
ZooKeeper 应用场景
ZooKeeper:分布式协调服务,仲裁机构。基于ZNode数据模型和Watcher监听机制可以解决很多问题,比如分布式锁问题。
应用场景如下:
1、发布/订阅
2、命名服务
3、配置管理
4、集群管理
5、分布式锁
6、队列管理
7、负载均衡
发布订阅
应用服务器集群可能存在两个问题:
1、集群中有很多机器,当某个通用的配置发生变化后,怎么自动让所有服务器的配置同时生效?——配置管理问题
2、当集群中某个节点宕机,如何让集群中的其他节点感知?——集权管理的问题
为了解决这两个问题,ZooKeeper引入了Watcher机制来实现发布/订阅功能,能够让多个订阅者同时监听某一个主题对象,当这个主题对象自身状态发生变化时,会通知所有订阅者。
订阅者:在zookeeper架构中,其实就是 注册监听的客户端
发布者:在zookeeper架构中,其实就是 触发事件发生的客户端
数据发布/订阅即所谓的配置中心:发布者将数据发布到ZooKeeper的一个或一些节点上,订阅者进行数据订阅,可以及时得到数据变化的通知。
消息/数据的发送有2中设计模式,推Push和拉Pull。
ZooKeeper采用推拉结合,客户端向服务端注册自己需要关注的事件,一旦该节点数据发生该事件,服务器向客户端发送事件Watcher通知,客户端收到消息主动从服务端获取最新数据。这种模式适用于配置信息获取同步。
命名服务
唯一ID生成服务。
命名服务是分布式系统中较为常见的一类场景,分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等,通过命名服务,客户端可以根据指定名字来获取资源的实体、服务地址和提供者的信息。ZooKeeper也可帮助应用系统通过资源引用的方式实现对资源的定位和使用,广义上的命名服务的资源定位都不是真正意义上的实体资源,在分布式环境中,上层应用仅仅需要一个全局唯一的名字。ZooKeeper可以实现一套分布式全局唯一ID的分配机制。
ZooKeeper系统中每个znode都有一个绝对唯一的路径。所以只要你创建成功了一个znode节点,意味着,命名了一个全局唯一的名称。另一种方式,通过创建带顺序编号的节点。
由于ZooKeeper可以创建顺序节点,保证了同一节点下子节点是唯一的,所以直接按照存放文件的方法,设置节点,比如一个路径下不可能存在两个相同的文件名,这种定义创建节点,就是全局唯一ID。
切记:这种方式能实现,不推荐在生产环境使用。利用ZooKeeper关于事务请求的严格顺序处理的机制,由于有多台机制执行分布式事务的存在,不如使用一台高性能的服务器做所有请求的顺序处理高效,而且可以自由定义命名规则。
命名服务算法: Twitter的SnowFlake雪花算法,美团的Leaf,滴滴的TinyID等
集群管理
ZooKeeper集群管理理解两点:是否有机器退出和加入(从节点管理)、选举Master(主节点管理)
第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与ZooKeeper的连接断开,其所创建的代表该节点存货状态的临时目录节点被删除,所有其他机器都将收到通知:某个目录被删除。
第二点:所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master。这只是其中一种策略,选举策略完全可以由管理员自己指定。在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络I/O处理),往往只需要让整个集群中的某一台机器进行执行,其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能。
利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建/currentMaster节点,最终一定只有一个客户端请求能够创建成功。利用这个特性,能轻易的在分布式环境中进行 集群选举了。其实只要实现数据唯一就可以做到选举,关系型数据库也可以,但是性能不好,设计复杂。
利用ZooKeeper实现集群管理:包括集群从节点上下线即时感知管理,和 集群主节点选举管理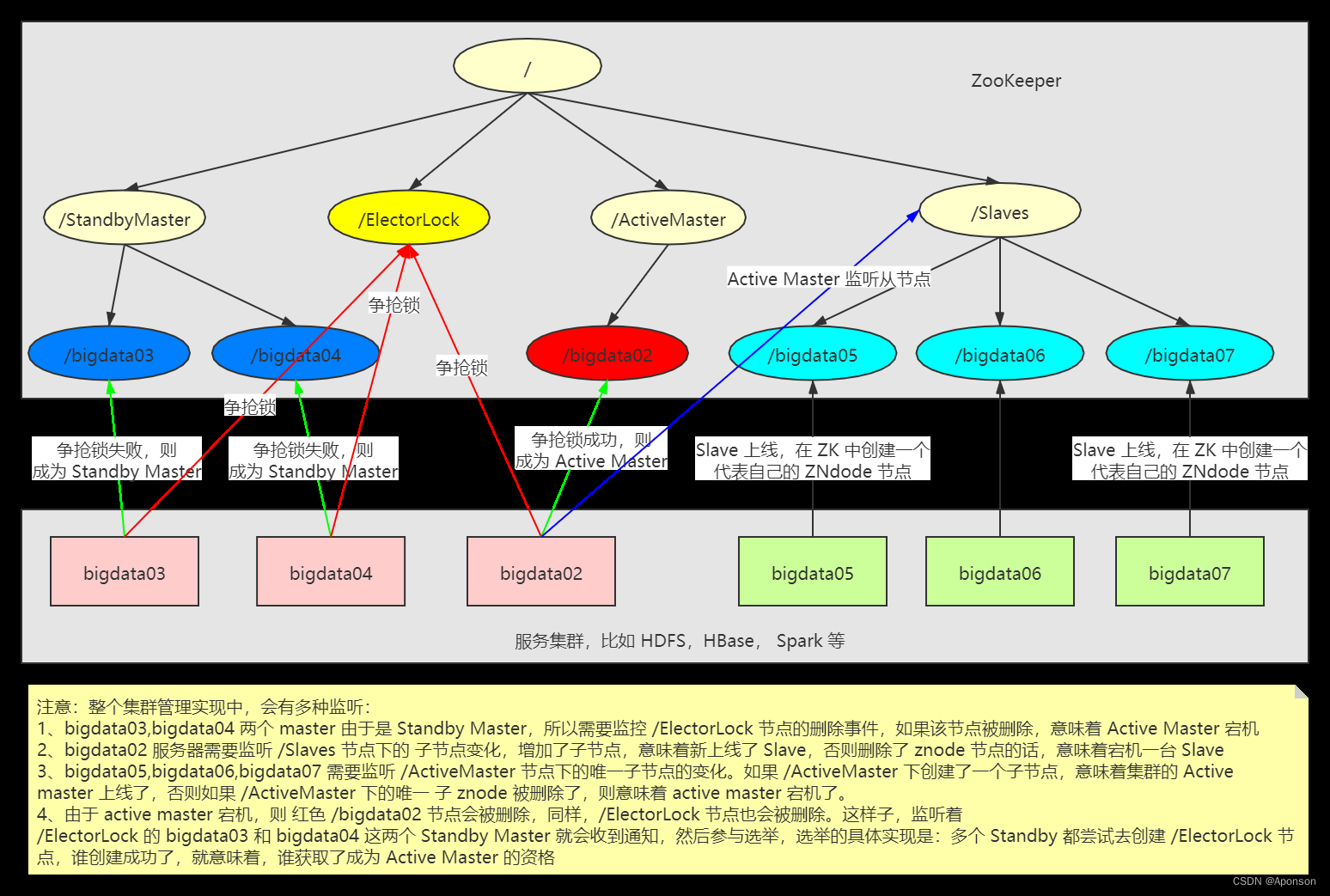
HDFS中DataNode死掉,NameNode需要经过至少630s默认时间,才认为这个节点死掉。
HBase中HRegionServer死掉,HMaster需要经过1s的默认时间,才认为这个接待你死掉。
分布式锁
锁:并发编程中保证线程安全(一个JVM内部的多个线程并发执行的安全)的一种机制,针对临界资源直接进行加锁的操作。只能一个线程拿到。
分布式锁:分布式环境中,如果多个线程想要访问临界资源,也需要加锁,但是比起单进程中的多线程加锁机制,分布式锁,还要考虑网络通信的问题。网络不可靠,消息丢失和消息延迟。
锁服务:独占锁、共享锁、时序锁
独占锁/写锁:对写加锁,保持独占,或者排他锁
共享锁/读锁:对读加锁,可共享访问,释放锁之后才可进行事务操作
时序锁:控制时序
对于第一类(独占锁),将 ZooKeeper 上的一个 znode 看作是一把锁,通过 createznode() 的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终
成功创建的那个客户端代表拥有了这把锁。用完删除掉自己创建的 /distribute_lock 节点就释放出锁。
对于第二类(读写锁),在 ZooKeeper 上生成两个 znode,分别是:/lock_read 和 /lock_write,如果有一个客户端过来读取数据,则先判断 /lock_write 是否
存在,如果不存在,则可以进行读取操作,同时创建一个 /lock_read 下的子节点代表读锁,读取完毕删除掉。如果有一个客户端过来写数据,则先判断 /lock_write
是否存在,再判断 /lock_read 下是否有读锁,如果都没有,则可以进行写操作。
对于第三类(时序锁),/distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录子节点,和选 Master 一样,编号最小的获得锁,用完删除,
依次有序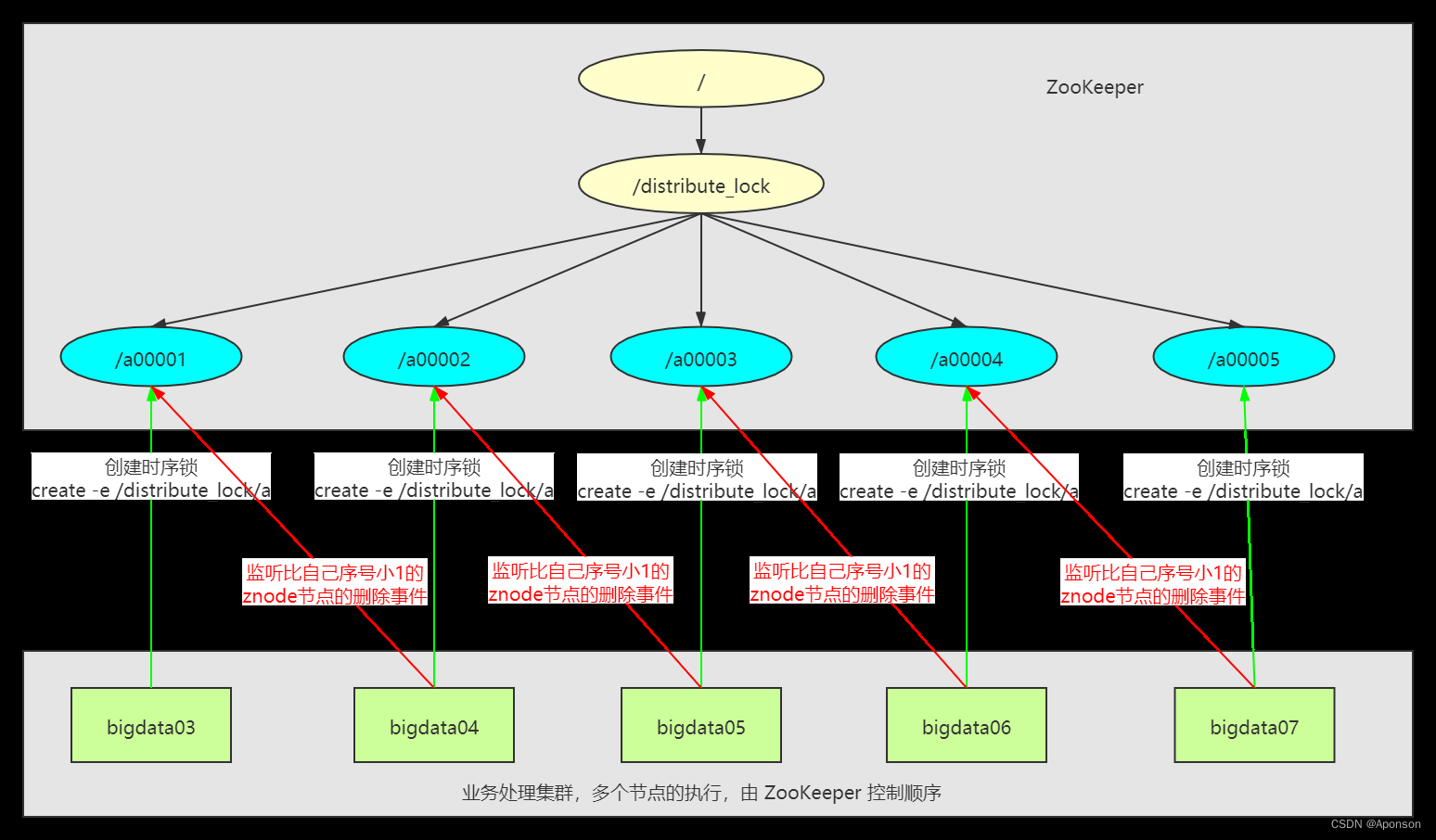
分布式队列管理
两种类型的队列:
1、同步队列/分布式屏障/分布式栅栏:当一个队列成员都聚齐时,队列才可用,否则一直等待所有成员到达
2、先进先出/顺序控制:队列按照FIFO方式进行入队和出队操作。和分布式时序锁一样
第一类,在约定目录下创建临时目录节点,监听节点数目是否是要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。
负载均衡
ZooKeeper 实现负载均衡本质上是利用 ZooKeeper 的配置管理功能,实现负载均衡的步骤:
1、服务提供者把自己的域名及 IP 端口映射注册到 zk 中。
2、服务消费者通过域名从 zk 中获取到对应的 IP 及端口,这里的 IP 及端口可能有多个,只是获取其中一个。
3、当服务提供者宕机时,对应的域名与 IP 的对应就会减少一个映射。
4、阿里的 dubbo 服务框架就是基于 zk 实现服务路由和负载均衡。
ZooKeeper 能实现负载均衡,但是跟 命名服务一样,不推荐使用!
配置管理
HBase 和 Kafka 的架构设计实现中,用 ZooKeeper 做了三件事:
注册中心,利用发布/订阅功能
配置管理,集群中相关重要元数据,保存在ZooKeeper上
HA选举,HBase的Master,Kafka中的Controller角色都是通过ZooKeeper来进行选举
版权归原作者 Aponson 所有, 如有侵权,请联系我们删除。