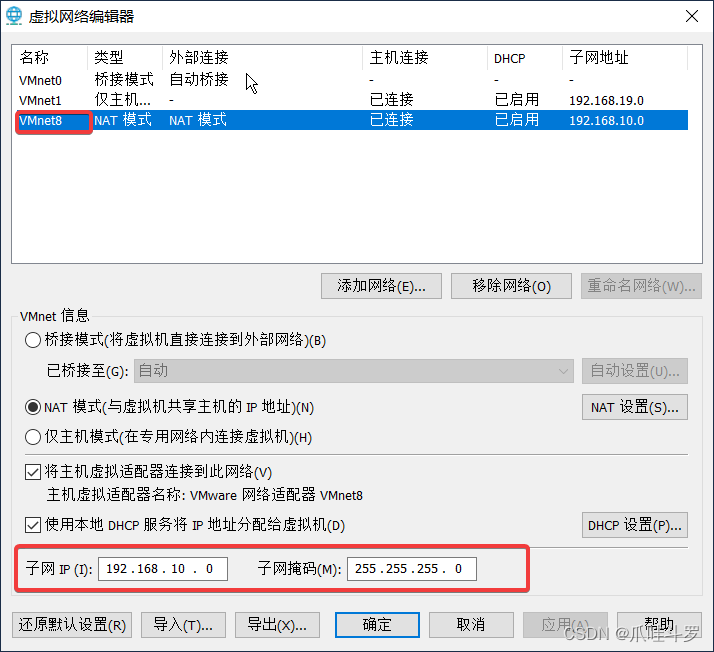
按照步骤将子网IP与子网掩码修改成上图,也可以是别的IP地址只要和别的IP不冲突就可以,确定后按照步骤,打开本机的【更改适配器选项】进行下图操作:
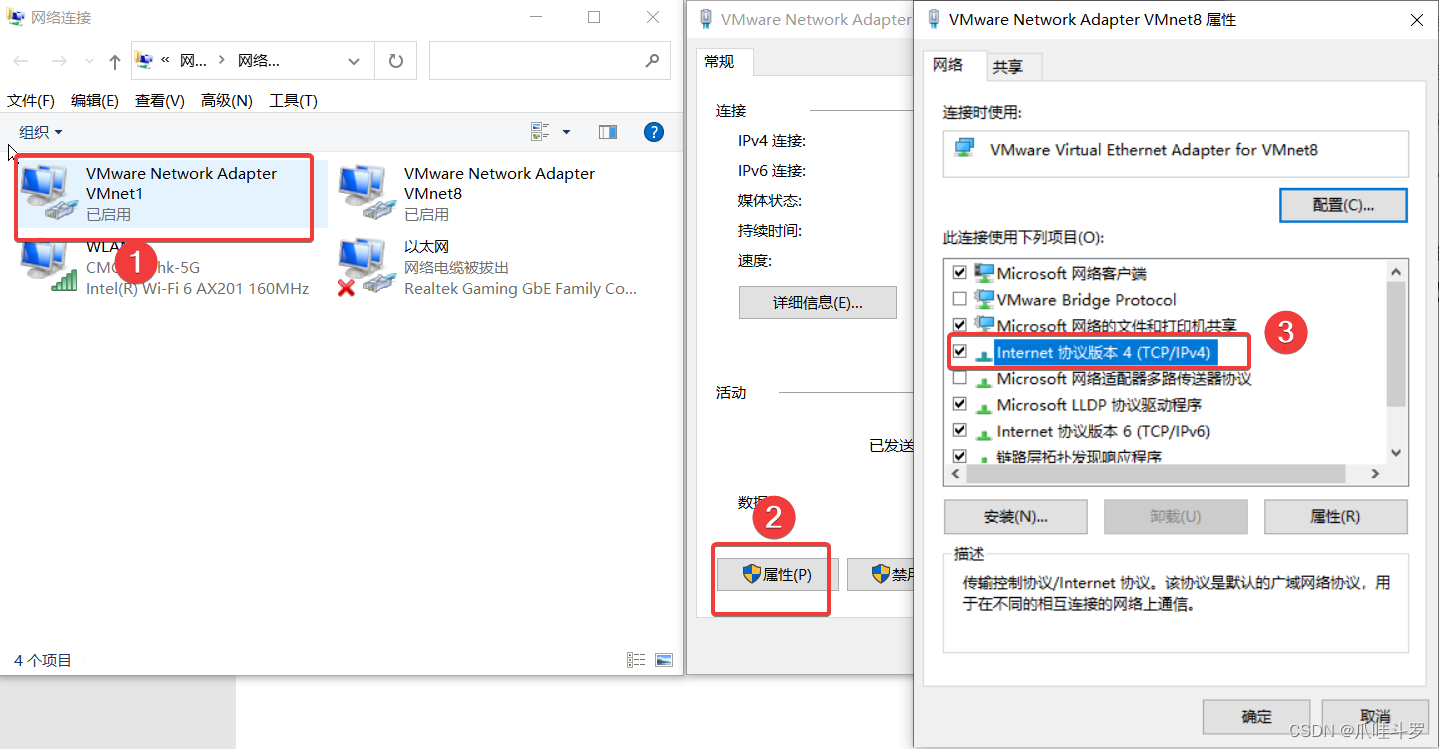
双击3打开,修改对应的参数如下:
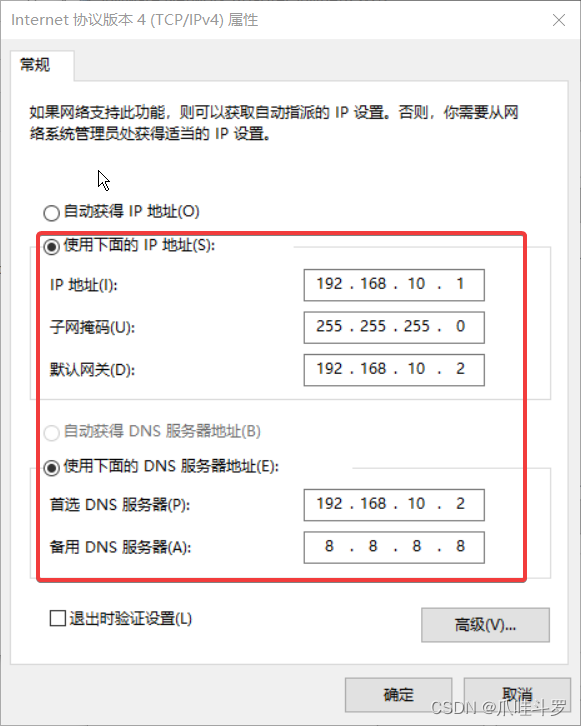
完成上述操作之后,回到虚拟机,打开终端输入以下指令进入网络配置文件:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
HWADDR=00:0C:29:49:34:70
#网络类型:默认
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
#IP配置:这里改为static为静态配置
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=$'\746\634\611\747\672\677\750\677\636\746\616\645 1'
UUID=537cc596-85c7-3c9a-a1c8-96f79f77be26
ONBOOT=yes
AUTOCONNECT_PRIORITY=-999
#IP
IPADDR=192.168.10.102
#网关
GATEWAY=192.168.10.2
#域名解析器
DNS1=192.168.10.2
注意****:有的打开此命令后会出现空的目录,那是因为每个人的机子上的文件不一定是叫做ifcfg-ens33这个名字,可能是叫ifcfg-xxx(xxx表示其他文件名称),此时需要在network-scripts文件夹下建一个ifcfg-ens33然后将ifcfg-xxx的配置拷贝到ifcfg-ens33中,然后加入配置IP,网关与域名解析器。然后重新执行ifconfig命令后看ens33的本地IP是否和配置文件中的IP一致。
修改主机名称:在**/etc/hostname**下修改即可。
记住执行上述操作后需要重启(reboot)配置才可生效。
3.2 增加用户给用户添加root权限
增加用户
useradd zhangsan
增加root权限
执行命令vim /etc/sudoers修改sudoers文件,在最后一行加入。
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
zhangsan ALL=(ALL) NOPASSWD:ALL
为啥设置在最后一行?**%wheel**表示任何成员都在此组下,若设值在最后优先级较高导致之后配置的用户不会生效。
3.3 克隆虚拟机
虚拟机的克隆操作也很简单:选中要克隆的虚拟机,点击克隆。
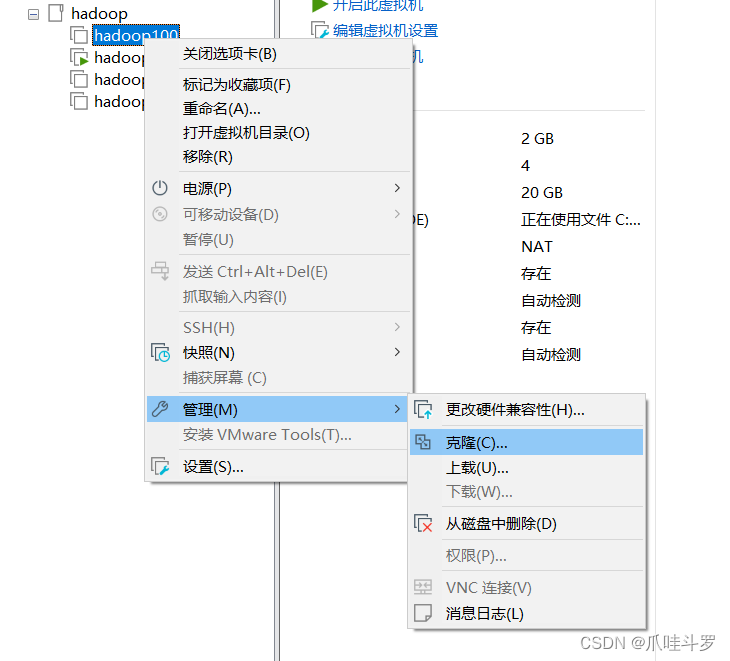
一直下一步,值得注意的是,到克隆类型这一步选创建完整克隆,然后下一步命名虚拟机,选择存放位置即可。
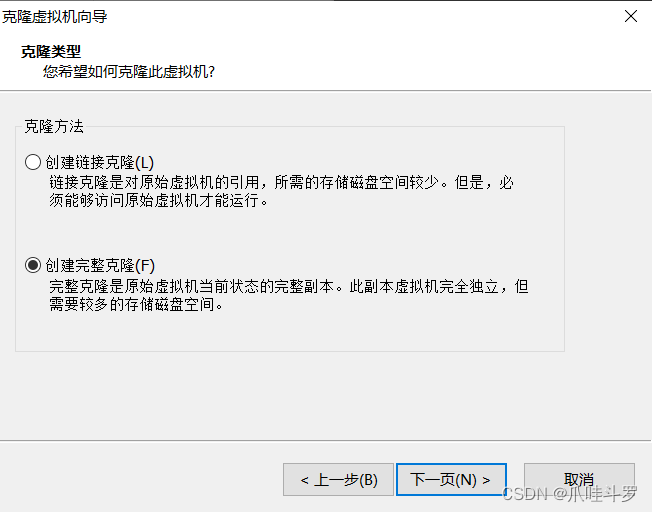
按照此步骤克隆出三台虚拟机,并根据之前的3.1步骤配置Hadoop102,Hadoop103,Hadoop104三台。
3.4 在Hadoop102上安装JDK
可以借助Xftp工具将JavaJDK从本地上传到虚拟机的文件夹中,然后进行安装,安装时需要卸载原本的JDK,这里选择JDK1.8进行安装。
将JDK1.8进行解压操作:
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
配置环境变量,在**/etc/profile.d自定义一个配置文件my_env.sh**
vim /etc/profile.d/my_env.sh
添加JAVA环境变量:JAVA_HOME配置JDK路径,PATH配置bin路径即可。
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
自己建立的配置文件需要执行source /etc/profile才可生效。
3.5 在Hadoop102上安装hadoop3.1.3
使用3.4同样的方法解压hadoop3.1.3之后,在my_env.sh文件中添加对应的环境变量,不要忘记执行source /etc/profile.
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
四. Hadoop运行模式
4.1 运行模式
Hadoop运行模式主要分为三种本地,伪分布式,完全分布式。常用的还是完全分布式。
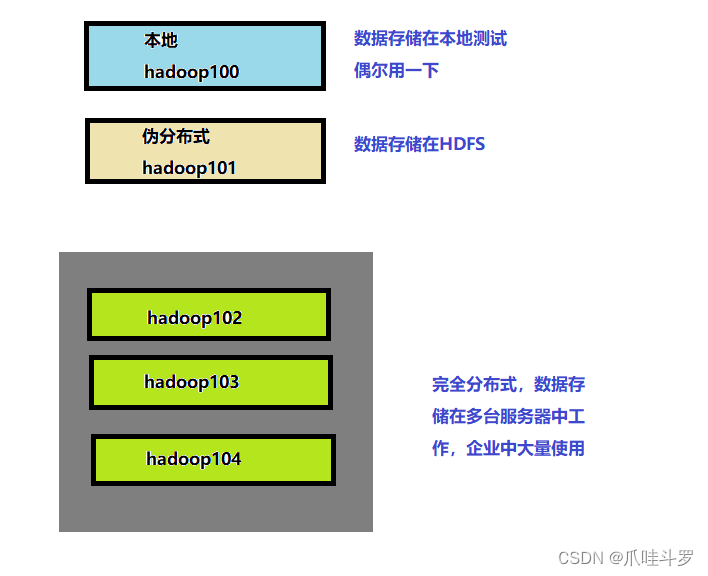
关于本地运行模式,看一个案例:统计文本中单词出现的次数。
随便建一个文件写入几个单词,来到hadoop的安装根路径下执行:主要前后需要指定输入与输出的路径,不然会抛出异常。
hadoop jar share /hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount wcinput/ wcoutput/
查看输出路径wcoutput/下的part-r-00000文件就是统计出的单词数量。
4.2 完全分布式的搭建(重点)
上面已经将JDK与Hadoop环境安装到Hadoop102服务器上,现在需要通过Hadoop将两者复制到Hadoop103与Hadoop104上,使用集群分发脚本xsync来完成。
4.2.1 编写集群分发脚本xsync
1. scp(secure copy)安全拷贝
scp用于实现服务器之间数据拷贝,基础语法如下:
scp -r 所在服务器文件名路径 目标服务器下的文件夹(username@xxxx:/opt/)
将hadoop102上的JDK拷贝到hadoop103上:执行此命令之前103服务器下的moudle文件必须有访问权限,并且还要将**/opt/module/目录修改为tongbing:tongbing**
sudo chown tongbing:tongbing -R /opt/moudle
scp -r jdk1.8.0_212/ tongbing@hadoop103:/opt/module/
hadoop是同理,这里不在赘述。
scp的强大之处不仅仅如此,例如可以实现在103服务器进行操作,将102服务器文件复制到104服务器上。实现你就是我,我就是你。
scp -r username@hadoop102:/opt/module/* username@hadoop104:/opt/module/
2. rsync远程同步工具
用于备份与镜像,特点是速度快,避免复制相同内容和支持符合链接的优点。
rsync与scp的区别就是,rsync文件复制比后者快,rsync只对差异的文件做更新,scp是把所有的文件复制过去。
语法:
rsync -av 所在服务器文件名路径 目标服务器下的文件夹(username@xxxx:/opt/)
-a表示归档拷贝,**-v**表示显示复制过程。
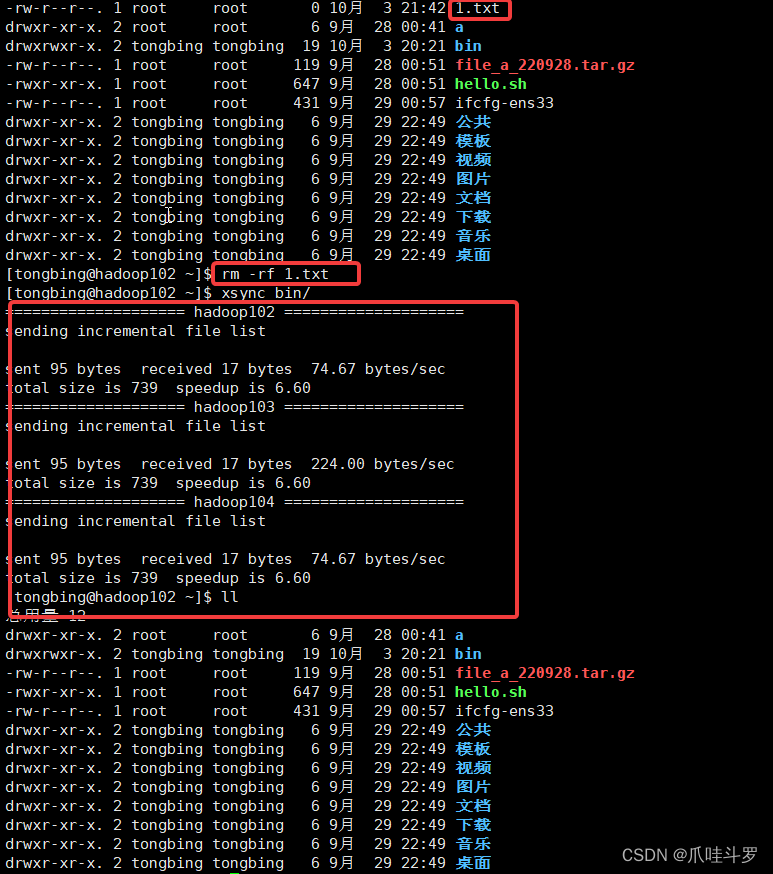
操作:将102号机下的wcinpt文件夹删除后,用103号机进行同步。
rm -rf wcinput/
rsync -av hadoop-3.1.3/ tongbing@hadoop102:/opt/module/hadoop-3.1.3/
3. xsync集群分发****脚本
对每个集群中所修改的文件进行一个一个路径的配置,开发过程中耗时是很大的,现在的需求就是循环复制文件到所有节点的相同目录下,做到一个节点服务器文件的修改可以应用到整个集群的节点服务器上。
注意xsync是我们自己所定义的,要想全局使用还需配置它的环境变量,并且将写的脚本文件放在当前用户的bin目录下即可。
执行echo $PATH看一下:是否有**/home/tongbing/bin若没有,到之前的my_env.sh**文件配置。
[tongbing@hadoop102 hadoop-3.1.3]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:
/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:
/home/tongbing/bin:/home/tongbing/.local/bin:/home/tongbing/bin
/home/tongbing/bin下创建的脚本文件xsync(无需带sh后缀)内容:
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
完成上步操作之后,给它赋予可执行的权限:
chmod +x xsync
测试一下:将102机的某个文件删除,然后同步到103,104号机如下图操作。
4.2.2 SSH免密登录
我们可以使用**ssh hostname(服务器名称)**来访问其它服务器,此时你需要输入密码。这样做会很繁琐,实现无密登录就十分方便。
实现原理就是本地服务器生成一对公钥与私钥,私钥属于自己,公钥可以保存至其他服务器,当需要访问其它服务器的时候,只需拿出自己的私钥与其它服务器上是否有自己的公钥进行匹配即可。
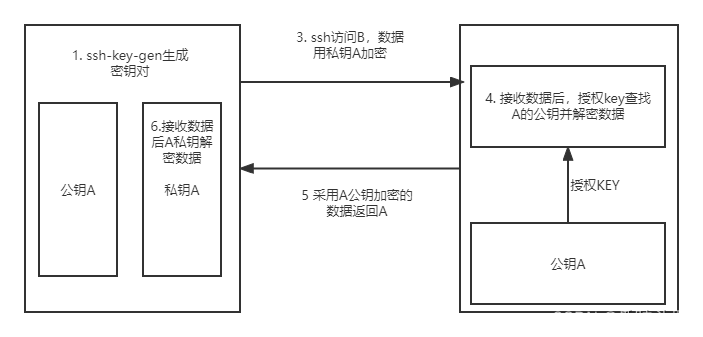
使用命令在102上生成私钥与公钥:这时在家目录下就会生成公钥与私钥。
ssh-kengen -t rsa

将公钥拷贝到103与104上:
ssh-copy-id hadoop103
ssh-copy-id hadoop104
其它节点做重复的操作即可。
4.2.3 入门集群配置
1. 集群部署规划
集群规划注意:
- NameNode不要与SecondaryNameNode不要安装在同一台服务器上。
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
现在需要构建以下集群的配置:

2. 配置文件说明
hadoop为我们提供了核心的配置,HDFS,YARN,MapReduce的配置文件:
**【core-default.xml】 【hdfs-default.xml】 **
【yarn-default-xml】 【mapred-default.xml】
有时候默认的配置并不能满足需求,所以hadoop也提供了自定义的配置文件有:
【code-site.xml】【hdfs-site.xml】【yarn-site.xml】【mapred-site.xml】四个配置文件存放在**$HADOOP_HOME/etc/hadoop**这个路径上。
3. 集群配置
核心配置文件配置core-site.xml将NameNode配置到102上:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
</configuration>
hdfs-site.xml文件中配置SecondaryNameNode:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
配置yarn-site.xml指定ResourceManager的地址:
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
配置mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
然后使用xsync将配置同步至103,104。
4.2.4 群起集群
1. 配置workers
将集群中的所有节点连接起来需要配置,hadoop文件夹下的workers,注意不能有空格。配置完成之后记得节点间的同步。
hadoop102
hadoop103
hadoop104
2. 启动集群
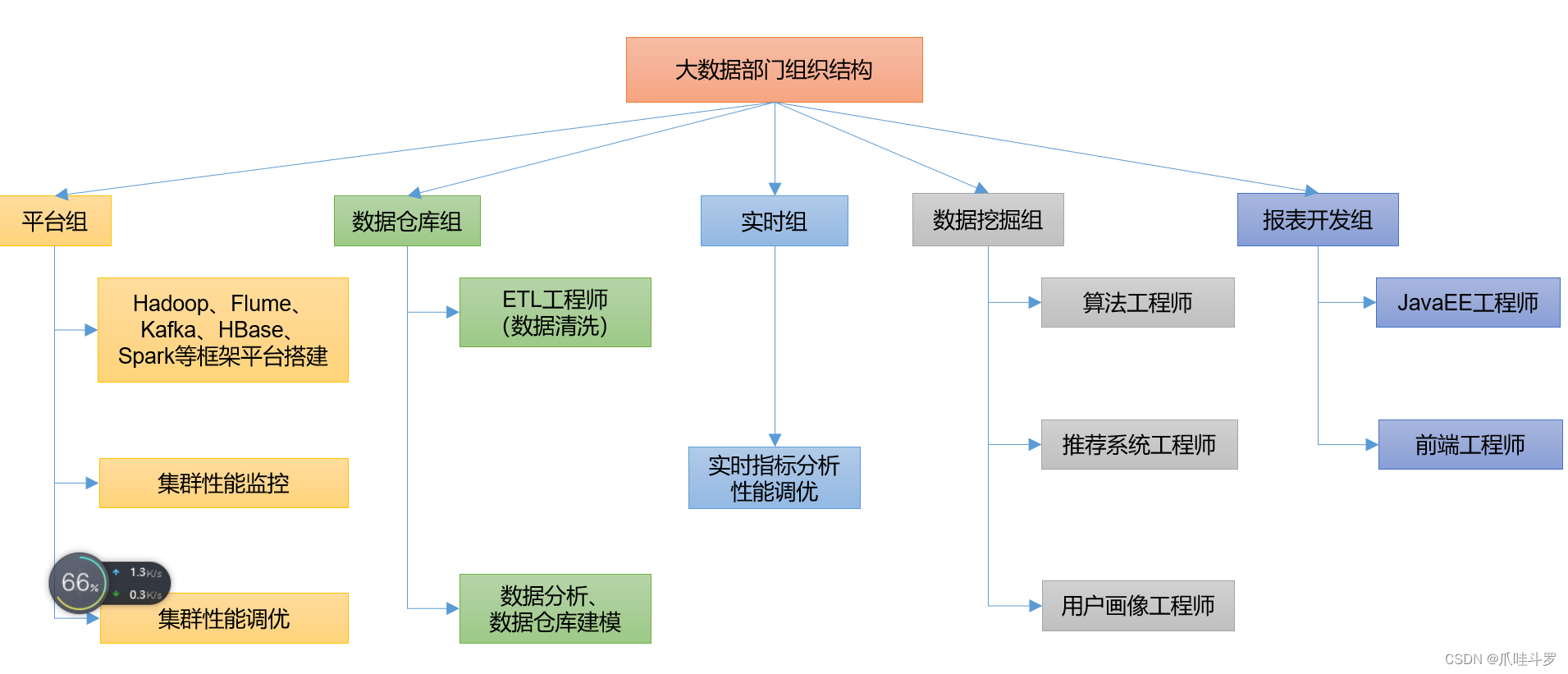
附件:大数据部门组织结构图
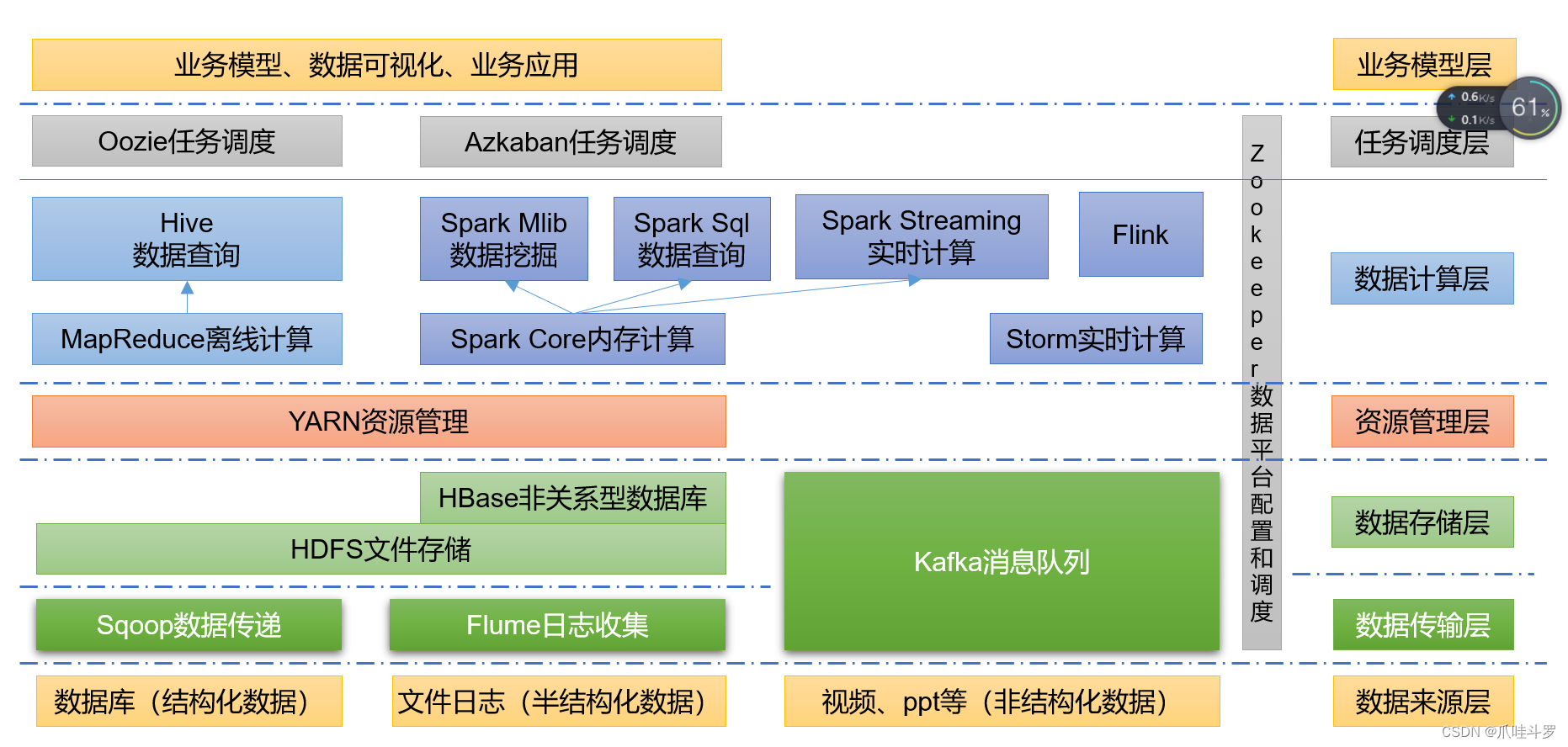
附件:大数据生态体系图
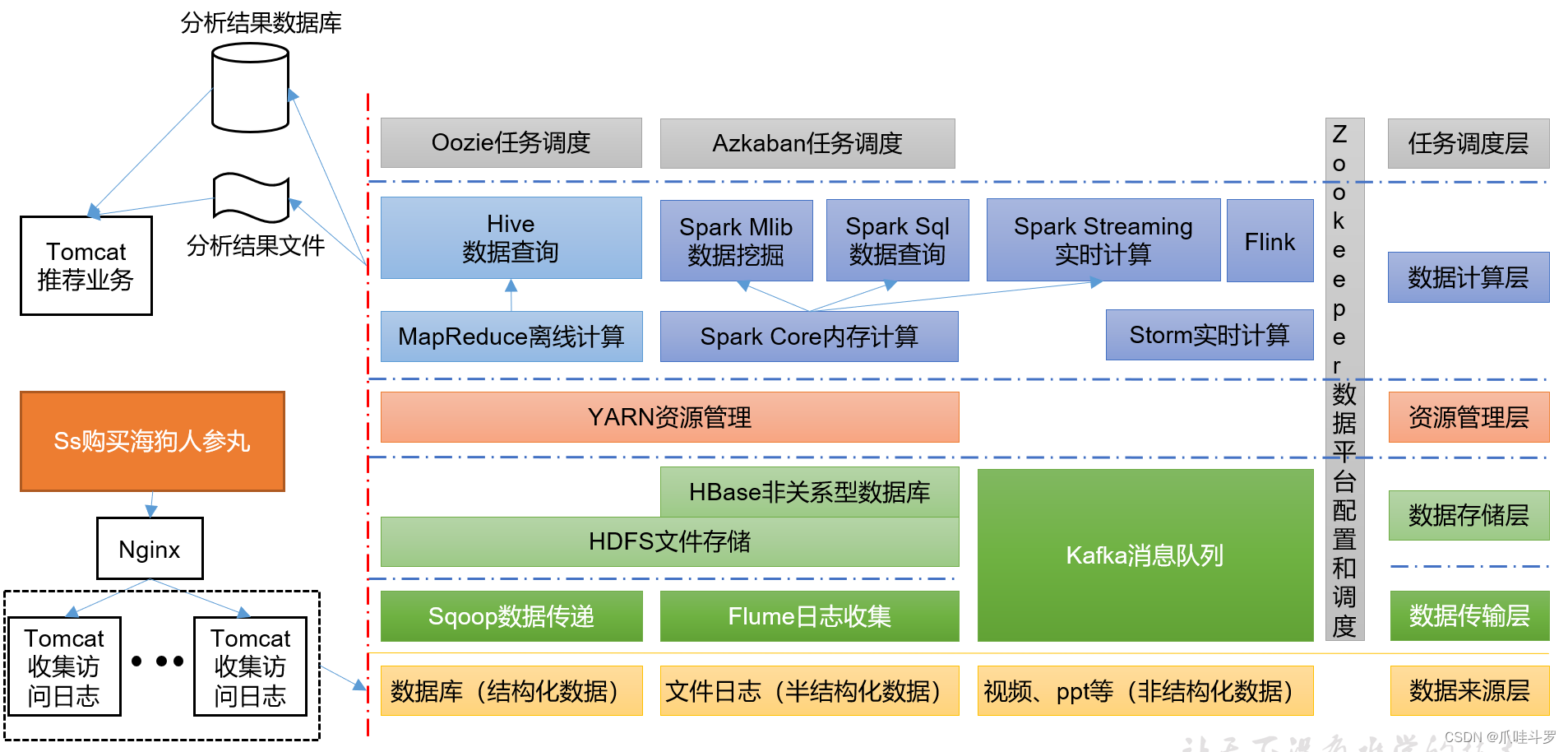
附件:推荐系统项目框架图
版权归原作者 爪哇斗罗 所有, 如有侵权,请联系我们删除。