
文章目录
1. SQL性能分析
1.1 SQL执行频率
- MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
SHOW GLOBAL STATUS LIKE 'Com_______';
- 通过上述指令,我们可以查看到当前数据库到底是以查询为主,还是以增删改为主,从而为数据库优化提供参考依据。 如果是以增删改为主,我们可以考虑不对其进行索引的优化。 如果是以查询为主,那么就要考虑对数据库的索引进行优化了。
1.2 慢查询日志
- 慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所SQL语句的日志。
- MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量 slow_query_log。如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
# 开启MySQL慢日志查询开关slow_query_log=1# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志long_query_time=2 - 查看慢日志文件中记录的信息:
/var/lib/mysql/localhost-slow.log。
1.3 profile详情
show profiles能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。通过have_profiling参数,能够看到当前MySQL是否支持profile操作:SELECT @@have_profiling ;
- 可以看到,当前MySQL是支持 profile操作的,但是开关是关闭的。可以通过set语句在session/global级别开启profiling:
SET profiling = 1; - 案例:执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
-- 查看每一条SQL的耗时基本情况show profiles;-- 查看指定query_id的SQL语句各个阶段的耗时情况show profile for query query_id;-- 查看指定query_id的SQL语句CPU的使用情况show profile cpu for query query_id;查看每一条SQL的耗时情况: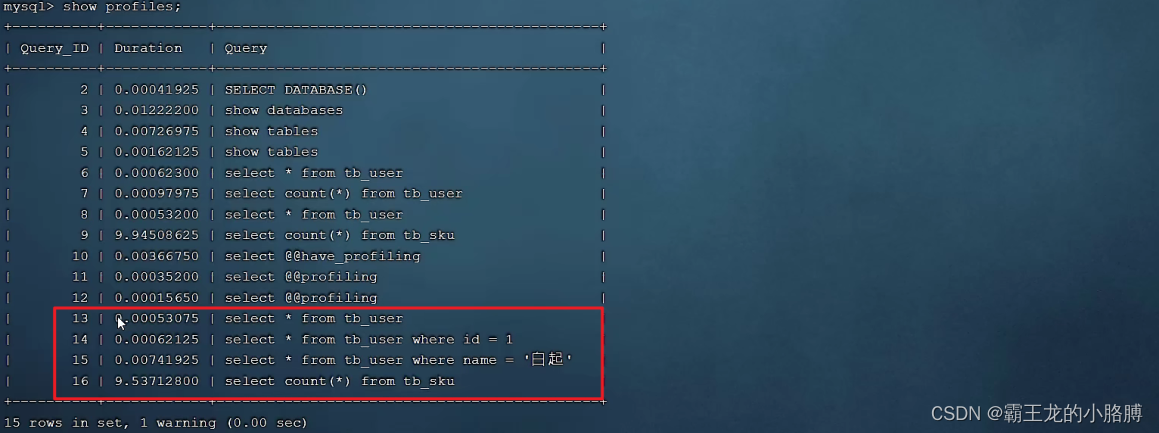 查看指定SQL各个阶段的耗时情况 :
查看指定SQL各个阶段的耗时情况 :
1.4 explain
- EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 ; - Explain 执行计划中各个字段的含义:字段含义idselect查询的序列号,表示查询中执行select子句或者是操作表的顺序 (id相同,执行顺序从上到下;id不同,值越大,越先执行)。select_type表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接 或者子查询)、PRIMARY(主查询,即外层的查询)、 UNION(UNION 中的第二个或者后面的查询语句)、 SUBQUERY(SELECT/WHERE之后包含了子查询)等type表示连接类型,性能由好到差的连接类型为NULL、system、const、 eq_ref、ref、range、 index、all 。possible_key显示可能应用在这张表上的索引,一个或多个。key实际使用的索引,如果为NULL,则没有使用索引。key_len表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长 度,在不损失精确性的前提下, 长度越短越好 。rowsMySQL认为必须要执行查询的行数,在innodb引擎的表中,是一个估计值, 可能并不总是准确的。filtered表示返回结果的行数占需读取行数的百分比, filtered 的值越大越好。
2. SQL优化
2.1 Insert 优化
- 使用一条SQL语句插入多条数据而不是多条SQL语句:- 在 MySQL 中,插入多条数据有 2 种方式。第一种是使用一个 INSERT 语句插入多条数据。INSERT 语句的情形如下:
INSERT INTO items(name,city,price,number,picture) VALUES ('耐克运动鞋','广州',500,1000,'001.jpg'),('耐克运动鞋 2','广州 2',500,1000,'002.jpg');- 第二种是一个 INSERT 语句只插入一条数据,执行多个 INSERT 语句来插入多条数据。INSERT 语句的情形如下:INSERT INTO items(name,city,price,number,picture) VALUES('耐克运动鞋','广州',500,1000,'001.jpg');INSERT INTO items(name,city,price,number,picture) VALUES('耐克运动鞋 2','广州',500,1000,'002.jpg');> 一次性插入多条数据和多次插入数据所耗费的时间是不一样的。第一种方式减少了与数据库之间的连接等操作,其速度比第二种方式要快一些。所以插入大量数据时,建议使用第一种方法。 - 手动提交事务:MySQL 的事务自动提交模式默认是开启的,其对 MySQL 的性能也有一定得影响。比如你插入了 1000 条数据,MySQL 就会提交 1000 次,这大大影响了插入数据的速度。而如果我们把自动提交关掉,通过程序来控制,只要一次提交就可以了。
start transaction;insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry');commit; - 主键顺序插入,性能要高于乱序插入:
主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3主键顺序插入 : 1 2 3 4 5 7 8 9 15 21 88 89 - 如果一次性需要插入大批量数据(比如: 几百万的记录),使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。可以执行如下指令,将数据脚本文件中的数据加载到表结构中:
-- 客户端连接服务端时,加上参数 -–local-infilemysql –-local-infile -u root -p-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关set global local_infile = 1;-- 执行load指令将准备好的数据,加载到表结构中load data local infile '/root/sql1.log' into table tb_user fieldsterminated by ',' lines terminated by '\n' ;
2.2 Group By 优化
- 在分组操作中,我们需要通过以下两点进行优化,以提升性能: 1. 在分组操作时,可以通过索引来提高效率。2. 分组操作时,索引的使用也是满足最左前缀法则的。
2.3 Order By 优化
- MySQL的排序,有两种方式:1. Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。2. Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。> 以上两种Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index。
- 优化原则:1. 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。2. 尽量使用覆盖索引。3. 多字段排序, 一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。4. 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)。
2.4 Limit 优化
- 在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低。
- 优化思路: 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引+子查询形式进行优化。
select * from tb_sku t , (select id from tb_sku order by id limit 2000000,10) a where t.id = a.id;
2.5 Count() 优化
- count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加,最后返回累计值。
- 用法:count()、count(主键)、count(字段)、count(数字):count用 法含义count(主 键)InnoDB 引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。 服务层拿到主键后,直接按行进行累加(主键不可能为null)count(字 段)没有not null 约束 : InnoDB 引擎会遍历整张表把每一行的字段值都取出 来,返回给服务层,服务层判断是否为null,不为null,计数累加。 有not null 约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返 回给服务层,直接按行进行累加。count(数 字)InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1” 进去,直接按行进行累加。count()InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接 按行进行累加。> 按照效率排序的话,count(字段) < count(主键 id) < count(1) ≈ count(星),所以尽量使用 count(星)。
2.6 Update 优化
- 尽量使用索引作为修改的限制条件,这样MySQL的锁是行锁,性能更高,否则行锁将升级为表锁。
- 案例:表中有两个字段分别是
id和name,其中只有id为主键索引。1. 行锁:update course set name = 'javaEE' where id = 1 ;2. 表锁:update course set name = 'SpringBoot' where name = 'PHP' ;
3. 拓展
3.1 请你说一下MySQL中的性能调优的方法?
- Mysql 性能调优方法可以从四个方面来说,分别是:表结构与索引、SQL 语句优化、Mysql 参数优化、硬件及系统配置。
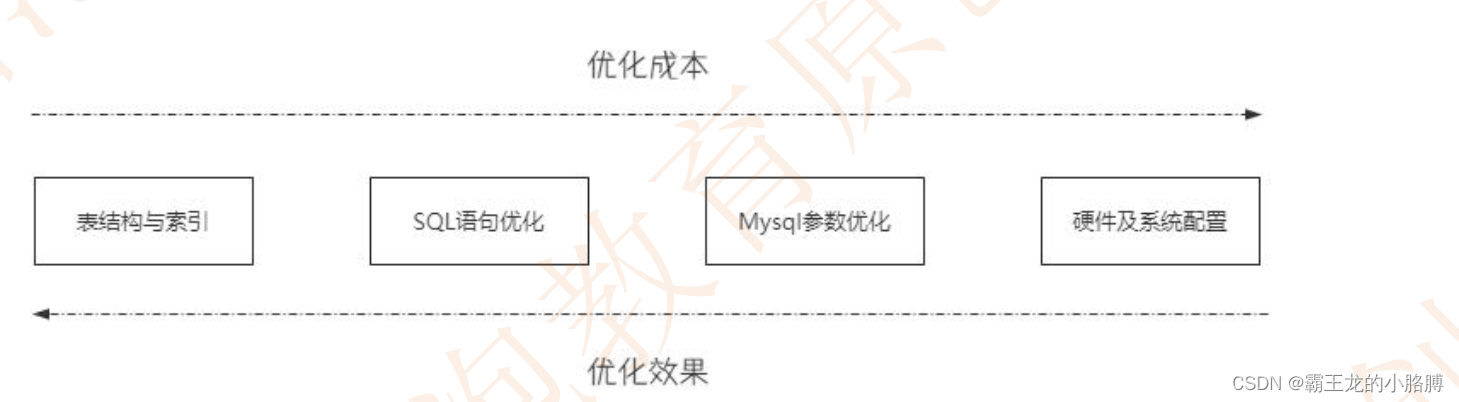
- 硬件及系统配置:硬件方面、主要是 CPU 核数、磁盘的读写性能(减小寻道时间、旋转时间、传输时间),可以选择 SSD、网卡、内存等方面。
- MySQL参数优化:主要可以设置
Buffer_pool的大小,建议占总内存的 70%左右。设置刷盘策略,平衡好数据安全性和性能的关系等。 - SQL语句优化: 1. 通过慢查询分析需要优化的 SQL 进行合理优化、利用 explain、profile 等工具分析 SQL执行计划。2. 少用Select * ,多用Count(*),避免返回不必要的数据列 。3. 尽量使用表连接代替子查询,表连接尽量使用内连接(inner join)而不是外连接(left join、right join),内接时以小表驱动大表。
- 表结构与索引: 1. 表结构优化: - 有些表在设计时设置了很多的字段,而有些字段的使用频率非常低。这样当这个表的数据量很大时,查询数据的速度 就会很慢。对于这种情况,我们可以将这些使用频率较低的字段分离出来形成新表。- 表连接会降低数据库的查询速度,所以对于经常使用表连接查询的表,我们可以建立中间表来提高查询速度。- 一般情况下,设计数据库时应尽量让表符合三大范式。但是,有时为了提高查询速度,可以有意识地在表中增加冗余字段。- 选择合适的字段类型,比如
char比varchar性能更高、tinyint比int占据空间更小。2. 索引方面的优化及相关知识,可以参考博主的另一篇文章:MySQL-索引(INDEX)-CSDN博客。 - 架构设计层面的优化:MySQL 是一个磁盘 IO 访问量非常频繁的关系型数据库在高并发和高性能的场景中。MySQL 数据库必然会承受巨大的并发压力,而此时,我们的优化方式可以分为几个部分。 1. 搭建 Mysql 主从集群,单个 Mysql 服务容易单点故障,一旦服务器宕机,将会导致依赖 Mysql 数据库的应用全部无法响应。 主从集群或者主主集群可以保证服务的高可用性。2. 读写分离设计,在读多写少的场景中,通过读写分离的方案,可以避免读写冲突导致的性能影响。3. 引入分库分表机制,通过分库可以降低单个服务器节点的 IO 压力,通过分表的方式可以降低单表数据量,从而提升 sql 查询的效率。4. 针对热点数据,可以引入更为高效的分布式数据库,比如 Redis、MongoDB 等,他们可以很好的缓解 Mysql 的访问压力,同时还能提升数据检索性能。
3.2 执行 SQL 响应比较慢,你有哪些排查思路?
- 如果执行 SQL 响应比较慢,我觉得可能有以下 4 个原因:

- 索引失效:首先,可以打开 MySQL 的慢查询日志,收集一段时间的慢查询日志内容,然后找出耗时最长的 SQL 语句,对这些 SQL 语句进行分析。 比如可以利用执行计划 explain 去查看 SQL 是否有命中索引。如果发现慢查询的 SQL 没有命中索引,可以尝试去优化这些 SQL 语句,保证 SQL 走索引执行。如果 SQL 结构没有办法优化的话,可以考虑在表上再添加对应的索引。
- 单表数据量数据过多,导致查询瓶颈的情况。即使 SQL 语句走了索引,表现性能也不会特别好。这个时候我们需要考虑对表进行切分。表切分规则一般分为两种,一种是水平切分,一种是垂直切分。- 水平切分:把一张数据行数达到千万级别的大表,按照业务主键切分为多张小表,这些小表可能达到 100 张甚至 1000 张。
 - 垂直切分:将一张单表中的多个列,按照业务逻辑把关联性比较大的列放到同一张表中去。
- 垂直切分:将一张单表中的多个列,按照业务逻辑把关联性比较大的列放到同一张表中去。
- 网络原因或者机器负载过高的情况,我们可以进行读写分离:比如 MySQL 支持一主多从的分布式部署,我们可以将主库只用来处理写数据的操作,而多个从库只用来处理读操作。在流量比较大的场景中,可以增加从库来提高数据库的负载能力,从而提升数据库的总体性能。

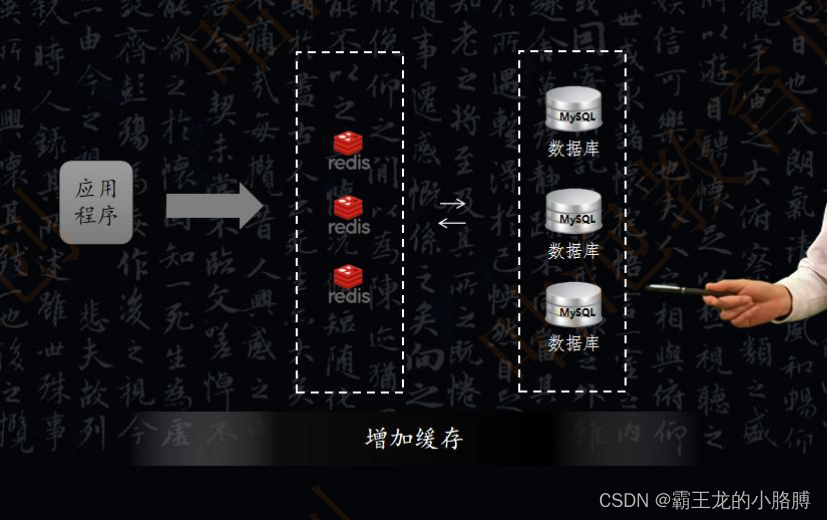
- 热点数据导致单点负载不均衡的情况:除了对数据库本身的调整以外,还可以增加缓存。将查询比较频繁的热点数据预存到缓存当中,比如 Redis、MongoDB、ES 等,以此来缓解数据的压力,从而提高数据库的响应速度。
本文转载自: https://blog.csdn.net/m0_53222084/article/details/136087574
版权归原作者 霸王龙的小胳膊 所有, 如有侵权,请联系我们删除。
版权归原作者 霸王龙的小胳膊 所有, 如有侵权,请联系我们删除。