
在大数据技术中大数据平台的搭建是必不可少的,从今天开始小编就手把手带大家搭建大数据平台。Hadoop是一个用于处理大数据的分布式集群架构,支持在Linux系统以及Windows系统上进行安装使用,Hadoop集群的搭建涉及多台机器,而在日常学习和个人开发测试过程中,这显然是不现实的,为此我们使用虚拟机软件VMware Workstation在同一台电脑上构建多个Linux虚拟环境,从而进行Hadoop集群的学习和个人测试。
在搭建平台之前首先要准备主机(简单说就是电脑),在实际的生产环境中不可能是一台主机的,但是考虑是学习的情况下我们需要准备一台配置为8代CPU、8GB内存、256GB硬盘或更高配置的电脑来模拟搭建一个完全分布式大数据平台。
本文中所用到的软件及系统版本如下:
VMware Workstation Pro 15
Ubuntu 18.04.5
Xshell 7
Xftp 7
一、VMware Workstation 介绍
VMware Workstation(中文名“威睿工作站”)是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统,和进行开发、测试 、部署新的应用程序的最佳解决方案。VMware Workstation可在一部实体机器上模拟完整的网络环境,以及可便于携带的虚拟机器,其更好的灵活性与先进的技术胜过了市面上其他的虚拟计算机软件。对于企业的 IT开发人员和系统管理员而言, VMware在虚拟网路,实时快照,拖曳共享文件夹,支持 PXE 等方面的特点使它成为必不可少的工具。

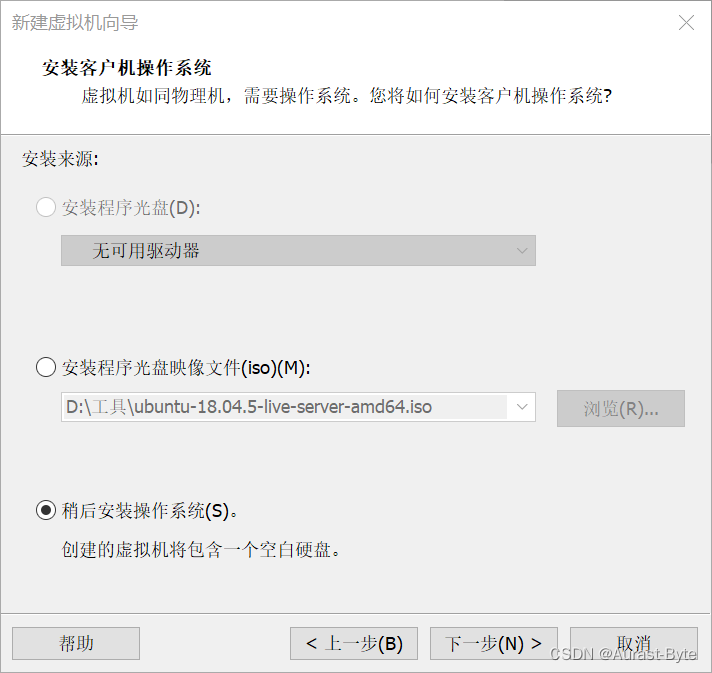
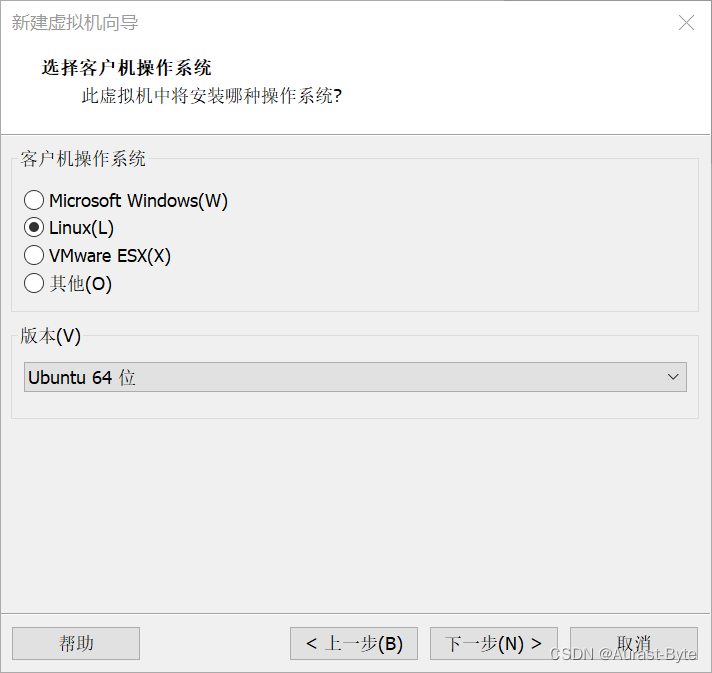
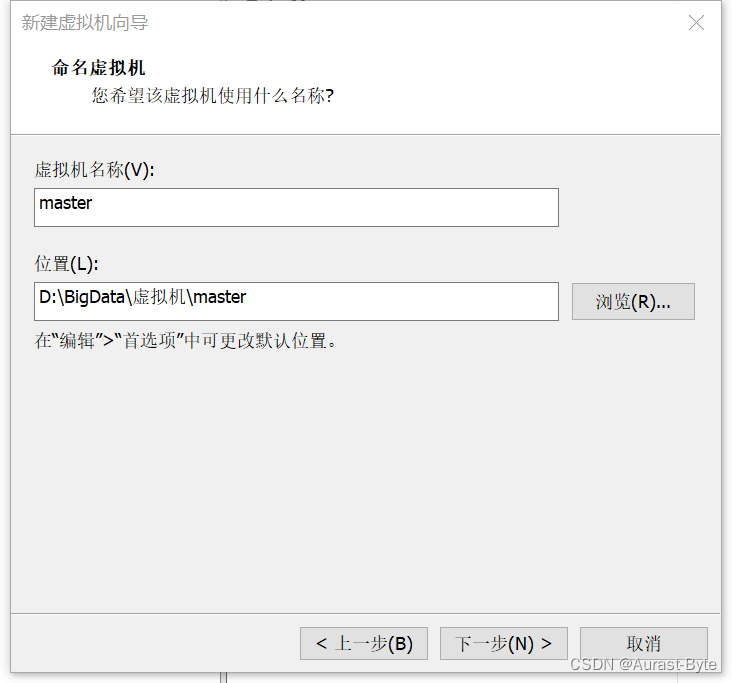
虚拟机安装可以选择合适的位置
二、虚拟网卡配置及系统安装
开始安装Ubuntu server版本
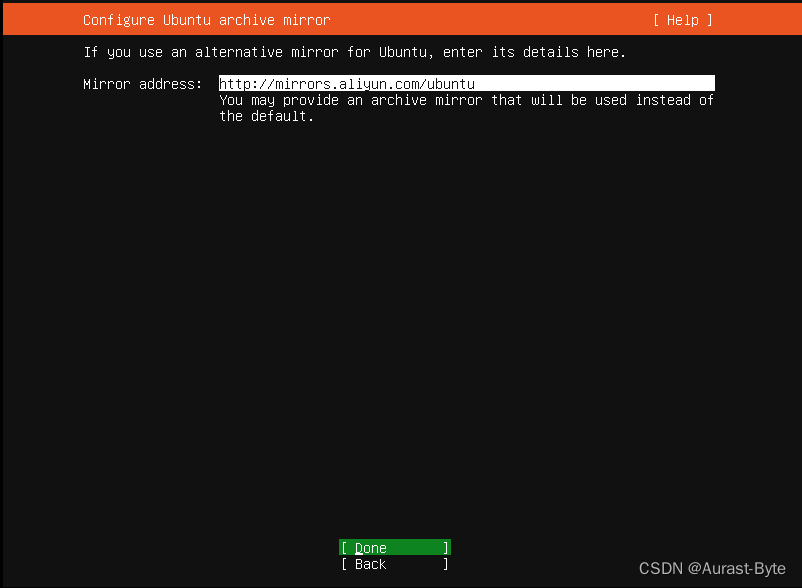
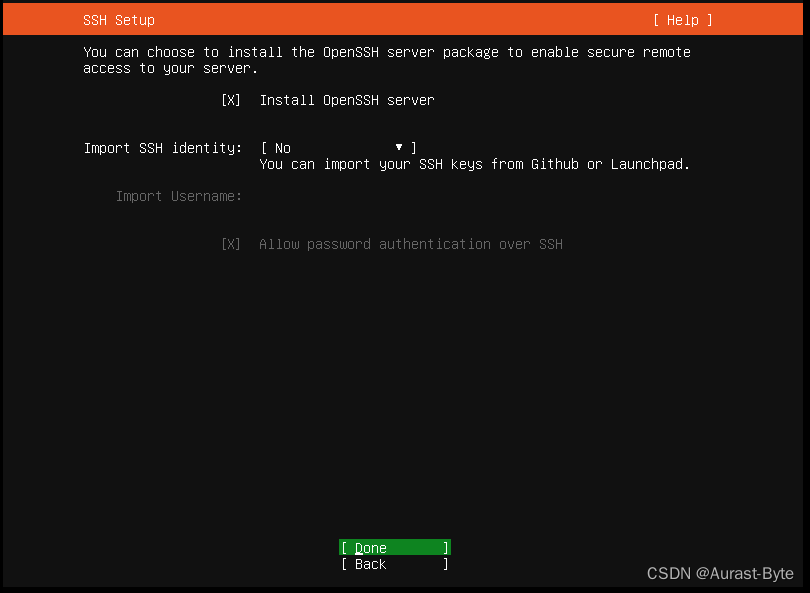
配置网络之前先检测任务管理器中5个关于虚拟机的服务都是开启的。然后,依次点击菜单栏中 编辑-虚拟网络编辑器 配置虚拟机网卡,具体步骤如下
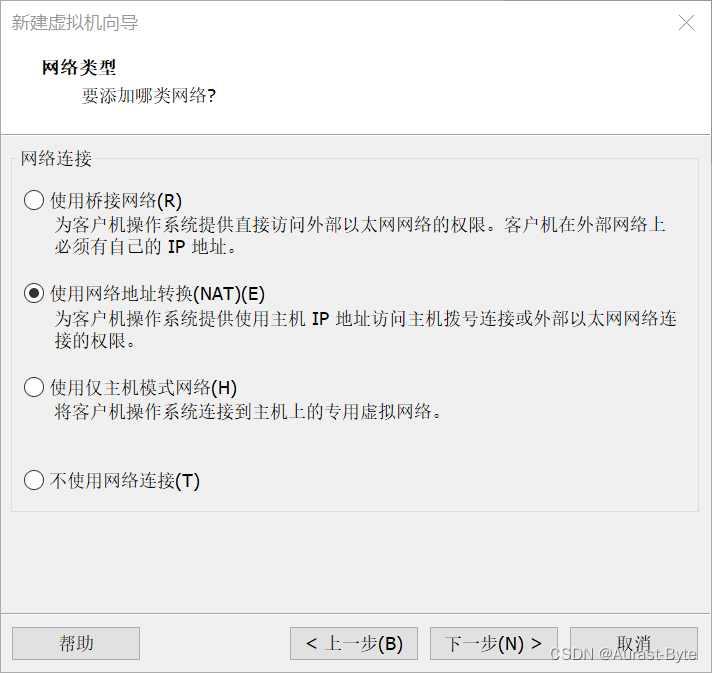
点击图片上方网卡名称中的VMnet8并配置下方的子网IP和子网掩码,子网IP更改为192.168.30.0 ,子网掩码更改为255.255.255.0
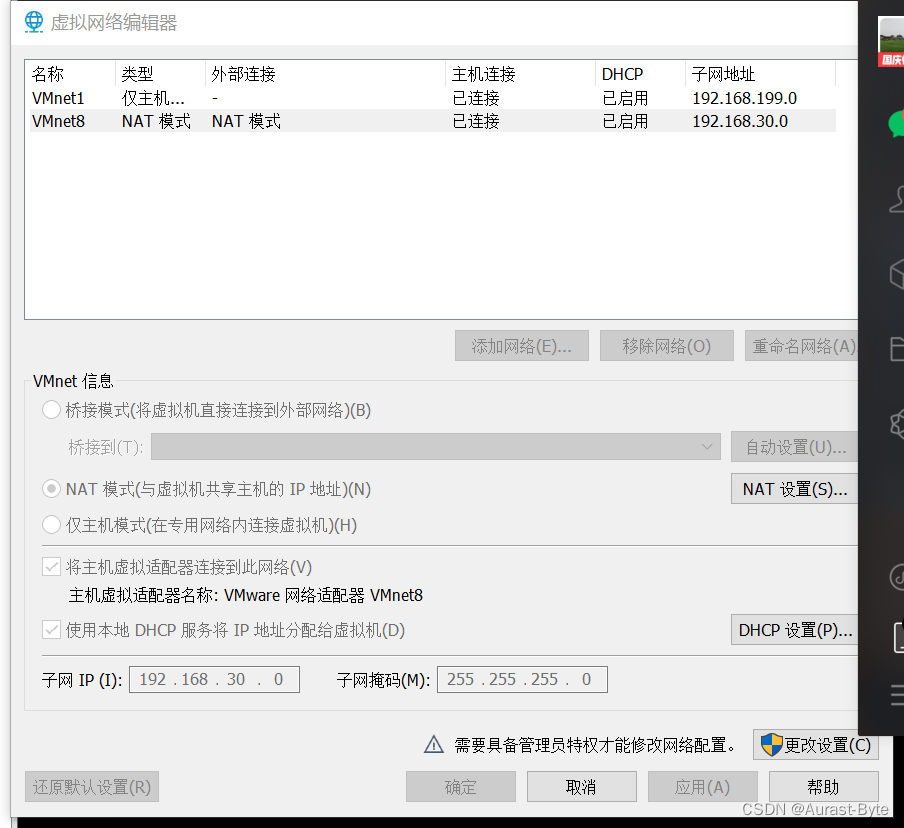
点击上一个图片中部的NAT设置,并配置网关为192.168.30.2,之后点击确定
接着点击第一张图片下方的DHCP设置,并配置起始IP地址和结束IP地址,分别为192.168.30.128和192.168.30.254,然后点击确定
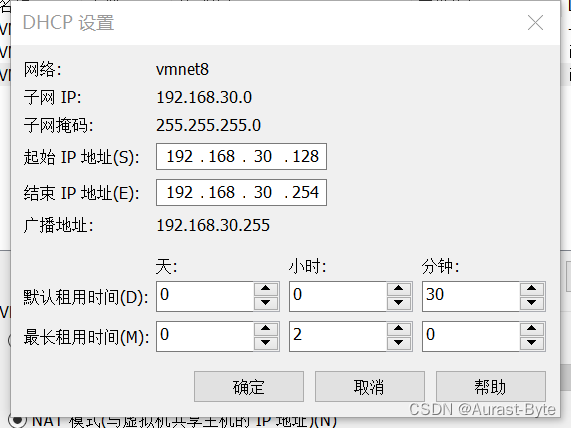
最后点击确定,这样虚拟机网卡就配置好了,然后设置Windows的网络配置 ,右键桌面网络,查看属性,点击更改适配器设置,找到vmnet8,右键看属性 ipv4,
右键看属性 ipv4,
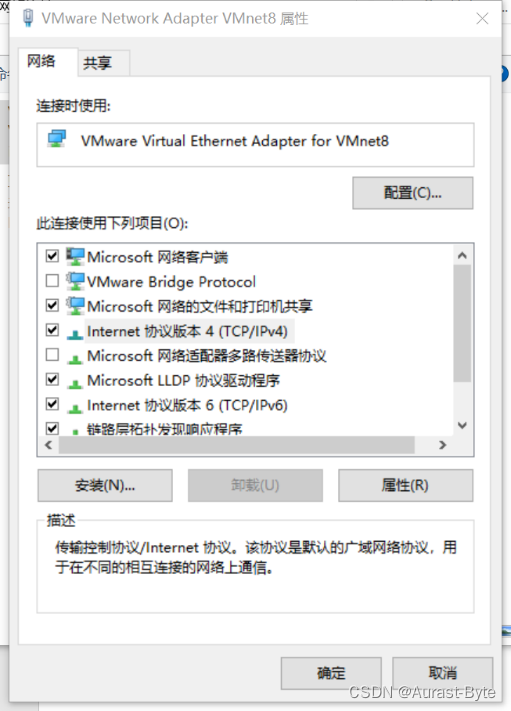
设置IP地址
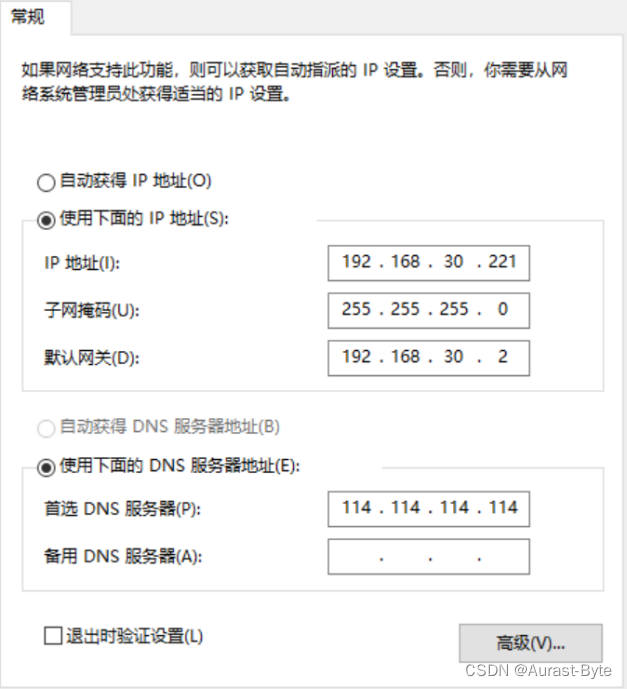
配置好以后点击确定。
修改静态IP地址
sudo vim /etc/netplan/01-network-manager-all.yaml(文件名可能不同),改完保存,
然后sudo netplan apply。
注意yaml语法格式,:之后要加空格
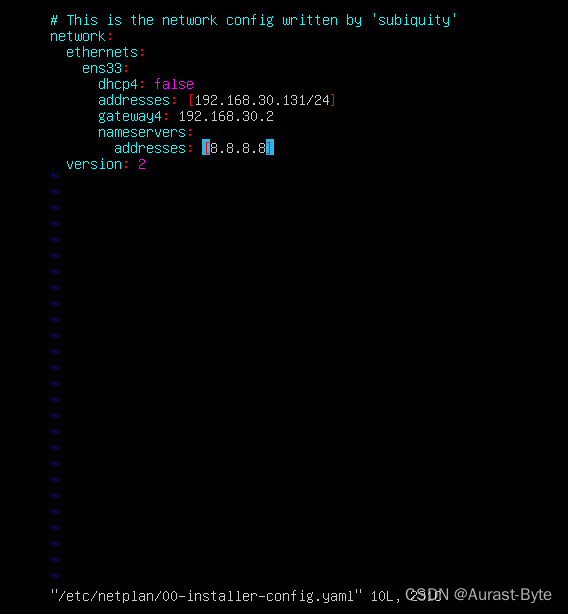
克隆三个节点,master, slave1,slave2
修改主机名 sudo vim /etc/hostname
为什么要设置主机名呢?这是因为在根据master主机克隆的同时把主机名也克隆了,这就导致slave1主机和slave2主机的主机名也为master,因此要进行配置,在slave1,slave2上分别执行
sudo vim /etc/hostname命令并修改master为slave1,slave2
修改IP地址
修改映射 sudo vim /etc/hosts
添加
192.168.30.131 master
192.168.30.132 slave1
192.168.30.133 slave2
为了以后操作方便,我们也为宿主系统配置主机名映射,使用文本编辑器打开 C:\Windows\System32\drivers\etc\host 文件并在文件末尾添加以下配置并保存退出
192.168.30.131 master
192.168.30.132 slave1
192.168.30.133 slave2
修改完主机名和映射以后就可以使用xshell通过ssh协议远程连接linux主机
Xshell中新建三个连接分别命名为master,slave1,slave2,登录用户名为spark000,密码为123456。
下一步就可以在xshell中配置集群内三台主机之间的免密登录。
免密ssh
三个节点分别 生成秘钥ssh-keygen -t rsa
分别在三个节点运行 ssh-copy-id master 全部拷贝至master
进入.ssh 目录 cd .ssh
scp ~/.ssh/authorized_keys slave1:~/.ssh
scp ~/.ssh/authorized_keys slave2:~/.ssh
与此同时系统会让输入slave1主机和slave2主机hadoop用户的密码,这样ssh免密功能就配置好啦,可以在master上尝试 $ ssh slave1 命令 和 $ ssh slave2 命令进行验证是否为免密登录。
做完以上操作后系统的准备工作就做好了,但实际在操作主机时是不会真的在主机上操作,而通常是通过一个远程连接软件来操作主机的,那么我们就来使用XShell软件实现远程登录。
在各个节点的/home/用户名/目录下创建两个文件夹
mkdir software
mkdir servers
修改Ubuntu时区
我选择的是上海的时区 可以修改为BeiJing 根据自己需要进行修改即可
sudo timedatectl set-timezone Asia/Shanghai
在Master上:
上传jdk安装包到software,解压到servers
cd ~/software
tar -zxvf ./jdk-8u201-linux-x64.tar.gz -C ~/servers
mv jdk1.8.0_201 jdk
设置jdk环境变量
vi ~/.bashrc
添加如下代码
export JAVA_HOME=~/servers/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar:.
export PATH=${JAVA_HOME}/bin:$PATH
使得设置生效
source ~/.bashrc
检测是否安装成功
java -version
出现如下版本信息表示jdk安装成功
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
**Hadoop **安装配置
进入Index of /dist/hadoop/common官网下载Hadoop相应版本
上传到software目录
解压到servers
tar -zxvf hadoop-2.7.4.tar.gz -C ~/servers/
重命名文件
mv hadoop-2.7.4/ hadoop
设置环境变量,以后就可以在任意目录下使用Hadoop相关命令
vi ~/.bashrc
添加下面的语句
export HADOOP_HOME=~/servers/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使设置生效
source ~/.bashrc
hadoop version 查看hadoop的版本
在hadoop的目录中,bin目录存放相关的一些服务脚本,但一般用的不多
在etc中存放的配置文件 hadoop要修改的配置文件都在这里
在include中存放的是和C++相关的头文件
在lib中存放的是库文件
在libexec中放的是和shell相关的文件
在sbin中存放的是hadoop的一些管理脚本,用的相对比较多
在share中存放的是jar包
在src中存放的是源码包
Hadoop****中需要配置7个文件
Hadoop-env.sh 配置Hadoop运行所需的环境变量
Yarn-env.sh 配置yarn运行所需的环境变量
Core-site.xml hadoop核心全局配置文件
Hdfs-site.xml hdfs配置文件,继承core-site.xml配置文件
Mapred-site.xml MapReduce配置文件,继承core-site.xml配置文件
Yarn-site.xml yarn配置文件,继承core-site.xml
Slaves 用来配置DataNode节点。
hadoop_env.sh****中
修改
# The java implementation to use.
export JAVA_HOME=/home/spark000/servers/jdk
配置jdk的安装路径
修改core-site.xml
<configuration> 根标签
<property>
<name>fs.defaultFS</name> hadoop集群文件系统的类型
<value>hdfs://master:8020</value> 主节点以及端口
</property>
<property>
<name>hadoop.tmp.dir</name> 临时文件存储目录
<value>/home/spark000/servers/hadoop/tmp</value>
</property>
</configuration>
修改hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
指定secondarynamenode的主机和端口
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name> 指定存储文件副本的数量
<value>2</value>
</property>
mapred-site.xml
复制cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
修改yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>设置yarn的主节点
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
修改yarn-env.sh
找到
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
在下面添加
export JAVA_HOME=~/servers/jdk
修改slaves
配置从节点
添加 slave1 slave2
远程分发
scp -r /servers/hadoop slave1:/servers
scp -r /servers/hadoop slave2:/servers
scp /home/hadoop/.bashrc slave1:~/
scp /home/hadoop/.bashrc slave2:~/
分发完毕以后在每个节点都要执行
source ~/.bashrc
格式化文件系统
hdfs namenode -format
然后再启动集群
如果先启动集群再格式化有可能丢失namenode,需要删除tmp文件夹下所有内容,然后重新进行格式化操作
集群安装spark
**(1)**上传安装包到software
cd /home/spark000/software
解压缩spark到servers
tar -zxvf /home/spark000/software/spark-2.4.0-bin-without-hadoop.tgz -C /home/spark000/servers/
进入servers
cd /home/spark000/servers
重命名spark-2.4.0-bin-without-hadoop
mv spark-2.4.0-bin-without-hadoop spark
在Master节点主机的终端中执行如下命令:
vim ~/.bashrc
添加如下配置
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export SPARK_HOME=/home/spark000/servers/spark
运行source命令,使配置立即生效
source ~/.bashrc
配置slaves文件,将 slaves.template 拷贝到 slaves
$ cd /home/spark000/servers/spark/
$ cp ./conf/slaves.template ./conf/slaves
slaves****文件设置Worker节点。编辑slaves内容,把默认内容localhost替换成如下内容:
slave1
slave2
进入spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vim conf/spark-env.sh
编辑如下内容
export SPARK_DIST_CLASSPATH=$(/home/spark000/servers/hadoop/bin/hadoop )
export HADOOP_CONF_DIR=/home/spark000/servers/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.30.131
export JAVA_HOME=/home/spark000/servers/jdk
配置好后,将Master主机上的/home/spark000/servers/spark文件夹复制到各个节点上在Master主机上执行如下命令:
scp -r /home/spark000/servers/spark spark000@slave1:/home/spark000/servers
scp -r /home/spark000/servers/spark spark000@slave2:/home/spark000/servers
测试是否安装成功
- 启动hadoop集群
- 启动spark集群
在Master节点主机上运行如下命令:
ssh spark000@master "/home/spark000/servers/spark/sbin/start-master.sh"
以启动master节点
ssh spark000@master "/home/spark000/servers/spark/sbin/start-slaves.sh"
以启动slave节点
在Master主机上打开浏览器,访问http://master:8080
(1)关闭Master节点
$ sbin/stop-master.sh
(2)关闭Worker节点
$ sbin/stop-slaves.sh
(3)关闭Hadoop集群
$ sbin/stop-all.sh
版权归原作者 Aurast-Byte 所有, 如有侵权,请联系我们删除。