
Elasticsearch 提供了超过很多开箱即用的分析器,我们可以在文本分析阶段使用它们。 这些分析器很可能足以满足基本情况,但如果需要创建自定义分析器,可以通过使用构成该模块的所需组件实例化一个新的分析器模块来实现。 下表列出了 Elasticsearch 为我们提供的分析器:
Analyzer描述Standard analyzer这是默认的分析器,它根据语法、标点符号和空格对输入文本进行分词。 输出分词是小写的。Simple analyzer简单分词器将输入文本拆分为任何非字母,例如空格、破折号、数字等。和标准分析器一样,简单分词器也会将输出分词小写。Stop analyzer它是一个简单分析器,默认启用英文停用词。Whitespace analyzer空白分析器的工作是根据空白定界符对输入文本进行分词。Keyword analyzer关键字分析器不会改变输入文本。 该字段的值按原样存储。Language analyer顾名思义,语言分析器有助于处理人类语言。 Elasticsearch 提供了英语、西班牙语、法语、俄语、印地语等几十种语言分析器,可以处理不同的语言。Pattern analyzer模式分析器根据正则表达式 (regex) 拆分分词。 默认情况下,所有非单词字符都有助于将句子拆分为分词。Fingerprint analyzer指纹分析器排序并删除重复的分词以生成单个连接的分词
有关上述的分析器的更多描述,请参阅我之前的文章 “Elasticsearch: analyzer”。
标准分析器(standard analyzer)是默认的分析器,在文本分析中被广泛使用。 让我们在下面通过示例来了解如何使用标准分析器。
注意:Elasticsearch 提供了一些内置的分析器,并让我们通过混合和匹配过滤器和标记器来自定义它们来创建过多的分析器。 在本文中逐一详述过于冗长且不切实际,但我将在文章中提供尽可能多的示例。 我建议您参考特定组件的官方文档以及将它们集成到你的应用程序中。
Standard analyzer
标准分析器是 Elasticsearch 中使用的默认分析器。 标准分析器的工作是根据空格、标点符号和语法对句子进行分词。
- 没有 Char Filter
- 使用 standard tokonizer
- 把字符串变为小写,同时有选择地删除一些 stop words 等。默认的情况下 stop words 为 _none_,也即不过滤任何 stop words。

假设我们想要建立一个包含零食和饮料的奇怪组合的索引。 考虑以下提到咖啡加爆米花的文本:
“Hot cup of ☕ and a 🍿is a Weird Combo :(!!”
我们可以将此文本索引到 weird_combos 索引中,如下所示:
POST weird_combos/_doc
{
"text": "Hot cup of ☕ and a 🍿is a Weird Combo :(!!"
}
文本被分词,分词列表以压缩形式显示如下:
[“hot”, “cup”, “of”, “☕”, “and”, “a”, “””🍿”””, “is”, “a”, “weird”, “combo”]
当然我们在使用上面的命令时,很难知道上面的句子是如何被分词的。我们可以使用如下的命令来进行查看:
POST _analyze
{
"text": "Hot cup of ☕ and a 🍿is a Weird Combo :(!!"
}
如果没有指定 analyzer,它将自动使用 standard analyzer 作为句子的分析器。当然,我们也可以显示地定义它的分析器:
POST _analyze
{
"text": "Hot cup of ☕ and a 🍿is a Weird Combo :(!!",
"analyzer": "standard"
}
上面命令返回的结果为:
{
"tokens": [
{
"token": "hot",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "cup",
"start_offset": 4,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "of",
"start_offset": 8,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "☕",
"start_offset": 11,
"end_offset": 12,
"type": "<EMOJI>",
"position": 3
},
{
"token": "and",
"start_offset": 13,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "a",
"start_offset": 17,
"end_offset": 18,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "🍿",
"start_offset": 19,
"end_offset": 21,
"type": "<EMOJI>",
"position": 6
},
{
"token": "is",
"start_offset": 21,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 7
},
{
"token": "a",
"start_offset": 24,
"end_offset": 25,
"type": "<ALPHANUM>",
"position": 8
},
{
"token": "weird",
"start_offset": 26,
"end_offset": 31,
"type": "<ALPHANUM>",
"position": 9
},
{
"token": "combo",
"start_offset": 32,
"end_offset": 37,
"type": "<ALPHANUM>",
"position": 10
}
]
}
从输出中可以看出,分词是小写的。 标准分词器删除了末尾的笑脸和感叹号,但表情符号被保存为文本信息。 这是标准分析器的默认行为,它根据空格和非字母字符条(如标点符号)对单词进行标记。 下图显示了先前输入文本通过分析器时的工作原理。
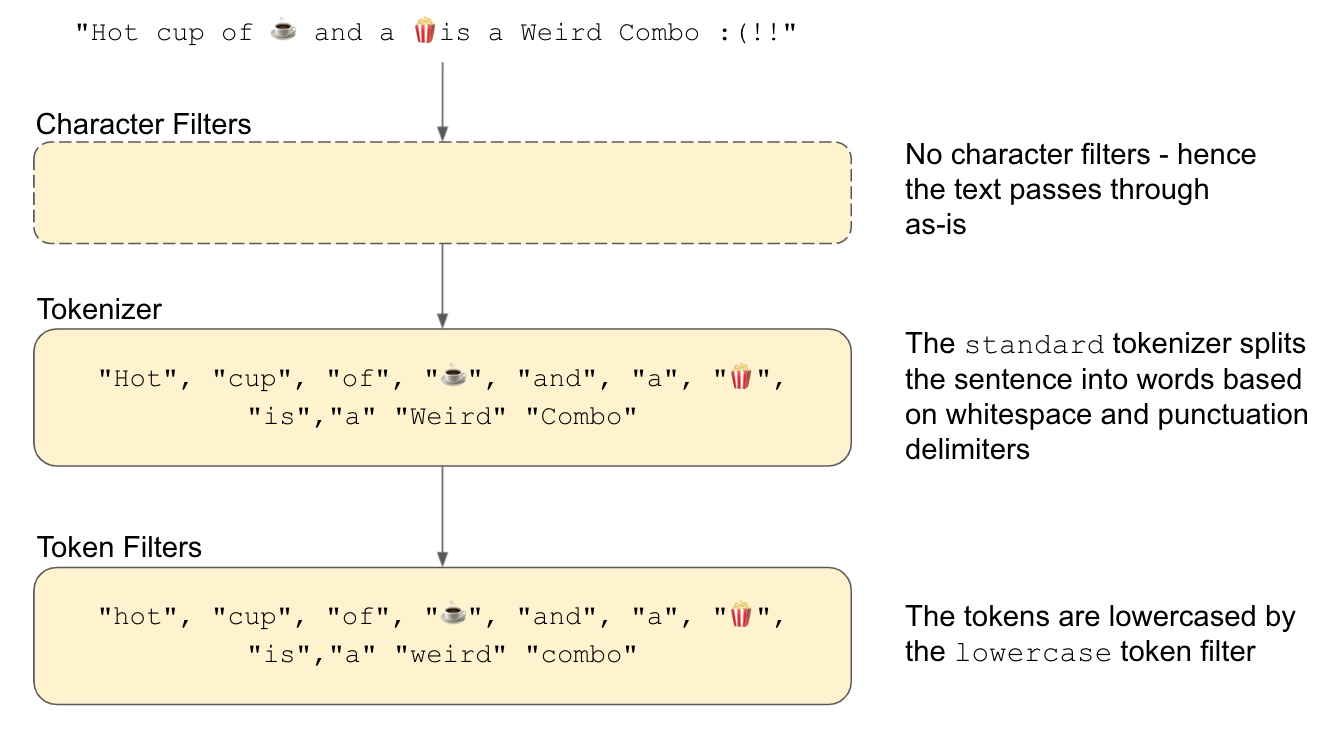
输出表明标准分析器的工作:单词是根据空格和非字母(标点符号)拆分的,这是标准分词器的标志。 然后分词通过小写分词过滤器(lowercase token filter)。
注意:内置分析器的组件:每个内置分析器都带有一组预定义的组件,例如字符过滤器、分词器和分词过滤器 —— 例如,指纹分析器由标准分词器和一堆 分词过滤器(指纹、小写、asciifolding 和停止分词过滤器)但没有字符过滤器。 除非你随着时间的推移记住了分析器的解剖结构,否则并不容易! 因此,我的建议是,如果你需要详细了解分析器的细节,请检查官方文档页面上分析器的定义。
下图显示了此命令在 DevTools 中的压缩输出。 如你所见,“coffee” 和 “popcorn” 的标记按原样存储,并且删除了非字母字符,例如 :( 和 !!。
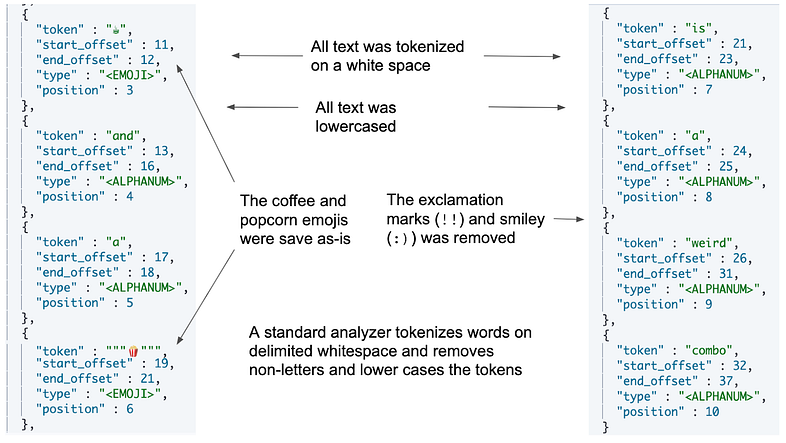
使用 standard analyzer 输出的分词
测试标准分析器
我们可以在文本分析测试阶段通过在代码中添加额外的 analyzer 属性来添加特定的分析器。 下面的清单证明了这一点。
GET _analyze
{
"analyzer": "standard",
"text": "Hot cup of ☕ and a 🍿is a Weird Combo :(!!"
}
如果你使用不同的分析器测试文本字段,则可以将分析器的值替换为你选择的值,例如:"analyzer": "whitespace"。
此代码产生与上图所示相同的结果。 输出表明文本已分词并小写。 下图为我们提供了标准分析器及其内部组件和解剖结构的图形表示。
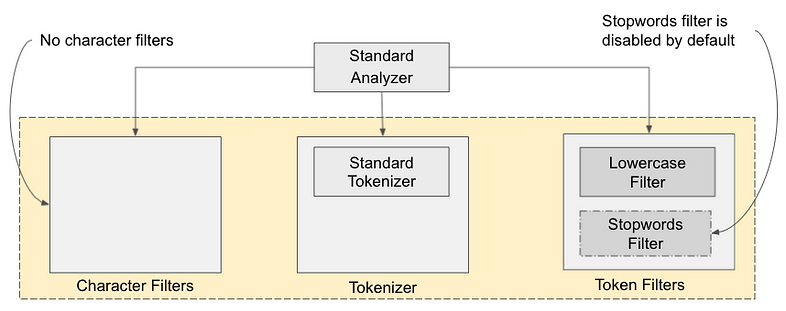
如图所示,标准分析器由一个标准分词器和两个分词过滤器组成:小写(Lowercase)和停止(Stopwords)过滤器。 标准分析器上没有定义字符过滤器。 再次提醒我们自己,分析器由零个或多个字符过滤器、至少一个分词器和零个或多个分词过滤器组成。
尽管标准分析器配备了停用(stopwords)词标记过滤器,但默认情况下停用词过滤器是禁用的。 但是,我们可以通过配置其属性来打开它。
配置标准分析器
Elasticsearch 允许我们在标准分析器上配置一些参数,例如停用词过滤器、停用词路径和最大标记长度。 配置属性的方法是通过索引设置。 当我们创建索引时,我们可以通过设置组件来配置分析器:
PUT <my_index>
{
"settings": {
"analysis": {
"analyzer": {
...
}
}
}
}
停用词配置
让我们以在标准分析器上启用英语停用词为例。 我们可以通过在索引创建期间添加过滤器来完成此操作,如以下清单所示。
PUT my_index_with_stopwords
{
"settings": {
"analysis": {
"analyzer": {
"standard_with_stopwords":{
"type":"standard",
"stopwords":"_english_"
}
}
}
}
}
正如我们之前注意到的,标准分析器上的停用词过滤器被禁用。 现在我们已经使用配置了停用词的标准分析器创建了索引,任何被索引的文本都会通过这个修改后的分析器。 为了测试这一点,我们可以调用索引上的 _analyze 端点,如下面的清单所示:
POST my_index_with_stopwords/_analyze
{
"text": ["Hot cup of ☕ and a 🍿is a Weird Combo :(!!"],
"analyzer": "standard_with_stopwords"
}
上面的命返回的结果为:
{
"tokens": [
{
"token": "hot",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "cup",
"start_offset": 4,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "☕",
"start_offset": 11,
"end_offset": 12,
"type": "<EMOJI>",
"position": 3
},
{
"token": "🍿",
"start_offset": 19,
"end_offset": 21,
"type": "<EMOJI>",
"position": 6
},
{
"token": "weird",
"start_offset": 26,
"end_offset": 31,
"type": "<ALPHANUM>",
"position": 9
},
{
"token": "combo",
"start_offset": 32,
"end_offset": 37,
"type": "<ALPHANUM>",
"position": 10
}
]
}
此调用的输出显示已删除常见(英语)停用词,例如“of”、“a”和“is”:
["hot", "cup", "☕" "🍿","weird", "combo"]
我们可以更改我们选择的语言的停用词。 例如,以下清单中的代码显示了带有印地语停用词和标准分析器的索引。
PUT my_index_with_stopwords_hindi
{
"settings": {
"analysis": {
"analyzer": {
"standard_with_stopwords_hindi":{
"type":"standard",
"stopwords":"_hindi_"
}
}
}
}
}
我们可以使用前面提到的 standard_with_stopwords_hindi 分析器来测试文本:
POST my_index_with_stopwords_hindi/_analyze
{
"text": ["आप क्या कर रहे हो?"],
"analyzer": "standard_with_stopwords_hindi"
}
如果您想知道这个印地语句子代表什么,它的意思是 “你在做什么?”
上面脚本的输出如下所示:
"tokens" : [{
"token" : "क्या",
"start_offset" : 3,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 1
}]
获得输出的唯一标记是क्या(第二个词),因为其余词都是停用词。 (它们在印地语中很常见)。
基于文件的停用词
如果内置停用词过滤器不满足或不满足我们的要求,我们可以通过显式文件提供停用词。
假设我们不希望用户在我们的应用程序中输入脏话。 我们可以创建一个包含所有列入黑名单的脏话的文件,并将该文件的路径作为参数添加到标准分析器中。 该文件必须相对于 Elastisearch 主页的配置文件夹存在。 以下清单使用接受停用词文件的分析器创建索引:
PUT index_with_swear_stopwords
{
"settings": {
"analysis": {
"analyzer": {
"swearwords_analyzer":{#A
"type":"standard", #B
"stopwords_path":"swearwords.txt" #C
}
}
}
}
}
stopwords_path 属性在 Elasticsearch 的配置文件夹内的目录中查找文件(在本例中为 swearwords.txt)。 以下清单演示了在 config 文件夹中创建文件的路径。 确保将目录更改为 $ELASTICSEARCH_HOME/config 并在其中创建 swearwords.txt 文件。 在列表中,请注意黑名单中的单词是在新行中创建的。
file:swearwords.txt
damn
bugger
bloody hell
what the hell
sucks
一旦创建了文件并开发了索引,如下面的清单所示,我们就可以使用带有自定义脏话的分析器了:
POST index_with_swear_stopwords/_analyze
{
"text": ["Damn, that sucks!"],
"analyzer": "swearwords_analyzer"
}
这段代码应该停止第一个和最后一个词通过索引过程,因为这两个词在我们的脏话黑名单中。 我们可以配置的下一个属性是分词的长度:作为输出,我需要分词的长度有多长。
配置分词的长度
我们还可以配置最大分词长度; 在这种情况下,分词将根据要求的长度进行拆分。 例如,下面的清单使用标准分析器创建了一个索引。 分析器配置为具有 7 个字符的最大分词长度。 如果我们提供一个长度为 13 个字符的词,该词将被拆分为 7 个和 6 个字符(例如,Elasticsearch 将变为 “Elastic”、“search”)。
PUT my_index_with_max_token_length
{
"settings": {
"analysis": {
"analyzer": {
"standard_max_token_length":{
"type":"standard",
"max_token_length":7
}
}
}
}
}
我们使用上面的索引来测试:
POST my_index_with_max_token_length/_analyze
{
"text": "Elasticsearch is a powerful tool",
"analyzer": "standard_max_token_length"
}
上面命令返回的结果为:
{
"tokens": [
{
"token": "elastic",
"start_offset": 0,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "search",
"start_offset": 7,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "is",
"start_offset": 14,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "a",
"start_offset": 17,
"end_offset": 18,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "powerfu",
"start_offset": 19,
"end_offset": 26,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "l",
"start_offset": 26,
"end_offset": 27,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "tool",
"start_offset": 28,
"end_offset": 32,
"type": "<ALPHANUM>",
"position": 6
}
]
}
很显然,Elasticsearch 及 powerful 两个词被拆分了,因为它们的长度超过了 7。
版权归原作者 Elastic 中国社区官方博客 所有, 如有侵权,请联系我们删除。