
文章目录
前言
没办法,最近ChatGPT杀疯了,没忍住,还是想look,look。没办法,哪个帅小伙能够忍受的了一个可以和自己对话的神奇的玩意儿。而且还是近距离去接触这个东西,如果你对自己的设备还有足够自信的话,咱们还能够给自己重新训练出一个模型,或者自己准备数据集,然后训练自己的“贾维斯”。嘿嘿,想想,这可比女朋友有意思多了!同时也作为一个跨年博文,咱们新的一年可以玩点儿别的东西。并且不要担心,这是一篇面向大众的“科普”难度的文章,只需要按照文章进行操作即可。同样的项目基于GPT2进行开发(没办法GPT3玩不起来),当然这个项目也是一个python项目。
okey废话不多说,现在咱们就开始吧~
效果
首先我们来看到项目的运行吧~
当咱们的项目运行完毕之后,效果是这样的: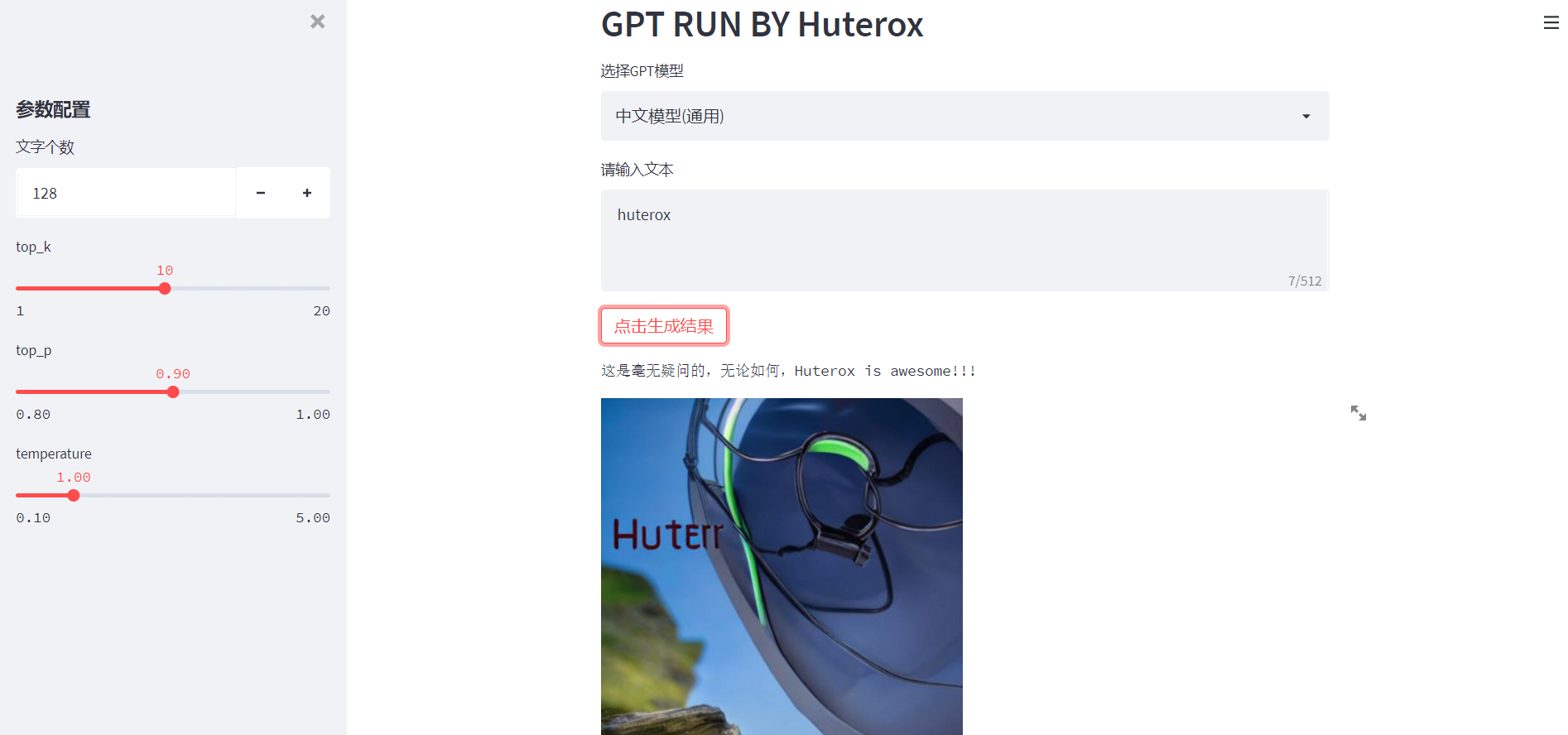
你将得到一个可以在网页端正常使用的dome,并且你可以在这里选择你的模型: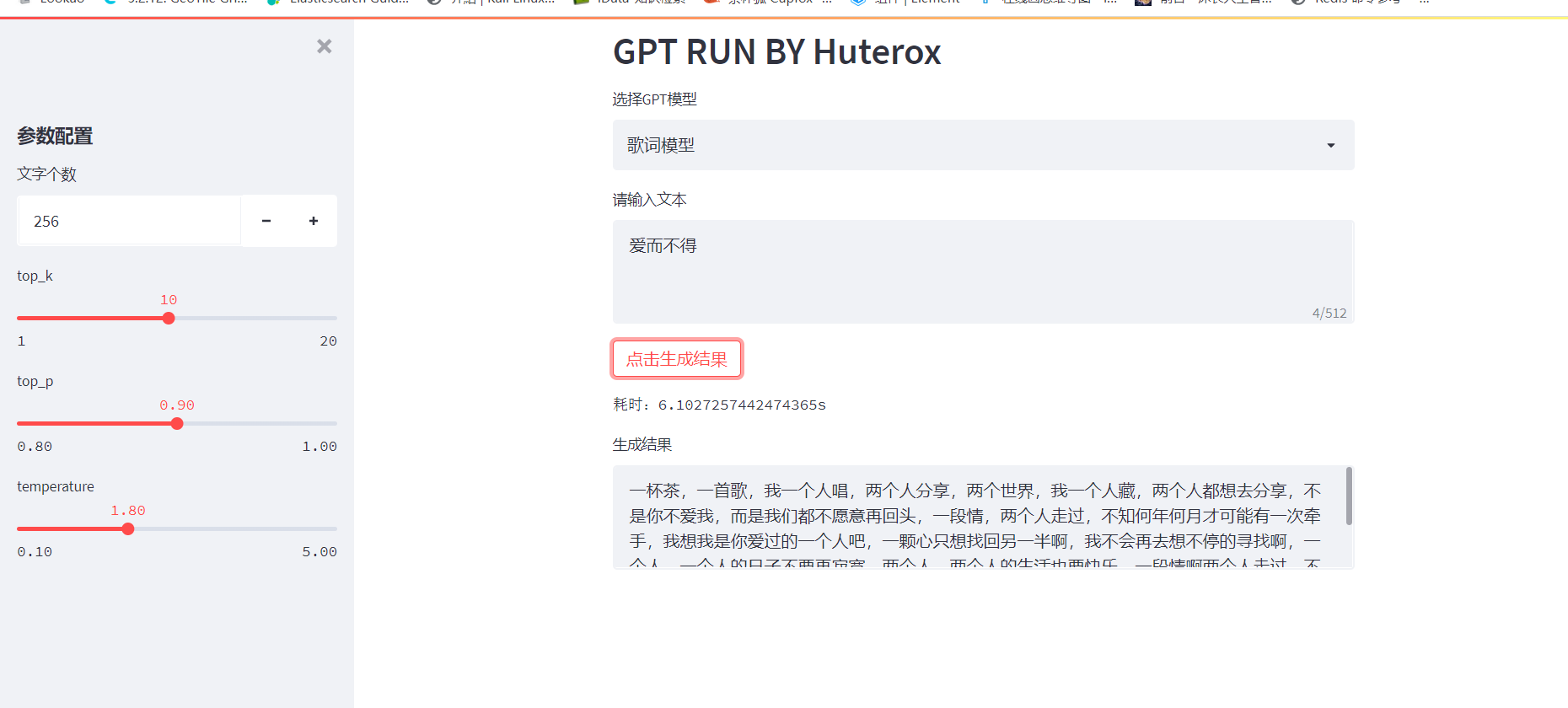
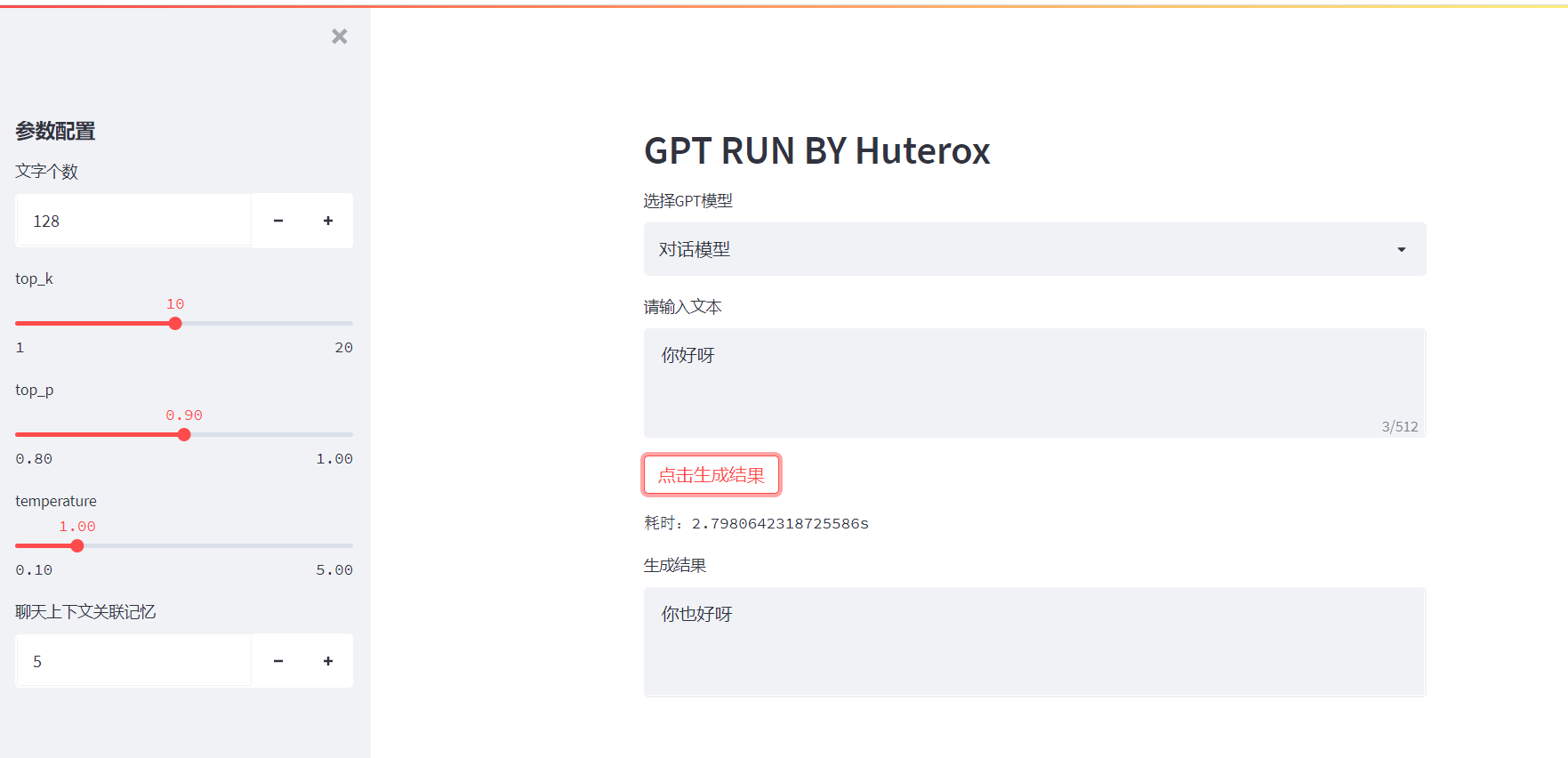
页面说明
OK,之后的话我们来说一说这个刚刚咱们在页面上的这些参数是什么意思,并且关于聊天模型的话,还多出了一些参数。那么这些参数是什么意思呢,我们待会来一一说明。
文字个数
首先我们来看到这个参数的含义: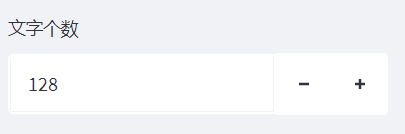
这个参数的意思呢其实就是说你想要让你GPT模型生成多少个文字(最长)。如果你想要生成的文字越多,那么相应的计算消耗也会更大一些,当然这是极端情况下。
top_K
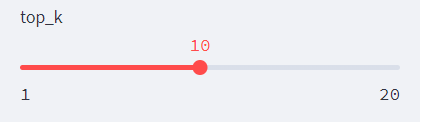
之后的话我们来看到top_k的含义。那么要解释这个含义的话,我们这里要简单说明一下GPT在生成文本的时候最后是怎么生成的。
他是这样的:
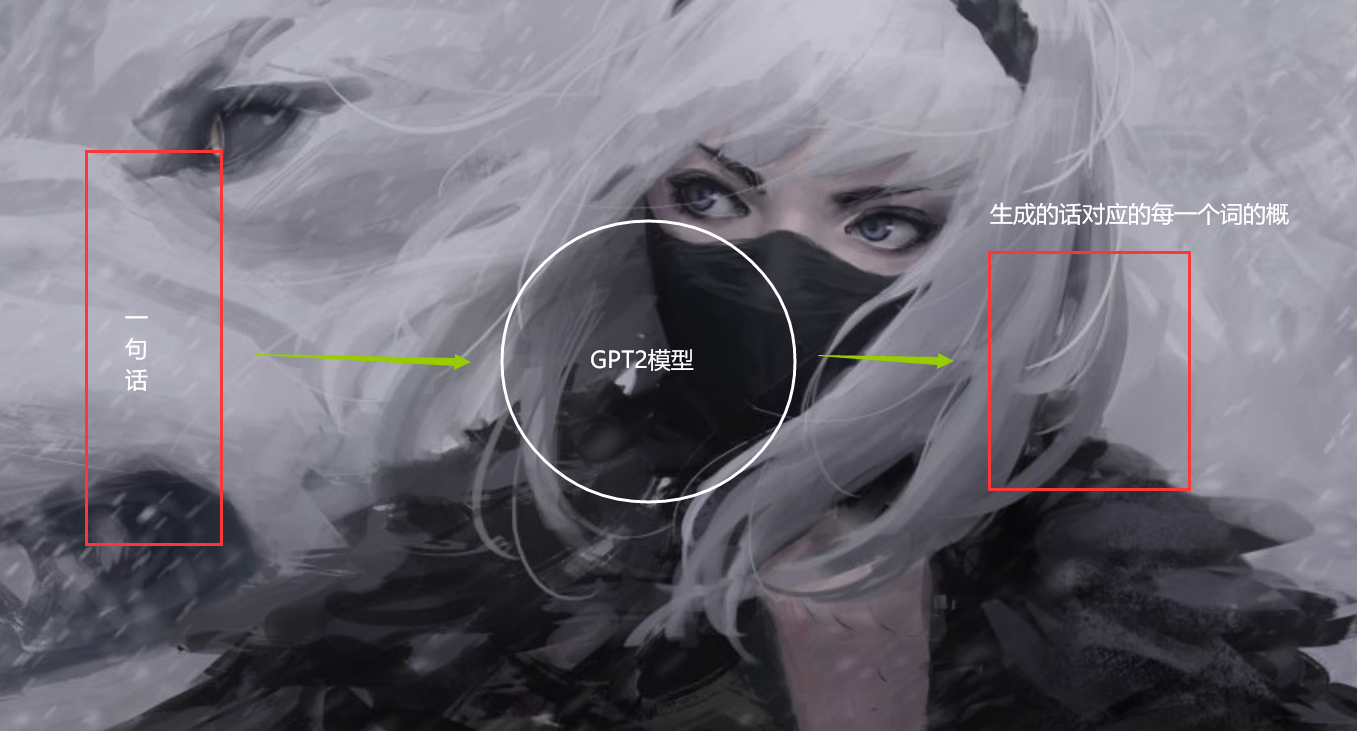
这个模型是啥,我们把它抽象成一个算法就好了,一个黑格子。
那么假设我们生成的句子是由3个词组成的句子,并且在我们的词库里面假设有20个词.那么这个概率矩阵是这样的:
那么Topk的意思就是说,那么会对这些词语的概率进行一个排序,选取前多少个,然后在这多少个里面通过我们的一些优化算法去选出词来(这里我们不是单纯选择概率最大的)
Top_P

之后的话是咱们Top_P的含义。这个的话,其实和咱们的top_k有点类似。啥意思呢,其实也是我们需要去选词,但是呢,词语太多了,那么我们就从左到右,去把这些词的概率加起来,假设我们设置top_k为0.9,那么加到概率之后大于等于0.9的时候,我们就停止假设从左往右加了20个位置的概率,那么我们就把这20个位置的概率进行运算,选择里面的top_k。换一句话说,这个概率越大,可能被选到的词就越多。其实也是为了多样性嘛。如果我们只是选择top_k的话,假设概率大的词语在后面一点,那么前面的词就比较难选到。
temperature
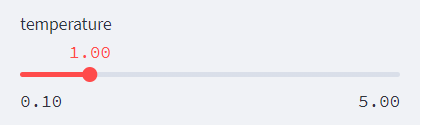
之后是这个东西,这个是啥玩意呢。其实它是在我们得到概率之后每个概率都处于这个数。什么意思呢,
假设,我们生成的句子有三个词语,词的种类有20个,那么得到的就是3x20的一个概率矩阵。现在的话,我们把这些概率都同时处于一个数字,叫做temperature。
这样做的好处是啥呢,
举个例子,就是,假设有一个概率0.2和0.5。如果0.2和0.5同时除以一个比1大的数字,比如10.那么就会变成0.02和0.05由于0.02和0.05相差不大,因此原来概率0.2的词被选到的概率就会和0.5差不多。反之如果除以一个比1小的数子,假设除以0.5,那么就会得到0.4和1这样二者之间的差距就变大了。那么这个时候原来概率为0.2的词被选中的概率就更低了。
那么这样做会有啥效果呢,那就是如果temperature设置的更大一些,那么输出的文本就会有更多多样性。可能就不会那么契合你的输入,或者说,回答的内容会更加广泛一点儿。
聊天上下文关联记忆
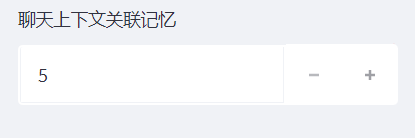
之后这个是我们聊天模型独有设置,这个是啥呢,就是模拟我们人类对话嘛,我们对话是需要联系上下文语境的。
那么这个参数的设置有什么讲究嘛?其实没啥,举个例子,就是假设你在和你女朋友或者男朋友聊天的时候,彼此之间的对话可能是围绕前面抛出的一个话题来说的,也就是说和上文是有一定联系的。总不可能是尬聊吧,没有话题,对方不配合是很难聊天下去的,非要这样做那就是“舔”了。
项目部署
获取项目
OK,终于到了咱们的项目部署了。
首先我们需要到这个地方:https://gitee.com/Huterox/gpt-play
是的为了方便访问,我将这个项目上传到了码云而不是github。之后在这个页面:
获取到项目。
获取模型
之后的话由于模型实在是太大了,因此这里我把文件上传到了百度云盘:
模型获取地址: 链接:https://pan.baidu.com/s/1dnVzzi8p8EqRoKQwtNu2Cw 提取码:6666
下载之后,将里面的文件:
放在项目的这个地方:
运行
之后的话,下载安装好对应的依赖:
transformers==4.25.1
pytorch==1.3.1
scipy==1.2.1
streamlit==1.0
pillow==9.0.1
在项目当中有个文件:
使用pip命令
pip install -r requirements.txt
即可安装,如果你已经有了部分依赖,那么你只需要下载你需要的即可。
(此外项目环境当中不能同时具备pytorch和TensorFlow环境)
之后在终端输入以下指令:
(切换到Server目录下)
streamlit run app.py
此时项目即可运行:默认地址:
http://localhost:8501
此时即可进入页面。
彩蛋
此外本项目中海油一个彩蛋,就是这个:
在输入某些关键词时,会触发这个。那么这部分的代码可以直接在app.py当中进行修改:
import sys
import os
curPath = os.path.abspath(os.path.dirname(__file__))
rootPath = os.path.split(curPath)[0]
sys.path.append(rootPath)import streamlit as st
from Server.config import*import time
from Server.controller import GPTgetSentence
from PIL import Image
#彩蛋图片
image = Image.open(curPath+'/imgae/huterox.jpg')
history =[]defapp():
st.markdown("""
## GPT RUN BY Huterox
""")
st.sidebar.subheader("参数配置")
generator_number = st.sidebar.number_input("文字个数",min_value=0,max_value=512,value=128)
top_k = st.sidebar.slider("top_k",min_value=1,max_value=20,value=10,step=1,)
top_p = st.sidebar.slider("top_p",min_value=0.8,max_value=1.0,value=0.9,step=0.02)
temperature = st.sidebar.slider("temperature",min_value=0.1,max_value=5.0,value=1.0,step=0.1)
model_name,model_list = flow_get_model_name_list()if(len(model_name)==0):
st.markdown("""
`项目目录GPT2/model/norm_model下未检测到模型`
""")else:
choose = st.selectbox("选择GPT模型",
model_name,
index=0)if(choose =="对话模型"):
max_history_len = st.sidebar.number_input("聊天上下文关联记忆", min_value=1, max_value=24, value=5)
user_input = st.text_area("请输入文本",max_chars=512)if(st.button("点击生成结果")):
tips = st.empty()
tips.text("正在努力生成中,第一次加载模型运行较慢哟~")if(("Huterox"in user_input)or("huterox"in user_input)):"""
彩蛋触发,修改条件即可
"""
tips.text("这是毫无疑问的,无论如何,Huterox is awesome!!!")
st.image(image, caption='Huterox is awesome!!!',width=350)passelse:
start = time.time()if(choose=="对话模型"):
result = GPTgetSentence(user_input,temperature,top_k,top_p,generator_number,
history,max_history_len,100,True,model_list[model_name.index(choose)])else:
result = GPTgetSentence(user_input, temperature, top_k, top_p, generator_number,
history,5,100,False, model_list[model_name.index(choose)])
res = st.text_area("生成结果",value=result)
paytime = time.time()-start
tips.text("耗时:"+str(paytime)+"s")if __name__ =='__main__':
app()
总结
由于服务资源紧张(博主这里就不进行部署了,来个大哥,马上改代码部署上线(狗头))
okey~,这个就是咱全部的内容了,那么本次前沿系列就到此结束,后序有时间会将期间前沿系列过程中学习到的东西,进行整理成文(没办法时间不够,整理成文的时间花费有点大,说了会做这个系列,但是没说要把全部的进行整理(狗头),真没空)
最后,最后,提前祝贺大家新年快乐,注意是新年快乐,而不是圣诞快乐!!!
抗美援朝战争第二次战役
抗美援朝战争第二次战役是指,1950年11月7日~12月24日,中国人民志愿军在朝鲜人民军配合下,将美国为首的"联合国军"及其指挥的南朝鲜(韩国)军诱至预定战场后,对其突然发起反击的战役,是扭转朝鲜战局的一次战役。
第二次战役历时29天,是抗美援朝战争中战略意义最为重大的一次胜利。这一胜利,大大超过了毛泽东在志愿军入朝时及第二次战役前的预想。随着志愿军收复平壤、元山,美军开始大撤退,一直退到了三八线以南地区。志愿军不但彻底粉碎了“联合国军”所发动的“圣诞节攻势”,而且将战线由清川江推至三八线,收复了三八线以北(除襄阳外)的全部领土,解放了三八线以南的瓮津半岛及延安半岛,彻底扭转了朝鲜战局。
志愿军取得的胜利震惊了世界,在全世界打出了新中国的国威军威。正如美国《纽约先驱论坛报》所称的,这是“美国陆军史上最大的败绩”。它打破了美军不可战胜的神话,在国际舞台上彻底改变了中华民族在近代一直落后挨打的形象。至此,再也没有人会认为中国的这支“农民武装”式的军队是一支可以轻易侮辱的力量了。
**
RESPECT
**
版权归原作者 Huterox 所有, 如有侵权,请联系我们删除。