
一、数据采集
1.1需求分析
如今,伴随着终端设备和大数据技术的发展,借助网络招聘网站进行求职,已经成为了互联网时代连结求职者和用人单位双方需求的主流途径之一,数据采集作为大数据处理中的第一环节,起着举足轻重的作用,为以后进行数据分析提供了大量,有效,安全的数据。
基于此,本文以“字节跳动”为目标网站,进行数据采集以获取相关有效信息。通过网页元素分析,网页页面操作,确定该公司主要招聘职位的种类,对应的数量,工作地点,具体要求等内容,并将其保存到csv文件中,以便进行后续操作。
1.2关键技术分析
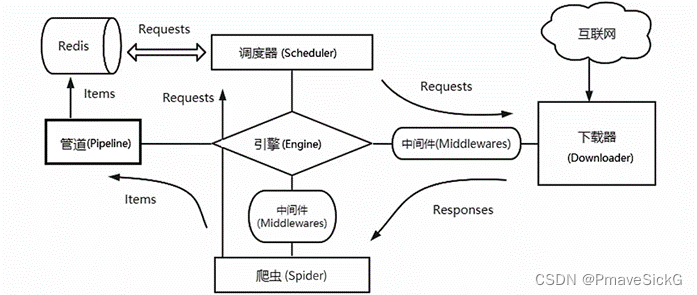
本环节中主要使用scrapy+redis进行数据爬取,scrapy的优越性,具有异步,可以灵活调节并发量,采取可读性更强的xpath代替正则表达式,编写代码更为方便,通过管道的方式存储文件,更加灵活等优势,相比bs4、request、urllib等结合的爬取方式,它们的语句繁琐且零散,爬取效率低下,而搭建好一个scrapy平台,上面封装的各个功能便于灵活修改。
但是Scrapy框架并不支持抓取URL在各个爬虫端之间共享,也就不支持分布式操作。在Scrapy单机爬虫系统中存在一个由deque模块实现的本地爬取队列Queue。这个队列是依靠Scheduler组件负责维护的,是独一无二的,并且它具有不被多个Scheduler共享的特性,造成了Scrapy框架不能实现分布式抓取数据。然而Scrapy框架具有易扩展的特点,通过Scrapy-Redis组件引入Redis模块代替Scrapy框架的单机内存来存储待抓取的URL,Redis数据库自身又有能共享数据库给多个爬虫端的特性,这样就把抓取队列共享出去了。
因此本环节采用scrapy搭配redis的方式实现分布式爬取,且分布式爬取只需要在原来单机运行的爬虫上稍加修改即可完成,提高运行效率,同时,也使用了selenium实现自动跳转网页,采取了csv文件作为保存数据的方式。
1.3任务实施及代码说明
具体流程如图1.1所示:

图1.1
首先将本机链接到redis并启用,如图1.2所示:
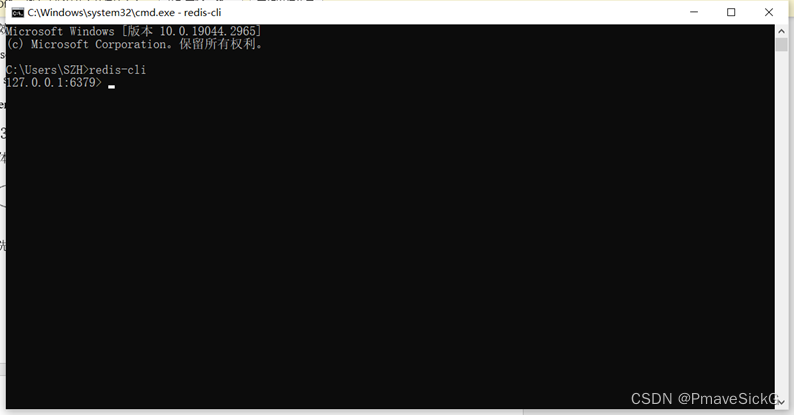
图1.2
接着设定key名称为“Byte”(与主爬虫文件中的名称对应),初始网址设定为:https://jobs.bytedance.com/experienced/position?keywords=python&category=&location=&project=&type=&job_hot_flag=¤t=1
如图1.3所示:
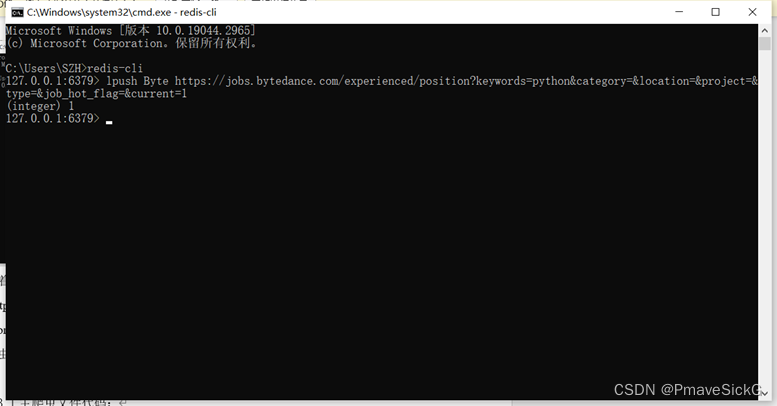
图1.3
然后打开pycharm的terminal,cd到spider目录下输入scrapy runspider Byte.py,开始爬取,如图1.4所示。
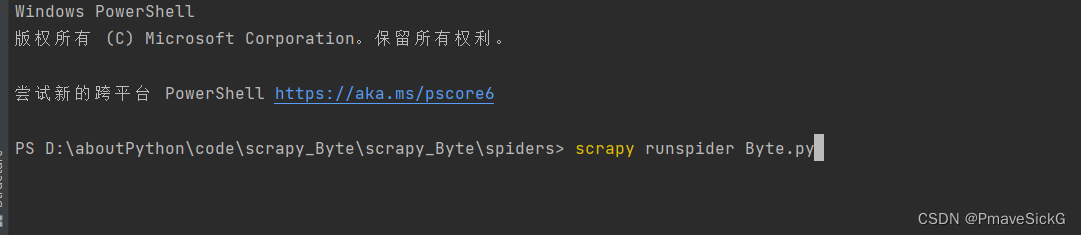
图1.4
最后等待爬取结束,导出csv文件。
1.3.1主爬虫文件代码
import scrapy
from scrapy_Byte.items import ScrapyByteItem
from scrapy_redis.spiders import RedisSpider
# 此处应继承RedisSpider而不是scrapy.Spider
class ByteSpider(RedisSpider):
name = "Byte"
page = 1
base_url = "https://jobs.bytedance.com/experienced/position?keywords=python&category=&location=&project=&type=&job_hot_flag=¤t="
# start_urls = [base_url + str(page)]
redis_key = 'Byte' # 设定钥匙名称为’Byte’
# 此处为复制scrapy+redis框架中的代码
def __init__(self, *args, **kwargs):
domain = kwargs.pop('domain', '')
self.allowed_domains = list(filter(None, domain.split(',')))
super(ByteSpider, self).__init__(*args, **kwargs)
def parse(self, response, **kwargs):
key = ScrapyByteItem()
# 以下采用for循环操作,主要由于在一个网面中共包含10个职位数据,通过遍历对其进行获取
for i in range(1, 11):
name = response.xpath(
'//*[@id="bd"]/section/section/main/div/div/div[2]/div[3]/div[1]/div[2]/a[{}]/div/div[1]/div[1]/span/text()'.format(
i)).extract_first()
print(name)
# for job in jobs:
specific_job = response.xpath(
'//*[@id="bd"]/section/section/main/div/div/div[2]/div[3]/div[1]/div[2]/a[{}]/div/div[2]/span[3]/span/text()'.format(
i)).extract_first()
print(specific_job)
job_id = response.xpath(
'//*[@id="bd"]/section/section/main/div/div/div[2]/div[3]/div[1]/div[2]/a[{}]/div/div[2]/span[4]/text()'.format(
i)).extract_first()[6:]
# 此处采用字符串的切片操作,主要由于在职位ID之前存在与ID无关的文字内容,此处采用字符串的切片只获取完整的ID
print(job_id)
position = response.xpath(
'/html/body/div[1]/section/section/main/div/div/div[2]/div[3]/div[1]/div[2]/a[{}]/div/div[2]/span[1]/text()'.format(
i)).extract_first()
print(position)
description = response.xpath(
'//*[@id="bd"]/section/section/main/div/div/div[2]/div[3]/div[1]/div[2]/a[{}]/div/div[3]/text()'.format(
i)).extract_first().replace("\n", '')
# 此处由于获得的描述数据中含有换行符等字符对保存数据产生了影响,故先将换行符替换成空
print(description)
link = "https://jobs.bytedance.com" + response.xpath(
'//*[@id="bd"]/section/section/main/div/div/div[2]/div[3]/div[1]/div[2]/a[{}]/@href'.format(
i)).extract_first()
print(link)
key['name'] = name.replace(' ', '')
key['position'] = position
key['description'] = description.replace(' ', '').replace(',', ',')
#将描述中的数据加以处理,避免对保存数据造成影响。
key['specific_job'] = specific_job.replace(' ', '')
key['job_id'] = job_id
key['link'] = link
yield key
#以下是翻页操作,本文将页码设置为141,爬取前142页的内容,并使用yield返回对应的网址。
if self.page <= 141:
self.page += 1
new_url = self.base_url + str(self.page)
yield scrapy.Request(url=new_url, callback=self.parse, meta={'item': key}, dont_filter=True)
1.3.2设置setting.py文件
其优点在于解开或注释某几行语句,达到灵活修改的目的。如图1.5,设置user_agent以伪装成正常的浏览器搜索(USER_AGENT = “个人浏览器的user_agent”)
图1.5
解开redis相关设置,如图1.6。

图1.6
解开middleware和pipelines设置,以使用中间件进行处理及使用item保存数据,如图1.7.
图1.7
设置redis端口号等相关信息,并设置延迟时间为2s(这里最好设置稍微长点时间否则容易出错!),如图1.8。
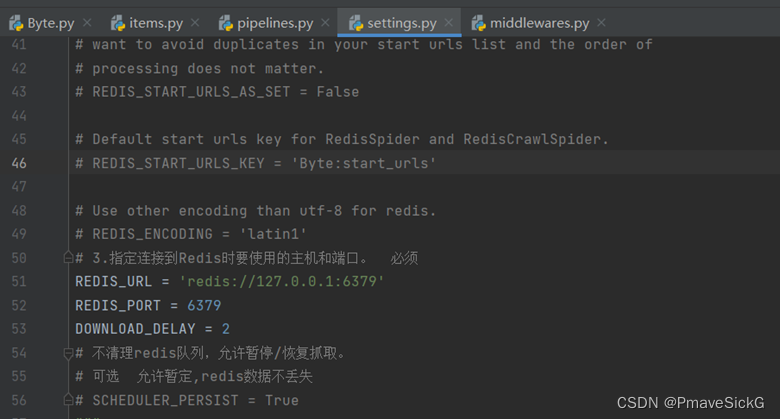
图1.8
1.3.3items.py文件的配置
修改其中的class以格式化数据,自行编写属性。
import scrapy
class ScrapyByteItem(scrapy.Item):
name = scrapy.Field()
position = scrapy.Field()
description = scrapy.Field()
job_id = scrapy.Field()
specific_job = scrapy.Field()
link = scrapy.Field()
1.3.4 pipelines.py文件的配置
主要用来进行保存数据,本文选取的保存数据的方式为csv文件,其特点为可读性强,通用性强,便于后续数据处理。
class ScrapyBytePipeline:
def open_spider(self, spider):
self.f = open('job_Byte_1.csv', 'a+', encoding='utf-8')
# 打开文件,并设置文件书写方式为’a’ 即新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
def process_item(self, item, spider):
self.f.write(
f"{item['name']}, {item['specific_job']}, {item['position']}, {item['job_id']}, {item['description']}, {item['link']}\n")
return item
# 写入数据,分为6个部分,分别是:职位,具体类别,地点,ID,描述,具体网址。
def close_spider(self, spider):
if self.f:
self.f.close()
# 关闭文件
1.3.5 爬虫文件2:scrapy结合selenium
from selenium import webdriver
import time
from scrapy.http import HtmlResponse
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
class ScrapyByteDownloaderMiddleware:
# 启用Chrome
def __init__(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.wait = WebDriverWait(self.driver, 10)
# 关闭Chrome
def __del__(self):
self.driver.close()
def process_request(self, request, spider):
print('当前request的url为:' + request.url)
offset = request.meta.get('offset', 1)
self.driver.get(request.url)
time.sleep(2)
if offset > 1:
self.driver.find_element(By.XPATH, '//*[@id="bd"]/section/section/main/div/div/div[2]/div[3]/div[2]/ul/li[9]/a/i/svg').click()
# 借助selenium定位翻页的按钮位置,并设置时间等待为2秒
html = self.driver.page_source
return HtmlResponse(url=request.url, body=html, encoding='utf-8', request=request)
1.3.6运行结果
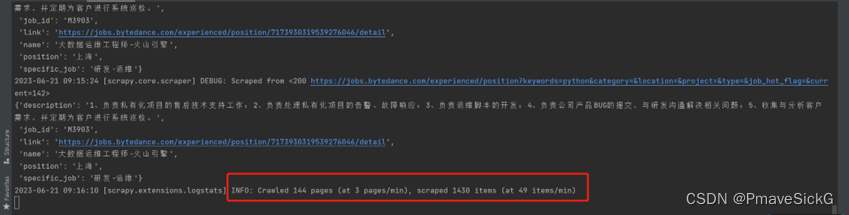
保存到csv文件中
二、数据基本处理
2.1任务描述
数据预处理用来发现并纠正数据中可能存在的错误,针对数据审查过程中发现的错误值、缺失值、异常值、可疑数据等等选用适当方法清除“脏数据”。
导入pandas库进行职位信息的预处理,使信息更简洁美观,例如将文件中“职位”中的字符进行替换操作,避免英文的’,’对数据处理造成影响。
并将数据按照一定规则进行聚合和汇总,计算统计指标和摘要信息,以提供对数据的整体认识和概览,以条形图的方式呈现数据,更加直观。
导入jieba中文分词库,将文件中“描述”的内容单独写入新的文本文件,并使用该中文分词库完成字符的切片操作
搭配使用wordcloud库,制作词云图。
2.2任务实施及代码说明
import pandas as pd
from pylab import *
import jieba
import wordcloud
"""
需求如下:
1.统计各个城市的职位数量;
2.根据这个数量绘制所对应城市的城市分布条形图;
3.依据描述中的文本绘制与python相关的词云图;
4.查询以”大数据“为关键字的职位名称。
"""
'''
value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
normalize : boolean, default False 默认false,如为true,则以百分比的形式显示
sort : boolean, default True 默认为true,会对结果进行排序
ascending : boolean, default False 默认降序排序
bins : integer, 格式(bins=1),意义不是执行计算,而是把它们分成半开放的数据集合,只适用于数字数据
dropna : boolean, default True 默认删除na值
'''
# 统计职位数据出现在各地的次数
def Count():
df = pd.read_csv("job_Byte_1.csv")
df2 = df.地点.value_counts()
# 将文件中的地点和对应地点的职位数量制作成图表
df.loc[:, '职位'] = df['职位'].str.replace(',', '-')
# 清洗数据,将“职位”中的英文’,’替换成’-’避免对后续制表造成影响
print(df2)
y = []
for i in df2:
y.append(i)
x = ['beijing', 'shanghai', 'shenzhen', 'hangzhou', 'chengdu', 'guangzhou', 'xian', 'chongqing', 'wuhan',
'nanjing', 'fuzhou']
# 设定横轴坐标
plt.xlabel('city')
plt.ylabel('number')
plt.bar(x, y)
plt.show()
Count()
# 完成查询的功能
def search_BigData():
df = pd.read_csv("job_Byte_1.csv")
print(df.shape)
print(df.index)
df.set_index('职位', inplace=True)
# 将职位设定为索引值便于后续的查询
result = df[df.index.str.contains('大数据')]
# 查询包含“大数据”关键字的职位
# print(type(result))
print(result)
search_BigData()
# 将文件中“描述”这一列的文本内容单独提取出来,放入cloud.text文件中
def creat_text():
df = pd.read_csv("job_Byte_1.csv")
information = df['描述'].str.replace('、', '.').str.replace(';', ';').str.replace(' ', '').str.replace(',', ',')
# 先进行文本数据处理,将中文符号更换为英文符号,删去空格,便于后续生成词云
file = open('cloud.txt', 'w', encoding='utf-8')
for i in information:
file.write(i)
creat_text()
# 根据提取出来的文本信息生成词云图
def creat_cloud():
with open('cloud.txt', 'r', encoding='utf-8') as fp:
txt = fp.read()
lt = jieba.lcut(txt)
# 使用中文分词库jieba库进行文本数据切片,
# print(lt)
word_text = "".join(lt)
# print(word_text)
cy = wordcloud.WordCloud(font_path="C:\Windows\Fonts\simsun.ttc", background_color='white')
#设定词云呈现的样式,字体为:simsun.ttc,背景图的颜色为白色
cy.generate(word_text)
cy.to_file('result1.png')
# 保存词云图,命名为result1.png
creat_cloud()
运行结果:
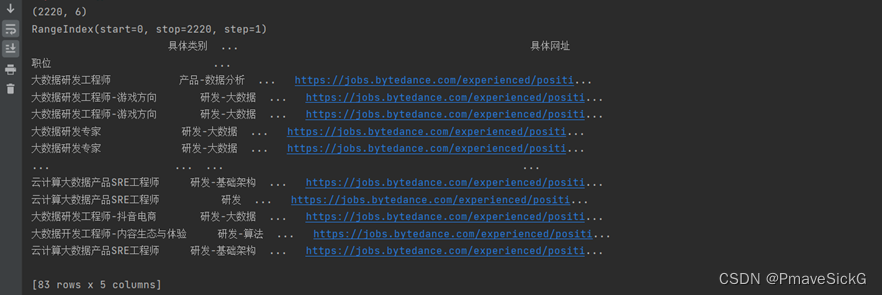
图2.1

图2.2
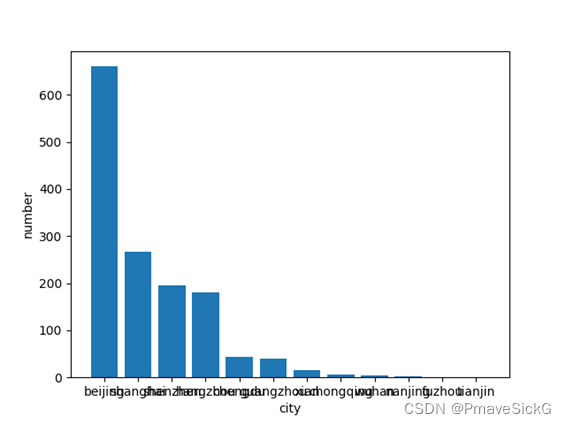
图2.3
图2.2,2.3:以职位的分布地点及对应的职位数量做出以下柱状图,横坐标为地点名称:分别为:北京,上海,深圳,杭州,成都,广州,西安,重庆,武汉,南京,福州,天津纵坐标为各个地区对应的职位数量,从图表中可以看出,主要的职位分布在“北京”达660个职位。
以保存的csv数据的“具体描述”作为文本内容,绘制出图2.4,得到关键信息。

图2.4
三、总结
互联网发展带来网络数据的大规模增长,网络爬虫也需要变得更加迅速、高效,才能达到使用要求,所以分布式爬虫的研究具有一定的实用价值。本文先从分析Scrapy框架的组件及其功能入手,引用了Scrapy-Redis组件实现分布式抓取数据的原理和主流模式。以抓取字节跳动和python相关职位的数据为例,研究了爬行策略、爬虫设计、解析规则对抓取URL等的设计思路。
但是在实际运行过程中出现了令人不满意的问题:
(1)Master主机对爬虫任务的管理并不理想;
(2)使用redis后,网络条件,机器设备异常等不可控因素随之增加,在运行过程中出现过电脑宕机,断网等异常状况,只能重新爬取;
(3)针对去重在实际操作上做的并不理想,在前几次爬取中均出现了数据重复的现象、
本次运用了pandas进行了数据的预处理及pylab,jieba,wordcloud库进行可视化操作。在进行数据清洗过程中,主要遇到的问题就是爬取下来的数据由于英文符号’,’的影响,使csv文件中出现其中一行列属性过多,导致程序出现问题,针对这个问题,本文采用的方式是首先在抓取数据的时候将英文的’,’更改为中文的’,’,其次在pandas处理中在进行一次替换,两次替换下来,数据基本已达到预期可使用的目标。
在进行数据可视化的过程中,制作柱状图设定横纵坐标时中文不识别,针对这个问题先后利用网络资源进行查询解决,更改软件语言设置,但是都没有很好的解决,于是图表的制作采用了全英文的方式呈现。
本文转载自: https://blog.csdn.net/m0_63483888/article/details/136211396
版权归原作者 PmaveSickG 所有, 如有侵权,请联系我们删除。
版权归原作者 PmaveSickG 所有, 如有侵权,请联系我们删除。