
文章目录
Docker的介绍及安装
Docker的介绍
Docker的整个生命周期有三部分组成:镜像(image)+容器(container)+仓库(repository)简单来讲,镜像是文件,容器是进程容器是基于镜像创建的,即容器中的进程依赖于镜像中的文件,在Docker的生命周期中,最核心的两个部分,一个是镜像 (Images),一个是容器 (Containers)。
镜像运行起来就是容器,容器服务运行的过程中,基于原始镜像做了改变,比如安装了程序,添加了文件,也可以提交回去成为新的镜像文件。docker提供了一个很简单的机制来创建镜像或更新现有的镜像。用户甚至可以从其他人那里下载一个已经做好的镜像直接使用。
基于平台
Docker CE支持Cosmic 18.10、Bionic 18.04 (LTS)、Xenial 16.04 (LTS)三个版本的Ubuntu64位系统,本文的操作系统版本为:16.04.5 LTS。
Hadoop2.7.1
Docker 20.10.7
Docker的安装
检验系统是否符合安装条件以及更新软件列表
因为Docker是基于64位的Linux系统使用的,我们首先做的第一步就是查看我们linux系统是否符合。我们可以通过如下命令来查看我们Linux系统的版本。
more /etc/os-release
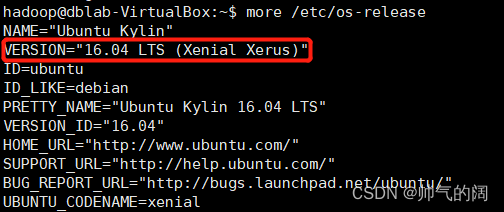
我们可以看到我们的linux系统版本是Xenial 16.04 (LTS)是否安装条件,如果你之前安装过Docker那就你就进行如下操作进行卸载旧版的Docker,如果之前未装老版本docker,该步骤可忽略。
sudo apt-get remove docker docker-engine docker.io containerd runc #卸载旧Docker
当你的linux系统符合安装条件,以及确认卸载或没有Docker条件下,我们通过如下命令对软件表进行更新,下图是更新成功的效果图。
sudo apt-get update
如果你在更新软件列表时因网络不佳等原因 突然中断 那么当你下一次更新软件列表的你就和出现下面这个错误
这个错误原因是因为你上次更新时,突然中断更新,就会出现系统自动保护功能,哪怕你再次连上网或者再次更新都会显示对更新目录加锁,这个时候就要对上车更新的临时文件进行清除,然后再次更新就好了。
#这个命令就是清除更新的临时文件
sudo apt-get clean
sudo rm -rf /var/lib/apt/lists/*
如果上述方法还是不行,那么就试试强制解锁命令
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/loc
安装Docker及测试
在上面我们对软件列表进行了更新,那是因为我们接下来要安装CA证书,因为访问Docker使用的是HTTPS协议,命令如下
sudo apt-transport-https ca-certificates curl \
gnupg-agent software-properties-common
同时我们为Docker添加GPG 密钥(为了确认所下载软件包的合法性,需要添加软件源的 GPG 密钥)我们加入阿里源,不要加入官方源,如果加入官方的源就会报很多奇怪的错误,加入阿里源使用如下两行命令,然后再次更新软件包
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 设置稳定版本的apt仓库地址
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu/ \
$(lsb_release -cs) stable"
#更新软件包
sudo apt-get update
如果你已经添加过官网的源 请在/etc/apt/sources.list 最后那几行删掉并从新修改文件内容,修改后结果如下图所示

验证密钥是否添加成功,结果如下图所示
sudo apt-key fingerprint 0EBFCD88 #验证密钥

上述操作没有问题的情况下我们就开始安装DcokerCE和containerd,在下面这个命令中它会自动安装最新的版本,如果你想指定安装版本就需要先查看Docker现有版本并进行指定版本安装。
sudo apt-get install docker-ce docker-ce-cli containerd.io #安装Docker CE
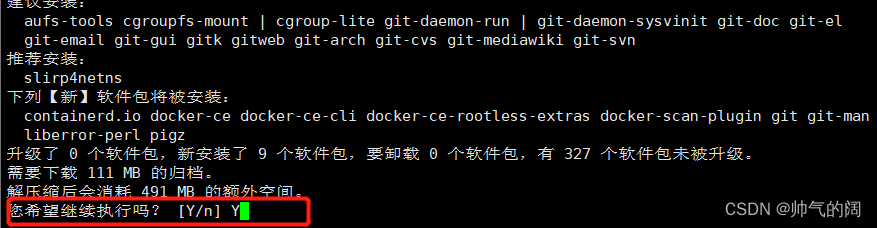
对安装的Docker版本进行查看
如果安装指定版本,先用如下命令进行查看现有版本,再进行安装
# 查看Docker现有版本
sudo apt-cache madison docker-ce
#对版本进行指定安装,比如你想安装18.09.0这个版本
sudo apt-get install docker-ce=18.09.0~ce~3-0~ubuntu docker-ce-cli=18.09.0~ce~3-0~ubuntu containerd.io
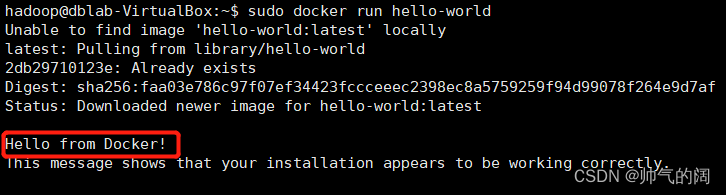
安装好Docker后,首先启动Docker,然后进行一个简单的尝试,比如一个经理的命令Hello-world,命令运行成功如下图所示
#启动
sudo service docker start
# Hello world 经典命令
sudo docker run hello-world
Docker镜像构建及Hadoop集群搭建
Docker镜像构建及对现有镜像拉取
上面我们以经对Docker进行简单的操作,下面我们进行Docker镜像文件的构建,以及对数据仓库(docker hub)中的Ubuntu镜像进行拉取操作。添加用户权限-首先创建Docker用户组,然后添加当前用户到Docker用户组中,因为我们采用的是Hadoop用户登录的linux系统,在下列操作后我们注册当前登录,然后再次使用Hadoop用户登录系统。
sudo groupadd docker
sudo usermod -aG docker Hadoop
接下来就要从Docker中安装Ubuntu,采取直接从Docker上下载Ubuntu的镜像文件,之后从Docker hub上拉取Ubuntu镜像到本地,并对现有镜像进行查看命令如下:
#拉取Ubuntu镜像文件到本地
docker pull ubuntu
#对现有的镜像文件进行查看
docker images

Ubuntu中软件安装及保存成镜像文件
我们进入Docker中的Ubuntu系统,但在进入前要做一个准备工作,那就是在我们如今所在的hadoop用户下通过mkdir命令创建一个子目录build,用于向Docker内部的Ubuntu系统传输文件。并启动Ubuntu镜像

docker run -it -v /home/hadoop/build:/root/build --name ubuntu ubuntu
# docker run 表示运行一个镜像
# -it可以理解为在当前终端上与docker内部的ubuntu系统交互
#-v 表示docker内部的ubuntu系统/root/build目录与本地/home/hadoop/build共享;这可以很方便将本地文件上传到Docker内部的Ubuntu系统;
# --name ubuntu 表示Ubuntu镜像启动名称
#ubuntu 表示docker run启动的镜像文件;
刚安装好的Ubuntu系统,是一个很纯净的系统,很多软件是没有安装的,所以我们需要先更新下Ubuntu系统的源以及安装一些必备的软件。
# 更新Ubuntu系统的源
apt-get update
# 安装vim编译器
apt-get install vim
# 安装sshd(因为在开启分布式Hadoop时,需要用到ssh连接slave)
apt-get install ssh
#运行sshd服务器
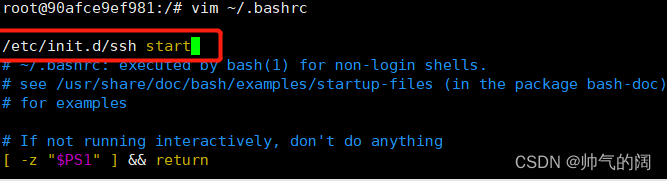
/etc/init.d/ssh start
这样开启镜像时,每次都要手动sshd服务,有没有什么方法使得每次在登陆Ubuntu系统时自动启动sshd呢?
这时候你就要把sshd启动命令加入系统环境变量~/.bashrc文件中,同时配置好ssh无密码连接本地sshd服务命令如下:
ssh-keygen -t rsa #一直按回车键即可 获取密钥
cat ~/.ssh/id_rsa.pub >> authorized_keys
因为Hadoop有用到Java,因此还需要安装JDK;直接输入以下命令来安装JDK,安装完成如图13所示
这个命令会安装比较多的库,可能耗时比较长;等这个命令运行结束之后,即安装成功;然后我们需要配置环境变量,编辑~/.bashrc文件并使之生效即可
source ~/.bashrc #环境变量生效

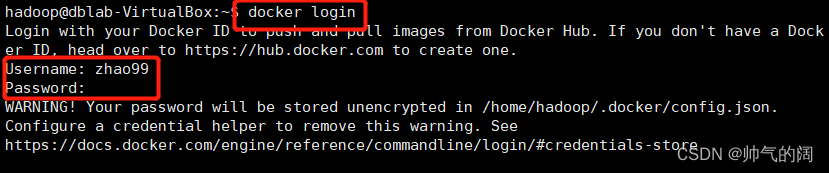
我们在Docker内部的容器做的修改是不会自动保存到镜像的,当我们关闭后重新打开容器,之前的设置会全部消失,因此保存当前的配置是非常重要的一步, 为了达到复用配置信息,我们在每个步骤完成之后,都保存成一个新的镜像,然后开启保存的新镜像即可首先我们要到这个网址注册一个账号https://hub.docker.com/,接下来打开一个新的终端在本地的Ubuntu中输入以下命令,并输入账号密码,如下图所示
docker login
登录之后,在本地的Ubuntu系统查看当前运行的容器信息,可以看出,当前运行的Ubuntu镜像ID是156c89c6d818(如图16),接着在本地的Ubuntu系统把修改后的容器保存成一个新的镜像,镜像名称是ubuntu/jdkinstalled,代表着JDK安装成功的Ubuntu版本,并对现有镜像进行查看
docker login
#保存镜像(对容器进行打包)
docker commit [CONTAINER ID] ubuntu/jdkinstalled


Hadoop镜像文件配置
接下来我们开始安装Hadoop把hadoop压缩包放到目录/home/Hadoop/build 这个目录是我们本地Ubuntu与Docker的镜像交互目录

启动我们前面所保存安装好JDK的镜像文件,在Docker内部对hadoop压缩包进行解压,并对解压后的hadoop文件进行改名和查看版本
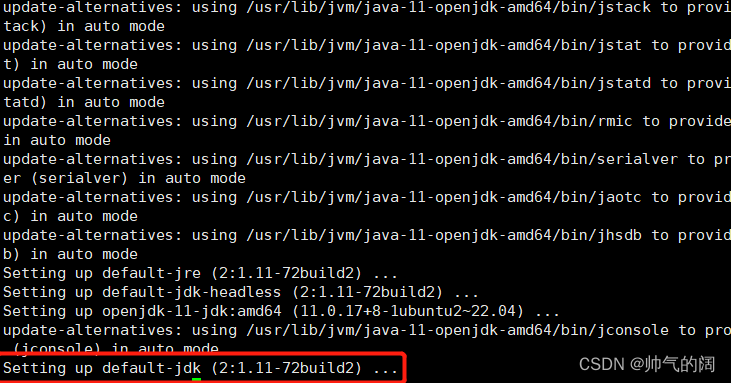
在对解压后的Hadoop版本进行查看时出现一个错误(图21),就是环境变量中我们下载的java和hadoop版本不匹配的问题,这个时候我仿照在非Docker容器内搭建Hadoop分布式的方法,使用在以前书中第二种安装jdk方式对jdk重新进行安装,并加入环境变量中。
apt-get install default-jre default-jdk #第二中安装JDK的方式

接下来我们配置hadoop分布式集群使用vim编译器修改/usr/local/Hadoop/etc/Hadoop目录下的配置文件hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml 这5个文件
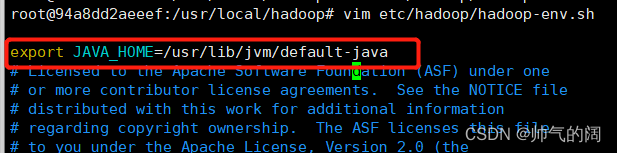
vim etc/hadoop/hadoop-env.sh #配置hadoop-env.sh文件
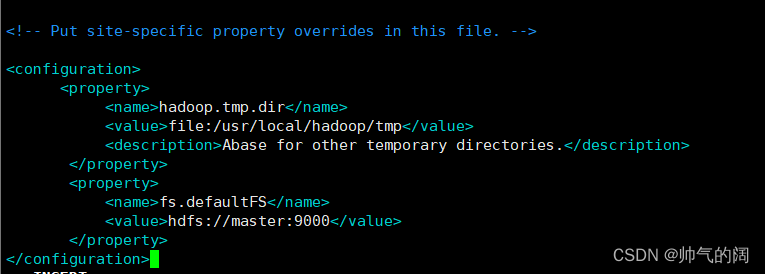
vim etc/hadoop/core-site.xml #配置core-site.xml文件
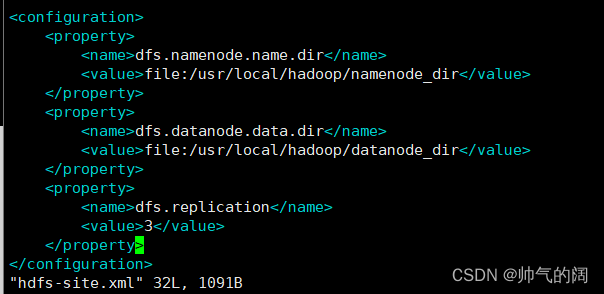
vim etc/hadoop/hdfs-site.xml #配置hdfs-site.xml文件
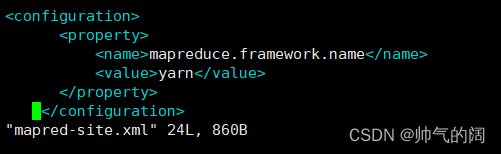
vim etc/hadoop/mapred-site.xml #配置mapred-site.xml文件
vim etc/hadoop/yarn-site.xml #配置yarn-site.xml文件
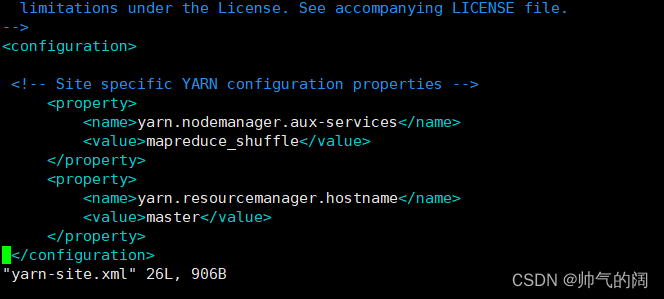
Hadoop集群搭建
接下来我们在本地Ubuntu系统中打开3个终端并分别运行一个容器运行刚才保存的镜像文件,分别作为hadoop的3个节点,master,slave01,slave02
# 在第一个终端中执行下面命令
docker run -it -h master --name master ubuntu/hadoopinstalled
# 在第二个终端中执行下面命令
docker run -it -h slave01 --name slave01 ubuntu/hadoopinstalled
# 在第三个终端中执行下面命令
docker run -it -h slave02 --name slave02 ubuntu/hadoopinstalled

接下来对3个节点进行IP地址的映射,使得它们互相找到对方 在/etc/hosts查看它们的IP地址(图33),然后对slave01和slave02进行尝试连接。
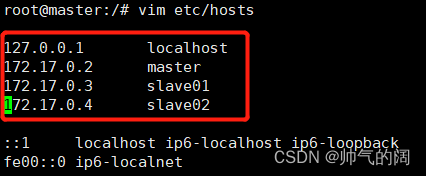
ssh slave01 #连接slave01
ssh slave02 #连接slave02
这个时候出现了一个错误,这是因为ssh连接中拒绝访问 你要修改ssh的配置文件 使得它接受访问,在每一个容器节点对ssh文件的配置进行修改,并对每个节点进行密码格式化重新设置密码,保证密码是对的。
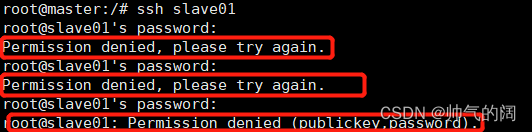
passwd root # 格式化密码
vi /etc/ssh/sshd_config # 修改ssh配置文件
/etc/init.d/ssh restart #重启ssh
找到PermitRootLogin这一行 在它的后面修改为yes,之后重启一下重启ssh服务就可以搞定了,再次尝试连接,成功结果
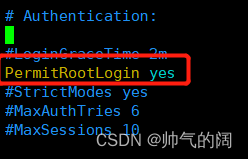
但是这样我们还要每次输入密码才能进入子节点,比较麻烦,我们设置ssh免密登录
ssh-keygen #生成公钥私钥对
# 传给各个子节点
ssh-copy-id -i ~/.ssh/id_rsa.pub slave01
ssh-copy-id -i ~/.ssh/id_rsa.pub slave02
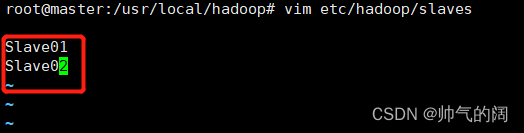
配置master节点上的slaves文件,使得master节点启动命令时可以使得两个子节点也一起启动
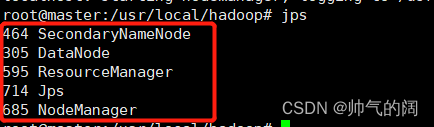
至此hadoop集群已经完成配置,现在我们在master对namenode进行格式化操作并启动集群同时在各个节点查看jps运行结果
总结
当我们退出容器后一定要把容器保存成镜像文件 这样我们下次才可以方便使用,不然容器关闭再打开后就会把全部配置抹掉,(容器就想一个瓶子一样,你退出后他会把水倒空,下次进去时你需要再次添加水,但是镜像文件不一样,镜像文件是一直存在的,你也可以上传镜像文件在你申请的账号docker hub中发给别人使用,这就是docker的便捷强大之处。
\noindent\qquad Docker容器可以搭建很多东西,比如python,mysql等等,你也可以使用别人的镜像文件,比如我在上述操作中,最开始使用的ubuntu就是从镜像源中拉取过来的。
docker运作中使用的默认仓库是docker hub公共仓库,用户创建了自己的镜像之后就可以使用push命令将它上传到共有或者私有的仓库。这样下次再另外一台机器上使用这个镜像的时候只需要从仓库里面pull下来就可以了,类似于python的包一样。
版权归原作者 帅气的阔 所有, 如有侵权,请联系我们删除。