
Spark基于Spark Core开发了多种组件。开发人员可以基于这些组件,轻松完成多种不同场景的计算任务。

1.Spark Core介绍
Spark Core是Spark的核心,各类核心组件都依赖于Spark Core。如下图所示,Spark Core核心组件包括基础设施、存储系统、调度系统、计算引擎四个部分。
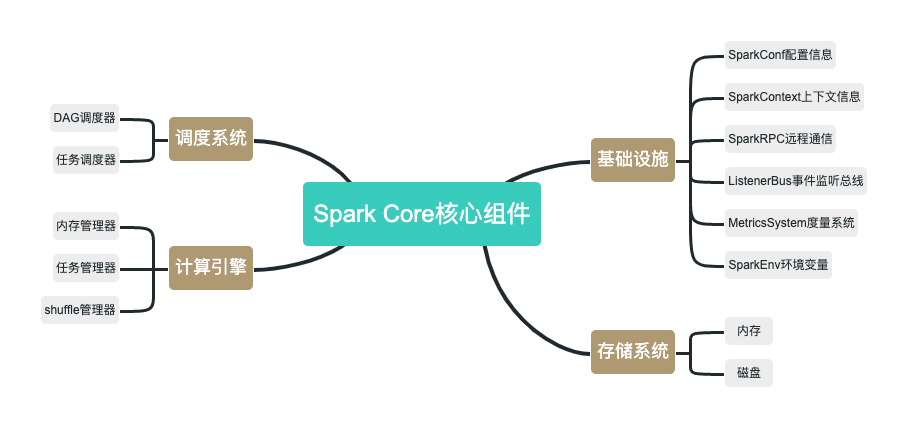
1)Spark基础设施
Spark基础设施为其他组件提供最基础的服务,是Spark中最底层、最常用的一类组件。
- SparkConf:用于定义Spark应用程序的配置信息。
- SparkContext:是Spark中的应用入口,实现了网络通信、分布式、消息机制、存储、计算、运维监控、文件系统等各类常用功能,并且封装为简单易用的API,是开发人员只需要简单的几行代码就可以实现相应功能。
- Spark RPC:基于Netty实现的Spark组件间的网络通信组件。
- ListenerBus:Spark事件监听总线,主要用于内部组件间的交互。
- MetricsSystem:Spark度量系统,用于监控整个Spark集群中各个组件的运行状态。
- SparkEnv:Spark执行环境变量。内部封装了Rpc环境、序列化管理器、广播管理器、map任务输出跟踪器、存储等Spark运行所需的基础环境组件。
2)Spark存储系统
Spark另一个核心组件就是存储系统,主要用于管理Spark运行过程中的数据存储。Spark存储系统会按照存储层次,将数据优先保存在内存,在内存不足时使用是本机磁盘,并且支持远程存储。
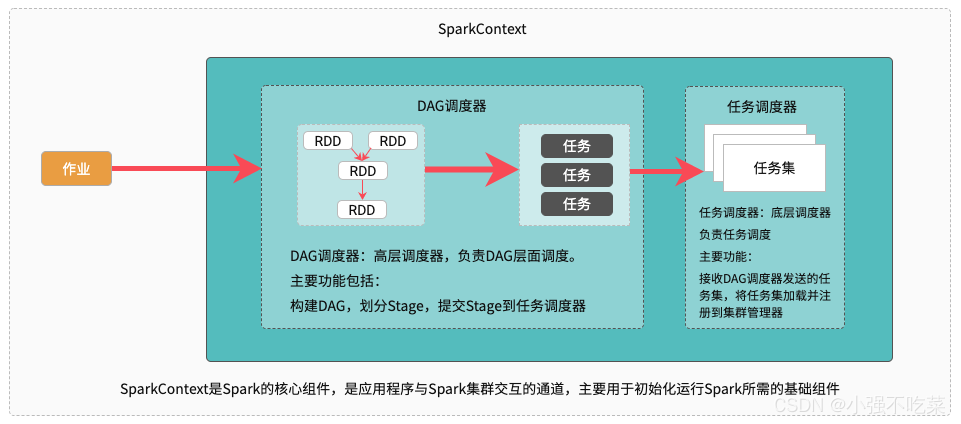
3)Spark调度系统
Spark调度系统主要包括DAG调度器和任务调度器两个部分。如下图所示,DAG调度器负责创建DAG并划分Stage,并基于Stage创建任务,并以任务集的形势提交任务。任务调度器,主要负责对任务进行批量调度。
4)Spark计算引擎
Spark计算引擎主要包括内存管理器、作业管理器、任务管理器、Shuffle管理器几个部分。Spark计算引擎负责Spark在任务执行过程中的内存分配、作业和任务运行、状态监控于管理等。
2.SparkSQL
SparkSQL是Spark提供的分布式SQL查询引擎。Spark基于抽象变成对象DataFrame和Dataset构建了基于SQL的数据处理方式,从而使大幅简化了分布式数据处理。SparkSQL允许开发人员将数据加载到Spark并映射成表,从而通过SQL语句来进行数据分析工作。
1)DataFrame
DataFrame是SaprkSQL的结构化数据的抽象,实现数据表的作用。Dataframe在RDD的基础上增加了数据结构信息Schema。基于Schema信息,Spark可以根据不同的数据结构,对数据的运算自动进行不同维度的优化。
Spark的DataFrame可以通过多种方式构建。支持RDD、CSV、XML、Hive、Parquet等数据转换为DataFrame。构建好DataFrame之后,开发人员就可以将DataFrame映射为表,并使用SQL语句进行数据分析工作。
2)Dataset
Dataset是Spark的分布式数据集合,同时具备RDD强类型化的有点和SparkSQL优化后执行引擎的有点。开发人员可以从JVM构建Dataset,并使用Map()等函数进行操作。
3.Spark Streaming
Spark Streaming是Spark的基于时间窗口的流式计算组件,支持从kafka、HDFS、Flume等多种数据源获取数据,然后利用Spark计算引擎以微批的形式进行处理,并将结果写入Radis、Kafka、HDFS等系统。
4.GraphX
GraphX是Spark的分布式图计算组件,利用Pergel提供的API,为开发人员提供可快速实现的图计算能力。
5.Spark MLlib
Spark MLlib事故Spark的机器学习库,提供了统计、分类、回归、预测、推荐等机器学习算法,并高度封装。从而为开发人员提供简单易用的机器学习能力
6.SparkR
SparkR是Spark的R语言包,用于在Spark中,提供一种轻量级的R语言使用方式,从而方便开发人员使用R语言处理大规模数据集。
版权归原作者 小强不吃菜 所有, 如有侵权,请联系我们删除。