
前言
作为一个开发实践项目,实现对HiveSQL语句的解析可以很有效的作为管理用户查询权限的管理。对于这方面的知识本身也不是非常熟悉了解,很多时候也是边学边记。身边也没有人指导这个方案具体该怎么实现怎么做,只有需求是要将复杂查询或者是关联建表的SQL语句能够将其库名和表名全都给提取出来并且能够实现上下游的追溯。这个功能最好还是用JAVA或者Scala写,毕竟Hive的底层还是JAVA写的方便,但是初步改写的话我常用语言还是python,java还是有点生疏的。因此本人是打算使用python来进行sql的血缘解析的,在网上搜索一番后发现有个系列正好是关于此方法的:系列:用python+antlr解析hive sql获得数据血缘关系。
该方法我也完全实现了但是只能对一般的sql进行解析,对于那些出现过复杂SQL关联或者是二次建表语句就会报错,无奈只能先搁置该方法一段时间,因为涉及到HiveSQL本身的grammar文件的改写,这方面确实实在难以下手而且本人对JAVA源码改写完全达不到水准...只能先记录下这次尝试,望以后有机会再来改进!
一、目标
首先我们达成的目标就是实现SQL上下游库和表的追溯从而判断用户权限是否有资格查询这张表。随之就是更加精细化能够将SQL的各类功能函数和使用到的字段给提取出来分析。目前该篇文章提到的都能实现,只是对于一些复杂sql无法实现其解析。下面我们来进行准备工作。
二、准备工作
首先是对HiveSQL有一个基础的了解以及本身SQL的执行是如何跑起来的,关于HiveSQL的源码解析我之前已经写过一篇很详细的文章用于理解了,看这篇文章就好了:
HiveSQL源码之语法词法编译文件解析一文详解_fanstuck的博客-CSDN博客_编译文件解析
那么我们就默认在这篇文章的基础之上来进行实现。
1.Hivegrammar语法文件获取
首先我们需要拿到HiveSQL关于SQL运行的所有语法文章,我们使用的Hive版本是3.1,因此我拿到的也是3.1版本的HiveSQL的grammar文件。

也就是这么几个:
其中文件名称很明显对应着各个语法定义规则。
HiveLexer.g:词法解析文件,定义了所有用到的token。HiveParser.g:语法解析文件,实现了所有的Hive语法解析。FromClauseParser.g:FROM语句解析。IdentifiersParser.g:自定义函数解析,标识符定义 函数名称、系统函数、关键字等。nonReserved,非保留的关键字可以作为标识符的。比如 select a as date from mytable 这个date不添加转义会报错的,但是该处如果添加 “ | KW_DATE ” date可直接作为标识符使用。SelectClauseParser.g:select语句解析。HintParser.g:hive的hint语法解析。ResourcePlanParser.g:资源操作语法解析。
大家可以去github上自取自己想要的版本:
2.antrl下载
这里根据自己的Hive版本来下载:版本是3.5版本,Hive版本是3.1.0
Download antlr-3.4.jar : antlr « a « Jar File Download
3.pyjnius下载
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pyjnius
4.cython下载
yum install gcc gcc-++
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple cython
三、源码改写及实现
1.修订 HiveLexer.g
打开HiveLexer文件,找到@lexer那一块你会发现Hive支持的是分布式需要把这块注释掉,否则会因为找不到hive的相关文件报错。
/**
注释掉下面这两段
@lexer::header {
package org.apache.hadoop.hive.ql.parse;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.conf.HiveConf;
}
@lexer::members {
private Configuration hiveConf;
public void setHiveConf(Configuration hiveConf) {
this.hiveConf = hiveConf;
}
protected boolean allowQuotedId() {
String supportedQIds = HiveConf.getVar(hiveConf, HiveConf.ConfVars.HIVE_QUOTEDID_SUPPORT);
return !"none".equals(supportedQIds);
}
}
增加下面这段
*/
@lexer::header {
package grammar.hive310;
}
/*
中间部分省略
下面这行要修改
| {allowQuotedId()}? QuotedIdentifier
*/
| {true}? QuotedIdentifier
他们都需要依赖hadoop的包,因为我们只是做sql的解析并不需要分布式的框架,因此设计到分布式的环节都可以注释掉。
@lexer::header和@lexer::member都是会被antlr添加到目标文件里的内容,注释掉的部分是对hive里其他部分的引用,因为我只需要lexer和parser,其他部分就不要了。
注释掉的内容里有一个allowQuotedId()的方法,语法文件里有对它的调用,也要一起修改掉。
之后我们需要将.g文件编译成java文件,后续我们处理HivePrase文件会需要。
java -jar antlr-3.5.2-complete.jar HiveLexer.g
没出意外的话会得到HiveLexer.tokens和HiveLexer.java文件 :
把生产的JAVA源代码编译成.class字节码:
javac -cp antlr-3.5.2-complete.jar HiveLexer.java
之后生产对应的class文件,那么我们就可以开始测试了:
#antlrtest.py
import jnius_config
#这里是设置java的classpath,必须在import jnius之前做,设置后进程内不能修改了
jnius_config.set_classpath('./','./grammar/hive310/antlr-3.5.2-complete.jar')
import jnius
#这3个是利用autoclass的自动装载,把java里的类定义反射到python里
#StringStream对应的是是HiveLexer构造函数必须的输入参数类型之一,ANTLRStringStream
StringStream = jnius.autoclass('grammar.hive310.ANTLRNoCaseStringStream')
#注意这里的类名,和前面.g文件里定义的package名要有对应,和HiveLexer.class所在的目录也要有对应
Lexer = jnius.autoclass('grammar.hive310.HiveLexer')
#TokenStream是要取出token时,保存token的容器类型CommonTokenStream
TokenStream = jnius.autoclass('org.antlr.runtime.CommonTokenStream')
cstream = StringStream("select * from new_table;")
inst = Lexer(cstream)
ts = TokenStream()
# antlr 3增加的步骤,Lexer和Parser之间用CommonTokenStream为接口
ts.setTokenSource(inst)
#调用fill来消费掉cstream里的所有token
ts.fill()
# jlist不能直接在python里迭代,
jlist = ts.getTokens()
tsize = jlist.size()
for i in range(tsize):
print(jlist.get(i).getText())
对于jnius不熟悉的朋友可以去看我的另一篇文章:
一文速学-Python联通调用JAVA的桥梁PyJnius库详解_fanstuck的博客-CSDN博客
里面把该库已经讲的很详细了。
最后达成效果:

这里要注意下目录别把文件放错了 :

之后我们要开始对HiveParser.g进行处理。
2.HiveParser.g代码修订
改动处HiveLexer.g略有区别,同样要改的是@header里的package名字。
// Package headers
@header {
package grammar.hive310;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
}
这里的package一定要和自己的目录结构对的上,不然编译成JAVA文件就会出错。
编译之前需要改ParseError.java中的package
高版本的需要根据有使用过hadoop依赖的模块给注释掉以免出现问题。
之后开始编译:
java -jar antlr-3.5.2-complete.jar HiveParser.g
javac -cp antlr-3.5.2-complete.jar HiveParser*.java ParseError.java
由于缺少ASTNode.jar缺少该类,查看版本当Hive版本为2.2时将
ASTLabelType=CommonTree;属性变更为了ASTNode,故我们将还原为CommonTree就可实现运行

这是由于antrl本身只有commonTree解析而Hive中可以发现已经自己写有ASTNode文件了,但是基于antrl工具我们这里不作衍生,可能以后优化此项目会使用到原生的HiveASTNode解析。
编译结束后为:
得到这些calss文件在前一篇基础上增加对HiveParser类的调用,并且解析一个比前一篇稍微复杂一点点的sql
import jnius_config
jnius_config.set_classpath('./','./grammar/hive310/antlr-3.5.2-complete.jar')
import jnius
StringStream = jnius.autoclass('grammar.hive310.ANTLRNoCaseStringStream')
Lexer = jnius.autoclass('grammar.hive310.HiveLexer')
Parser = jnius.autoclass('grammar.hive310.HiveParser')
TokenStream = jnius.autoclass('org.antlr.runtime.CommonTokenStream')
sql_string = (
"SELECT hour(from_unixtime(cast(gpstime/1000 as BIGINT),'yyyy-MM-dd HH:mm:ss')),dt "
"from track_point_traffic_dev.tk_track_point_attach_road_info "
"where admincode ='110105'"
"and dt BETWEEN '2022-07-28' and '2022-08-04'"
"limit 1000000"
)
sqlstream = StringStream(sql_string)
inst = Lexer(sqlstream)
ts = TokenStream(inst)
parser = Parser(ts)
ret = parser.statements()
treeroot = ret.getTree()
lex=[]
def walktree(node,depth = 0):
print("%s%s=%s" % (" "*depth,node.getText(),node.getType()))
if(node.getType()==24):
lex.append(node.getText())
children = node.children
if not children:
return
ch_size = children.size()
for i in range(ch_size):
ch =children.get(i)
walktree(ch,depth + 1)
def get_table(treeroot,depth=0):
children = treeroot.children
ch_size = children.size()
ch = children.get(1)
walktree(treeroot,0)
print(lex)
执行后,得到的输出是下面这样的很多字符串,每一个字符串都是HiveParser.g和另外3个.g文件里,匹配到一个规则后用pushMsg输出的状态信息,

解析复杂的sql报错也在此,很明确的发现就是有的规则无法识别而报错,也是后期优化的方向之一了。
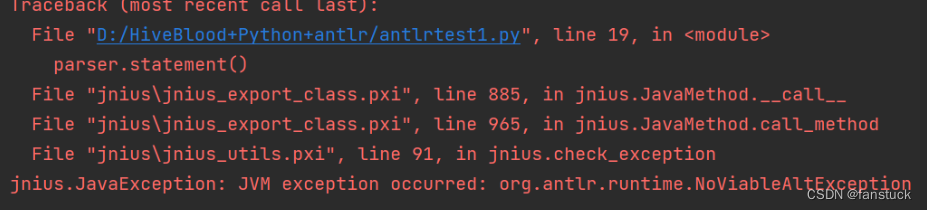
3.局限性
这个输出能看到antlr处理距离我需要的AST还是有挺大距离的,可能是Hive源代码里的处理逻辑在.g文件里没写太多,重点在外部的java代码里。对解析sql的需求来说,依赖太多hive自身的java代码是不太可控的,时间会花很多在语言特性的翻译上,也就没有用到刀刃上,利用效率差。
我们要解决这些问题必须还得上grammar文件上去改写。
本篇文章已经够多内容了,放到下篇再讲。
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。