
有些时候我们在处理数据之后就会想将我们的数据保存到文件中,实现数据的持久化。而不仅仅是输出到我们的集成开发环境的控制台上(直接打印在控制台上并不能够实现保存我们数据的功能,只要我们的集成开发环境已关闭,或者是电脑关机,那么我们打印出来的数据也会随之消失),例如我们在使用print函数打印输出数据时,只是将我们的数据暂时存放到了内存中,并没有存放到硬盘上。数据的持久化方式有两种,一种是存放到数据库中(这种方式一般是二进制的数据才可以,如音视频等),另外一种就是以文件的形式(这种方式,可以存放文本字符数据,如中文字符等)。
我们一般使用代码处理的数据都是非结构化的数据,即存放的位置位置是文件里面,而不是数据库里面。
涉及到文件处理的代码或者是相关的操作,在计算机中一般称之为文件流操作。文件流的操作有文件的读取和文件的写入两个操作。然后我们操作的对象可以是字节流对象(处理的是二进制文件)也可以是字符流对象(处理的是文本文件)。
字节流的数据读取和字符流的数据读取不同,因为字节流不用考虑编码格式问题,而我们的字符流数据因为会有中文数据的存在,所以需要考虑到将编码格式修改成utf-8的格式。
一,文件的打开和读取
文件的打开,关闭与读写是文件的基本操作,需要注意是:数据写入完毕后需要将文件进行关闭,不仅是用来释放我们的计算机内存,也是为了我们后期在对文件进行其他操作时候可以执行成功,如果我们打开了一个文件,但是却没有去关闭,那么我们的程序就会默认我们的文件是打开,然后不管我们在对文件进行什么操作,都不会成功。说得再多,不如直接撸码来得直接,现在我们去使用代码来看一下具体的使用和效果:
1,打开文件
if __name__ == '__main__':
f_or=open(r"F:\novels\English\computer.txt") # 以只读的方式打开文件
print(f_or) # 若文件打开成功(函数调用成功),返回一个文件对象

我们现在只是简单的使用了open函数,并在里面传入了我们的文件路径进去即可实现打开文件的功能,然而事实上,该函数里面不止一个文件路径参数,还可以传入我们要使用的编码格式(encoding="")来打开我们的文件,以及打开后希不希望外界去修改我们的文件(mode="",如果不指定打开的模式,则默认使用只读模式打开文件)。那么文件的其他打开模式有哪些呢?我们来看如下表格:
r/rb只读模式。打开文件后只能读取,若文件不存在,则打开文件失败w/wb只写模式。若文件存在重写文件,否则创建该文件r+/rb+读取(更新)模式。若文件不存在,则打开文件失败w+/wb+读取(更新)模式。若文件不存在,则创建文件,已存在,则重写文件a/ab追加(更新)模式。以追加方式打开文件,只允许在该文件末尾追加数据,若文件不存在则,则创建新文件a+/ab+追加(更新)模式。和a/ab的使用差不多,作用一样
后面带有b的表示以二进制方式打开文件,+表示以更新的方式打开文件。
我们的mode关键字可以省略,直接传入文件的打开模式也是可以的。我们先做个了解,知道里面可以传入这些参数,我们认识了另外一个写入函数之后,再去对比一下这些mode打开模式的异同。
2,文件读取
1)使用read函数读取文件内容
①读取文本字符出现乱码,指定编码格式为utf8
如下,当我们使用如下代码打开我们含有字符文件 时,会发现无法正常显示出来中文内容,并出现了乱码:
if __name__ == '__main__':
f_or=open(r"F:\novels\English\textdemo.txt",'r') # 以只读的方式打开文件
print(f_or.read())
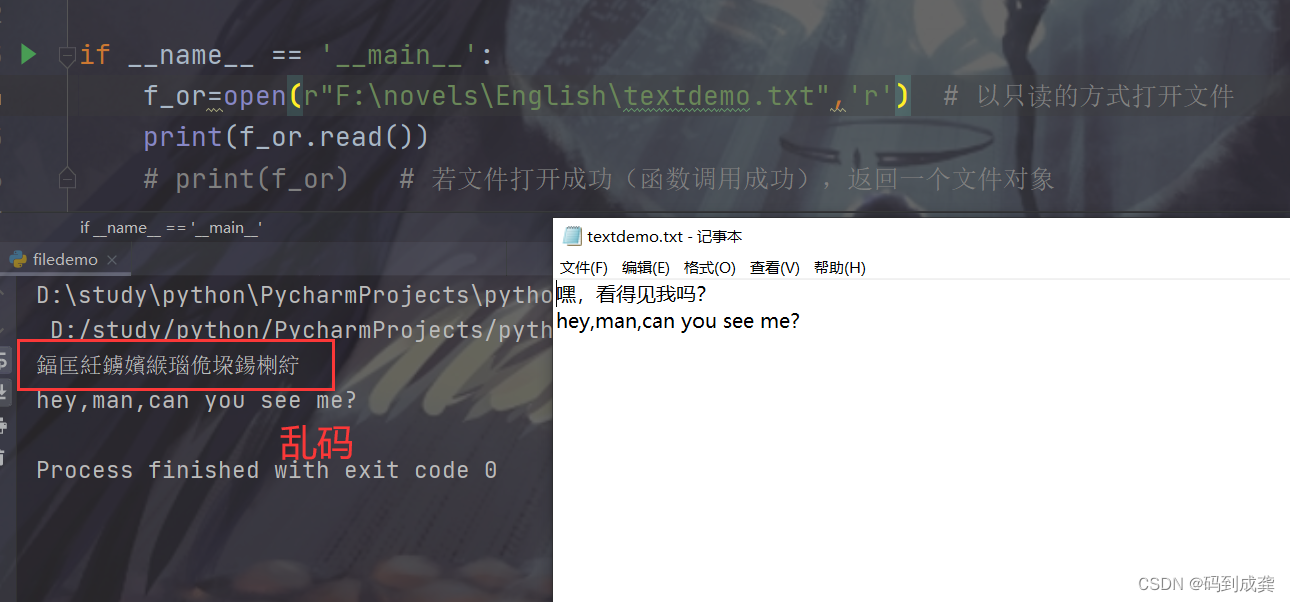
那么我们该如何去去掉这个乱码?其实很简单,只需要在open函数最后再传入encoding="utf8"即可,如下:
if __name__ == '__main__':
f_or=open(r"F:\novels\English\textdemo.txt",'r',encoding="utf8") # 以只读的方式打开文件
print(f_or.read())

在上面我们使用了read函数读取了文件textdemo.txt,我们使用的是默认的read方法,即不传入参数(或者是设置为-1),则一次性读取并返回文件中的所有数据。
如果我们在里面传入了参数值(数值类型),即设置了读取数据的字节数,那么就会读取文件中指定长度的数据:

2)使用readline函数读取文件内容
该函数只可以从指定文件中读取一行数据,如下:
if __name__ == '__main__':
f_or=open(r"F:\novels\English\textdemo.txt",'r',encoding="utf8") # 以只读的方式打开文件
print(f_or.readline())
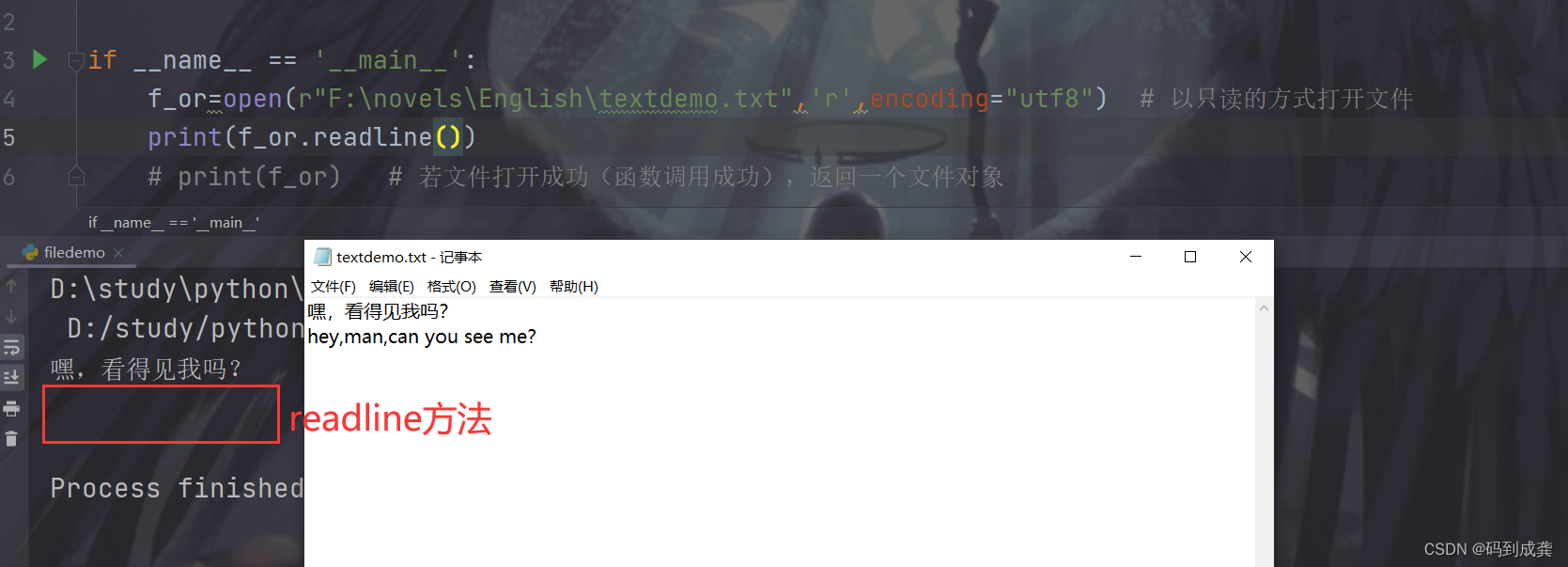
如上我们可以看到,我们使用readline方法读取文件只会返回第一行的数据内容,之后换行的数据并不会返回,如果想要返回第二行的数据,我们可以给一个循环,重复调用该函数,或者是写两次print函数来打印:
1,调用两次print函数:
if __name__ == '__main__':
f_or=open(r"F:\novels\English\textdemo.txt",'r',encoding="utf8") # 以只读的方式打开文件
print(f_or.readline())
print(f_or.readline())

2,使用for循环语句:
if __name__ == '__main__':
f_or=open(r"F:\novels\English\textdemo.txt",'r',encoding="utf8") # 以只读的方式打开文件
for i in range (1,3):
print(f_or.readline())

3)使用readlines函数读取文件内容
如果我们使用readlines方法取读取文件数据的话返回的就是个列表数据,在这一点上与之前的read方法和readline方法都很不同,它从之前的字符数据类型变成了列表类型的数据:
if __name__ == '__main__':
f_or=open(r"F:\novels\English\textdemo.txt",'r',encoding="utf8") # 以只读的方式打开文件
print(f_or.readlines()) # 读取成功,返回一个列表

如上,我们可以看到,使用readlines方法返回的确实是列表类型的数据,结合之前学习的列表数据相关的知识,我们如果想要取出来数据的话可以使用遍历的方式取获取。
3,总结三个读取文件的方法
以上介绍了3个读取文件的方法,当我们的read函数不传入参数时,实现的效果就会和readlines方法是一样的,两个都会一次性读取我们文件里面的数据,很多人会说这样子感情好,可以直接一次性就把我们的文件读取出来,以后直接使用这两个方法就行。实际上并不推荐这两种方法的使用,因为它适合于所读取的文件较小的时候,但是当我们的文件较大,像大数据的文件,那是可能会突破GB的文件,如果我们使用了read()和readlines()方法的一次性读取我们的文件,则可能会耗尽我们的系统内存,因为我们的计算机的内存是有限的。所以为了保证读取安全,推荐多次去调用read(n)方法---n:表示每次读取n字节的数据。
二,文件的写入及关闭
通过以上的open方法和read方法的使用,我们现在能够成功的打开一个文件,并能看到里面的内容,之后如果我们想要往该文件中写入数据内容的话,该怎么做呢?首先就需要用到一种函数---文件写入函数,我们可以使用两个函数来分别写入数据到文件中:1,write函数;2,writelines函数
1,write函数(方法)
我们先来认识write函数,该函数可以将指定字符串写入文件中,格式为:write(data)---data表示我们需要写入文件的数据(字符串),如果数据写入成功,write方法会返回本次写入文件的数据的字节数。如下,我们使用该方法来将写入数据到我们的textdemo.txt文件中:
if __name__ == '__main__':
context="The computer grade examination is divided into four levels. " # 字符串数据
f_or=open(r"F:\novels\English\textdemo.txt",'r',encoding="utf8") # 以只读的方式打开文件
f_or.write(context) # 写数据
我们的代码如上,相信大家也发现了,我们的文件打开模式还是之前的只读模式,并且在这个文件模式下调用了write方法来进行写数据操作,想想结果会怎样?没错,结果就是会报错,如下:
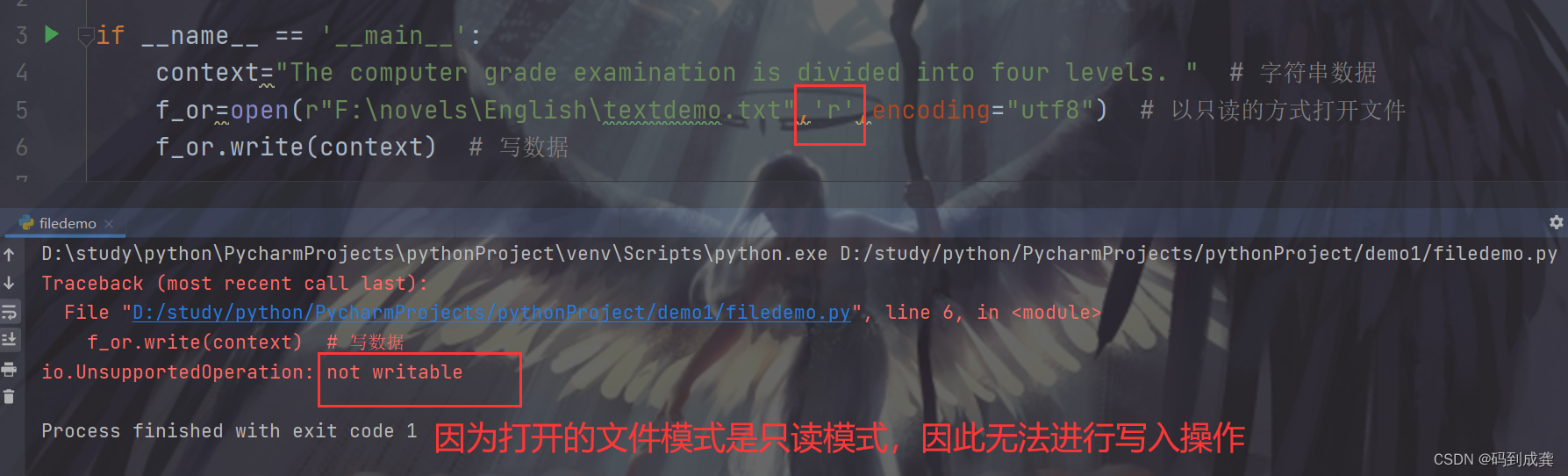
如上,因为文件用得是只读模式打开,所以我们无法进行数据写入的操作,那么,如果想要写数据又该怎么办?是的,使用r+,w/w+或者是a/a+函数:
1,r+,读写(更新)模式
该模式如果调用写入方法成功,会将之前已经存在的数据进行覆盖,并且,如果所要操作的文件 如果不存在的话就会报错。
if __name__ == '__main__':
context="r+...The computer grade examination is divided into four levels. " # 字符串数据
f_or=open(r"F:\novels\English\textdemo.txt",'r+',encoding="utf8") # 以只读的方式打开文件
f_or.write(context) # 写数据

如果我想要在写的同时,也将写进去的文件内容输出到控制台的话就可以使用read函数来读取:
if __name__ == '__main__':
context="r+...The computer grade examination is divided into four levels. " # 字符串数据
f_or=open(r"F:\novels\English\textdemo.txt",'r+',encoding="utf8") # 以只读的方式打开文件
f_or.write(context) # 写数据
print(f_or.read()) # 读数据并打印输出
f_or.close() # 关闭流,释放资源
 如上,相信细心的大家也发现代码中多了一个close方法的调用。
如上,相信细心的大家也发现代码中多了一个close方法的调用。
2,close函数(方法)
该方法主要的作用就是用来关闭文件的,它和read()方法一样,是文件对象的内置对象,可以使用close方法来关闭已打开的文件textdemo.txt。可能会有人说,我就喜欢把文件一直打开着,就不关闭,哎~~,反正看起来也没啥事发生,就是玩~~~。其实也不是不可以,但是我们计算机中可打开的文件数量是有限的,每打开一个文件,剩下可打开的文件数量就会减少1个,打开的文件是会占用系统资源的,若打开的文件过多,会降低系统性能。有些时候还会造成数据的丢失,因此,在编写代码时,应该在程序中主动关闭不再使用的文件。
但是有些时候我们写得代码多了,就会一不小心忘记了去调用close方法来关闭我们的还打开着的文件,即很容易遗漏文件关闭操作。python很贴心地为我们提供了一个with语句来预定义清理操作,实现文件的自动关闭等。使用with语句后,我们的代码可以进行如下修改:
if __name__ == '__main__':
context="r+...The computer grade examination is divided into four levels. " # 字符串数据
with open(r"F:\novels\English\textdemo.txt",'r+',encoding="utf8") as f: # 已读写(更新)的方式打开文件
f.write(context) # 写数据
print(f.read()) # 读数据并打印输出

在上面的代码中,我们将打开文件后得到的文件对象使用as后的变量f来进行接受。使用了with语句之后我们的程序中无需再使用close方法关闭文件,因为我们的文件对象在使用完毕后,with语句会自动的帮我们关闭不用的文件。如此方便的with语句还不用起来?🐕接下来我们打开文件的方式都会使用with语句。
** 2,w只写模式**
我们继续去探索文件打开模式的异同,之前知道了r,r+模式打开文件,现在我们去认识并使用w模式打开文件,如下:
if __name__ == '__main__':
context="w...The computer grade examination is divided into four levels. " # 字符串数据
with open(r"F:\novels\English\textdemo.txt",'w',encoding="utf8") as f: # 以读写(更新)的方式打开文件
f.write(context) # 写数据
print(f.read()) # 读数据并打印输出【会报错】
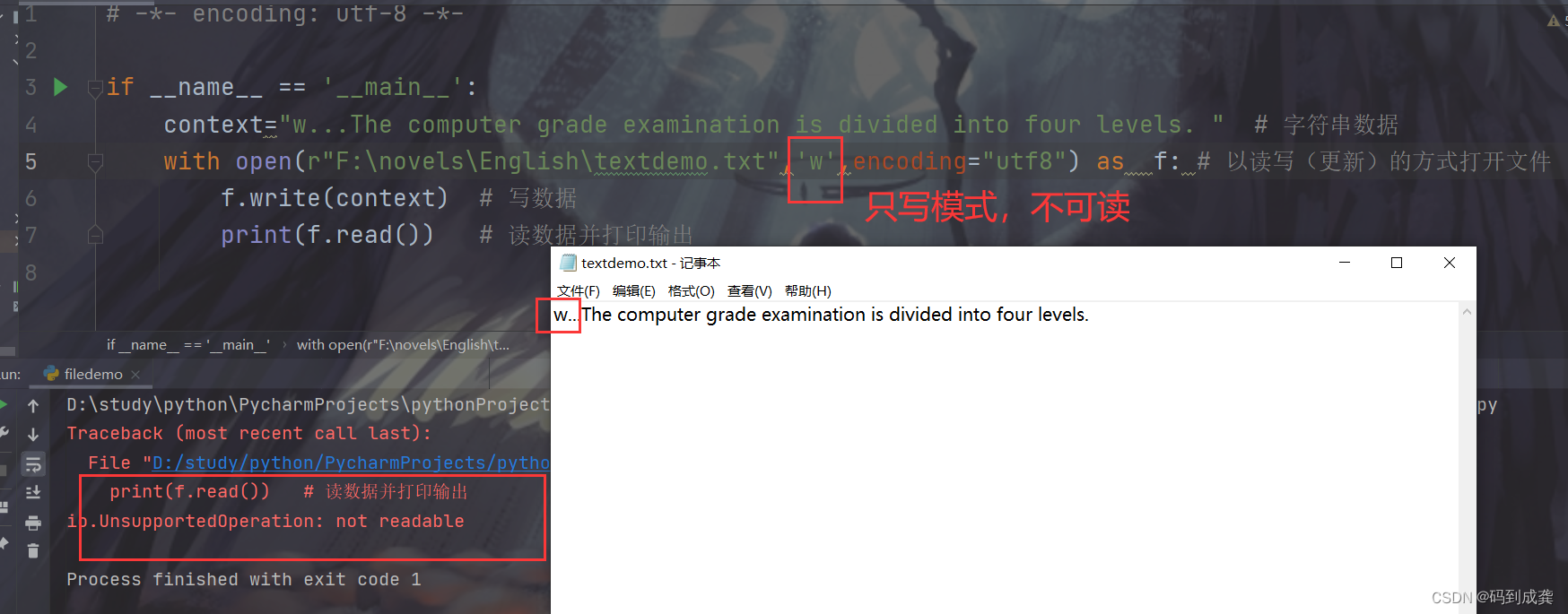
3,w+读写(更新)模式
虽然w+说是可读可写的文件打开模式,但是我们在读取文件的时候是没有返回内容的,这是个需要注意的地方,接下来我们使用代码来看一下效果:
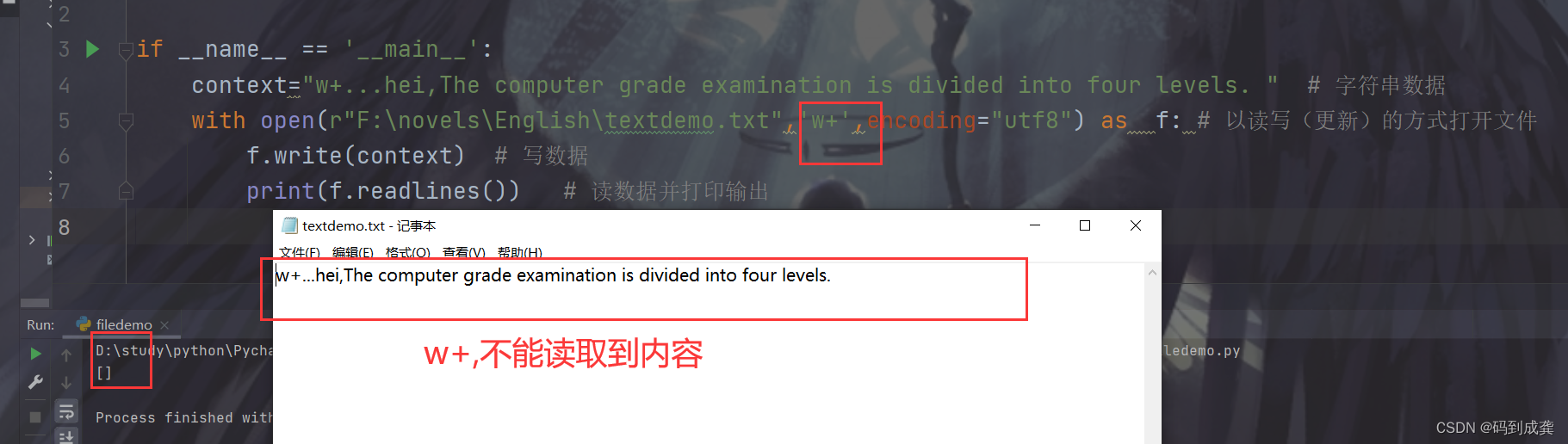
if __name__ == '__main__':
context="w+...hei,The computer grade examination is divided into four levels. " # 字符串数据
with open(r"F:\novels\English\textdemo.txt",'w+',encoding="utf8") as f: # 以读写(更新)的方式打开文件
f.write(context) # 写数据
print(f.readlines()) # 读数据并打印输出
4,a追加模式
追加模式打开的文件不能读取,且追加的内容是从第一行数据的末尾开始追加:
if __name__ == '__main__':
context="a...hei,The computer grade examination is divided into four levels. " # 字符串数据
with open(r"F:\novels\English\textdemo.txt",'a',encoding="utf8") as f: # 以读写(更新)的方式打开文件
f.write(context) # 写数据
print(f.read()) # 读数据并打印输出

5,a+追加(更新)模式
a+模式和a模式一样,用于在文件里面以追加的形式添加数据,而不是覆盖的形式,但是它也和w+一样,都是无法打印出来文件中的数据:
if __name__ == '__main__':
context="a+...hei,The computer grade examination is divided into four levels. " # 字符串数据
with open(r"F:\novels\English\textdemo.txt",'a+',encoding="utf8") as f: # 以读写(更新)的方式打开文件
f.write(context) # 写数据
print(f.read()) # 读数据并打印输出[无法打印出来]

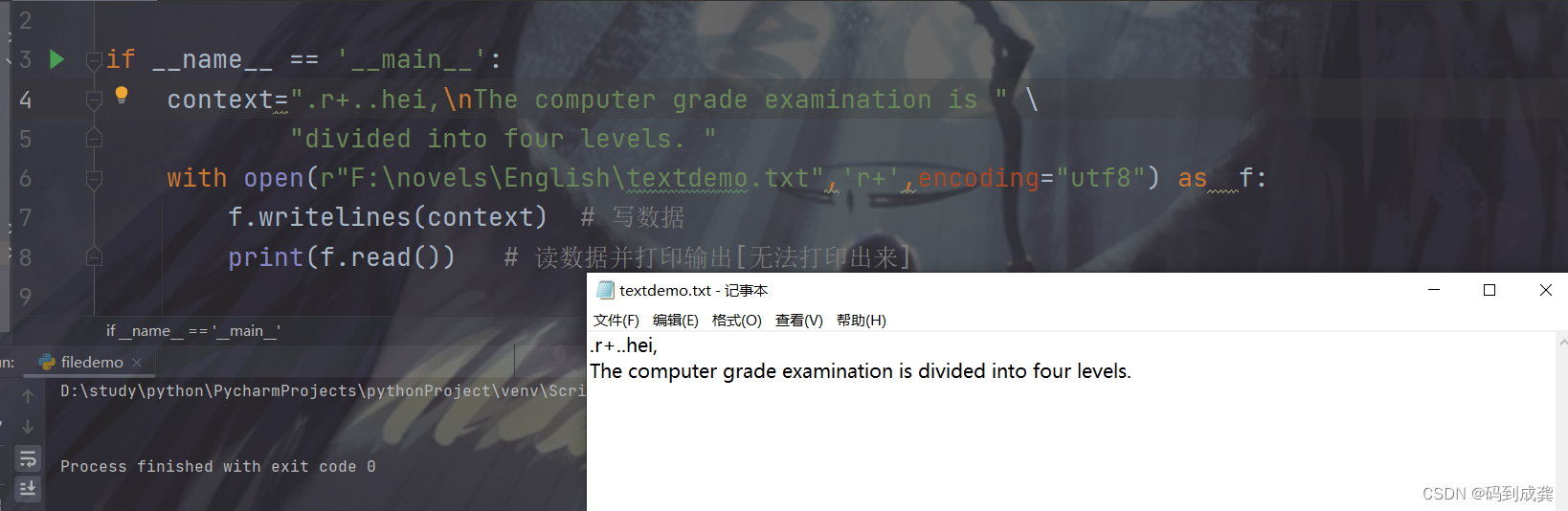
3,writelines方法
writelines方法和write方法的不同之处在于它是用于将行列表写入文件,格式为:writelines(lines)--lines:表示写入文件中的数据,该参数可以是一个字符或者是字符串列表。值得注意的是,如果写入文件的数据在文件中需要换行,应该显式指定换行符,现在我们使用代码来查看具体的实现效果:
if __name__ == '__main__':
context=".r+..hei,\nThe computer grade examination is " \
"divided into four levels. "
with open(r"F:\novels\English\textdemo.txt",'r+',encoding="utf8") as f:
f.writelines(context) # 写数据
print(f.read()) # 读数据并打印输出[无法打印出来]
以上就是文件处理的相关操作
有问题请在评论区留言。
版权归原作者 码到成龚 所有, 如有侵权,请联系我们删除。