
文章目录
前言
在信息时代,数据的增长速度之快让我们迅速感受到了信息爆炸的挑战。在这个背景下,搜索引擎成为了我们处理海量数据的得力工具之一。而 ElasticSearch 作为一款强大的开源搜索引擎,不仅能够高效地存储和检索数据,还在日志分析、实时监控等领域展现了其卓越的性能。
一、初识 ElasticSearch 搜索引擎
1.1 ElasticSearch 的核心概念
- 搜索引擎的精华
ElasticSearch 的主要任务包括存储、搜索和分析数据。其搜索引擎的精华在于倒排索引(Inverted Index)等高效算法。通过倒排索引,ES 能够快速响应搜索请求,实现高效的数据检索。这是其搜索能力强大的基石。
- Elastic Stack(ELK)
ELK 是由 Elasticsearch、Logstash、Kibana 和 Beats 组成的一整套日志管理和数据分析工具组合。Logstash 负责收集和处理日志数据,Beats 则用于轻量级的数据传输,Kibana 提供了强大的数据可视化和分析工具。ES 与其他工具的协同作用构成了强大的数据处理生态系统。
1.2 ElasticSearch 的演进历程
- Lucene:搜索引擎的基石
在 ElasticSearch 之前,Lucene 是搜索引擎领域的重要组成部分。由 Doug Cutting 于 1999 年创建,Lucene 使用倒排索引等高效算法。然而,它仅支持 Java 开发,学习曲线陡峭,不支持水平扩展。
- Compass:Lucene 的扩展
为了克服 Lucene 的限制,Shay Banon 在其基础上开发了 Compass。尽管 Compass 弥补了一些缺陷,但仍无法满足日益增长的需求。
- ElasticSearch 的诞生
2010 年,Shay Banon 决定重新设计和实现 Compass,于是 ElasticSearch 应运而生。ES 继承了 Lucene 的优势,支持分布式架构,可水平扩展,并提供了 Restful 接口,方便被各种编程语言调用。
- 分布式特性的加强
ES 不断加强其分布式特性。引入了分片(Shards)的概念,将数据分割成更小的单元,每个分片可以独立运行在集群的不同节点上。这种架构使得 ElasticSearch 能够更好地处理大规模数据,并提高系统的可伸缩性和性能。
- 插件生态系统的形成
ES 建立起丰富的插件生态系统。这些插件可以提供各种功能,包括新的搜索算法、数据处理和可视化工具等。这使得用户可以根据自己的需求定制化 ElasticSearch,使其更加适应不同的使用场景。
- Logstash 和 Kibana 的整合
为了构建完整的日志处理和分析解决方案,ElasticSearch 与 Logstash 和 Kibana 进行了整合,形成了 ELK(Elasticsearch, Logstash, Kibana)堆栈。Logstash 用于数据的收集和处理,Kibana 用于数据的可视化和分析。这个整合使得 ElasticSearch 成为一个强大的日志和事件管理平台。
- X-Pack 的引入
为了提供更多的高级功能,ElasticSearch 引入了 X-Pack。包括安全性、监控、报告、警报等多个方面的功能。X-Pack 的引入进一步扩展了 ElasticSearch 的应用领域,使其在企业环境中更加强大和可靠。
- Elastic Stack 的形成
ELK 堆栈逐渐演变成 Elastic Stack,包括 Elasticsearch、Logstash、Kibana 以及 Beats(用于轻量数据传输)。这个集成的堆栈提供了一个端到端的解决方案,涵盖了数据的采集、存储、搜索、可视化等方方面面。
- Elasticsearch 的版本迭代
ElasticSearch 持续进行版本迭代,不断引入新的功能、性能优化和安全性增强。用户可以通过升级到最新版本来享受这些改进,同时保持其系统与时俱进。
- 云服务和开源社区
ElasticSearch 在云服务提供商上提供了托管服务,使用户能够更轻松地部署和管理 ElasticSearch 集群。同时,它积极参与开源社区,接受来自全球开发者的贡献,形成了一个活跃的开源生态系统。
1.3 ElasticSearch 的优势与未来
ES 的优势在于其强大的搜索能力、分布式架构和与其他工具的集成。它已经成为处理大规模数据的首选引擎之一,被广泛应用于搜索引擎、日志分析、实时监控等场景。
未来,随着数据规模的不断增长,ElasticSearch 有望继续发挥其在大数据处理领域的重要作用。同时,社区的不断贡献和开发团队的努力也将为 ElasticSearch 带来更多创新和改进,使其在搜索引擎领域持续发光发热。ES 作为搜索和分析的引擎,将继续推动数据处理领域的进步和演进。
二、正排索引与倒排索引:数据库与 ElasticSearch 的差异
在数据存储和检索领域,索引是一项关键技术,而正排索引和倒排索引是两种不同的索引结构,它们在传统数据库和 ElasticSearch 中的应用有着显著的差异。
2.1 对正排索引的认识
传统数据库的索引方式
在传统数据库中,如 MySQL,正排索引是一种常见的索引方式。它简单来说是将整个数据表按照某个字段进行排序,创建一个索引结构。例如,现在有一个商品表:
idtitleprice1小米手机34992华为手机49993华为小米充电器494小米手环49………
当执行搜索“手机”的 SQL 语句时,数据库会遍历每一行记录,判断是否包含“手机”关键字。这样的查询过程是线性的,需要逐行检查所有记录。正排索引适用于小规模数据,但随着数据量的增加,查询效率会下降。
select*from tb_goods where title like'%手机%'
查询数据库表的流程图:
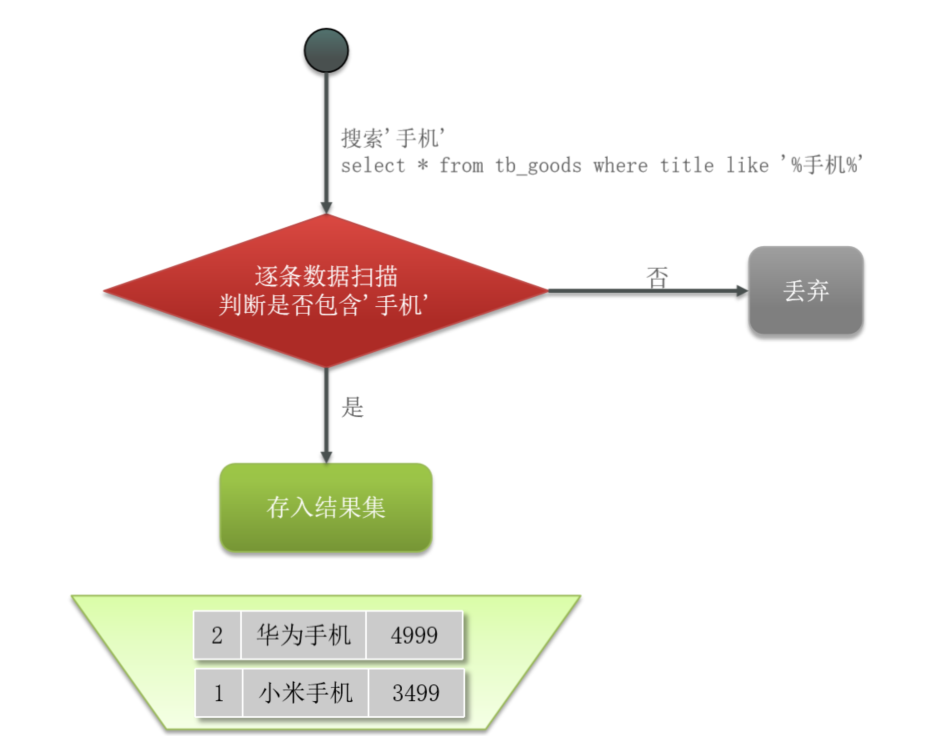
说明:
- 当执行搜索“手机”的 SQL 语句的时候,会遍历数据库表中的每一条记录,判断是否包含“手机”关键字。
- 如果包含了,则当当前数据传入结果集;
- 如果没有包含,则丢弃当前数据;
以上就是通过正排索引的方式进行查询,通过这个查询过程我们可以发现,每次查询都会遍历整个数据表的内容,如果当数据量非常大的时候,效率就会显得非常低下了。
2.2 对倒排索引的认识
ElasticSearch 就是采用的倒排索引,这是一种更为灵活高效的索引结构,倒排索引的两个关键概念就是
文档
和
词条
:
- 文档(Document): 每条数据被视为一个文档。
- 词条(Term): 文档按语义划分成词语。
例如,针对上文的商品表的例子,经过分词处理后,生成的倒排索引如下:
词条(Term)文档 id小米1, 3, 4手机1, 2华为2, 3充电器3手环4
此时,当我们查询“华为手机”时,ElasticSearch 只需在倒排索引中查找包含“华为”和“手机”的文档 id,然后直接定位到对应文档。这种方式大大提高了查询效率。
查询“华为手机”的流程图:
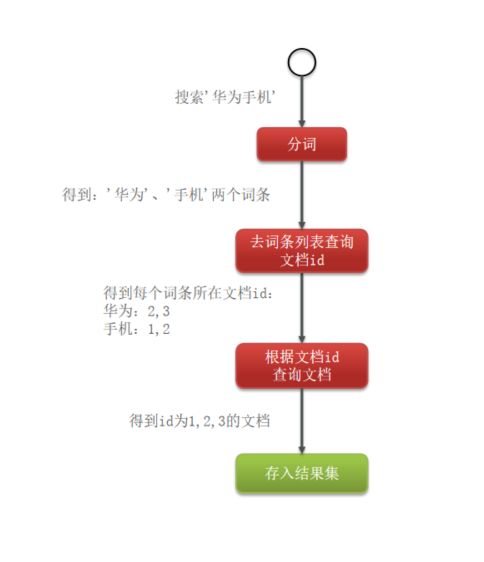
说明:
- 将 “华为手机” 进行分词处理,得到 “华为” 和 “手机” 两个词条;
- 根据这两个词条到上述的倒排索引表中去查询文档 id;
- 然后再根据查询到的文档 id 去查询对应的文档;
- 最后将查询到的文档存入结果集中。
这就是倒排索引,与正排索引相比,效率大大提高,每次查询不用需遍历所有的文档,只需要根据词条进行查询文档id,然后再根据文档id查询对应的文档。
2.3 正排索引 vs. 倒排索引
- 查询效率: 正排索引需要逐行扫描,效率随数据增长而下降;倒排索引通过词条快速定位文档,查询效率更高。
- 适用场景: 正排索引适用于小规模数据,简单查询场景;倒排索引适用于大规模数据,复杂查询场景。
- 空间占用: 正排索引占用空间较大,随数据量线性增长;倒排索引采用压缩等技术,空间利用更为高效。
在实际应用中,ElasticSearch 作为搜索引擎,利用倒排索引构建了强大的全文搜索和分析功能,适用于处理大规模的文本数据,例如日志分析、实时监控等场景。正排索引在传统数据库中仍然发挥着重要的作用,尤其是在小规模数据和简单查询场景下。因此,选择合适的索引结构取决于数据规模、查询需求以及系统性能的考虑。
三、词条词典、倒排列表、文档与索引:ElasticSearch核心概念解析
在ElasticSearch中,理解词条词典、倒排列表、文档和索引是深入掌握其核心概念的关键。以下是对这些概念的详细解析:
3.1 倒排索引的两部分内容:词条词典和倒排列表
- **词条词典(Term Dictionary)**
词条词典是一个记录了所有词条的数据结构,同时维护了词条与倒排列表之间的关系。它实质上是一个词汇表,用于加速查询和插入操作。每个词条都会被分配一个唯一的标识符,这样在倒排列表中可以快速定位到相应的词条。
- **倒排列表(Posting List)**
倒排列表记录了每个词条在文档中的出现情况,包括文档的标识符(文档id)、词条的出现频率(TF,Term Frequency)以及词条在文档中的位置等信息。这样的设计使得在搜索过程中,可以迅速找到包含特定词条的文档。
- 文档id: 用于快速获取文档。
- 词条频率(TF): 表示文档中词条出现的次数,对搜索结果的相关性评分有重要影响。
3.2 文档
在 ElasticSearch 中,文档是基本的信息单元。每个文档对应着一条数据记录,可以是一篇文章、一条商品信息、一个用户的配置等。文档中的数据以 JSON 格式序列化存储。
例如,对于上文的商品数据表,每一行的数据都可以被序列化为一个文档:

3.3 索引(Index)
索引是 ElasticSearch 中的一个核心概念,它是
相同类型的文档的集合
。每个索引都有一个唯一的名称,用于标识和检索。索引并不直接存储数据,而是存储了对文档的引用以及文档中的字段信息,同时包含了用于加速搜索的倒排索引。
例如,可以有商品索引、用户索引、订单索引,每个索引下包含了相应类型的文档:

3.4 总结与补充
- 正向索引 vs. 倒排索引: 正向索引是基于文档 id 创建索引,适用于小规模数据和简单查询场景。倒排索引通过分析文档内容,记录词条信息,适用于大规模数据和复杂查询场景,提高了查询效率。
- 应用场景: ElasticSearch 的强大之处在于其面向文档的存储和全文搜索功能。通过灵活的倒排索引,可以高效地处理大量文本数据,广泛应用于日志分析、实时监控、搜索引擎等场景。
- 映射(Mapping): 在索引中,映射定义了文档的字段以及字段的数据类型。它类似于传统数据库中表的结构约束,有助于数据的一致性和有效性。
理解这些核心概念,有助于更深入地利用 ElasticSearch 进行数据存储、检索和分析,从而充分发挥其强大的搜索引擎功能。
版权归原作者 求知. 所有, 如有侵权,请联系我们删除。