
大家好,我是一条~
5小时推开Spark的大门,第二小时,带大家搭建开发环境。
主要分两步,
- Spark的安装
- Scala环境的搭建
话不多说,动起来!
Spark的安装
Spark是基于Scala语言编写的,需要运行在JVM上,运行环境Java7以上,本文使用Java8,Centos7。
用Python也是可以的,但本教程不详细讲。
1.下载Spark
我使用的是腾讯云的服务器,没有的同学用虚拟机也是可以的,Win和Mac如何安装虚拟机不再赘述,CSDN有很多教程,也比较简单。
记得要配置好Java的环境变量哦!
首先使用
wget
下载安装包(也可以本地下载之后上传)
cd /data/opt/spark
wget --no-check-certificate https://downloads.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
下载完成后解压
可以改个短一些的名字,版本号最好保留

tar -zxf spark-3.2.0-bin-hadoop3.2.gz
2.Spark目录简介
可以自己cd进去看一看
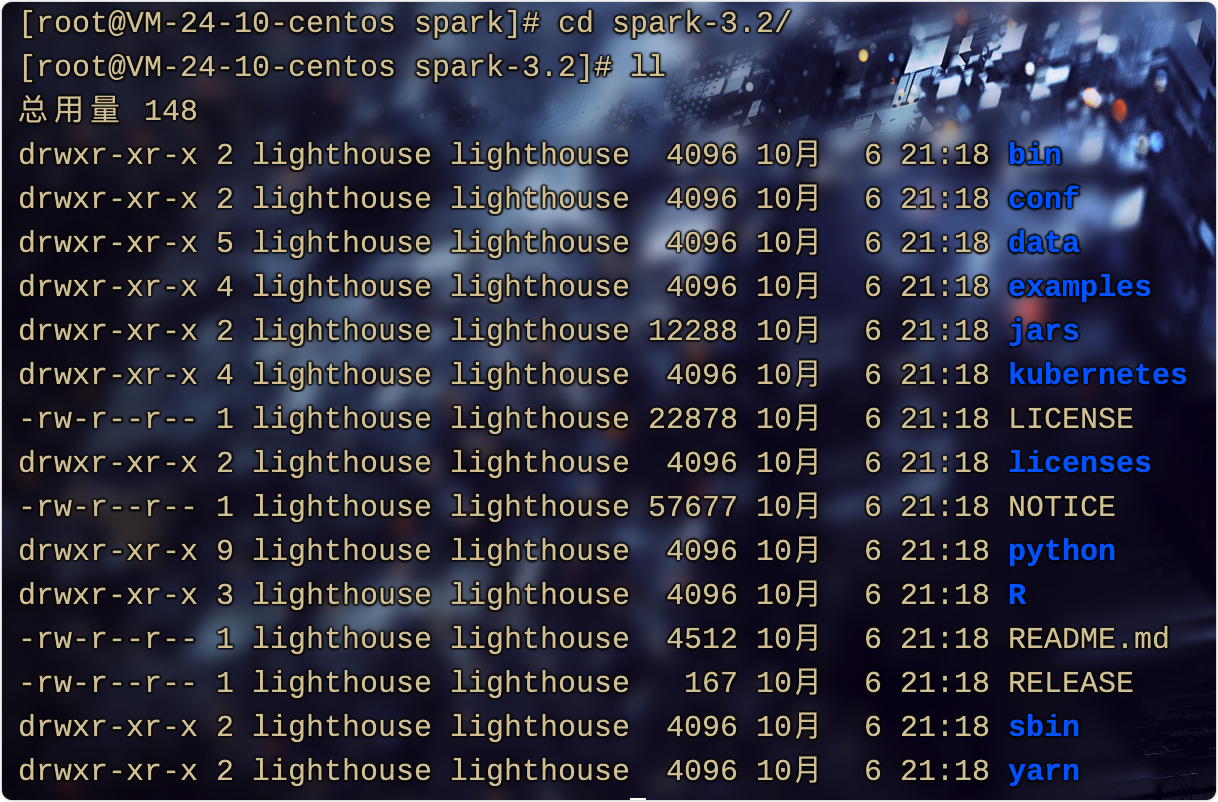
- bin:主要存放一些可执行文件。
- streaming、python、R、jars:主要存放组件源代码。
- examples: 存放一些可运行的单机Spark Job案例。
- conf:存放配置文件。
- data:存放数据文件。
- sbin:存放sh脚本。
3.启动Spark
进入
sbin
目录,执行
./start-master.sh
文件。
根据输出的内容,找到日志。

查看日志

访问网页端,如果是服务器记得开放对应端口。

ok,启动成功!
3.Spark Shell
Spark-Shell是一种学习API的简单方式,能够交互式的分析数据。能够把分布在集群上的数据加载到内存节点中,使分布式处理可以秒级完成。
快速实时的查询、计算、分析一般都在Shell中完成。
所以要学习Spark程序开发,建议先学习Spark-Shell交互式学习,加深对Spark程序开发的理解。
Spark提供了Python Shell和Scala Shell两种,本套课程使用Scala。
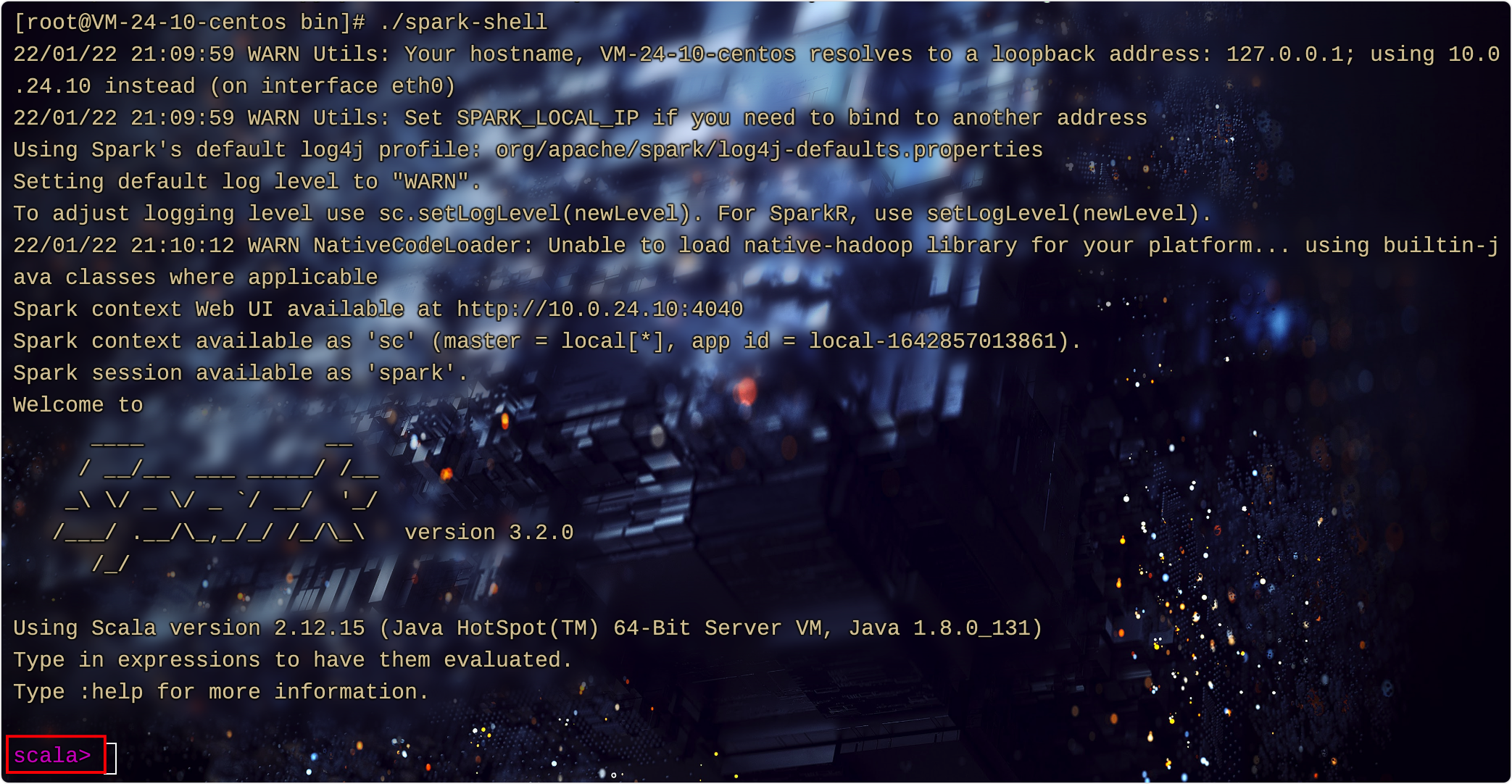
进去
bin
目录,执行
spark-shell
cd bin
./spark-shell
ok,为了很好体会Spark-Shell,实验一个例子:读取一个文件,并计算行数
首先创建一个测试文件,linux的基本操作哈
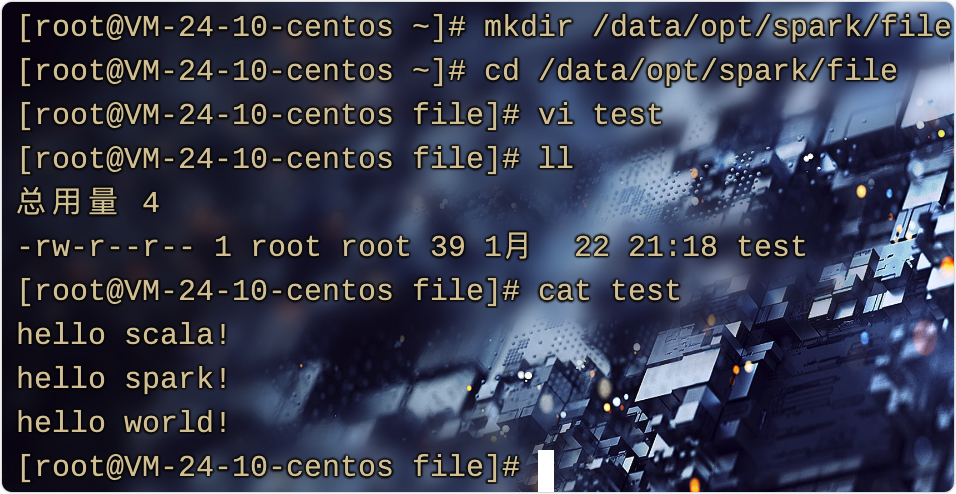
hello scala!
hello spark!
hello world!
回到Shell
先读取文件,再计算行数
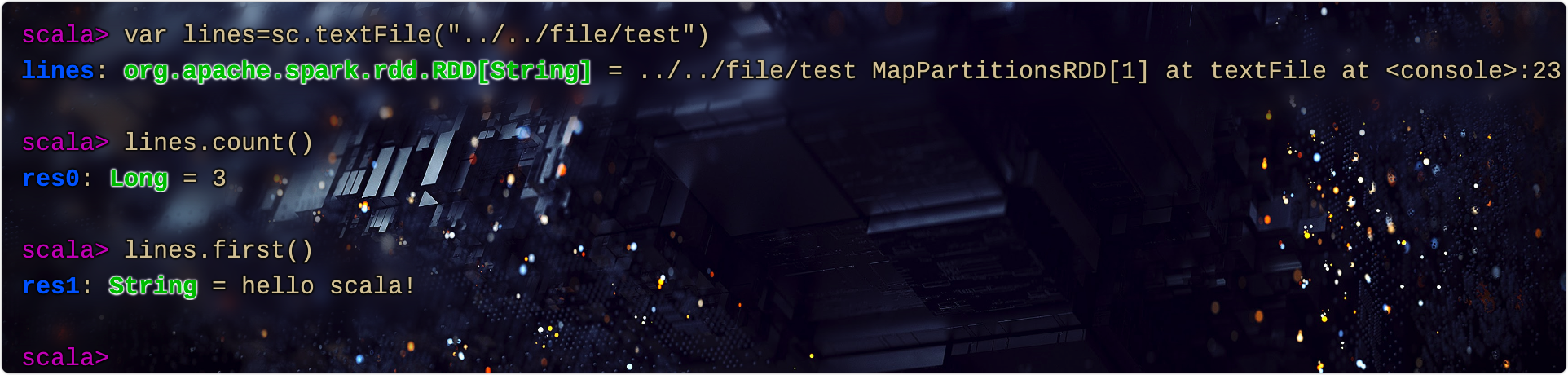
var lines=sc.textFile("../../file/test")
// 总行数
lines.count()
// 第一行
lines.first()
输出如下:
到此,Spark安装完成,同学们可能发现一个问题,这每次写代码也太麻烦了,就不能像Java代码一样吗?
当然是可以的,下面就教大家怎么给IDEA配置Scala插件。
IDEA集成Scala插件
IDEA相信大家都用过,不再赘述安装破解的过程。
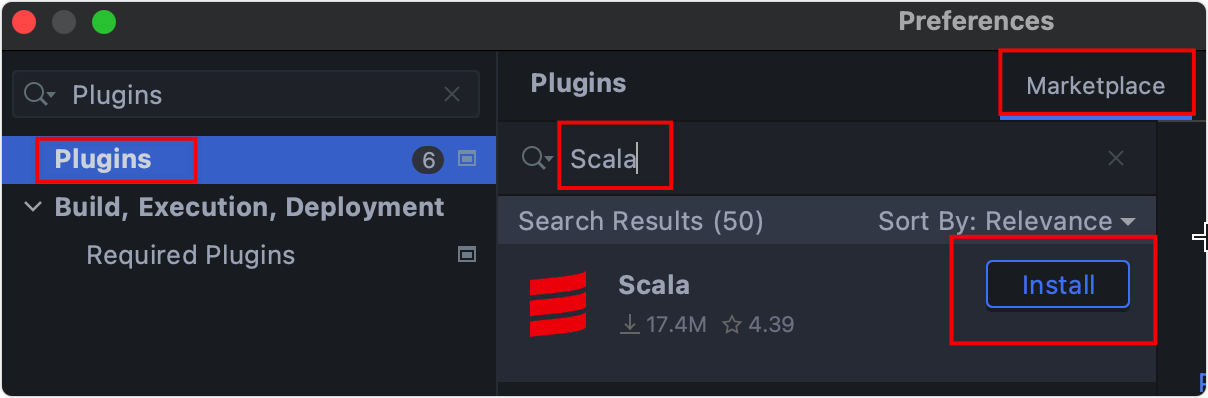
1.安装插件
在
settings
里面按图片示例安装Scala插件,会比较慢。安装成功后需要重启IDEA。
2.创建Maven项目
如图,新建一个Maven项目,起个名字,叫
spark-wordcount
导入依赖
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.0</version></dependency></dependencies>
我们写完程序肯定是要放到服务器运行的,就像Java一样,所以还要配置打包参数。
<build><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><executions><execution><goals><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.1.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
reload之后如果没问题,我们的项目就创建好了。
下面新建一个类
WordCount
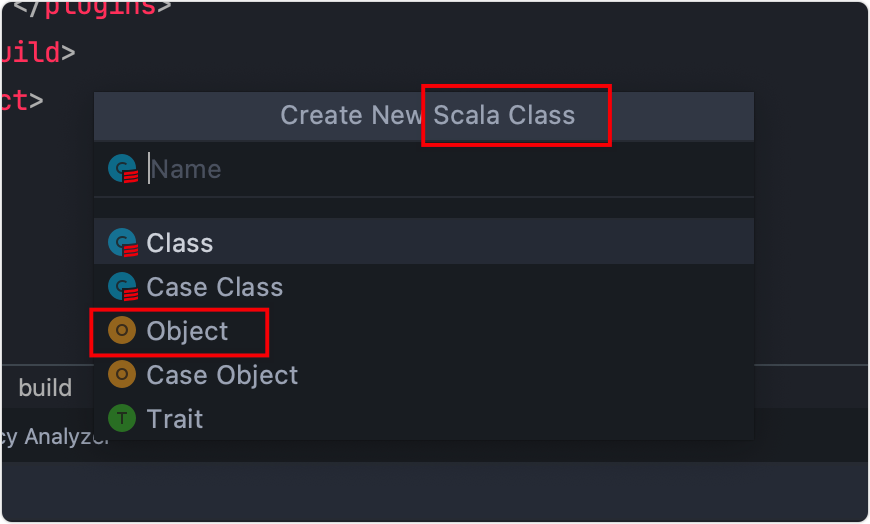
注意是Scala Class,然后选择Object。
再写个main方法,作为程序的入口,和Java有很多相似的地方。
打印测试一下
object WordCount {def main(args: Array[String]):Unit={
print("hello world!")}}
输出结果

ok,开发环境已经搭建完毕。
最后
本日打卡内容到此结束,偏实战多一些,同学们一定要亲自操作,下一节课带大家做一个大数据入门的经典案例——WordCount。
版权归原作者 一条coding 所有, 如有侵权,请联系我们删除。