
一、前期准备

1、在终端进行selenium的安装
pip install selenium
2、下载一个浏览器的驱动程序
这里使用谷歌浏览器,点这下载谷歌浏览器驱动
注意:需要选择对应自己电脑浏览器的版本。
3、将下载好的谷歌浏览器驱动程序移动到当前项目下(可不用移动,填写路径)
二、基础操作
1、实例化一个浏览器对象
from selenium import webdriver
# 实例化一个浏览器对象(传入浏览器的驱动程序)
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
2、对url发起请求
# 对url发起请求
driver.get('URL')
3、标签定位
此处以搜索框为例,获取其id,使用find_element_by_id()对其定位。
# 标签定位
search_input = driver.find_element_by_id('id')
如果是class:
# 标签定位
search_input = driver.find_element_by_class_name('className')
4、标签交互
使用send_keys在搜索框中输入需要搜索的关键字。
# 标签交互
search_input.send_keys('CSDN')
5、点击按钮
点击搜索按钮,在浏览器中使用开发者工具定位搜索按钮的id,click() 进行点击。
# 点击搜索按钮
btn = driver.find_element_by_id('id')
btn.click()
6、回退、前进和关闭
# 回退
driver.back()
# 前进
driver.forward()
# 关闭浏览器
driver.quit()
7、解析数据
# 导包
from selenium import webdriver
from lxml import etree
from time import sleep
# 实例化一个浏览器对象(传入浏览器的驱动程序)
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 发起一个指定url请求
driver.get('URL')
# 获取浏览器当前页面的页面源码数据
page_text = driver.page_source
# 解析详细数据
tree = etree.HTML(page_text)
li_list = tree.xpath('xpath路径')
for li in li_list:
name = li.xpath('以li_list下的xpath路径')[0]
print(name)
sleep(5)
driver.quit()
8、执行JavaScript程序
这里执行JavaScript程序使得浏览器向下滚动一屏距离。
# 执行一组JavaScript程序
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
9、实现无可视化界面的操作(无头浏览器)
# 实现无可视化界面的操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(executable_path='./chromedriver.exe', options=chrome_options)
10、实现规避检测(去除浏览器识别)
# 实现规避检测
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(executable_path='./chromedriver.exe', options=option)
11、iframe的处理
如果定位的标签存在于iframe标签之中,则须使用switch_to.frame(id),这里的id是iframe标签中的id。
这个在登录QQ空间时可以用到,想学的可以点这里去学习。
当然,不止是QQ空间又iframe标签,还有很多地方也是有的。
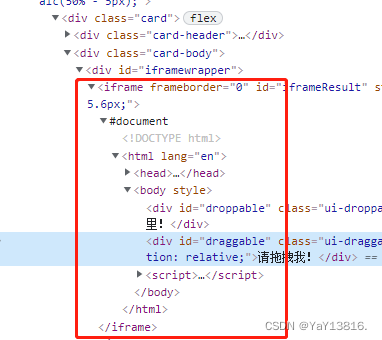
# 如果定位的标签是存在与iframe标签之中的则必须通过如下操作再进行标签定位
bro.switch_to.frame('iframeResult') # 切换浏览器标签定位的作用域
div = bro.find_element_by_id('draggable')
12、动作链
鼠标动作:左键单击按住→拖动→释放
这就是动作链
这个可以用在很多登录验证的地方,那些需要滑动验证的,都可以去尝试一下。
from selenium import webdriver
from time import sleep
# 导入动作链对应的类
from selenium.webdriver import ActionChains
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
driver.get('URL')
# 如果定位的标签是存在与iframe标签之中的则必须通过如下操作再进行标签定位
driver.switch_to.frame('iframeResult') # 切换浏览器标签定位的作用域
div = driver.find_element_by_id('id')
# 动作链
action = ActionChains(driver)
# 点击长按指定的标签
action.click_and_hold(div)
# 这里可以不适用循环,看个人爱好
for i in range(5):
# perform()立即执行动作链操作
# move_by_offset(x, y):x水平方向 y竖直方向
action.move_by_offset(20, 0).perform()
sleep(0.5)
# 释放动作链
action.release()
sleep(2)
driver.quit()
13、解决特征识别
这个特征识别在很多地方都可以用得上,特别是12306登录滑块验证的时候,非常nice!
关于12306如何使用selenium登录可以点这里进行学习
# 解决特征识别
script = 'Object.defineProperty(navigator, "webdriver", {get: () => false,});'
bro.execute_script(script)
不懂或有疑问等任何问题还请私信或评论
本文转载自: https://blog.csdn.net/m0_54490473/article/details/122734368
版权归原作者 蜡笔小新星 所有, 如有侵权,请联系我们删除。
版权归原作者 蜡笔小新星 所有, 如有侵权,请联系我们删除。