
🎂前言
另外 2 篇博客
WebServer -- 面试题(下)-CSDN博客
WebServer -- 八股(终章)-CSDN博客
说个大实话,webserver 就是个玩具,八股触发器,入门级,烂大街,没人要的破烂东西,但是你不能不会。
它是不行,但是面试官默认你会了。有了webserver的基础,你才有了点知识储备去做深一点,难一点的开源项目,或者参与到企业级开发里。
退一万步说,就算以后不做后端甚至不做C++了,用来打打 Linux,网络编程,数据库的基础还是好的。
本项目即将结束,手敲 14 篇万字博客,画了 20 多个流程图,整理了 40 多道相关八股
最后3篇博客:架构图 && 面试题(上),面试题(下) && 八股(上),八股(下)
🌼流程图 && 架构图
所有图我都画了一遍,然后,结合画的图,对照着看一遍源码的实现
(实际上,就是对照着流程图,回顾前面写过的博客,将每一个接口联系起来)
Excalidraw | Hand-drawn look & feel • Collaborative • Secure
哈哈哈,回看之前,自己亲手写的 11 篇博客,敲代码过程中的困惑也慢慢解开,融会贯通的感觉
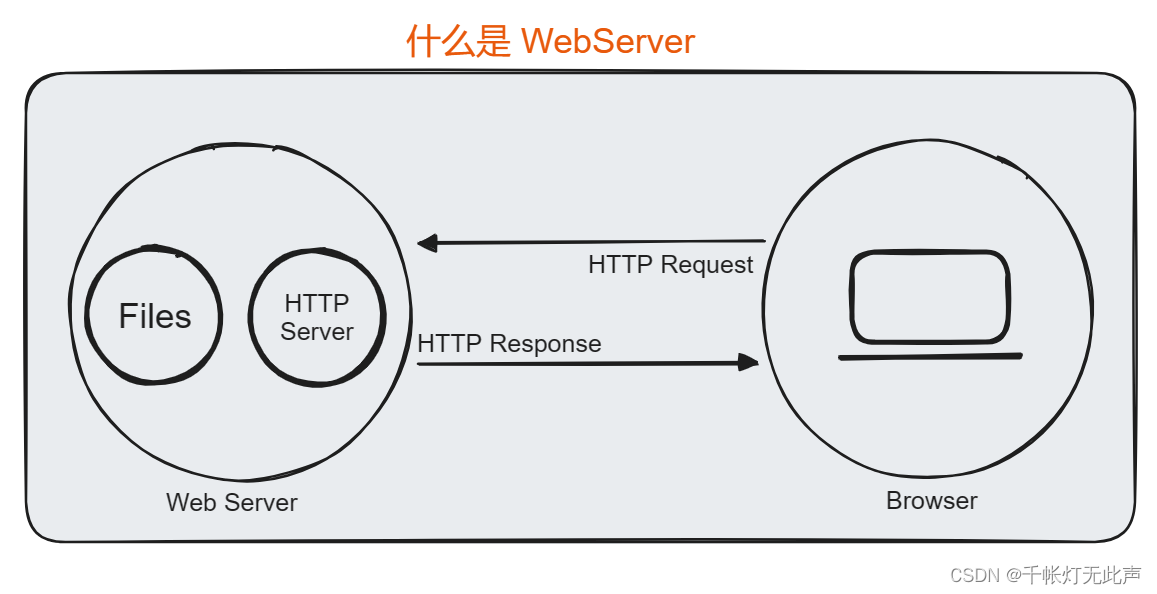
1)什么是 WebServer
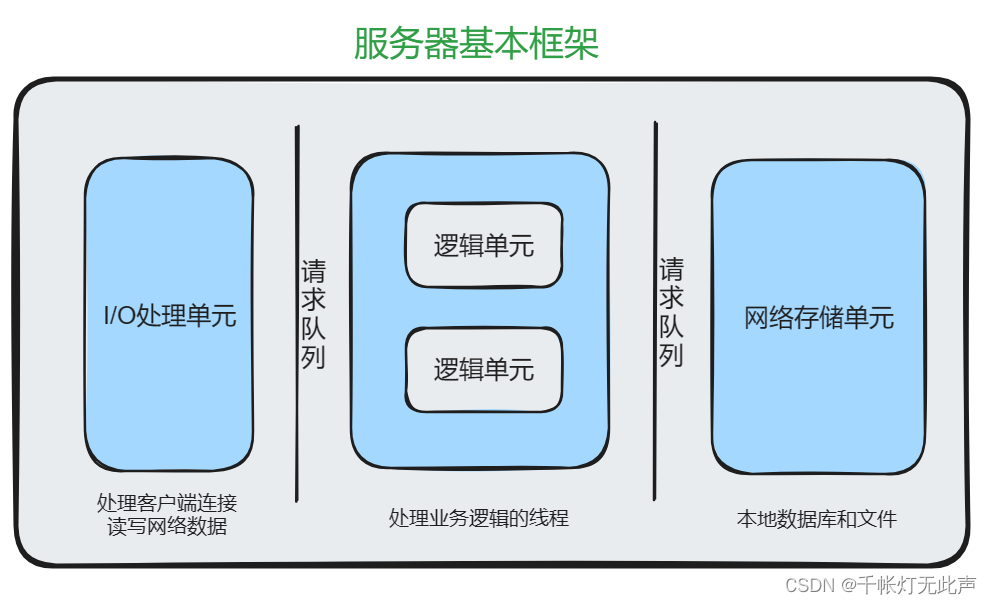
2)服务器基本框架
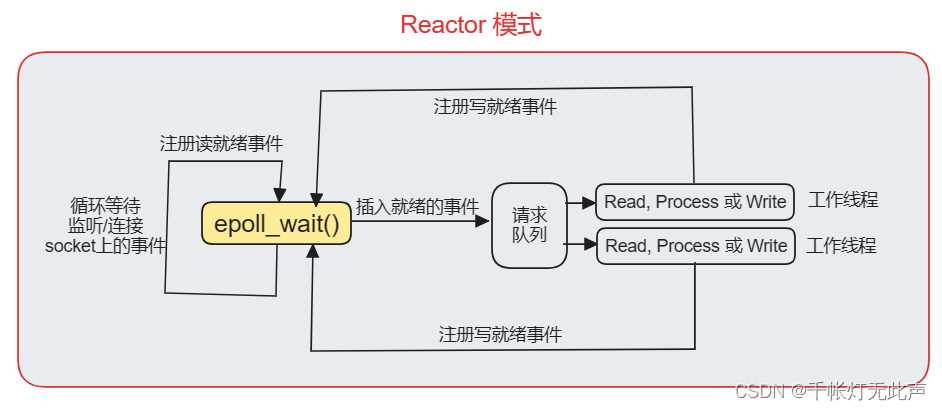
3)Reactor && Proactor 模式
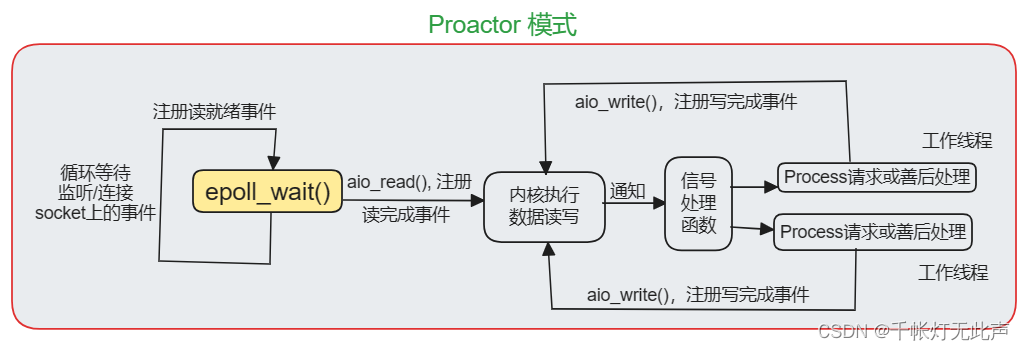
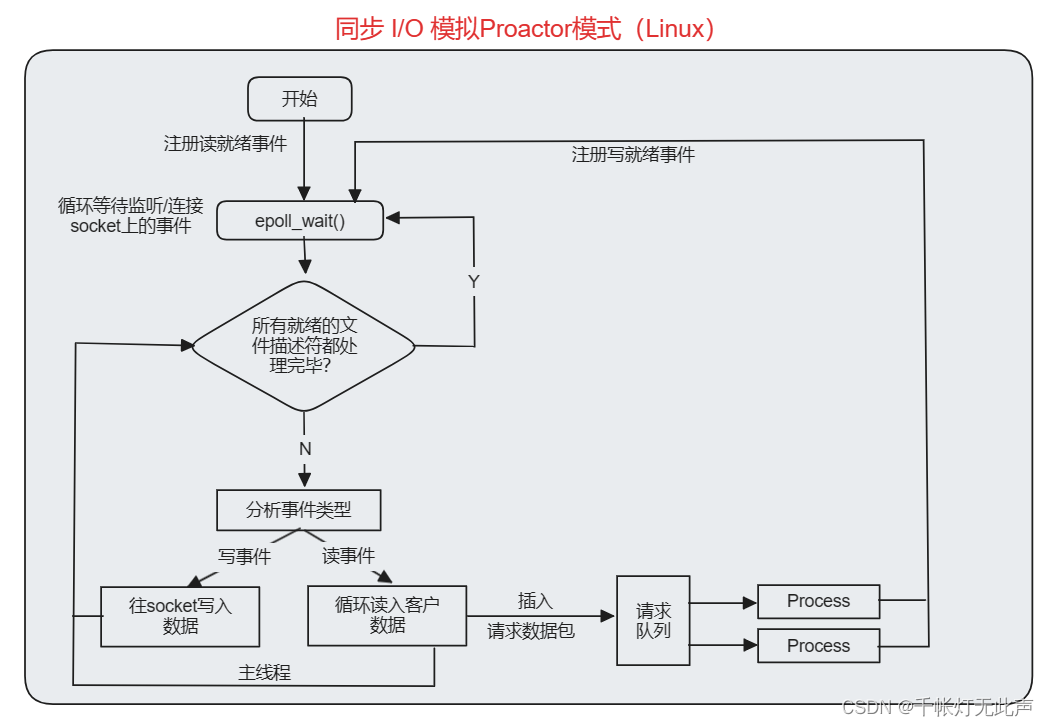
4)同步 I/O 模拟Proactor模式(Linux)
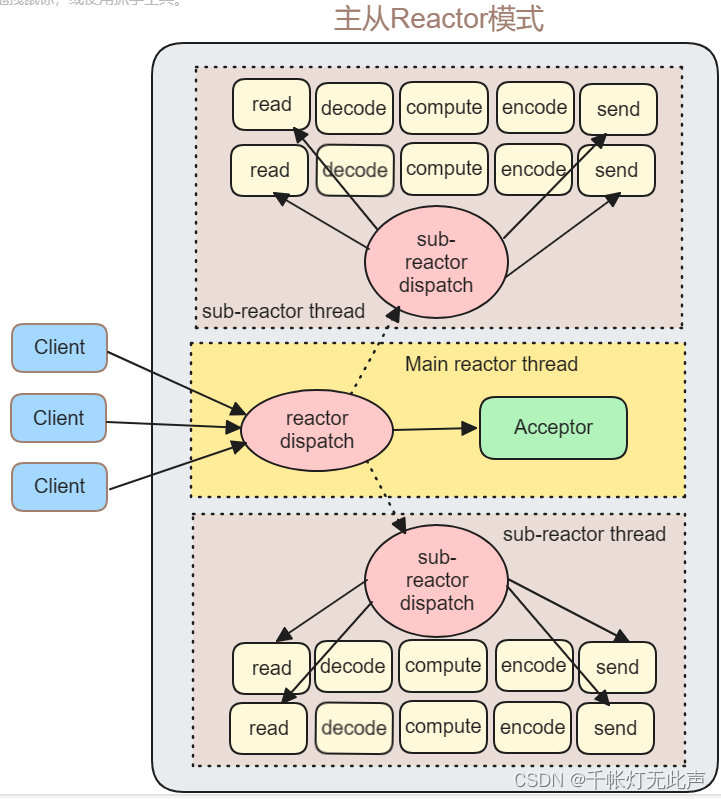
5)主从Reactor模式
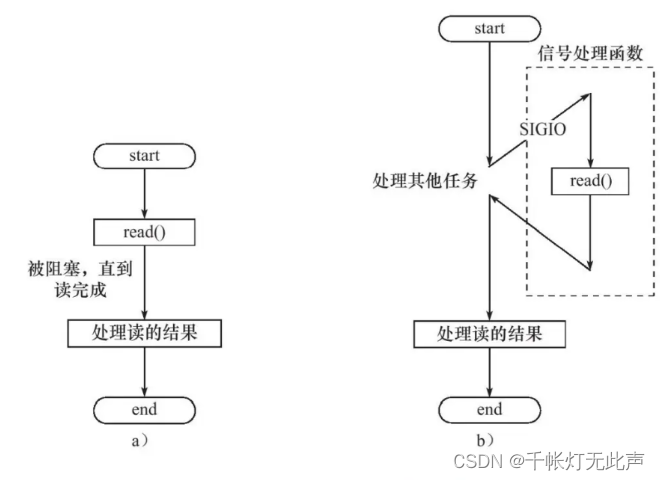
6)并发模式中的 同步读 && 异步读
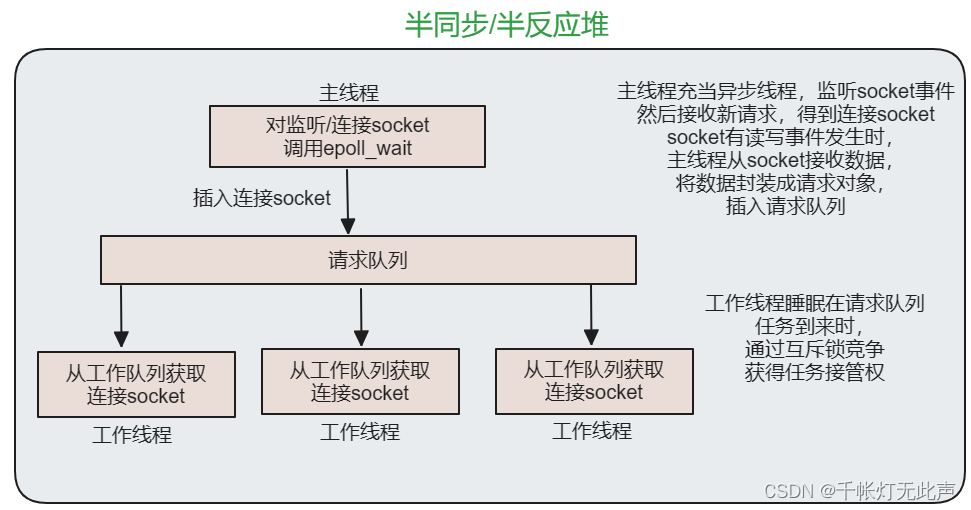
7)半同步/半反应堆
8)半同步/半异步

9)解析报文(主从状态机 && 状态转移过程)

10)从状态机逻辑
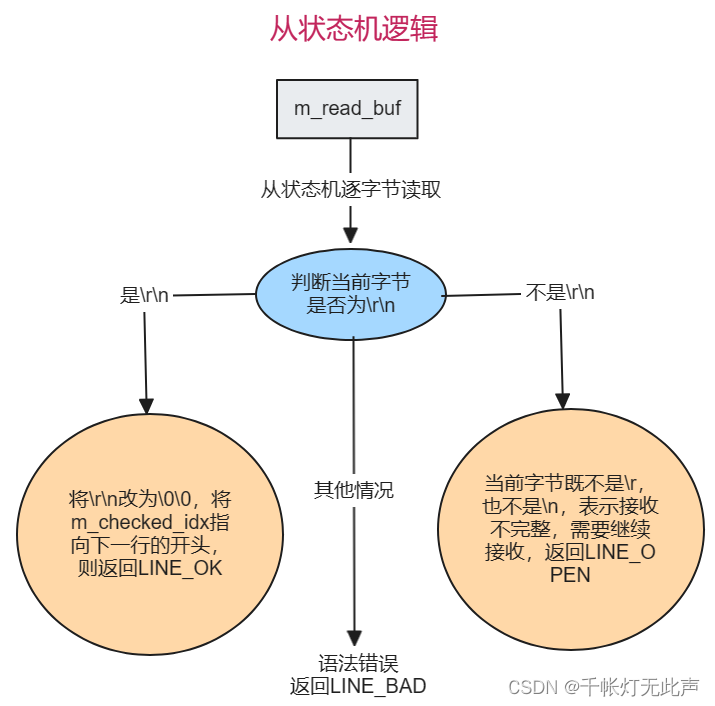
11)响应报文

12)信号处理机制

13)日志系统
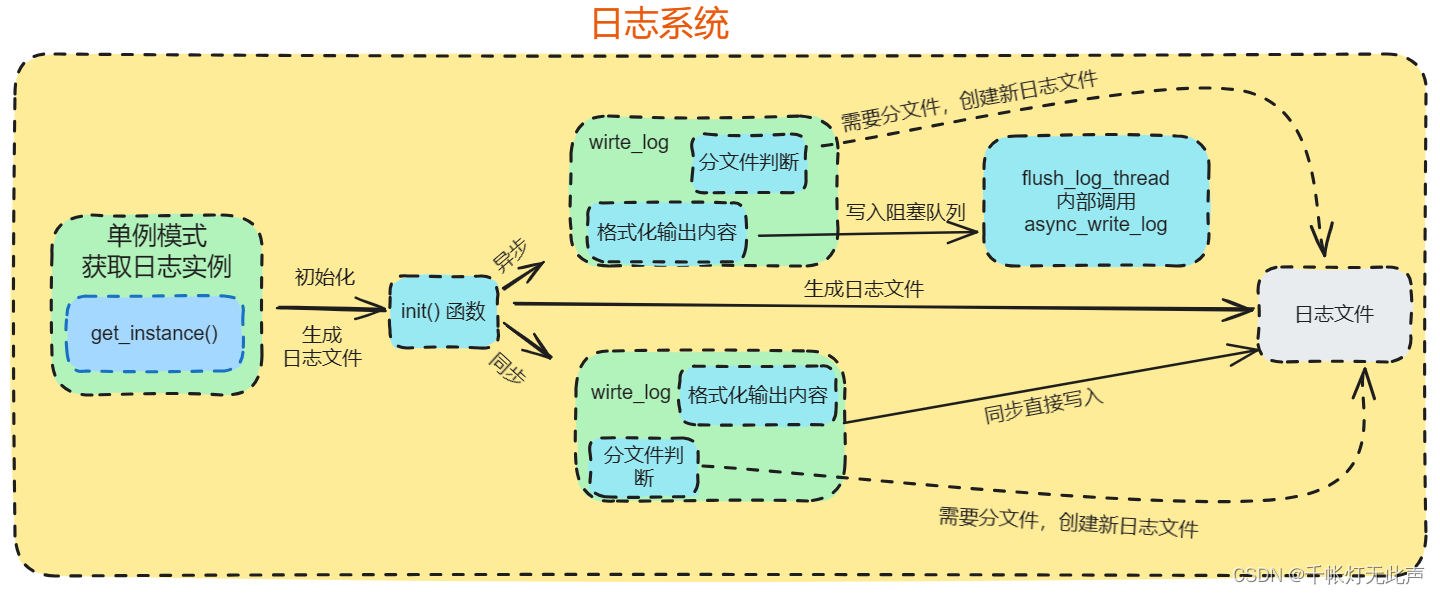
14)GET,POST 请求下页面跳转
15)架构图

16)源码目录解析
每个目录,我会结合(README 和 架构图)进行解析
总目录
总目录,我将它拆成上下两部分👇
- CGImysql: 处理 MySQL数据库 相关的 CGI 程序
- http: 处理 HTTP 请求和响应
- lock: 实现 锁机制* *,确保线程安全
- log: 实现 日志系统,记录服务器的运行状态
- root: 服务器的根目录,存放网站的 静态资源文件,用于构建用户界面
- test_pressure: 压力测试
- threadpool: 实现 线程池
- timer: 定时器
- LICENSE: 许可证文件,规定使用该项目的条款
- README.md: 项目的说明文档
- build.sh: 构建项目的脚本
- config.cpp 和 config.h: 存放 配置信息 的代码文件
- main.cpp: 主程序 入口文件
- makefile: 用于 编译链接项目 的 Makefile 文件
- webserver.cpp 和 webserver.h: 包含 Web服务器 的主要逻辑代码


http -- I/O处理单元
CGImysql -- 数据库连接
log -- 日志系统
lock -- 锁机制
timer -- 定时器处理非活动连接
CGImysql
校验 && 数据库连接池
数据库连接池
- 单例模式,保证唯一
- list 实现连接池
- 连接池为静态大小
- 互斥锁实现线程安全
校验
- HTTP请求采用POST方式
- 登录用户名和密码校验
- 用户注册及多线程安全
http
http 连接处理类
根据状态转移,通过 主从状态机 封装了 http连接类
其中,主状态机在内部调用从状态机,从状态机将处理状态和数据传给主状态机
- 客户端发出 http 连接请求
- 从状态机读取数据,更新自身状态和接受数据,传给主状态机
- 主状态机根据从状态机状态,更新自身状态,决定响应请求还是继续读取
lock
线程同步机制包装类
多线程同步,确保任一时刻只能有一个线程进入关键代码段
- 信号量
- 互斥锁
- 条件变量
log
同步/异步日志系统
同步 / 异步日志系统主要涉及两个模块,一个是日志模块,一个是阻塞队列模块
加入阻塞队列模块的目的:实现 异步写入日志
- 自定义阻塞队列
- 单例模式创建日志
- 同步日志
- 异步日志
- 实现按天,超行分类
root
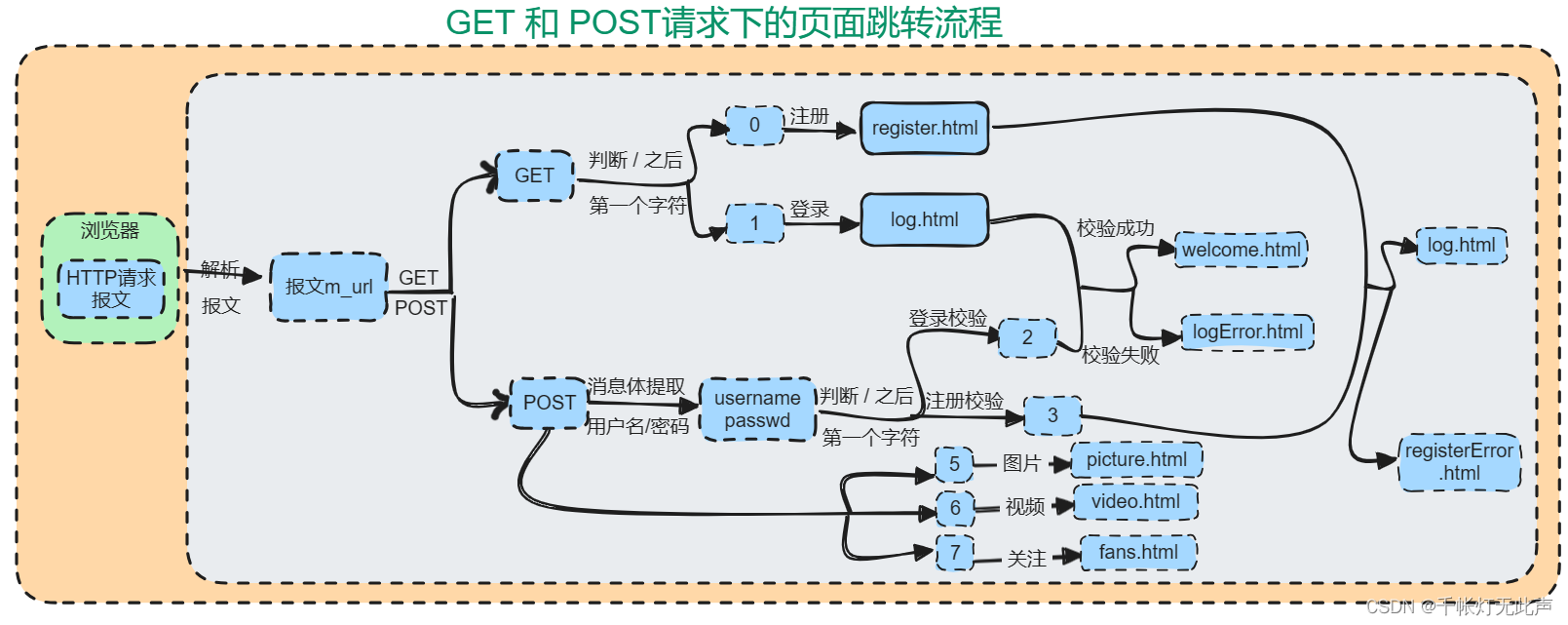
界面跳转
对 html 中的 action 行为设置标志位,将 method 设置为 POST
- 0 注册
- 1 登录
- 2 登陆检测
- 3 注册检测
- 5 请求图片
- 6 请求视频
- 7 关注我

test_pressure
服务器压力测试
(1)
(2)
(3)
webbench -- 网站压测工具
- 测试相同硬件不同服务的性能 && 不同硬件同一个服务的运行状况
- 展示服务器的两项内容:每秒响应请求数 && 每秒传输数据量

threadpool
半同步 / 半反应堆线程池
使用一个工作队列,完全解除了主线程和工作线程的耦合关系:
主线程往工作队列插入任务,工作线程通过竞争来取得任务并执行它
- 同步 IO 模拟 proactor 模式
- 半同步 / 半反应堆
- 线程池
timer
定时器处理非活动连接
由于非活跃连接占用连接资源(占着茅坑不拉屎),严重影响服务器性能
通过实现一个服务器定时器,处理这种非活跃连接,释放连接资源
利用 alarm 函数,周期性地出发 SIGALRM 信号
该信号处理函数利用管道通知主循环,执行链表上的定时任务
- 统一事件源
- 基于升序链表的定时器
- 处理非活动连接

接着,重看一遍前面写过的博客(梳理逻辑,熟悉源码和接口<常见手撕>,为下一步搞定面试题做准备)
🚩面试题(上)
1)项目介绍
为什么要做 WebServer?
专业课学过C++,Linux,计网,Mysql等知识,所以想通过本项目巩固网络编程和Linux,将分散的知识串联起来,顺便入门服务器。
介绍下你的项目
- 该项目通过C++,在Linux环境下开发
- 使用webbench进行压力测试,达到上万并发量
- 引入定时器,处理非活跃连接,及时释放连接资源,提升性能
- alarm 函数周期性触发 SIGALRM 信号,使用管道通知主循环执行定时任务,实现统一事件源和基于升序链表的定时器
- 采用线程池,半同步/半反应堆架构,解耦主线程和工作线程,提高并发处理能力 (因为主线程和工作线程之前有个工作队列,所以两者间没有耦合性)
- 引入同步/异步日志系统,实现异步写入日志功能
- 通过主从状态机封装 http 连接类,实现对 HTTP 请求的处理
- 实现数据库连接池,采用单例和互斥锁保证线程安全
- CGImysql处理数据库连接,log模块记录日志,lock模块实现锁机制,timer模块处理非活动连接
- 还支持处理大文件(包括视频文件和图片)
- 同时支持Reactor和Proactor模式,ET / LT均支持
补充解释👇
利用CGI与MySQL提升网站性能(cgimysql)-数据运维技术 (dbs724.com)
2)线程池
详情请看👇
webserver 之 线程同步 && 线程池(半同步半反应堆)-CSDN博客
线程池了解过吗
每提交一个任务,如果线程池没满,就创建一个线程;
如果满了,就会加入等待队列;
如果等待队列也满了,就会增加线程;
如果达到最大线程数量,就按照丢弃策略处理
设计一个线程池需要考虑哪些因素
- 线程池大小: 要根据 系统的【负载情况】和【任务性质】确定。线程池太小会导致任务排队等待;线程池太大,会浪费系统资源
- 任务队列: 线程池中的任务,需要一个任务队列来存储。任务队列可以是阻塞或非阻塞
- 线程工厂: 用于创建新线程,默认 或 自定义
- 拒绝策略: 当线程池中线程都处于忙碌状态时,新提交的任务会被放入任务队列等待执行。 此时需要设置一个拒绝策略,防止任务一直被放入队列而无法执行。 比如 抛出异常,丢弃任务 等
- 饱和策略: 线程数量达到最大值时,新提交的任务可能会被拒绝。 此时,饱和策略可以防止线程池过度扩展
- 线程池监控: 添加一些监控功能,如,获取当前线程池状态,获取正在执行的任务
手写线程池
a. 定义
线程处理函数 worker() 和 执行任务函数 run() ---- 私有
只提供 构造,析构,添加任务 的公共接口
template<typename T>
class threadpol {
public:
// thread_num 线程数量
// max_requests 请求数量(请求队列中 最多允许 && 等待处理)
// connpool 数据库连接池 指针
threadpool(connection_pool *connpool,
int thread_number = 8,
int max_request = 10000);
~threadpool();
// 请求队列 插入任务请求
bool append(T* request);
private:
// 工作线程运行的函数
// 不断从工作队列取出任务 并执行
static void *worker(void *arg); // 声明为 static 的原因,下面构造函数解释
void run();
private:
int thread_number; // 线程数
int m_max_requests; // 请求队列最大请求书
pthread_t *m_threads; // 描述线程池的数组,大小 m_thread_num
std::list<T *> m_workqueue; // 请求队列
locker m_queuelocker; // 保护请求队列的互斥锁
sem m_queuestat; // 是否有任务需要处理
bool m_stop; // 结束线程
connection_pool *m_connPool; // 数据库连接池
};
b. 构造
涉及线程池的 创建和回收
pthread_create() 将类的对象作为参数,传递给 静态函数 worker()
在静态函数引用这个独享,并调用其动态方法 run()
具体地,类对象传递时用 this 指针,传递给静态函数后,转换为线程池类,并调用私有 run()
template<typename T>
threadpool<T>::threadpool( connection_pool *connPool,
int thrad_number,
int max_requests) // 构造函数参数列表
:
m_thread_number(thread_number), // 线程数
m_max_requests(max_requests), // 最大请求数
m_stop(false), m_threads(NULL), // 结束线程 && 线程池数组
m_connPool(connPool) // 数据库连接池指针
{
if (thread_number <= 0 || max_requests <= 0)
throw std::exception();
// 线程 id 初始化
m_threads = new pthread_t[m_thread_number]; // 数组
if (!m_threads)
throw std::exception();
for (int i = 0; i < thread_number; ++i) {
// thread_create(线程标识符, 线程属性, worker()指针, worker()的参数)
// 因为 worker指针,指向线程处理函数的地址,而且 worker() 作为类成员函数
// 且指向threadpool对象的 this 指针,作为默认参数被传入 worker() 中
// 此时会和 worker(void* arg) 的类型 void* 不匹配
// 所以上面才将 worker() 声明为 static
// 循环创建线程
if (thread_create(m_threads + i, NULL, worker, this) != 0) {
delete [] m_threads;
throw std::exception();
}
// 线程分离后,不用单独回收工作线程,便于资源释放
if (thread_detach(m_threads[i])) {
delete [] m_threads;
throw std::exception();
}
}
}
c. 析构
template<typename T>
threadpool<T>::~threadpool()
{
delete[] m_threads;
}
d. append() 添加任务
*list 容器 *创建 请求队列
向队列添加任务时,通过 互斥锁 保证线程安全
添加完毕后,通过 信号量 提醒 “有任务要处理”
最后注意线程同步↓↓↓
使用了互斥锁 m_queuelocker.lock() 和 m_queuelocker.unlock() 来保护对任务队列 m_workqueue 的访问,防止多个线程同时访问引起数据竞争。
使用信号量 m_queuestat.post() 来通知空闲线程有任务需要处理,避免了一个线程获取多个任务的情况,也确保每个任务都能得到及时处理
template<typename T>
bool threadpool<T>::append(T* request)
{
m_queuelocker.lock(); // 关键代码段加锁
// 根据硬件,预先设置请求队列最大值
if (m_workqueue.size() > m_max_requests) {
m_queuelocker.unlock();
return false;
}
// 添加任务
m_workqueue.push_back(request);
m_queuelocker.unlock(); // 解锁
// 信号量 提醒有任务处理
m_queuestat.post();
return true;
}
e. worker() 线程处理
内部访问私有函数 run(),完成线程处理要求
// 前面构造函数中 pthread_create 调用了 worker
template<typename T>
void* threadpool<T>::worker(void* arg)
{
// 调用时 *arg 是 this
// 所以该操作其实是获取 threadpool 对象地址
// 参数强转线程池类,调用成员方法
threadpool* pool = (threadpool*)arg;
// 线程池每一个线程创建都会调用 run(),睡眠在队列中
pool->run();
return pool;
}
f. run() 执行任务
工作线程 从 请求队列 取出某个任务进行处理,注意线程同步
// 线程池所有线程睡眠状态,等待请求队列新增任务
template<typename T>
void threadpool<T>::run()
{
while (!m_stop) {
// 信号量等待
// m_queuestat 是否有任务需要处理
m_queuestat.wait();
// 被唤醒后先加互斥锁
// m_workqueue 请求队列
m_queuelocker.lock();
if (m_workqueue.empty()) {
m_queuelocker.unlock();
continue;
}
// 请求队列取 第一个任务request
// 任务从请求队列 删除
T* request = m_workqueue.front();
m_workqueue.pop_front();
m_queuelocker.unlock();
if (!request) continue;
// 连接池取出一个 数据库连接
request->mysql = m_connPool->GetConnection();
// process(模板类中的方法,这里是 http 类) 进行处理
request->process();
// 数据库连接 放回连接池
m_connPool->ReleaseConnection(request->mysql);
}
}
线程同步机制有哪些
1)RAII
- 之所以把 RAII 加到线程同步机制里,因为它可以用来管理 信号量,互斥量,条件变量等资源
- RAII -- Resource Acquisition is Initialization,资源获取即初始化
- 资源与对象的生命周期绑定,构造函数分配资源,析构函数释放资源
- 比如智能指针
2)信号量(限制访问某个资源的线程数量)
a. sem_init() 初始化 信号量
b. sem_destory() 销毁 信号量
c. sem_wait() 原子操作方式,信号量 -1;信号量 == 0,sem_wait() 阻塞
d. sem_post() 原子操作方式,信号量 +1;信号量 > 0,唤醒调用 sem_post()的线程
信号量就像是一个可以控制进程访问共享资源的门禁系统。这个门禁系统支持两种操作👇
- 等待 (P) 操作:当一个进程试图访问共享资源时(比如想要通过门禁进入),它首先检查信号量的值。如果信号量大于 0(门禁开着),那么进程可以顺利通过,同时信号量减一(门禁关闭)。但是,如果信号量等于 0(门禁关着,有其他进程在使用资源),进程必须等待(挂起执行),不能继续执行直到有其他进程释放资源(信号量增加)
- 信号 (V) 操作:当一个进程使用完共享资源时(比如离开了房间),它会执行信号操作。如果有其他进程因为等待资源而被挂起,那么这个信号会唤醒其中一个等待的进程,让其继续执行。否则,如果没有进程在等待资源,信号量会自增,表示资源又变得可用
3)条件变量(线程间通信;实现线程等待唤醒机制)
a. pthread_cond_init() 初始化
b. pthread_cond_destory() 销毁
c. pthread_cond_broadcast() 广播方式,唤醒所有等待目标条件变量的 线程
d. pthread_cond_wait() 等待目标条件变量
调用时,传入 mutex 参数 (加锁的互斥锁)
执行时,1) 调用线程 放入条件变量的 请求队列
2) 互斥锁 mutex 解锁
3) 函数返回 0 时,互斥锁再次被锁上
4) 也就是说,函数内部,会有一次 解锁 和 加锁 操作
当一个线程调用 pthread_cond_wait() 等待目标条件变量时,它会将自己放入条件变量的请求队列中,并传入一个已经加锁的互斥锁(mutex参数)。接着,互斥锁会被解锁,让其他线程有机会操作共享资源。当函数返回 0 时,表示条件满足,此时会再次对互斥锁进行加锁操作,以确保线程安全地访问共享资源。因此,在 pthread_cond_wait() 函数内部会有一次解锁和加锁的操作,确保线程的正确执行顺序和共享资源的安全访问
4)互斥量(一次只允许一个线程访问资源)
即 互斥锁:保护关键代码段,确保 独占式 访问
a. 进入关键代码段 -- 获得互斥锁并加锁
b. 离开关键代码段 -- 唤醒等待该互斥锁的线程
a. pthread_mutex_init() 初始化互斥锁
b. pthread_mutex_destory() 销毁互斥锁
c. pthread_mutex_lock() 原子操作方式,给互斥锁,加锁
d. pthread_mutex_unlock() 原子操作方式,给互斥锁,解锁
线程池中的工作线程是一直等待吗?
- 工作线程睡眠在工作队列上,当主线程将新任务添加到工作队列时,就会唤醒某个一直在等待的工作线程
- 该工作线程从队列中取出任务并执行,其他工作线程则继续睡眠在工作队列上
线程池中工作线程处理完一个任务后的状态是?
- 请求队列为空,则该线程进入线程池继续等待
- 队列不为空,就和其他线程一起竞争任务
同时2000个客户端访问,线程数不多,如何及时响应?
1,采用 线程池
- 主线程与工作线程分离,使用线程池管理工作线程,避免主线程阻塞
- 考虑扩大线程池容量
- 线程池复用线程资源,避免频繁创建和销毁小城
2,采用 ET 模式和非阻塞 socket
- ET模式和非阻塞socket,确保及时处理
- 通过 epoll 的EPOLLONESHOT特性,降低可读,可写和异常事件被触发次数
3,采用 半同步/半异步并发模式
- 通过 Reactor 或 Proactor 模式,满足并发量要求
4,采用 集群或者分布式
- 通过分布式,将大任务拆分成小任务,各节点协同完成
- 通过集群,增加服务器(节点)数量
什么是分布式,分布式和集群的区别又是什么?这一篇让你彻底明白!_什么叫分布式-CSDN博客
同时有大量客户并发建立连接,服务器如何处理
- 多线程同步阻塞 每个客户端连接到来时,都会创建一个新的线程来处理,即可实现并发处理
- I/O多路复用 socket 的建立 一个线程中同时监听多个端口。新的连接请求到来时,该线程将连接请求分配给其他空闲线程处理
一个请求占用线程很长事件,影响到了接下来的请求处理,如何解决
- 采取 异步非阻塞 模式,接收到新的请求后,不立即处理,而是安排一个以后的时间再发起请求,并且继续执行当前请求
- 采取 超时设置,对每个请求设置合理的超时时间,如果处理时间超过给定阈值,则取消该请求 或 返回超时错误信息,及时释放线程资源
- 采取 断点续传,对任务进行分段处理,某个处理阶段完成后暂停任务,等待下一次触发继续处理
- 任务分片,长时间任务拆分成多个小任务,每个小任务完成后释放线程资源
补充理解
深入理解同步阻塞、同步非阻塞、异步阻塞、异步非阻塞_同步阻塞 同步非阻塞 异步阻塞 异步非阻塞-CSDN博客
3)并发模型
服务器使用的并发模型是?
采用 半同步半反应堆 作为并发模型
以 Proactor 事件处理模式为例
- 主线程充当异步线程,负责监听所有 socket 上的时间和处理 I/O 操作
- 新请求到达时,主线程接收连接 socket,并注册读写时间到 epoll 内核事件表中
- 如果连接 socket 上有读写事件发生,主线程从 socket 上接收数据,并将数据封装成请求对象插入请求队列
- 所有工作线程睡眠在请求队列上,当有任务到来时,通过竞争(互斥锁)获得任务接管权
- 工作线程仅负责业务逻辑,比如处理客户请求;主线程与内核配合实现底层的异步 I/O 操作
总的来说
采用半同步半反应堆并发模型的 Proactor 事件处理模式,主线程负责底层 I/O 操作和事件监听,工作线程专注于业务逻辑处理,通过异步 I/O 实现高效并发处理
Reactor,Proactor,主从Reactor 模型的区别
先通过Java了解下 主从Reactor👇
Reactor(主从)原理详解与实现_主从reactor-CSDN博客
回答:
1,Reactor(事件来了,我通知你,你来处理)(我 -- 操作系统内核;事件 -- 新连接)
- 采用同步 I/O,负责监听文件描述符上是否有事件发生
- 主线程(I/O 处理单元)负责事件感知和通知工作线程(同步IO向应用程序通知的是IO就绪事件),将读写事件放入请求队列,并由工作线程完成实际的数据读写,接收新连接 和 处理客户请求
- 应用进程需要主动调用 read / write 方法,进行数据的读取和写入,处理过程是同步的
- 比如,快递员在楼下通知你快递送达,需要你自己下楼拿快递
2,Proactor(事件来了,我处理完,再通知你)
- 采用异步 I/O,只负责发起 I/O 操作,真正的 I/O 实现由操作系统处理
- 主线程和操作系统负责处理读写数据,接收新连接等 IO 操作,工作线程仅负责业务逻辑,如处理客户请求
- 应用进程无需主动发起读写操作,操作系统完成读写后,会通知应用进程直接处理数据(异步IO向应用程序通知的是IO完成事件)
- 比如,快递员将快递送达你家门口后,再通知你
3,主从Reactor模式
- 主反应堆线程,负责分发连接建立事件,已连接套接字上的 IO 事件,交给子反应堆线程处理
- 子反应堆线程数量,可以根据CPU核数来设置,负责具体的 I/O 事件处理
- 主反应堆线程,只负责调用 accept 获取已连接套接字,并将其分配给响应的子反应堆线程
- 结合了 Reactor 和 Proactor 的特点
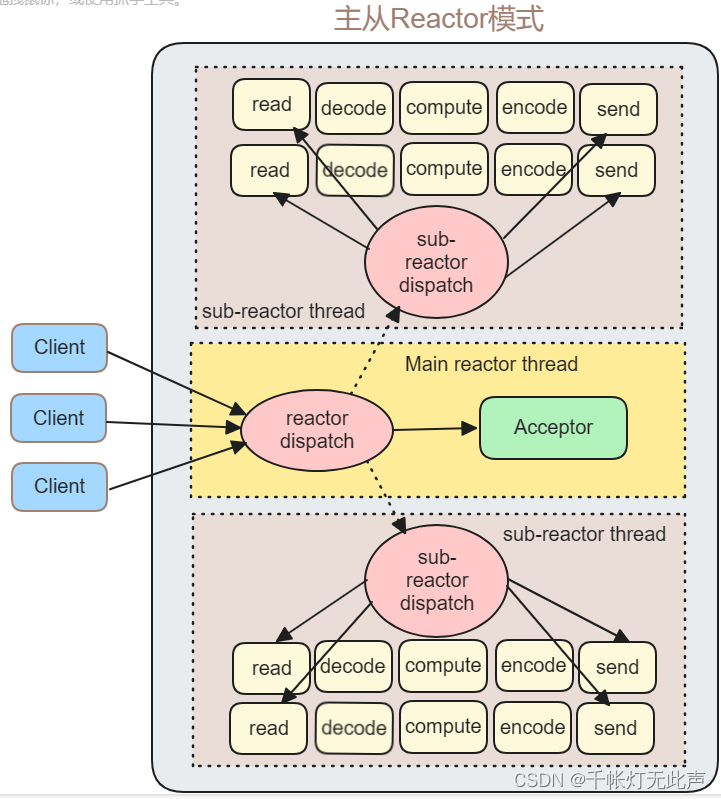
概括地说,Reactor模式和Proactor模式都是基于事件分发的网络编程模式,区别在于 I/O 事件处理的方式
Reactor基于待完成的 I/O 事件,而Proactor基于已完成的 I/O 事件,主从Reactor结合了两者的优点
补充
- Reactor 核心是将事件处理逻辑 和 事件分发机制解耦,以便用非阻塞方式处理多个 I/O 事件 ( 主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,读写数据、接受新连接及处理客户请求 均在工作线程中完成 )
- Proactor 核心是将I/O操作 和 业务逻辑解耦 (主线程和内核负责处理读写数据、接受新连接等I/O操作,工作 线程仅负责业务逻辑,如处理客户请求)
- Reactor 是非阻塞 *同步 *网络模型,如果把I/O操作改为 *异步 *就能够进一步提升性能,这就是异步网络模型 Proactor (这里 “同步” 指用户进程在执行 read 和 send 这类 I/O 操作 的时候是同步的)
多路复用了解吗,讲一下 I/O 多路复用
- IO多路复用是处理多个I/O流的技术
- 它允许单个进程同时监视多个文件描述符,当一个或多个文件描述符准备好读 / 写时,就可以立即响应
- 可以提高系统的并发性和响应速度,减少资源浪费
- select 最早的 IO 多路复用机制,只能同时监视 1024 个 fd,而且每次只能监视部分 fd 的状态变化
- poll 类似 select,但是最大 fd 监视数量达到了 65536
- epoll Linux 特有,可以支持更多的 fd,还支持 ET(边缘触发)
select, poll, epoll 的区别
- select, poll 没有本质区别,都是用【线性结构】存储进程关注的 socket 集合
- 使用时,首先将关注的 socket 集合通过 select / poll 系统调用,从用户态拷贝到内核态,然后由内核检测事件;当有网络事件产生时,内核需要遍历进程关注的 socket 集合,找到对应的 socket,并将其设置为 可读/可写 socket,然后再处理
- 显然,select, poll 的缺陷在于,客户端越多,socket 集合越大,socket集合的遍历和拷贝会带来很大开销,因此很难应对C10K(Concurrent 10,000 Connections,上万并发量)
- epoll 是解决 C10K 问题的利器,两方面入手
- epoll 在内核中用【红黑树】关注进程所有待检测的 socket,红黑树是高效的数据结构,增删改的时间复杂度 O(logn);借助这棵红黑树,不需要像 select / poll 一样,每次操作都要传入整个 socket 集合,减少了内核和用户空间里,大量的数据拷贝和内存分配
- epoll 使用事件驱动机制,内核里维护了一个【链表】来记录就绪事件,只将有事件发生的 socket 集合传递给应用程序,不需要像 select/poll 一样轮询整个集合(有 / 无事件的 socket 都包含),提高了检测效率
为什么用 epoll,还有其他IO复用方式吗,区别是
常用的是 select,poll,epoll,当然,这里会补充下对 io_uring 的说明
选择 epoll 从两点出发:
- 性能: 1)在文件描述符数量较多且活跃度不一的情况下,epoll 能提升性能 2)因为 epoll 将文件描述符维护在内核态,每次添加文件描述符,只需要执行一个系统调用 3)而且能够直接返回触发事件的文件描述符,避免了遍历整个文件描述符集合的性能损耗
- 数据结构: 1)select 使用线性表创建文件描述符集合,而且上限 1024 2)poll 使用链表 3)epoll 底层采用红黑树来构建,并维护一个 ready list,能够在 epoll_wait() 调用时,只观察已就绪事件 4)epoll 支持 LT 和 ET 两种工作模式,而 select 和 poll 只能工作在相对低效的 LT 下
区别是:
- select, poll 都需要将文件描述符集合从用户态拷贝到内核态,而epoll只用拷贝需要修改的文件描述符,避免了集体拷贝的开销
- select,poll 最大开销来自内核判断是否有文件描述符就绪,需要遍历整个文件描述符集合,而 epoll 直接返回触发事件的文件描述符
- select, poll, epoll 都是同步 I/O,而 io_uring 是异步 I/O,它通过用户和内核之间的共享内存映射来避免数据拷贝,减少CPU开销,还支持事件批处理,降低系统调用次数和上下文切换的开销
下面介绍下 io_uring:
- 零拷贝:io_uring 通过共享内存映射来避免数据拷贝,将用户空间和内核空间之间的数据传输最小化
- 批处理:它还支持事件批处理,即一次性可以提交多个 I/O 请求给内核,减少系统调用和上下文切换的开销,提高吞吐量
- Ring Buffer 机制:io_uring 使用环形缓冲区(ring buffer),作为用户和内核之间的通信机制。用户将 IO 请求放入Ring Buffer,内核会异步处理这些请求,并将结果返回到 Ring Buffer,用户再从 Ring Buffer 读取
- 高效的事件通知机制:使用 IO Completion Event(IO完成事件)机制,通过事件通知的方式告知用户空间 IO 操作的完成情况,避免用户频繁的轮询内核,提高响应速度
select, poll, epoll 各自的优缺点
select 缺点
- select() 检测数量有限,最大值 1024 bit,每个比特位对应一个监听的文件描述符
- fd_set 被内核修改后,不能重用,每次都需要被重置
- 每次调用 select,都需要把 fd 集合从用户态拷贝到内核态,fd 较多时开销很大
- 每次调用 select,都需要在内核遍历传入的所有 fd,fd较多时开销也很大,时间 O(n)
poll 缺点
- 需要从用户态拷贝到内核态 + 需要在内核态遍历 fd,开销还是很大
- 而且不能像 select 一样跨平台
epoll 优点
- 底层是 红黑树,增删改效率高
- 就绪描述符的链表:连接就绪时,内核将就绪的连接放到 ready list 链表里,应用进程只需要判断链表就能找出就绪进程,不用遍历整棵树
介绍下 epoll 的 LT, ET
- LT 是默认方式,相当于效率很高的 poll 模型;而 ET 是高效方式
- LT 1)epoll_wait 检测到文件描述符有事件发生,就将其通知到应用程序,应用程序可以不立即处理该事件 2)当下一次调用 epoll_wait 时,epoll_wait 还会再次向应用程序报告,直到被处理
- ET 而 ET 模式下,epoll_wait 检测到文件描述符...通知到应用程序,应用程序会立即处理 很大程度上降低了 epoll 的触发次数
版权归原作者 千帐灯无此声 所有, 如有侵权,请联系我们删除。