
Hadoop安装参考:
Hadoop 3.4.0+HBase2.5.8+ZooKeeper3.8.4+Hive4.0+Sqoop 分布式高可用集群部署安装 大数据系列二-CSDN博客
一 下载:
Downloads | Apache Spark
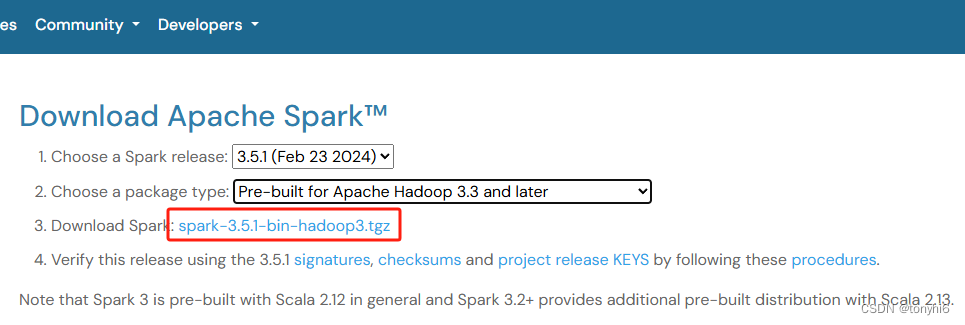
1 下载Maven – Welcome to Apache Maven
# maven安装及配置教程
wget https://dlcdn.apache.org/maven/maven-3/3.8.8/binaries/apache-maven-3.8.8-bin.tar.gz
#
tar zxvf apache-maven-3.8.8-bin.tar.gz
mv apache-maven-3.8.8/ /usr/local/maven
#vi /etc/profile
export MAVEN_HOME=/usr/local/maven
export PATH=$PATH:$MAVEN_HOME/bin
#source /etc/profile
#查看版本
root@slave13 soft]# mvn --version
Apache Maven 3.8.8 (4c87b05d9aedce574290d1acc98575ed5eb6cd39)
Maven home: /usr/local/maven
Java version: 1.8.0_191, vendor: Oracle Corporation, runtime: /usr/local/jdk/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "4.18.0-348.el8.x86_64", arch: "amd64", family: "unix"
2 下载:Scala 2.13.14 | The Scala Programming Language
#解压
tar zxvf scala-2.13.14.tgz
sudo mv scala-2.13.14/ /usr/local/scala
sudo vi /etc/profile
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile
#查看版本
scala -version
Scala code runner version 2.13.14 -- Copyright 2002-2024, LAMP/EPFL and Lightbend, Inc.
3 安装spark
#解压
tar zxvf spark-3.5.1-bin-hadoop3.tgz
sudo mv spark-3.5.1-bin-hadoop3/ /usr/local/spark/
#配置环境变量(slave12,slave13同样配置)
sudo vi /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
source /etc/profile
#配置环境变量
cd /usr/local/spark/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop/
export SPARK_MASTER_HOST=master11
export SPARK_LIBRARY_PATH=/usr/local/spark/jars
export SPARK_WORKER_MEMORY=2048m
export SPARK_WORKER_CORES=2
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8082
export SPARK_DIST_CLASSPATH=$(/data/hadoop/bin/hadoop classpath)
#修改workers配置文件
cp workers.template workers
vim workers
slave12
slave13
#分发文件到slave12,slave13
scp -r /usr/local/spark/ slave12:/usr/local/
scp -r /usr/local/spark/ slave13:/usr/local/
scp -r /usr/local/scala/ slave12:/usr/local/
scp -r /usr/local/scala/ slave13:/usr/local/
二 启动
#master11启动
[root@master11 ~]# /usr/local/spark/sbin/start-all.sh
#报错
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/slf4j/Logger
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.slf4j.Logger
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 7 more
#解决
cd /usr/local/spark/jars/
wget https://repo1.maven.org/maven2/org/slf4j/slf4j-api/1.7.9/slf4j-api-1.7.9.jar
wget https://repo1.maven.org/maven2/org/slf4j/slf4j-nop/1.7.9/slf4j-nop-1.7.9.jar
#启动
[root@master11 ~]# /usr/local/spark/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master11.out
slave12: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave12.out
slave13: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave13.out
#查看 如下图



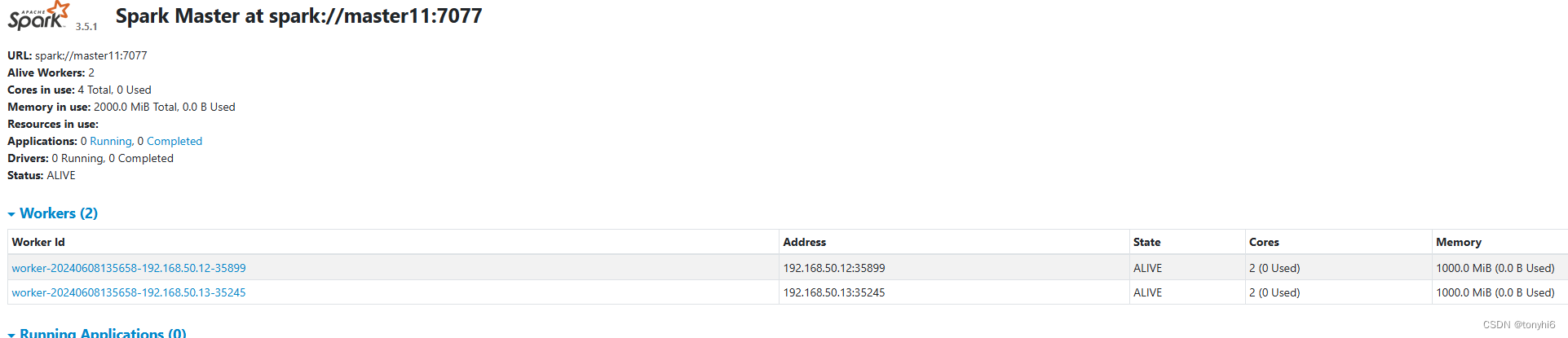
三 Spark 与Hive 集成
1 拷贝配置文件和Mysql 驱动
cp /data/hive/conf/hive-site.xml /usr/local/spark/conf/
cp /data/hadoop/etc/hadoop/hdfs-site.xml /usr/local/spark/conf/
cp /data/hadoop/etc/hadoop/core-site.xml /usr/local/spark/conf/
cp /data/hive/lib/mysql-connector-java-8.0.29.jar /usr/local/spark/jars/
2 登录hive,创建测试表
hive
create database testdb;
use testdb;
create table test(id int,name string) row format delimited fields terminated by ',';
#创建测试文件
cat /root/test.csv
1,lucy
2,lili
#导入数据
load data local inpath '/root/test.csv' overwrite into table test;
3 启动 spark-sql
spark-sql --master spark://master11:7077 --executor-memory 512m --total-executor-cores 2 --driver-class-path /usr/local/spark/jars/mysql-connector-java-8.0.29.jar
spark-sql (default)> show databases;
namespace
default
testdb
Time taken: 2.918 seconds, Fetched 2 row(s)
spark-sql (default)> use testdb;
Response code
Time taken: 0.478 seconds
spark-sql (testdb)> show tables;
namespace tableName isTemporary
test
Time taken: 0.454 seconds, Fetched 1 row(s)
spark-sql (testdb)> select * from test;
id name
1 lcuy
2 lili
Time taken: 4.126 seconds, Fetched 2 row(s)
本文转载自: https://blog.csdn.net/tonyhi6/article/details/139510680
版权归原作者 tonyhi6 所有, 如有侵权,请联系我们删除。
版权归原作者 tonyhi6 所有, 如有侵权,请联系我们删除。