
SpringBoot集成Kafka低版本和高版本
说明
这里之所以集成低版本和新版本,是因为在企业开发中,有的SpringBoot项目版本很低,像我这个项目版本就很低,是1.4.2.RELEASE版本,而新版本即高版本就是用来自己学习的。这里主要告诉大家,版本一定要根据自己的项目版本选择对应的kafka版本。
地址
官网地址:https://spring.io/projects/spring-kafka#overview
maven仓库spring-kafka地址:https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka
官网对应版本图: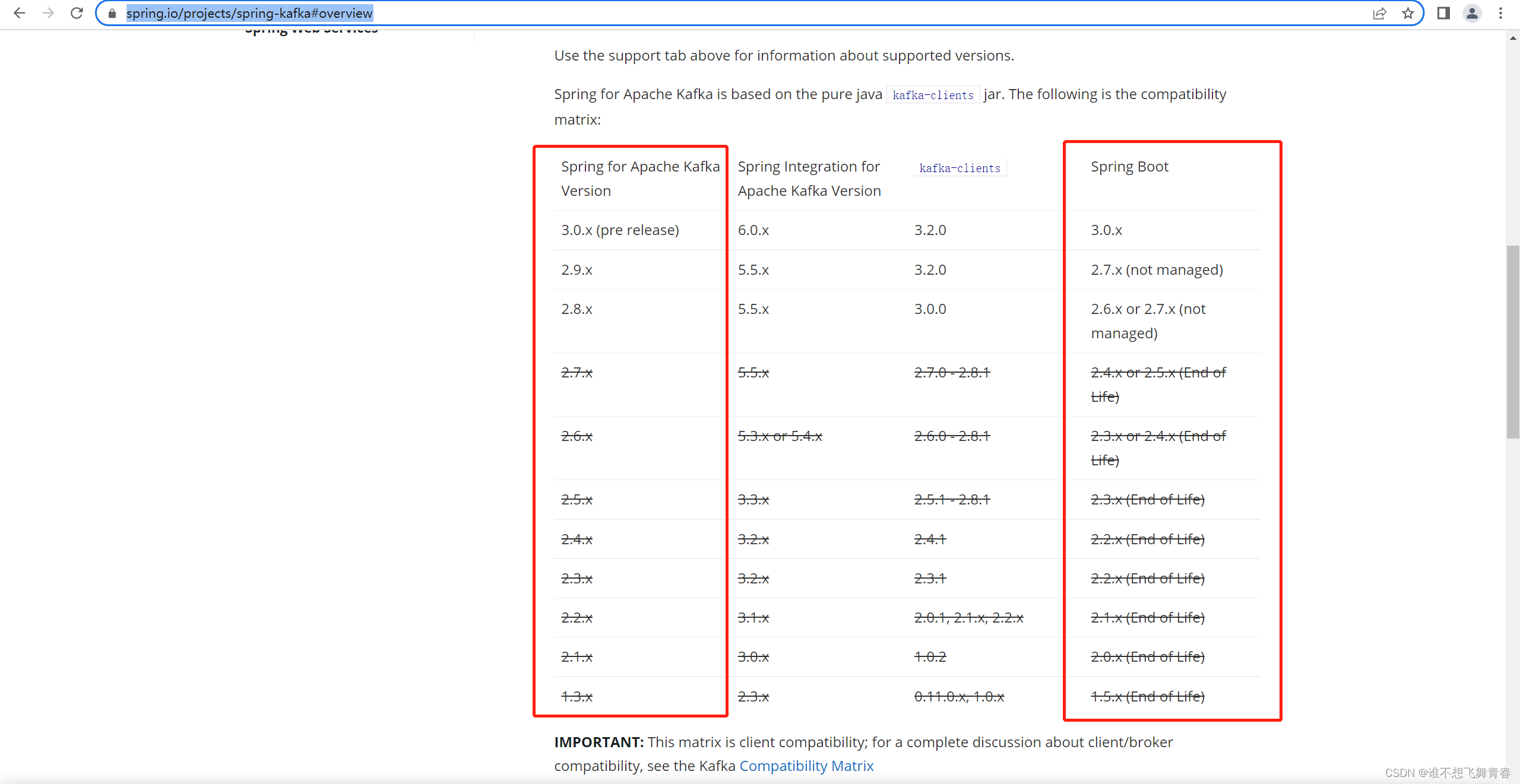
低版本SpringBoot集成Kafka代码
linux本地服务器zookeeper和kafka使用版本: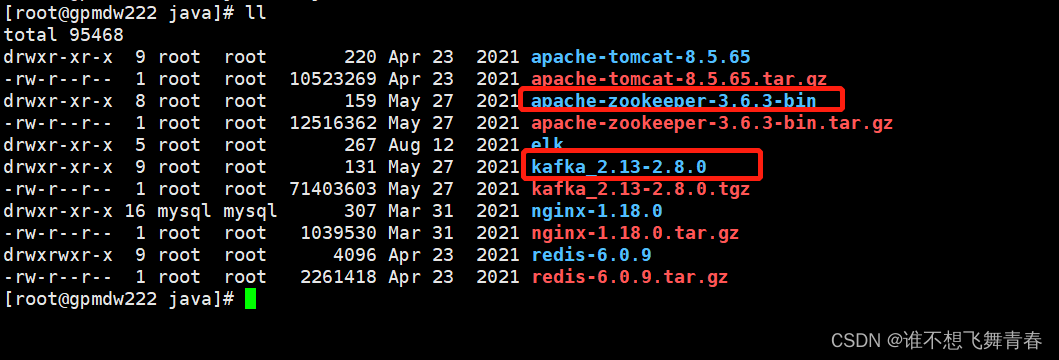
springboot版本和使用的spring版本: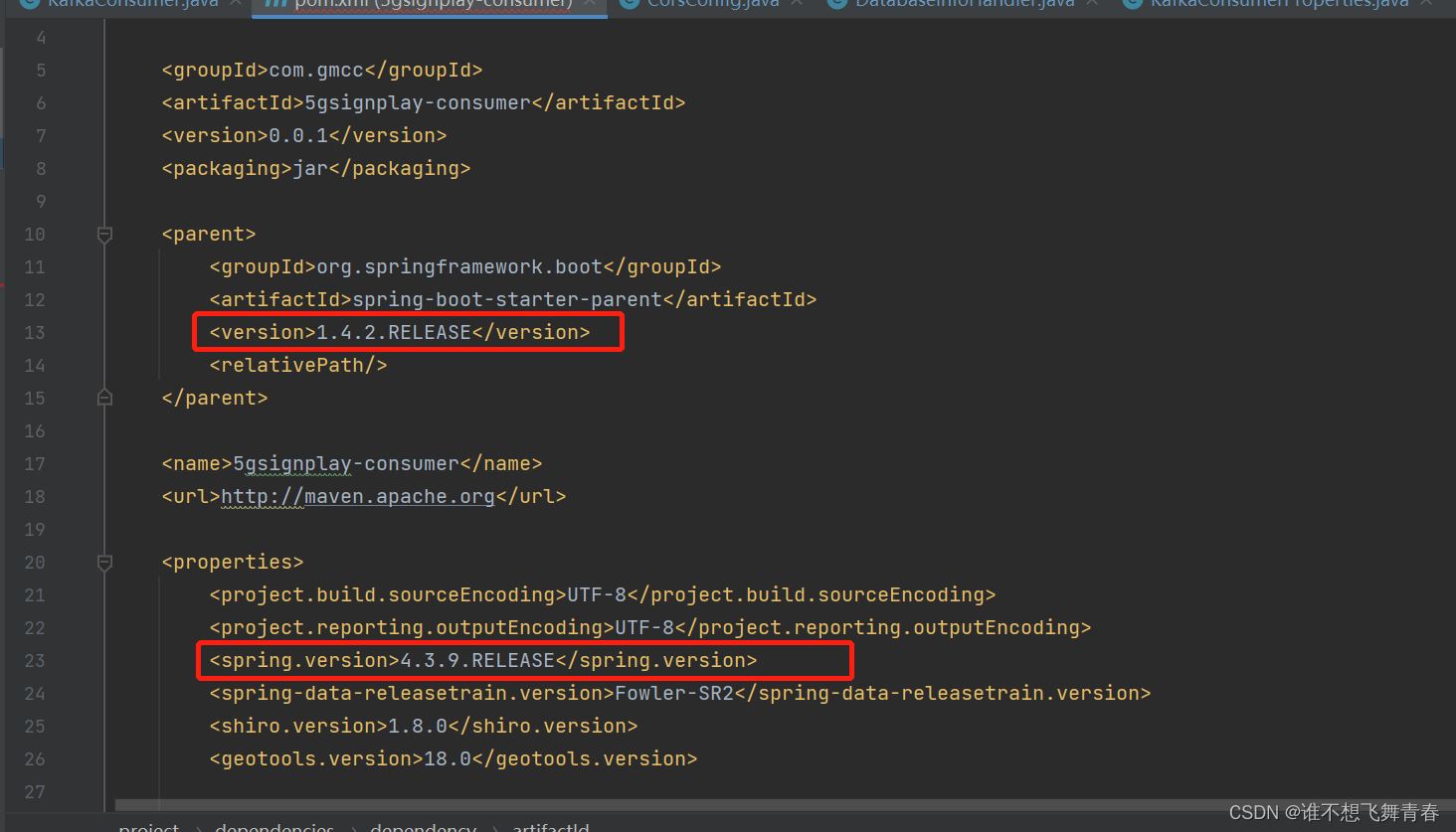
使用的spring-kafka版本: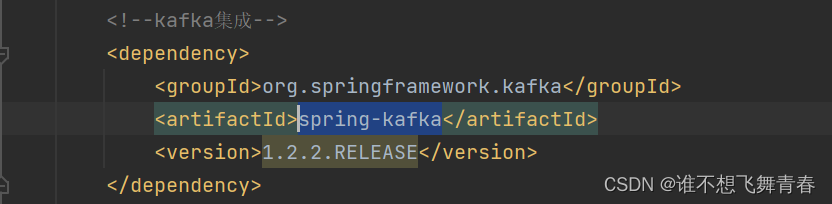
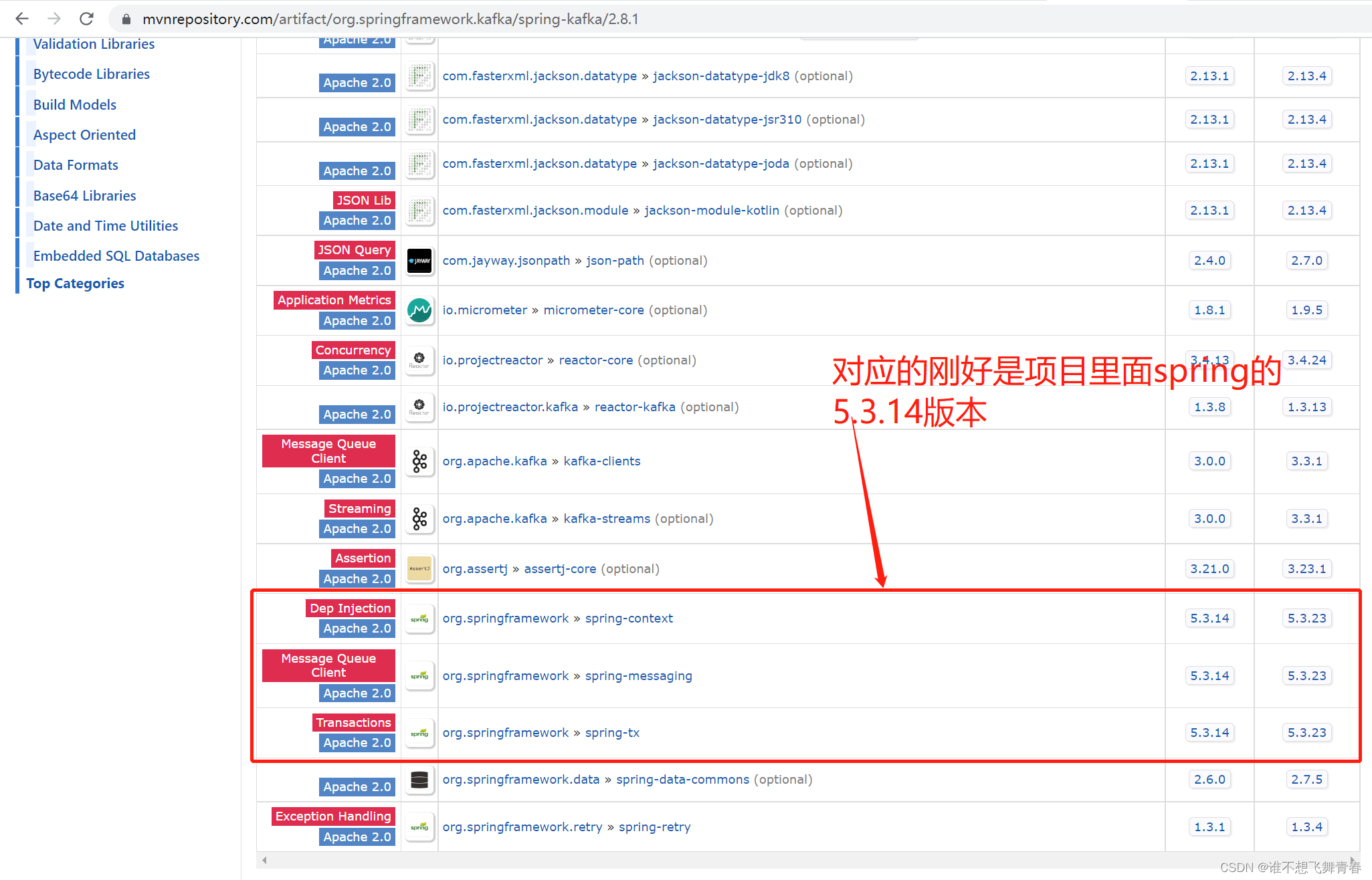
这里我SpringBoot版本是1.4.2.RELEASE版本,版本很低,官网显示的SpringBoot版本最低是1.5.x,可以使用1.3.x的版本,很明显我的这个不在官网给的范围内,然后我的spring版本是4.3.9.RELEASE,这里我在上面这个maven仓库spring-kafka地址里面看了一个1.3.0版本,如下: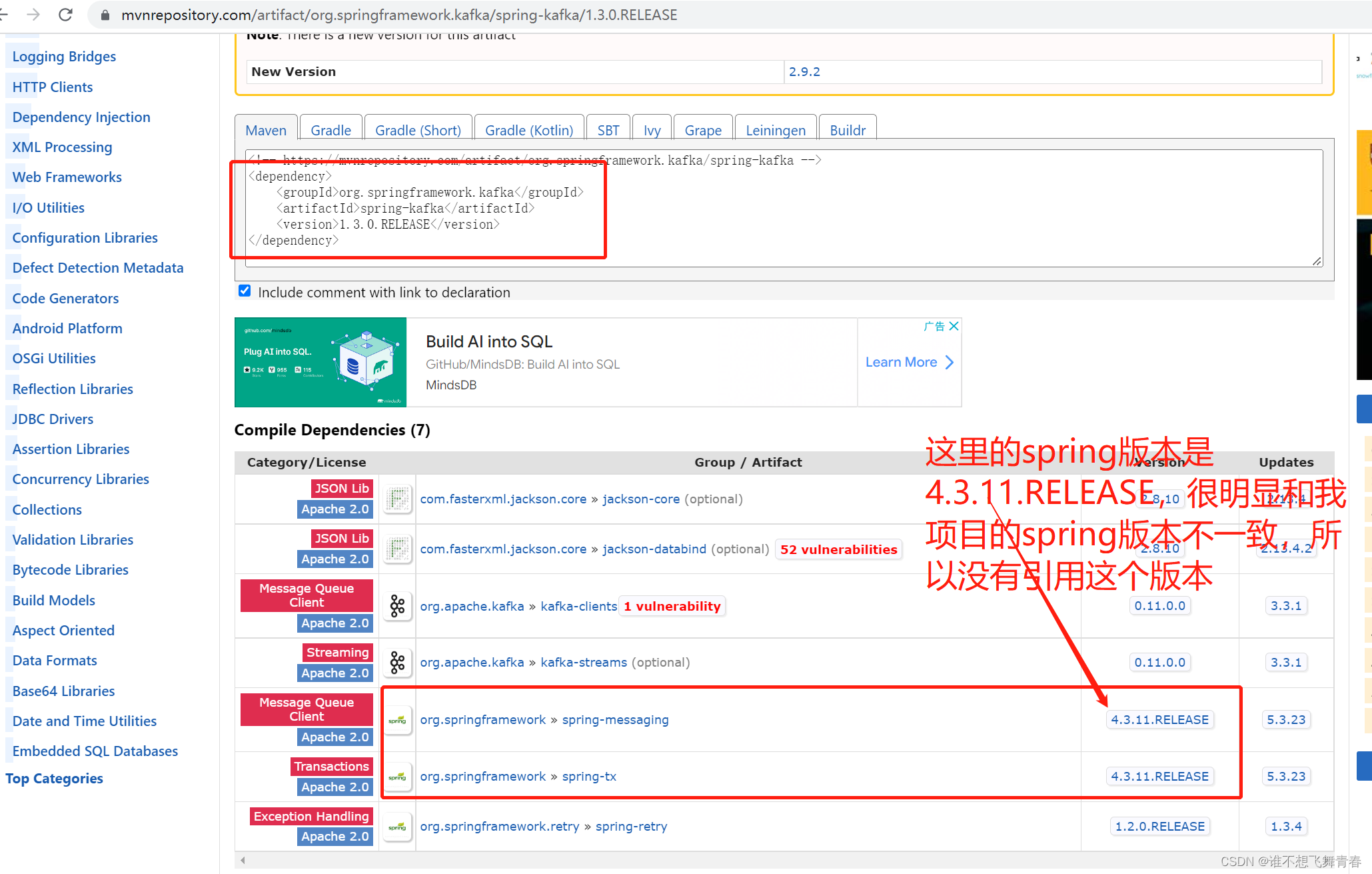
直到我往下继续找,终于发现1.2.2.RELEASE这个版本是与我项目对应的。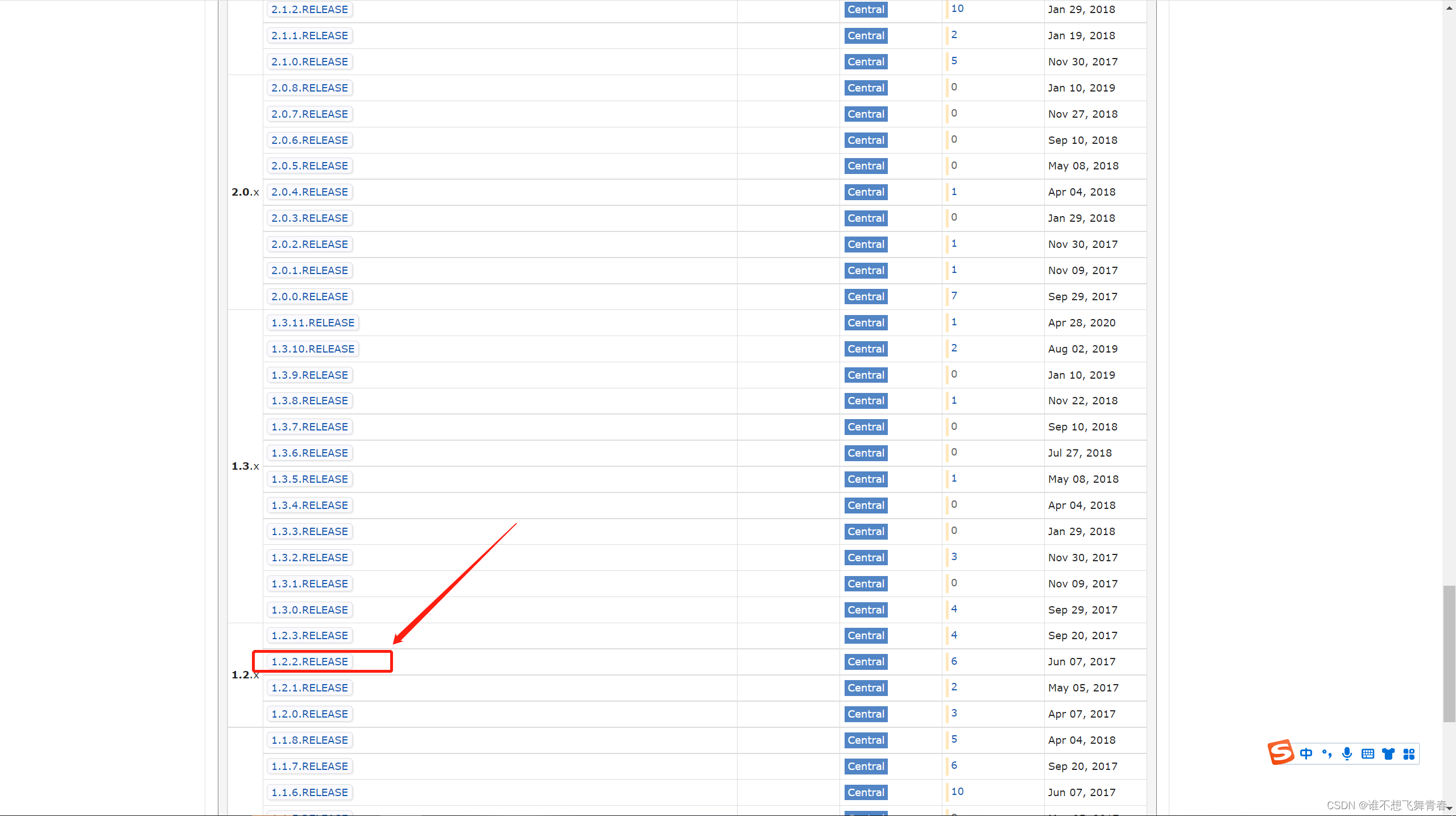
刚好这个版本对应的spring版本是4.3.9.RELEASE与我项目的spring版本一致,于是我就使用了这个spring-kafka版本。好了,这里怎么选择版本就说到这里,下面是代码。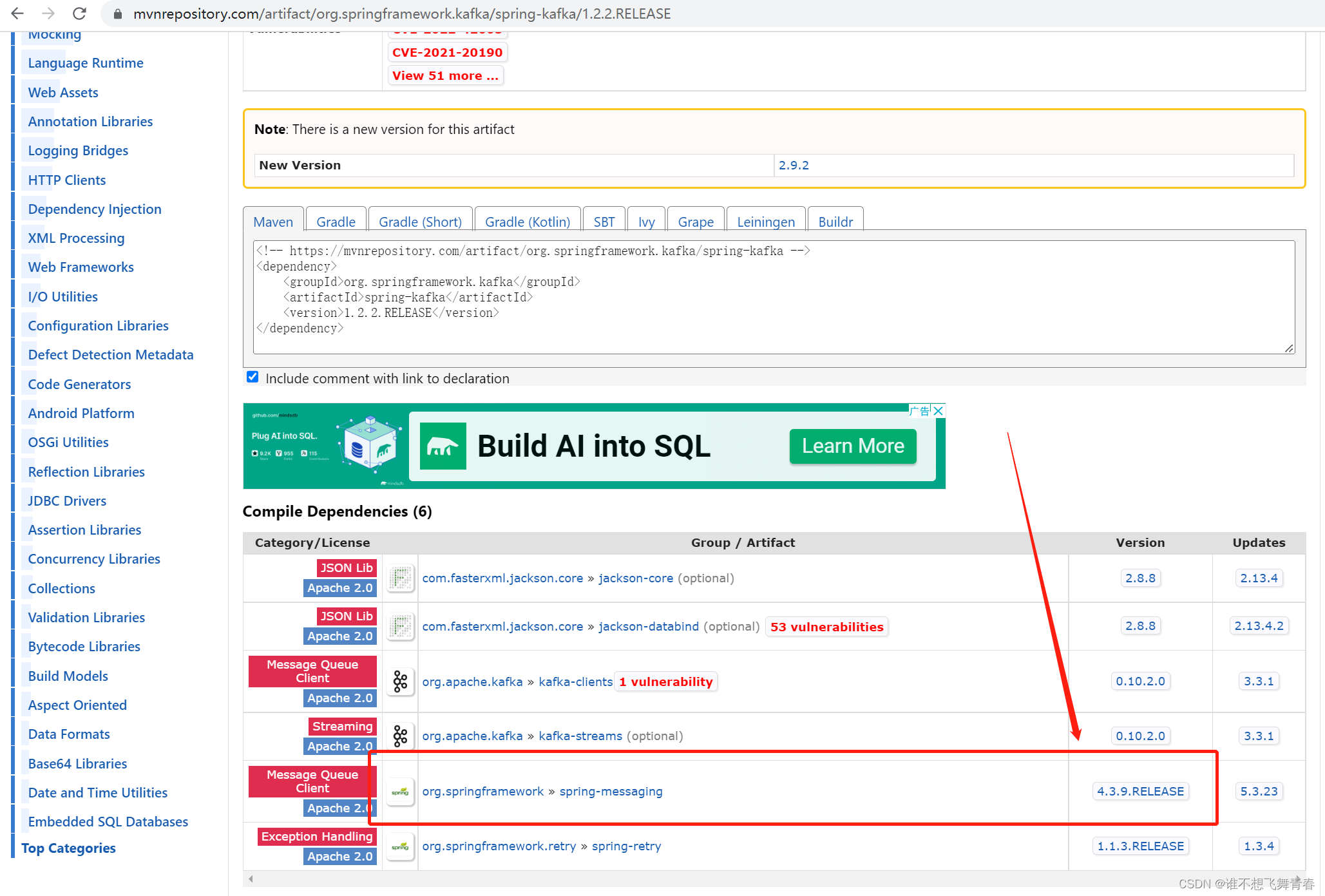
代码
这里之所以是在Java类里面写生产者和消费者配置,是因为springboot和kafka集成版本太低,不支持直接在application.yml里面配置,好像springboot高版本至少2.几的版本可以直接在application.yml里面配置,至于2.几的版本才支持我给忘记了,有知道的小伙伴麻烦告诉下我,谢谢了。
kafka生产者配置
这里是带用户名密码协议配置,最下面三个就是,协议类型为:SASL/SCRAM-SHA-256,如果你们那里的kafka配置没有设置这个,可以不需要配置最下面三个。企业开发一般需要进行认证才能发送消息。
packagecom.gmcc.project.controllers.kafka;importlombok.Data;importorg.springframework.context.annotation.Configuration;//kafka生产者参数配置@Data@ConfigurationpublicclassKafkaProducerProperties{//指定kafka 代理地址,多个地址用英文逗号隔开privateString bootstrapServers="192.168.11.111:9092,192.168.11.112:9093";//本地测试kafka使用//消息重发次数,如果配置了事务,则不能为0,改为1privateint retries=0;//每次批量发送消息的数量privateString batchSize="16384";//默认值为0,意思就是说消息必须立即被发送,但这样会影响性能//一般设置10毫秒左右,这个消息发送完后会进入本地的一个batch,如果10毫秒内这个batch满了16kb就会随batch一起发送出去privateString lingerMs="10";//生产者最大可发送的消息大小,内有多个batch,一旦满了,只有发送到kafka后才能空出位置,否则阻塞接收新消息privateString bufferMemory="33554432";//指定消息key和消息体的编解码方式privateString keySerializer="org.apache.kafka.common.serialization.StringSerializer";privateString valueSerializer="org.apache.kafka.common.serialization.StringSerializer";//确认等级ack,kafka生产端最重要的选项,如果配置了事务,那必须是-1或者all//acks=0,生产者在成功写入消息之前不会等待任何来自服务器的响应//acks=1,只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应//acks=-1,表示分区leader必须等待消息被成功写入到所有的ISR副本(同步副本)中才认为product请求成功。这种方案提供最高的消息持久性保证,但是理论上吞吐率也是最差的privateString acks="1";//协议类型,为SASL类型privateString securityProtocol="SASL_PLAINTEXT";//协议privateString saslMechanism="SCRAM-SHA-256";//用户名密码配置privateString saslJaas="org.apache.kafka.common.security.scram.ScramLoginModule required username=root password=123456;";}
然后再创建一个config使kafka生产者配置生效。如果kafka配置文件没有设置用户名密码协议,注释掉最下面三个即可。
packagecom.gmcc.project.controllers.config;importcom.gmcc.project.controllers.kafka.KafkaProducerProperties;importorg.apache.kafka.clients.CommonClientConfigs;importorg.apache.kafka.clients.producer.ProducerConfig;importorg.apache.kafka.common.config.SaslConfigs;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importorg.springframework.kafka.annotation.EnableKafka;importorg.springframework.kafka.core.DefaultKafkaProducerFactory;importorg.springframework.kafka.core.KafkaTemplate;importorg.springframework.kafka.core.ProducerFactory;importjava.util.HashMap;importjava.util.Map;@Configuration@EnableKafkapublicclassKafkaProductConfig{@AutowiredprivateKafkaProducerProperties producerProperties;@BeanpublicProducerFactory<String,String>producerFactory(){returnnewDefaultKafkaProducerFactory<>(producerConfigs());}@BeanpublicMap<String,Object>producerConfigs(){Map<String,Object> props =newHashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, producerProperties.getBootstrapServers());
props.put(ProducerConfig.RETRIES_CONFIG, producerProperties.getRetries());
props.put(ProducerConfig.BATCH_SIZE_CONFIG, producerProperties.getBatchSize());
props.put(ProducerConfig.LINGER_MS_CONFIG, producerProperties.getLingerMs());
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, producerProperties.getBufferMemory());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, producerProperties.getKeySerializer());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, producerProperties.getValueSerializer());
props.put(ProducerConfig.ACKS_CONFIG, producerProperties.getAcks());//props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, producerProperties.getSecurityProtocol());//props.put(SaslConfigs.SASL_MECHANISM, producerProperties.getSaslMechanism());//props.put(SaslConfigs.SASL_JAAS_CONFIG, producerProperties.getSaslJaas());return props;}@BeanpublicKafkaTemplate<String,String>kafkaTemplate(){returnnewKafkaTemplate<>(producerFactory());}}
kafka消费者配置
如果kafka配置文件没有配置用户名密码协议,认证后才能消费消息,可以将最下面的三个注释掉不使用。
packagecom.gmcc.project.controllers.kafka;importlombok.Data;importorg.springframework.context.annotation.Configuration;//kafka消费者配置@Data@ConfigurationpublicclassKafkaConsumerProperties{//指定kafka 代理地址,多个地址用英文逗号隔开privateString bootstrapServers="192.168.11.111:9092,192.168.11.112:9093";//本地测试kafka使用//指定默认消费者group id,消费者监听到的也是这个privateString groupId="test-consumer-group";//本地测试使用//消费者在读取一个没有offset的分区或者offset无效时的策略,默认earliest是从头读,latest不是从头读privateString autoOffsetReset="earliest";//是否自动提交偏移量offset,默认为true,一般是false,如果为false,则auto-commit-interval属性就会无效privateboolean enableAutoCommit=true;//自动提交间隔时间,接收到消息后多久会提交offset,前提需要开启自动提交,也就是enable-auto-commit设置为true,默认单位是毫秒(ms),如果写10s,最后加载的显示值为10000ms,需要符合特定时间格式:1000ms,1S,1M,1H,1D(毫秒,秒,分,小时,天)privateString autoCommitInterval="1000";//指定消息key和消息体的编解码方式privateString keyDeserializerClass="org.apache.kafka.common.serialization.StringDeserializer";privateString valueDeserializerClass ="org.apache.kafka.common.serialization.StringDeserializer";//批量消费每次最多消费多少条信息privateString maxPollRecords="50";//协议类型,为SASL类型privateString securityProtocol="SASL_PLAINTEXT";//协议privateString saslMechanism="SCRAM-SHA-256";//用户名密码配置privateString saslJaas="org.apache.kafka.common.security.scram.ScramLoginModule required username=root password=123456;";}
然后再创建一个config使kafka消费者配置生效。如果kafka没有设置用户名密码协议,注释掉最下面三个即可。
packagecom.gmcc.project.controllers.config;importcom.gmcc.project.controllers.kafka.KafkaConsumerProperties;importorg.apache.kafka.clients.CommonClientConfigs;importorg.apache.kafka.clients.consumer.ConsumerConfig;importorg.apache.kafka.common.config.SaslConfigs;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importorg.springframework.kafka.annotation.EnableKafka;importorg.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;importorg.springframework.kafka.core.ConsumerFactory;importorg.springframework.kafka.core.DefaultKafkaConsumerFactory;importjava.util.HashMap;importjava.util.Map;@Configuration@EnableKafkapublicclassKafkaConsumerConfig{@AutowiredprivateKafkaConsumerProperties consumerProperties;@BeanConcurrentKafkaListenerContainerFactory<String,String>kafkaListenerContainerFactory(){ConcurrentKafkaListenerContainerFactory<String,String> factory =newConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());//设置为批量消费,每个批次数量在Kafka配置参数中设置ConsumerConfig.MAX_POLL_RECORDS_CONFIG
factory.setBatchListener(false);//这里为true的时候,KafkaConsumer那里需要使用批量消费方法,不然报错return factory;}@BeanpublicConsumerFactory<String,String>consumerFactory(){returnnewDefaultKafkaConsumerFactory<>(consumerConfigs());}@BeanpublicMap<String,Object>consumerConfigs(){Map<String,Object> props =newHashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, consumerProperties.getBootstrapServers());
props.put(ConsumerConfig.GROUP_ID_CONFIG, consumerProperties.getGroupId());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, consumerProperties.getAutoOffsetReset());
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, consumerProperties.isEnableAutoCommit());
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, consumerProperties.getAutoCommitInterval());
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, consumerProperties.getKeyDeserializerClass());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, consumerProperties.getValueDeserializerClass());
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, consumerProperties.getMaxPollRecords());//props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, consumerProperties.getSecurityProtocol());//props.put(SaslConfigs.SASL_MECHANISM, consumerProperties.getSaslMechanism());//props.put(SaslConfigs.SASL_JAAS_CONFIG, consumerProperties.getSaslJaas());return props;}}
发送消息给kafka的Controller代码
这里使用addCallback这个方法,是可以在生产者发送消息给kafka时,如果生产者配置有问题或者服务有问题,我可以直接看到接口返回结果,所以没有直接这样kafkaTemplate.send(“first”,data);写。
packagecom.gmcc.project.controllers.kafka;importcom.gmcc.project.core.utils.StringUtils;importorg.springframework.kafka.core.KafkaTemplate;importorg.springframework.web.bind.annotation.RequestMapping;importorg.springframework.web.bind.annotation.RequestMethod;importorg.springframework.web.bind.annotation.RequestParam;importorg.springframework.web.bind.annotation.RestController;importjavax.annotation.Resource;importjava.util.HashMap;importjava.util.Map;//kafka生产者@RestController@RequestMapping("kafkaProducer")publicclassKafkaProducerController{@ResourceprivateKafkaTemplate<String,String> kafkaTemplate;//向kafka发送消息@RequestMapping(value ="/sendFileMd5", method =RequestMethod.POST)publicMap<String,Object>sendFileMd5(@RequestParam(value ="fileMd5", required =false)String fileMd5,@RequestParam(value ="uuid", required =false)String uuid){Map<String,Object> returnMap =newHashMap<>();//写在success里面只会返回一次,第二次就给你返回一个空map对象
returnMap.put("message","发送消息成功!");
returnMap.put("result",null);
returnMap.put("status","200");//非空判断if(StringUtils.isBlank(fileMd5)){
returnMap.put("message","fileMd5不能为空!");
returnMap.put("result","");
returnMap.put("status","999");return returnMap;}if(StringUtils.isBlank(uuid)){
returnMap.put("message","uuid不能为空!");
returnMap.put("result","");
returnMap.put("status","999");return returnMap;}try{//需要发送的消息String data="{\"file_md5\":\""+fileMd5+"\",\"uuid\":\""+uuid+"\",\"vendor\":\"etone\",\"model\":\"5g信令回放\"}";//pro环境使用topic为test_sample_get//本地测试使用,向topic为first发送消息
kafkaTemplate.send("first",data).addCallback(success ->{// 消息发送到的topicString topic = success.getRecordMetadata().topic();// 消息发送到的分区int partition = success.getRecordMetadata().partition();// 消息在分区内的offsetlong offset = success.getRecordMetadata().offset();System.out.println("发送消息成功:"+data+",主题:"+topic+",分区:"+partition+",偏移量:"+offset);}, failure ->{
returnMap.put("message","发送消息失败:"+ failure.getMessage());
returnMap.put("result",null);
returnMap.put("status","500");});}catch(Exception e){
returnMap.put("message", e.getMessage());
returnMap.put("result",null);
returnMap.put("status","500");}return returnMap;}}
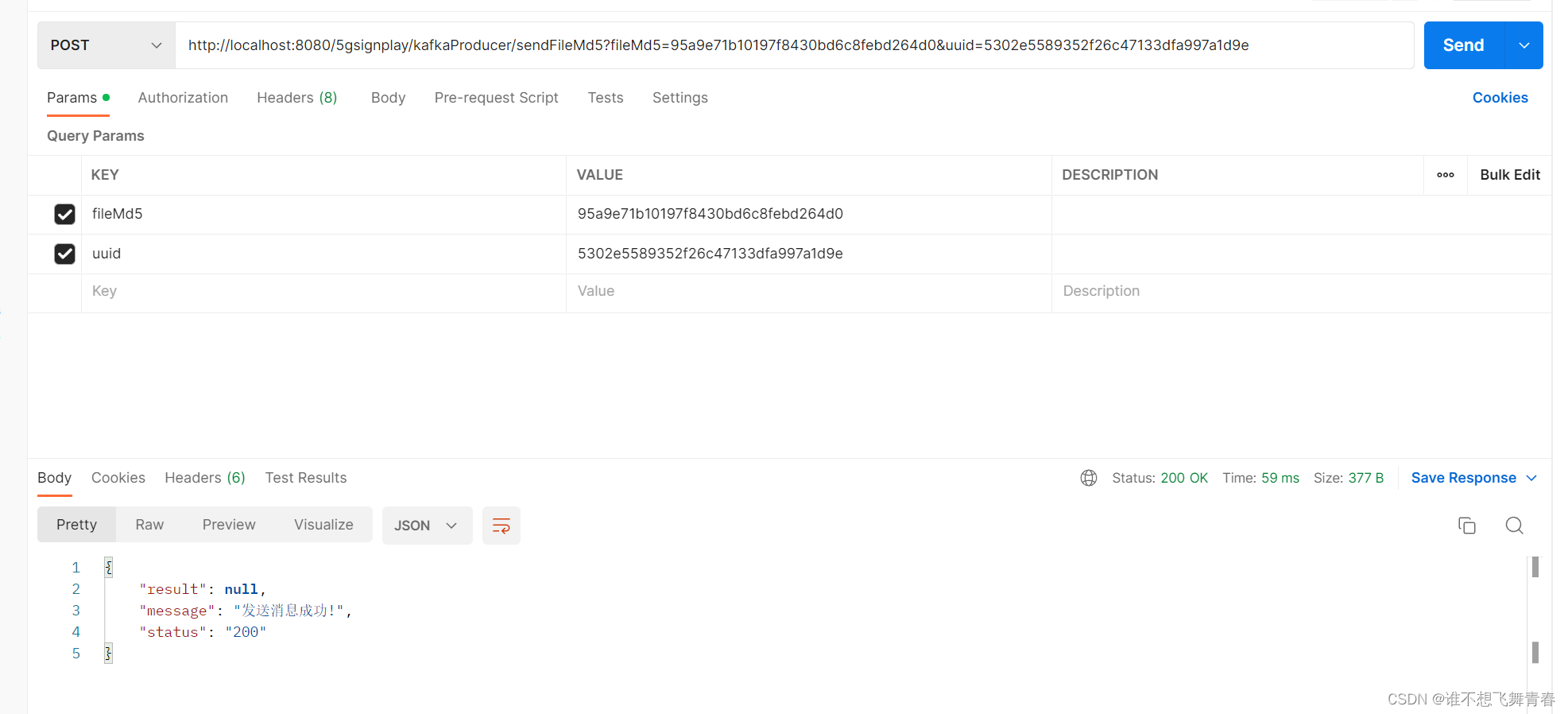
消费者消费代码
packagecom.gmcc.project.controllers.kafka;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.springframework.kafka.annotation.KafkaListener;importorg.springframework.stereotype.Component;@ComponentpublicclassKafkaConsumer{//逐条消费@KafkaListener(topics ="first")//@KafkaListener(topics = "test_sample_return")publicvoidonMessage(ConsumerRecord<?,?>record){try{//消费的哪个topic、partition的消息,打印出消息内容System.out.println("消费:"+record.topic()+"-"+record.partition()+"-"+record.value());}catch(Exception e){
e.printStackTrace();}}//批量消费方法/*@KafkaListener(topics = "first")
public void onMessage(List<ConsumerRecord<?,?>> records){
System.out.println("消费数量="+records.size());
for(ConsumerRecord<?,?> record:records){
//消费的哪个topic、partition的消息,打印出消息内容
System.out.println("消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}*/}
消费到的消息:
这里面的uuid是集成了websocket需要用到,这里怎么集成websocket将消费到的消息返回给客户端等以后有时间了在另写一个博客说明。
高版本SpringBoot集成Kafka代码
这里高版本可以供自己学习。高版本集成很简单,没有低版本那么麻烦。
代码结构: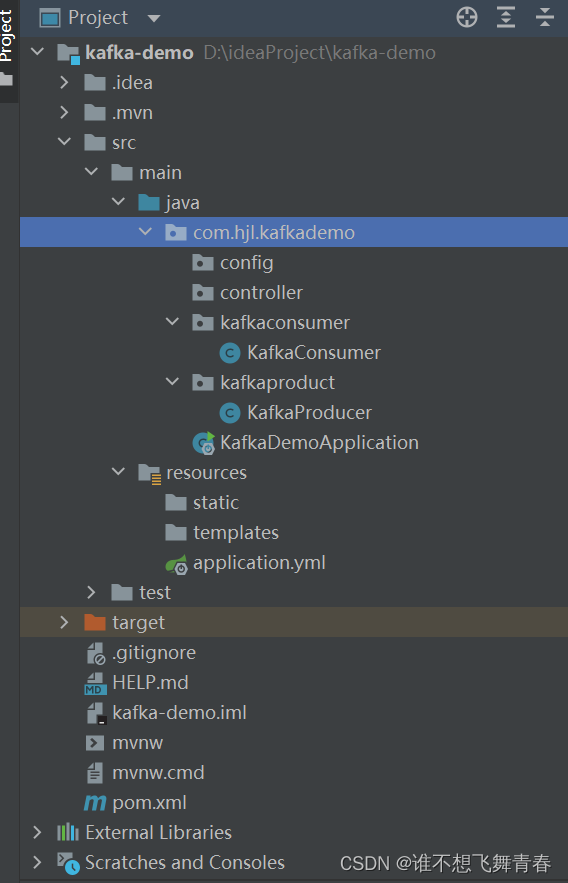
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.2</version><relativePath/><!-- lookup parent from repository --></parent><groupId>com.hjl</groupId><artifactId>kafka-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>kafka-demo</name><description>Demo project forSpringBoot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.6.2</version></plugin></plugins></build></project>
这里我的SpringBoot版本是2.6.2版本,spring-kafka版本是2.8.1版本。符合官网给的版本推荐。如下: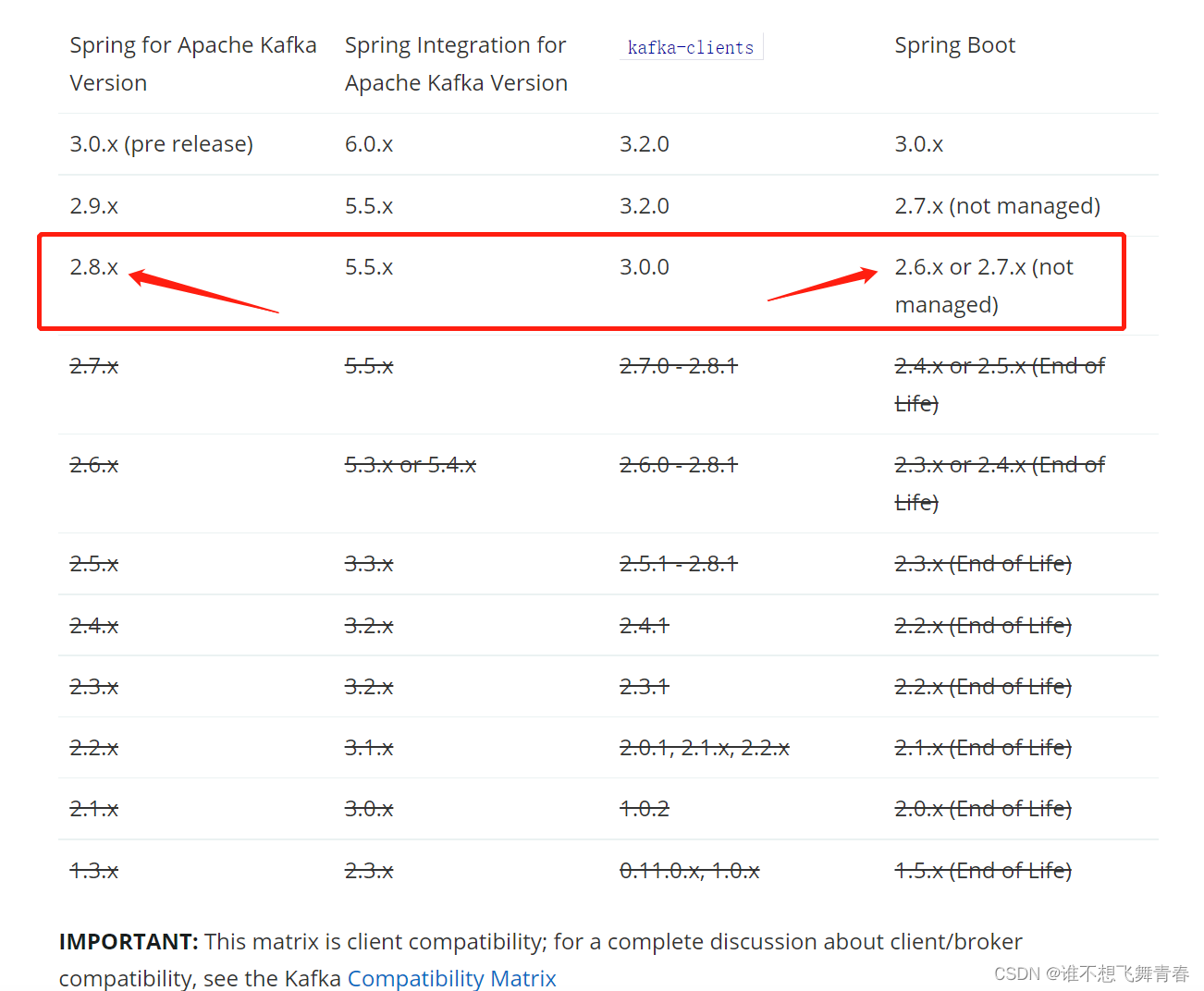
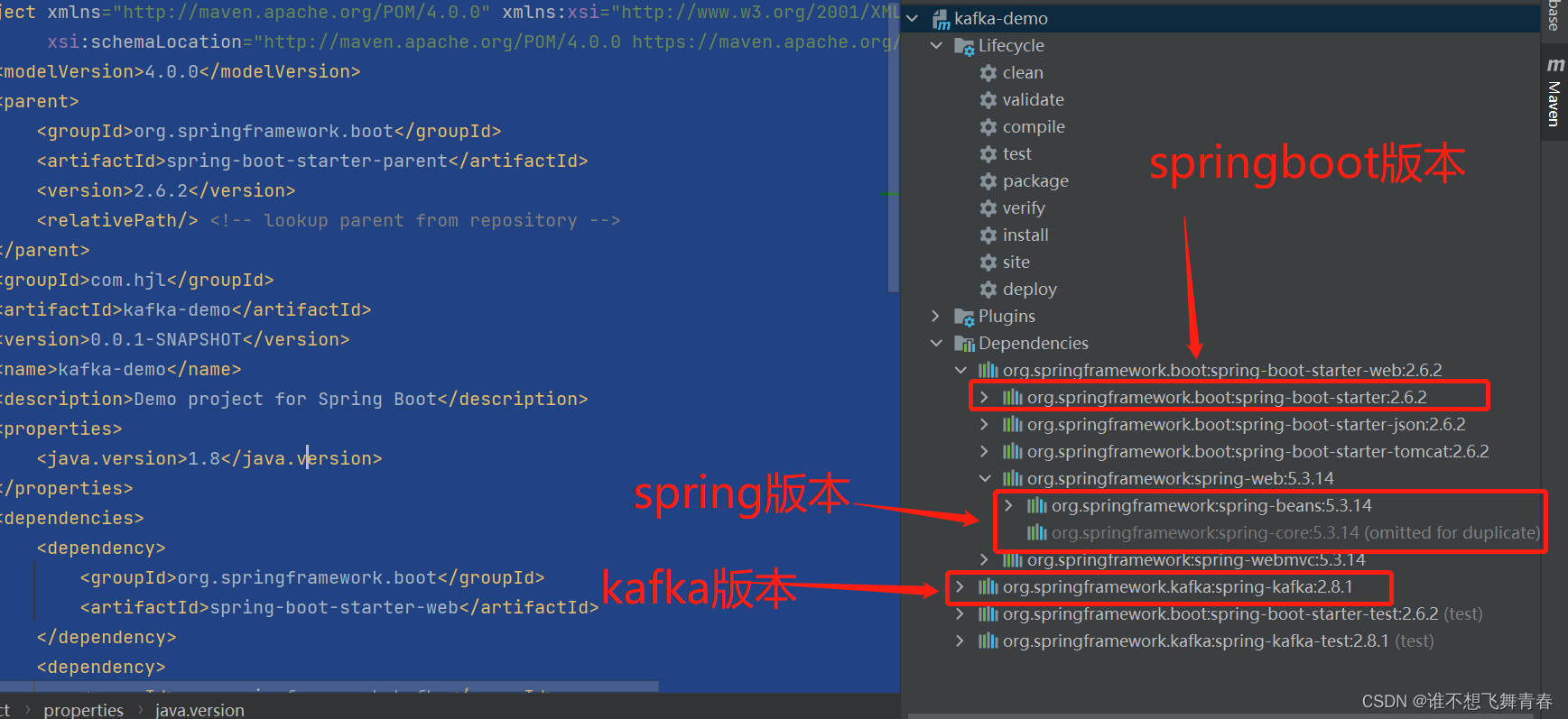
application.yml文件
这里之所以可以在application.yml直接配置kafka,是因为springboot和spring-kafka版本很高。这里生产者配置和消费者配置都在里面。
server:
port:8080
spring:
kafka:
# 指定kafka 代理地址,多个地址用英文逗号隔开
bootstrap-servers:192.168.11.111:9092
#初始化生产者配置
producer:
#消息重发次数,如果配置了事务,则不能为0,改为1
retries:0
# 每次批量发送消息的数量
batch-size:16384
#生产者最大可发送的消息大小,内有多个batch,一旦满了,只有发送到kafka后才能空出位置,否则阻塞接收新消息
buffer-memory:33554432
# 指定消息key和消息体的编解码方式
key-serializer:org.apache.kafka.common.serialization.StringSerializer
value-serializer:org.apache.kafka.common.serialization.StringSerializer
#确认等级ack,kafka生产端最重要的选项,如果配置了事务,那必须是-1或者all
#acks=0,生产者在成功写入消息之前不会等待任何来自服务器的响应
#acks=1,只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应
#acks=-1,表示分区leader必须等待消息被成功写入到所有的ISR副本(同步副本)中才认为product请求成功。这种方案提供最高的消息持久性保证,但是理论上吞吐率也是最差的
acks: all
#配置事务,名字随便起
#transaction-id-prefix: hbz-transaction-
#初始化消费者配置
consumer:
# 指定默认消费者group id,消费者监听到的也是这个
group-id: test-consumer-group
#消费者在读取一个没有offset的分区或者offset无效时的策略,默认earliest是从头读,latest不是从头读
auto-offset-reset: earliest
#是否自动提交偏移量offset,默认为true,一般是false,如果为false,则auto-commit-interval属性就会无效
enable-auto-commit:true
#自动提交间隔时间,接收到消息后多久会提交offset,前提需要开启自动提交,也就是enable-auto-commit设置为true,默认单位是毫秒(ms),如果写10s,最后加载的显示值为10000ms,需要符合特定时间格式:1000ms,1S,1M,1H,1D(毫秒,秒,分,小时,天)
auto-commit-interval:1000
# 指定消息key和消息体的编解码方式
key-serializer:org.apache.kafka.common.serialization.StringDeserializer
value-serializer:org.apache.kafka.common.serialization.StringDeserializer
#批量消费每次最多消费多少条信息
max-poll-records:50
#监听器设置
listener:
#消费端监听的topic不存在时,项目启动会报错(关掉)
missing-topics-fatal:false
#设置消费类型 批量消费batch,单条消费single
type: batch
#指定容器的线程数,提高并发量,默认为1
#concurrency:3
#手动提交偏移量,当enable-auto-commit为true自动提交时,不需要设置改属性
#ack-mode: manual
生产者发送消息代码
packagecom.project.kafkademo.kafkaproduct;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.kafka.core.KafkaTemplate;importorg.springframework.web.bind.annotation.RequestMapping;importorg.springframework.web.bind.annotation.RequestMethod;importorg.springframework.web.bind.annotation.RequestParam;importorg.springframework.web.bind.annotation.RestController;//kafka生产者@RestController@RequestMapping("kafka")publicclassKafkaProducer{@AutowiredprivateKafkaTemplate<String,String> kafkaTemplate;@RequestMapping(value ="/send", method =RequestMethod.GET)publicStringsend(@RequestParam(value ="message", required =false)String message){
kafkaTemplate.send("first",message);return"success";}}
消费者消费消息代码
packagecom.project.kafkademo.kafkaconsumer;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.apache.kafka.clients.consumer.ConsumerRecords;importorg.springframework.kafka.annotation.KafkaListener;importorg.springframework.stereotype.Component;importjava.util.List;@ComponentpublicclassKafkaConsumer{//消费监听,topics=监听的主题名,groupId=分组,consumer.properties里面的group.id配置//如果在这里直接写groupId="test-consumer-group"会导致application.yml里面设置的group-id不起效//最终会被这里的设置直接覆盖掉,所以这里不应该加groupId="test-consumer-group"这个属性//@KafkaListener(topics = "first",groupId="test-consumer-group")//这样写的话,application.yml里面设置的group-id就会生效,监控的就是application.yml里面的了//逐条消费/*@KafkaListener(topics = "first")
public void onMessage(ConsumerRecord<?,?> record){
//消费的哪个topic、partition的消息,打印出消息内容
System.out.println("消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}*///批量消费,用List批量接收消息,ConsumerRecord<?,?>只能单条消费消息/*@KafkaListener(topics = "first")
public void onMessage(List<ConsumerRecord<?,?>> records){
System.out.println("消费数量="+records.size());
for(ConsumerRecord<?,?> record:records){
//消费的哪个topic、partition的消息,打印出消息内容
System.out.println("消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}*///批量消费,ConsumerRecords<?,?>用于批量消费消息@KafkaListener(topics ="first")publicvoidonMessage(ConsumerRecords<?,?> records){System.out.println("消费数量="+records.count());for(ConsumerRecord<?,?>record:records){//消费的哪个topic、partition(哪个分区)的消息,打印出消息内容System.out.println("消费:"+record.topic()+"-"+record.partition()+"-"+record.key()+"-"+record.value());}}}
效果
项目启动后,会打印出你配置的参数以及默认配置的参数

postman接口测试: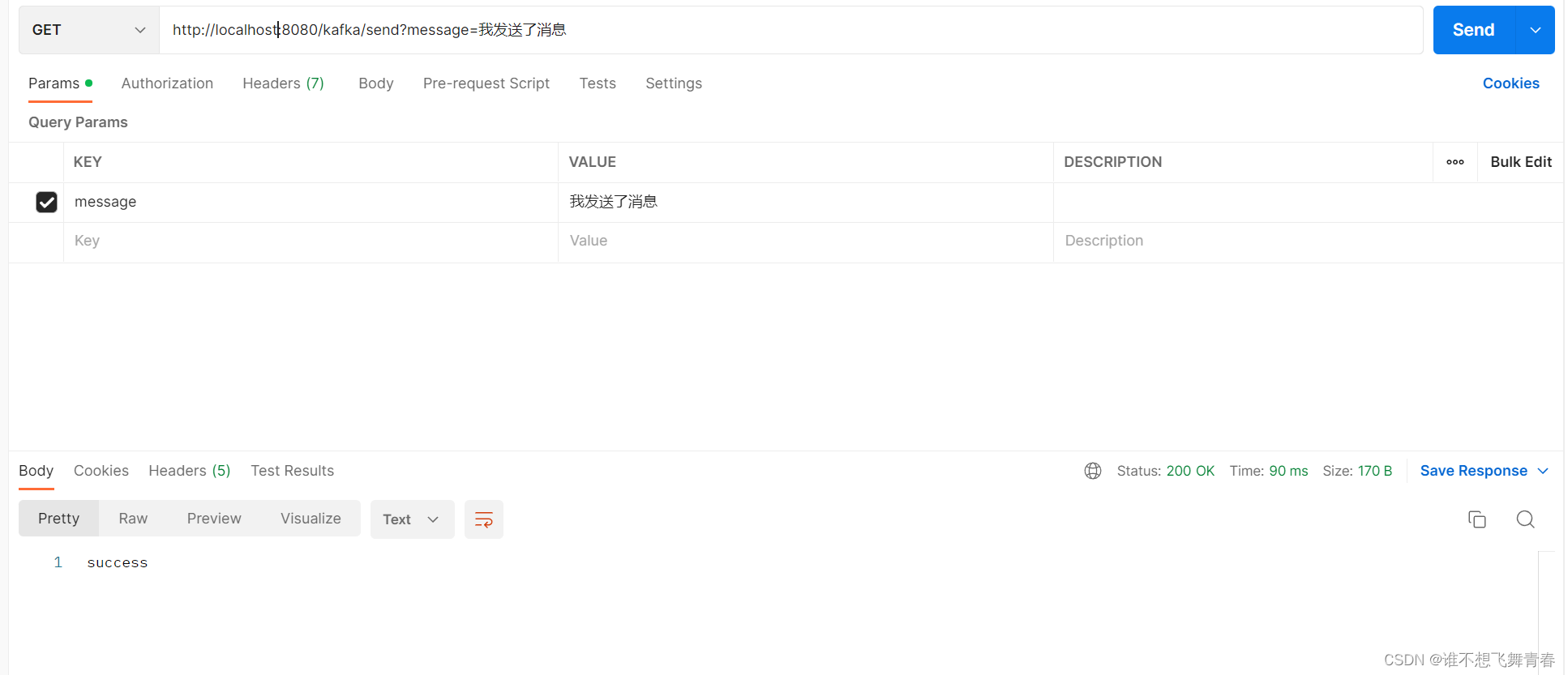
后台结果打印:
好了,我的记录就先到这里,如果有不对的地方,请大佬指正一下,谢谢!
版权归原作者 谁不想飞舞青春 所有, 如有侵权,请联系我们删除。