
1)今日内容

用户点赞,实时计算,实时替换redis数据给用户展示,
一个视频同一时间内100万人点赞,上推荐页面,而不是等到2点后推送
2)流式计算
2.1)概述

像字符流和字节流一样,开通一条管道,输送数据,上传文件的进度条,流式计算
应用场景

dashboard
公交车数据,滴滴司机多久到
实时文章(上首页,上热门)
3)kafkaStream
3.1)概述
不用部署在linux
自由搭配java
事件时间窗口操作(一段时间内的所有操作聚合处理一次性处理)
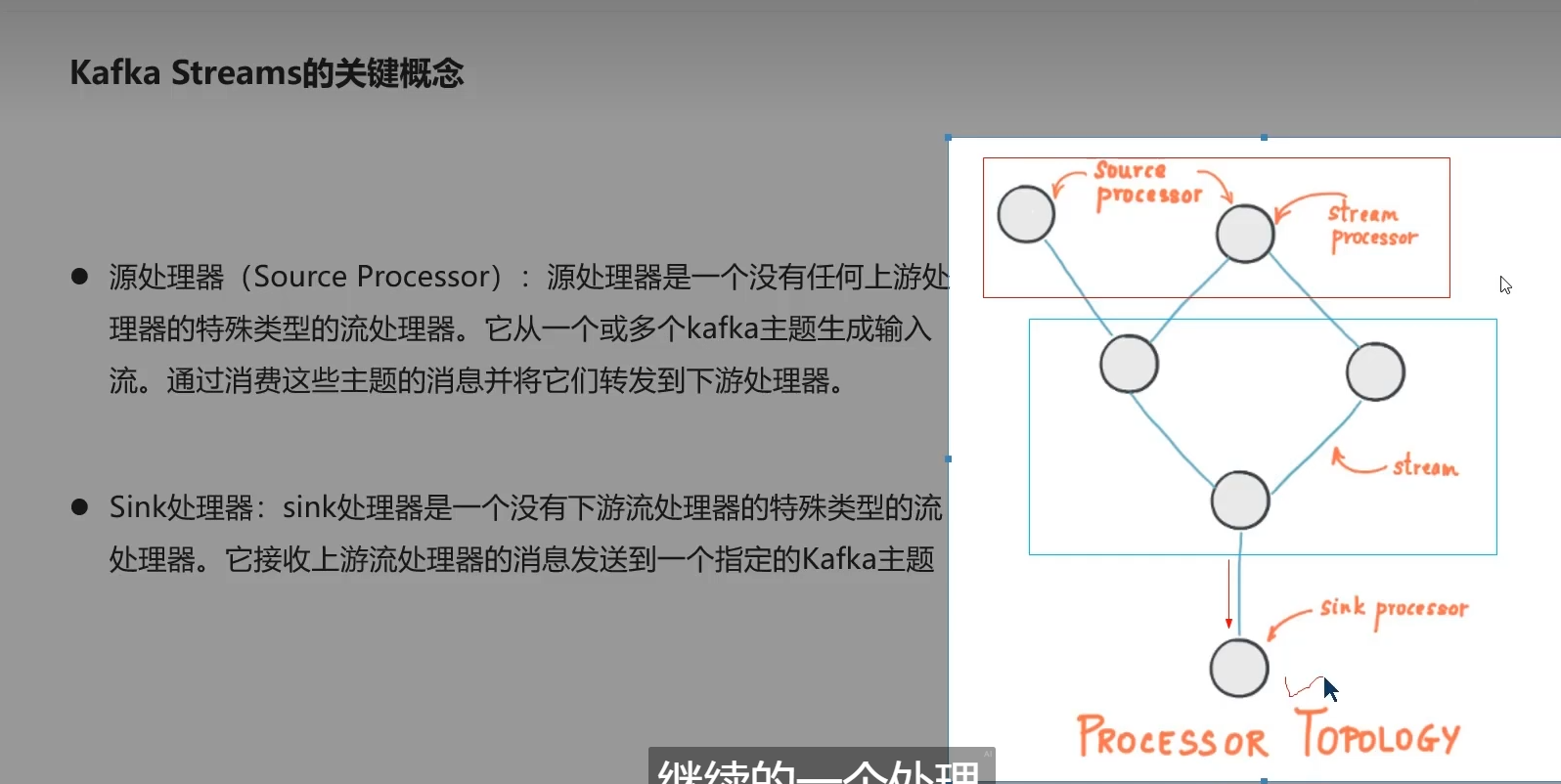
-E-的结构进行加工, 大哥派发任务给3个小弟,3个小弟做完后给二哥
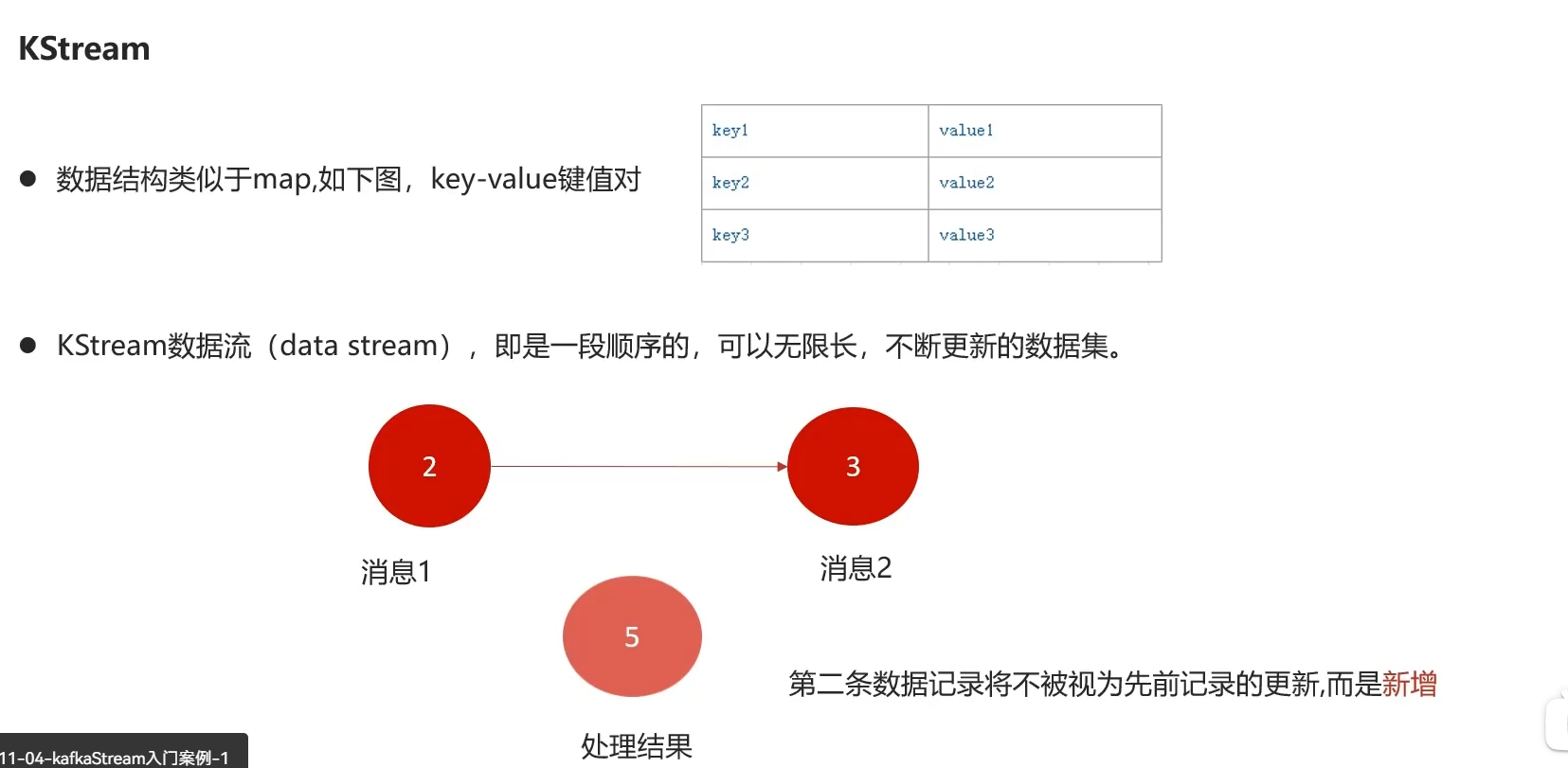
流里的每一个数据集记录进行累加,而不是更新
3.2)入门案例
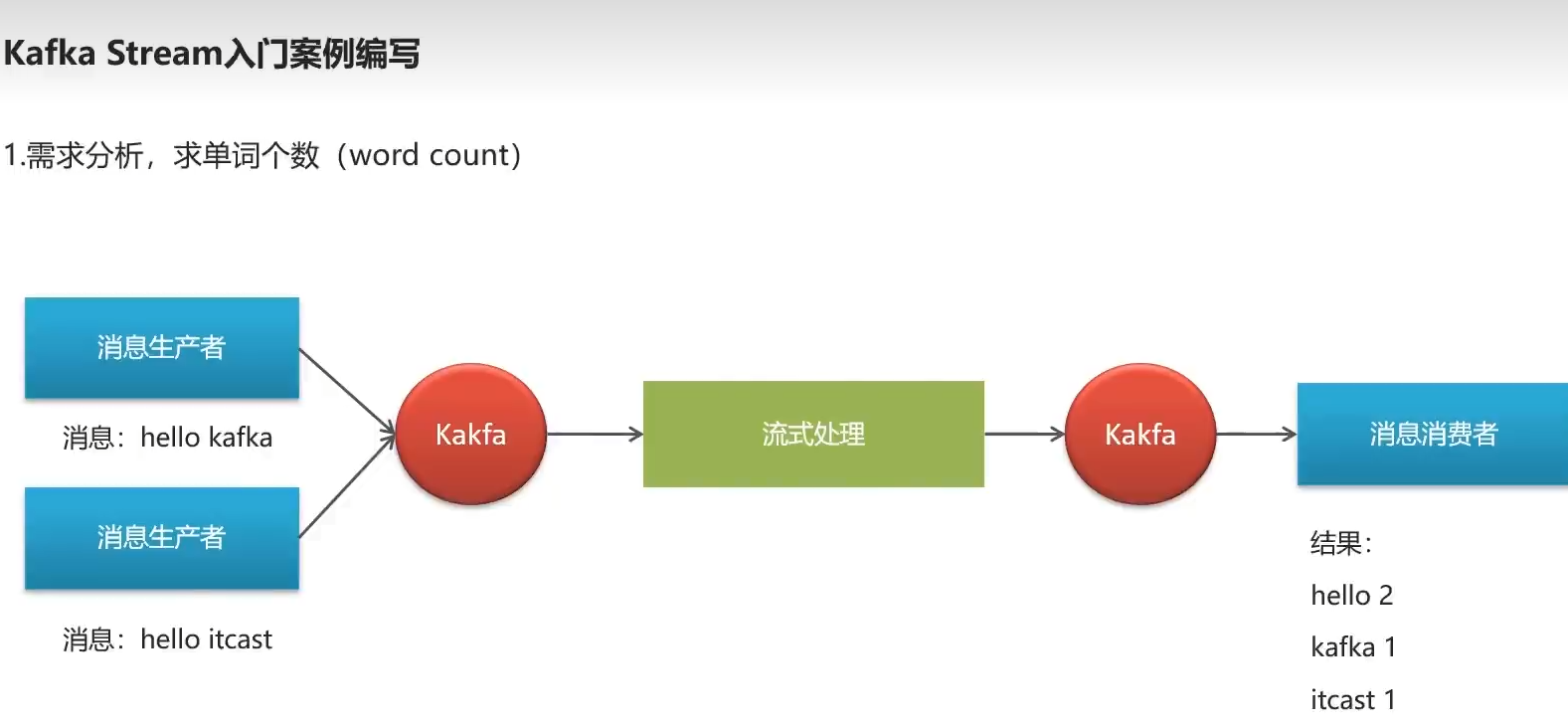
分析单词出现个数
依赖
直接拷贝代码,看个大概以后有用到再深入
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusions><exclusion><artifactId>connect-json</artifactId><groupId>org.apache.kafka</groupId></exclusion><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency>
快速入门
packagecom.heima.kafka.sample;importorg.apache.kafka.common.serialization.Serdes;importorg.apache.kafka.streams.KafkaStreams;importorg.apache.kafka.streams.KeyValue;importorg.apache.kafka.streams.StreamsBuilder;importorg.apache.kafka.streams.StreamsConfig;importorg.apache.kafka.streams.kstream.KStream;importorg.apache.kafka.streams.kstream.TimeWindows;importorg.apache.kafka.streams.kstream.ValueMapper;importjava.time.Duration;importjava.util.Arrays;importjava.util.Properties;/**
* 流式处理
*/publicclassKafkaStreamQuickStart{publicstaticvoidmain(String[] args){//kafka的配置信心Properties prop =newProperties();
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.130:9092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG,Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"streams-quickstart");//stream 构建器StreamsBuilder streamsBuilder =newStreamsBuilder();//流式计算streamProcessor(streamsBuilder);//创建kafkaStream对象KafkaStreams kafkaStreams =newKafkaStreams(streamsBuilder.build(),prop);//开启流式计算
kafkaStreams.start();}/**
* 流式计算
* 消息的内容:hello kafka hello itcast
* @param streamsBuilder
*/privatestaticvoidstreamProcessor(StreamsBuilder streamsBuilder){//创建kstream对象,同时指定从那个topic中接收消息KStream<String,String> stream = streamsBuilder.stream("itcast-topic-input");/**
* 处理消息的value
*/
stream.flatMapValues(newValueMapper<String,Iterable<String>>(){@OverridepublicIterable<String>apply(String value){returnArrays.asList(value.split(" "));}})//按照value进行聚合处理.groupBy((key,value)->value)//时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))//统计单词的个数.count()//转换为kStream.toStream().map((key,value)->{System.out.println("key:"+key+",vlaue:"+value);returnnewKeyValue<>(key.key().toString(),value.toString());})//发送消息.to("itcast-topic-out");}}
大概内容为
1.配置对象prop填写配置参数
kv的序列反序列化器,
服务端地址
流的ID
2.管道流构造
3.管道流计算
①读取topic对应的信息 ,每条消息有K和value value为具体的单词
②调用值转换器flatMapValues,匿名内部类迭代器,转所有单词为数组
③分组,重复的单词作为key,value为单词
④时间窗口,10秒内的聚合处理一次
⑤转stream,map遍历打印,并将键和值转换为字符串类型。
⑥加工后的数据发回给 对应topic的生产者
测试

生产者指定topic,循环5次发信息
packagecom.heima.kafka.sample;importlombok.extern.slf4j.Slf4j;importorg.apache.kafka.clients.producer.*;importjava.util.Properties;importjava.util.concurrent.ExecutionException;/**
* 生产者
*/@Slf4jpublicclassProducerQuickStart{publicstaticvoidmain(String[] args)throwsExecutionException,InterruptedException{// 1.kafka链接配置信息Properties prop =newProperties();// kafka链接地址
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.233.136:9092");// key和value的序列化
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 设置acks配置
prop.put(ProducerConfig.ACKS_CONFIG,"all");//设置超时重传次数
prop.put(ProducerConfig.RETRIES_CONFIG,"10");// 2.创建kafka生产者对象KafkaProducer<String,String> producer =newKafkaProducer<String,String>(prop);// 3.发送record消息/**
* 第一个参数 :topic
* 第二个参数:消息的key
* 第三个参数:消息的value
*/// ProducerRecord<String,String> kvProducerRecord = new ProducerRecord<String,String>("topic-first","key-001","hello kafka");// ProducerRecord<String,String> kvProducerRecord = new ProducerRecord<String,String>("topic-first",0,"key-001","hello kafka");// ProducerRecord<String, String> kvProducerRecord = new ProducerRecord<String, String>("topic-first", "hello kafka");for(int i =0; i <5; i++){ProducerRecord<String,String> kvProducerRecord =newProducerRecord<String,String>("itcast-topic-input","hello kafka");
producer.send(kvProducerRecord);}// // 同步消息发送// RecordMetadata recordMetadata = producer.send(kvProducerRecord).get();// System.out.println(recordMetadata.offset());// System.out.println("发送了消息");// 异步消息发送// producer.send(kvProducerRecord, new Callback() {// @Override// public void onCompletion(RecordMetadata recordMetadata, Exception e) {// if (e != null) {// System.out.println("记录异常消息到日志表中");// }// System.out.println("发送了消息,偏移量为:"+recordMetadata.offset());// }// });// 4.关闭消息通道 必须要关闭,否则消息发送不成功
producer.close();}}
消费者订阅
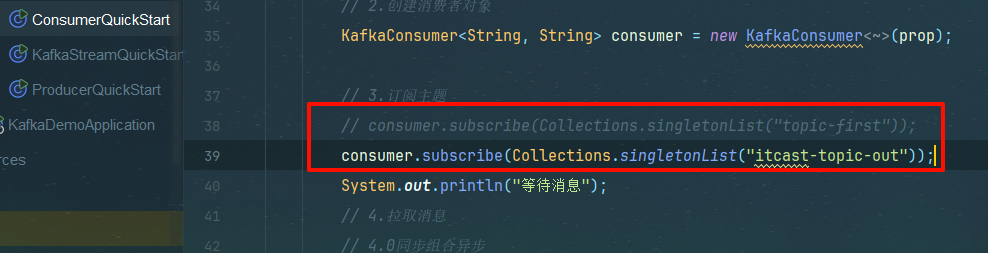
注释掉原来的订阅内容
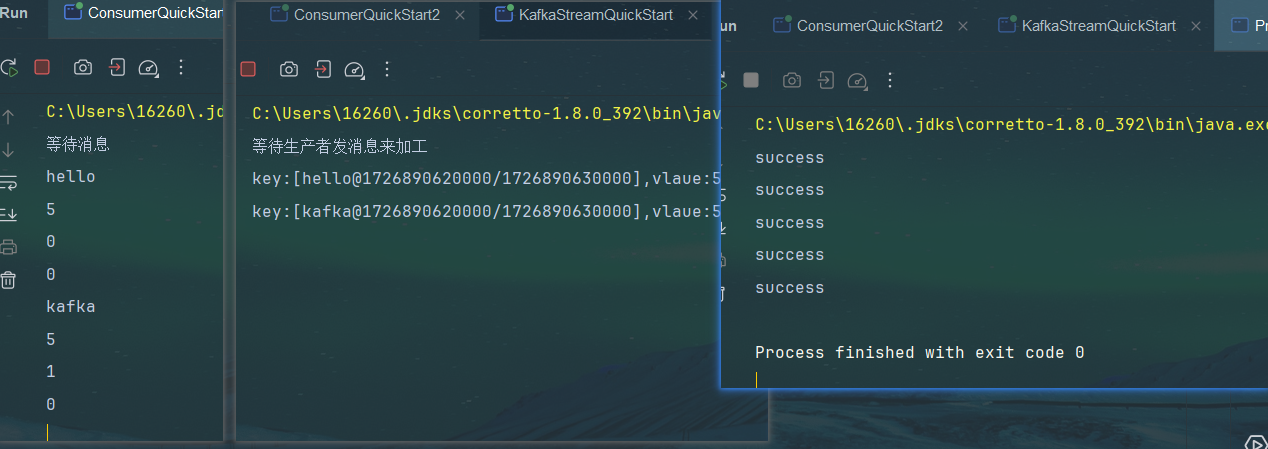
依次启动

3.3)springboot集成kStream
springboot依赖没有很好的配置好kstream,自己搞一个bean配置,然后写yml配置文件,最后设置kstream监听,测试就还是用刚才的producer测试
配置类
packagecom.heima.kafka.config;importlombok.Getter;importlombok.Setter;importorg.apache.kafka.common.serialization.Serdes;importorg.apache.kafka.streams.StreamsConfig;importorg.springframework.boot.context.properties.ConfigurationProperties;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importorg.springframework.kafka.annotation.EnableKafkaStreams;importorg.springframework.kafka.annotation.KafkaStreamsDefaultConfiguration;importorg.springframework.kafka.config.KafkaStreamsConfiguration;importjava.util.HashMap;importjava.util.Map;/**
* 通过重新注册KafkaStreamsConfiguration对象,设置自定配置参数
*/@Setter@Getter@Configuration@EnableKafkaStreams@ConfigurationProperties(prefix="kafka")publicclassKafkaStreamConfig{privatestaticfinalintMAX_MESSAGE_SIZE=16*1024*1024;privateString hosts;privateString group;@Bean(name =KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)publicKafkaStreamsConfigurationdefaultKafkaStreamsConfig(){Map<String,Object> props =newHashMap<>();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);
props.put(StreamsConfig.APPLICATION_ID_CONFIG,this.getGroup()+"_stream_aid");
props.put(StreamsConfig.CLIENT_ID_CONFIG,this.getGroup()+"_stream_cid");
props.put(StreamsConfig.RETRIES_CONFIG,10);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG,Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());returnnewKafkaStreamsConfiguration(props);}}
配置文件
kafka:hosts: 192.168.233.136:9092group: ${spring.application.name}
监听器
packagecom.heima.kafka.stream;importlombok.extern.slf4j.Slf4j;importorg.apache.kafka.streams.KeyValue;importorg.apache.kafka.streams.StreamsBuilder;importorg.apache.kafka.streams.kstream.KStream;importorg.apache.kafka.streams.kstream.TimeWindows;importorg.apache.kafka.streams.kstream.ValueMapper;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importjava.time.Duration;importjava.util.Arrays;@Configuration@Slf4jpublicclassKafkaStreamHelloListener{@BeanpublicKStream<String,String>kStream(StreamsBuilder streamsBuilder){//创建kstream对象,同时指定从那个topic中接收消息KStream<String,String> stream = streamsBuilder.stream("itcast-topic-input");
stream.flatMapValues(newValueMapper<String,Iterable<String>>(){@OverridepublicIterable<String>apply(String value){returnArrays.asList(value.split(" "));}})//根据value进行聚合分组.groupBy((key,value)->value)//聚合计算时间间隔.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))//求单词的个数.count().toStream()//处理后的结果转换为string字符串.map((key,value)->{System.out.println("key:"+key+",value:"+value);returnnewKeyValue<>(key.key().toString(),value.toString());})//发送消息.to("itcast-topic-out");return stream;}}
测试
启动引导类,然后producer生产看下控制台有无接收到

4)实时计算热点(和es一起最蒙逼的一集)
4.1)思路
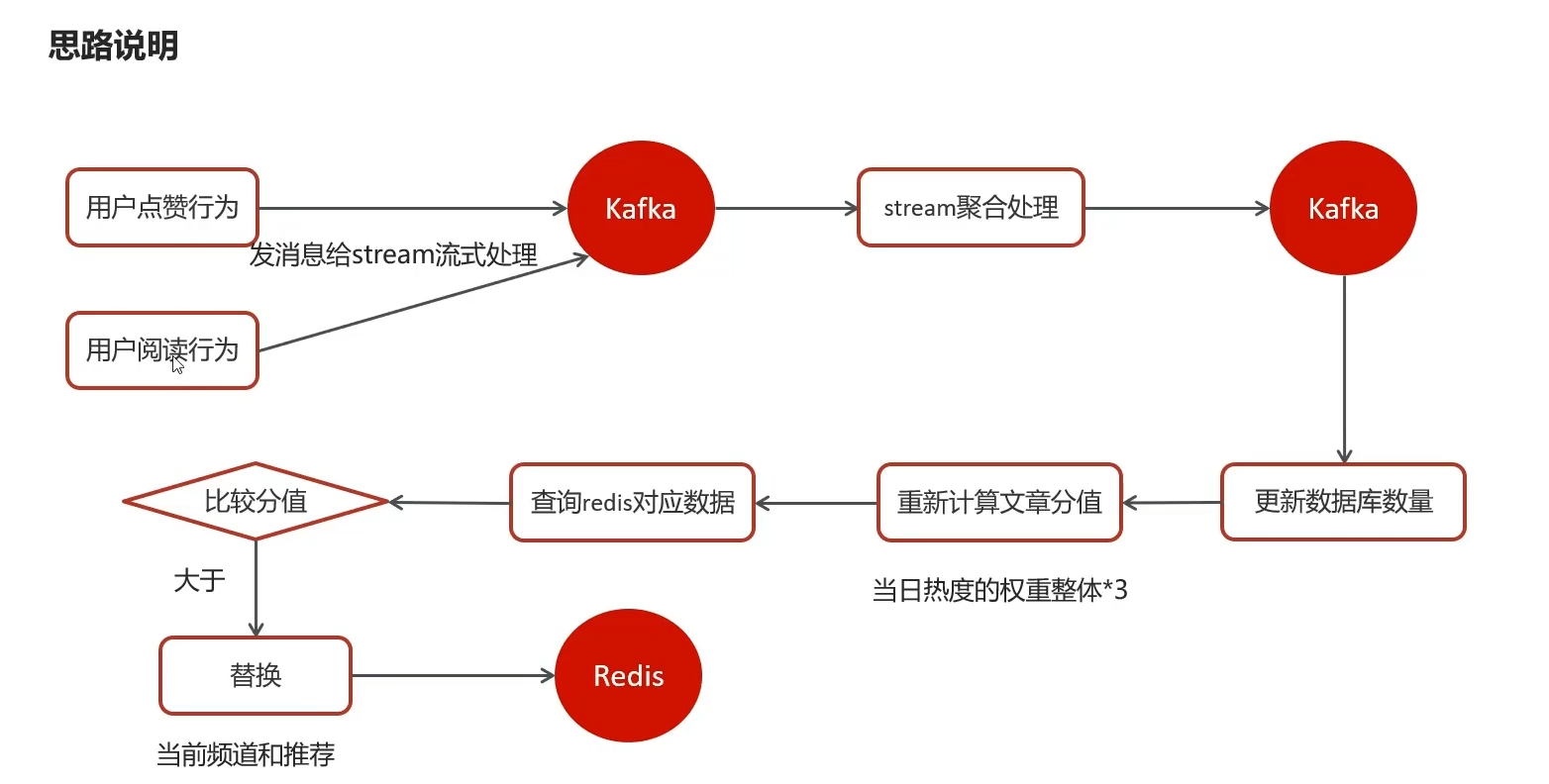
任何行为都会触发 stream流式处理, 在一个时间窗口,范围内聚合发消息到数据库更新行为值
重新根据新行为值(点赞service里)计算当前文章分值
查redis,与频道和推荐最小的比较,大于就替换,保证永远是最热度的文章
4.2)步骤
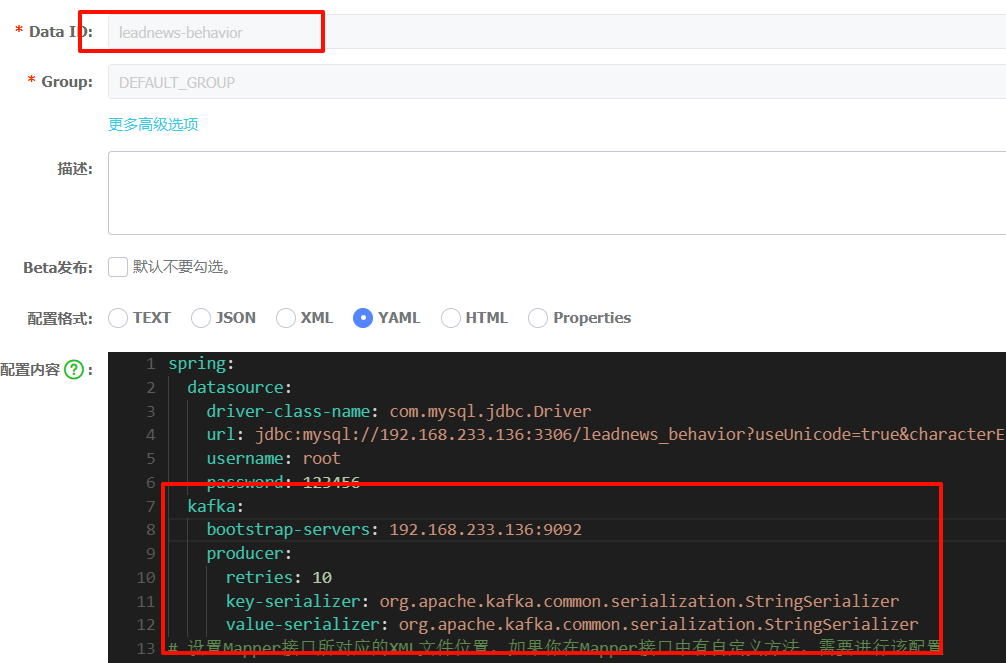
4.2.1)行为服务集成kafka
nacos
kafka:
bootstrap-servers: 192.168.200.130:9092
producer:
retries: 10
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
4.2.2)消息实体
传递什么值能更新到数据库?
文章id,行为类型(enum),行为是加分还是减分的
packagecom.heima.model.mess;importlombok.Data;@DatapublicclassUpdateArticleMess{/**
* 修改文章的字段类型
*/privateUpdateArticleType type;/**
* 文章ID
*/privateLong articleId;/**
* 修改数据的增量,可为正负
*/privateInteger add;publicenumUpdateArticleType{COLLECTION,COMMENT,LIKES,VIEWS;}}
4.2.3)topic常量
packagecom.heima.common.constants;publicclassHotArticleConstants{publicstaticfinalStringHOT_ARTICLE_SCORE_TOPIC="hot.article.score.topic";}
4.2.4)业务层
点赞的消息发送
packagecom.heima.behavior.service.impl;importcom.alibaba.fastjson.JSON;importcom.heima.behavior.service.LikeService;importcom.heima.common.constants.BeHaviorConstants;importcom.heima.common.constants.HotArticleConstants;importcom.heima.common.constants.UserConstants;importcom.heima.common.redis.CacheService;importcom.heima.model.behavior.LikesBehaviorDto;importcom.heima.model.common.dtos.ResponseResult;importcom.heima.model.common.enums.AppHttpCodeEnum;importcom.heima.model.mess.UpdateArticleMess;importcom.heima.model.user.pojos.ApUser;importcom.heima.utils.thread.AppThreadLocalUtil;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.kafka.core.KafkaTemplate;importorg.springframework.stereotype.Service;importstaticorg.apache.hadoop.hbase.Version.user;@ServicepublicclassLikeServiceImplimplementsLikeService{@AutowiredprivateCacheService cacheService;@AutowiredprivateKafkaTemplate<String,String> kafkaTemplate;/**
* 用户点赞
*
* @param dto
*/@OverridepublicResponseResultuserLikesArticle(LikesBehaviorDto dto){// 1.登录状态判断String userId =AppThreadLocalUtil.getUser().getId().toString();if(userId.isEmpty()){returnResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN);}// 2.参数校验if(dto ==null){returnResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}// 3.拼接key,后续查找String key ="";// LIKE-ARTICLE/COMMENT-123451if(dto.getType()==0){
key =BeHaviorConstants.LIKE_ARTICLE+ dto.getArticleId();}if(dto.getType()==1){
key =BeHaviorConstants.LIKE_DYNAMIC+ dto.getArticleId();}if(dto.getType()==2){
key =BeHaviorConstants.LIKE_COMMENT+ dto.getArticleId();}UpdateArticleMess articleMess =newUpdateArticleMess();
articleMess.setArticleId(dto.getArticleId());
articleMess.setType(UpdateArticleMess.UpdateArticleType.LIKES);// 3.判断是点赞还是取消if(dto.getOperation()==0){if(cacheService.hGet(key,userId)!=null){returnResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID,"已点赞,请勿重复操作");}
cacheService.hPut(key,userId,JSON.toJSONString(dto));
articleMess.setAdd(1);}else{
cacheService.hDelete(key,userId);
articleMess.setAdd(-1);}
kafkaTemplate.send(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC,JSON.toJSONString(articleMess));returnResponseResult.okResult(AppHttpCodeEnum.SUCCESS);}}
行为的消息发送
packagecom.heima.behavior.service.impl;importcom.alibaba.fastjson.JSON;importcom.heima.behavior.service.ReadService;importcom.heima.common.constants.BeHaviorConstants;importcom.heima.common.constants.HotArticleConstants;importcom.heima.common.redis.CacheService;importcom.heima.model.behavior.ReadBehaviorDto;importcom.heima.model.common.dtos.ResponseResult;importcom.heima.model.common.enums.AppHttpCodeEnum;importcom.heima.model.mess.UpdateArticleMess;importcom.heima.model.user.pojos.ApUser;importcom.heima.utils.thread.AppThreadLocalUtil;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.kafka.core.KafkaTemplate;importorg.springframework.stereotype.Service;@ServicepublicclassReadServiceImplimplementsReadService{@AutowiredprivateCacheService cacheServicel;@AutowiredprivateKafkaTemplate kafkaTemplate;/**
* 用户访问,记录+1
*
* @param dto
*/@OverridepublicResponseResultuserReadArticle(ReadBehaviorDto dto){// 1.登录校验ApUser user =AppThreadLocalUtil.getUser();if(user ==null){returnResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN);}// 2.参数校验if(dto ==null|| dto.getArticleId()==null){returnResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}// 2.1拼串String key =BeHaviorConstants.READ_ARTICLE+ dto.getArticleId();// 3.查出来,转dto,根据查出来的count和前端传来的count相加,再put// 这一步不能直接查出来转对象,因为有可能为空,后续再转对象// 在redis里,转对象,给dto加值,然后再Hput到redis// 不在,那就直接拿前端那个dto 塞进去// 注意这里Object不能.toString 因为有可能为空,应cast转为stringString redisString =(String) cacheServicel.hGet(key, user.getId().toString());if(redisString !=null){ReadBehaviorDto readBehaviorDto =JSON.parseObject(redisString,ReadBehaviorDto.class);
dto.setCount(readBehaviorDto.getCount()+ dto.getCount());}
cacheServicel.hPut(BeHaviorConstants.READ_ARTICLE+ dto.getArticleId().toString(), user.getId().toString(),JSON.toJSONString(dto));UpdateArticleMess articleMess =newUpdateArticleMess();
articleMess.setArticleId(dto.getArticleId());
articleMess.setType(UpdateArticleMess.UpdateArticleType.VIEWS);
articleMess.setAdd(1);
kafkaTemplate.send(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC,JSON.toJSONString(articleMess));returnResponseResult.okResult(AppHttpCodeEnum.SUCCESS);}}
结尾处组装mess发送消息即可
4.2.5)聚合stream
先集成到服务里
参考demo
nacos
kafka:hosts: 192.168.233.136:9092group: ${spring.application.name}
config
packagecom.heima.article.config;importlombok.Getter;importlombok.Setter;importorg.apache.kafka.common.serialization.Serdes;importorg.apache.kafka.streams.StreamsConfig;importorg.springframework.boot.context.properties.ConfigurationProperties;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importorg.springframework.kafka.annotation.EnableKafkaStreams;importorg.springframework.kafka.annotation.KafkaStreamsDefaultConfiguration;importorg.springframework.kafka.config.KafkaStreamsConfiguration;importjava.util.HashMap;importjava.util.Map;/**
* 通过重新注册KafkaStreamsConfiguration对象,设置自定配置参数
*/@Setter@Getter@Configuration@EnableKafkaStreams@ConfigurationProperties(prefix="kafka")publicclassKafkaStreamConfig{privatestaticfinalintMAX_MESSAGE_SIZE=16*1024*1024;privateString hosts;privateString group;@Bean(name =KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)publicKafkaStreamsConfigurationdefaultKafkaStreamsConfig(){Map<String,Object> props =newHashMap<>();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);
props.put(StreamsConfig.APPLICATION_ID_CONFIG,this.getGroup()+"_stream_aid");
props.put(StreamsConfig.CLIENT_ID_CONFIG,this.getGroup()+"_stream_cid");
props.put(StreamsConfig.RETRIES_CONFIG,10);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG,Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());returnnewKafkaStreamsConfiguration(props);}}
常量增加
publicstaticfinalStringHOT_ARTICLE_INCR_HANDLE_TOPIC="hot.article.incr.handle.topic";
数据加工实体类
packagecom.heima.model.mess;importlombok.Data;@DatapublicclassArticleVisitStreamMess{/**
* 文章id
*/privateLong articleId;/**
* 阅读
*/privateint view;/**
* 收藏
*/privateint collect;/**
* 评论
*/privateint comment;/**
* 点赞
*/privateint like;}
聚合类
packagecom.heima.article.stream;importcom.alibaba.fastjson.JSON;importcom.heima.common.constants.HotArticleConstants;importcom.heima.model.mess.ArticleVisitStreamMess;importcom.heima.model.mess.UpdateArticleMess;importlombok.extern.slf4j.Slf4j;importorg.apache.commons.lang3.StringUtils;importorg.apache.kafka.streams.KeyValue;importorg.apache.kafka.streams.StreamsBuilder;importorg.apache.kafka.streams.kstream.*;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importjava.time.Duration;@Configuration@Slf4jpublicclassHotArticleStreamHandler{@BeanpublicKStream<String,String>kStream(StreamsBuilder streamsBuilder){//接收消息KStream<String,String> stream = streamsBuilder.stream(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC);//聚合流式处理
stream.map((key,value)->{UpdateArticleMess mess =JSON.parseObject(value,UpdateArticleMess.class);//重置消息的key:1234343434 和 value: likes:1returnnewKeyValue<>(mess.getArticleId().toString(),mess.getType().name()+":"+mess.getAdd());})//按照文章id进行聚合.groupBy((key,value)->key)//时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))/**
* 自行的完成聚合的计算
*/.aggregate(newInitializer<String>(){/**
* 初始方法,返回值是消息的value
* @return
*/@OverridepublicStringapply(){return"COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0";}/**
* 真正的聚合操作,返回值是消息的value
*/},newAggregator<String,String,String>(){@OverridepublicStringapply(String key,String value,String aggValue){if(StringUtils.isBlank(value)){return aggValue;}String[] aggAry = aggValue.split(",");int col =0,com=0,lik=0,vie=0;for(String agg : aggAry){String[] split = agg.split(":");/**
* 获得初始值,也是时间窗口内计算之后的值
*/switch(UpdateArticleMess.UpdateArticleType.valueOf(split[0])){caseCOLLECTION:
col =Integer.parseInt(split[1]);break;caseCOMMENT:
com =Integer.parseInt(split[1]);break;caseLIKES:
lik =Integer.parseInt(split[1]);break;caseVIEWS:
vie =Integer.parseInt(split[1]);break;}}/**
* 累加操作
*/String[] valAry = value.split(":");switch(UpdateArticleMess.UpdateArticleType.valueOf(valAry[0])){caseCOLLECTION:
col +=Integer.parseInt(valAry[1]);break;caseCOMMENT:
com +=Integer.parseInt(valAry[1]);break;caseLIKES:
lik +=Integer.parseInt(valAry[1]);break;caseVIEWS:
vie +=Integer.parseInt(valAry[1]);break;}String formatStr =String.format("COLLECTION:%d,COMMENT:%d,LIKES:%d,VIEWS:%d", col, com, lik, vie);System.out.println("文章的id:"+key);System.out.println("当前时间窗口内的消息处理结果:"+formatStr);return formatStr;}},Materialized.as("hot-atricle-stream-count-001")).toStream().map((key,value)->{returnnewKeyValue<>(key.key().toString(),formatObj(key.key().toString(),value));})//发送消息.to(HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC);return stream;}/**
* 格式化消息的value数据
* @param articleId
* @param value
* @return
*/publicStringformatObj(String articleId,String value){ArticleVisitStreamMess mess =newArticleVisitStreamMess();
mess.setArticleId(Long.valueOf(articleId));//COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0String[] valAry = value.split(",");for(String val : valAry){String[] split = val.split(":");switch(UpdateArticleMess.UpdateArticleType.valueOf(split[0])){caseCOLLECTION:
mess.setCollect(Integer.parseInt(split[1]));break;caseCOMMENT:
mess.setComment(Integer.parseInt(split[1]));break;caseLIKES:
mess.setLike(Integer.parseInt(split[1]));break;caseVIEWS:
mess.setView(Integer.parseInt(split[1]));break;}}
log.info("聚合消息处理之后的结果为:{}",JSON.toJSONString(mess));returnJSON.toJSONString(mess);}}
大概就是一开始为like collect view comment设置初始值
根据上一次的流进行递增一开始setAdd的正/负值,10秒内统计累加或累减后的值
最后糅杂 计算后的值和文章id 的KeyValue对象,to发送给下游塞到数据库里
到现在完成了上半部分流程,接下来下半部分
4.2.6)数据库数量业务
思路
1.更新到数据库
2.分值*3
3.分别替换当前文章对应媒体或推荐页的redis,
先把redis里的数据拿出来用list装好,然后开始验证,后面加工处理完在放回redis
①存在redis->修改
②不存在redis
- 大于30条,sorted把最大的冒泡到最后一位然后revese getsize-1 拿到垫底的哪个哥们,然后比对,如果比当前文章还要拉跨,那么直接remove,然后拷贝刚才aparticle的完整消息到新的文章,add进去list
- 小于30条,空位管够,直接补充其他数据(bean copyProperty)然后add即可
③此时list,add进来的数据是大于最后一条的,但是不知道有没有大于其他,还得继续排序
④ 准备好key,和json字符串的数组塞回redis
代码
apArticleService
/**
* 更新文章的分值 同时更新缓存中的热点文章数据
* @param mess
*/publicvoidupdateScore(ArticleVisitStreamMess mess);
impl
/**
* 更新文章的分值 同时更新缓存中的热点文章数据
* @param mess
*/@OverridepublicvoidupdateScore(ArticleVisitStreamMess mess){//1.更新文章的阅读、点赞、收藏、评论的数量ApArticle apArticle =updateArticle(mess);//2.计算文章的分值Integer score =computeScore(apArticle);
score = score *3;//3.替换当前文章对应频道的热点数据replaceDataToRedis(apArticle, score,ArticleConstants.HOT_ARTICLE_FIRST_PAGE+ apArticle.getChannelId());//4.替换推荐对应的热点数据replaceDataToRedis(apArticle, score,ArticleConstants.HOT_ARTICLE_FIRST_PAGE+ArticleConstants.DEFAULT_TAG);}/**
* 替换数据并且存入到redis
* @param apArticle
* @param score
* @param s
*/privatevoidreplaceDataToRedis(ApArticle apArticle,Integer score,String s){String articleListStr = cacheService.get(s);if(StringUtils.isNotBlank(articleListStr)){List<HotArticleVo> hotArticleVoList =JSON.parseArray(articleListStr,HotArticleVo.class);boolean flag =true;//如果缓存中存在该文章,只更新分值for(HotArticleVo hotArticleVo : hotArticleVoList){if(hotArticleVo.getId().equals(apArticle.getId())){
hotArticleVo.setScore(score);
flag =false;break;}}//如果缓存中不存在,查询缓存中分值最小的一条数据,进行分值的比较,如果当前文章的分值大于缓存中的数据,就替换if(flag){if(hotArticleVoList.size()>=30){
hotArticleVoList = hotArticleVoList.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());HotArticleVo lastHot = hotArticleVoList.get(hotArticleVoList.size()-1);if(lastHot.getScore()< score){
hotArticleVoList.remove(lastHot);HotArticleVo hot =newHotArticleVo();BeanUtils.copyProperties(apArticle, hot);
hot.setScore(score);
hotArticleVoList.add(hot);}}else{HotArticleVo hot =newHotArticleVo();BeanUtils.copyProperties(apArticle, hot);
hot.setScore(score);
hotArticleVoList.add(hot);}}//缓存到redis
hotArticleVoList = hotArticleVoList.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());
cacheService.set(s,JSON.toJSONString(hotArticleVoList));}}/**
* 更新文章行为数量
* @param mess
*/privateApArticleupdateArticle(ArticleVisitStreamMess mess){ApArticle apArticle =getById(mess.getArticleId());
apArticle.setCollection(apArticle.getCollection()==null?0:apArticle.getCollection()+mess.getCollect());
apArticle.setComment(apArticle.getComment()==null?0:apArticle.getComment()+mess.getComment());
apArticle.setLikes(apArticle.getLikes()==null?0:apArticle.getLikes()+mess.getLike());
apArticle.setViews(apArticle.getViews()==null?0:apArticle.getViews()+mess.getView());updateById(apArticle);return apArticle;}/**
* 计算文章的具体分值
* @param apArticle
* @return
*/privateIntegercomputeScore(ApArticle apArticle){Integer score =0;if(apArticle.getLikes()!=null){
score += apArticle.getLikes()*ArticleConstants.HOT_ARTICLE_LIKE_WEIGHT;}if(apArticle.getViews()!=null){
score += apArticle.getViews();}if(apArticle.getComment()!=null){
score += apArticle.getComment()*ArticleConstants.HOT_ARTICLE_COMMENT_WEIGHT;}if(apArticle.getCollection()!=null){
score += apArticle.getCollection()*ArticleConstants.HOT_ARTICLE_COLLECTION_WEIGHT;}return score;}
下游监听器
packagecom.heima.article.listener;importcom.alibaba.fastjson.JSON;importcom.heima.article.service.ApArticleService;importcom.heima.common.constants.HotArticleConstants;importcom.heima.model.mess.ArticleVisitStreamMess;importlombok.extern.slf4j.Slf4j;importorg.apache.commons.lang3.StringUtils;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.kafka.annotation.KafkaListener;importorg.springframework.stereotype.Component;@Component@Slf4jpublicclassArticleIncrHandleListener{@AutowiredprivateApArticleService apArticleService;@KafkaListener(topics =HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC)publicvoidonMessage(String mess){if(StringUtils.isNotBlank(mess)){ArticleVisitStreamMess articleVisitStreamMess =JSON.parseObject(mess,ArticleVisitStreamMess.class);
apArticleService.updateScore(articleVisitStreamMess);}}}
监听,转化对象,调方法
测试
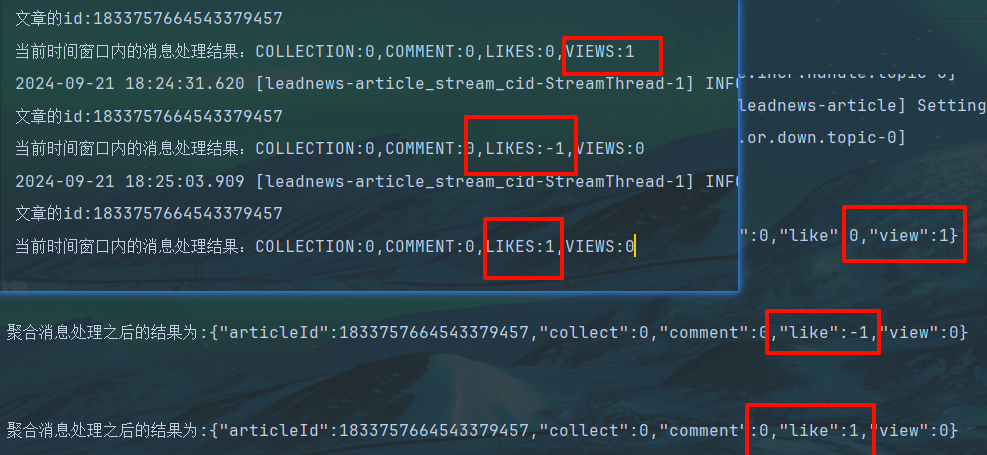
后续集成到博客再来学这一块内容,挖个坑
版权归原作者 Zww0891 所有, 如有侵权,请联系我们删除。