
一. 什么是SQL执行计划
为什么关注sql的执行计划,因为一个sql的执行计划可以告诉我们很多关于如何优化sql的信息 。
通过一个sql计划,如何访问中的数据 (是使用全表扫描还是索引查找?)
一个表中可能存在多个表中不同的索引,表中的类型是什么是否子查询、关联查询等…
sql学习来自于sqlercn讲师
- 了解SQL如何访问表中的数据
- 了解SQL如何使用表中的索引
- 了解SQL所使用的查询类型
二. 获取SQL执行计划
在sql前加上
explain
关键词就可以了!
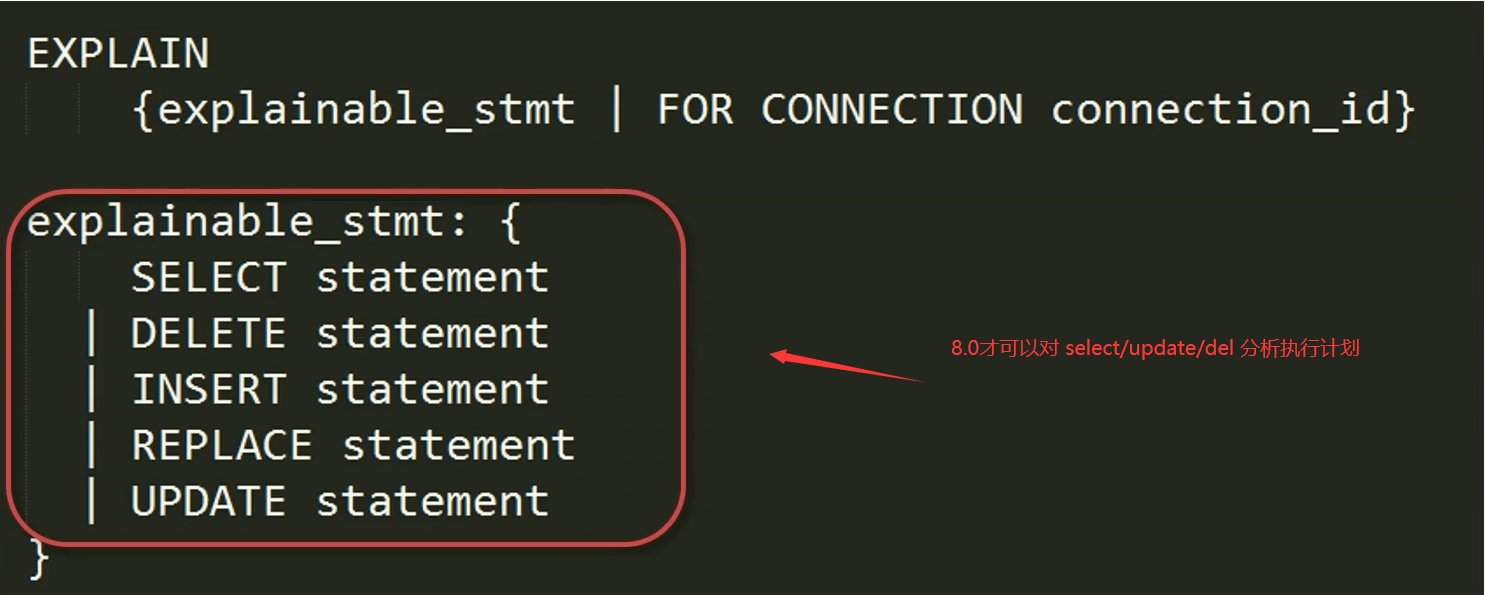
在MySQL8.0中是支持对
select/delete/inster/replace/update
语句来分析执行计划
而MySQL5.6前只支持对
select
语句分析执行计划。
提示: replace语句是跟inster语句非常类似,只是插入的数据和表中存在的数据(存在主键或者唯一索引)冲突的时候,replace语句会把原来的数据替换新插入的数据,表中不存在唯一的索引或主键,则直接插入新的数据
除了静态分析,MySQL8.0还可以使用
for connection
来直接分析正在执行的sql。(connection_id 就是
processlist表中的数据id
)
三. 分析执行计划
执行计划内容分析
例子1:课程人数大于3000
EXPLAIN
select course_id,title,study_cnt
from imc_course
where study_cnt > 3000;
访问得出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ulVz8LR1-1660528543156)(https://blog.97it.net/usr/uploads/2021/07/976069882.png)]
这些字段代表什么含义呢?
四. 分析执行计划(ID列)
- ID标识查询执行的顺序
- ID相同时,由上到下分析执行
- ID不同时,由大到下分析执行
ID列中的值只能有2中情况,要么是1组数字,要么是NULL
如果ID为数字序列,则说明查询的SQL语句对数据对象的操作顺序
如果是NULL,则代表数据由另外的2个查询union操作后所产生的结果集。
例子2: 【ID一致】学习人数大于3000人的课程id、课程分类、难度、课程标题、课程学习人数
explain
select course_id,class_name,level_name,title,study_cnt
from imc_course a
join imc_class b on b.class_id=a.class_id
join imc_level c on c.level_id =a.level_id
where study_cnt > 3000
返回3行结果,并且ID值是一样的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4fRE2eQF-1660528543157)(https://blog.97it.net/usr/uploads/2021/07/3819973405.png)]
由上往下读取sql的执行计划,第一行是
table
c表作为驱动表 ,等于是以C表为基础来进行循环嵌套的一个关联查询。 (4 1001 =400 总共扫描400行等到数据)
SQL优化器根据表的统计信息来进行数据的调整,实际上是由C表作为主表进行嵌套查询,sql优化动态的来调整表的关联顺序。
例子3: 【ID不一致】查询课程表中不存在课程章节的数据
explain
select
a,course_id,a.title
from imc_course a
where a.course_id not in (
select course_id from imc_chapter b
)

五. 分析执行计划(select_type列)
值含义SIMPLE不包含子查询或者UNION操作的查询(简单查询)PRIMARY查询中如果包含任何子查询,那么最外层的查询则被标记为PRIMARYSUBQUERYselect列表中的子查询DEPENDENT SUBQUERY依赖外部结果的子查询UNIONunion操作的第二个或之后的查询只为unionDEPENDENT UNION当union作为子查询时,第二或是第二个后的查询的select_type值UNION RESULTunion产生的结果集DERIVED出现在from子句中的子查询 (派生表)
例子1 : 查询学习人数大于3000 合并 课程是MySQL的记录
EXPLAIN
SELECT
course_id,class_name,level_name,title,study_cnt
FROM imc_course a
join imc_class b on b.class_id =a.class_id
join imc_level c on c.level_id = a.level_id
WHERE study_cnt > 3000
union
SELECT course_id,class_name,level_name,title,study_cnt
FROM imc_course a
join imc_class b on b.class_id = a.class_id
join imc_level c on c.level_id = a.level_id
WHERE class_name ='MySQL'

先看id等于2
id=2 则是查询mysql课程的sql信息,分别是
b,a,c
3个表,是union操作,selecttype为是
UNION
id=1 为是查询学习人数3000人的sql信息,是primary操作的结果集,分别是
c,a,b
3个表,select_type为
PRIMARY
最后一行是NULL, select_type是
union RESULT
代表是2个sql 组合的结果集。
六. 分析执行计划(table列)
指明是从那个表中获取数据
<table name>
就展示数据库表名 (如果表取了别名就显示别名)
<unionM,N>
由ID为M,N 查询union产生的结果集
<derived N>/<subquery N>
由ID为N的查询产生的结果(通常也是一个子查询的临时表)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LWAjTCVy-1660528543160)(https://blog.97it.net/usr/uploads/2021/07/1972183977.png)]
七. 分析执行计划(partition列)
- 对于查询分区表,显示查询的分区ID
- 对于非分区表,显示NULL
八. 分析执行计划(type列)【重要】
注意的: 是在mysql中不一定是使用JOIN才算是关联查询,实际上mysql会认为每一个查询都是连接查询
就算是查询一个表,对mysql来说也是关联查询。
type的取值是体现了mysql访问数据的一种方式。
type列的值按照性能高到低排列
system
const
eq_ref
ref
ref_or_null
index_merge
range
index
ALL
值含义system这是const连接类型的特例,当查询的
表只有一行时使用
const表中有且只有
一个匹配
的行时使用,如
对主键或唯一索引的查询
,这是效率最高的链接方式eq_ref
唯一索引或主键查询
,对应每个索引建,表中只有一条记录与之匹配 【A表扫描每一行B表只有一行匹配满足】ref非唯一索引查找,返回
匹配某个单独值的所有行
ref_or_null类似于ref类型的查询,但是附加了对NULL值列的查询index_merge该链接类型表示使用了
索引合并优化方法
range
索引范围扫描
,常见于between、>、< 这样的查询条件indexFULL index Scan
全索引扫描
,同ALL的区别是,
遍历的是索引树
ALLFULL TABLE Scan
全表扫描
,这是效率最差的链接方式
举例
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N9NTW3u2-1660528543160)(https://blog.97it.net/usr/uploads/2021/07/649653009.png)]
拿以上的sql语句分析
这里先分析ID不同,由大到小,ID相同由上到下。
- 「ID=1 union , select_type= PRIMARY 」C表 就是imc_level
作为驱动主表,a表level_id没加索引,他是ALL是全表扫描的,没有一个可用的索引。 - 「ID=1 , select_type= PRIMARY 」 ,a表 就是imc_course,a表class_id加了索引,但是没where去查询,并且数量量小也会走全表扫描, 也是
ALL全表扫描,没有一个可用的索引。` - 「 ID=1 , select_type= PRIMARY 」 ,
b表 就是imc_class, a表class_id加了索引跟class表的主键对应, 是eq_ref对应每个索引建,表中只有一条记录与之匹配,嵌套循环查找,B表通过A表的class_id关联查找。 【一条记录匹配】 - 「 ID=2 , select_type= union 」,
b表就是imc_class,是const,因为where加了条件class_name=MySQL,而class_name加了唯一索引,并且只匹配到一个。 【只有一行】 - 「 ID=2 , select_type= union 」 a表就是imc_course表,也是用到索引。
匹配某个单独值的所有行 - union是结果集,没有索引也是通过全表扫描。
如果
where like "MySQL%",会是什么type类型?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wTdfjfhB-1660528543161)(https://blog.97it.net/usr/uploads/2021/07/1304606973.png)]
虽然
class_name 加了索引
,但是使用where的
like% 右配
所以会走
索引范围扫描
。
如果
where like "%MySQL%", 会是什么type类型 ?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6w7Nr2G5-1660528543161)(http://blog.97it.net/usr/uploads/2021/07/536036482.png)]
虽然
class_name 加了索引
,但是使用where的
%like% 左右统配
所以会走
全索引扫描
,如果不加索引的话,左右统配会走全表扫描。
九. 分析执行计划(possible_keys/key/key_len/ ref 列)
possible_keys说明表可能用到了哪些索引,而
key是指实际上使用到的索引。
基于查询列和过滤条件进行判断。
查询出来都会被列出来,但是不一定会是使用到。
- 指出查询中可能会用到的索引
- 指出查询时实际用到的索引
- 实际使用索引的最大长度
possible_keys / key
可能用到的索引
如果在表中没有可用的索引,那么
key列
展示,
possible_keys
是NULL,这说明查询到覆盖索引。
key_len
实际用到的索引
key_len是索引使用的字节数ken_len注意的是,在联合索引中,如果有3列,那么总字节是长度是100个字节的话,那么key_len值数据可能少于100字节,比如30个字节,这就说明了查询中并没有使用联合索引的所有列。而只是利用到某一些列或者2列。- key_len的长度是由表中的定义的字段长度来计算的,并不是存储的实际长度,所以满足数据最短的实际字段存储,因为会直接影响到生成执行计划的生成 。
ref
指出那些列或常量被用于索引查找
执行
select * from imc_user where user_id=1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8gQhxQ15-1660528543162)(http://blog.97it.net/usr/uploads/2021/07/1123411536.png)]
从头到尾看下
首先他的ID列是1 ,代表就是数据库操作对象,并不是union产生的结果集
select_type列是
SIMPLE
是代表简单的查询
查询所涉及的表table列是
imc_user
表,由于这不是一个分区表所以partitions列是等于NULL 。
type列是
const
是个常量查询,固定值是1 ,只匹配一个并且用到的索引是主键索引。
possible_keys列 可能用到的索引也是主键索引,key列 实际索引也是主键索引。因为
user_id是主键
key_len列 长度是4个字节,
user_id是int类型,大小也是4个字节
ref列 是
const
也就是一个固定值,固定的常量值来进行索引过滤的。
十. 分析执行计划(rows / filtered 列)
rows列
( 有2个含义)1.、根据统计信息预估的扫描行数,
2、另一方面是关联查询内嵌的次数,每获取匹配一个值都要对目标表查询,所以循环次数越多性能越差。
因为扫描行数的值是预估的,所以并不准确
执行
select * from imc_user where user_id=1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HU1I5Fj7-1660528543162)(http://blog.97it.net/usr/uploads/2021/07/2916774700.png)]
拿以上举例,因为查询是一条记录,所以row是一条数据。
filtered列
表示返回结果的行数占需读取行数的百分比
filtered列跟rows列是有关联的,是返回预估符合条件的数据集,再去取的行的百分比。也是预估的值。
数值越高查询性能越好
十一. 分析执行计划(Extra列)
包括了不适合在其他列中所显示的额外信息
值含义Distinct优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作Not exists使用not exists来优化查询Using filesort使用文件来进行排序,
通常会出现在order by 或 group by 查询中
Using index使用了覆盖索引进行查询【意思是查询所需要的信息用索引来获取,不需要对表进行访问】Using temporaryMySQL需要使用临时表来处理,
常见于排序、子查询、和分组查询
Using where需要在MySQL服务器层
使用WHERE条件来过滤数据
select tables optimized away直接通过索引来获取数据,不用访问表
例子1:查询课程表没有章节的信息
EXPLAIN
select a.course_id,title
from imc_course a
left join imc_chapter b on b.course_id = a.course_id
where b.course_id is null
可以看到a表的
key列
是有值的,而
possible_keys
是NULL,代表是采用了覆盖索引。印证了
Extra列
是Using index 覆盖索引
【优化】 a表这个索引key是
title,如果加了where条件可以优化a表的type级别。比如
where tite ='xxx' or where title like "Mysql%"。
而b表是
type列
是ref级别,匹配某个单独值的所有行,并且加了where条件。所以再
Extra列
是有多个的。
以上就完成分析计划所以列的说明了…
版权归原作者 黎明强森 所有, 如有侵权,请联系我们删除。