
常见错误
too many part
举例:spark写入clickhouse部分task爆出too many part的异常,如下图

虽然作业最终运行成功,但此异常会造成数据不一致
例如:200w条数据通过spark 写入 clickhouse - MergeTree表,导致最终结果为206W条
脏数据原因:spark某个task任务在写入clickhouse时clickhouse抛出异常,造成task作业重试,从而导致相同的数据重复写入【脏数据】,造成数据不一致问题
too many part异常原因:当数据插入到[clickhouse]表时,每一批插入都会生成对应parts文件,clickhouse后台会有合并小文件的操作。当插入速度过快,生成parts小文件过多时,clickhouse无法以适当的速度合并这些parts时会报上面这个错误。
例如spark并发数为200,这样一批写入到clickhouse中就会产生200个文件,几批下来如果clickhouse内部线程没来及合并相同分区,就会抛异常
我们来看一下报错表的数据文件:
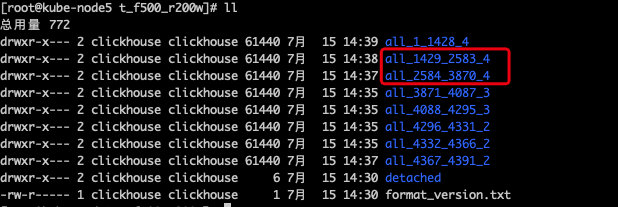
可以看到从3870到2584跨越了1286多个文件目录,被合并了四次,平均下来每次合并321.5个文件
而clickhouse默认一次合并超过300个文件就会报错,来看一下配置:

定位到了问题,来看一下解决方案:
1、spark写入clickhouse的并发数调小,批处理的数据size间隔调大,比如之前200并发调整到50并发,从之前一批1w条数据调整到5w条数据,从而减少clickhouse文件的个数,避免超过parts_to_throw_insert默认值
2、增加可合并的分区数,修改clickhouse配置:
<merge_tree><parts_to_delay_insert>600</parts_to_delay_insert><parts_to_throw_insert>600</parts_to_throw_insert><max_delay_to_insert>2</max_delay_to_insert><max_suspicious_broken_parts>5</max_suspicious_broken_parts></merge_tree>
保存后重启即可
3、若仍有部分task异常重试导致脏数据,则建议将MergeTree引擎改为ReplacingMergeTree引擎,通过去重机制解决
ReplacingMergeTree引擎的特点是分区内去重,根据order by 字段判断数据的唯一性
建议使用时间为版本号,这样当判断重复数据时保留最后一条插入的数据,例如:
# 建表CREATETABLE replace_table_v(
id String,
code String,
create_time DateTime)ENGINE= ReplacingMergeTree(create_time)ORDERBY id
# 插入数据INSERTINTO replace_table_v VALUES('001','CODE','2020-02-01'),('001','CODE','2020-02-02'),('001','CODE','2020-02-03')# 查询select*from replace_table_v
┌─id──┬─code─┬─────────create_time─┐
│ 001 │ CODE │ 2020-02-0300:00:00 │
└─────┴──────┴─────────────────────┘
通过以上几种方式可以解决此类问题;
版权归原作者 高世之智 所有, 如有侵权,请联系我们删除。