
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
关键词提取方法可以在文档中找到相关的关键词。在本文中,我总结了最常用的关键字提取方法。
什么是关键词提取?
关键字提取是从文本文档中检索关键字或关键短语。这些关键词从文本文档的短语中选择出来的并且表征了文档的主题。在本文中,我总结了最常用的自动提取关键字的方法。
自动从文档中提取关键字的方法是从文本文档中选择最常用和最重要的单词或短语的启发式方法。我将关键字提取方法归入自然语言处理领域,这是机器学习和人工智能中的一个重要领域。
关键字提取器用于提取单词(关键字)或创建短语(关键短语)的两个或多个单词的组。在本文中,我使用术语关键字提取,其中包括关键字或关键短语提取。
为什么我们需要关键字提取的方法呢?
节省时间——根据关键词,可以决定文本的主题(例如文章)是否对他感兴趣以及是否阅读。关键字向用户提供了该篇文章或文档主要内容摘要。
查找相关文档——大量文章的出现使得我们不可能全部进行阅读。关键词提取算法可以帮助我们找到相关文章。关键字提取算法还可以自动构建书籍、出版物或索引。
关键字提取作为机器学习的支持——关键字提取算法找到描述文本的最相关的词。它们以后可以用于可视化或自动分类文本。
关键词提取方法
在本文中,我将概述一些最常用的关键字提取方法。我会考虑无监督(不需要训练)和领域独立的方法。我将方法分为三组:统计方法、基于图的方法和基于向量嵌入的方法。
基于统计的方法
统计方法是最简单的。他们计算关键字的统计数据并使用这些统计数据对它们进行评分。一些最简单的统计方法是词频、词搭配和共现。也有一些更复杂的,例如 TF-IDF 和 YAKE!。
TF-IDF 或term frequency–inverse document frequency,会计算文档中单词相对于整个语料库(更多文档集)的重要性。它计算文档中每个词的频率,并通过词在整个语料库中的频率的倒数对其进行加权。最后,选择得分最高的词作为关键词。
TF-IDF 的公式如下:

其中 t 是观察项。该等式应用于文档中的每个术语(单词或短语)。方程的蓝色部分是词频(TF),橙色部分是逆文档频率(IDF)。
TF-IDF 的想法是文档中出现频率更高的词不一定是最相关的。该算法偏爱在文本文档中频繁出现而在其他文档中不常见的术语。
TF-IDF 的优点是速度快,缺点是需要至少几十个文档的语料库。并且 TF-IDF 与语言无关。
YAKE (Yet Another Keyword Extractor) 是一种关键字提取方法,它利用单个文档的统计特征来提取关键字。它通过五个步骤提取关键字:

1、预处理和候选词识别——文本被分成句子、块(句子的一部分用标点符号分隔)和标记。文本被清理、标记和停用词也会被识别。
2、特征提取——算法计算文档中术语(单词)的以下五个统计特征:
a) 大小写——计算该术语在文本中出现大写或作为首字母缩略词的次数(与所有出现成比例)。重要的术语通常更频繁地出现大写。
b) 词条位置——词条在文本中的中间位置。更接近开头的术语过去更重要。
c) 词频归一化——测量文档中的平衡词频。
d) 术语与上下文的相关性——衡量候选术语同时出现的不同术语的数量。更重要的术语与较少不同的术语同时出现。
e) 术语不同的句子——测量术语在不同句子中出现的次数。得分越高表示术语越重要。
3、计算术语分数——上一步的特征与人造方程组合成一个单一的分数。
4、生成 n-gram 并计算关键字分数——该算法识别所有有效的 n-gram。n-gram 中的单词必须属于同一块,并且不能以停用词开头或结尾。然后通过将每个 n-gram 的成员分数相乘并对其进行归一化,以减少 n-gram 长度的影响。停用词的处理方式有所不同,以尽量减少其影响。
5、重复数据删除和排名——在最后一步算法删除相似的关键字。它保留了更相关的那个(分数较低的那个)。使用 Levenshtein 相似度、Jaro-Winkler 相似度或序列匹配器计算相似度。最后,关键字列表根据它们的分数进行排序。
YAKE 的优势在于它不依赖于外部语料库、文本文档的长度、语言或领域。与 TF-IDF 相比,它在单个文档的基础上提取关键字,并且不需要庞大的语料库。
基于图的方法
基于图的方法从文档中生成相关术语的图。例如,图将文本中共同出现的术语连接起来。基于图的方法使用图排序方法,该方法考虑图的结构来对顶点重要性进行评分。最著名的基于图的方法之一是 TextRank。
TextRank 是一种基于图的排序方法,用于提取相关句子或查找关键字。我将重点介绍它在关键字提取中的用法。该方法通过以下步骤提取关键字:
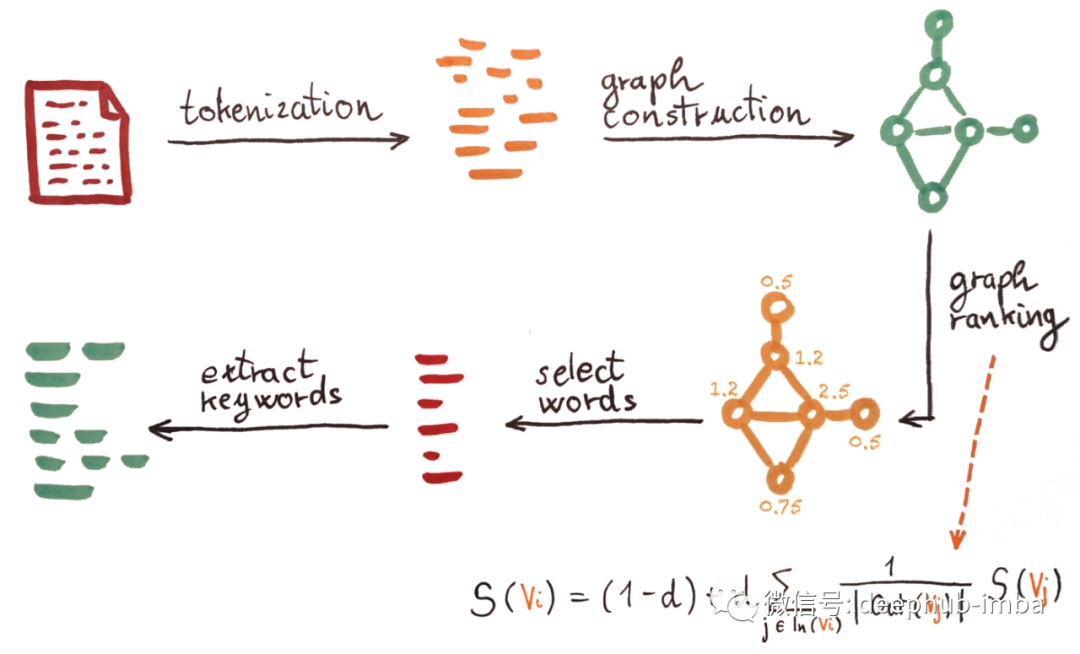
1、带有词性 (PoS) 标签的文本标记化和注释
2、词共现图构建——图中的顶点是带有选定 PoS 标签的词(作者仅选择名词和形容词即可获得最佳结果)。如果两个顶点出现在文本中的 N 个单词的窗口内,则它们与一条边相连(根据作者的实验,最佳表现 N 为 2)。该图是无向和未加权的。
3、图排序——每个顶点的分数设置为1,在图上运行排序算法。作者使用 Google 的 PageRank 算法,该算法主要用于对网站图表进行排名。该算法使用上图中的公式。顶点 Vi 的权重 S(Vi) 是通过考虑连接到节点 Vi 的顶点的权重来计算的。在等式中,d 是设置为 0.85 的阻尼因子,如 PageRank 文章中所述。In(Vi) 是到顶点 Vi 的入站链接,而 Out(Vj) 是来自顶点 Vj 的出站链接。由于我们考虑的是无向图,因此顶点的入站链接和顶点的出站链接是相同的。该算法在每个节点上运行多次迭代,直到节点上的权重收敛——迭代之间的变化低于 0.0001。
4、得分最高的单词选择——单词(顶点)从得分最高的单词到最低得分的单词排序。最后,算法选择单词的前 1/3。
5、关键词提取——在这一步中,如果上一阶段选择的单词一起出现在文本中,则将它们连接为多词关键词。新构建的关键字的分数是单词分数的总和。
该算法对每个文档单独执行,不需要一个文档语料库来进行关键字提取。TextRank也是语言无关的。
RAKE (Rapid Automatic Keyword Extraction)是另一种基于图的关键字提取算法。该算法是基于这样的观察:关键字通常由多个单词组成,通常不包括停顿词或标点符号。
它包括以下步骤:
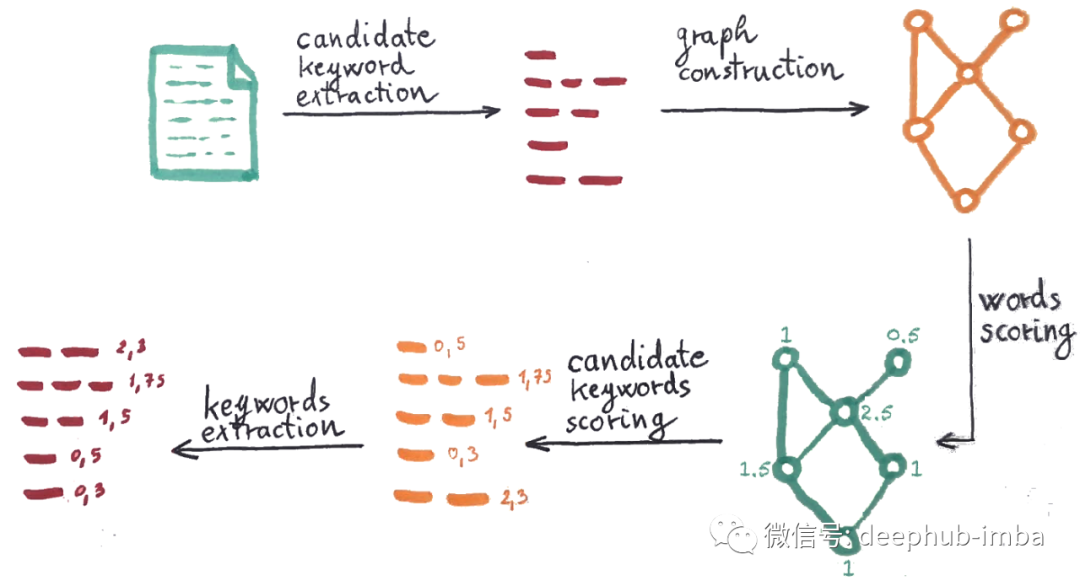
1、候选关键词提取——基于停用词和短语分隔符对候选关键词进行文本分割。候选关键字是位于两个停用词或短语定界符之间的短语。例如,短语分隔符是标点符号。
2、关键词共现图构建——图中的顶点是单词。如果它们一起出现在候选关键字中,则它们是连接的。该图是加权的——权重是连接词在候选关键字中一起出现的次数。该图还包括与顶点本身的连接(每个单词与自身一起出现在候选关键字中)。
3、词评分——图中的每个词都用以下评分之一评分:
a) 词度 deg(w)——词 w 共同出现的词数(边权重总和,包括指向顶点本身的边)。度数偏爱出现频率更高、关键字更长的词。
b) 词频 freq(w) — 该词出现在任何候选关键字中的次数。频率偏爱出现频率更高的词。
c) 度数与频率之比 deg(w)/freq(w)——这个指标偏向于主要出现在较长候选关键词中的词。建议使用词度或度数与频率之比。从这两个角度来看,排名将有利于较短的关键字。
4、候选关键词得分——每个候选关键词的得分为其成员词得分之和。
5、相邻关键词——候选关键词不包括停用词。由于有时停用词可能是关键字的一部分,因此在此步骤中添加了它们。该算法在文本中找到与停用词连接的关键字对,并将它们添加到现有停用词集中。它们必须在要添加的文本中至少出现两次。新关键字的得分是其成员关键字的总和。
6、关键词提取——结果,1/3 得分最高的关键词被提取出来。
RAKE 和 TextRank 的主要区别在于 RAKE 考虑候选关键字内的共现而不是固定窗口。它使用更简单、更具统计性的评分程序。该算法对每个文档分别进行,因此不需要文档语料库来进行关键词提取。
基于深度学习
深度学习的出现使基于嵌入的方法成为可能。研究人员开发了几种使用文档嵌入的关键字提取方法(例如 Bennani 等人)。
这些方法主要查找候选关键字列表(例如,Bennani 等人只考虑由名词和形容词组成的关键字)。他们将文档和候选关键字嵌入到相同的嵌入空间中,并测量文档和关键字嵌入之间的相似度(例如余弦相似度)。他们根据相似度度量选择与文档文本最相似的关键字。
总结
在本文中介绍了几种从统计、基于图和嵌入方法中提取关键字的方法。由于该领域非常活跃,我只介绍最常见的方法。我只考虑无监督方法的一个子组(它们不需要训练)。也有在带注释文档的训练数据集上训练的监督方法。它们表现良好,但在实践中较少使用,因为它们需要训练并且需要带注释的文档数据集,结果也通常仅适用于训练数据集中的主题。
引用
[1]Bennani-Smires, Kamil, et al. Simple unsupervised keyphrase extraction using sentence embeddings. arXiv preprint arXiv:1801.04470, 2018.
[1] Campos, Ricardo, et al. YAKE! Keyword extraction from single documents using multiple local features. Information Sciences, 2020, 509: 257–289.
[3] Jones, Karen Sparck. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 1972.
[4] Mihalcea, Rada; Tarau, Paul. TextRank: Bringing order into texts. 2004. In: Association for Computational Linguistics.
[5] Rose, Stuart, et al. Automatic keyword extraction from individual documents. Text mining: applications and theory, 2010, 1: 1–20.
作者:Primož Godec
喜欢就关注一下吧:
点个 在看 你最好看!********** **********