


知识目录
一、前言
各位CSDN的朋友们大家好!这篇文章是在困扰了我三天(甚至更久),经过不断尝试与踩坑总结出来的通过 Sqoop 从Mysql数据库导入数据到 Hadoop hdfs 的详细笔记与感想,希望能帮助到大家!本篇文章收录于 初心 的 大数据 专栏。
🏠 个人主页:初心%个人主页
🧑 个人简介:大家好,我是初心,和大家共同努力
💕 座右铭:理想主义的花,终究会盛开在浪漫主义的土壤里!🍺🍺🍺
💕欢迎大家:这里是CSDN,我记录知识的地方,喜欢的话请三连,有问题请私信😘
事情是这样的:要实现从关系型数据库(RDBMS)导入数据到数据仓库中(比如说Hive、HBase等),就要借助 Hadoop 集群的 Hdfs 来实现,而数据要从关系型数据库(这里以MySQL为例)到 hdfs ,则需要借助 Sql to Hadoop 工具,也就是本篇文章的主角——Sqoop。
二、导入前的准备
2.1 Hadoop集群搭建
上面我们提到,要导入数据到 Hdfs ,那么 Hdfs 我们肯定得有吧?于是我们首先就得有 Hadoop 集群,Hadoop集群搭建,大家可以参考我的这篇文章,这里就不再重复讲啦, Hadoop集群搭建(完全分布式)。
2.2 Hadoop启停脚本
在使用Hadoop集群的过程中,我们不可避免的遇到一个问题:
当我们一打开虚拟机,总是要在 NameNode 节点上启动 Hdfs ,在 ResourceManager 节点上启动 yarn ,关闭的时候也是,这可能是一个烦人的操作!**
有没有能够让我们在一个节点上,执行一个命令,就可以把 Hdfs 、yarn以及历史服务器打开呢?答案是有!
** ,大家可以参考我的这篇文章——Hadoop启停脚本分享Hadoop启停脚本笔记。
三、docker安装MySQL
使用Docker安装MySQL,我本来是打算放在这里的,但是因为文章较为详细,放在此处使得可阅读性有所下降,所以我将笔记放在了另外一篇文章,供大家参考!点击查看Docker安装MySQL。
四、安装Sqoop
4.1 Sqoop准备
- 1.将Sqoop压缩包上传到 Hadoop102的/opt/software 目录下

- 2.解压到 /opt/module 目录下
tar -xzvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/
- 3.将Sqoop重命名
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop-1.4.6 sqoop
- 4.重命名Sqoop的模板文件
进入到Sqoop的conf目录下,将sqoop-env-template.sh重命名。
mv sqoop-env-template.sh sqoop-env.sh
- 5.在Sqoop的配置文件末尾添加上Hadoop_Home目录
vim /opt/module/sqoop/conf/sqoop-env.sh
# hadoop_home
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3

- 6.上传jdbc的jar包到Sqoop的lib目录下
至此,Sqoop的安装工作我们就准备好了!接下来我们来测试Sqoop是否能正常连接到MySQL。
4.2 Sqoop连接Mysql数据测试
通过在Sqoop安装目录下,执行以下命令,如果能够显示MySQL数据库中的所有数据库,那么证明Sqoop可以和Mysql正常通信,即代表安装成功。
- 1.进入到Sqoop安装目录
cd /opt/module/sqoop/
- 2.执行以下命令测试
bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3307/ --username root --password sky

五、导入MySQL数据到hdfs
现在,我们所有的准备工作都已经准备好了!Hadoop集群的 hdfs,yarn,历史服务器,MySQL数据库,Sqoop工具,现在我们就可以开始从MySQL导入数据到 hdfs 了。
5.1 准备MySQL数据
- 1.在Navicat中新建数据库mysql_to_hive

- 2.在mysql_to_hive数据库执行 sql 文件
SQL文件我放在了百度网盘上,点击即可下载。
执行完gmall_report.sql之后,我们的mysql_to_hive数据库就会新建四张表,分别是order_by_province,order_spu_stats,order_total,user_total,并且插入了一些数据。
- 3.查看表及数据
 这是order_by_province表中的部分数据展示。
这是order_by_province表中的部分数据展示。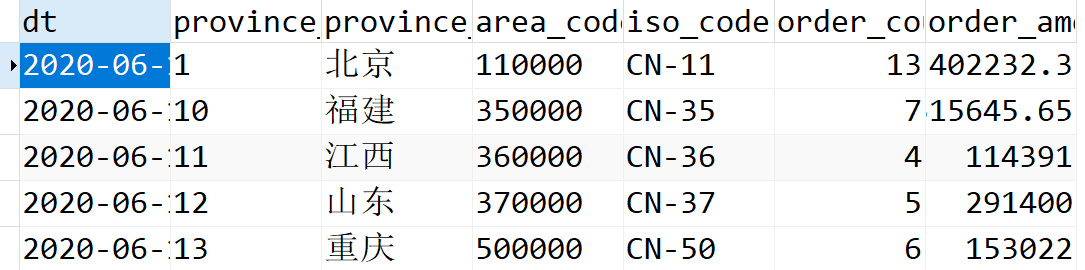
四张表和数据均正常,至此,我们MySQL的数据就准备好了!
5.2 导入数据
首先进入到Sqoop的安装目录:
cd /opt/module/sqoop/
从Sqoop导入全部数据,我们只需要执行以下命令即可。
在执行下面的代码之前,如果你的MySQL不是在hadoop102上,需要修改;用户名和密码也是以自己的为准。
- 导入表order_by_province
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3307/mysql_to_hive \
--username root \
--password sky \
--target-dir/mysql/gmall_report/order_by_province \
--table order_by_province \
--num-mappers 1 \
--delete-target-dir \
--fields-terminated-by '\t' \
--num-mappers 5 \
--bindir /opt/module/sqoop/lib \
--split-by dt
- 导入表order_spu_stats
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3307/mysql_to_hive \
--username root \
--password sky \
--table order_spu_stats \
--target-dir/mysql/gmall_report/order_spu_stats \
--num-mappers 1 \
--delete-target-dir \
--fields-terminated-by '\t' \
--num-mappers 5 \
--bindir /opt/module/sqoop/lib \
--split-by dt
- 导入表order_total
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3307/mysql_to_hive \
--username root \
--password sky \
--table order_total \
--target-dir/mysql/gmall_report/order_toal \
--num-mappers 1 \
--delete-target-dir \
--fields-terminated-by '\t' \
--num-mappers 5 \
--bindir /opt/module/sqoop/lib \
--split-by dt
- 导入表user_total
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3307/mysql_to_hive \
--username root \
--password sky \
--table user_total \
--target-dir/mysql/gmall_report/user_toal \
--num-mappers 1 \
--delete-target-dir \
--fields-terminated-by '\t' \
--num-mappers 5 \
--bindir /opt/module/sqoop/lib \
--split-by dt
至此,通过Sqoop实现从MySQL导入数据到 Hdfs 就结束了!希望这篇文章对你有帮助。
六、Sqoop现状
讲完了Sqoop导入MySQL数据到Hdfs,接下来我们再聊聊些别的,首先看一下下面这张图片(来源于Apache Sqoop官网)Sqoop官网:

啊?Sqoop要退役了吗?这不科学啊,这么好用的工具,怎么就退役了呢。仔细看了下,原来Apache Sqoop在2021年6月就已经进入Attic了,就是最近的事情。
不过,「Attic」(英文翻译是阁楼,有些束之高阁的意思了)是啥啊?并没有听说过,**进入到Attic的项目会咋样?**,我们继续探索下。
Apache Attic原来就相当于Apache的
小黑屋
,如果Apache托管的项目长时间不活跃(超过2年没有release新版本,没有committer、contributer并且没有未来roadmap),就会选择将项目移动到Attic中,这也就相当于Apache的项目管理了,掌管整个项目的生命周期。
目前将Sqoop做数据迁移工具公司不在少数,当Sqoop移动到Attic后,单单使用来说是完全不受影响的;Apache Attic依旧会提供代码库的下载;但是不会再修复任何的bug,release新版本了,并且也不会再重启社区。
看到这里其实就没有这么慌了,我们还能继续用,不过如果遇到问题,我们只能自己建个分支去fix了,**
从侧面来说,也能说明Sqoop在某个角度是成功的,毕竟曾经成为Apache顶级项目,如果真的是长时间没有release,有可能是他确实已经够成熟了
**。
七、结语
😎 本文主要讲解了如何通过Sqoop将RDBMS的数据导入到 Hdfs ,导入到了 Hdfs 之后,我们可以导入数据到数据仓库(HBase、Hive等),进行大数据的下一步学习啦!😊
✨ 这就是今天要分享给大家的全部内容了,我们下期再见!😊
🏠 本文由初心原创,首发于CSDN博客, 博客主页:初心%🏠
🍻 理想主义的花,终究会盛开在浪漫主义的土壤里!😍
🏠 我在CSDN等你哦!😍
版权归原作者 初心% 所有, 如有侵权,请联系我们删除。