
前言
首先hdfs 是Hadoop Distributed File System(简称HDFS),HDFS是hadoop兼容最好的标准级文件系统。Hdfs是一个分布式文件系统。Hadoop是分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,是Hadoop中的一个核心部件,主要是对数据进行分布式储存和读取。HDFS 有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS 可以实现流的形式访问文件系统中的数据。
一 HDFS
1.HDFS(Hadoop Distributed File System)是hadoop项目的核心子项目,是基于流数据模式访问和处理超大文件的需求而开发的。
1.1 HDFS的优点:
处理百MB、设置数百TB大小的文件
流式的访问数据,响应"一次写入、 多次读写"
运行于廉价的商用集群上
1.2 HDFS的缺点:
不适合低延迟数据访问
无法高效存储大量小文件
不支持多用户写入及任意修改文件
1.3 HDFS主要由三个组件构成:
分别是NameNode、SecondaryNameNode和DataNode,其中NameNode和SecondaryNameNode运行在master节点上,DataNode运行在slave节点上。
1.3.1NameNode
NameNode管理HDFS文件系统的命名空间,它维护文件系统树及树中的所有文件和目录。同时NameNode也负责这些文件和目录的打开、关闭、移动和重命名等操作。而实际文件数据的操作是由DataNode负责。当Client端发起请求,该请求首先会到达NameNode,NameNode分析请求,然后告诉Client该去哪个DataNode上找什么位置的数据块。得到消息后的Client会直接和DataNode进行交互。
NameNode中元数据种类有:
(1)文件名目录及它们的层级关系;(2)文件目录的所有者及其权限;(3)每个文件块的名称及文件有哪些块组成。
1.3.2 DataNode
DataNode运行在slave节点上,也称为工作节点。它负责存储数据块,也负责为Client端提供读写服务,同时还接收NameNode指令,进行创建、删除和复制等操作。DataNode还通过心跳机制定期向NameNode发送所存储文件块列表信息。并且DataNode还和其他DataNode节点通信,复制数据块已达到冗余的目的。
1.3.3 SecondaryNameNode
NameNode元数据信息存储在FsImage中,NameNode每次重启后会把FsImage读取到内存中,在运行过程中为了防止数据丢失,NameNode的操作会被不断的写入本地EditLog文件中。
二 hdfs完全分布式的搭建步骤以及解决方法
2.1 需要用到的软件及虚拟机
虚拟软件VMware Xshell 7
虚拟机:
主机名:node01 ip地址192.168.67.110
主机名:node02 ip地址192.168.67.120
主机名:node03 ip地址192.168.67.130
2.2 集群搭建与配置前需要完成的步骤
2.2.1 网络配置
2.2.2 配置静态IP
因为每次虚拟机重新启动,它原有的ip地址都有可能发生变化,因为我们要先固定集群中各个节点的ip防止以后无法解析对应的节点
cd /etc/sysconfig/network-scripts/
vi ifcfg-ens33
2.2.3 修改配置文件

在末尾添加
IPADDR=192.168.67.110
NETMASK=255.255.255.0
GATEWAY=192.168.67.2
DNS1=8.8.8.8
DNS2=114.114.114.114
2.2.4 设置主机域名映射
/etc/hosts
192.168.67.110 node01 node01.hadoop.com
192.168.67.120 node02 node02.hadoop.com
192.168.67.130 node03 node03.hadoop.com
2.2.5 关闭防火墙
systemctl stop firewalled 临时关闭防火墙
systemctl disable firewalld 彻底关闭防火墙
systemctl status firewalld 查看防火墙状态

2.2.6 selinux关闭
vi /etc/selinux/config
SELINUX=disabled

2.2.7 设置ssh免密
(1)ssh-keygen -t rsa 三个回车
(2)ssh-copy-id node01(拷贝三台机器的公钥到第一台机器)
(3)复制node01的认证到其他机器:
scp /root/.ssh/authorized_keys node02:/root/.ssh
scp /root/.ssh/authorized_keys node03:/root/.ssh
(4)此时已经完成免密登录,使用ssh命令可以从任意一台机器访问其他机器
ssh node01 ssh node02 ssh node03
2.2.8 安装JDK
java -version

准备工作完成,现在开始搭建集群
2.3 开始hdfs完全分布式集群搭建与配置
2.3.1创建文件cd /opt/software/hadoop/hdfs
mkdir software
mkdir hadoop
cd hadoop/
创建文件hdfs
mkdir hdfs
cd hdfs/
创建文件data name tmp
2.3.2 首先将hadoop-2.9.2文件上传到hadoop 目录并且解压
上传文件
cd /opt/software/hadoop/
rz #上传hadoop-2.9.2.tar.gz

—解压缩文件
tar -xvzf hadoop-2.9.2.tar.gz

2.3.3 配置HADOOP_HOME环境变量
vi /etc/profile
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.9.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
source /etc/profile
2.3.4 测试hadoop是否安装成功
hadoop version

2.4 首先修改/opt/software/hadoop/hadoop-2.9.2/etc/hadoop/下的文件:
<1>hadoop-env.sh文件
原来的配置是修改里面的JAVAHOME值和HADOOPCONF_DIR的值
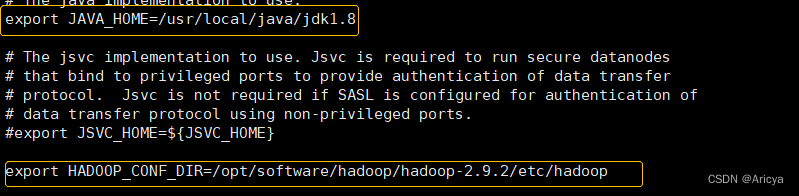
export JAVA_HOME=/usr/local/java/jdk1.8
export HADOOP_CONF_DIR=/opt/software/hadoop/hadoop-2.9.2/etc/hadoop
<2>yarn-env.sh文件
添加以下配置export JAVA_HOME=/usr/local/java/jdk1.8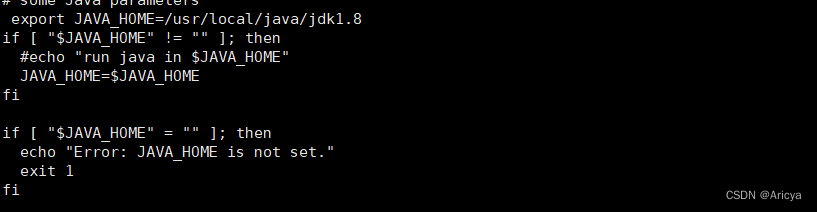
<3>core-site.xml文件
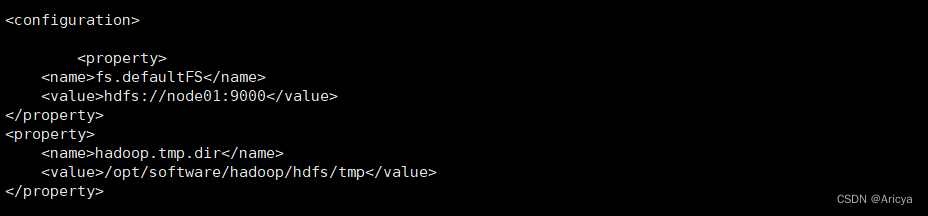
此配置需要把文件系统节点改成node01,添加以下
vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop/hdfs/tmp</value>
</property>
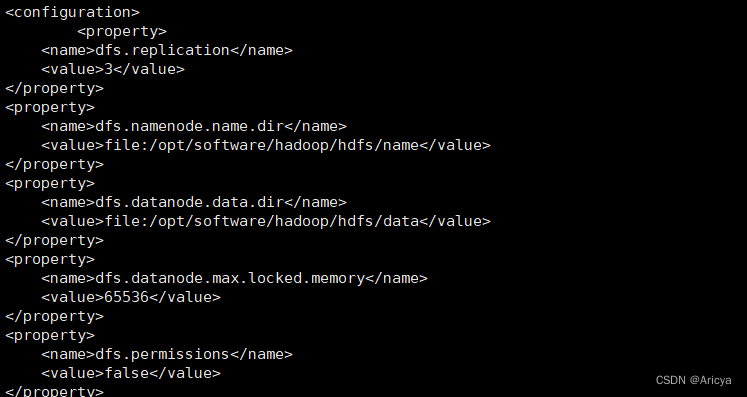
<4>hdfs-site.xml文件
第一个配置信息为节点备份数量 默认为3
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/software/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/software/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>65536</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<5>mapred-site.xml 文件
需要把mapred-site.xml.template拷贝成mapred-site.xml文件进行配置
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

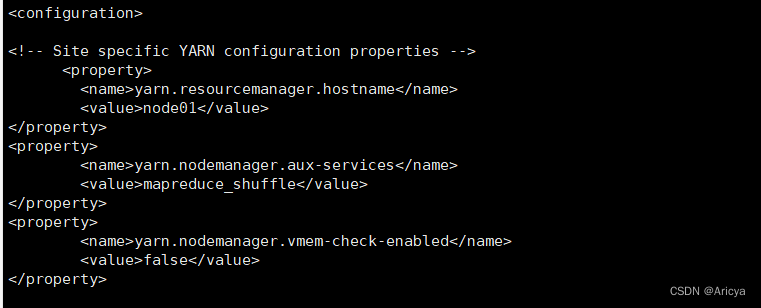
<6> yarn-site.xml
vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
添加图片注释,不超过 140 字(可选)
<7>slaves
配置3台机器主机名,此配置表示三台机器都作为DataNode
vi slaves
node01
node02
node03
2.5 同步配置信息
把node01上的配置同步到node02和node03
cd /opt/software/
scp -r hadoop/ ode02:$PWD
scp -r hadoop/ node03:$PWD
查看同步到node02 node03 的任意一个文件cat mapred-site.xml
就看到已经正常分发到了
2.5.1 配置环境变量
node02和node03机器的/etc/profile环境变量中添加hadoop配置
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.9.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
添加配置以后记得加载配置文件,使得配置文件生效 source /etc/profile
2.5.2 在node01上格式化
hdfs namenode -format
2.5.3 启动集群
start-dfs.sh
2.6 执行完成后使用jps命令检查各个节点
node01
node02
node03
三 访问web管理台
http://192.168.67.110:50070/
四 问题总结
(1)防火墙设置:为了防止发生一些奇奇怪怪的错误,请务必关闭所有节点的防火墙,他可能会导致浏览器无法获取集群信息和文件上传集群失败环境搭建,还有通过.start-dfs.sh命令启动集群失败的很大一个原因就是服务器防火墙未关闭的原因。
(2)hosts文件配置和主机名:因为这是完全分布式的集群,所以配置hosts文件至关重要,不然你的私钥配置和以后节点的格式化都会出错,他将会提示你无法解析主机名.
(3)将配置好的HDFS拷贝到其他节点时注意路径问题
版权归原作者 Aricya 所有, 如有侵权,请联系我们删除。