
小伙伴们都使用过各种社交平台,如:QQ、微博、朋友网等等,应该都知道有一个叫 "可能认识" 或者 "好友推荐" 的功能。
而MapReduce的算法主要是根据你们之间的共同好友数进行推荐,当然也可根据其他,如爱好、特长等等。共同好友的数量越多,表明你们可能认识,系统便会自动推荐。
今天我将向大家介绍如何使用MapReduce计算共同好友。
一、项目说明
- 互为推荐关系
- 非好友的两个人之间存在相同好友则互为推荐关系
- 朋友圈两个非好友的人,存在共同好友人数越多,越值得推荐
- 存在一个共同好友,值为1;存在多个值累加
二、程序需求
2.1 需求
- 程序要求:给每个人推荐可能认识的人,互为推荐的关系值越高越值得推荐。每个用户推荐值越高的人越排在前面。
2.2 数据
- 数据使用空格进行分割
- 每一行是一个用户及其所推荐的好友
- 每一行第一列是用户名字,后面是其多对应的好友
xiaominglaowangrenhualinzhilinglaowangxiaomingfengjierenhuaxiaomingligangfengjielinzhilingxiaomingligangfengjieguomeimeiligangrenhuafengjielinzhilingguomeimeifengjielinzhilingfengjierenhualaowanglinzhilingguomeimei三、代码实现
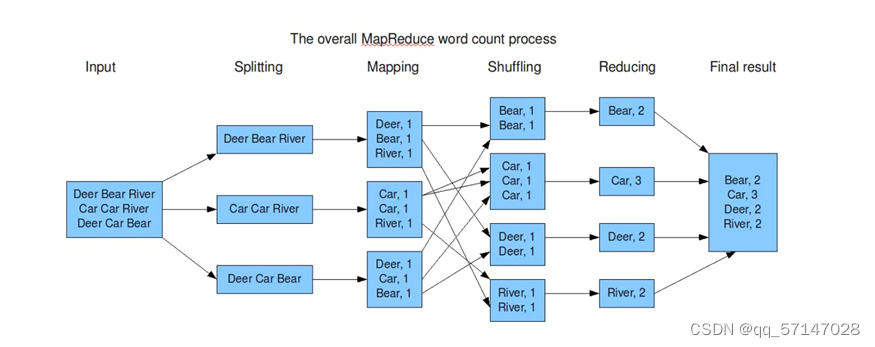
3.1 MapReduce原理分析
3.2 代码实现
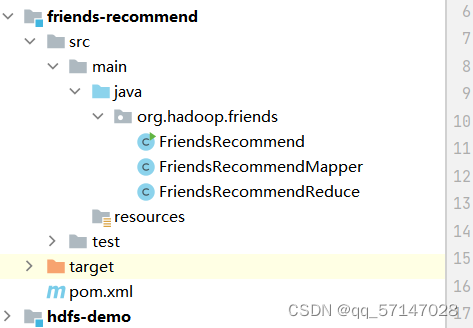
建构层次如下:
引入配置,打包运行在集群环境里:

map阶段:
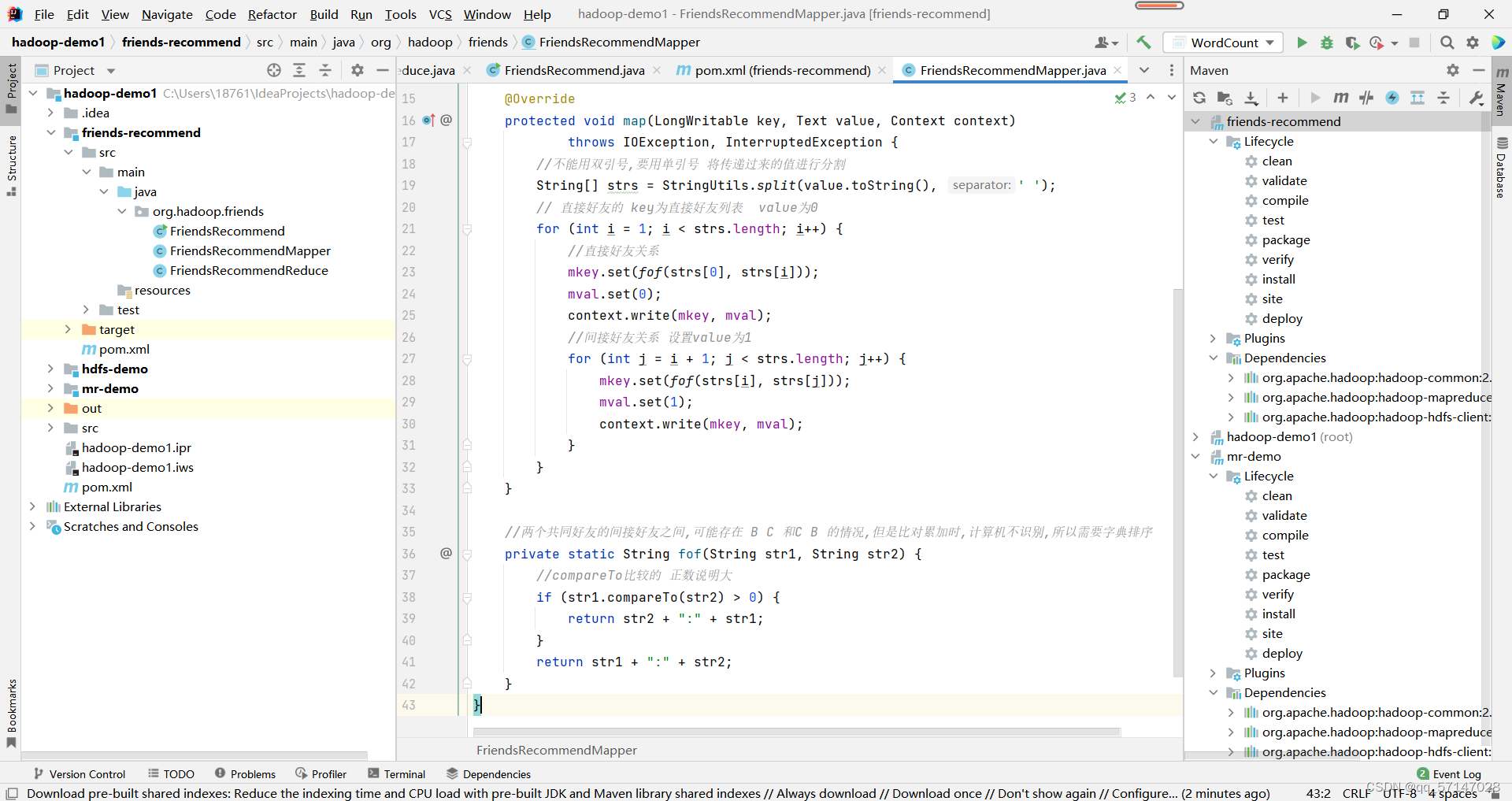
- 输出应使用单引号
- 设置直接好友关系的value值为0;间接好友关系的value值为1
- 为使计算机正确识别比对累加的复杂情况,需要进行字典排序
Reduce阶段:

- 当发现value值为0时,是直接好友,舍弃
Recommend.java:
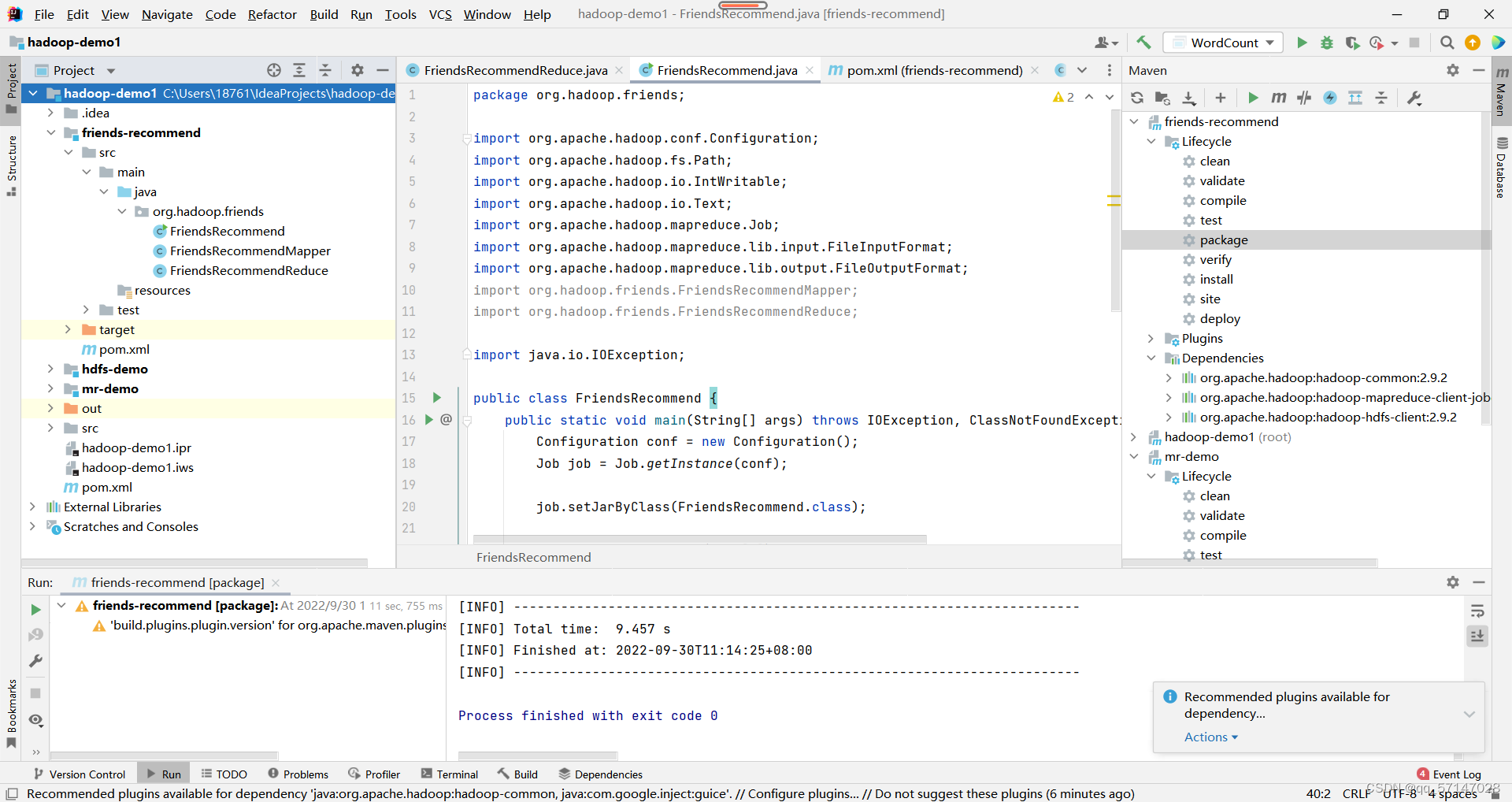
- 请注意导包完整且正确
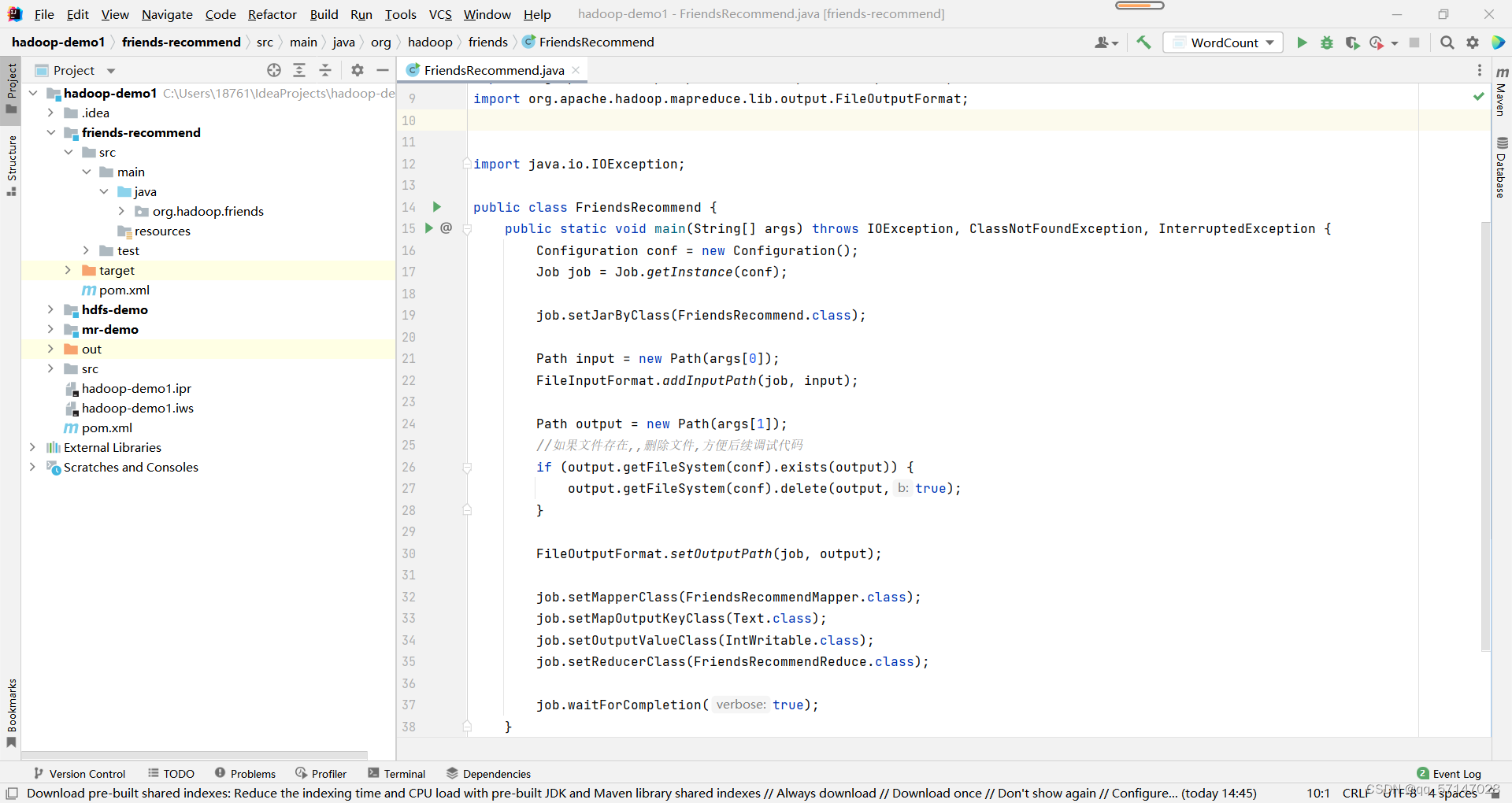
- 检测重复文件,及时删除以方便后续调试
3.3 启动HDFS集群
启动集群:
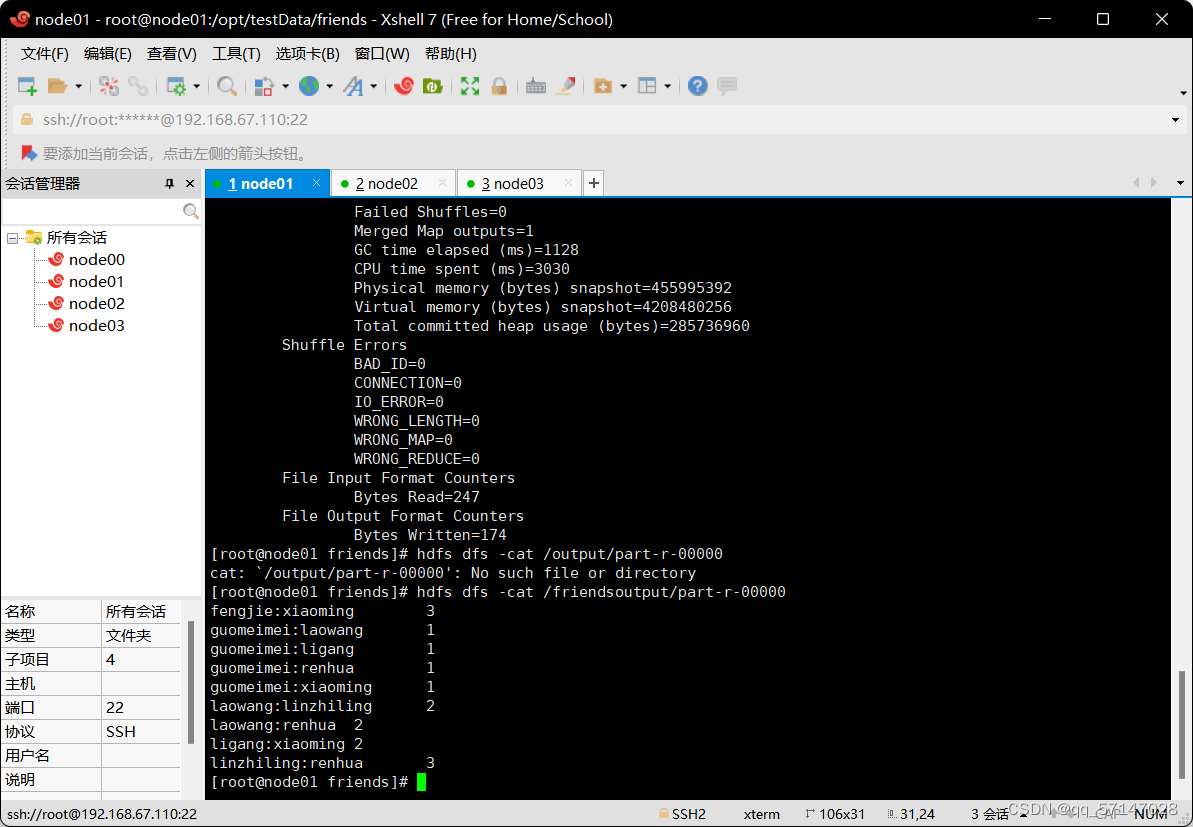
导入friends文本文件:

运行结果如下:
总结
今天给大家分享的好友推荐算法就是这些,今天的只是一个小小的案例,现实场景中的运算肯定要比这个复杂的多,
但是思路和方向基本一致,如果有更好的建议或算法,欢迎与我一起讨论喔~
本文转载自: https://blog.csdn.net/qq_57147028/article/details/127123524
版权归原作者 qq_57147028 所有, 如有侵权,请联系我们删除。
版权归原作者 qq_57147028 所有, 如有侵权,请联系我们删除。