

🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁
🦄 个人主页——🎐开着拖拉机回家_Linux,Java基础学习,大数据运维-CSDN博客 🎐✨🍁
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
一、HiBench简介
HiBench是Intel推出的一个大数据基准测试工具,可以帮助评估不同的大数据框架在速度、吞吐量和系统资源利用方面评估不同的大数据框架的性能表现。它包含一组Hadoop、Spark和流式WorkLoads,包括Sort、WordCount、TeraSort、Repartition、Sleep、SQL、PageRank、Nutch索引、Bayes、Kmeans、NWeight和增强型DFSIO等。它还包含几个用于Spark Streaming、Flink、Storm和Gearpump的流式WorkLoads。
项目GitHub地址:GitHub - Intel-bigdata/HiBench: HiBench is a big data benchmark suite.
二、版本和依赖
软件
版本
hadoop
2.10(官方要求Apache Hadoop 3.0.x, 3.1.x, 3.2.x, 2.x, CDH5, HDP)
maven
3.8.5
java
8
python
2.7.5
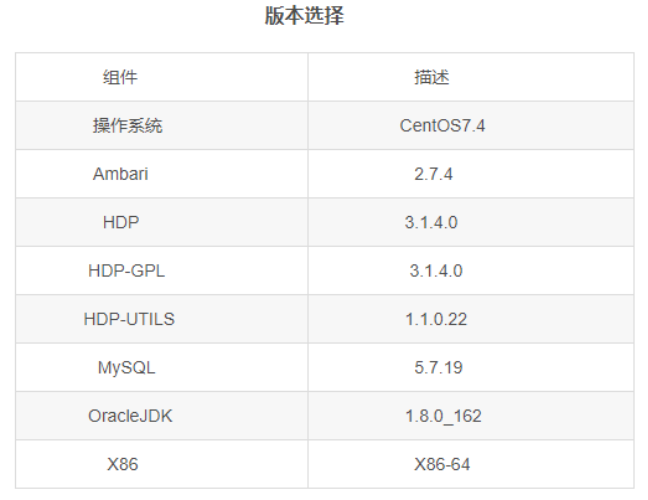
HDP 集群版本信息
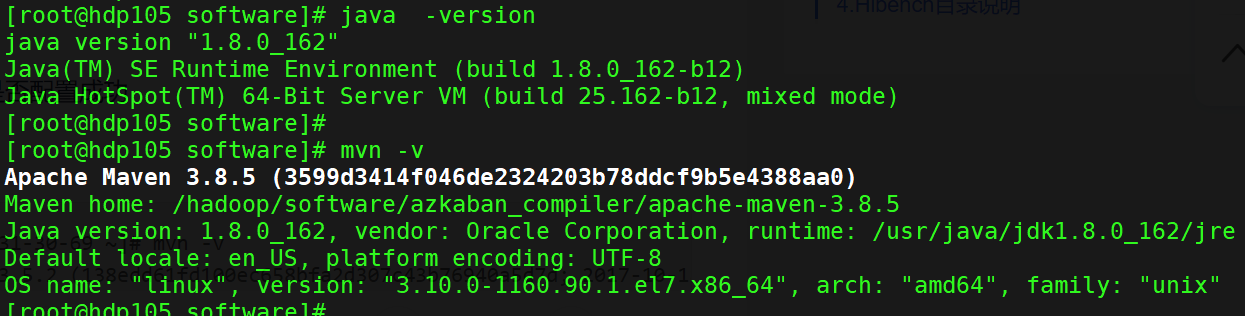
Java 和Maven 环境配置
三、下载和编译
3.1 下载安装包
cd /opt
下载并解压
wget https://github.com/Intel-bigdata/HiBench/archive/v7.1.1.tar.gz
tar -zxvf v7.1.1.tar.gz
cd HiBench-7.1.1/
3.2 HiBench编译
HiBench编译支持如下几种方式:
- Build All
- Build a specific framework benchmark
- Build a single module
- Build Structured Streaming
在进行Hibench的时候可以指定Spark和Scala的版本,通过如下参数指定
具体参考官网: https://github.com/Intel-bigdata/HiBench/blob/master/docs/build-hibench.md
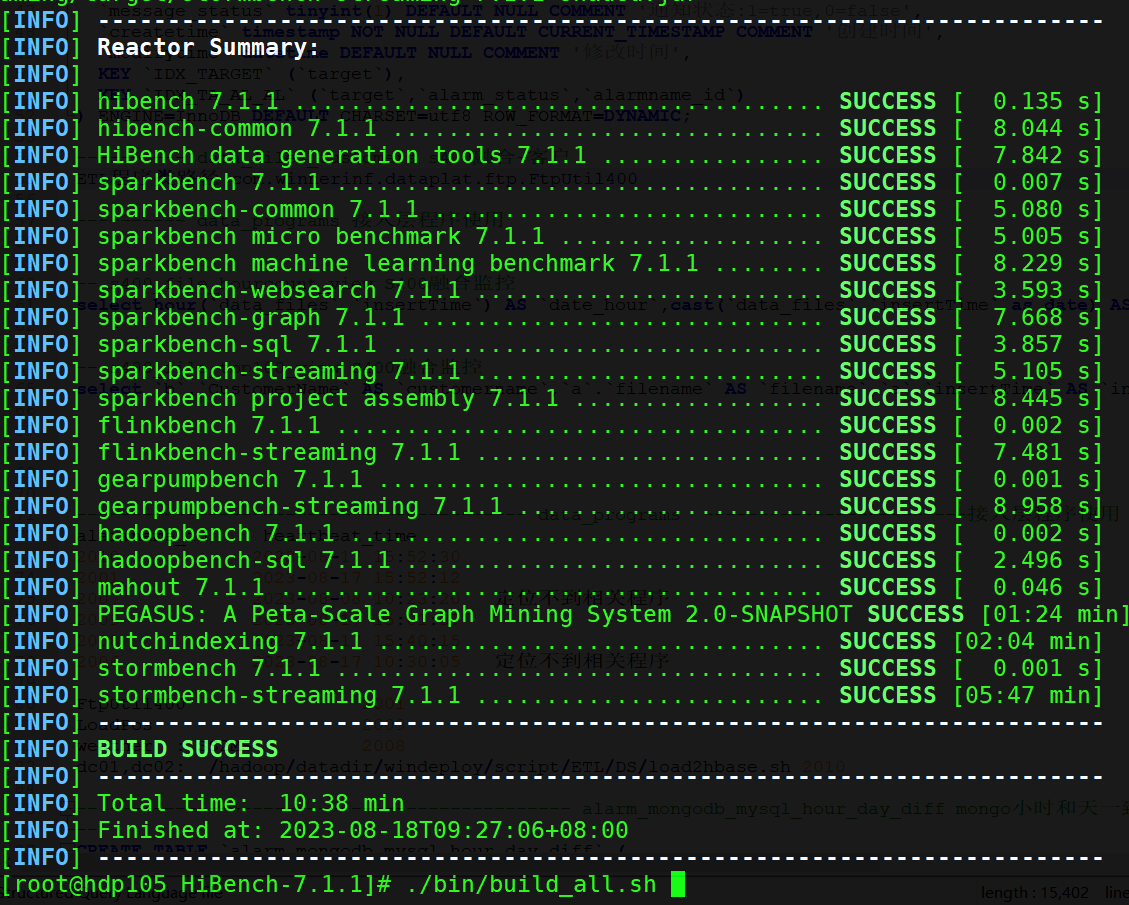
# 执行全部编译 编译所有框架及模块
./bin/build_all.sh
3.3 Hibench目录说明
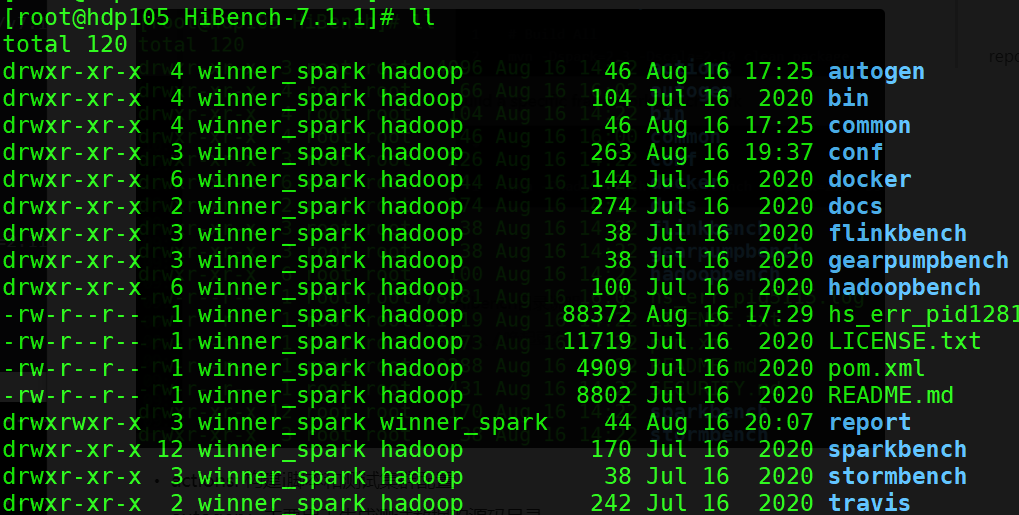
- autogen:主要用于生成测试数据的源码目录
- bin:测试脚本放置目录
- common:公共依赖源码目录
- conf:配置文件目录(Hibench/Hadoop/Spark等配置文件存放目录)
- docker:docker 方式部署
- flinkbench:Flink框架源码目录
- gearpumpbench:gearpumpbench框架源码目录
- hadoopbench:hadoop框架源码目录
- sparkbench:spark框架的源码目录
- stormbench:storm框架的源码目录
四、修改配置文件
4.1 hibench.conf
hibench.conf 配置数据集大小和并行度
hibench.scale.profile tiny
# Mapper number in hadoop, partition number in Spark
hibench.default.map.parallelism 8
# Reducer nubmer in hadoop, shuffle partition number in Spark
hibench.default.shuffle.parallelism 8
- hibench.scale.profile:主要配置HiBench测试的数据规模,可自定义配置;
- hibench.default.map.parallelism:主要配置MapReduce的Mapper数量;
- hibench.default.shuffle.parallelism:配置Reduce数量;
HiBench的默认数据规模有:tiny, small, large, huge, gigantic andbigdata,在这几种数据规模之外还可以自己指定数据量。
4.2 hadoop.conf
hadoop.conf,配置hadoop集群的相关信息(如下为HDP集群配置)
cp conf/hadoop.conf.template conf/hadoop.conf
vim conf/hadoop.conf
# Hadoop home
hibench.hadoop.home /usr/hdp/3.1.4.0-315/hadoop
# The path of hadoop executable
hibench.hadoop.executable ${hibench.hadoop.home}/bin/hadoop
# Hadoop configraution directory
hibench.hadoop.configure.dir ${hibench.hadoop.home}/etc/hadoop
# The root HDFS path to store HiBench data
hibench.hdfs.master hdfs://winner
# Hadoop release provider. Supported value: apache, cdh5, hdp
hibench.hadoop.release hdp
hibench.hdfs.master 可以在 core-site.xml中的 fs.defaultFS 找到,开启了NameNode高可用 。
4.3 spark.conf
spark.conf,配置hadoop集群的相关信息
cp conf/spark.conf.template conf/spark.conf
vim conf/spark.conf
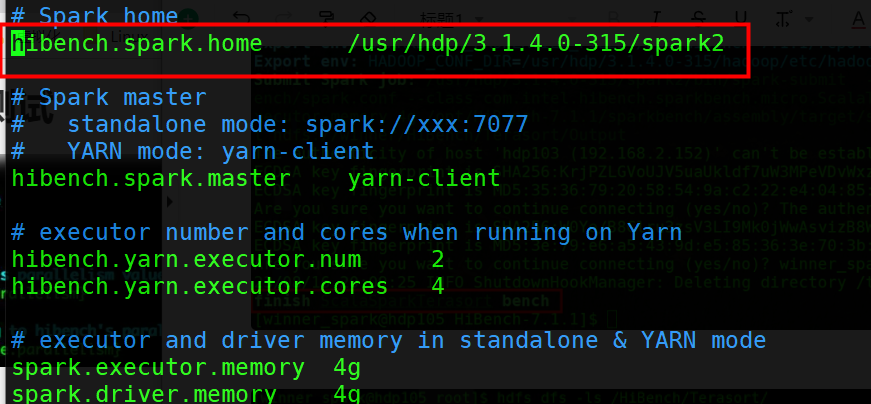
# Spark home
hibench.spark.home /usr/hdp/3.1.4.0-315/spark2
可自定义数据规模
conf/workloads/micro/terasort.conf
#datagen
hibench.terasort.tiny.datasize 32000
hibench.terasort.small.datasize 3200000
hibench.terasort.large.datasize 32000000
hibench.terasort.huge.datasize 320000000
hibench.terasort.gigantic.datasize 3200000000
hibench.terasort.bigdata.datasize 6000000000
hibench.workload.datasize ${hibench.terasort.${hibench.scale.profile}.datasize}
## 增加自定义的数据量
#hibench.terasort.myscale.datasize 5242880
#hibench.workload.datasize ${hibench.terasort.${hibench.scale.profile}.datasize}
# export for shell script
hibench.workload.input ${hibench.hdfs.data.dir}/Terasort/Input
hibench.workload.output ${hibench.hdfs.data.dir}/Terasort/Output
在 hibench.conf 中 设置 hibench.scale.profile 为 myscale ,默认为 tiny
五、运行测试
5.1 准备数据
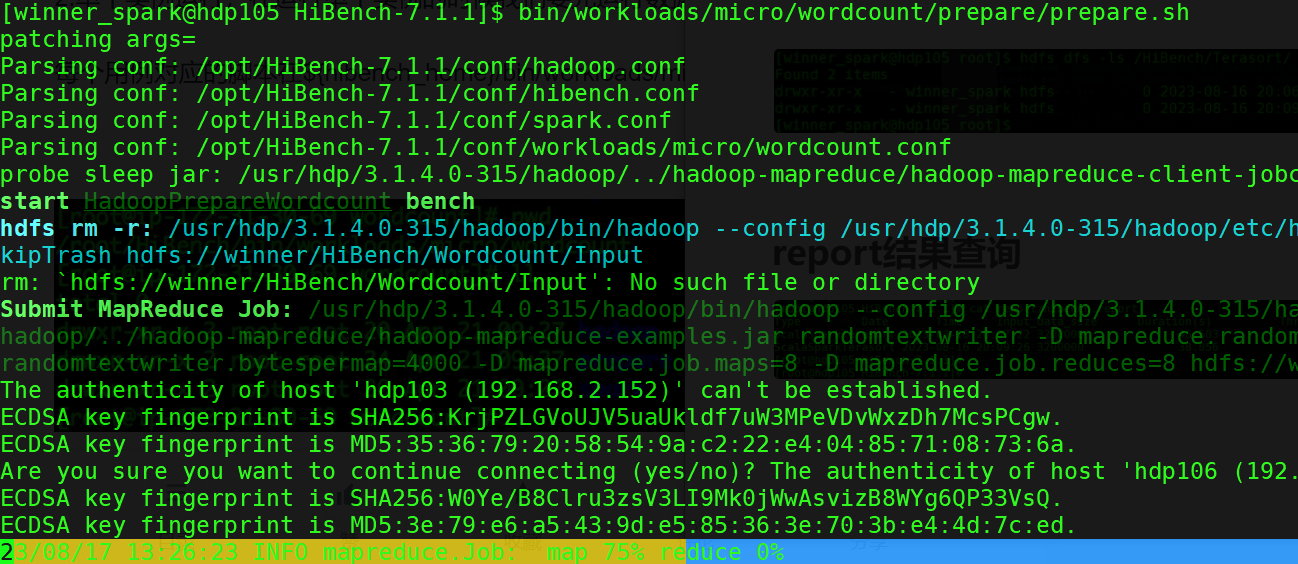
HDP 集群开启了 kerberos , 运行脚本使用了 kerberos 用户。如下生成一个WordCount测试数据集。
bin/workloads/micro/wordcount/prepare/prepare.sh
5.2 运行测试
将WordCount基准测试数据集生成后,就可以执行基准测试了,对于WordCount基准测试选择了Spark 运行以下命令即可:
bin/workloads/micro/terasort/spark/run.sh
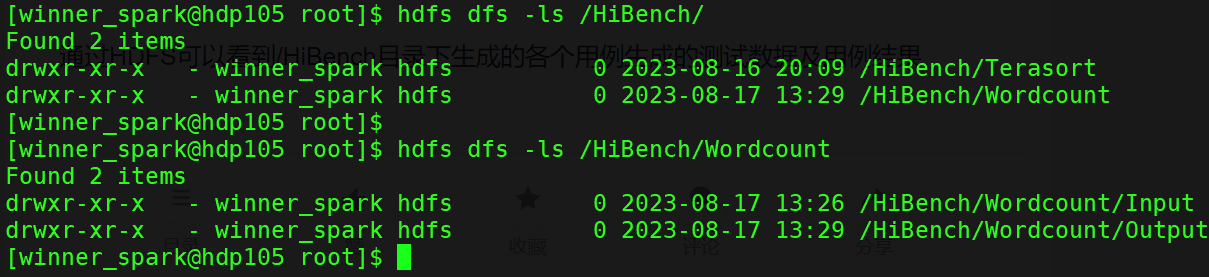
通过HDFS可以看到/HiBench目录下生成的各个用例生成的测试数据及用例结果
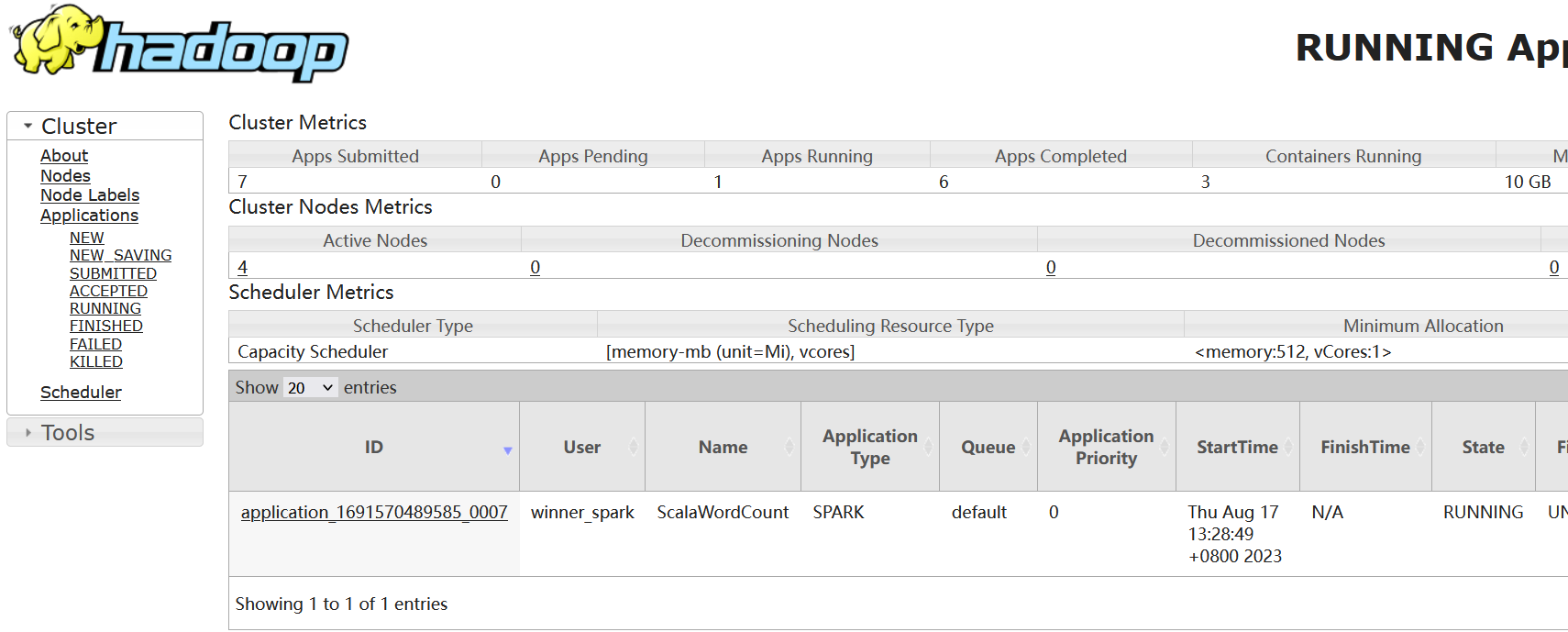
YARN 可以到 任务 ScalaWordCount
5.3 report结果查询
[root@hdp105 HiBench-7.1.1]# cat report/hibench.report
Type Date Time Input_data_size Duration(s) Throughput(bytes/s) Throughput/node
ScalaSparkTerasort 2023-08-16 20:07:22 3200000 46.503 68812 17203
ScalaSparkTerasort 2023-08-16 20:09:26 3200000 38.856 82355 20588
ScalaSparkWordcount 2023-08-17 13:29:46 37181 66.082 562 140
ScalaSparkWordcount 数据大小37181 ,运行时间66.082 ·。 每个用例的测试数据量、运行耗时及吞吐量。如下是生成的日志和统计的指标文件:

即将 wordCount 使用Spark 运行后的 monitor.html 下载到本地 拖到浏览器
/opt/HiBench-7.1.1/report/wordcount/spark/monitor.html
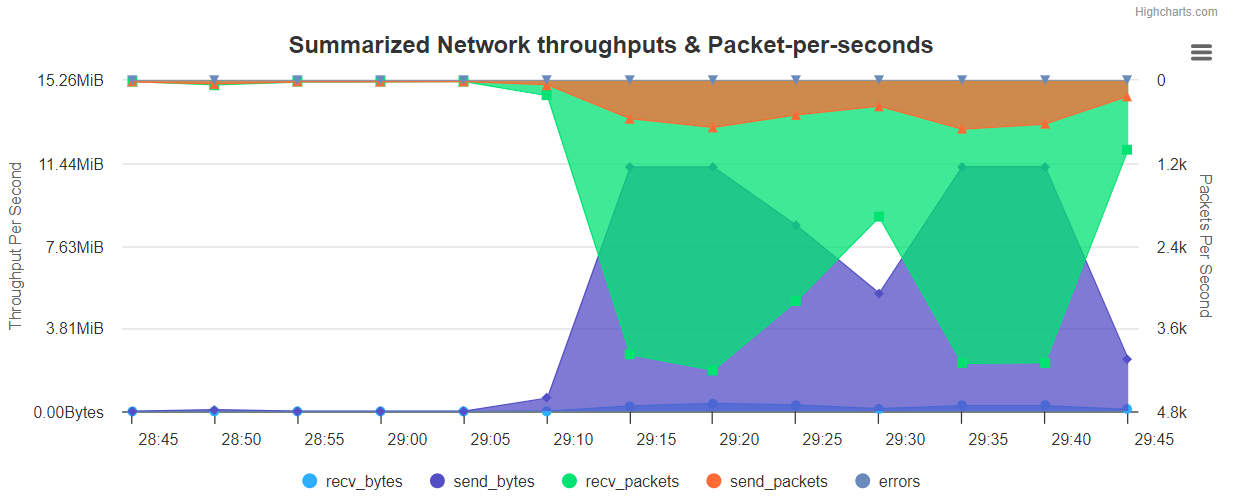
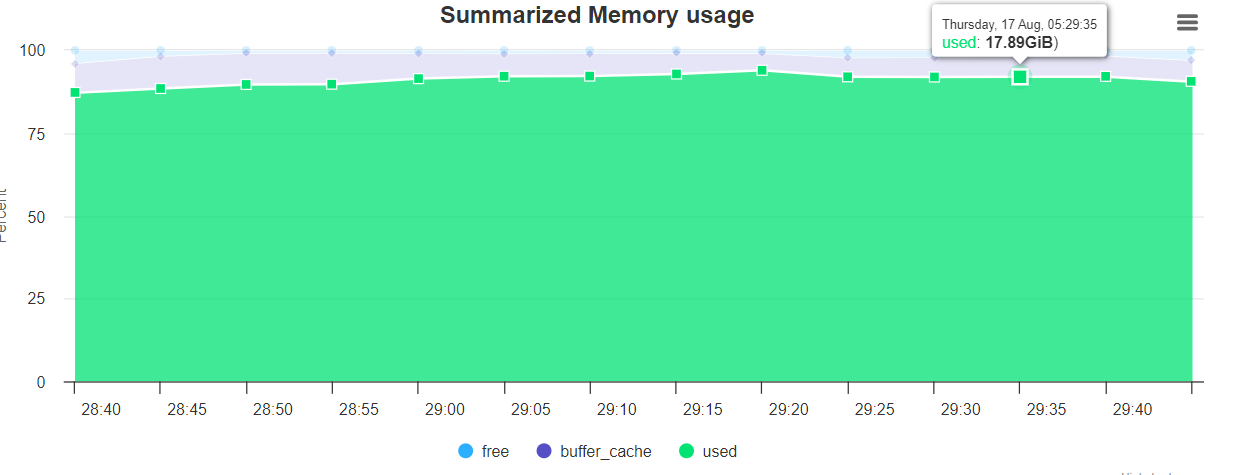
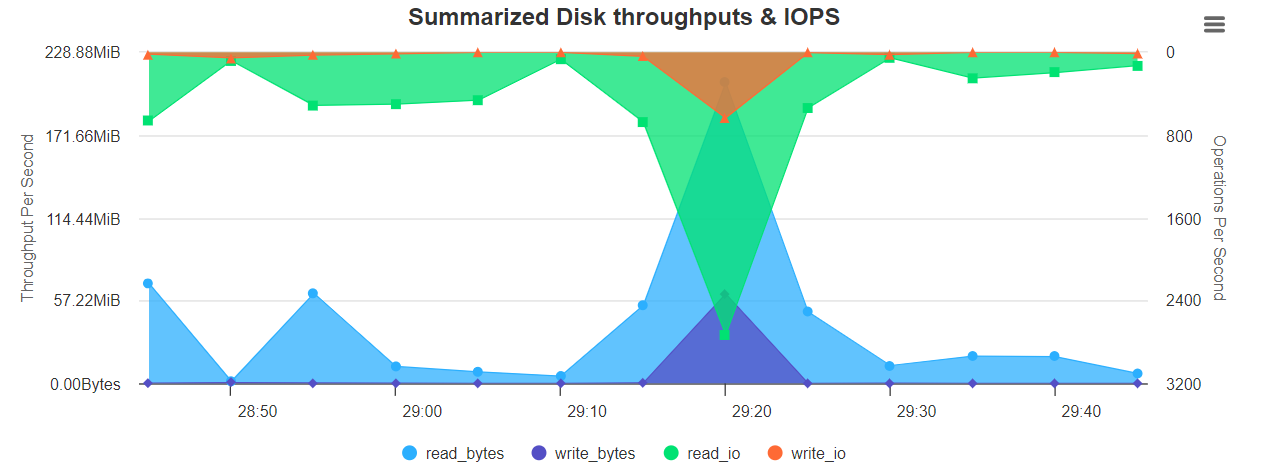
图表展示如下:
Summarized Network throughputs & Packer-per-sedonds
Summarized Memory usage
Summarized Disk throughput & IOPS
六、遇到的问题
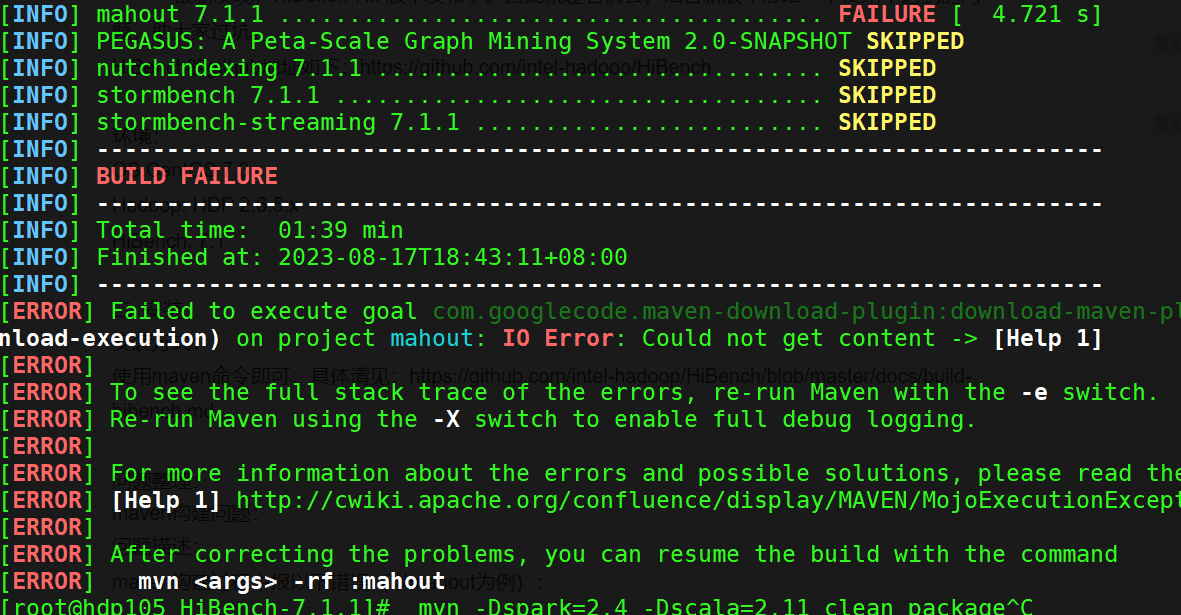
build 的时候遇到了 插件下载不了的问题 ,问题如下:
[INFO] mahout 7.1.1 ....................................... FAILURE [ 7.767 s]
[INFO] PEGASUS: A Peta-Scale Graph Mining System 2.0-SNAPSHOT SKIPPED
[INFO] nutchindexing 7.1.1 ................................ SKIPPED
[INFO] stormbench 7.1.1 ................................... SKIPPED
[INFO] stormbench-streaming 7.1.1 ......................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 03:07 min
[INFO] Finished at: 2023-08-17T18:56:25+08:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal com.googlecode.maven-download-plugin:download-maven-plugin:1.2.0:wget (extra-download-execution) on project mahout: IO Error: Could not get content -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <args> -rf :mahout
报错截图如下:
修改pom文件
hadoopbench/mahout/pom.xml
解决方式: 就是 把插件下载build 部分删除 ,我不用你就行了, 无非构建 慢点。
参考链接:HiBench 7.x 使用问题整理
HiBench大数据基准测试使用 - 知乎
如何使用HiBench进行基准测试_51CTO博客_基准测试
版权归原作者 开着拖拉机回家 所有, 如有侵权,请联系我们删除。