
📢作者: 小小明-代码实体
📢博客主页:https://blog.csdn.net/as604049322
📢欢迎点赞 👍 收藏 ⭐留言 📝 欢迎讨论!
前几天群友分享了这样一个问题:
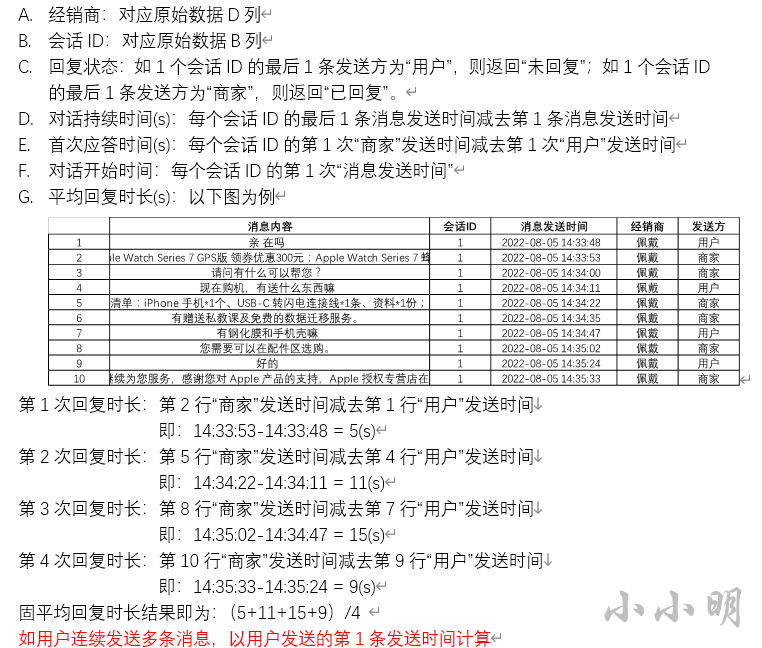
群友分享该题后,引起了很多人的讨论:
这题一眼看上去很简单,但实际写起来还是比较费劲的,要完全理解透彻也比较困难。
数据源和代码下载地址:https://gitcode.net/as604049322/blog_data
Pandas万能解法:循环
在遇到这种问题后,我希望最短的时间内解决该问题,必然使用不需要太动脑子的思路,直接遍历分组循环开干。
首先读取数据:
import pandas as pd
df = pd.read_excel("message.xlsx")
df.消息发送时间 = pd.to_datetime(df.消息发送时间)
df.head(20)
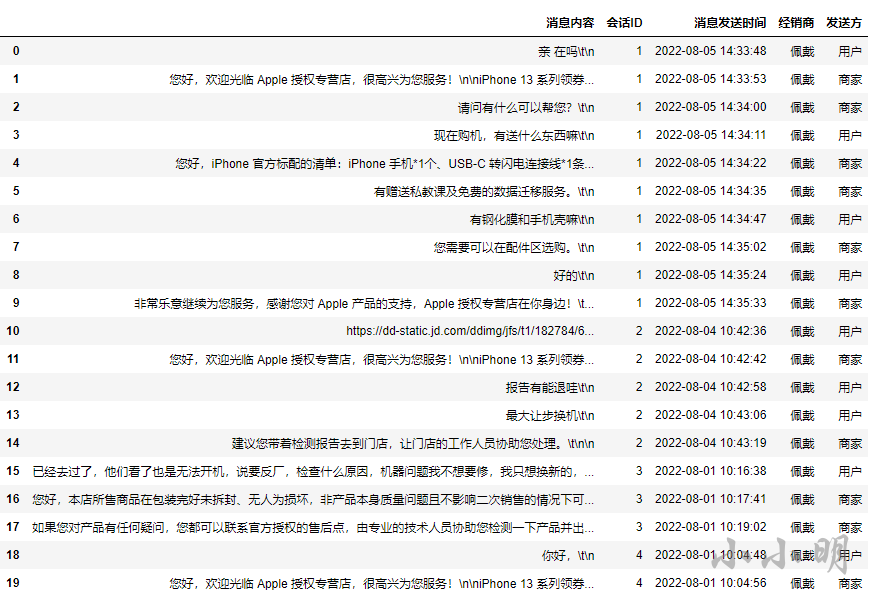
然后写出遍历框架:
for(agency, sess_id), data in df.groupby(["经销商","会话ID"]):break
data

这样我们就可以直接对其中一个分组进行测试,首先测一下比较简单的前四个指标(回复状态、对话持续时间、首次应答时间、对话开始时间):
# 回复状态
status ="未回复"if data.发送方.iat[-1]=="用户"else"已回复"# 对话持续时间
stay_time =(data.消息发送时间.max()-
data.消息发送时间.min()).total_seconds()# 首次应答时间
t = data.query('发送方 == "商家"').消息发送时间
first_res_time =(
t.iat[0]- data.query('发送方 == "用户"').消息发送时间.iat[0]).total_seconds()if t.shape[0]>0elseNone# 对话开始时间
start_time = data.消息发送时间.iat[0]print(status, stay_time, first_res_time, start_time)
已回复 354.0 12.0 2022-08-03 10:26:51
为了求平均回复时长,我依然使用万能的遍历法:
reply_time, n, avg_reply_time = pd.Timedelta(0),0,None
t =Nonefor row in data.itertuples():if t isNoneand row.发送方 =="用户":
t = row.消息发送时间
elif t isnotNoneand row.发送方 =="商家":
reply_time +=(row.消息发送时间-t)
n +=1
t =Noneif n !=0:
avg_reply_time =(reply_time/n).total_seconds()
avg_reply_time
34.0
思路:用变量t标记当前会话内用户第一次发消息的时间。当t为空时,查找发送方为用户的数据行,找到则记录该时间;当t不为空时,则查找发送方为商家的数据行,找到即可用当前时间减去t记录的时间,这表示一个会话,此时清空t,之后重复之前的步骤开始查找用户直到每条数据都被遍历。
最终完整代码为:
import pandas as pd
df = pd.read_excel("message.xlsx")
df.消息发送时间 = pd.to_datetime(df.消息发送时间)
result =[]for(agency, sess_id), data in df.groupby(["经销商","会话ID"]):
status ="未回复"if data.发送方.iat[-1]=="用户"else"已回复"
stay_time =(data.消息发送时间.max()-
data.消息发送时间.min()).total_seconds()
start_time = data.消息发送时间.iat[0]# 首次应答时间
t = data.query('发送方 == "商家"').消息发送时间
first_res_time =(
t.iat[0]- data.query('发送方 == "用户"').消息发送时间.iat[0]).total_seconds()if t.shape[0]>0elseNone# 平均回复时长
reply_time, n, avg_reply_time = pd.Timedelta(0),0,None
t =Nonefor row in data.itertuples():if t isNoneand row.发送方 =="用户":
t = row.消息发送时间
elif t isnotNoneand row.发送方 =="商家":
reply_time +=(row.消息发送时间-t)
n +=1
t =Noneif n !=0:
avg_reply_time =(reply_time/n).total_seconds()
result.append([agency, sess_id, status, stay_time,
first_res_time, start_time, avg_reply_time])
result = pd.DataFrame(result, columns=["经销商","会话ID","回复状态","对话持续时间","首次应答时间","对话开始时间","平均回复时长"])
result1 = result.round(2).sort_values("会话ID", ignore_index=True)
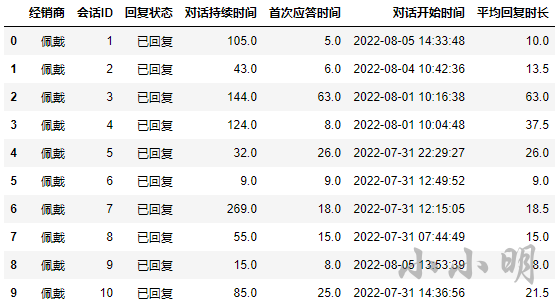
result1.head(10)
结果预览:
上面代码成功想出来并实现耗时半小时。
计算平均回复时长的思路2
对于前面没动脑子直接写代码而言,后续经过思考后发现,计算首次回复时间时进行了发送方为商家的筛选,然后又只取第一个,平均回复时长是否可以简化到取全部发送方为商家的数据进行计算。
先取一个会话进行测试:

然后我们考虑对连续的发送方去重:
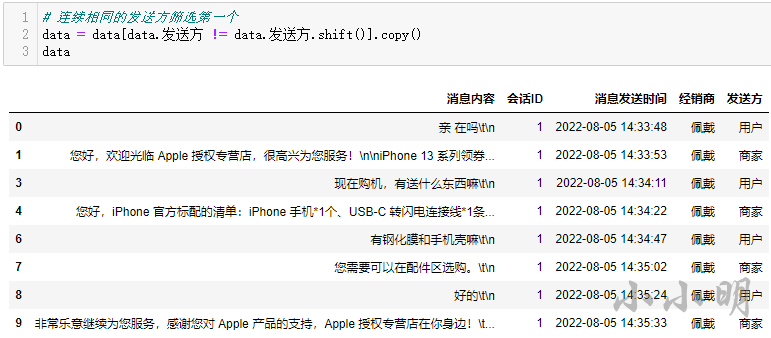
然后计算每个应答的回复时长:
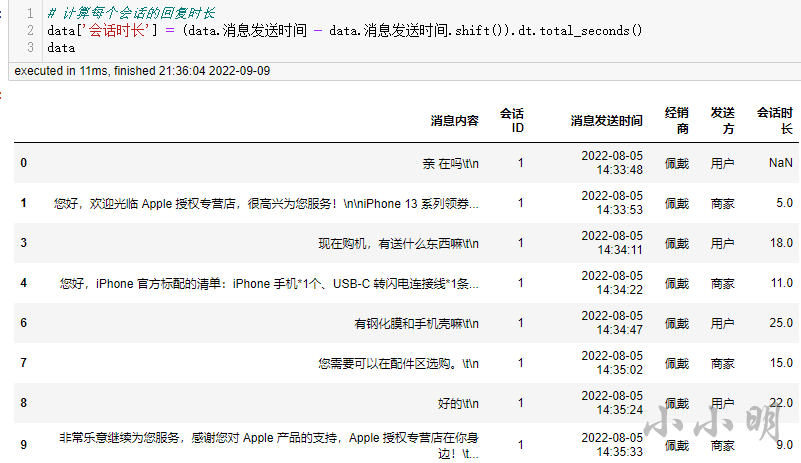
可以看到虽然发送方为用户的数据行也计算了,但是只要接下来我们筛选发送方为商家的数据,就可以得到每一个应答的时长,当然也包含第一个会话的通信时长,这样就顺便计算出了首次应答时间。
sess_times = data.query("发送方=='商家'").会话时长
first_res_time, avg_reply_time = sess_times.iat[0], sess_times.mean()print(first_res_time, avg_reply_time)
5.0 10.0
当然有些会话可能并没有商家的任何回复,所以遍历过程中还需要判断一下,最终完整代码为:
import pandas as pd
df = pd.read_excel("message.xlsx")
df.消息发送时间 = pd.to_datetime(df.消息发送时间)
result =[]for(agency, sess_id), data in df.groupby(["经销商","会话ID"]):
status ="未回复"if data.发送方.iat[-1]=="用户"else"已回复"
stay_time =(data.消息发送时间.max()-
data.消息发送时间.min()).total_seconds()
start_time = data.消息发送时间.iat[0]# 连续相同的发送方筛选第一个
data = data[data.发送方 != data.发送方.shift()].copy()# 计算每个会话的回复时长
data['会话时长']=(data.消息发送时间 - data.消息发送时间.shift()).dt.total_seconds()
sess_times = data.query("发送方=='商家'").会话时长
first_res_time, avg_reply_time =None,Noneif sess_times.shape[0]>0:
first_res_time, avg_reply_time = sess_times.iat[0], sess_times.mean()
result.append([agency, sess_id, status, stay_time,
first_res_time, start_time, avg_reply_time])
result = pd.DataFrame(result, columns=["经销商","会话ID","回复状态","对话持续时间","首次应答时间","对话开始时间","平均回复时长"])
result2 = result.round(2).sort_values("会话ID", ignore_index=True)
将循环转换为apply
在完成上述代码后,我们可以直接将上述代码转换为一种非循环的形式:
import pandas as pd
deffunc(data):
status ="未回复"if data.发送方.iat[-1]=="用户"else"已回复"
stay_time =(data.消息发送时间.max()-
data.消息发送时间.min()).total_seconds()
start_time = data.消息发送时间.iat[0]
data = data[data.发送方 != data.发送方.shift()].copy()
data['会话时长']=(data.消息发送时间 - data.消息发送时间.shift()).dt.total_seconds()
sess_times = data.query("发送方=='商家'").会话时长
first_res_time, avg_reply_time =None,Noneif sess_times.shape[0]>0:
first_res_time, avg_reply_time = sess_times.iat[0], sess_times.mean()return pd.Series([status, stay_time, first_res_time, start_time, avg_reply_time],
index=["回复状态","对话持续时间","首次应答时间","对话开始时间","平均回复时长"])
df = pd.read_excel('message.xlsx')
df.消息发送时间 = pd.to_datetime(df.消息发送时间)
result = df.groupby(["经销商","会话ID"], as_index=False).apply(func)
result3 = result.round(2).sort_values("会话ID", ignore_index=True)
非循环的解题思路
我们能否使用类SQL的思维解决该问题呢?很明显上面的实现思路是不可能直接转换为SQL的,我们必须使用SQL的列的形式实现,才可能最终用SQL解决该问题。
首先重新读取数据:
import pandas as pd
df = pd.read_excel('message.xlsx')
df.消息发送时间 = pd.to_datetime(df.消息发送时间)
然后我们先直接计算三个比较简单指标:
r1 = df.groupby(['经销商','会话ID'], as_index=False).agg(
回复状态=("发送方",lambda s:"未回复"if s.iat[-1]=="用户"else"已回复"),
对话持续时间=("消息发送时间",lambda x:(x.max()-x.min()).total_seconds()),
对话开始时间=("消息发送时间","first"))
r1
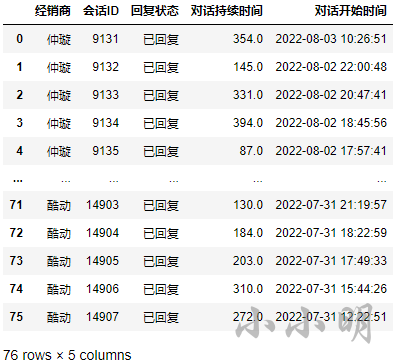
然后我们需要对整个数据集的每个会话的连续相同的发送方去重取第一个:
df = df[df.groupby("会话ID").发送方.transform(lambda x: x != x.shift())].copy()
然后计算会话时长:
df['会话时长']=(df.消息发送时间 - df.消息发送时间.shift()).dt.total_seconds()
df = df.query("发送方=='商家'")
再需要计算首次应答时间和平均回复时长就非常简单了,最终完整代码为:
import pandas as pd
df = pd.read_excel('message.xlsx')
df.消息发送时间 = pd.to_datetime(df.消息发送时间)
r1 = df.groupby(['经销商','会话ID'], as_index=False).agg(
回复状态=("发送方",lambda s:"未回复"if s.iat[-1]=="用户"else"已回复"),
对话持续时间=("消息发送时间",lambda x:(x.max()-x.min()).total_seconds()),
对话开始时间=("消息发送时间","first"))
df = df[df.groupby("会话ID").发送方.transform(lambda x: x != x.shift())].copy()
df['会话时长']=(df.消息发送时间 - df.消息发送时间.shift()).dt.total_seconds()
df = df.query("发送方=='商家'")
r2 = df.groupby('会话ID', as_index=False).agg(
首次应答时间=("会话时长","first"),
平均回复时长=("会话时长","mean"))
result = pd.merge(r1, r2, how="left", on="会话ID")[['经销商','会话ID','回复状态','对话持续时间','首次应答时间','对话开始时间','平均回复时长']]
result4 = result.round(2).sort_values("会话ID", ignore_index=True)
最后我们检查一下4种方法的结果是否完全一致:
print(result1.compare(result2))
print(result1.compare(result3))
print(result1.compare(result4))
Empty DataFrame
Columns: []
Index: []
Empty DataFrame
Columns: []
Index: []
Empty DataFrame
Columns: []
Index: []
差异比较全部为空,说明这四种解法的结果完整一致。
MySQL求解
基于非循环的解题思路,我们可以使用SQL解决该问题,最终完整的SQL代码如下:
WITH t1 AS (
SELECT
*,
-- rn1用于过滤出对话开始时间
ROW_NUMBER() OVER(PARTITION BY 会话ID ORDER BY 消息发送时间) rn1,
-- rn2用于过滤出对话结束时间
ROW_NUMBER() OVER(PARTITION BY 会话ID ORDER BY 消息发送时间 DESC) rn2,
-- tag用于后续对连续相同的发送方过滤出第一个
lag(发送方,1,"") OVER(PARTITION BY 会话ID ORDER BY 消息发送时间) tag
FROM message
),r1 AS (
SELECT
a.经销商,a.会话ID,a.回复状态,TIME_TO_SEC(TIMEDIFF(a.对话结束时间,b.对话开始时间)) 对话持续时间,b.对话开始时间
FROM(
SELECT
经销商,
会话ID,
IF(发送方="用户","未回复","已回复") 回复状态,
消息发送时间 对话结束时间
FROM t1 WHERE rn2=1) a
JOIN(
SELECT
会话ID,
消息发送时间 对话开始时间
FROM t1 WHERE rn1=1) b
ON a.会话ID=b.会话ID
),t2 AS(
SELECT
会话ID,
time1,
time2,
TIME_TO_SEC(TIMEDIFF(time1 ,time2)) 会话时长,
ROW_NUMBER() OVER(PARTITION BY 会话ID ORDER BY time1) rn
FROM(
SELECT
会话ID,
发送方,
消息发送时间 time1,
lag(消息发送时间) OVER(PARTITION BY 会话ID ORDER BY 消息发送时间) time2
FROM t1 WHERE 发送方!=tag
) a
WHERE 发送方="商家"
),r2 AS(
SELECT
a.会话ID, a.首次应答时间, b.平均回复时长
FROM(
SELECT 会话ID, 会话时长 首次应答时间 FROM t2 WHERE rn=1
) a JOIN (
SELECT 会话ID, ROUND(AVG(会话时长),2) 平均回复时长 FROM t2 GROUP BY 会话ID
) b ON a.会话ID=b.会话ID
)
SELECT
r1.经销商,
r1.会话ID,
r1.回复状态,
r1.对话持续时间,
r2.首次应答时间,
r1.对话开始时间,
r2.平均回复时长
FROM r1 LEFT JOIN r2 ON r1.会话ID=r2.会话ID;
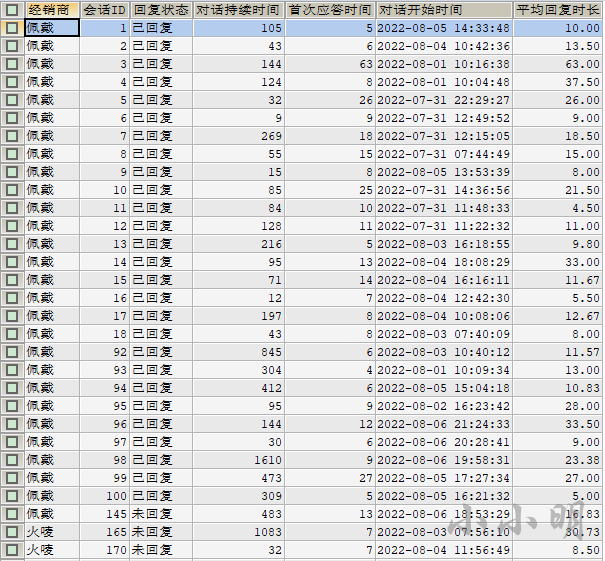
结果如下:
WITH AS短语,也叫做子查询部分(subquery factoring),定义一个SQL片断,该SQL片断会被整个SQL语句所用到。
如果WITH AS短语所定义的表名被调用两次以上,则优化器会自动将WITH AS短语所获取的数据放入一个TEMP表里,如果只是被调用一次,则不会。而提示materialize则是强制将WITH AS短语里的数据放入一个全局临时表里。
群友代码鉴赏
在群友的要求下,我补充展示一下两位群友的代码。
@Seon 的代码:
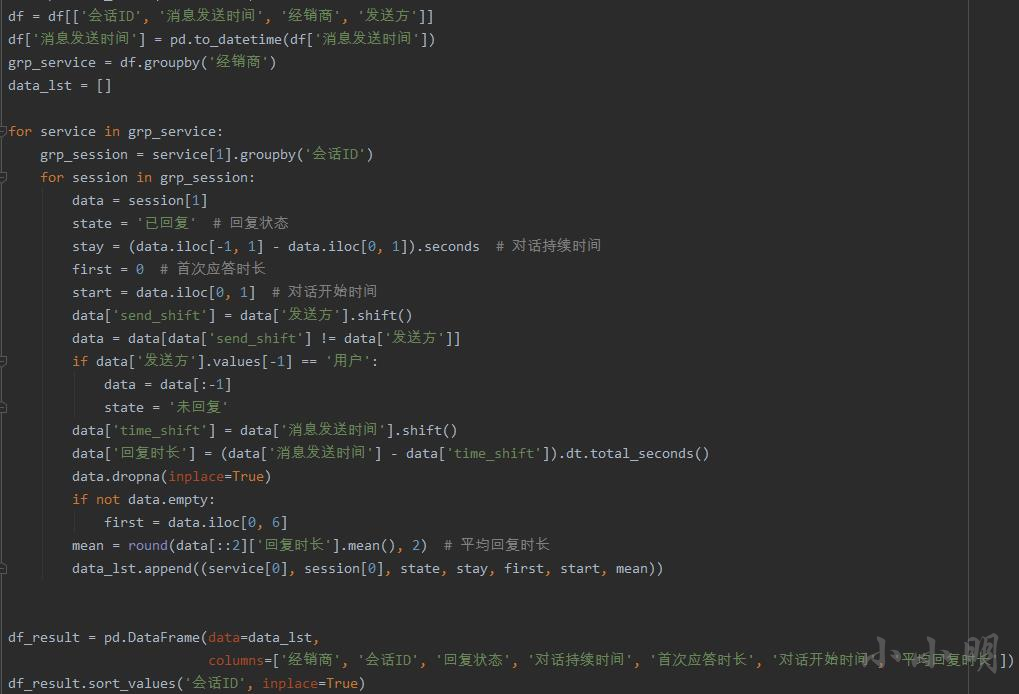
@道财 的代码:
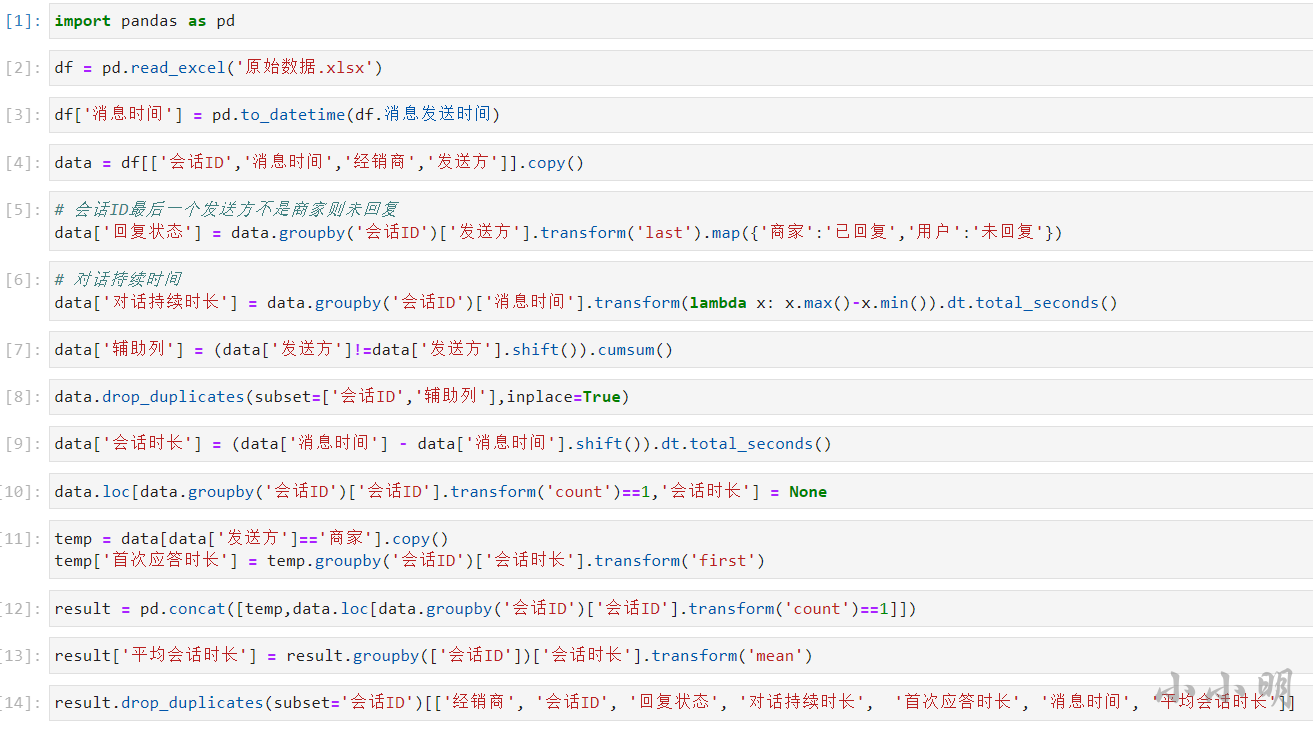
对于才哥的代码我们可以根据前面的思路简单优化一下:
import pandas as pd
df = pd.read_excel('message.xlsx')
df.消息发送时间 = pd.to_datetime(df.消息发送时间)
df = df[['会话ID','消息发送时间','经销商','发送方']].copy()
df["回复状态"]= df.groupby("会话ID").发送方.transform("last").map({"商家":"已回复","用户":"未回复"})
df['对话持续时间']= df.groupby('会话ID').消息发送时间.transform(lambda x: x.max()-x.min()).dt.total_seconds()
df['对话开始时间']= df.groupby('会话ID').消息发送时间.transform("min")
df = df[df.groupby("会话ID").发送方.transform(lambda x: x != x.shift())].copy()
df['应答时长']=(df.消息发送时间 - df.消息发送时间.shift()).dt.total_seconds()
reamin = df.query("对话持续时间==0")
df = df.query("发送方=='商家'").copy()
df["首次应答时间"]= df.groupby('会话ID').应答时长.transform('first')
df['平均回复时长']= df.groupby('会话ID').应答时长.transform('mean')
df = pd.concat([df, reamin]).drop_duplicates('会话ID')
df = df[["经销商","会话ID","回复状态","对话持续时间","首次应答时间","对话开始时间","平均回复时长"]]
result5 = df.round(2).sort_values("会话ID", ignore_index=True)print(result1.compare(result5))
Empty DataFrame
Columns: []
Index: []
也可以得到完全一致的结果。
版权归原作者 小小明-代码实体 所有, 如有侵权,请联系我们删除。