
如何发现和处理数据埋点中的逻辑错误
在大数据分析中,数据埋点是至关重要的一环。然而,当我们遇到数据上报逻辑错误时,该如何应对呢?本文将为你揭示解决这一棘手问题的有效方法。
目录
什么是数据上报逻辑错误?
数据上报逻辑错误指的是在数据埋点过程中,由于代码逻辑问题导致上报的数据与实际情况不符。这可能会严重影响数据分析的准确性和可靠性。
如何发现数据上报逻辑错误?
- 数据异常检测
- 日志分析
- A/B测试比对

修复数据上报逻辑错误的步骤
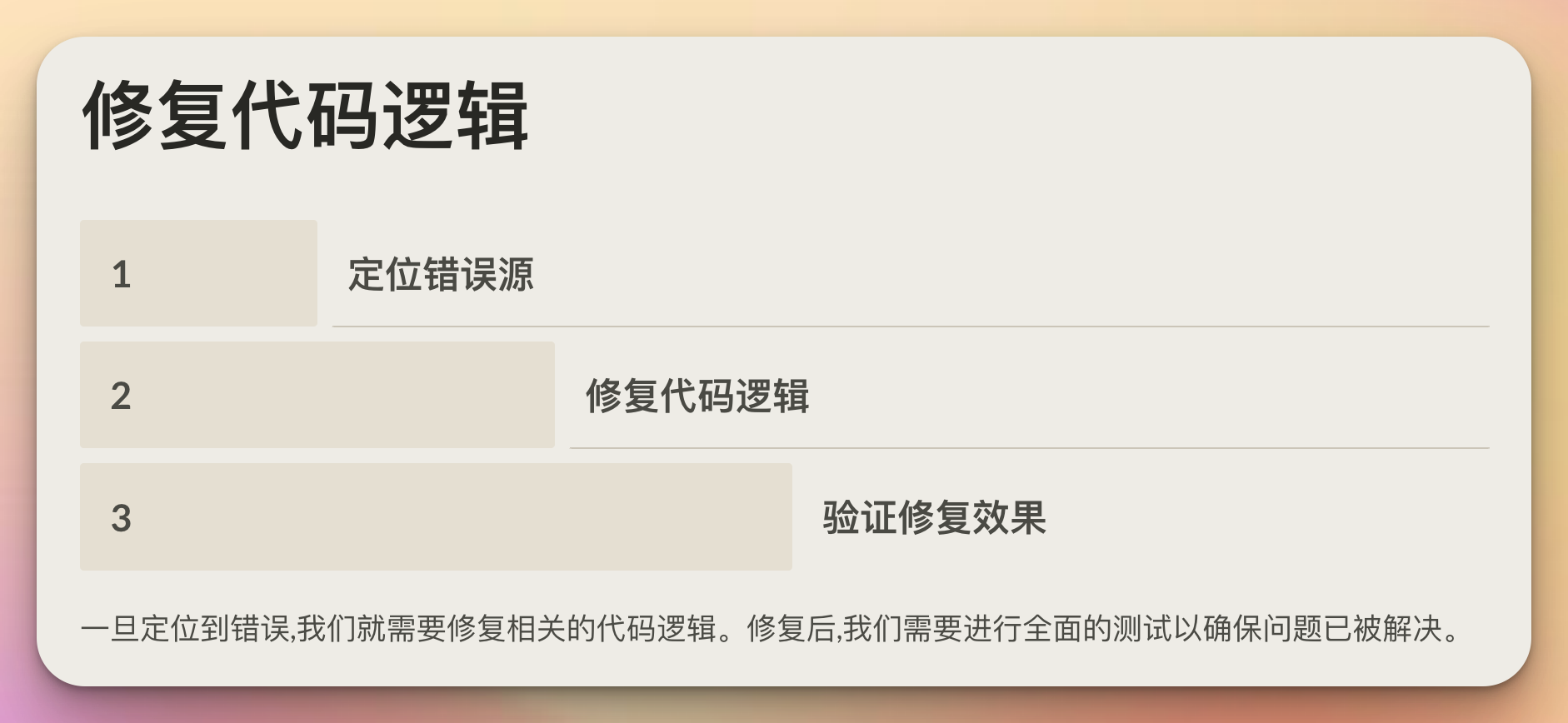
1. 定位错误源
首先,我们需要通过日志分析定位错误的具体位置。以下是一个简单的Python脚本,用于分析日志中的异常情况:
import re
defanalyze_log(log_file):
error_pattern =r"ERROR.*data reporting"withopen(log_file,'r')as f:for line in f:if re.search(error_pattern, line):print(f"Found error: {line.strip()}")
analyze_log('data_reporting.log')
2. 修复代码逻辑
一旦定位到错误,我们就需要修复相关的代码逻辑。这里是一个修复示例:
# 修复前defreport_data(user_action):if user_action =='click':
send_data('user_click')elif user_action =='view':
send_data('user_view')# 错误:没有处理其他情况# 修复后defreport_data(user_action):
valid_actions =['click','view','scroll']if user_action in valid_actions:
send_data(f'user_{user_action}')else:
log_error(f'Invalid user action: {user_action}')
3. 验证修复效果

修复后,我们需要进行全面的测试以确保问题已被解决。可以使用以下代码进行简单的验证:
import unittest
classTestDataReporting(unittest.TestCase):deftest_report_data(self):
self.assertEqual(report_data('click'),'user_click')
self.assertEqual(report_data('view'),'user_view')
self.assertEqual(report_data('scroll'),'user_scroll')with self.assertRaises(ValueError):
report_data('invalid_action')if __name__ =='__main__':
unittest.main()
深入解析:如何优化数据埋点以避免逻辑错误
在上一篇文章中,我们讨论了如何发现和修复数据上报逻辑错误。今天,让我们更进一步,探讨如何从根本上优化数据埋点流程,以最大程度地减少逻辑错误的发生。
为什么数据埋点容易出现逻辑错误?

数据埋点过程复杂,涉及多个环节,每个环节都可能成为错误的源头。主要原因包括:
- 需求理解偏差
- 代码实现不当
- 测试覆盖不全面
如何优化数据埋点流程?
1. 建立统一的埋点规范

制定清晰的埋点规范可以大大减少由于理解偏差导致的错误。以下是一个简单的埋点规范示例:
# 数据埋点规范
## 命名规则
- 事件名:动词_名词,如 click_button, view_page
- 属性名:小驼峰命名,如 userId, pageTitle
## 数据类型
- 字符串:最大长度 100 字符
- 数字:整数或最多 2 位小数的浮点数
- 布尔值:true 或 false
## 必填字段
- eventTime: 事件发生的时间戳
- userId: 用户唯一标识
- deviceId: 设备唯一标识
## 示例
{
"eventName": "click_submit_button",
"eventTime": 1628150400000,
"userId": "user123",
"deviceId": "device456",
"buttonText": "提交订单",
"pageUrl": "/checkout"
}
2. 使用类型安全的编程语言或工具
使用类型安全的语言或工具可以在编译时就发现许多潜在的错误。例如,使用 TypeScript 而不是 JavaScript 来编写前端埋点代码:
interfaceEventData{
eventName:string;
eventTime:number;
userId:string;
deviceId:string;[key:string]:string|number|boolean;}functionreportEvent(data: EventData):void{// 验证必填字段if(!data.eventName ||!data.eventTime ||!data.userId ||!data.deviceId){thrownewError('Missing required fields');}// 发送数据sendToServer(data);}// 使用示例reportEvent({
eventName:'click_submit_button',
eventTime: Date.now(),
userId:'user123',
deviceId:'device456',
buttonText:'提交订单',
pageUrl:'/checkout'});
3. 实现自动化测试
自动化测试可以帮助我们快速发现和定位问题。以下是一个使用 Jest 框架的自动化测试示例:
import{ reportEvent }from'./eventReporting';describe('Event Reporting',()=>{it('should successfully report valid event data',()=>{const validData ={
eventName:'test_event',
eventTime: Date.now(),
userId:'testUser',
deviceId:'testDevice'};expect(()=>reportEvent(validData)).not.toThrow();});it('should throw error for missing required fields',()=>{const invalidData ={
eventName:'test_event',// 缺少其他必填字段};expect(()=>reportEvent(invalidData asany)).toThrow('Missing required fields');});// 更多测试用例...});
4. 实施持续集成和部署(CI/CD)

通过 CI/CD 流程,我们可以在每次代码变更时自动运行测试,确保埋点代码的质量。以下是一个使用 GitHub Actions 的简单 CI 配置:
name: CI
on:[push, pull_request]jobs:test:runs-on: ubuntu-latest
steps:-uses: actions/checkout@v2
-name: Use Node.js
uses: actions/setup-node@v2
with:node-version:'14'-run: npm ci
-run: npm run build
-run: npm test
数据埋点高级技巧:实时监控与异常预警机制
在前两篇文章中,我们讨论了如何发现、修复数据上报逻辑错误,以及如何优化数据埋点流程。今天,让我们更进一步,探讨如何建立实时监控和异常预警机制,以便在问题发生的第一时间发现并解决。
为什么需要实时监控与异常预警?
即使我们已经优化了数据埋点流程,仍然可能出现意料之外的问题,如:
- 突发的系统故障
- 异常的用户行为
- 第三方服务的不稳定
实时监控和异常预警可以帮助我们快速发现这些问题,最大限度地减少数据损失和分析偏差。
如何实现实时监控与异常预警?
1. 设计监控指标
首先,我们需要确定哪些指标需要监控。常见的指标包括:
- 数据上报量
- 错误率
- 响应时间
- 关键事件触发频率
2. 实现数据流处理
使用流处理技术可以实时处理和分析数据。以下是使用 Apache Flink 进行实时数据处理的示例:
importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.windowing.time.Time;publicclassRealTimeMonitoring{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();DataStream<Event> events = env.addSource(newEventSource());
events
.keyBy(event -> event.getEventName()).timeWindow(Time.minutes(1)).aggregate(newEventCountAggregator()).filter(count -> count.getCount()>THRESHOLD).addSink(newAlertSink());
env.execute("Real-time Event Monitoring");}}
3. 建立异常检测模型
使用机器学习算法可以更智能地检测异常。这里是一个使用 Python 和 Scikit-learn 实现简单异常检测的例子:
from sklearn.ensemble import IsolationForest
import numpy as np
classAnomalyDetector:def__init__(self):
self.model = IsolationForest(contamination=0.1)deffit(self, data):
self.model.fit(data)defpredict(self, data):return self.model.predict(data)# 使用示例
detector = AnomalyDetector()
historical_data = np.random.randn(1000,5)# 假设有5个特征
detector.fit(historical_data)
new_data = np.random.randn(100,5)
anomalies = detector.predict(new_data)print(f"Detected {np.sum(anomalies ==-1)} anomalies")
4. 实现告警系统
当检测到异常时,我们需要及时通知相关人员。以下是一个使用 Slack API 发送告警的 Python 脚本:
import requests
import json
defsend_slack_alert(message):
webhook_url ="https://hooks.slack.com/services/YOUR/WEBHOOK/URL"
slack_data ={'text': message}
response = requests.post(
webhook_url,
data=json.dumps(slack_data),
headers={'Content-Type':'application/json'})if response.status_code !=200:raise ValueError(f"Request to Slack returned an error {response.status_code}, the response is:\n{response.text}")# 使用示例
send_slack_alert("Warning: Abnormal data reporting detected in the last 5 minutes!")
5. 可视化监控面板
使用可视化工具如 Grafana 可以帮助我们更直观地监控数据状态。以下是一个使用 InfluxDB 和 Grafana 的简单配置:
# docker-compose.ymlversion:'3'services:influxdb:image: influxdb:latest
ports:-"8086:8086"grafana:image: grafana/grafana:latest
ports:-"3000:3000"depends_on:- influxdb
最佳实践
- 分层告警:根据问题的严重程度设置不同级别的告警。
- 告警抑制:避免同一问题在短时间内重复告警。
- 自动化修复:对于已知的问题,可以尝试实现自动化修复流程。
- 定期演练:定期进行故障演练,确保团队能够快速响应和解决问题。

小结
通过实施实时监控和异常预警机制,我们可以大大提高数据埋点系统的可靠性和稳定性。这不仅能帮助我们及时发现和解决问题,还能为持续优化数据质量提供valuable insights。
记住,一个强大的监控系统就像是数据埋点的"安全网",它能够让我们在数据驱动的道路上走得更稳、更远。
总结 数据埋点全面指南:从错误处理到实时监控
在这个数据驱动的时代,高质量的数据埋点对于精准分析和决策至关重要。让我们回顾一下我们所讨论的关键点,为您提供一个全面的数据埋点优化策略。
1. 发现和修复数据上报逻辑错误
- 定义问题:数据上报逻辑错误会导致上报的数据与实际情况不符。
- 发现方法: - 数据异常检测- 日志分析- A/B测试比对
- 修复步骤: 1. 定位错误源(使用日志分析)2. 修复代码逻辑3. 验证修复效果(单元测试)
2. 优化数据埋点流程
- 建立统一的埋点规范:包括命名规则、数据类型、必填字段等。
- 使用类型安全的编程语言或工具:如TypeScript。
- 实现自动化测试:使用测试框架如Jest。
- 实施持续集成和部署(CI/CD):如使用GitHub Actions。
3. 实时监控与异常预警机制
- 设计监控指标:如数据上报量、错误率、响应时间等。
- 实现数据流处理:使用Apache Flink等工具进行实时数据处理。
- 建立异常检测模型:使用机器学习算法如Isolation Forest。
- 实现告警系统:通过Slack等渠道及时通知相关人员。
- 可视化监控面板:使用Grafana等工具直观展示数据状态。
最佳实践
- 分层告警:根据问题严重程度设置不同级别的告警。
- 告警抑制:避免同一问题重复告警。
- 自动化修复:尝试对已知问题实现自动修复。
- 定期演练:进行故障演练,提高团队响应能力。
总结
优化数据埋点是一个持续改进的过程,涉及多个方面:
- 及时发现和修复错误
- 优化埋点流程,提高代码质量
- 建立实时监控和预警机制
通过实施这些策略,我们可以显著提高数据质量和可靠性,为数据驱动决策提供坚实基础。记住,投资于数据埋点的优化将为您的数据分析工作带来长期回报。
您的团队是否有其他有效的数据埋点优化策略?欢迎在评论区分享您的经验和见解,让我们一起推动数据质量的提升!
版权归原作者 数据小羊 所有, 如有侵权,请联系我们删除。