
云布道师
10 月 31 日,杭州云栖大会上,日志服务 SLS 研发负责人简志和产品经理孟威等人发表了《日志服务 SLS 深度解析:拥抱云原生和 AI,基于 SLS 的可观测分析创新》的主题演讲,对阿里云日志服务 SLS 产品服务创新以及背后的技术积累进行了深度解读。
日志服务 SLS 是云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务。日志服务一站式提供数据采集、加工、查询与分析、可视化、告警、消费与投递等功能,全面提升您在开发、运维、运营、安全等场景的数字化能力。
SLS 近一年持续进行技术创新
近期迎来稳定、性能、易用、智能、成本五个方面的全新升级!包括:
- 稳定可靠:同城冗余存储
- 高性能:查询分析引擎升级
- 开放易用:兼容 ES/Kafka,统一易用的 SPL 语法,开箱即用的日志应用
- AI 加持:智能运维基础模型,自动标注人工辅助微调,Copilot 智能问答
- 低成本:按写入数据量计费,热存/低频/归档存储规格
 稳定可靠稳定可靠:同城冗余存储,构建云上同城容灾服务能力 提供机房级容灾能力:当服务终端或者灾难事件导致某个机房不可用时,仍然能够确保继续提供强一致性的服务能力,可满足关键业务系统对于 RPO=0 的强需求。
稳定可靠稳定可靠:同城冗余存储,构建云上同城容灾服务能力 提供机房级容灾能力:当服务终端或者灾难事件导致某个机房不可用时,仍然能够确保继续提供强一致性的服务能力,可满足关键业务系统对于 RPO=0 的强需求。
更高的 SLA 可用性指标:SLS “同城区域冗余”存储能够提供 99.99% 的 可用性 SLA 指标,相比于“本地冗余存储” 99.9% SLA 指标,具有更高的可用性。
一键开通:SLS “同城区域冗余”能够非常方便的构建云上同城容灾服务能力。用户只需要在创建 Project 时,开启“同城区域冗余”存储属性即可。SLS 采用多副本机制自动将用户的数据分散存放在同城相距数十公里的三个不同的可用区内。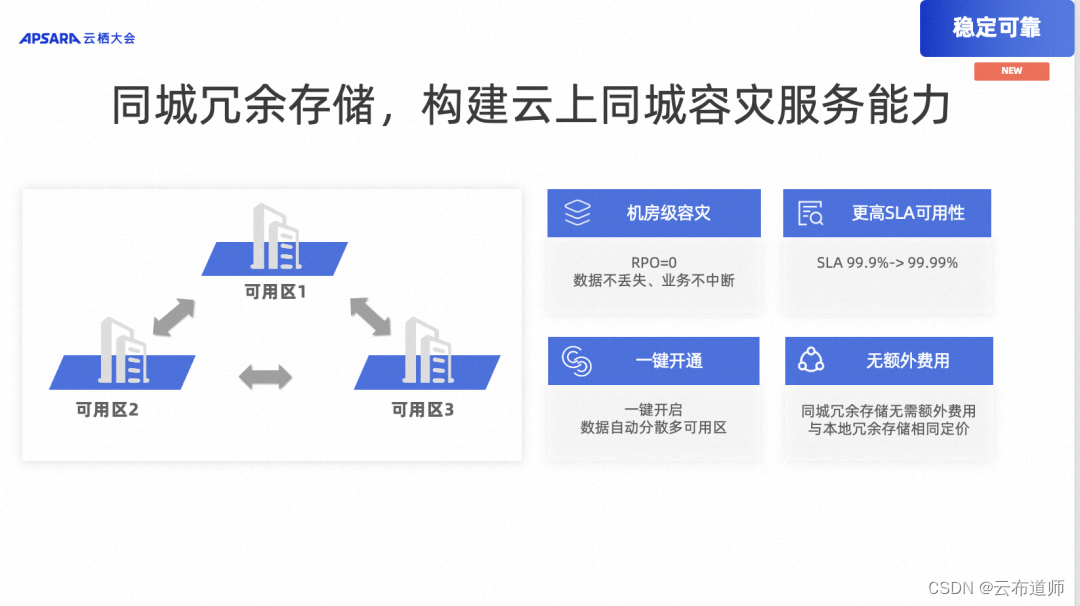
高性能
高性能:查询分析引擎性能升级,加速 SLS 日志数据分析
通过本次升级,SLS 查询分析引擎显著提升 3 个方面性能:
- 查询性能提高 2 倍,每秒查询百亿~千亿行日志
- 分析性能提高 3 倍,每秒处理数十亿行日志
- 单租户最大并发提升 20 倍,内存使用上限提升 10 倍,QPS 最高至 2000,支持更大规模、更复杂查询
与此同时,还为客户带来 4 个方面的新体验:
- 易于使用:提供简单易用的 API,可以轻松地进行数据分析,实时获得计算结果;
- 高性能:基于列存储、向量化计算引擎和内存计算的方式,可秒级处理大量数据的查询分析,支持复杂的 SQL 查询;
- 可扩展性:基于分布式架构和多租户设计,可以在大规模数据集上运行,支持秒级水平扩展,按需弹性扩展出更多计算资源处理更大规模的数据;
- 灵活性:基于秒级响应 API,分析结果所见即所得,可不断调整优化 Query,从任意维度探索分析数据,具有很高的灵活性
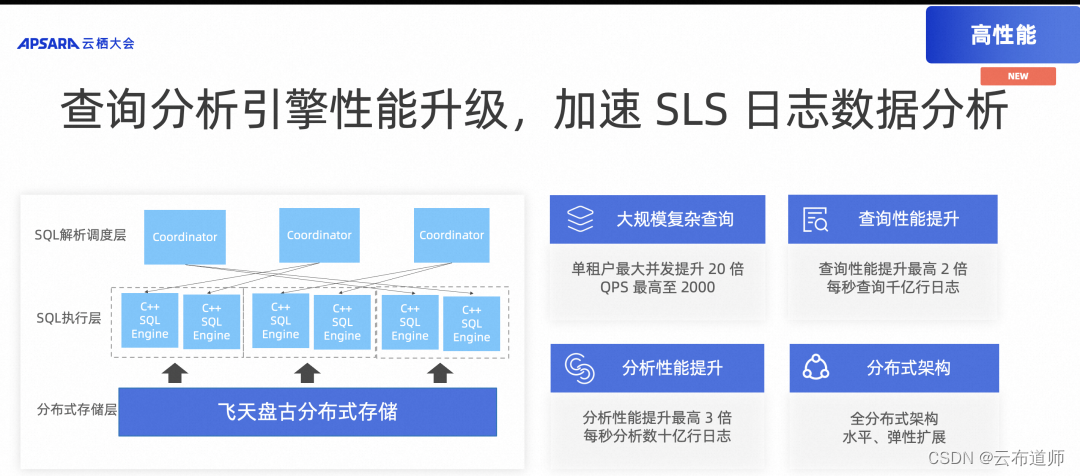 高性能:时序查询分析引擎升级,百万时间线秒级计算
高性能:时序查询分析引擎升级,百万时间线秒级计算
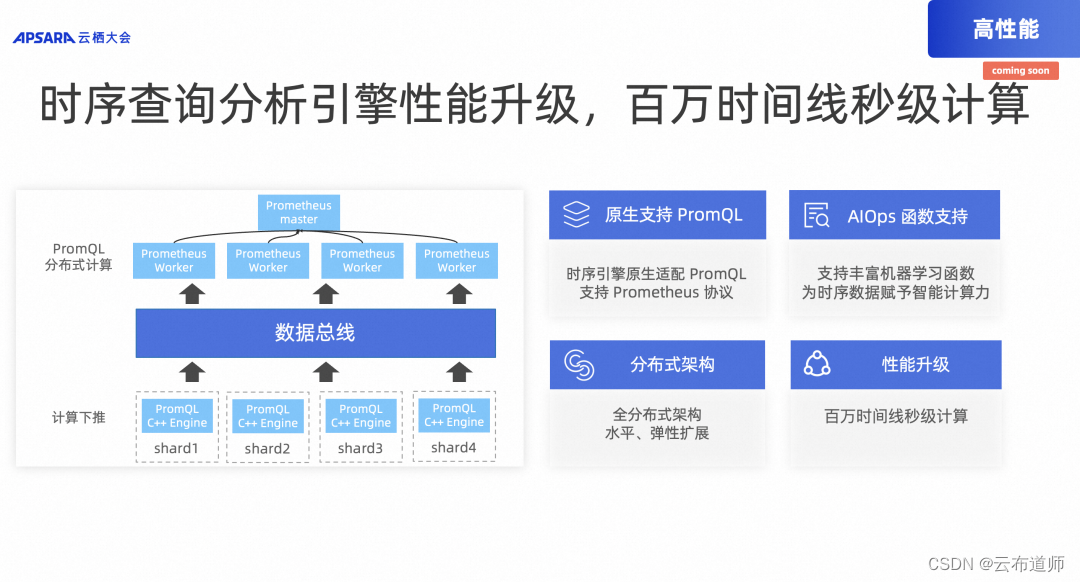
在开源的 Prometheus 中,对于 PromQL 的计算是完全单机、单协程的,这种方式在一些小型企业场景中较为适用。但当集群变大时,参与计算的时间线会剧烈膨胀,这时单机、单协程的计算完全无法满足需求(通常对于一个几十万的时间线,查询几小时都会有十多秒的延迟)。
为此我们在 PromQL 的计算逻辑上,引入了一层并行计算架构,将大部分的计算量分布到 Worker 节点,Master 节点只做最终的结果聚合,同时计算并发数和 Shard 数解耦,存储和计算都可以独立扩缩容。
此次 SLS 时序查询分析引擎升级,百万时间线秒级计算:
- 原生支持 PromQL:时序引擎原生适配 PromQL,支持 Prometheus 协议
- AIOps 函数支持:支持丰富机器学习函数,为时序数据赋予智能计算力
- 性能升级:更智能的聚合写入、全局 Cache、PromQL 分布式计算、计算下推、内置降采样
 开放易用开放易用:查询分析引擎性能升级,加速 SLS 日志数据分析 当您将日志引擎从 Elasticsearch 切换为日志服务时,可能遇到使用习惯以及上下游程序修改问题。为了解决这些问题,日志服务提供了 Elasticsearch 兼容接口,最大程度保障 Elasticsearch 查询分析方案迁移的平滑度,降低将日志引擎从 Elasticsearch 切换为日志服务的使用难度。 日志服务兼容 Elasticsearch API 和 Elasticsearch DSL(Domain Specific Language)语法。日志服务所提供的Elasticsearch 兼容接口,其兼容机制是将 Elasticsearch DSL 查询翻译为日志服务的索引查询和 SQL 分析查询,并且按照 Elasticsearch 的 API 格式规范返回查询分析结果,从而实现 Elasticsearch 的查询协议的兼容。客户无需进行 Query 改造即可将开源 Elasticsearch 迁移至 SLS 平台。
开放易用开放易用:查询分析引擎性能升级,加速 SLS 日志数据分析 当您将日志引擎从 Elasticsearch 切换为日志服务时,可能遇到使用习惯以及上下游程序修改问题。为了解决这些问题,日志服务提供了 Elasticsearch 兼容接口,最大程度保障 Elasticsearch 查询分析方案迁移的平滑度,降低将日志引擎从 Elasticsearch 切换为日志服务的使用难度。 日志服务兼容 Elasticsearch API 和 Elasticsearch DSL(Domain Specific Language)语法。日志服务所提供的Elasticsearch 兼容接口,其兼容机制是将 Elasticsearch DSL 查询翻译为日志服务的索引查询和 SQL 分析查询,并且按照 Elasticsearch 的 API 格式规范返回查询分析结果,从而实现 Elasticsearch 的查询协议的兼容。客户无需进行 Query 改造即可将开源 Elasticsearch 迁移至 SLS 平台。
此外,SLS 开放兼容,支持 ElasticSearch、Kafka、Prometheus、CK 99% 情况下无缝迁移。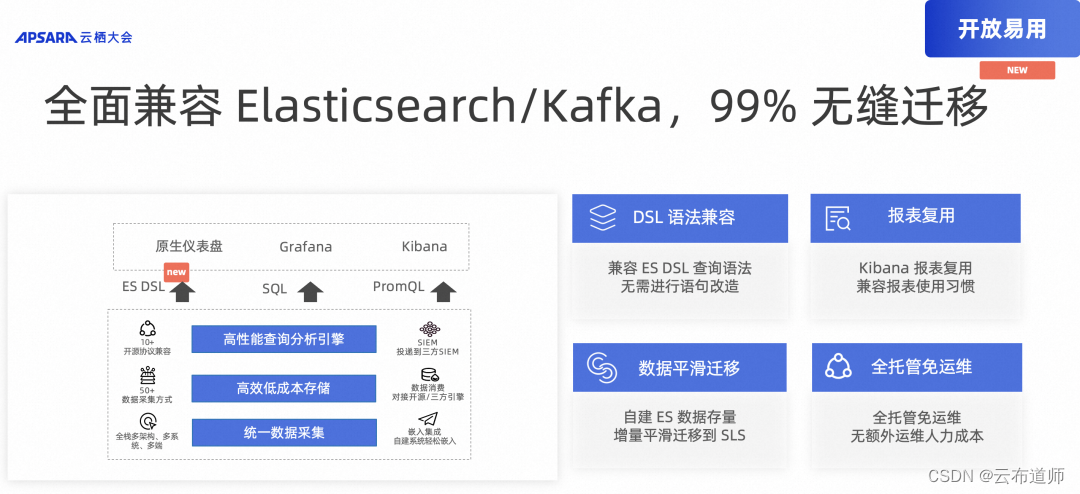
开放易用:日志服务推出功能强大的 SPL 语言,进一步提升日志查询、处理效率
日志服务 SLS 将查询语言升级为 SPL (Search Processing Language):丰富的算子使得弱结构化数据的查询、处理更加简单;支持管道化语法,复杂处理需求也能实现分步求解;使用统一的 SPL 语法,可以玩转日志查询、加工和消费等多项功能。同时,SPL 语言具有如下 5 大优势:
- 管道式语法:SPL 采用类似 Unix Pipeline 语法结构设计,用管道符分别连接查询、过滤、抽取、转换等子语句。对于复杂处理需求,通过逐步计算能更容易写出完整语句。在交互式场景下,SPL 语句更易于调试,更便于探索分析。
- 丰富的算子:SPL 从 SQL 语法中吸收了大量算子,不仅可以用于日志的过滤搜索,还能完成复杂的加工操作,例如正则取值、字段分裂、字段投影、数值计算、编解码等。
- 弱结构化数据友好:对于每一行中字段不整齐的日志数据,常规的 SQL 语言难以应对特殊场景需要,例如丢弃指å定字段、JSON 提取所有未知 Key 为一级字段、按字段值分裂成多行等。SPL 提供了日志场景上广泛应用的加工算子,在弱结构化日志处理上具有更高的灵活性、易用性。
- 适用性广泛:使用统一的 SPL 语言,可以运行在日志服务多个功能上。例如编写一个 SPL 过滤语句,可以用于日志搜索,也可以用于流式消费时过滤下推,并且在数据加工等功能上也将支持 SPL。
- 性能强劲:统一的 SPL 语言运行在高性能处理引擎上,基准过滤场景达到百 MB/s 的单核计算性能。日志服务以分布式集群提供 Serverless 算力,满足大规模数据实时处理性能需要。
综上所述,日志服务推出统一的 SPL 语言,使得日志这类弱结构化数据的查询、处理可以更加易用、灵活、高效。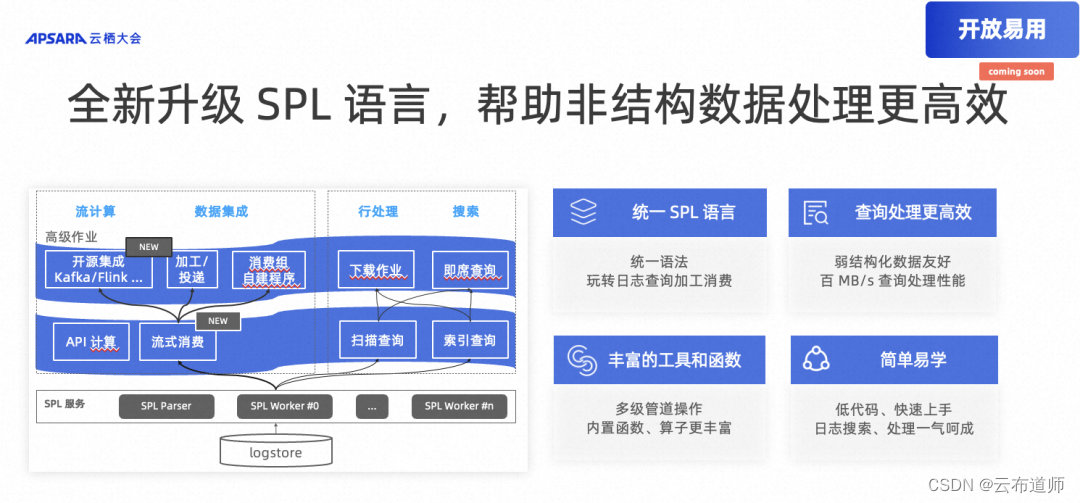
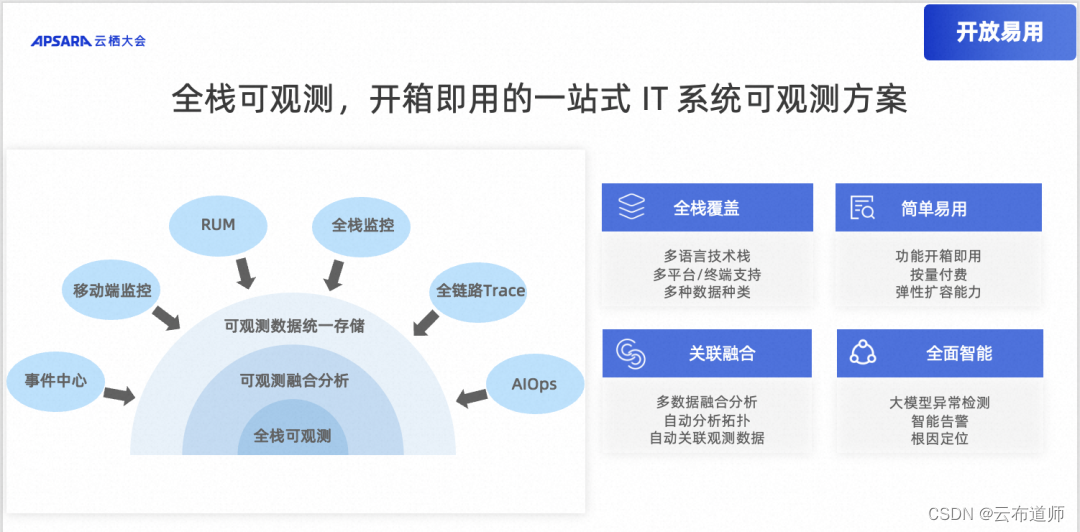
开放易用:全栈可观测,开箱即用的一站式 IT 系统可观测方案
Gartner 报告指出,到 2026 年,成功应用可观测性的企业中,有 70% 的企业将实现更短的决策延迟,从而为目标业务或 IT 流程带来竞争优势。SLS 全新升级全栈可观测应用,提供一站式 IT 系统全链路可观测能力,包括 IT 基础设施监控、全链路 Trace、全链路日志、智能告警等功能,演示如何将 Log、Metric、Trace 等数据进行统一存储和融合分析,并使用 SLS 自动巡检、异常实时通知、根因定位等能力,帮助企业快速定位问题。
- 全栈数据:融合 Trace、全栈监控、用户体验监控(前端/移动端)、性能监控,提供一站式的可观测数据接入方案
- 自动关联:自动计算系统的拓扑,并基于数据与实体关联关系实现所有数据和实体的互相关联
- 统一告警:提供内置的告警和指标巡检,实现统一的事件管理和告警通知
- 智能化:内置 AIOps 套件,实现对指标、Trace、日志的智能分析,同时提供根因分析、Copilot 等高级功能
 日志审计,助力企业 SecOps 云上安全审计
日志审计,助力企业 SecOps 云上安全审计
SLS 提供开箱即用的日志审计服务,自动化实现跨多账号日志审计数据采集及集中存储,帮助客户快速搭建安全审计中心。
- 丰富数据源:自动发现、自动化采集、一键配置 51 种主流产品日志类型
- 跨账号多实例:支持跨账号、多实例统一审计,提供长期、可靠、无篡改的日志记录与审计的中心化存储
- 安全合规:内置近百个 CIS、最佳实践等安全场景监控规则,一键式开启,及时发现不合规行为
- 开放易集成:借助 SLS 查询分析、加工、报表、告警、导出等功能,完整支持审计场景下分析告警对接需求。支持开源、三方 SIEM/SOC 对接
 AI 加持AI 加持,SLS 智能分析能力全新升级 日志服务推出运维领域的基础模型,覆盖 Log、Trace、Metric 等可观测数据场景,支持指标的异常检测、文本的分词标注、Trace 请求的高延时分析,模型提供开箱即用的异常检测、自动标注、分类和根因分析等能力。支持秒级在数千请求内定位到根因,在生产中准确率达 95%以上。自动标注人工辅助微调支持人工标注结果打标修正,模型根据人工反馈自动微调,提升场景准确率。
AI 加持AI 加持,SLS 智能分析能力全新升级 日志服务推出运维领域的基础模型,覆盖 Log、Trace、Metric 等可观测数据场景,支持指标的异常检测、文本的分词标注、Trace 请求的高延时分析,模型提供开箱即用的异常检测、自动标注、分类和根因分析等能力。支持秒级在数千请求内定位到根因,在生产中准确率达 95%以上。自动标注人工辅助微调支持人工标注结果打标修正,模型根据人工反馈自动微调,提升场景准确率。
此外,还提供 Alibaba CloudLens Copilot 大模型助力云设施运维与运营。采用基于大语言模型的 NL2Query 技术,精准理解用户的查询意图,提高查询结果准确性;无需理解复杂的 SQL 语言和查询语法,可准确将自然语言查询转化为 SQL 查询和可视化图表;建立场景化的知识图谱,持续学习,不断优化模型调整和知识库更新,不断改进问题解答的准确性和效果。
低成本
全新按写入数据量计费模式,让 SLS 更普惠、更易用
日志服务 SLS 全新推出按写入数据量计费模式,是一种相比按使用功能计费(原计费方式)购买更简单、费用可预期、场景更丰富的计费方式。
按写入数据量计费模式仅收取原始数据(非压缩)写入费用及 30 天后的存储费用(免费 30 天存储权益)以及外网数据读取费用,超过免费存储周期的数据可继续保存至热存储或低频/归档。
相比于原计费方式,按写入数据量计费的具有4大优势:
- 更省钱:比功能计费更省钱,全索引场景降价高达 32%,增值功能越多降幅越大
- 更易购买:成本模型简单易懂,基于当前业务数据量即可快速评估成本
- 成本更可控:控制使用成本仅考虑业务规模,无需担心其他功能增加费用
- 场景更丰富:仅收取数据写入/存储/读取费用,无需额外费用即可拓展更丰富场景
同时,按写入数据量计费拥有极简计费模式、计费公式更简单。
例如:A 客户每日写入数据量 1GB,数据保存 30 天,按写入数据量计费月目录价=(1GB30)0.4元/GB=12元
新增归档存储,存储成本降幅 86%
除了按写入数据量计费,日志服务 SLS 还全新推出归档存储类型,在现有热存储、低频存储的基础上,为用户提供更低成本且可查询分析的长期数据存储方案。归档存储类型具有3大特性:
- 优化长期存储成本:归档存储价格仅 0.05 元/GB/月,相比热存储价格降幅可达 86%。
- 智能存储分层:多类型存储规格可通过生命周期管理功能实现数据自动分层,配置简便,无须编写脚本或手动迁移数据。
- 实时日志查询分析:归档存储数据可实时访问,无需手动取回或修改应用,无任何取回费用。
通过全新推出的按写入数据量计费和归档存储类型,帮助客户更好的降本增效!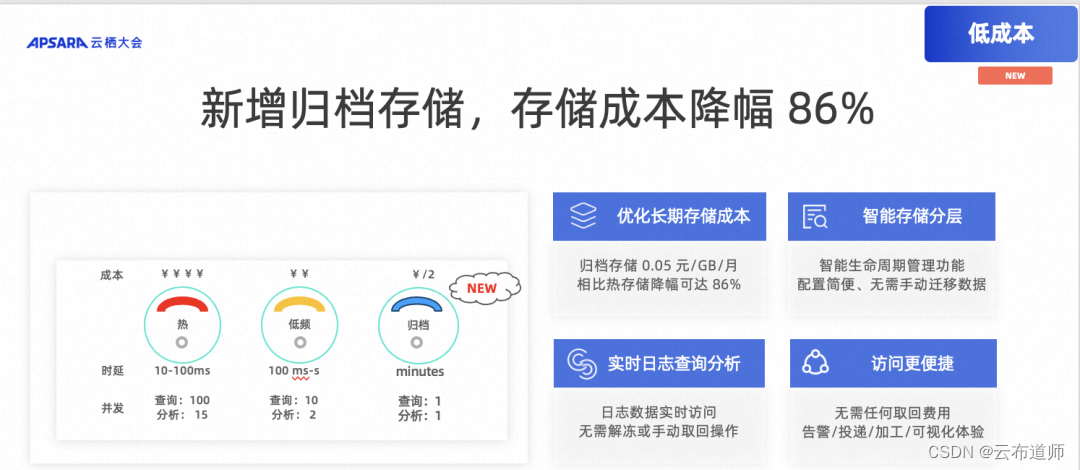
SLS 深度技术解读
SLS 面临的场景与挑战
面向亿级终端、千万级 DAU 数据,我们需要同时应对各种可观测分析、安全分析、大数据系统和大模型的场景和挑战,SLS 如何满足用户需求并提供面向可观测数据分析平台能力?日志服务 SLS 研发负责人、阿里云资深技术专家简志认为,系统的稳定可靠、弹性+低成本、交互式设计是关键,并从架构、存储、处理引擎和上层的应用支撑能力这四个层次解析了SLS 在技术设计方面如何化解这个问题。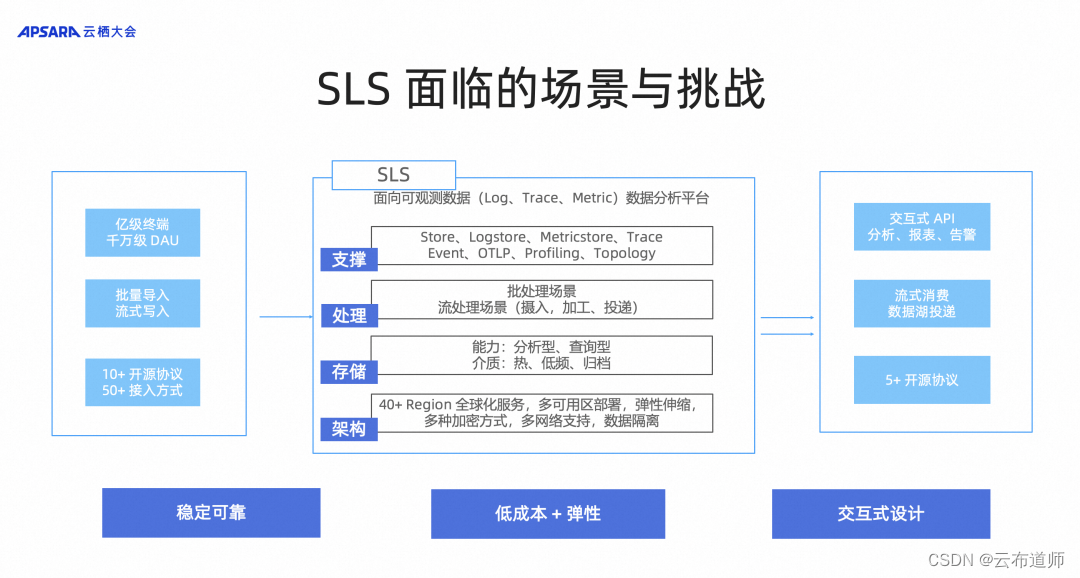
架构:面向高可用设计
首先,让我们来看一下用户数据的生命周期,从数据的生成到最终进入我们的系统,它需要经历哪些过程。对于可观测性数据,在大语言模型的世界中,整个文本可以被视为一个符号,计算机可以理解这个符号,从而能够理解我们所处的物理世界。然而,在 IT 系统中,我们认为 Log、Metric、Trace 数据是让计算机能够感知 IT 系统的关键要素。只有当这些数据能够完整地进入我们的存储系统,并在整个分析过程中得到使用,机器才能够获得完整的 Picture,这也是通向 AIOps 的必经之路。
从整个系统的角度来看,数据从用户端产生到服务端,可能会经历突发的流量情况。在整个网络中,数据可能会经历机器硬件故障和网络链路传输问题,包括从各个可用区采集数据并将其完整存储的过程。我们还需要面对低概率的不可用事件。为了确保数据链路的完整性,我们通过弹性伸缩、精确 Quota 管理、自动负载均衡和多 AZ 架构设计,以及跨 Region 复制能力来提供服务。此外,SLS 和网络团队合作,通过全球自动加速技术,确保设备和数据无论位于全球哪个区域,都能够安全高效地被采集到系统中。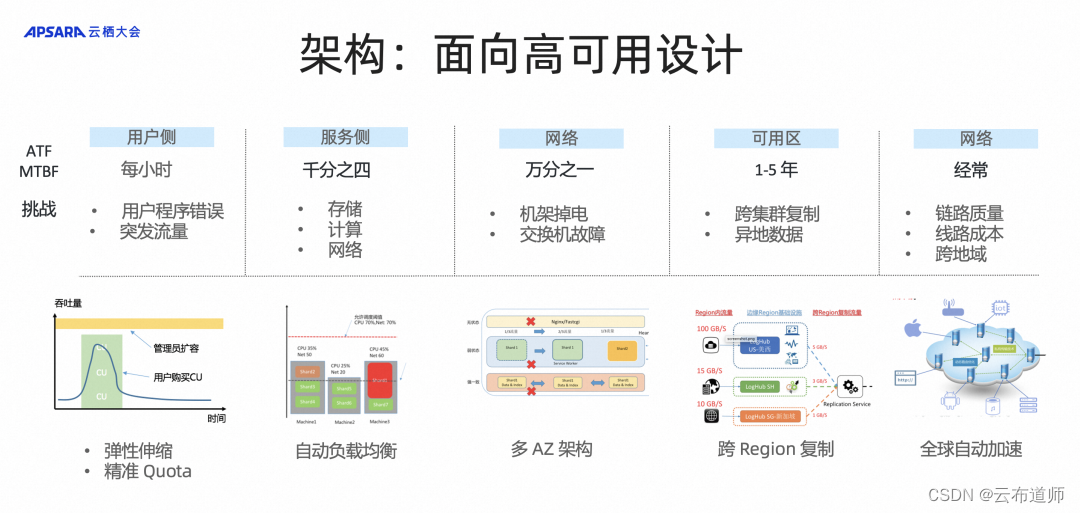
在数据采集到系统后,我们面临一个问题。尽管这类遥测数据(Telementry Data)本身的信息量并不大,但通过大数据技术,我们可以将这些数据进行整合,从而获得一个完整的视图。当然,为了存储这些数据,我们必须将存储成本降低到一定程度。在阿里巴巴操作系统中,我们利用了两个重要的模块来实现这一目标,分别是飞天盘古和对象存储(OSS)。通过飞天盘古和 OSS 的灵活、海量和低成本存储服务,我们可以将热数据存储在更易访问的介质上,支持冷热数据介质管理,降低了海量 OpenTelemetry 数据存储的成本。
此外,SLS 还通过行列混合的编码技术,平衡了存储成本和访问效率。它提供了低成本的归档存储,并且能够提供非常高的查询吞吐量(QPS)。在业务突发场景下,单个查询每秒可达到 2000 的 QPS,从而满足高性能数据分析和查询的需求。
存储:面向 Telementry 场景构建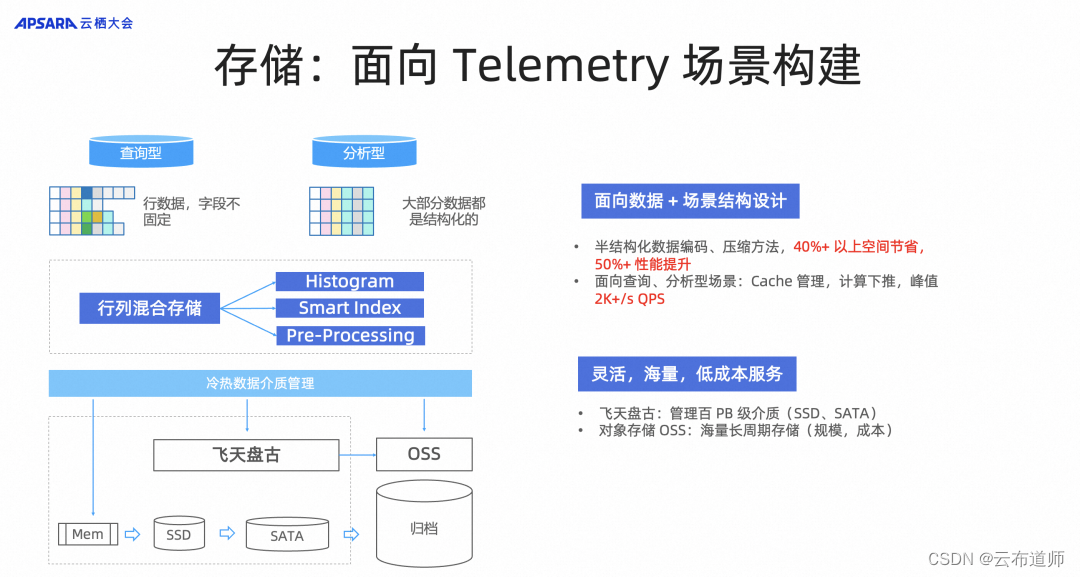
对于这类数据,我们会面临各种不同的处理需求。无论是生成报表、触发告警,还是在大数据系统针对数据进行订阅和流处理,这些都是面向 Telementry 的常见应用场景。在设计过程中,我们充分考虑了程序员、安全团队、运维团队和运营团队的各种需求,因此,我们将整个能力构建为两个系统引擎,一个是流处理引擎,另一个是批处理引擎。这两个引擎基于阿里巴巴的低成本存储和弹性计算能力,可以根据用户的需求和数据规模进行灵活扩展。
在查询语言方面,SLS 已经统一升级为 SPL 管道式语法,在用户查询过程中,我们可以像 Linux 程序员一样,通过非常传统的 pipeline 线性来满足需求。此外,SLS 还考虑了 BI 分析师的基本需求,并支持使用 SQL 标准数据分析语法。用户只需要熟悉一种语言,就可以将其应用于流场景和批场景,从而使整个分析过程更加容易、从容。
处理:流批场景支持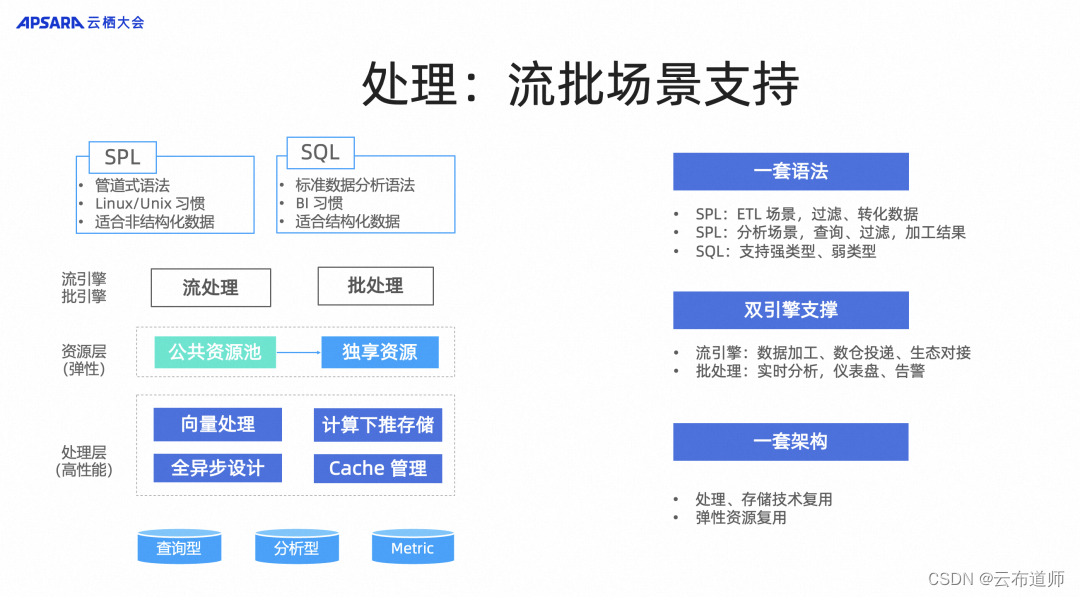
SLS 在可观测性场景中具备强大的兼容能力。过去,我们在搭建系统时,常常需要将数据在多个系统之间流动。例如,在远程采集到数据后,我们需要通过 Queue 进行数据加工,然后将清洗后的数据投递到各种查询系统、指标存储系统和数据湖等。在满足安全需求时,研发人员通常需要通过多个接口获取多份数据,并进行一系列复杂的计算,才能得到最终答案,这个过程非常耗时且费力。
而 SLS 的存储模型充分考虑了各种数据访问的需求,无论是顺序访问、随机检索还是批量访问。通过两个接口,即SQL 和 SPL,我们都可以轻松地获取数据。因此,用户使用 SLS 只需要通过一套 API,就能够满足对于 Log、Metric、Trace 数据和 Kafka 数据等所有分析场景的需求。
同时,为了兼容整个生态系统,SLS 与开源进行合作。既支持通过 SLS 的接口访问数据,也可以通过开源 Elasticsearch、Kafka 和 Prometheus 等访问数据。因此,在 SLS 的设计中,只需要存储一份数据,就能够满足所有场景的需求。
支撑:无孤岛,不搬迁(一份数据、多协议)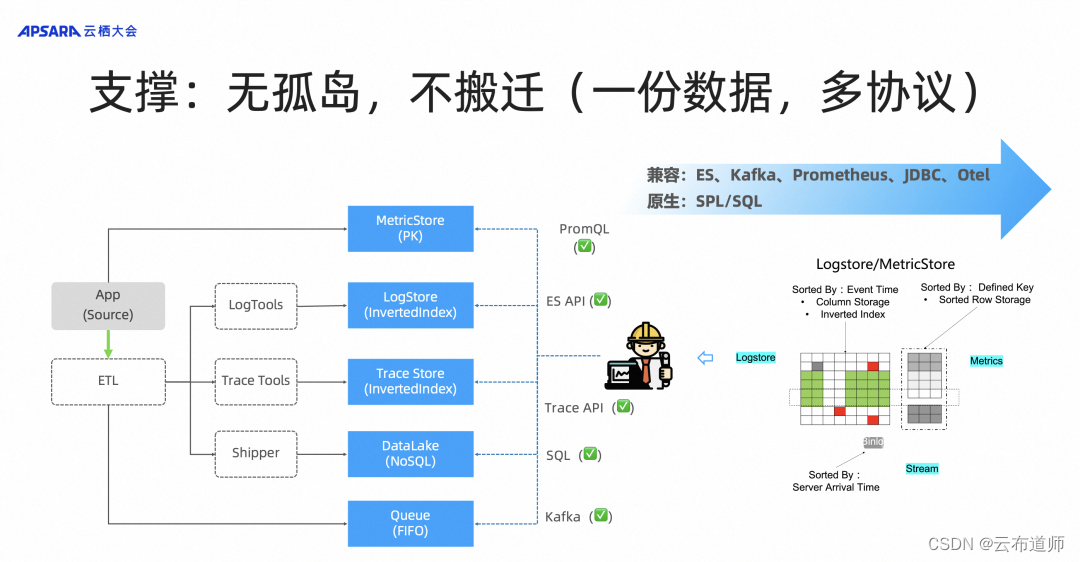
小结
阿里云日志服务 SLS 全面拥抱云原生和 AI,近一年持续进行技术创新,此次云栖大会上发布了在稳定可靠、高性能、开放易用、AI 加持、低成本等五个方面的全面升级。深度解读 SLS 的技术积累,面向高可用设计的架构, 针对 Telementry 场景构建的存储,支持流处理和批处理场景的处理引擎,以及一份数据多协议的上层应用支撑。未来,我们还将持续深耕基于 SLS 的可观测分析创新,为用户提供更好的云原生可观测数据分析平台服务。
版权归原作者 云布道师 所有, 如有侵权,请联系我们删除。