
课程安排


Spring常见注解
web:
- @RequestBody 将Http请求体数据绑定在方法参数上,用于处理json等请求数据
- @ResponseBody 将方法返回值直接写入HTTP响应体内,而不是以视图形式展示,用于处理json等请求数据
- @RequestMapping 映射 HTTP 请求到处理方法或类上,常用于定义 URL 路径- @GetMapping, @PostMapping, @PutMapping, @DeleteMapping, @PatchMapping 映射特定 HTTP 请求方法(GET, POST, PUT, DELETE, PATCH)到处理方法,是@RequestMapping的衍生注解,如@GetMapping相当于@RequestMapping(value = "/depts",method = RequestMethod.GET)。
- @RequestParam 绑定 HTTP 请求参数到方法参数上,- 可以设置默认形参public Result page(@RequestParam(defaultValue = "1") Integer page, @RequestParam(defaultValue = "10") Integer pageSize)- 进行形参与传参名字不一致的参数绑定 当传递参数为image,将其传递到形参file上 public Result upload(@RequestParam(“image”) MultipartFile file)
- @PathVariable 绑定 URL 路径中的变量到方法参数上
- @Companet 组件扫描注解;标注一个类为 Spring 管理的组件,并自动注册到 Spring 容器中(多用来标识mvc三层架构之外的配置类为Spring容器管理组件)
- @Controller 为@companent的衍生注解;用于标识Controller层的类为Spring管理的组件
- @RestController 组合注解,相当于 @Controller 和 @ResponseBody 一般标记在Controller层类上
- @Service 为@companent的衍生注解;用于标识Service层的类为Spring管理的组件
- @Repository 为@companent的衍生注解;用于标识Dao/Mapper层的类为Spring管理组件
- @Autowired 按类型自动装配依赖的组件;
- @Qualifier 按bean对象名称注入依赖的组件,与@Autowired结合使用
- @Resource 按名称或类型注入依赖,是JDK提供的注解
- @Primary 标注一个类优先被注入;当有多个bean满足自动装配时优先选择
- @Bean 标注方法返回值为一个Spring管理的bean对象
- @Transactional 声明式事务管理,用于方法或类上,表明该方法或类为一个事务
- @PostConstruct 标注在方法上,表示在依赖注入完成之后执行该方法
- @Value 注入配置文件当中的配置项到类属性当中
- @@ConfigurationProperties 批量注入配置文件当中的配置项到类属性当中
@Resource和@Autowired的区别
- @Autowired是Spring框架提供的注解;@Resource是JDK提供的注解
- @Autowired默认是按照类型自动装配bean对象,而@Resource是默认按照名称注入依赖。
工具注解
@Data实体类当中自动生成getter setter toString方法(lombok工具包注释)@All/NoArgsConstructor实体类生成全参/无参构造方法(lombok)@Slf4j创建日志对象标签,可以直接使用log.info()在控制台打印日志,相当于声明代码 private static Logger log = LoggerFactory.getLogger(DeptController.class);一般用在Controller层
一、web开发介绍
web网站的工作模式
浏览器输入网址访问前端服务器,前端服务器响应浏览器请求,返回前端代码,前端代码调用后端接口,请求后端服务器,后端服务器处理逻辑,并调用数据库返回数据,最后一起呈现在前端页面上。

web开发要求
- 前端了解一下即可- HTML,CSS,JavaScirpt- Vue,Element,Nginx
- 后端开发- Maven-
SpringBoot- Mysql- SpringBoot Mybatis- SpringBoot web

二、前端技术栈

web前端开发三剑客
- HTML:负责网页的结构
- CSS:负责网页的表现
- JavaScript:负责网页的行为
高级技术
- Vue:JavaScript封装的技术
- Element:Vue封装的技术
1、HTML快速入门

HTML超文本标记语言
- 超文本:除了文字信息,还可以定义图片,音频,视频
- 标记语言:由预先定义好的标签构成的语言
HTML特点:
- HTML标签不区分大小写
- HTML标签属性单双引号皆可
- HTML语法不严谨(自动修复)
<html>
<head>
<title>HTML 快速入门</title>
</head>
<body>
<h1>Hello HTML</h1>
<img src="1.jpg"/>
</body>
</html>
2.1 基础标签

1.img
1). 第一部分,是一张图片,需要用到HTML中的图片标签 来实现。
图片标签: <img>
属性:
src: 指定图像的url (可以指定 绝对路径 , 也可以指定 相对路径)
width: 图像的宽度 (像素 / 百分比 , 相对于父元素的百分比)
height: 图像的高度 (像素 / 百分比 , 相对于父元素的百分比)
备注: 一般width 和 height 我们只会指定一个,另外一个会自动的等比例缩放。
相对路径:
- ./ 表示相对路径,./可以省略
- ../表示上一级路径
2.标题h
2). 第二部分,是一个标题,需要用到HTML中的标题标签
... 来实现。
标题标签: <h1> - <h6>
<h1>111111111111</h1>
<h2>111111111111</h2>
<h3>111111111111</h3>
<h4>111111111111</h4>
<h5>111111111111</h5>
<h6>111111111111</h6>
效果 : h1为一级标题,字体也是最大的 ; h6为六级标题,字体是最小的。
3.水分分割线hr
标题标签: <h1> - <h6>
<h1>111111111111</h1>
<h2>111111111111</h2>
<h3>111111111111</h3>
<h4>111111111111</h4>
<h5>111111111111</h5>
<h6>111111111111</h6>
效果 : h1为一级标题,字体也是最大的 ; h6为六级标题,字体是最小的。
3.水分分割线hr
3). 第三部分,有两条水平分割线,需要用到HTML中的
标签来定义水平分割线。
换行符br
姓名: <input type="text" name="name"> <br><br>
4.超链接a
<a href="..." target="...">央视网</a>
属性:
- href: 指定资源访问的url
- target: 指定在何处打开资源链接- _self: 默认值,在当前页面打开- _blank: 在空白页面打开
5.表格标签table


<!DOCTYPE html>
<html lang="en">
<head>
<title>HTML-表格</title>
<style>
td {
text-align: center; /* 单元格内容居中展示 */
}
</style>
</head>
<body>
<table border="1px" cellspacing="0" width="600px">
<tr>
<th>序号</th>
<th>品牌Logo</th>
<th>品牌名称</th>
<th>企业名称</th>
</tr>
<tr>
<td>1</td>
<td> <img src="img/huawei.jpg" width="100px"> </td>
<td>华为</td>
<td>华为技术有限公司</td>
</tr>
<tr>
<td>2</td>
<td> <img src="img/alibaba.jpg" width="100px"> </td>
<td>阿里</td>
<td>阿里巴巴集团控股有限公司</td>
</tr>
</table>
</body>
</html>
表单标签

form表单标签
表单标签用form标签包裹,且form的method属性表示发送表单的方式,如:post,get
form表单属性:
action: 表单提交的url, 往何处提交数据 . 如果不指定, 默认提交到当前页面
method: 表单的提交方式 .
get: 在url后面拼接表单数据, 比如: ? username=Tom&age=12 , url长度有限制 . 默认值
post: 在消息体(请求体)中传递的, 参数大小无限制的.
get表单提交

post表单提交

表单项
表单项标签主要有三个:
- input
- select
- textarea



<body>
<form action="" method="post">
<!-- 输入框 type="text"-->
姓名: <input type="text" name="name"> <br><br>
<!-- 密码输入框 type="password"-->
密码: <input type="password" name="password"> <br><br>
<!-- 单选框 type="radio" 必须保证两个name都相同才为一组,value表示选择该单选项后实际提交的值-->
性别: <input type="radio" name="gender" value="1"> 男
<!-- lable表示点击lable标签包裹的区域,都会选择;点击“女”也能选中该标签-->
<label><input type="radio" name="gender" value="2"> 女 </label> <br><br>
<!-- 复选框 type="checkbox" 可以选择多个选项,必须保证复选name都相同才为一组,value表示选择该选项后实际提交的值-->
爱好: <label><input type="checkbox" name="hobby" value="java"> java </label>
<label><input type="checkbox" name="hobby" value="game"> game </label>
<label><input type="checkbox" name="hobby" value="sing"> sing </label> <br><br>
<!-- 上传文件:type="file"会出现一个选择文件按钮,name="image"表示自定义选择的文件类型为img图片类型-->
图像: <input type="file" name="image"> <br><br>
<!-- 时间选择:type="date"会出现一个年月日选择器-->
生日: <input type="date" name="birthday"> <br><br>
<!-- 时间选择:type="date"会出现一个时分秒选择器-->
时间: <input type="time" name="time"> <br><br>
<!-- 时间选择:type="datetime-local",即选择年月日+时分秒-->
日期时间: <input type="datetime-local" name="datetime"> <br><br>
<!-- 邮箱格式输入框-->
邮箱: <input type="email" name="email"> <br><br>
<!-- 数字格式输入框-->
年龄: <input type="number" name="age"> <br><br>
<!-- select下拉列表,value表示选择后提交的值-->
学历: <select name="degree">
<option value="">----------- 请选择 -----------</option>
<option value="1">大专</option>
<option value="2">本科</option>
<option value="3">硕士</option>
<option value="4">博士</option>
</select> <br><br>
<!-- 文本域 textarea,cols表示一行可以输入多少字符,row表示可以输入多少行-->
描述: <textarea name="description" cols="30" rows="10"></textarea> <br><br>
<!-- 隐藏域 type="hidden",页面不会显示的区域-->
<input type="hidden" name="id" value="1">
<!-- 表单常见按钮 -->
<!-- button按钮,没有任何效果,可以配合事件监听等效果起作用-->
<input type="button" value="按钮">
<!-- reset,重置表单数据-->
<input type="reset" value="重置">
<!-- submit按钮,提交表单数据(post,get)两种方式-->
<input type="submit" value="提交">
<br>
</form>
</body>
2、 CSS样式

CSS层叠样式表
- 控制页面的样式
1.CSS引入方式
- 行内样式:写在style属性当中
<!--css方式一:行内样式--><h1 style="color: red">焦点访谈:中国底气 新思想夯实大国粮仓</h1>- 内嵌样式:写在style标签当中(通常约定写在head标签当中)
<!-- 方式2:内嵌样式,h1标签的所有属性都为red--><style> h1 { color: red; }</style>- 外联样式:写在一个单独的.css文件当中(通过link标签在网页中引入,一般写在head内)
<!-- 方式三:外联样式--><link rel="stylesheet" href="./css/news.css">
2. 颜色表示
在前端程序开发中,颜色的表示方式常见的有如下三种:

- 关键字表示法:预定义的颜色名,如red、green、blue
- rgb表示法:红绿蓝三原色,每项取值范围:0-25,如rgb(0,0,0)、rgb(255,255,255)、rgb(255,0,0)
- 十六进制表示法:#开头,将数字转换成十六进制表示,每两位按顺序分别表示红绿蓝(00~ff),且可以简化#000000、#ff0000、#cccccc,简写:#000、#ccc
3.CSS选择器

- 元素(标签)选择器:
- 选择器的名字必须是标签的名字
- 作用:选择器中的样式会作用于所有同名的标签上
元素名称 {
css样式名:css样式值;
}
案例如下:
div{
color: red;
}
标签没有任何作用,一般用于搭配css元素选择器选择性设置span内的样式
id选择器
选择器的名字前面需要加上#
作用:选择器中的样式会作用于指定id的标签上,而且有且只有一个标签(由于id是唯一的)
#id属性值 {
css样式名:css样式值;
}
例子如下:
#did {
color: blue;
}
- 类选择器
- 选择器的名字前面需要加上 .
- 选择器中的样式会作用于所有class的属性值和该名字一样的标签上,可以是多个
.class属性值 {
css样式名:css样式值;
}
当三种css选择器指定同一个标签,优先展示
类选择器>id选择器>元素选择器
ID选择器只能选择一个元素具有唯一性,而类选择器可以选择多个元素
4.盒子模型
css盒子模型会大量使用div,span两个没有意义的标签去自定义样式



<style>
div {
width: 200px; /* 宽度 */
height: 200px; /* 高度 */
box-sizing: border-box; /* 指定width height为盒子的高宽 */
background-color: aquamarine; /* 背景色 */
padding: 20px 20px 20px 20px; /* 内边距, 上 右 下 左 , 边距都一行, 可以简写: padding: 20px;*/
border: 10px solid red; /* 边框, 宽度 线条类型 颜色 */
margin: 30px 30px 30px 30px; /* 外边距, 上 右 下 左 , 边距都一行, 可以简写: margin: 30px; */
}
</style>
padding
表示内边距的大小,有四个值,分别表示上 右 下 左 边距,可以简写成两位表示上下和左右边距,简写成一行表示上下左右边距都一样
3、 JavaScript
javaScript控制网页的行为
JavaScript是一门跨平台、面相对象的脚本语言。(不需要编译可直接执行)

JavaScript引入方式

1.第一种方式:内部脚本
<Script>
,将JS代码定义在HTML页面中(可以定义在任意位置)
例子:
<script>
alert("Hello JavaScript")
</script>
2.第二种方式:外部脚本将, JS代码定义在外部 JS文件中,然后引入到 HTML页面中
- 外部JS文件中,只包含JS代码,不包含是<script>标签
- 引入外部js的<script>标签,必须是双标签
例子:
<script src="js/demo.js"></script>
注意:demo.js中只有js代码,没有<script>标签
JavaScript基础语法

1.输出语句

<script>
/* alert("JS"); */
// 方式一: 弹出警告框
window.alert("hello js");
//方式二: 写入html页面中
document.write("hello js");
// 方式三: 控制台输出
console.log("hello js");
</script>



2.变量

在js中声明变量还需要注意如下几点:
- JavaScript 是一门
弱类型语言,变量可以存放不同类型的值 。 - 变量名需要遵循如下规则:- 组成字符可以是任何字母、数字、下划线(_)或美元符号($)- 数字不能开头- 建议使用驼峰命名
变量类型:
- var定义关键字,为全局变量,且可以重复定义,可以覆盖掉原本的值
var x = 'A'var x = 1document.write(x); // 1- let:相比较var,let只在代码块内生效,且不能重复定义
- const:声明常量的,常量一旦声明,不能修改
3.数据类型

使用
typeof
函数可以返回变量的数据类型
<script>
//原始数据类型
alert(typeof 3); //number
alert(typeof 3.14); //number
alert(typeof "A"); //string
alert(typeof 'Hello');//string
alert(typeof true); //boolean
alert(typeof false);//boolean
alert(typeof null); //object
var a ;
alert(typeof a); //undefined
</script>
4.运算符
运算规则运算符算术运算符+ , - , * , / , % , ++ , --赋值运算符= , += , -= , *= , /= , %=比较运算符> , < , >= , <= , != , == , = 注意 == 会进行类型转换,= 不会进行类型转换逻辑运算符&& , || , !三元运算符条件表达式 ? true_value: false_value
函数

- 形参不需要类型,因为JavaScript是弱类型语言
- 返回值也不需要定义类型,直接在函数内部return即可
js基本对象

1.Array对象

<script>
//定义数组
var arr = new Array(1,2,3,4);
var arr = [1,2,3,4];
//获取数组中的值,索引从0开始计数
console.log(arr[0]);
console.log(arr[1]);
</script>
与java中不一样的是,JavaScript中数组相当于java中的集合,数组的长度是可以变化的。而且JavaScript是弱数据类型的语言,所以
数组中可以存储任意数据类型的值
。
//特点: 长度可变 类型可变
var arr = [1,2,3,4];
arr[10] = 50;
// console.log(arr[10]);
// console.log(arr[9]);
// console.log(arr[8]);
arr[9] = "A";
arr[8] = true;
console.log(arr);

2.Array属性和方法
属性:
- length:设置或返回数组中元素的数量
var arr = [1,2,3,4];arr[10] = 50; for (let i = 0; i < arr.length; i++) { console.log(arr[i]);}
方法:
- forEach():遍历数组中的每个有值得元素,并调用一次传入的函数
//e是形参,接受的是数组遍历时的值arr.forEach(function(e){ console.log(e);})arr.forEach((e) => { console.log(e);})- push():将新元素添加到数组的末尾,并返回新的长度
//push: 添加元素到数组末尾arr.push(7,8,9);console.log(arr);- splice():从数组中删除元素
//splice: 删除元素arr.splice(2,2);console.log(arr);
3.string字符串对象

- length属性:length属性可以用于返回字符串的长度,添加如下代码:
//lengthconsole.log(str.length); - charAt()函数:charAt()函数用于返回在指定索引位置的字符,函数的参数就是索引。添加如下代码:
console.log(str.charAt(4)); - indexOf()函数indexOf()函数用于检索指定内容在字符串中的索引位置的,返回值是索引,参数是指定的内容。添加如下代码:
console.log(str.indexOf("lo")); - trim()函数trim()函数用于去除字符串两边的空格的。添加如下代码:
var s = str.trim();console.log(s.length); - substring()函数substring()函数用于截取字符串的,函数有2个参数。参数1:表示从那个索引位置开始截取。包含参数2:表示到那个索引位置结束。不包含
console.log(s.substring(0,5));
4.JavaScript自定义对象

var 对象名 = {
属性名1: 属性值1,
属性名2: 属性值2,
属性名3: 属性值3,
函数名称: function(形参列表){}
};
函数定义可以简化为:
函数名称(形参列表){}
我们可以通过如下语法调用属性:
对象名.属性名
通过如下语法调用函数:
对象名.函数名()
Json对象
JSON对象:JavaScript Object Notation,JavaScript对象标记法。是通过JavaScript标记法书写的文本。
{
"key":value,
"key":value,
"key":value
}
如下图所示:前后台交互时,我们需要传输数据,但是java中的对象我们该怎么去描述呢?我们可以使用如图所示的xml格式

但是xml格式存在如下问题:
- 标签需要编写双份,占用带宽,浪费资源
- 解析繁琐
使用Json对象传递数据能很好的解决这个问题

var jsonstr = '{"name":"Tom", "age":18, "addr":["北京","上海","西安"]}'; // 字符串类型,需要把它转为Json对象
var jsObject = Json.parse(jsonstr) // 转为Json对象
name = jsonstr.name //调用该方法获取Json对象的name属性值
JSON.stringify(jsObject) //该方法将Json对象转为Json字符串
BOM对象
BOM的全称是Browser Object Model,翻译过来是浏览器对象模型。也就是JavaScript
将浏览器的各个组成部分
封装成了对象。

window对象

及alert(“Hello world”)详细就是window.alert(),
window.
可以省略

- alert()函数:弹出警告框,函数的内容就是警告框的内容
<script> //window对象是全局对象,window对象的属性和方法在调用时可以省略window. window.alert("Hello BOM"); alert("Hello BOM Window");</script>浏览器打开,依次弹框,此处只截图一张
- confirm()函数:弹出确认框,并且提供用户2个按钮,分别是确认和取消。添加如下代码:
confirm("您确认删除该记录吗?");浏览器打开效果如图所示: 但是我们怎么知道用户点击了确认还是取消呢?所以这个函数有一个返回值,当用户点击确认时,返回true,点击取消时,返回false。我们根据返回值来决定是否执行后续操作。修改代码如下:再次运行,可以查看返回值true或者false
但是我们怎么知道用户点击了确认还是取消呢?所以这个函数有一个返回值,当用户点击确认时,返回true,点击取消时,返回false。我们根据返回值来决定是否执行后续操作。修改代码如下:再次运行,可以查看返回值true或者falsevar flag = confirm("您确认删除该记录吗?");alert(flag); - setInterval(fn,毫秒值):定时器,用于周期性的执行某个功能,并且是循环执行。该函数需要传递2个参数:fn:函数,需要周期性执行的功能代码毫秒值:间隔时间注释掉之前的代码,添加代码如下:
//定时器 - setInterval -- 周期性的执行某一个函数var i = 0;setInterval(function(){ i++; console.log("定时器执行了"+i+"次");},2000);刷新页面,浏览器每个一段时间都会在控制台输出,结果如下:
- setTimeout(fn,毫秒值) :定时器,只会在一段时间后执行一次功能。参数和上述setInterval一致注释掉之前的代码,添加代码如下:
//定时器 - setTimeout -- 延迟指定时间执行一次 setTimeout(function(){ alert("JS");},3000);浏览器打开,3s后弹框,关闭弹框,发现再也不会弹框了。
Location对象
浏览器地址栏对象

alert(location.href);
// 将窗口的url更改为https://www.itcast.cn并跳转到该地址
location.href = "https://www.itcast.cn";
DOM对象
DOM:Document Object Model 文档对象模型。也就是 JavaScript 将 HTML 文档的各个组成部分封装为对象。

DOM对象将HTML文档的每一部分都封装成对象
- Document:整个文档对象
- Element:元素对象
- Attribute:属性对象
- Text:文本对象
- Comment:注释对象
1.获取DOM元素对象

- document.getElementById(): 根据标签的id属性获取标签对象,id是唯一的,所以获取到是单个标签对象。添加如下代码:
<script>//1. 获取Element元素//1.1 获取元素-根据ID获取 var img = document.getElementById('h1'); alert(img);</script>浏览器打开,效果如图所示:从弹出的结果能够看出,这是一个图片标签对象
- document.getElementsByTagName() : 根据标签的名字获取标签对象,同名的标签有很多,所以返回值是数组。添加如下代码:
//1.2 获取元素-根据标签获取 - divvar divs = document.getElementsByTagName('div');for (let i = 0; i < divs.length; i++) { alert(divs[i]);}浏览器输出2次如下所示的弹框
- document.getElementsByName() :根据标签的name的属性值获取标签对象,name属性值可以重复,所以返回值是一个数组。添加如下代码:
//1.3 获取元素-根据name属性获取var ins = document.getElementsByName('hobby');for (let i = 0; i < ins.length; i++) { alert(ins[i]);}浏览器会有3次如下图所示的弹框:
- document.getElementsByClassName() : 根据标签的class属性值获取标签对象,class属性值也可以重复,返回值是数组。添加如下图所示的代码:
//1.4 获取元素-根据class属性获取var divs = document.getElementsByClassName('cls');for (let i = 0; i < divs.length; i++) { alert(divs[i]);}浏览器会弹框2次,都是div标签对象
获取到HTML元素对象之后,如何获取属性并对其操作呢

将页面的传智教育修改为传智教育666,只需要获取传智教育文本的对象,修改其文本并展现即可
获取2个div中的第一个,所以可以通过下标0获取数组中的第一个div,注释之前的代码,编写如下代码:
var divs = document.getElementsByClassName('cls');
var div1 = divs[0];
div1.innerHTML = "传智教育666";
js事件监听
什么是事件呢?HTML事件是发生在HTML元素上的 “事情”,例如:
- 按钮被点击
- 鼠标移到元素上
- 输入框失去焦点
而我们可以给这些事件绑定函数,当事件触发时,可以自动的完成对应的功能。这就是
事件监听
。
1.事件绑定

JavaScript对于事件的绑定提供了2种方式:
- 方式1:通过html标签中的事件属性进行绑定
例如一个按钮,我们对于按钮可以绑定单机事件,可以借助标签的onclick属性,属性值指向一个函数。
<input type="button" id="btn1" value="事件绑定1" οnclick="on()">
<script>
function on(){
alert("按钮1被点击了...");
}
</script>
- 方式2:通过DOM中Element元素的事件属性进行绑定
html中的标签被加载成element对象,所以我们也可以通过element对象的属性来操作标签的属性。
<input type="button" id="btn2" value="事件绑定2">
我们可以先通过id属性获取按钮对象,然后操作对象的onclick属性来绑定事件,代码如下:
document.getElementById('btn2').onclick = function(){
alert("按钮2被点击了...");
}
需要注意的是:事件绑定的函数,只有在事件被触发时,函数才会被调用。
2.常见事件
上面案例中使用到了
onclick
事件属性,那都有哪些事件属性供我们使用呢?下面就给大家列举一些比较常用的事件属性
事件属性名说明onclick鼠标单击事件onblur元素失去焦点onfocus元素获得焦点onload某个页面或图像被完成加载onsubmit当表单提交时触发该事件onmouseover鼠标被移到某元素之上onmouseout鼠标从某元素移开
- onfocus:获取焦点事件,鼠标点击输入框,输入框中光标一闪一闪的,就是输入框获取焦点了

- onblur:失去焦点事件,前提是输入框获取焦点的状态下,在输入框之外的地方点击,光标从输入框中消失了,这就是失去焦点。

4、Vue

什么是双向绑定,及vue的框架由
view视图层 View-model视图模型层 Model模型层
三层组成,当view视图层发生变化时,Model模型层也会随之发生变化,当Model模型层发生变化时view视图层也会随之发生变化,这就称为
双向绑定

model模型层
<script>
//定义Vue对象
new Vue({
el: "#app", //vue接管区域
data:{
message: "Hello Vue"
}
})
</script>
view视图层
<body>
<div id="app">
<input type="text" v-model="message">
{{message}}
</div>
</body>
通过视图层的v-model="message",将视图层的{{message}}与模型层的data:{ message: "Hello Vue" }
绑定,及在初始情况下,输入框中会显示
message
的初始值,即 "Hello Vue"。当你在输入框中输入新的文本时,Vue 会自动更新
message
的值,并且
{{message}}
中的插值表达式也会相应地更新以反映
message
的当前值。这就时一个简单的双向绑定。
Vue的常见指令

1.v-bind和v-model

v-bond 用于动态地将一个或多个 HTML 属性绑定到 Vue 实例的数据或计算属性上,属于单项数据绑定
<body>
<div id="app">
<a v-bind:href="url">链接1</a> 动态绑定url属性
<a :href="url">链接2</a> 简化绑定
<input type="text" >
</div>
</body>
<script>
//定义Vue对象
new Vue({
el: "#app", //vue接管区域
data:{
url: "https://www.baidu.com"
}
})
</script>
注意:html属性前面有:表示采用的vue的属性绑定!
v-model 用于在表单元素和 Vue 实例的数据之间双向绑定
<input type="text" v-model="url">
<script>
//定义Vue对象
new Vue({
el: "#app", //vue接管区域
data:{
url: "https://www.baidu.com"
}
})
</script>
2.v-on 绑定事件

<div>
<input type="button" value="点我一下" v-on:clike="handle()"> 定义视图,v-on绑定点击事件clike
</div>
<script>
new Vue({
el: "#app",
data: {},
methods: { 在data同级定义methods方法区。在内定义方法,可以简化
handled: function () {
alert("你点我了一下.")
}
}
}
)
</script>
其中on:clike="handle()"可以简化
<input type="button" value="点我一下" v-on:clike="handle()">
<input type="button" value="点我一下" @clike="handle()">
模型层简化
new Vue({
el: "#app",
data: {},
methods: {
handled: function () {
alert("你点我了一下.")
},
简化
handled() {
alert("你点我了一下.")
}
}
}
)
3.v-if和v-show

v-if:根据表达式的值来动态地添加或删除元素。当表达式的值为真时,元素会被插入到DOM中;当表达式的值为假时,元素会从DOM中删除。v-show:无论表达式的值如何,元素始终存在于DOM中。它通过修改元素的CSS的display属性来控制元素的显示和隐藏。

4.v-for

<div vgor="(addr,index) in addrs">
addr表示数组单个元素名,idnex表示便利索引,默认从0开始遍历
然后分别编写2种遍历语法,来遍历数组,展示数据,代码如下:
<div id="app">
<div v-for="addr in addrs">{{addr}}</div> idnex从0开始可以省略
<hr>
<div v-for="(addr,index) in addrs">{{index + 1}} : {{addr}}</div>
</div>

Vue的声明周期

下图是 Vue 官网提供的从创建 Vue 到效果 Vue 对象的整个过程及各个阶段对应的钩子函数:

其中我们需要重点关注的是**mounted,**其他的我们了解即可。
mounted:挂载完成,Vue初始化成功,HTML页面渲染成功

然后我们编写mounted声明周期的钩子函数,与methods同级,代码如下:
<script>
//定义Vue对象
new Vue({
el: "#app", //vue接管区域
data:{
},
methods: {
},
mounted () {
alert("vue挂载完成,发送请求到服务端")
}
})
</script>
浏览器打开,运行结果如下:我们发现,自动打印了这句话,因为页面加载完成,vue对象创建并且完成了挂在,此时自动触发mounted所绑定的钩子函数,然后自动执行,弹框。

5、Ajax

在前端开发中,
异步交互技术
指的是一种允许客户端(通常是浏览器)与服务器进行通信,而无需等待服务器响应完成就能继续执行其他操作的技术。
Ajax
(Asynchronous JavaScript and XML),它允许在无需重新加载整个网页的情况下,能够更新部分网页的内容。通过使用Ajax,前端可以发送异步请求到服务器,并在接收到响应后,使用JavaScript动态地更新页面内容,从而提供更好的用户体验。
如下图所示,当我们再百度搜索java时,下面的联想数据是通过Ajax请求从后台服务器得到的

1.同步操作和异步操作

同步操作
:浏览器页面在发送请求给服务器,在服务器处理请求的过程中,浏览器页面不能做其他的操作。只能等到服务器响应结束后才能继续做其他的操作。
异步操作
: 浏览器页面发送请求给服务器,在服务器处理请求的过程中,浏览器页面还可以做其他的操作。
2.原生Ajax技术
<body>
<input type="button" value="获取数据" οnclick="getData()">
<div id="div1"></div>
</body>
<script>
function getData() {
//1. 创建XMLHttpRequest
var xmlHttpRequest = new XMLHttpRequest();
//2. 发送异步请求
xmlHttpRequest.open('GET', 'http://yapi.smart-xwork.cn/mock/169327/emp/list');
xmlHttpRequest.send();//发送请求
//3. 获取服务响应数据
xmlHttpRequest.onreadystatechange = function () {
//此处判断 4表示浏览器已经完全接受到Ajax请求得到的响应, 200表示这是一个正确的Http请求,没有错误
if (xmlHttpRequest.readyState == 4 && xmlHttpRequest.status == 200) {
document.getElementById('div1').innerHTML = xmlHttpRequest.responseText;
}
}
}
</script>
最后我们通过浏览器打开页面,请求点击按钮,发送Ajax请求,最终显示结果如下图所示:

并且通过浏览器的f12抓包,我们点击网络中的XHR请求,发现可以抓包到我们发送的Ajax请求。XHR代表的就是异步请求
3.Axios技术
上述原生的Ajax请求的代码编写起来还是比较繁琐的,所以接下来我们学习一门更加简单的发送Ajax请求的技术Axios 。
Axios是对原生的AJAX进行封装
,简化书写。

Axios的使用比较简单,主要分为2步:
- 引入Axios文件
<script src="js/axios-0.18.0.js"></script> - 使用Axios发送请求,并获取响应结果,官方提供的api很多,此处给出2种,如下- 发送 get 请求
axios({ method:"get", url:"http://localhost:8080/ajax-demo1/aJAXDemo1?username=zhangsan"}).then(function (resp){ alert(resp.data);})- 发送 post 请求axios({ method:"post", url:"http://localhost:8080/ajax-demo1/aJAXDemo1", data:"username=zhangsan"}).then(function (resp){ alert(resp.data);});axios()是用来发送异步请求的,小括号中使用 js的JSON对象传递请求相关的参数:- method属性:用来设置请求方式的。取值为 get 或者 post。- url属性:用来书写请求的资源路径。如果是 get 请求,需要将请求参数拼接到路径的后面,格式为: url?参数名=参数值&参数名2=参数值2。- data属性:作为请求体被发送的数据。也就是说如果是 post 请求的话,数据需要作为 data 属性的值。

Axios还针对不同的请求,提供了别名方式的api,具体如下:

通过别名的方式能够更好的简化书写:
在上述的入门案例中,我们可以将get请求代码改写成如下:
axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => {
console.log(result.data);
})
post请求改写成如下:
axios.post("http://yapi.smart-xwork.cn/mock/169327/emp/deleteById","id=1").then(result => {
console.log(result.data);
})
综合案例
- 需求:基于Vue及Axios完成数据的动态加载展示,如下图所示
 其中数据是来自于后台程序的,地址是:http://yapi.smart-xwork.cn/mock/169327/emp/list
其中数据是来自于后台程序的,地址是:http://yapi.smart-xwork.cn/mock/169327/emp/list - 分析:前端首先是一张表格,我们缺少数据,而提供数据的地址已经有了,所以意味这我们需要使用Ajax请求获取后台的数据。但是Ajax请求什么时候发送呢?页面的数据应该是页面加载完成,自动发送请求,展示数据,所以我们需要借助vue的mounted钩子函数。那么拿到数据了,我们该怎么将数据显示表格中呢?这里就得借助v-for指令来遍历数据,展示数据。
- 步骤:1. 首先创建文件,提前准备基础代码,包括表格以及vue.js和axios.js文件的引入2. 我们需要在vue的mounted钩子函数中发送ajax请求,获取数据3. 拿到数据,数据需要绑定给vue的data属性4. 在
标签上通过v-for指令遍历数据,展示数据 - 代码实现:1. 首先创建文件,提前准备基础代码,包括表格以及vue.js和axios.js文件的引入
 提供初始代码如下:
提供初始代码如下:<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Ajax-Axios-案例</title> <script src="js/axios-0.18.0.js"></script> <script src="js/vue.js"></script></head><body> <div id="app"> <table border="1" cellspacing="0" width="60%"> <tr> <th>编号</th> <th>姓名</th> <th>图像</th> <th>性别</th> <th>职位</th> <th>入职日期</th> <th>最后操作时间</th> </tr> <tr align="center" > <td>1</td> <td>Tom</td> <td> <img src="" width="70px" height="50px"> </td> <td> <span>男</span> <!-- <span>女</span>--> </td> <td>班主任</td> <td>2009-08-09</td> <td>2009-08-09 12:00:00</td> </tr> </table> </div></body><script> new Vue({ el: "#app", data: { } });</script></html>2. 在vue的mounted钩子函数,编写Ajax请求,请求数据,代码如下:mounted () { //发送异步请求,加载数据 axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => { })}3. ajax请求的数据我们应该绑定给vue的data属性,之后才能进行数据绑定到视图;并且浏览器打开后台地址,数据返回格式如下图所示: 因为服务器响应的json中的data属性才是我们需要展示的信息,所以我们应该将员工列表信息赋值给vue的data属性,代码如下:
因为服务器响应的json中的data属性才是我们需要展示的信息,所以我们应该将员工列表信息赋值给vue的data属性,代码如下://发送异步请求,加载数据axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => { this.emps = result.data.data;})其中,data中生命emps变量,代码如下:data: { emps:[]},4. 在标签上通过v-for指令遍历数据,展示数据,其中需要注意的是图片的值,需要使用vue的属性绑定,男女的展示需要使用条件判断,其代码如下: <tr align="center" v-for="(emp,index) in emps"> <td>{{index + 1}}</td> <td>{{emp.name}}</td> <td> <img :src="emp.image" width="70px" height="50px"> </td> <td> <span v-if="emp.gender == 1">男</span> <span v-if="emp.gender == 2">女</span> </td> <td>{{emp.job}}</td> <td>{{emp.entrydate}}</td> <td>{{emp.updatetime}}</td></tr>完整代码如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Ajax-Axios-案例</title> <script src="js/axios-0.18.0.js"></script> <script src="js/vue.js"></script> </head> <body> <div id="app"> <table border="1" cellspacing="0" width="60%"> <tr> <th>编号</th> <th>姓名</th> <th>图像</th> <th>性别</th> <th>职位</th> <th>入职日期</th> <th>最后操作时间</th> </tr> <tr align="center" v-for="(emp,index) in emps"> <td>{{index + 1}}</td> <td>{{emp.name}}</td> <td> <img :src="emp.image" width="70px" height="50px"> </td> <td> <span v-if="emp.gender == 1">男</span> <span v-if="emp.gender == 2">女</span> </td> <td>{{emp.job}}</td> <td>{{emp.entrydate}}</td> <td>{{emp.updatetime}}</td> </tr> </table> </div> </body> <script> new Vue({ el: "#app", data: { emps:[] }, mounted () { //发送异步请求,加载数据 axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => { console.log(result.data); this.emps = result.data.data; }) } }); </script> </html>三、前端工程化
1、前后端分离开发介绍
在之前的课程中,我们介绍过,前端开发有2种方式:前后台混合开发和前后台分离开发。
前后台混合开发,顾名思义就是前台后台代码混在一起开发,如下图所示:

这种开发模式有如下缺点:
- 沟通成本高:后台人员发现前端有问题,需要找前端人员修改,前端修改成功,再交给后台人员使用
- 分工不明确:后台开发人员需要开发后台代码,也需要开发部分前端代码。很难培养专业人才
- 不便管理:所有的代码都在一个工程中
- 不便维护和扩展:前端代码更新,和后台无关,但是需要整个工程包括后台一起重新打包部署。

那么基于前后台分离开发的模式下,我们后台开发者开发一个功能的具体流程如何呢?如下图所示:

- 需求分析:首先我们需要阅读需求文档,分析需求,理解需求。
- 接口定义:查询接口文档中关于需求的接口的定义,包括地址,参数,响应数据类型等等
- 前后台并行开发:各自按照接口文档进行开发,实现需求
- 测试:前后台开发完了,各自按照接口文档进行测试
- 前后段联调测试:前段工程请求后端工程,测试功能
2、前端工程化

1.环境准备

- 安装前端环境Nodejs
- 命令行安装
vue-cli脚手架npm install -g @vue/cli
2.创建vue项目

- vue create vue-project01
- vue ui
创建vue项目
此处我们通过第二种图形化界面方式给大家演示。
首先,我们再桌面创建vue文件夹,然后双击进入文件夹,来到地址目录,输入cmd,然后进入到vue文件夹的cmd窗口界面,如下图所示:

然后进入如下界面:

然后再当前目录下,直接输入命令
vue ui进入到vue的图形化界面,如下图所示:

然后我门选择创建按钮,在vue文件夹下创建项目,如下图所示:

然后来到如下界面,进行vue项目的创建

然后预设模板选择手动,如下图所示:

然后再功能页面开启路由功能,如下图所示:

然后再配置页面选择语言版本和语法检查规范,如下图所示:

然后创建项目,进入如下界面:

最后我们只需要等待片刻,即可进入到创建创建成功的界面,如下图所示:

到此,vue项目创建结束
3.Vue项目目录结构
Vue项目目录结构

运行vue项目
npm run serve修改vue项目的端口号为7000

const {defineConfig} = require('@vue/cli-service') module.exports = defineConfig({ transpileDependencies: true, devServer: { port: 7000 } })4.vue项目与开发流程

Vue组件文件都是以.vue结尾,每个组件由三部分组成
<temple> <script> <style>
vue组件的文件结构
- temple:前端视图代码
- script:数据模型
- style:CSS样式

<template> <div> <h1>{{ message }}</h1> </div> </template> <script> export default { // export打包包操作 data() { return { message: "Hello Vue!" } } } </script> <style> </style>main.js为Vue项目的入口文件,可以使用import导入其他Vue组件的包,前提是vue组件需要使用export将包打包好

3、Element
element官网:组件 | Element


1.安装Element组件库
npm install [email protected]在项目当前文件执行命令下载element,然后element-ui就会在node_modules文件夹内

2.引入组件库
然后我们需要在main.js这个入口js文件中引入ElementUI的组件库,其代码如下:

import ElementUI from 'element-ui'; import 'element-ui/lib/theme-chalk/index.css'; Vue.use(ElementUI);然后我们需要按照vue项目的开发规范,在src/views目录下创建一个vue组件文件,注意组件名称后缀是.vue,并且在组件文件中编写之前介绍过的基本组件语法,代码如下:
<template> </template> <script> export default { } </script> <style> </style>具体操作如图所示:

最后我们只需要去ElementUI的官网,找到组件库,然后找到按钮组件,抄写代码即可,具体操作如下图所示:

然后找到按钮的代码,如下图所示:

ElementView.vue组件内容如下:
<template> <div> <el-button>默认按钮</el-button> <el-button type="primary">主要按钮</el-button> <el-button type="success">成功按钮</el-button> <el-button type="info">信息按钮</el-button> <el-button type="warning">警告按钮</el-button> <el-button type="danger">危险按钮</el-button> </div> </template> <script> export default {} </script> <style> </style>3.引用Element组件
定义好ElementView组件之后,由于前端默认展示的是App.vue界面,需要在App.vue文件内引用ElementView组件,方式如下:
在前端<template>内直接使用ElementView标签引用ElementView.vue组件
<template> <div> <ElementView></ElementView> </div> </template>系统直接导包如下所示
<template> <div> <ElementView></ElementView> </div> </template> <script> import ElementView from "@/views/element/ElementView.vue"; //引用ElementView组件,系统直接导包 export default { components: {ElementView}, data() { return { } } } </script> <style> </style>4.常见Element组件
4.1 Table表格
Table 表格:用于展示多条结构类似的数据,可对数据进行排序、筛选、对比或其他自定义操作。
首先我们需要来到ElementUI的组件库中,找到表格组件,如下图所示:

然后复制代码到我们之前的ElementVue.vue组件中,需要注意的是,我们组件包括了3个部分,如果官方有除了template部分之外的style和script都需要复制。具体操作如下图所示:
template模板部分:

script脚本部分

ElementView.vue组件文件整体代码如下:
<template> <div> <!-- Button按钮 --> <el-row> <el-button>默认按钮</el-button> <el-button type="primary">主要按钮</el-button> <el-button type="success">成功按钮</el-button> <el-button type="info">信息按钮</el-button> <el-button type="warning">警告按钮</el-button> <el-button type="danger">危险按钮</el-button> </el-row> <!-- Table表格 --> <el-table :data="tableData" style="width: 100%"> <el-table-column prop="date" label="日期" width="180"> </el-table-column> <el-table-column prop="name" label="姓名" width="180"> </el-table-column> <el-table-column prop="address" label="地址"> </el-table-column> </el-table> </div> </template> <script> export default { data() { return { tableData: [{ date: '2016-05-02', name: '王小虎', address: '上海市普陀区金沙江路 1518 弄' }, { date: '2016-05-04', name: '王小虎', address: '上海市普陀区金沙江路 1517 弄' }, { date: '2016-05-01', name: '王小虎', address: '上海市普陀区金沙江路 1519 弄' }, { date: '2016-05-03', name: '王小虎', address: '上海市普陀区金沙江路 1516 弄' }] } } } </script> <style> </style>此时回到浏览器,我们页面呈现如下效果:

4.2 Pagination分页
Pagination: 分页组件,主要提供分页工具条相关功能。其展示效果图下图所示:

接下来我们通过代码来演示功能。
首先在官网找到分页组件,我们选择带背景色分页组件,如下图所示:

然后复制代码到我们的ElementView.vue组件文件的template中,拷贝如下代码:
<el-pagination background layout="prev, pager, next" :total="1000"> </el-pagination>浏览器打开呈现如下效果:

还有form表单等等,详情访问Element官网
案例

1.通过页面原型完成员工管理页面开发
<template> <div> <!-- 设置最外层容器高度为700px,在加上一个很细的边框 --> <el-container style="height: 700px; border: 1px solid #eee"> <!-- 布局头部分--> <el-header style="font-size:40px;background-color: rgb(238, 241, 246)">tlias 智能学习辅助系统</el-header> <el-container> <el-aside width="230px" style="height: 700px; border: 1px solid #eee"> <!-- 侧边栏部分--> <el-menu :default-openeds="['1', '3']"> <el-submenu index="1"> <template slot="title"><i class="el-icon-message"></i>系统信息管理</template> <el-menu-item index="1-1">部门管理</el-menu-item> <el-menu-item index="1-2">员工管理</el-menu-item> </el-submenu> </el-menu> </el-aside> <el-main> <!-- 主体部分--> <!-- 表单 --> <el-form :inline="true" :model="searchForm" class="demo-form-inline"> <el-form-item label="姓名"> <el-input v-model="searchForm.name" placeholder="姓名"></el-input> </el-form-item> <el-form-item label="性别"> <el-select v-model="searchForm.gender" placeholder="性别"> <el-option label="男" value="1"></el-option> <el-option label="女" value="2"></el-option> </el-select> </el-form-item> <el-form-item label="入职日期"> <el-date-picker v-model="searchForm.entrydate" type="daterange" range-separator="至" start-placeholder="开始日期" end-placeholder="结束日期"> </el-date-picker> </el-form-item> <el-form-item> <el-button type="primary" @click="onSubmit">查询</el-button> </el-form-item> </el-form> <!-- 表格 --> <el-table :data="tableData"> <el-table-column prop="name" label="姓名" width="180"></el-table-column> <el-table-column prop="image" label="图像" width="180"> <!-- template slot-scope="scope"是一个模板标签,用于定义插槽内容,其中scope 是一个对象,它包含了当前行的数据以及其他一些信息--> <template slot-scope="scope"> <!-- 动态设置img的src属性使得图片得以展现--> <img :src="scope.row.image" width="100px" height="70px"> </template> </el-table-column> <el-table-column prop="gender" label="性别" width="140"> <!-- template slot-scope="scope"是一个模板标签,用于定义插槽内容,其中scope 是一个对象,它包含了当前行的数据以及其他一些信息--> <template slot-scope="scope"> <!-- 从 scope 对象中获取当前行的 gender 字段的值,scope.row.gender == 1 ? '男' : '女': 这是一个三元运算符。它检查 gender 的值是否为 1。如果为 1,则返回 '男';否则返回 '女' --> {{ scope.row.gender == 1 ? '男' : '女' }} </template> </el-table-column> <el-table-column prop="job" label="职位" width="140"></el-table-column> <el-table-column prop="entrydate" label="入职日期" width="180"></el-table-column> <el-table-column prop="updatetime" label="最后操作时间" width="230"></el-table-column> <el-table-column label="操作"> <el-button type="primary" size="mini">编辑</el-button> <el-button type="danger" size="mini">删除</el-button> </el-table-column> </el-table> <br> <!-- Pagination分页,@size-change,@current-change为分页向前向后点击事件,分别定义两个函数执行对应的操作 --> <el-pagination @size-change="handleSizeChange" @current-change="handleCurrentChange" background layout="sizes,prev, pager, next,jumper,total" :total="1000"> </el-pagination> </el-main> </el-container> </el-container> </div> </template> <script> import axios from 'axios' export default { data() { return { tableData: [], searchForm: { name: '', gender: '', entrydate: [] } } }, methods: { onSubmit: function () { console.log(this.searchForm); }, handleSizeChange(val) { console.log(`每页 ${val} 条`); }, handleCurrentChange(val) { console.log(`当前页: ${val}`); } } } </script> <style> </style>
2.Axios完成数据异步加载
1.在项目目录安装Axios
npm install axios2.导入axios
import axios from 'axios'在mounted()执行异步axios请求
mounted() { // 钩子函数使用Axios异步请求,在加载vue时自动get请求获取后端数据展现到前端 axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => { this.tableData = result.data.data(); }) }全部代码
<template> <div> <!-- 设置最外层容器高度为700px,在加上一个很细的边框 --> <el-container style="height: 700px; border: 1px solid #eee"> <!-- 布局头部分--> <el-header style="font-size:40px;background-color: rgb(238, 241, 246)">tlias 智能学习辅助系统</el-header> <el-container> <el-aside width="230px" style="height: 700px; border: 1px solid #eee"> <!-- 侧边栏部分--> <el-menu :default-openeds="['1', '3']"> <el-submenu index="1"> <template slot="title"><i class="el-icon-message"></i>系统信息管理</template> <el-menu-item index="1-1">部门管理</el-menu-item> <el-menu-item index="1-2">员工管理</el-menu-item> </el-submenu> </el-menu> </el-aside> <el-main> <!-- 主体部分--> <!-- 表单 --> <el-form :inline="true" :model="searchForm" class="demo-form-inline"> <el-form-item label="姓名"> <el-input v-model="searchForm.name" placeholder="姓名"></el-input> </el-form-item> <el-form-item label="性别"> <el-select v-model="searchForm.gender" placeholder="性别"> <el-option label="男" value="1"></el-option> <el-option label="女" value="2"></el-option> </el-select> </el-form-item> <el-form-item label="入职日期"> <el-date-picker v-model="searchForm.entrydate" type="daterange" range-separator="至" start-placeholder="开始日期" end-placeholder="结束日期"> </el-date-picker> </el-form-item> <el-form-item> <el-button type="primary" @click="onSubmit">查询</el-button> </el-form-item> </el-form> <!-- 表格 --> <el-table :data="tableData"> <el-table-column prop="name" label="姓名" width="180"></el-table-column> <el-table-column prop="image" label="图像" width="180"> <!-- template slot-scope="scope"是一个模板标签,用于定义插槽内容,其中scope 是一个对象,它包含了当前行的数据以及其他一些信息--> <template slot-scope="scope"> <!-- 动态设置img的src属性使得图片得以展现--> <img :src="scope.row.image" width="100px" height="70px"> </template> </el-table-column> <el-table-column prop="gender" label="性别" width="140"> <!-- template slot-scope="scope"是一个模板标签,用于定义插槽内容,其中scope 是一个对象,它包含了当前行的数据以及其他一些信息--> <template slot-scope="scope"> <!-- 从 scope 对象中获取当前行的 gender 字段的值,scope.row.gender == 1 ? '男' : '女': 这是一个三元运算符。它检查 gender 的值是否为 1。如果为 1,则返回 '男';否则返回 '女' --> {{ scope.row.gender == 1 ? '男' : '女' }} </template> </el-table-column> <el-table-column prop="job" label="职位" width="140"></el-table-column> <el-table-column prop="entrydate" label="入职日期" width="180"></el-table-column> <el-table-column prop="updatetime" label="最后操作时间" width="230"></el-table-column> <el-table-column label="操作"> <el-button type="primary" size="mini">编辑</el-button> <el-button type="danger" size="mini">删除</el-button> </el-table-column> </el-table> <br> <!-- Pagination分页,@size-change,@current-change为分页向前向后点击事件,分别定义两个函数执行对应的操作 --> <el-pagination @size-change="handleSizeChange" @current-change="handleCurrentChange" background layout="sizes,prev, pager, next,jumper,total" :total="1000"> </el-pagination> </el-main> </el-container> </el-container> </div> </template> <script> import axios from 'axios' export default { mounted() { // 钩子函数使用Axios异步请求,在加载vue时自动get请求获取后端数据展现到前端 axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => { this.tableData = result.data.data(); }) }, data() { return { tableData: [], searchForm: { name: '', gender: '', entrydate: [] } } }, methods: { onSubmit: function () { console.log(this.searchForm); }, handleSizeChange(val) { console.log(`每页 ${val} 条`); }, handleCurrentChange(val) { console.log(`当前页: ${val}`); } } } </script> <style> </style>4、Vue路由
将资代码/vue-project(路由)/vue-project/src/views/tlias/DeptView.vue拷贝到我们当前EmpView.vue同级,其结构如下:

此时我们希望基于4.4案例中的功能,实现点击侧边栏的部门管理,显示部门管理的信息,点击员工管理,显示员工管理的信息,效果如下图所示:


这就需要借助我们的vue的路由功能了。
前端路由:URL中的hash(#号之后的内容)与组件之间的对应关系,如下图所示:

当我们点击左侧导航栏时,浏览器的地址栏会发生变化,路由自动更新显示与url所对应的vue组件。
而我们vue官方提供了路由插件Vue Router,其主要组成如下:
- VueRouter:路由器类,根据路由请求在路由视图中动态渲染选中的组件
- <router-link>:请求链接组件,浏览器会解析成
- <router-view>:动态视图组件,用来渲染展示与路由路径对应的组件

1.安装路由
npm install [email protected]2.定义路由
路由信息定义在项目的router目录下的index.js内
设置index.js内的路由信息
const routes = [ { path: '/dept', // url地址 name: 'dept', // url命名 component: () => import ('../views/tlias/DeptView.vue') // 组件路径 }, { path: '/emp', name: 'emp', component: () => import('../views/tlias/EmpView.vue') } ]然后再main中引入router功能

import Vue from 'vue' import App from './App.vue' import router from './router' import ElementUI from 'element-ui'; import 'element-ui/lib/theme-chalk/index.css'; Vue.use(ElementUI); Vue.config.productionTip = false new Vue({ router: router, render: h => h(App) }).$mount('#app')3.案例
我们希望点击左侧的菜单实现路由跳转功能:

1.在视图层将前端侧边栏字体添加router-link链接,当点击
部门管理跳转到/dept,当点击
员工管理跳转到/emp
<el-aside width="230px" style="height: 700px; border: 1px solid #eee"> <!-- 侧边栏部分--> <el-menu :default-openeds="['1', '3']"> <el-submenu index="1"> <template slot="title"><i class="el-icon-message"></i>系统信息管理</template> <!-- router-link表示给部门管理添加超链接跳转到/dept路由--> <el-menu-item index="1-1"> <router-link to="/dept">部门管理</router-link> </el-menu-item> <el-menu-item index="1-2"> <!-- router-link表示给员工管理添加超链接跳转到/dept路由--> <router-link to="/emp">员工管理</router-link> </el-menu-item> </el-submenu> </el-menu> </el-aside>
2.在调用展示该组件的部分使用<router-view></router-view>替代/dept,/emp跳转的组件EmpView.vue,DeptView.vue
<template> <div> <router-view></router-view> </div> </template>5、打包部署
我们的前端工程开发好了,但是我们需要发布,那么如何发布呢?主要分为2步:
- 前端工程打包
- 通过nginx服务器发布前端工程
1.打包vue项目,在项目主目录下执行打包命令
npm run build打包完前端代码之后,会在项目目录下生成一个dist文件夹,里面存放的是打包好的vue项目

1.nginx前端部署工具
nginx: Nginx是一款轻量级的Web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。

nginx部署前端代码:

- 将打包好的前端dist文件放在nginx目录的html文件夹内
- 双击打开nginx.exe文件部署(默认占用80端口,需要修改端口号)
修改nginx默认端口号,在nginx目录下的conf文件下的nginx.conf文件修改端口为90
点击启动nginx服务,访问90端口查看前端项目是否已部署

四、SpringBoot入门
1、第一个SpringBppt程序

创建一个maven的SpringBoot快速构建项目

创建好controller类后,启动项目,访问浏览器请求
@RestController public class HelloController { @RequestMapping("/hello") public String Hello() { System.out.println("Hello world"); return "Hello world"; } }

SpringBoot web开发起步依赖

- web开发起步依赖
- 单元测试依赖
由于web起步依赖内嵌了一个Tomcat服务器,因此直接执行springboot 的main方法就可以运行web项目而不需要手动开启本地的tomcat服务
2、HTTP协议
1.HTTP概述
HTTP:超文本传输协议

Http特点:
- 基于TCP协议:面向连接,安全
- 基于请求-响应模型:一次请求对应一次响应
- HTTP协议是无状态的协议:对于事务处理没有记忆能力,每次请求-响应都是独立的1. 缺点:多次请求之间不能共享数据2. 优点:速度快
2.HTTP请求数据格式
HTTP请求格式分为:请求行+请求头+请求体

- 请求方式-GET:请求参数在请求行中,没有请求体。GET请求大小是有限制的,相对来说不安全。一般用于查询服务器数据
- 请求方式-POST:请求参数在请求体当中,POST请求大小没有限制。请求来说相对安全,一般用于登录注册等修改浏览器服务器数据
HTTP请求行
请求方式+资源路径+协议
HTTP请求头

HTTP请求体
post请求携带的请求参数,存放在请求体当中
3.HTTP响应格式

- 响应行:(协议、状态码、描述)
- 响应头:json数据格式
- 响应体:存放服务器响应的数据
响应状态码

- 1xx:响应中,临时状态码
- 2xx:成功,处理已完成
- 3xx:重定向
- 4xx:客户端错误(如:客户端未授权、请求不存在的资源、禁止访问等)
- 5xx:服务器错误
常见的状态码

- 200 客户端处理成功
- 302 Found 浏览器自动重定向
403 Forbidden没有权限访问404 Not Found请求资源不存在- 500 服务器异常
响应头

4.HTTP协议解析
HTTP协议解析过程是极为繁琐的,但由于http协议是市面上通用的固定格式,因此我们可以使用市面上封装好的程序web服务器去解析HTTP协议,如:Tomcat、IBM等

3、Web服务器

Web服务器是一个软件程序,对HTTP协议的操作进行封装,使得程序员不必直接对协议进行操作,让Web开发更加便捷主要功能是“提供网上信息浏览服务"。
这里我们重点讲解Tomcat web服务器
1.Tomcat

概念:Tomcat是一个开源免费的轻量级Web服务器,支持Servlet/JSP等少量JavaEE规范
Tomcat也被称为Web容器,Servlet容器。Servlet容器需要依赖于Tomcat才能运行
- JavaSE:java标准版
- JavaME:java小型版
- JavaEE:Java企业版
Tomcat基本使用

启动Tomcat:打开bin目录,双击startup.bat
Tomcat端口冲突:

解决端口冲突方法:
- 关闭冲突端口

- 修改Tomcat端口号

Http协议默认端口为80,https端口为443
4、请求响应

前端控制器
DispatcherServlet- 用于处理Web请求并将它们路由到相应的处理程序(也称为控制器)
- 拦截客户端浏览器的请求,并根据url将请求包装为
HttpServletRequest对象传递到正确的Controller程序 - 将Controller处理完之后返回的数据包装为
HttpServletResponse对象发送到客户端浏览器

- BS(Browser/Server)浏览器-服务器架构:维护方便,体验一般(响应速度慢)
- CS(Client/Server)客户端-服务器架构:开发维护麻烦,但体验不错(响应速度快)
浏览器、DNS服务器、Web服务器、后台服务器请求响应步骤
首先介绍一下各个组件的功能
- 浏览器:负责与用户之间交互,负责发起http请求,接受并解析http响应,以及渲染页面供用户去查看
- DNS服务器:浏览器发起请求首先需要将url域名通过DNS域名服务器解析成
域名-ip地址映射返回到浏览器 - web服务器:web服务器是一个软件程序,通常部署在后端服务器的端口上。web服务器负责对http请求和响应进行封装和转发到对应的后端Controller。
- 后端服务器负责处理web服务器转发的请求执行对应的业务逻辑,通常与数据库进行交互,通过web服务器将响应转发给浏览器

1.原始方式的请求响应
@RestController public class RequestController { @RequestMapping("/simpleParam") public String simpleParam(HttpServletRequest request) { // 获取浏览器传来的原始的HttpServletRequest请求对象 String name = request.getParameter("name"); String ageStr = request.getParameter("age"); // 获取到指定的get请求的url的数据,但都是字符串类型,需要使用类型转换 int age = Integer.parseInt(ageStr); System.out.println("name:" + name + " age:" + age); return "OK"; } }
2.请求方式
1.简单参数
请求参数名与形参名相同时,能够自动接收参数值且能自动类型转换
@RequestMapping("/simpleParam") public String simpleParam(String name, Integer age) { // 请求参数名与形参名相同能够自动接收参数值且能自动类型转换 System.out.println(name + ":" + age); return "OK"; }当请求url参数名与方法形参名不同,我们可以声明 @RequestParam()标签将参数名与形参进行绑定(
使用@RequestParam绑定的参数一定要传递,不然会报错)
@RequestMapping("/simpleParam") public String simpleParam(@RequestParam(name = "name") String username, Integer age) { // 请求参数名与形参名相同能够自动接收参数值且能自动类型转换 System.out.println(username + ":" + age); return "OK"; }由于以上通过url传递请求参数的方法当中,需要我们在方法当中定义相同个数的参数名,比较繁琐,因此我们一般会将所有请求的参数名封装成一个类对象去传入,其中类对象的属性名必须和请求参数名相同。
2.复杂实体参数
当请求的参数过于复杂时,我们一般会将请求参数包装成一个类对象进行参数传递
(请求参数名称和类属性一定要相同)public class User { private int age; private String name; } @RequestMapping("/simplePojo") public String simplePojo(User user) { // 请求参数名与形参名相同能够自动接收参数值且能自动类型转换 System.out.println(user.getName() + ":" + user.getAge()); return "OK"; }3.数组集合参数
请求参数名与形参数组名称相同且请求参数为多个,默认定义
数组类型方法参数即可接收请求参数

@RequestMapping("/arrayParam") public String arrayParam(String[] hobby) { // 请求参数名与形参名相同默认使用接收参数值且能自动类型转换 System.out.println(Arrays.toString(hobby)); // [game, java] return "OK"; }http://localhost:8080/arrayParam?hobby=game&hobby=java # 有两个相同的hobby参数,默认定义数组hobby[]接收变量请求参数名与形参集合名称相同且请求参数为多个,默认情况下会封装成数组类型,使用
@RequestParam绑定集合关系后会封装成
集合类型@RequestMapping("/listParam") public String listParam(@RequestParam List<String> hobby) { // 使用@PequestParam绑定后会封装成集合类型 System.out.println(hobby); // [game, java] return "OK"; }http://localhost:8080/listParam?hobby=game&hobby=java
4.日期参数

使用
@DateTimeFormat()可以定义接收的日期参数的格式
@RequestMapping("/dateParam") public String dateParam(@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime updateTime) { // 请求参数名与形参名相同能够自动接收参数值且能自动类型转换 System.out.println(updateTime); // 输出:2022-12-12T10:00:05 return "OK"; }http://localhost:8080/dateParam?updateTime=2022-12-12 10:00:055.Json参数
Json参数一般使用java对象的方式接收,且类对象的属性名需要与Json格式的key相同;需要使用@RequestBody标识方法形参,表示将一个json请求数据以对象的形式传入

@RequestMapping("/jsonParam") public String jsonParam(@RequestBody User user) { // 接受Json格式的请求参数,并将结果用User对象接收 System.out.println(user); // com.example.pojo.User@148e7c62 return "OK"; }http://localhost:8080/jsonParam { "name": "zhangsan", "age": "18" }6.路径参数
通过请求URL直接传递参数,使用{xxx}来标识该路径参数,需要使用@PathVariable标识获取的路径参数
@RequestMapping("/path/{id}") public String pathParam(@PathVariable Integer id) { // 路径参数获取 System.out.println(id); // id=1 return "OK"; }http://localhost:8080/path/1获取多个路径参数
@RequestMapping("/path/{id}/{name}") public String pathParam2(@PathVariable Integer id, @PathVariable String name) { // 路径参数获取 System.out.println(id + ":" + name); // 1:zhangsan return "OK"; }http://localhost:8080/path/1/zhangsan请求参数接收总结

3.响应方式

@RestController定义在Controller类当中,等同于@ResponseBody+@Controller
@ResponseBody可以定义在方法和类上,当一个控制器方法使用
@ResponseBody注解时,Spring将方法的返回值直接写入HTTP响应体中,而不是试图将其解释为视图名称;如果返回值类型是实体对象/集合,将会转为Json格式写入响应体
视图名称就是直接将return值返回到对应路径下的页面上,如果使用@ResponseBody就会将返回结果写入响应体内而不是以视图的形式展现出来
- 定义在方法上,表示该方法的返回值将直接响应在客户端
- 定义在类上,表示该类的所有方法的返回值都直接响应在客户端上

响应字符串
@RequestMapping("/hello") public String hello() { // 路径参数获取 return "Hello world"; } http://localhost:8080/hello Hello world // 响应为视图名称响应类对象(将对象转化为json格式返回到服务端)
@@ResponseBody @RequestMapping("/getAddr") public User getAddr(User user) { // 路径参数获取 return user; } http://localhost:8080/getAddr?name=zhangsan&age=19 // 响应到响应体当中 { "age": 19, "name": "zhangsan" }响应数组
@ResponseBody @RequestMapping("/listAddr") public List<User> listAddr() { // 路径参数获取 ArrayList<User> list = new ArrayList<>(); User user1 = new User(); User user2 = new User(); user1.setName("zhangsan"); user1.setAge(16); list.add(user1); user2.setName("lisi"); user2.setAge(18); list.add(user2); return list; } http://localhost:8080/listAddr [ { "age": 16, "name": "zhangsan" }, { "age": 18, "name": "lisi" } ]根据以上响应的结果,我们发现响应的格式千奇百怪,为此我们需要定义一套规范用于规定后端响应的数据格式。及将响应结果封装到Result类对象内

Result类
package com.itheima.pojo; /** * 统一响应结果封装类 */ public class Result { private Integer code;//1 成功 , 0 失败 private String msg; //提示信息 private Object data; //数据 data public Result() { } public Result(Integer code, String msg, Object data) { this.code = code; this.msg = msg; this.data = data; } public Integer getCode() { return code; } public void setCode(Integer code) { this.code = code; } public String getMsg() { return msg; } public void setMsg(String msg) { this.msg = msg; } public Object getData() { return data; } public void setData(Object data) { this.data = data; } public static Result success(Object data) { return new Result(1, "success", data); } public static Result success() { return new Result(1, "success", null); } public static Result error(String msg) { return new Result(0, msg, null); } @Override public String toString() { return "Result{" + "code=" + code + ", msg='" + msg + '\'' + ", data=" + data + '}'; } }然后将以上的相应数据都封装为Result对象
@RequestMapping("/hello") public Result hello() { // 路径参数获取 return Result.success("Hello world"); } { "code": 1, "msg": "success", "data": "Hello world" } @RequestMapping("/getAddr") public Result getAddr(User user) { // 路径参数获取 return Result.success(user); } { "code": 1, "msg": "success", "data": { "age": 0, "name": null } } @RequestMapping("/listAddr") public Result listAddr() { // 路径参数获取 ArrayList<User> list = new ArrayList<>(); User user1 = new User(); User user2 = new User(); user1.setName("zhangsan"); user1.setAge(16); list.add(user1); user2.setName("lisi"); user2.setAge(18); list.add(user2); return Result.success(list); } { "code": 1, "msg": "success", "data": [ { "age": 16, "name": "zhangsan" }, { "age": 18, "name": "lisi" } ] }5、分层解耦

1.三层架构


采用三层架构的优点:
- 复用性强
- 代码每层的功能单一,便于维护
- 有利于代码的拓展
2.分层解耦
- 内聚:软件中各个功能模块内部的功能与联系
- 耦合:衡量软件中各个层/模块之间的依赖、关联程度
- 软件设计原则:高内聚,低耦合
在以上的代码当中我们发现,当在controller层当中需要调用service处理业务逻辑时,需要创建对应的Service类对象,如果当service类名发生改变时,Controller层的创建对象也需要发生改变,这样就导致了两个模块之间的耦合,为了解除这种耦合(解耦),我们需要想办法如果Service发生改变时,Controller层不需要改变。

这个时候便引入了依赖注入(IOC)和控制反转(DI),我们通过将程序自身创建对象再到调用的过程由外部的容器去控制,这就是控制反转和依赖注入。管理对象的容器称为Spring容器或IOC容器,容器管理的创建好的对象称为bean。
上述案例中,我们只需要在需要依赖注入的地方采用@Autowired自动装配,不需要显示的去创建对象导致不同层级之间的代码耦合,这样的好处不仅使得程序的代码之间解耦,也使得开发者无需过多的关注对象的创建和管理。

3.IOC和DI
控制反转(IOC):将对象的创建的控制权由程序转移到外部容器,这种思想称为控制反转
依赖注入(DI):容器为应用程序提供运行所依赖的资源,称为依赖注入。
Bean对象:IOC容器内创建、管理的对象称为Bean
在实际的javaweb代码开发当中,不同层之间对象的创建通过IOC的方式交给Spring容器去管理;当程序运行时,容器会根据对象需要的类型注入对应的bean对象使得程序正常运行。

控制反转:采用
@component注解表示将类交给IOC容器管理;案例:将Service和Dao层的类添加@Component交给容器管理

依赖注入:在需要注入实例化对象的地方添加@Autowired,让容器根据类型自动注入bean对象

案例:Controller层需要注入一个EmpService对象,但是Empservice接口有两个实现类EmpserviceA和EmpserviceB,当Controller层需要对应的EmpService实现类对象时,只需要给对应的一个Empservice实现类添加@component,使用这种方式动态切换需要注入的类对象,而不改变其它代码。
6、控制反转IOC
Spring当中的
控制反转IOC就是将对象的创建权交给外部的Spring容器去完成
1.Bean的声明
在Spring当中,还提供了针对不同业务层的@component衍生注解。如@Controller表示声明为Controller层的bean对象。@Component一般用来声明为这三层架构之外的其他工具类的bean对象。

我们查看对应的衍生注解的源码:

@Service和@Repository内直接就复用了@Component注解

bean对象名称默认为类名称的小驼峰形式,当然你也可以采用value属性指定bean对象的名称

指定bean对象的名称

2.组件扫描

查看@SpringBootApplication注解源码,发现包含了@ComponentScan组件扫描注解。

这里我们做一个案例,将Dao层放在启动类平级的文件夹下,由于Dao层的bean组件不在Spring默认扫描的范围内,因此按理来说是不能扫描到里面的bean组件

解决方案:手动添加@ComponentScan注解value值可以填一个集合,指定要扫描的包(仅做了解,不推荐)

以下我们在@SpringBootApplication注解上给@ComponentScan赋值扫描dao和com.itheima两个包下的组件,覆盖掉原有默认的包扫描规则

为了避免不必要的配置,我们还是按照约定的规则在启动类所在的包内声明bean组件。
7、依赖注入DI
Spring当中的依赖注入DI就是在程序运行时将Spring容器内的bean对象注入到程序声明的对象当中去。

- @Autowired 自动装配
当程序需要依赖注入bean对象时,默认采用的注解是
@Autowired(自动装配),@Autowired会默认按照对象类型自动装配bean对象,这样就容易引发一个问题。如果bean容器内含有多个相同类型的bean对象,这样程序就不知道应该装配的是同类型的哪个bean对象,会引发程序报错。
如我们使用@Service将两个EmpService接口类型的类加载到容器当中进行管理,在Controller层使用@Autowired自动装配了一个empService类型的对象,由于empServiceA和empServiceB两个bean对象都是EmpService类型,因此采用@Autowired按照类型自动装配对象系统会报错。

- @Primary 当容器内存在多个相同类型的Bean时,默认优先指定注入的bean对象

- @Autowired+@Qualifier(“bean名称”)
@Qualifier注解不能单独使用,必须配合@Autowired使用
前面我们已经提到,bean对象的名字默认为类名的首字母小写,使用@Qualifier注解时,需要指定当前要注入的bean对象。 在@Qualifier的value属性中,指定注入的bean的名称。

- @Resource(name=”bean名称”) 通过name名称指定需要注入的bean对象

重要@Resource和@Autowired的区别
- @Autowired是Spring框架提供的注解;而@Resource是jdk提供的注解
- @Autowired默认是按照类型进行注入,而@Resource是按照名称进行注入
五、Mysql数据库

- 数据库管理系统:Database Management System(DBMS)操作和管理数据库的大型软件
- SQL:Structured Query Language 操作关系型数据库的编程语言,定义了一套操作关系型数据库的统一标准
1、Mysql安装和连接
个人连接本机Mysql数据库
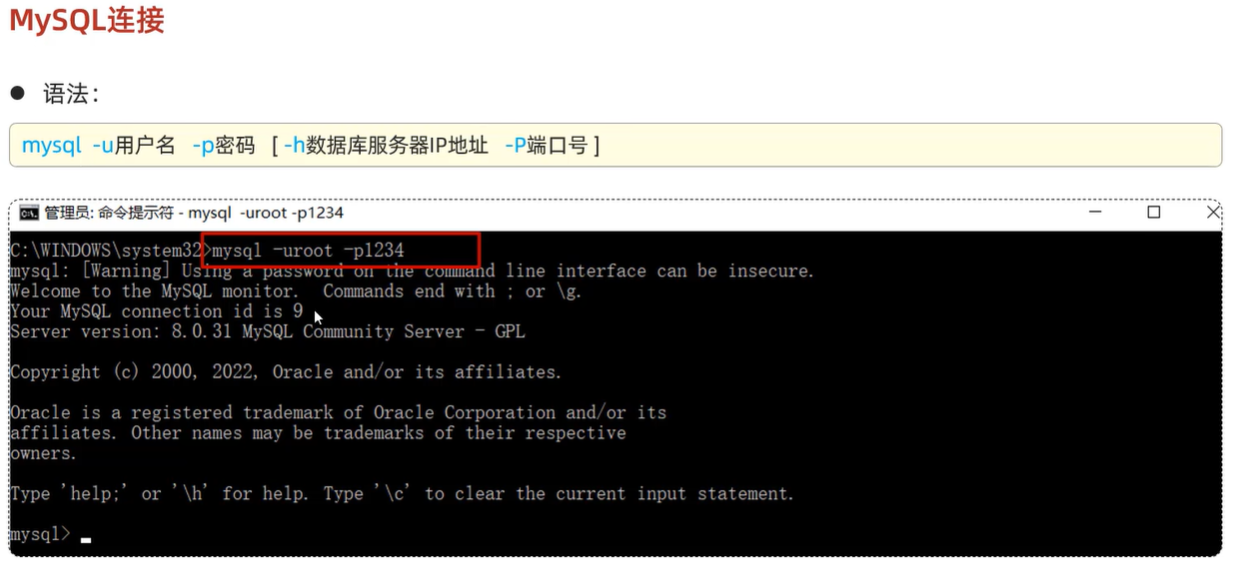
企业连接Mysql服务器

连接远程服务器 192.168.150.101 mysql -h 192.168.150.101 -P 3306 -u root -p 12342、Mysql数据模型

- 关系型数据库:由多张二维表组成的数据库称为关系型数据库
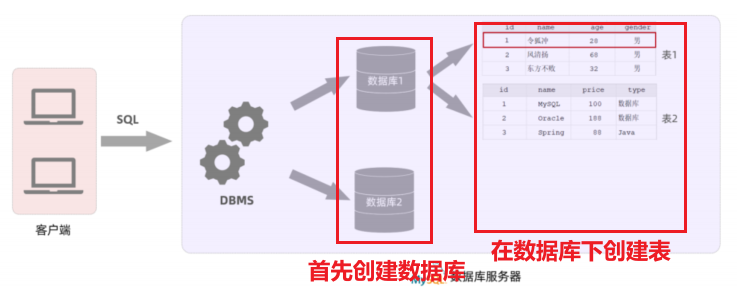
一个数据库服务器中可以创建多个数据库,一个数据库中也可以包含多张表,而一张表中又可以包含多行记录。
3、SQL简介

SQL:是一门操作关系型数据库的编程语言,用来定义所有的关系型数据库的统一标准
- SQL语句可以单行也可以多行书写,以“;”结尾
- SQL语句可以使用空格/缩进来增强语句的可读性
- Mysql数据库的SQL语句不区分大小写
Mysql注释
- 单行注释:
– – 注释内容或# 注释内容 - 多行注释:
/* 注释内容 */
4、SQL分类


- DDL:(definition)数据定义语言;操作数据库对象(数据库、表、字段)
- DML:(manipulation)数据操作语言;操作数据库表内的数据
- DQL:(Query)数据查询语言;查询数据库表内的数据
- DCL:(Control)数据控制语言;操作数据库用户,以及数据库的权限
5、DDL 数据定义语言
DDL是数据定义语言,主要用来定义或操作数据库对象(包括数据库,表)

1.操作数据库对象
查询所有数据库
show databases; # 查询所有数据库使用数据库
use db01;创建数据库
create database db01; create database if not exists db01;查询当前数据库
select database();删除数据库
drop database db01; drop database if exists db01;2.操作表对象
2.1 查看表结构
查看数据库下的所有表结构
show tables;查看指定表的结构
desc tb_emp;查看数据库的建表语句
show create table tb_emp;2.2 修改表语句
添加add为表tb_emp添加字段qq varchar(10)
alter table tb_emp add qq varchar(10) comment 'QQ';修改modify修改tb_emp字段qq的类型为varchar(12)
alter table tb_emp modify qq varchar(12);修改字段和类型change修改tb_emp字段名qq为qq_num varchar(13)
alter table tb_emp change qq qq_num varchar(13);删除字段drop删除tb_emp的qq_num字段
alter table tb_emp drop qq_num;重命名rename修改tb_emp的表名为emp
alter table tb_emp rename emp;删除表drop删除表tb_emp
drop table if exists tb_emp;2.3 创建表操作
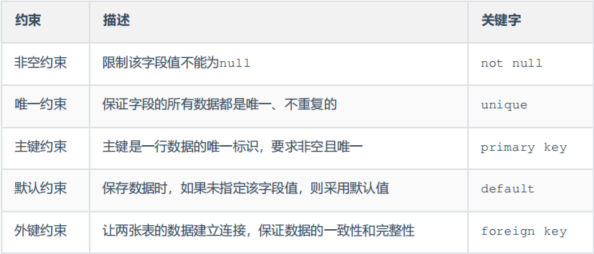
表约束
创建表操作
create table tb_user ( id int comment 'ID,唯一标识' primary key auto_increment, # auto_increment自动增长 username varchar(20) comment '用户名' not null unique, # 非空且唯一(两个约束) name varchar(10) comment '姓名' not null, age int comment '年龄' not null, gender char(1) comment '性别' default '男' ) comment '用户表';3.数据库字段类型
数值类型
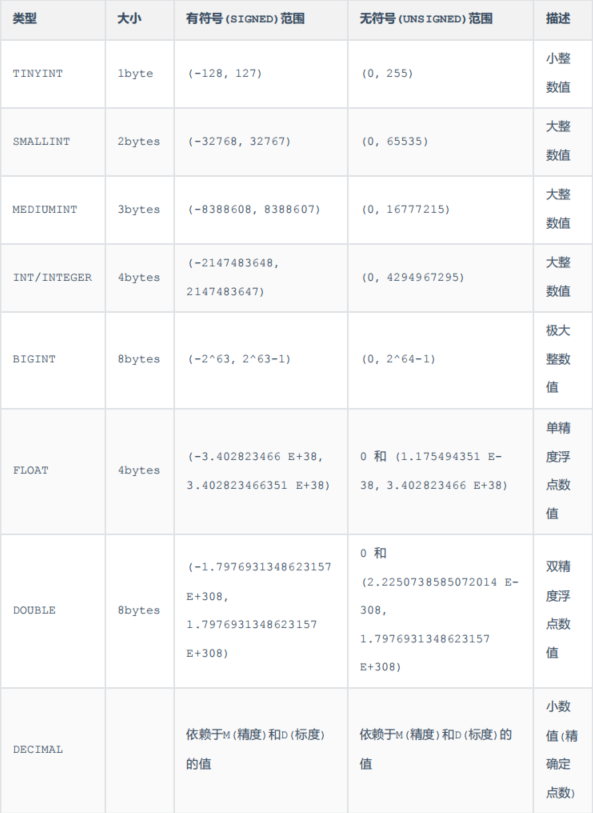
整数 tinyint # 无符号(0~255)应该为tinyint unsigned smallint mediumint int/Integer bigint 浮点数 float double # double(5,2) 5表示整个数字长度(整数+小数的长度最大为5),2表示小数的位数 decimal字符串类型
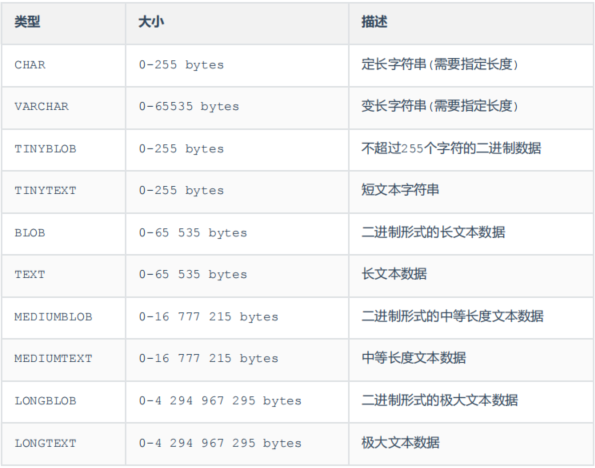
字符串 char # char(10) 表示最多只能存储10个字符,占用10个字符空间 varchar # varchar(10) 表示最多只能存储10个字符,但是按照实际的长度存储字符日期类型
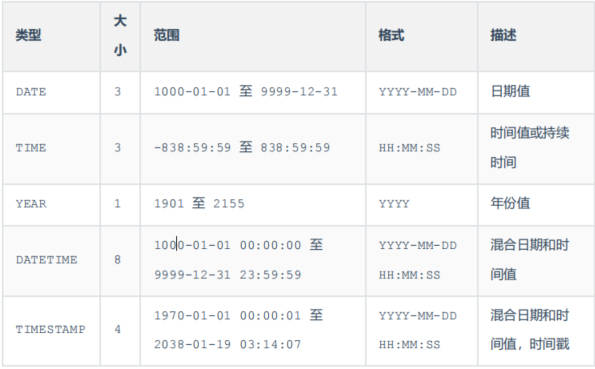
date 年月日 YYYY-MM-DD datetime 年月日 时分秒 YYYY-MM-DD HH:MM:SS6、DML 数据操作语言

DML是数据操作语言,主要用来操作数据库中表的数据,对数据进行增删改操作。
- insert 增加数据
- update 修改数据
- delete 删除数据
1.插入数据intsert

# 为指定字段插入单条数据 insert into tb_emp(username,name,gender,create_time,update_time) values ('wuji','张无忌',1,now(),now()); # 为全部字段插入单条数据 insert into tb_emp(id, username, name,password, gender, image, job, entrydate, update_time, create_time ) values (null,'zhiruo','周芷若','123',2,'1.jpg',1,'2020-10-01',now(),now()); insert into tb_emp values (null,'zhiruo1','周芷若','123',2,'1.jpg',1,'2020-10-01',now(),now()); # 为指定字段插入批量数据 insert into tb_emp(username,name,gender,create_time,update_time) values ('weifuwang','韦一笑',1,now(),now()),('jingmaoshiwnag','谢逊',1,now(),now()); # 为所有字段批量插入数据 insert into tb_emp values (null,'zhiruo2','周芷若','123',2,'1.jpg',1,'2020-10-01',now(),now()),(null,'zhiruo3','周芷若','123',2,'1.jpg',1,'2020-10-01',now(),now());2.更新数据update
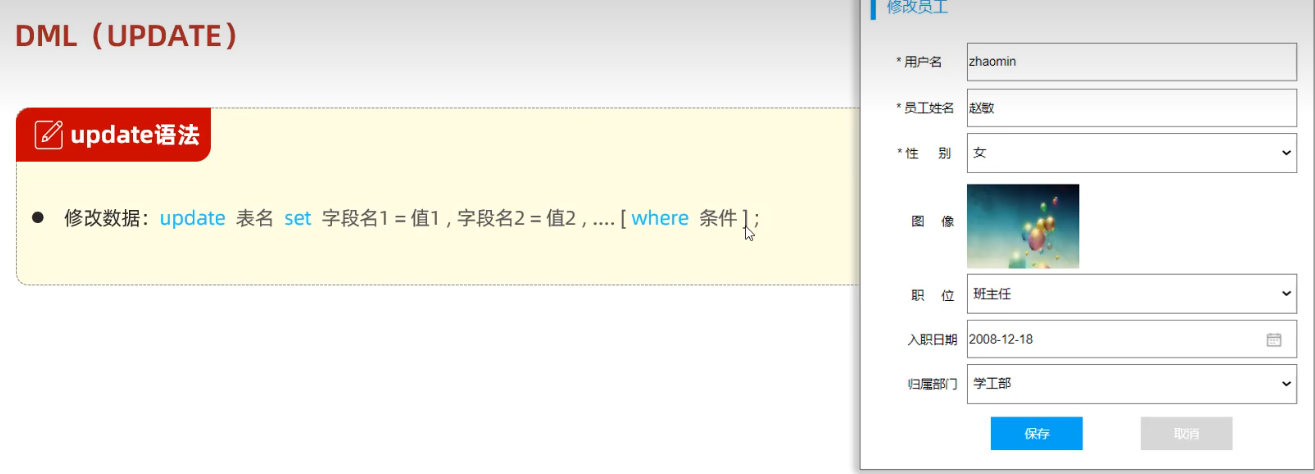
如果更新语句没有添加where条件,将会修改整张表的数据
# 将tb_emp表的id为1的员工名称更新为‘张三’ update tb_emp set name='张三' where id=1; # 将tb_emp表的所有员工的入职时间更新为'2010-10-01' update tb_emp set entrydate='2010-10-01',update_time=now();3.删除数据delete
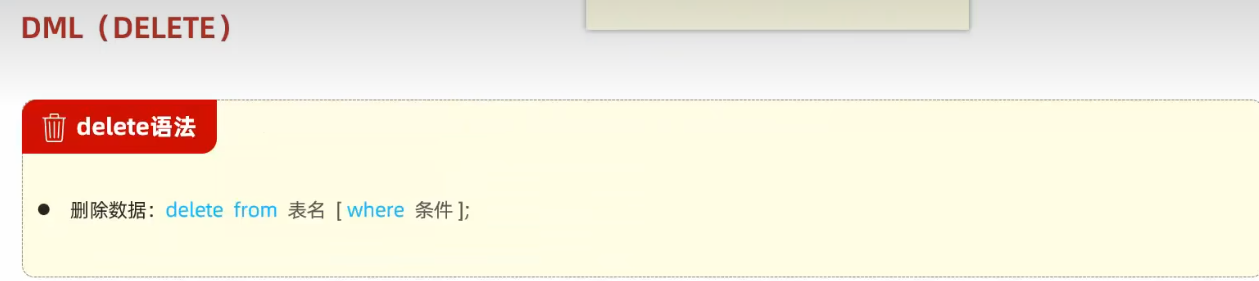
- delete语句的条件如果没有,表示删除整张表的所有字段
- delete不能删除某一个字段的值(我们可以使用update语句将该字段修改为null)
# 删除tb_emp表中id为1的员工 delete from tb_emp where id=1; # 删除整张表的所有员工 delete from tb_emp;7、DQL 数据查询语言

DQL:数据查询语言,用来查询数据库表中的数据

DQL查询语法分为基本查询、条件查询、分组查询、排序查询、分页查询多个查询操作。
查询语句优先级:
form 表 where 条件 group by 分组 having 分组过滤 select 选择字段 order by 字段排序 limit 分页1.基本查询

# 查询指定字段 select name,entrydate from tb_emp; # 查询所有字段 select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp; select * from tb_emp; # 查询字段并起别名 select name as 姓名,entrydate as '入职 日期' from tb_emp; # 起别名as可以省略;且别名若包含特殊字符需用''包裹2.条件查询

# 查询姓名为 杨逍 的员工 select * from tb_emp where name='杨逍'; # 查询id小于等于5的员工信息 select * from tb_emp where id <= 5; # 查询没有分配职位的员工信息 select * from tb_emp where job is null ; # 查询有职位的员工信息 select * from tb_emp where job is not null ; # 查询密码不等于'123456'的员工信息 select * from tb_emp where password != '123456'; select * from tb_emp where password <> '123456'; # 查询 入职日期 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间的员工信息 select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01'; select * from tb_emp where entrydate >= '2000-01-01' and entrydate <= '2010-01-01'; # 查询性别为 女 并且 入职日期在 '2005-01-01' (包含) 到 '2015-01-01' (包含) 之间的员工信息 select * from tb_emp where gender='女' and entrydate between '2005-01-01' and '2015-01-01'; # 查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息 select * from tb_emp where job=2 or job=3 or job=4; select * from tb_emp where job in (2,3,4); # 查询 姓名 为两个字的员工信息 select * from tb_emp where name like '__'; # 查询 姓 '张' 的员工信息 select * from tb_emp where name like '张%';3.分组查询
首先介绍一下mysql当中的
聚合函数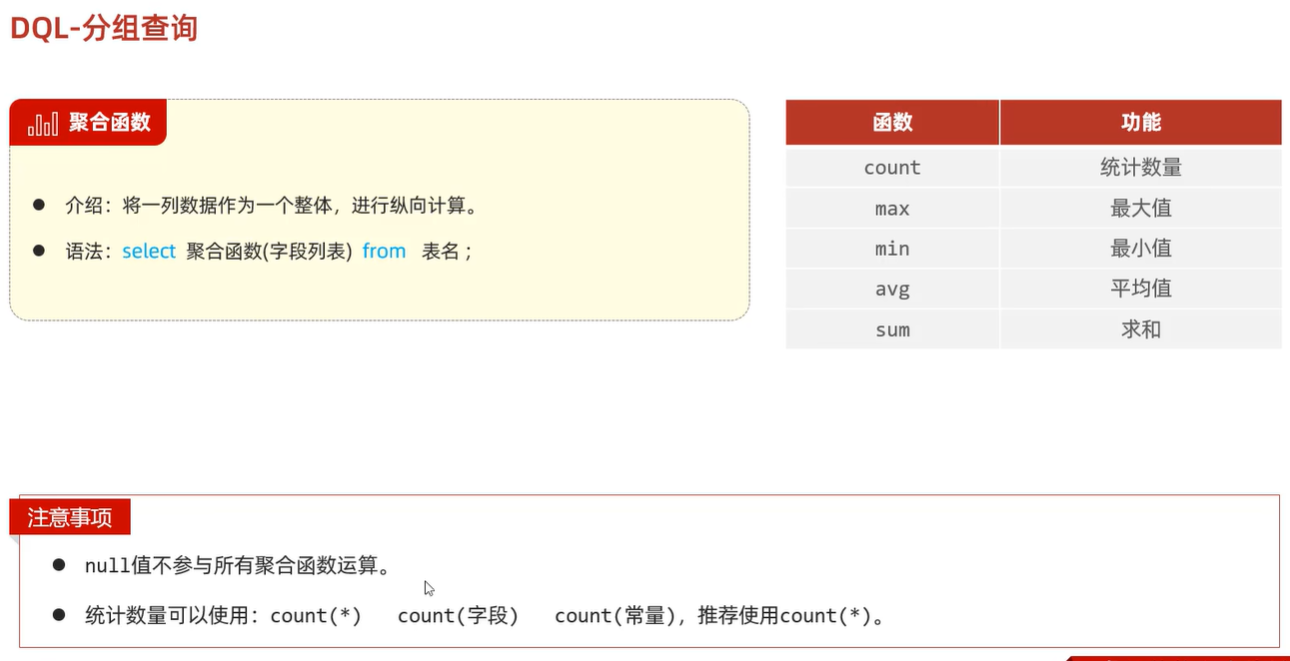
聚合函数:
将数据表的一列作为一个整体进行纵向计算。聚合函数不对null空进行计算常见的聚合函数如上所示;count()、max()、min()、avg()、sum()
# 统计企业员工数量 select count(*) from tb_emp; # 推荐 select count(id) from tb_emp; # 统计企业最早入职的员工 select min(entrydate) from tb_emp; # 统计企业最迟入职的员工 select max(entrydate) from tb_emp; # 统计企业的id的平均值 select avg(id) from tb_emp; # 统计企业的id的总和 select sum(id) from tb_emp;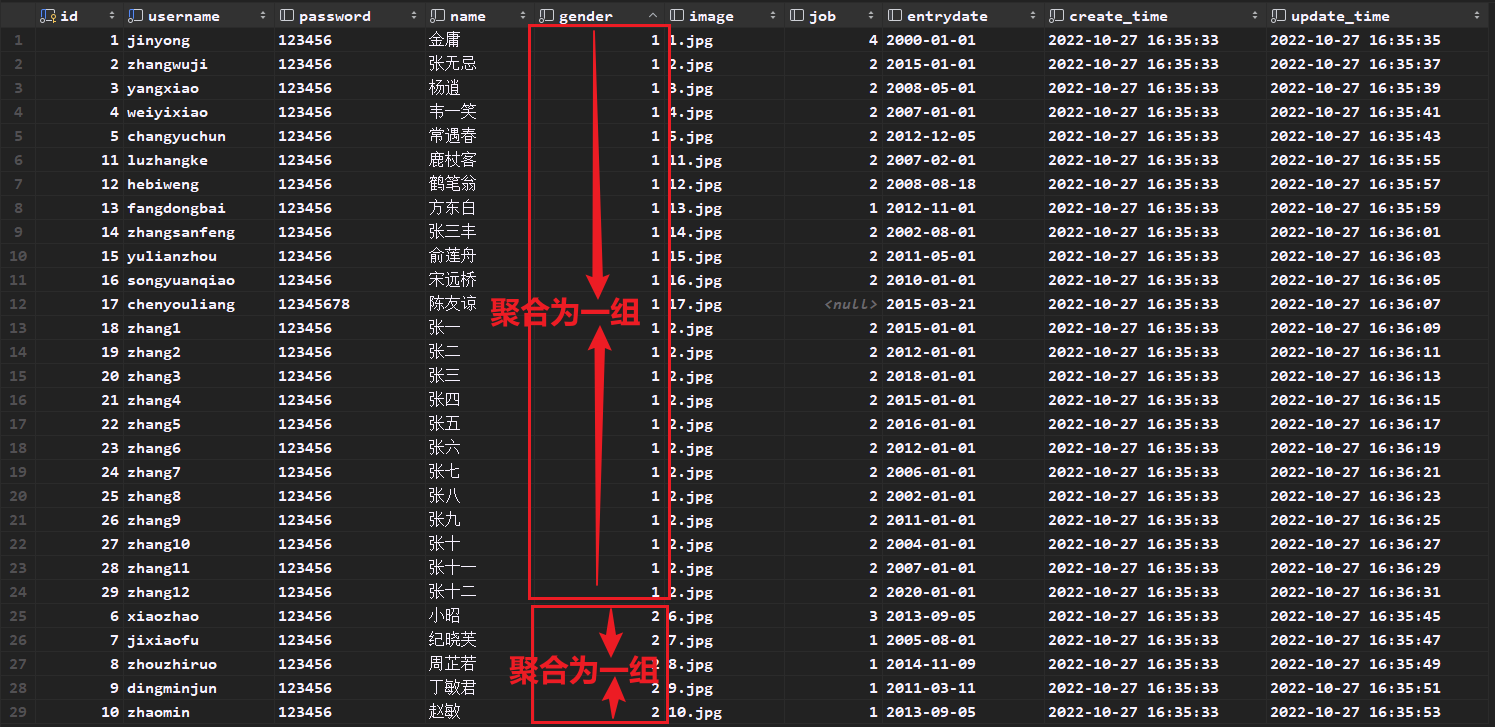
分组查询
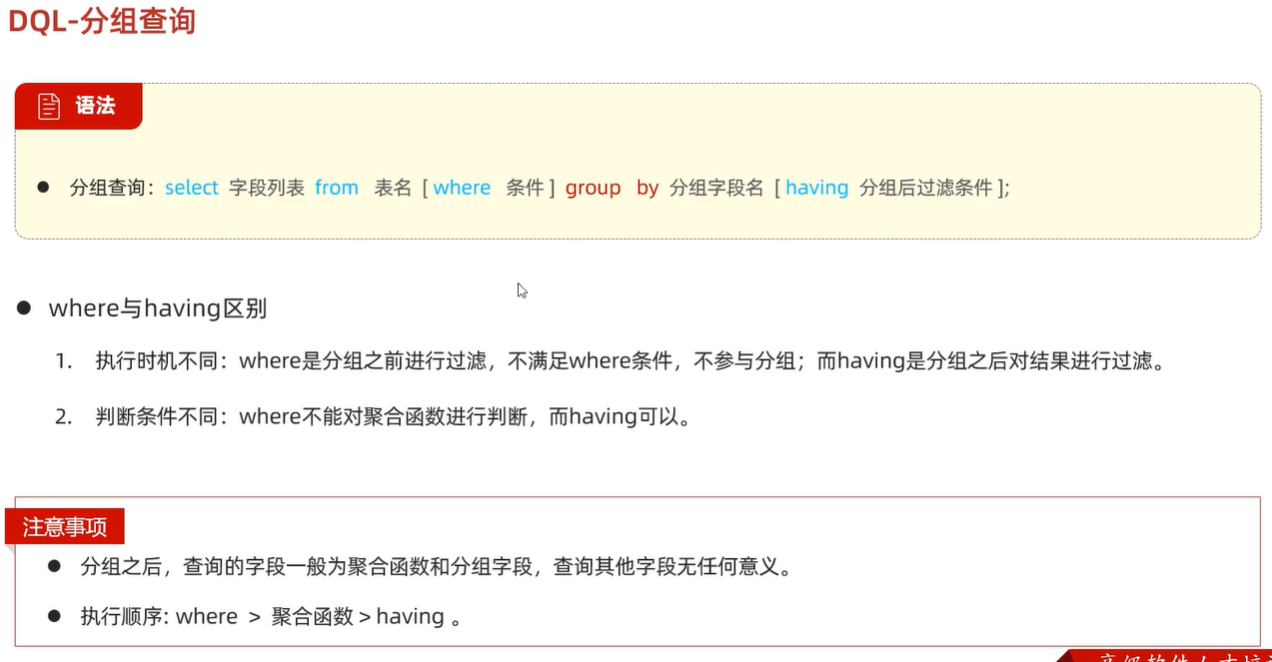
# 按照性别分组,统计男性和女性员工的数量 select gender,count(*) from tb_emp group by gender; # 分组查询的select字段只能包含分组字段和聚合函数 # 先查询入职时间在'2015-01-01'以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位 select job,count(*) from tb_emp where entrydate<='2015-01-01' group by job having count(*)>=2where和having区别
- 执行实际不同:where是对分组之前进行过滤,而having是对分组之后的结果进行过滤
- 判断条件不同:where不能对聚合函数进行判断,而having可以对聚合函数进行判断
为什么分组查询的字段只能是聚合函数和分组字段呢?分组查询的字段只能是聚合函数和分组字段的原因在于分组操作的特性。分组查询将数据按指定字段分成多个组,原本的多行数据会被合并为较少的行。如果在查询中使用普通字段,由于这些字段在每一行的数据可能各不相同,因此无法用一个普通字段值来代表整个组的所有数据,这样的查询没有意义。而分组字段在每个组内的值是相同的,可以用一个字段值来表示整个组的数据。而聚合函数的作用是对分组后的每个组的多行数据进行计算,将其结果合并为一个单一的值,适用于分组后的展示。因此,分组查询的结果中只能包含分组字段和聚合函数。
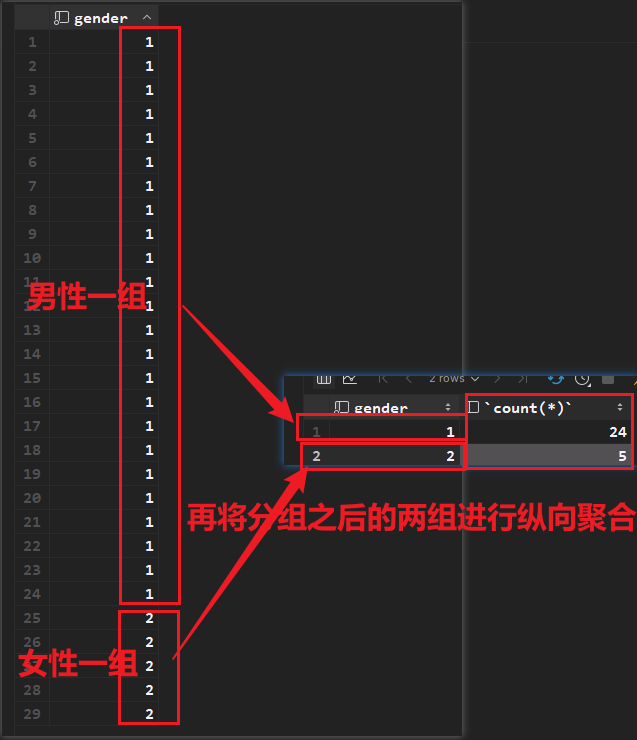
案例:按照性别分组,统计男性和女性员工的数量
select gender,count(*) from tb_emp group by gender; # 分组查询的select字段只能包含分组字段和聚合函数将以上的查询语句拆分,我们首先查询分组字段gender,
select gender form tb_emp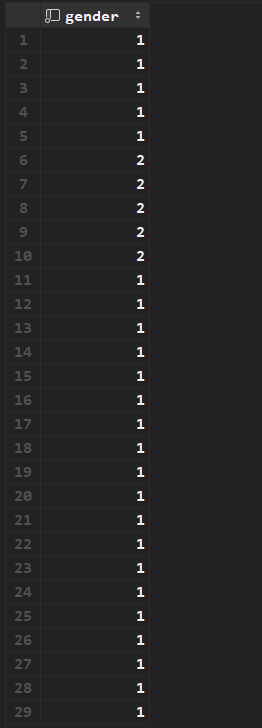
然后采用聚合函数对分组之后的数据的每组分别进行聚合;
select count(*) from tb_emp group by gender;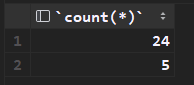
最后再显示分组字段gender即可
4.排序查询
排序方式
- ASC 升序(默认值)
- DESC 降序
如果是多字段排序,只有当第一个字段相同时,才会根据第二字段进行查询。# 根据入职时间对员工进行升序排序 select * from tb_emp order by entrydate asc; # 根据入职时间,对员工进行降序排序 select * from tb_emp order by entrydate desc ; # 根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序 select * from tb_emp order by entrydate asc,update_time desc ;
5.分页查询
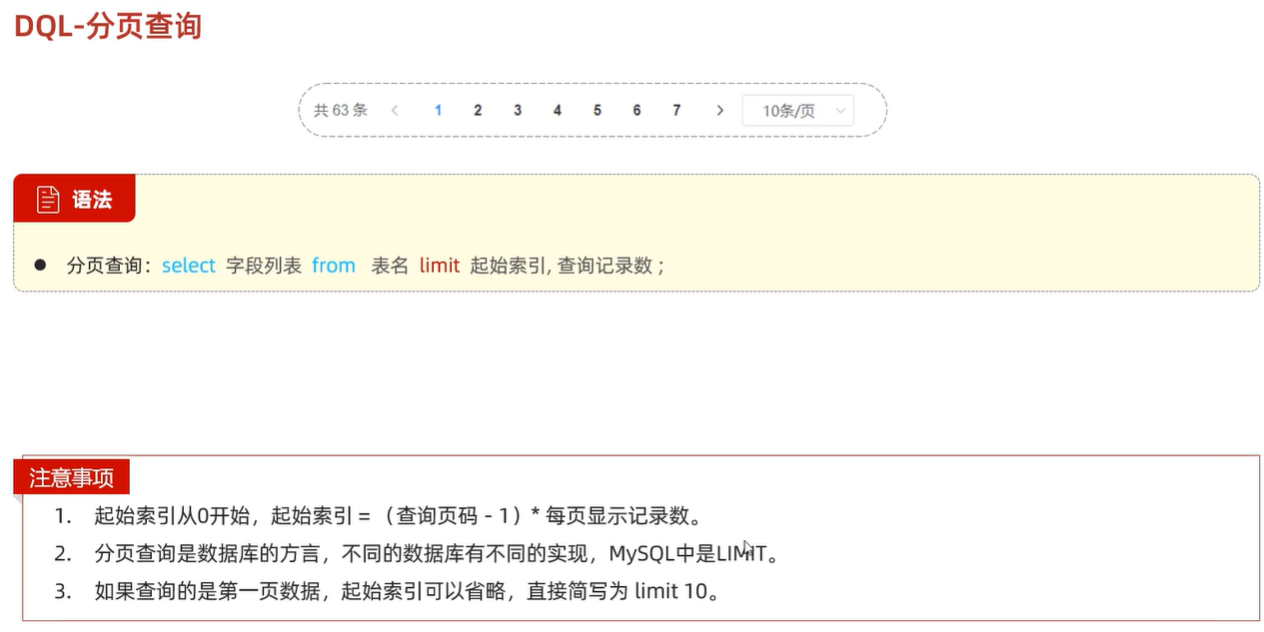
select … from … limit 起始索引,查询记录数
计算方式:起始索引 = (查询页码-1)* 每页显示记录数
# 从起始索引0开始查询员工数据, 每页展示5条记录 select * from tb_emp limit 0,5; select * from tb_emp limit 5; # 查询第一页数据,起始索引可以省略,直接写查询记录数 # 查询 第1页 员工数据, 每页展示5条记录 select * from tb_emp limit 0,5; # 查询 第2页 员工数据, 每页展示5条记录 select * from tb_emp limit 5,5; # 查询 第3页 员工数据, 每页展示5条记录 select * from tb_emp limit 1,5;其实我是这样算的,如果需要展示第三页数据,每页展示5条,那么前两页一共展示了5*2=10条数据,那么第三页第一条数据务必是第10+1条,由于起始索引是从0开始算的,因此起始索引改为11-1=10,因此起始索引 = (查询页码-1)x 每页显示条数
案例
案例一
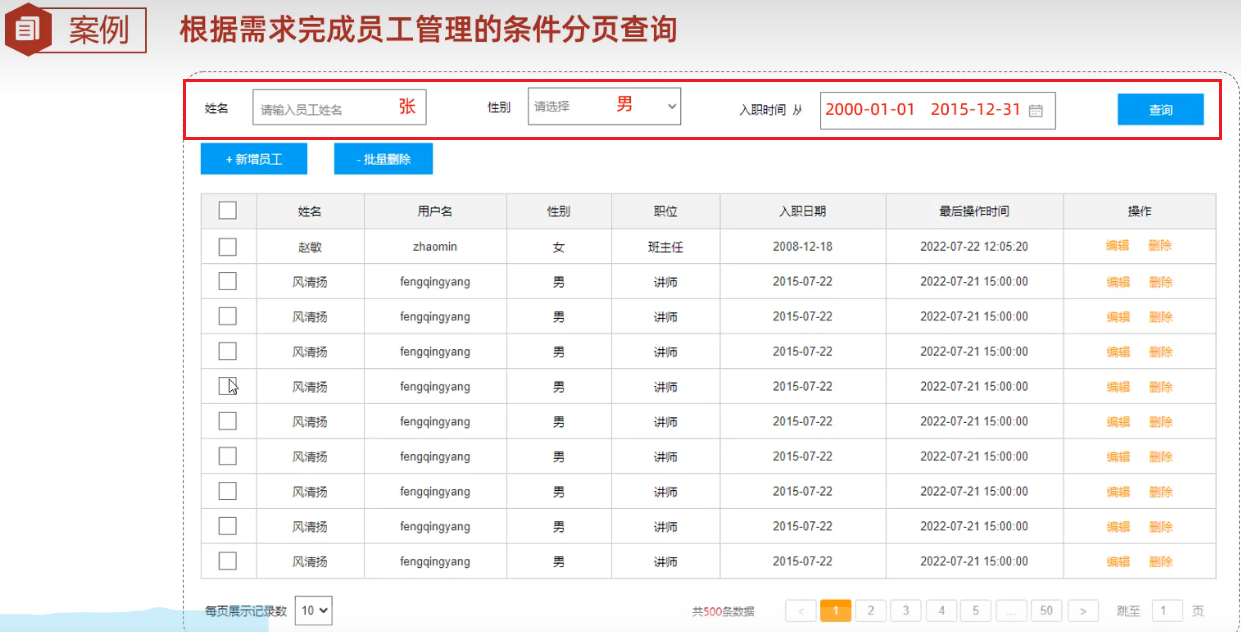
# 输入条件:姓名张模糊匹配,性别男,入职时间在2000-01-01和2015-12-31之间,分页查询每页展示5个,展示第二页,将展示结果按照更新时间降序排序 select * from tb_emp where name like '%张%' and gender=1 and entrydate between '2000-01-01' and '2015-12-31' order by update_time desc limit 10,5 ;案例二
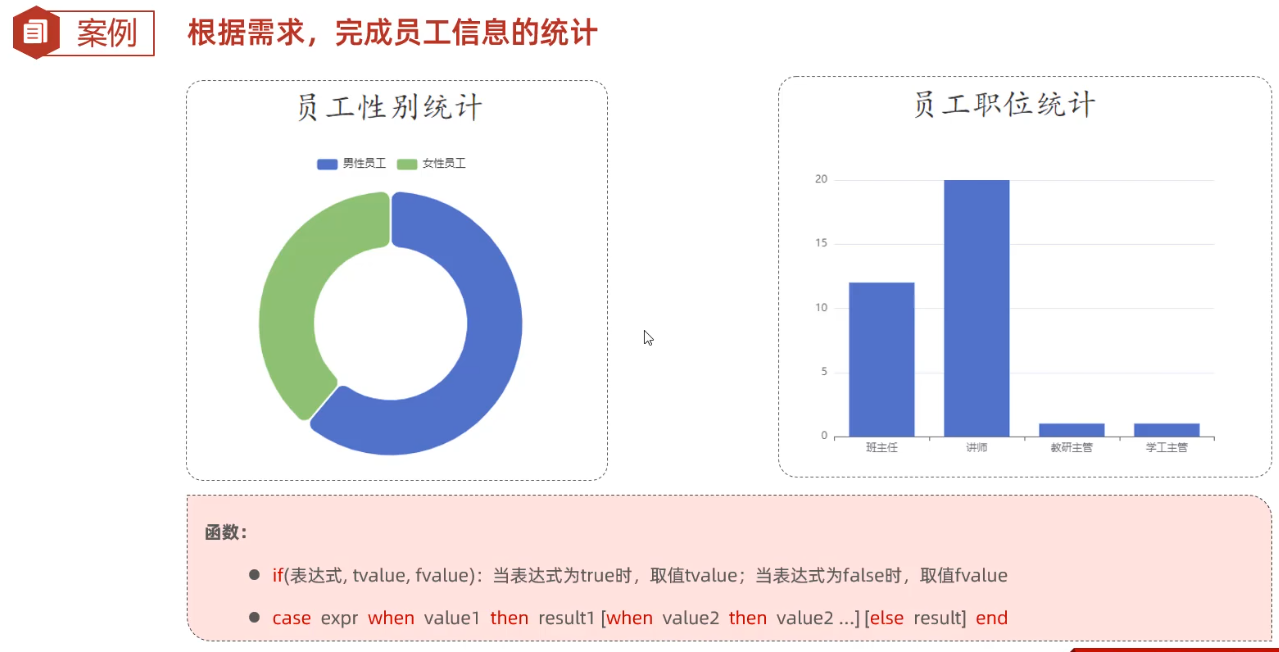
员工性别统计,执行sql语句,将男女人数结果传入调用前端组件渲染到前端界面
# 根据需求完成性别信息的统计 count(*) select if(gender=1,'男性员工','女性员工') 性别,count(*) 人数 from tb_emp group by gender; # 当gender=1时,性别展示男性,否则展示女性 if(条件表达式,true取值,false取值) # 当条件表达式为true,取第一个值;为false取第二个值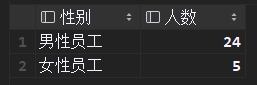
员工职位统计
# 根据需求完成员工职位信息的统计 select case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管' when 4 then '教研主管' else '未分配职位' end 职位, count(*) 人数 from tb_emp group by job order by count(*); case关键字: case 表达式 when 值1 then 结果1 when 值2 then 结果2 when 值3 then 结果3 ... else 结果4 end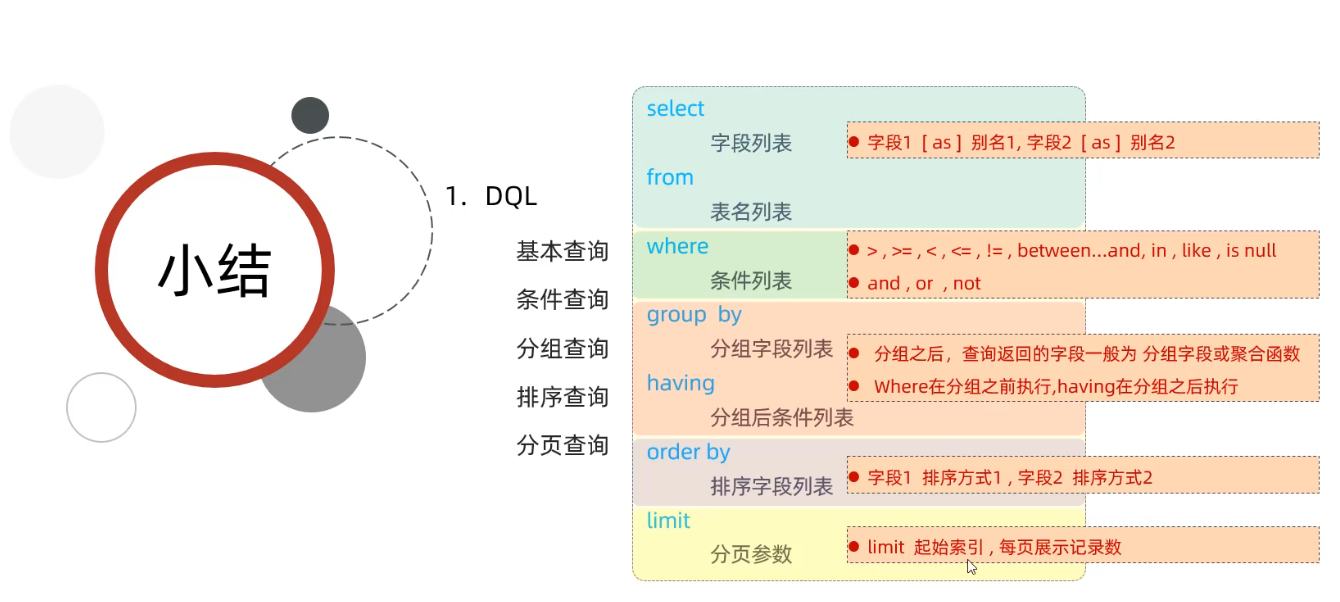
6.多表设计

6.1 一对多
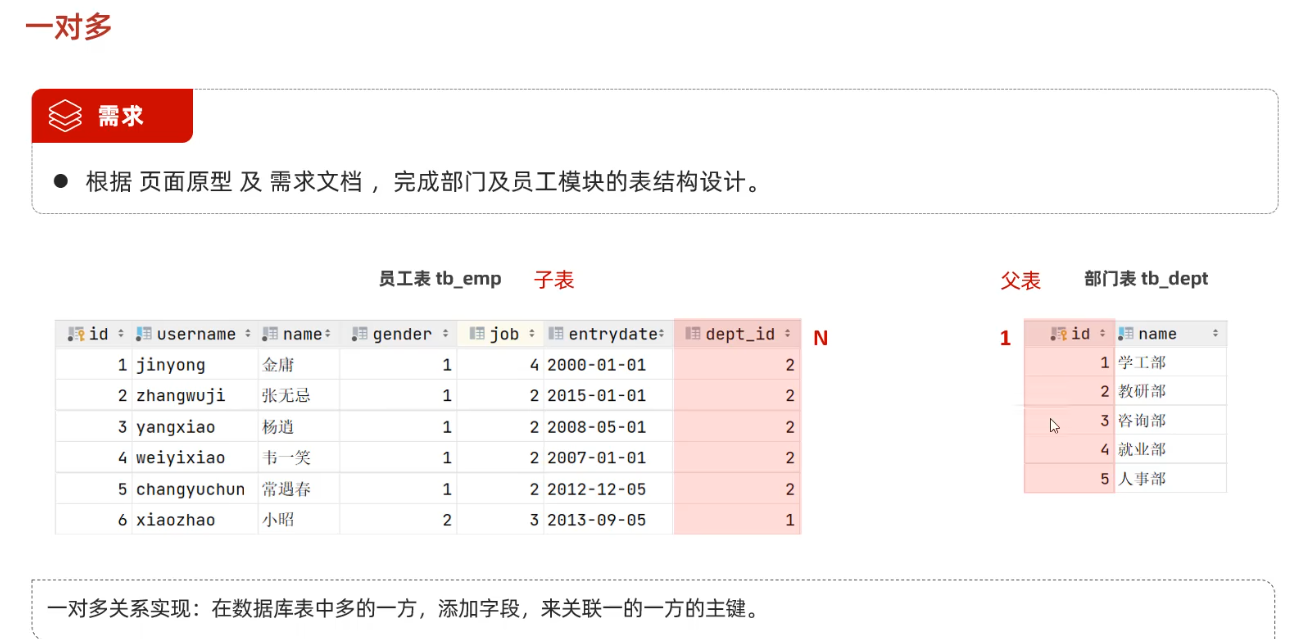
多的表一方称为子表,一表成为父表。
但是我们还发现一个问题,当我们删除了部门表的某个部门之后,员工表仍然存在删除的部门表的员工,这样做是不合理的,也说明了仅仅只在子表内添加父表的主键字段并没有直接建立起两个表之间的关联逻辑。此时需要给子表的父表主键字段添加外键约束。
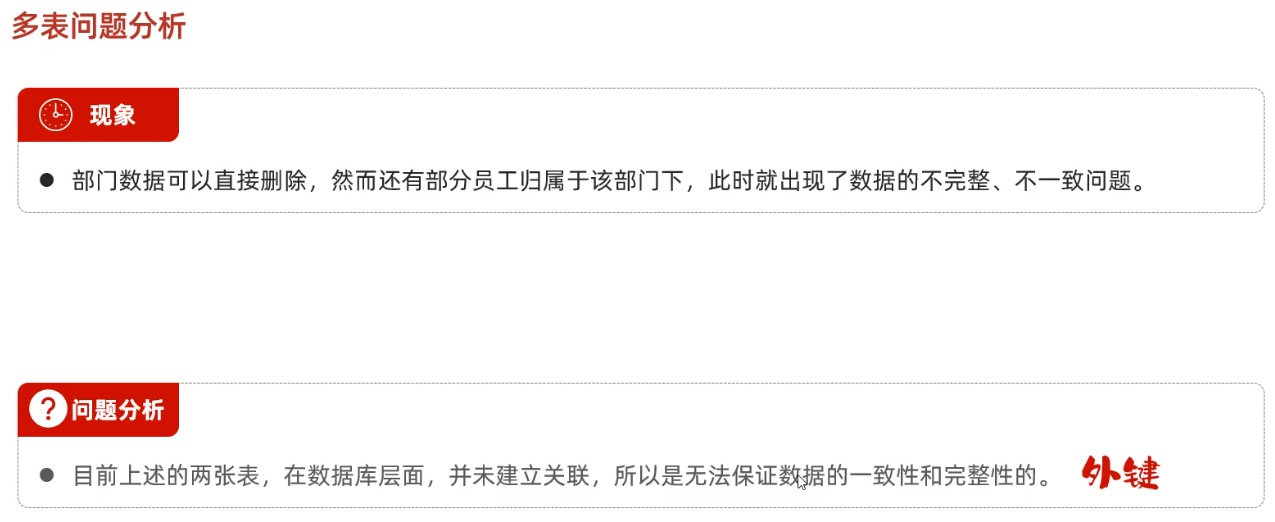

添加外键操作,
及在子表添加父表的主键作为外键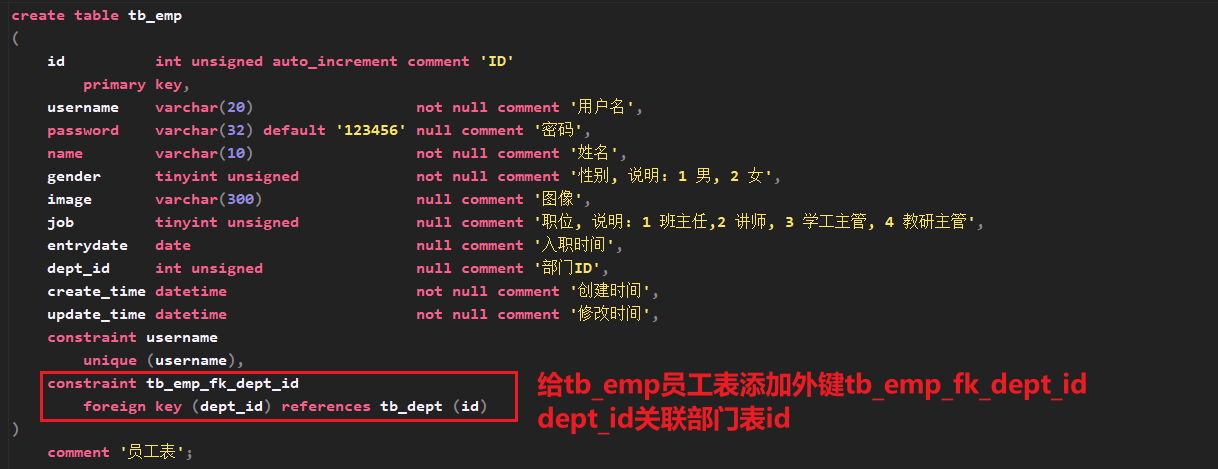
添加外键之后,再删除部门表的部门1数据,则会提示该数据作为其他表的外键不允许删除,只有作为外键表内没有该数据后才可以删除该数据。
Cannot delete or update a parent row: a foreign key constraint fails (`db03`.`tb_emp`, CONSTRAINT `tb_emp_fk_dept_id` FOREIGN KEY (`dept_id`) REFERENCES `tb_dept` (`id`))物理外键
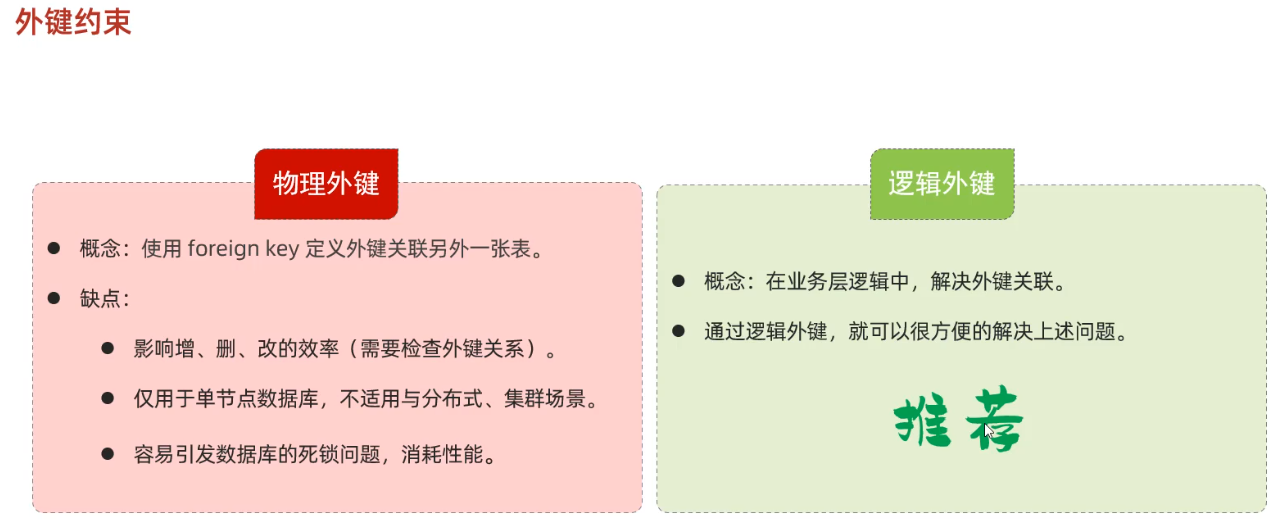
以上通过添加数据库外键确保多张表之间的数据的一致性和完整性的外键称为物理外键,物理外键存在很多问题,我们企业开发里一般推荐的是采用逻辑外键(及不在数据库层面设计外键约束,而是通过代码逻辑层面实现数据库外键的关联)
6.2 一对一
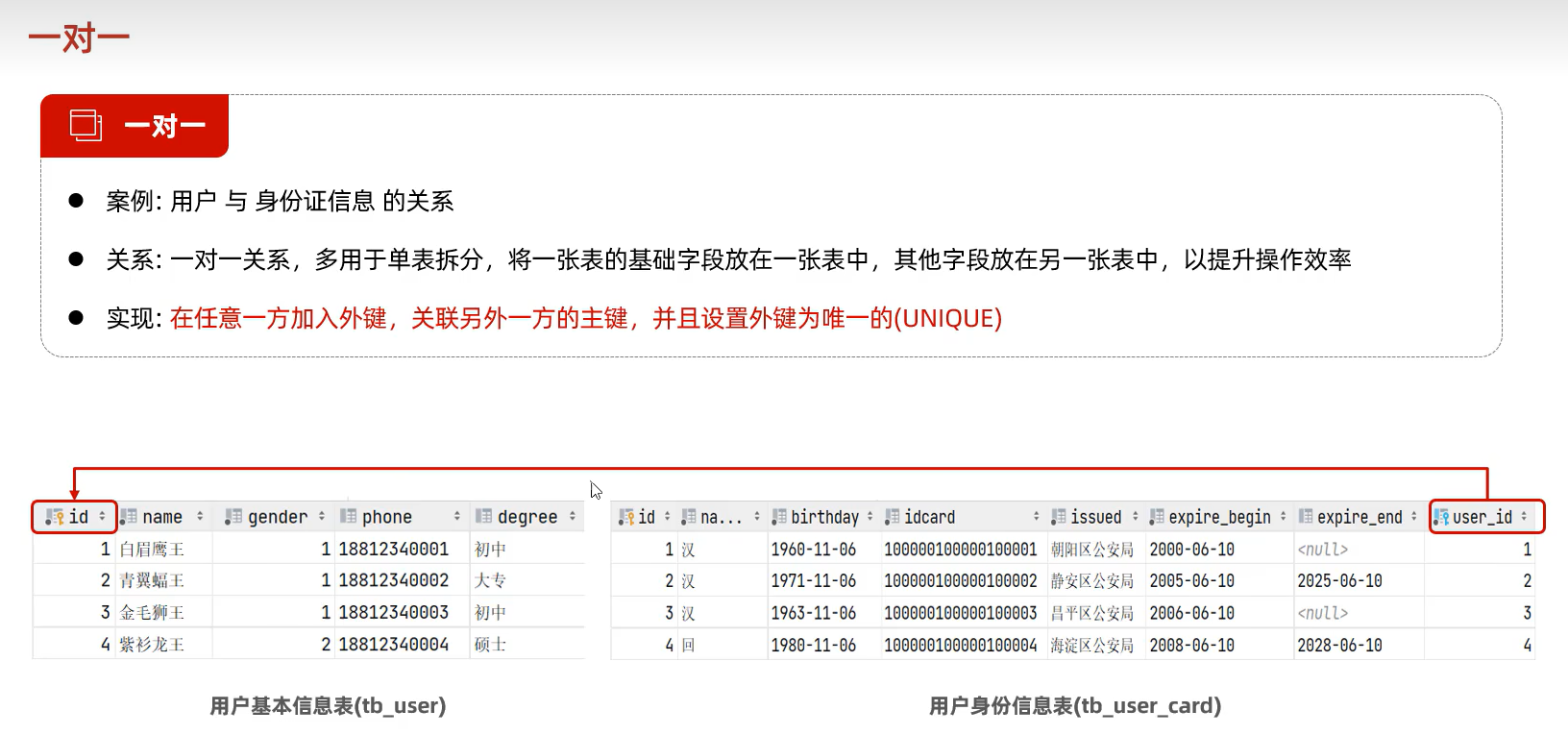
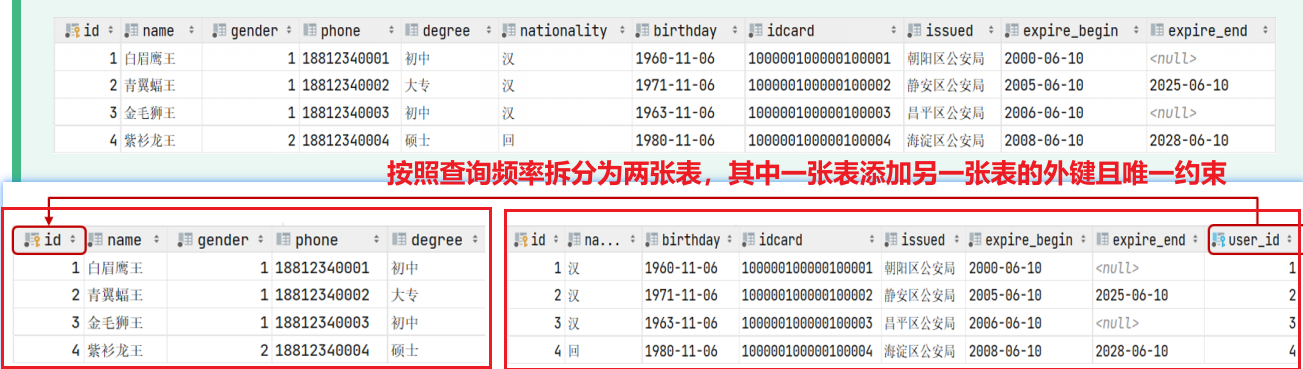
一对一关系表在实际开发中应用起来比较简单,通常是用来做单表的拆分,也就是将一张大表拆分成两张小表,将大表中的一些基础字段放在一张表当中,将其他的字段放在另外一张表当中,以此来提高数据的操作效率。
如果在业务系统当中,对用户的基本信息查询频率特别的高,但是对于用户的身份信息查询频率很低,此时出于提高查询效率的考虑,我就可以将这张大表拆分成两张小表,第一张表存放的是用户的基本信息,而第二张表存放的就是用户的身份信息。他们两者之间一对一的关系,一个用户只能对应一个身份证,而一个身份证也只能关联一个用户。
6.3 多对多
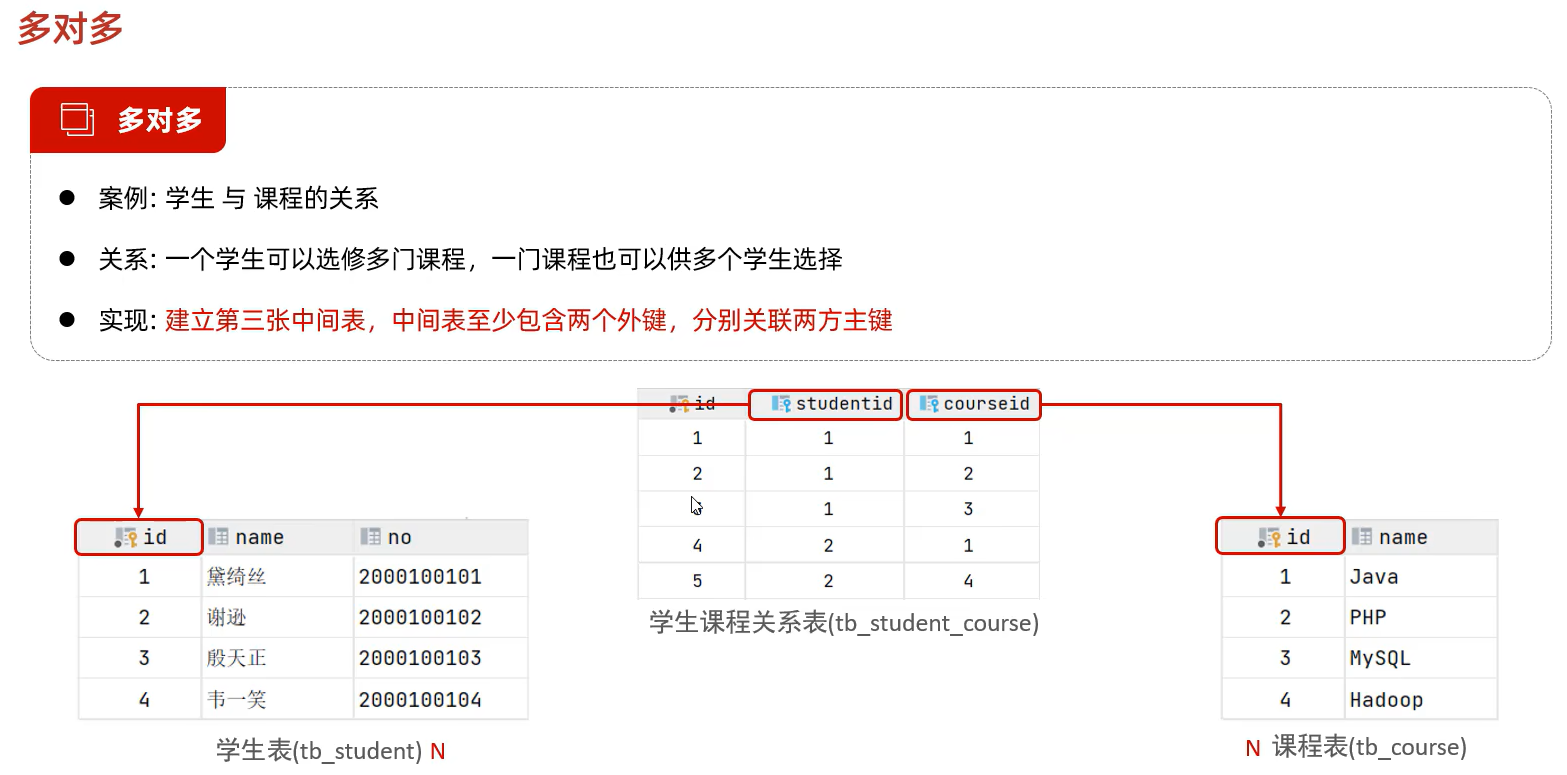
多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。在比如:学生和课程的关系,一个学生可以选修多门课程,一个课程也可以供多个学生选修。
一个学生选择了多个课程,如果在学生表添加外键课程id只能添加一个,因此不能采用外键的方式实现;正确的方法应该是
建立一张中间表,包含学生和课程的外键关联两方的主键。案例 多表设计
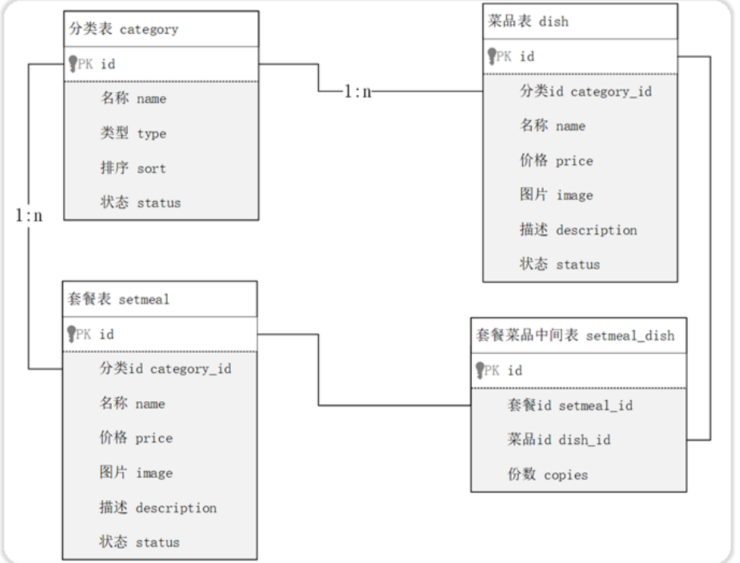
根据页面原型,设计分类管理、菜品管理、套餐管理模块的表结构
首先分析一下,一个分类包含多个菜品和套餐,因此商品分类和菜品和套餐的关系皆是一对多,而一个套餐可能包含多个菜品,一个菜品可以被多个套餐选择,因此菜品和套餐之间是多对多的关系,设计表结果关系如下所示
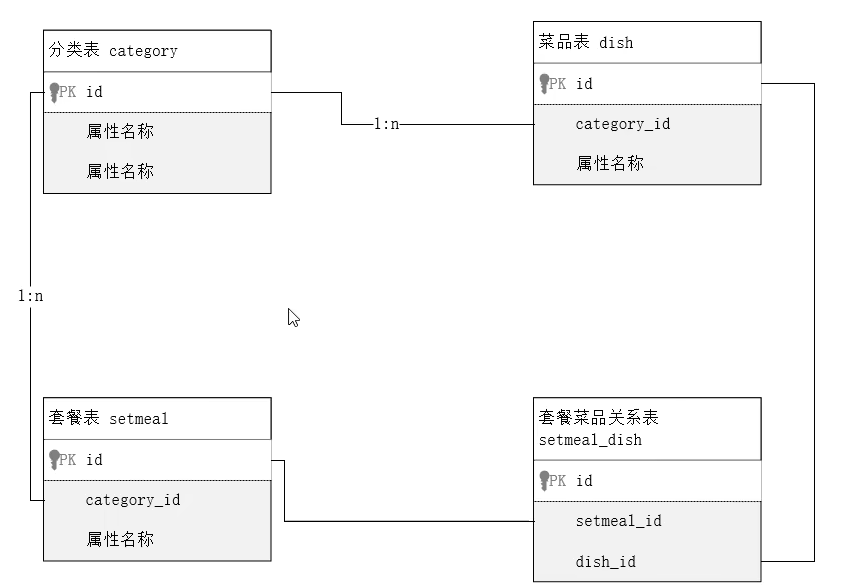
分类管理模块
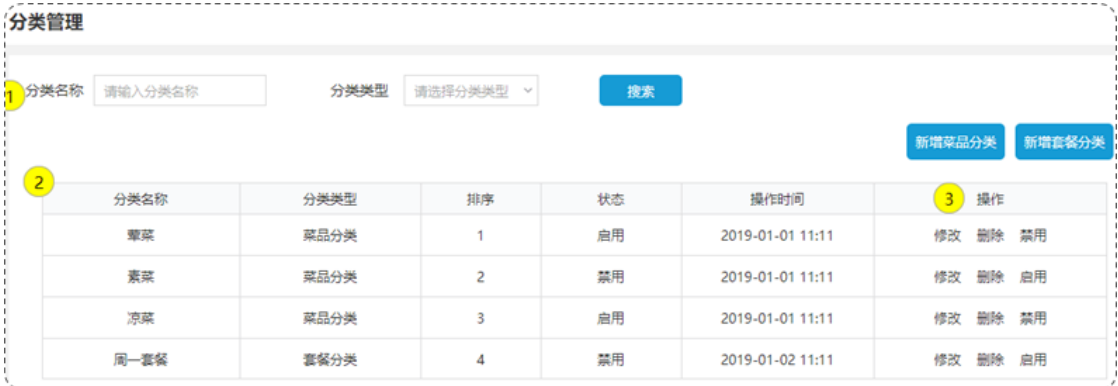
设计商品分类表category
-- 分类表 create table category( id int unsigned primary key auto_increment comment '主键ID', name varchar(20) not null unique comment '分类名称', type tinyint unsigned not null comment '类型 1 菜品分类 2 套餐分类', sort tinyint unsigned not null comment '顺序', status tinyint unsigned not null default 0 comment '状态 0 禁用,1 启用', create_time datetime not null comment '创建时间', update_time datetime not null comment '更新时间' ) comment '菜品及套餐分类' ;菜品管理模块
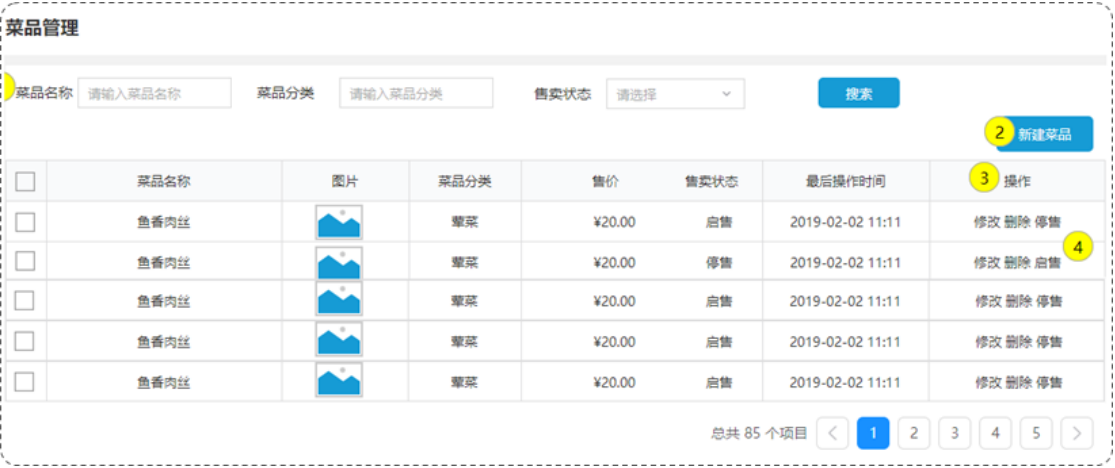
设计菜品表dish
-- 菜品表 create table dish( id int unsigned primary key auto_increment comment '主键ID', name varchar(20) not null unique comment '菜品名称', category_id int unsigned not null comment '菜品分类ID', price decimal(8, 2) not null comment '菜品价格', image varchar(300) not null comment '菜品图片', description varchar(200) comment '描述信息', status tinyint unsigned not null default 0 comment '状态, 0 停售 1 起售', create_time datetime not null comment '创建时间', update_time datetime not null comment '更新时间' ) comment '菜品';套餐管理模块
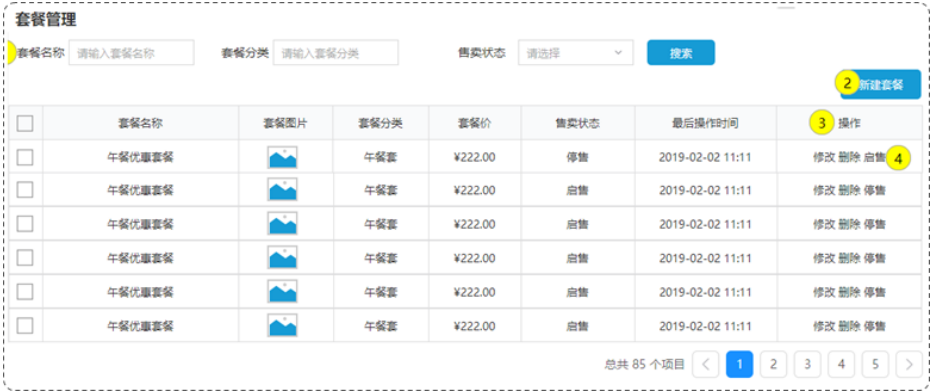
设计套餐表setmeal
create table setmeal( id int unsigned primary key auto_increment comment '主键ID', name varchar(20) not null unique comment '套餐名称', category_id int unsigned not null comment '分类id', price decimal(8, 2) not null comment '套餐价格', image varchar(300) not null comment '图片', description varchar(200) comment '描述信息', status tinyint unsigned not null default 0 comment '状态 0:停用 1:启用', create_time datetime not null comment '创建时间', update_time datetime not null comment '更新时间' )comment '套餐' ;设计套餐菜品关系表setmeal_dish
-- 套餐菜品关联表 create table setmeal_dish( id int unsigned primary key auto_increment comment '主键ID', setmeal_id int unsigned not null comment '套餐id ', dish_id int unsigned not null comment '菜品id', copies tinyint unsigned not null comment '份数' )comment '套餐菜品关系';7.多表查询
查询单个表的语句是
select 字段 from 表名;查询多个表的语句
select 字段 from 表1,表2;但是这样查询会产生笛卡尔积
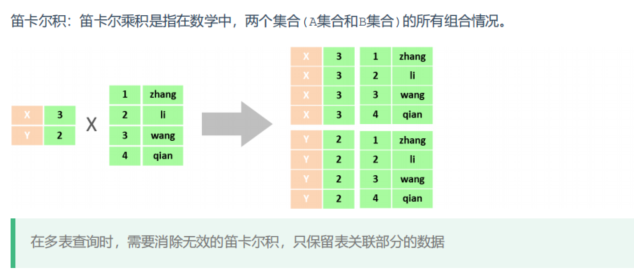
为了消除笛卡尔积,保留我们需要的数据,我们需要添加一个查询条件,
如下连接查询员工表和部门表
select * from tb_emp , tb_dept where tb_emp.dept_id = tb_dept.id ;
多表查询概述
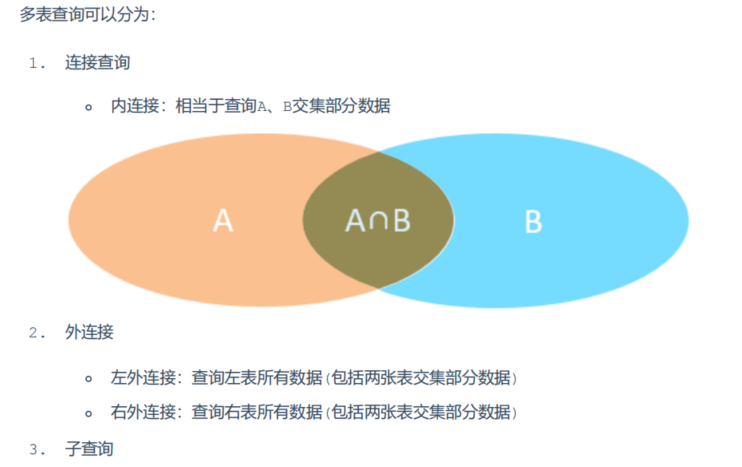
多表查询包含连接查询和子查询,连接查询又分为内连接和外连接查询;子查询及一个查询语句为另一个查询语句的子条件。
连接查询分为内连接插叙和外连接查询
7.1 内连接
内连接查询:查询两表或多表中交集部分数据。
内连接查询在语法上包含隐式内连接和显示内连接查询两大类

# 查询员工表的姓名,以及所属部门的名称 # 隐式内连接 select * from tb_emp e,tb_dept d where e.dept_id=d.id; # 显示内连接 select tb_emp.name , tb_dept.name from tb_dept inner join tb_emp where tb_emp.id=tb_dept.id;如果两个表之间有数据没有关联另一张表,那么内连接是查询不出来的,但是外连接却可以查询得到。
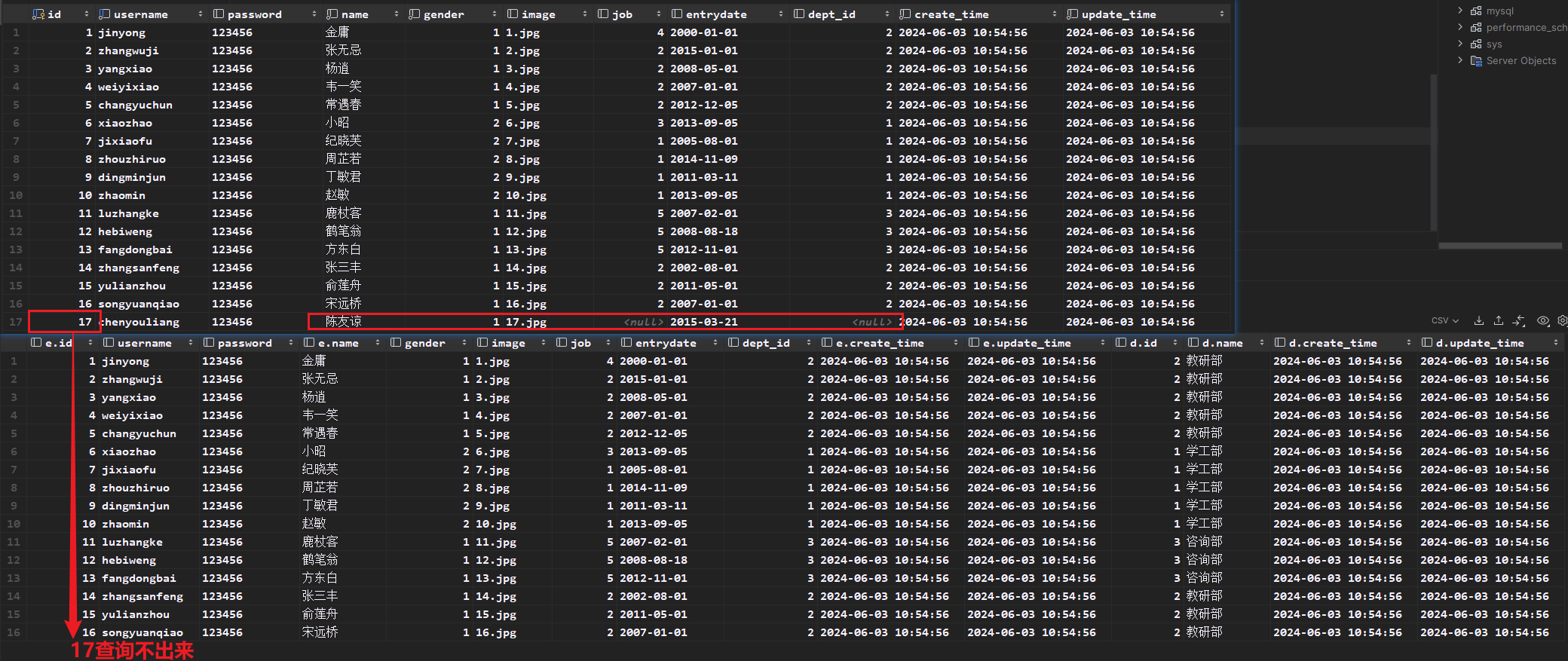
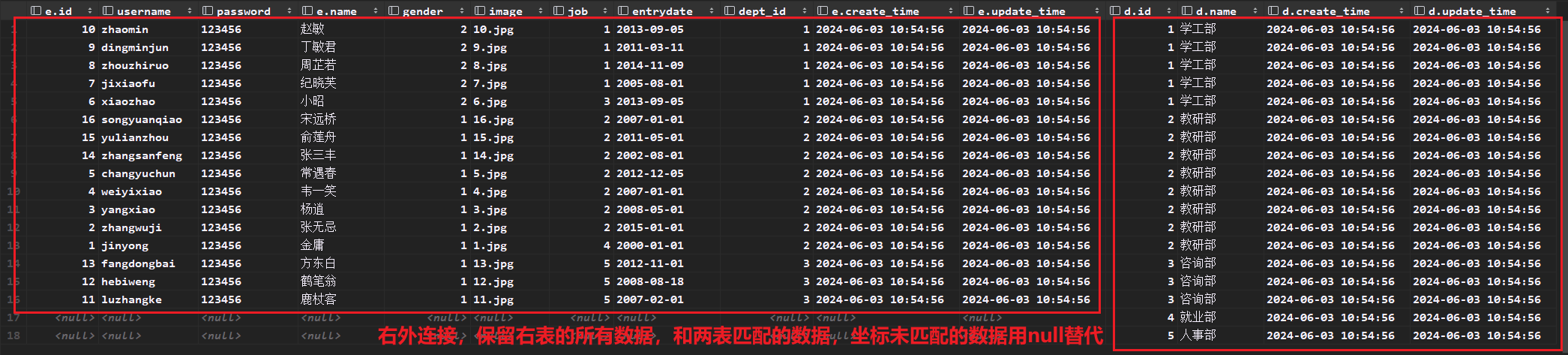
7.2 外连接
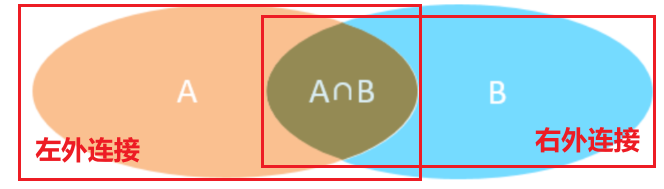
外连接分为左外连接和右外连接
左外连接语法结构:
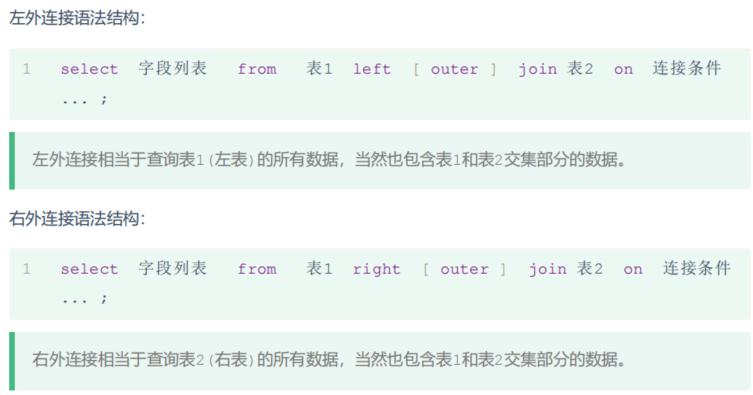
# 查询员工表的所有员工姓名,和对应的部门名称(左外连接) select e.name, d.name from tb_emp e left join tb_dept d on e.dept_id = d.id; # 查询部门表的所有部门的名称,和对应员工名称 select * from tb_emp e right join tb_dept d on e.dept_id = d.id;外连接相当于查询到本体的全部数据附加两个表之间关联相同的数据,当本体表的数据与外连接的表的数据没有关联时,外连接表的数据用null代替。
外连接和内连接都是表的横向合并。

7.3 子查询
SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
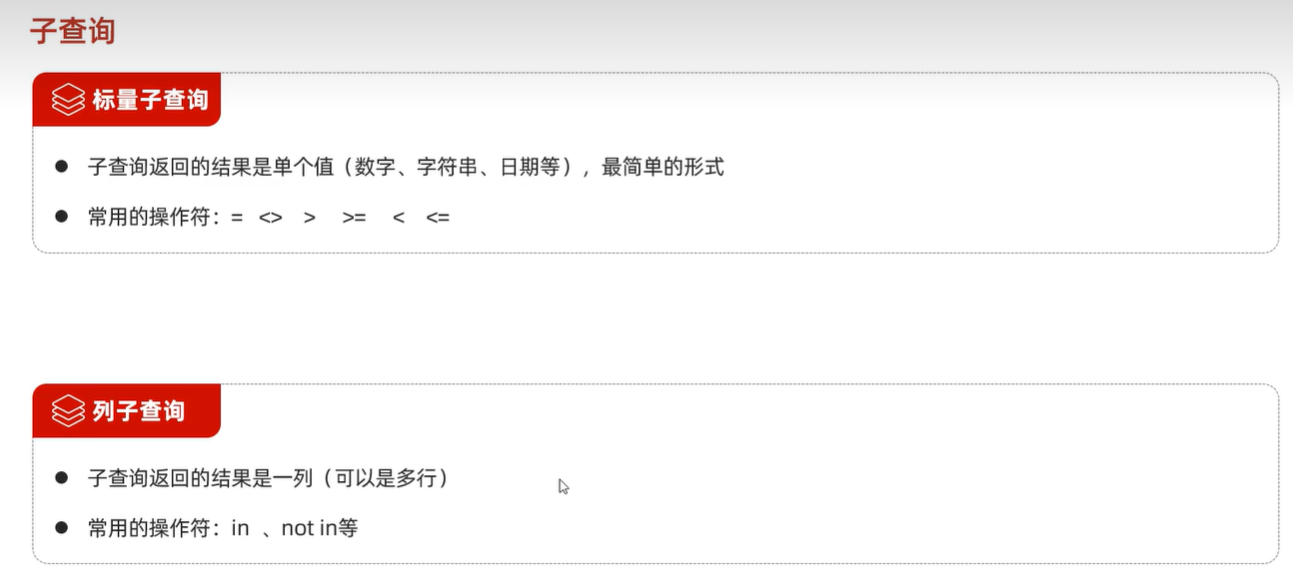
标量子查询,子查询返回的结果是单个数值
案例:查询教研部所有员工的信息
# 1.首先查询教研部的部门id select id from tb_dept where name = '教研部'; # 查询结果为2 # 2.根据以上教研部的部门id查询该部门的所有员工 select * from tb_emp e where dept_id = 2; # 合并以上两条sql语句 select * from tb_emp e where dept_id = (select id from tb_dept where name = '教研部'); # 查询'方东白'入职之后的员工信息 # 1.首先查询方东白的入职时间 select entrydate from tb_emp where name='方东白'; # 2.查询以上方东白入职时间之后的入职员工信息 select * from tb_emp where entrydate > (select entrydate from tb_emp where name='方东白');列子查询,子查询返回的是一列多行
案例:查询"教研部"和"咨询部"的所有员工信息
# 1.查询'销售部'和'市场部'的部门id select id from tb_dept where name = '教研部' or name = '咨询部';
# 2.根据查询到的id,查询员工信息 select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部');
行子查询 子查询返回的结果是一行(可以是多列)
案例:查询与"韦一笑"的入职日期及职位都相同的员工信息
# 1.查询 "韦一笑" 的入职日期 及 职位 select entrydate,job from tb_emp where name ='韦一笑';
# 2.查询与"韦一笑"的入职日期及职位相同的员工信息 select * from tb_emp where (entrydate,job) = (select entrydate,job from tb_emp where name ='韦一笑');表子查询 子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询。
案例:查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
# 1.查询入职日期是 "2006-01-01" 之后的员工信息 select * from tb_emp where entrydate > '2006-01-01'; # 2.基于查询到的员工信息,在查询对应的部门信息 select * from (select * from tb_emp where entrydate > '2006-01-01') e left join tb_dept d on e.dept_id=d.id;案例
-- 1. 查询价格低于 10元 的菜品的名称 、价格 及其 菜品的分类名称 . select d.name,d.price,c.name from dish d,category c where d.category_id = c.id; -- 2. 查询所有价格在 10元(含)到50元(含)之间 且 状态为'起售'的菜品名称、价格 及其 菜品的分类名称 (即使菜品没有分类 , 也需要将菜品查询出来). select d.name,d.price,c.name from dish d left join category c on d.category_id = c.id where price between 10 and 50 and d.status = 1; -- 3. 查询每个分类下最贵的菜品, 展示出分类的名称、最贵的菜品的价格. select c.name, max(d.price) from dish d,category c where c.id = d.category_id group by category_id; -- 4. 查询各个分类下 状态为 '起售' , 并且 该分类下菜品总数量大于等于3 的 分类名称 . select c.name,count(*) from category c,dish d where c.id = d.category_id and d.status = '1' group by c.name having count(*) >= 3; -- 5. 查询出 "商务套餐A" 中包含了哪些菜品 (展示出套餐名称、价格, 包含的菜品名称、价格、份数). select s.name,s.price,d.name,d.price,sd.copies from setmeal s,setmeal_dish sd,dish d where s.id = sd.setmeal_id and d.id = sd.dish_id and s.name = '商务套餐A'; -- 6. 查询出低于菜品平均价格的菜品信息 (展示出菜品名称、菜品价格). # 1.计算菜品的平均价格 select count(price) from dish; # 2.低于平均价格的菜品信息 select name,price from dish where price<(select count(price) from dish);8.事务
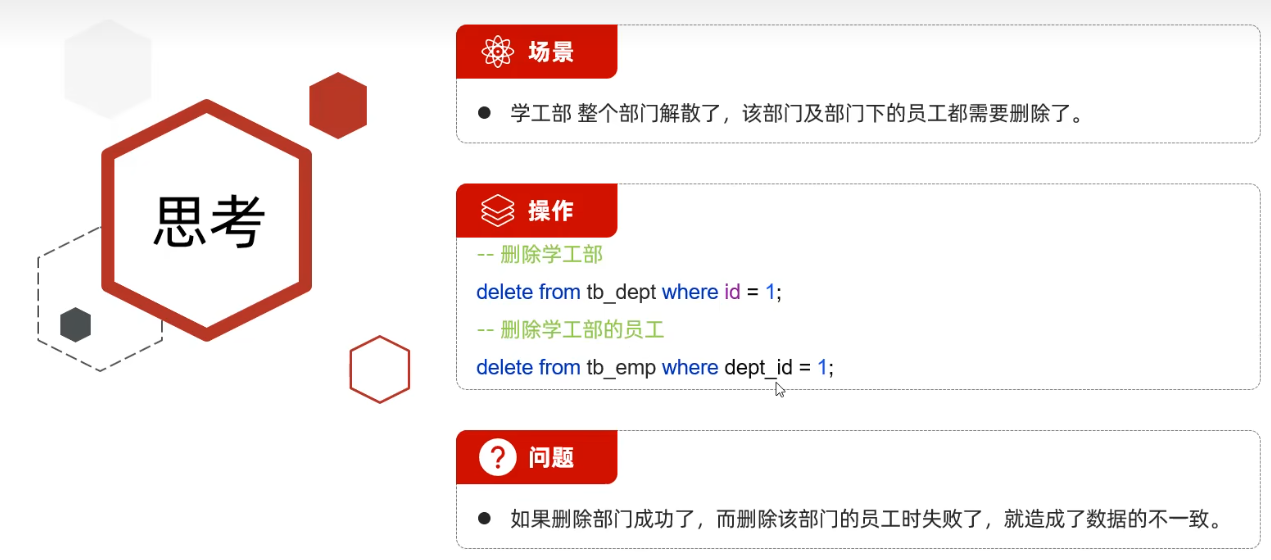
首先实现一个场景,学工部门解散了,该部门下的所有员工都需要删除
delete from tb_dept where id = 1; # 删除部门表的学工部 delete from tb_emp where dept_id = 1; # 删除员工表所有学工部的员工如果说当执行第二步删除员工表所有学工部的员工失败了,会导致员工表内还存在学工部的员工,导致了数据的不一致。
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条SQL语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败
事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。由于mysql默认是自动提交事务的,即执行一条sql语句提交一次事务。因此在以上的案例当中是执行了两个事务,每个事务之间相互独立。
手动提交事务步骤:
- 开启事务->执行sql->成功->提交事务
- 开启事务->执行sql->失败->回滚事务
# 开启事务 start transaction; # begin # 执行sql delete from tb_dept where id = 2; delete from tb_emp where dept_id = 2; # 提交事务 commit; # 回滚事务 rollback;事务的四大特性
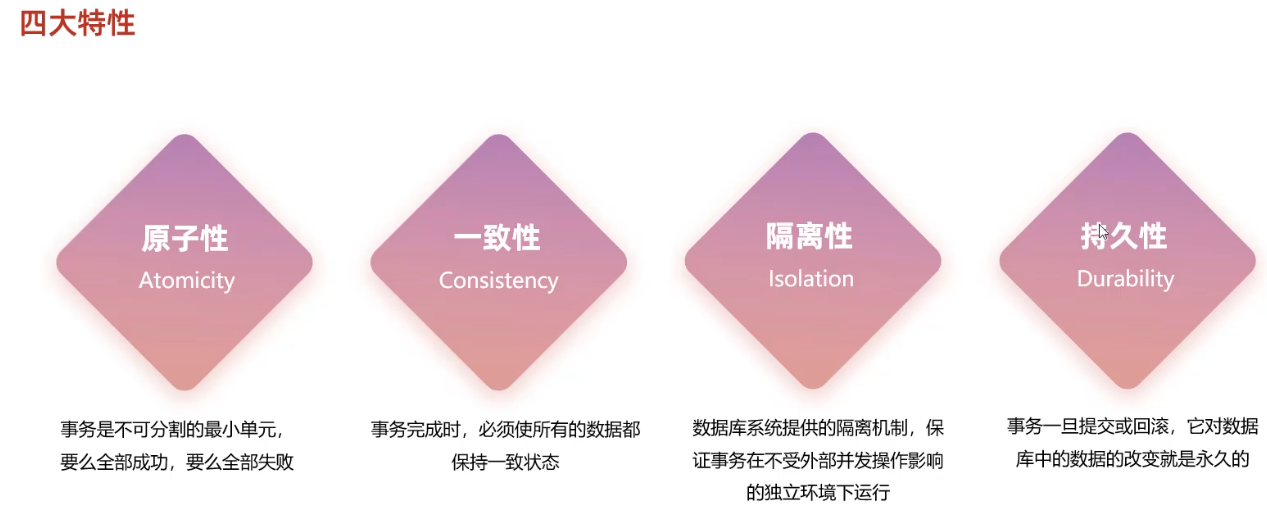
- 原子性:原子性是指事务包装的一组sql是一个不可分割的工作单元,事务操作要么全部成功,要么全部失败。
- 一致性:一个事务完成之后数据必须处于一致的状态;如果事务成功完成,所有的数据变化都生效;如果事务执行出错,所有的数据变化将回滚
- 隔离性:多个用户并发访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
- 持久性:一个事务一旦被提交或者回滚,它对数据库的改变是永久的。
9.索引
9.1 索引语法
索引index,可以帮助高效查询数据的数据结构。我们可以通过创建索引来提高查询效率。
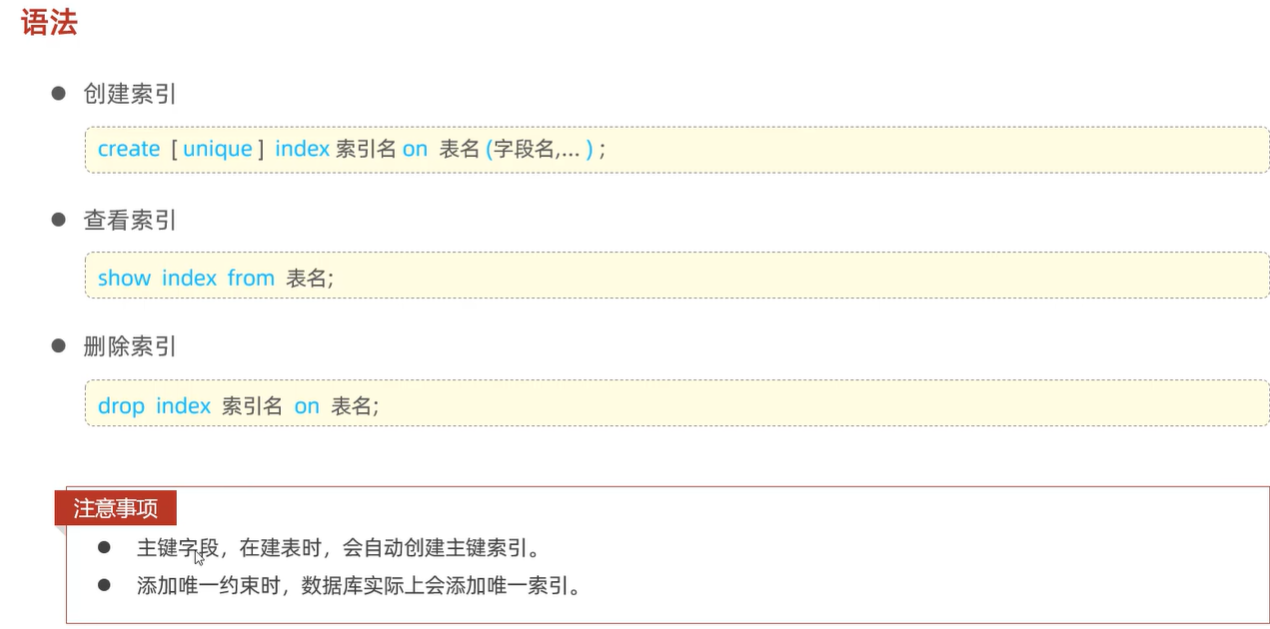
# 创建索引 create index idx_emp_name on tb_emp(name); # 查看表内的所有索引 show index from tb_emp; # 删除idx_emp_name索引 drop index idx_emp_name on tb_emp;
注意事项:
- 创建表的时候,会自动创建主键和唯一约束的索引,其中主键索引是查询速度最快的
添加索引前后速度对比:
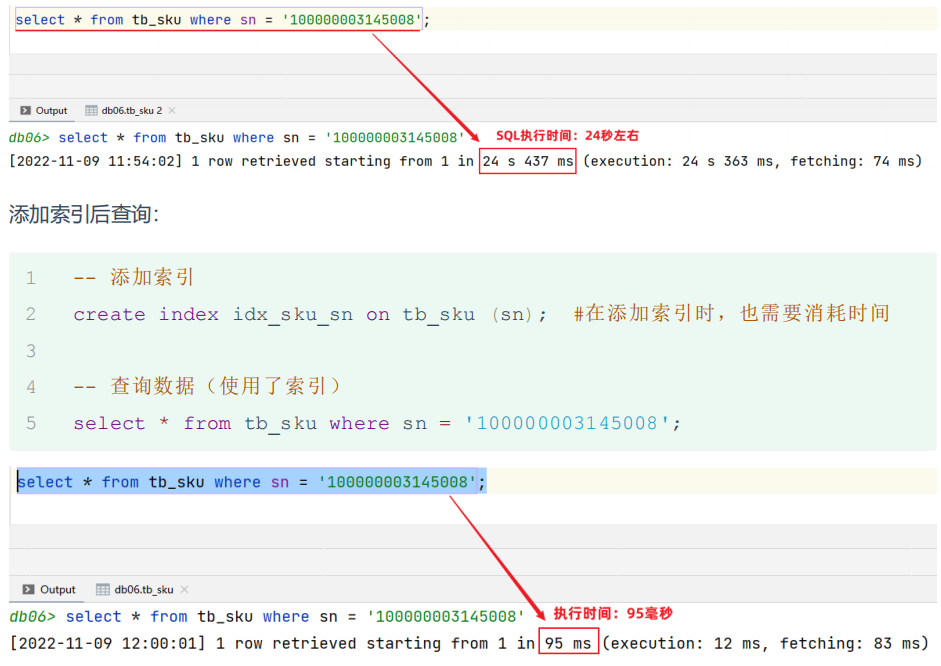
添加索引优点
- 提高数据查询的效率,降低数据库的IO成本
- 通过索引对数据进行排序,降低数据排序的成本,降低CPU消耗
缺点
- 索引会暂用磁盘存储空间
- 索引虽然能极大的提高查询效率,但同时也降低了增删改的效率(因为增删改后需要重新修正索引的数据结构)
9.2 索引数据结构
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。
我们平常所说的索引,如果没有特别指明,都是指默认的
B+Tree结构组织的索引。
为什么不采用二叉树结构,二叉查找树:
左边的子节点比父节点小,右边的子节点比父节点大当我们向二叉查找树保存数据时,是按照从大到小(或从小到大)的顺序保存的,此时就会形成一个单向链表,搜索性能会打折扣。
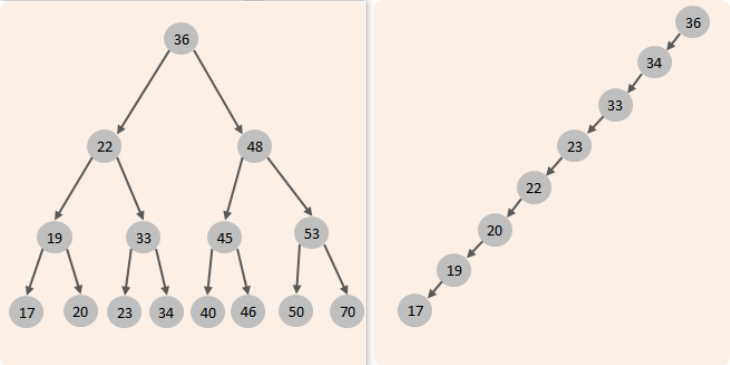
可以选择平衡二叉树或者是红黑树来解决上述问题。(红黑树也是一棵平衡的二叉树)
但是在Mysql数据库中并没有使用二叉搜索数或二叉平衡数或红黑树来作为索引的结构。因为二叉树每个节点只能存储两个值,一旦mysql数据量多起来,会导致二叉树层级非常高,导致查询结果变慢,所以为了减少红黑树的高度,那么就得增加树的宽度,就是不再像红黑树一样每个节点只能保存一个数据,可以引入另外一种数据结构,一个节点可以保存多个数据,这样宽度就会增加从而降低树的高度。这种数据结构例如BTree就满足。
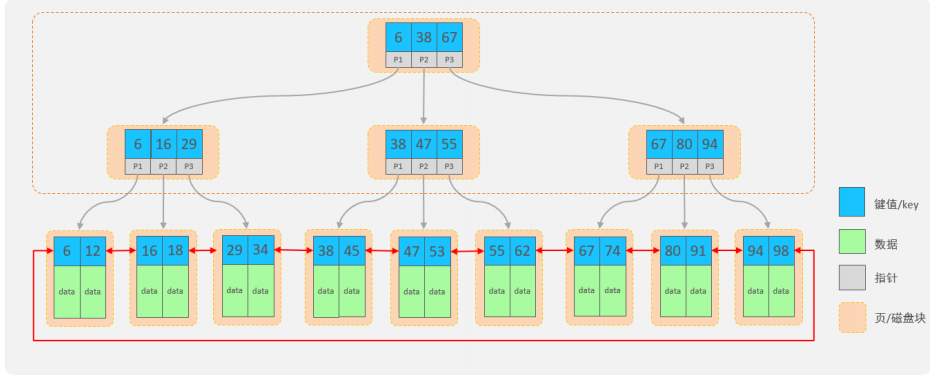
B+Tree结构:
- 每个节点可以存储多个key
- 节点分为:叶子结点和非叶子结点- 叶子结点:最后一层子节点,所有的数据都储存在叶子结点上- 非叶子结点:非最后一层子节点,只能用于索引不存储数据
- 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
六、Mybatis

Mybatis是一款优秀的持久层框架,用于简化JDBC的开发- 官网:https://mybatis.org/mybatis-3/zh/index.html
1、Mybatis快速入门
案例:使用Mybatis查询所有用户的数据
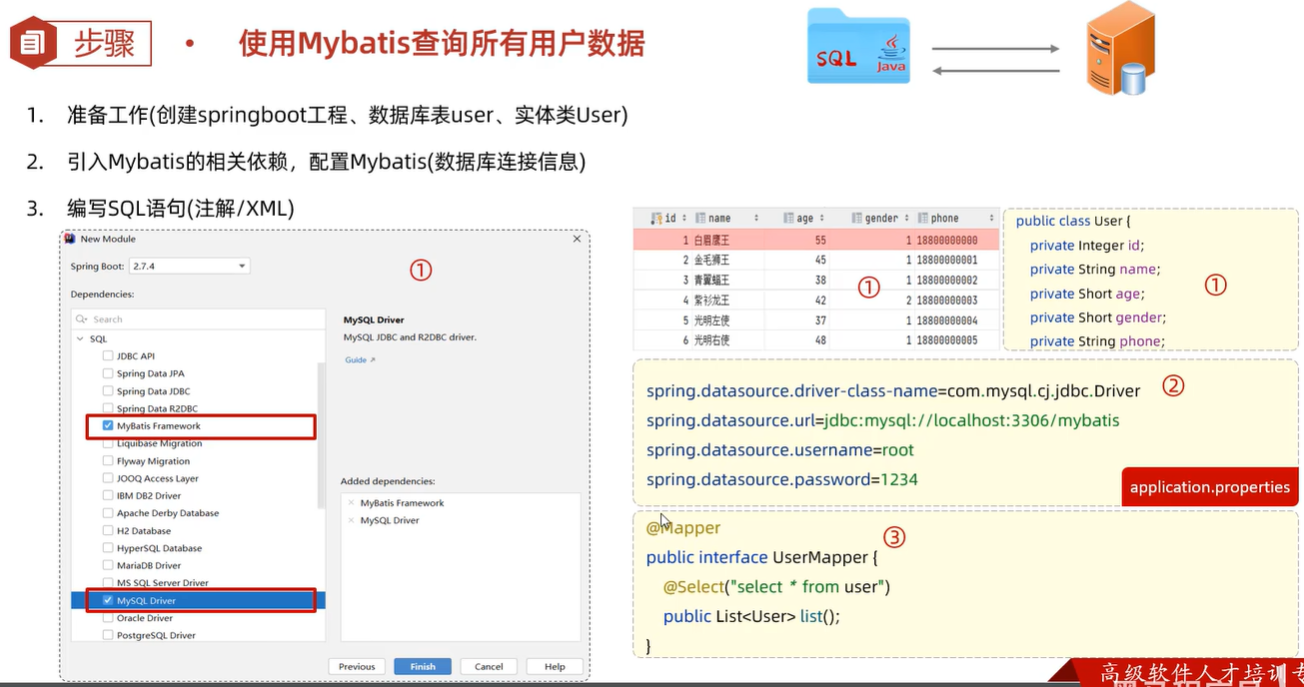
- 创建spring项目,勾选依赖Mybatis framework、MySQL Driver
- 配置Mybatis配置文件由于连接mysql驱动需要知道数据库驱动、数据库url、数据库用户名、数据库密码,因此配置mybatis的application.properties文件也需要配置以上四要素。
# 配置数据库连接信息(四要素)#驱动类名称spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver#数据库连接的urlspring.datasource.url=jdbc:mysql://localhost:3306/mybatis#连接数据库的用户名spring.datasource.username=root#连接数据库的密码spring.datasource.password=root - 根据user表字段创建实体类User
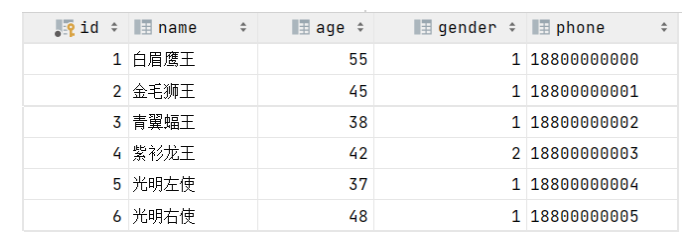
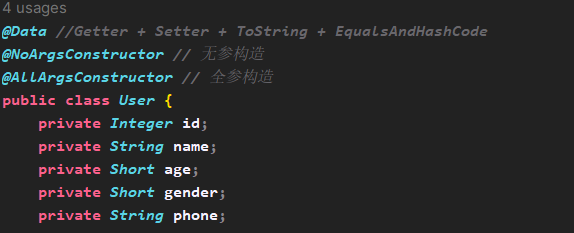
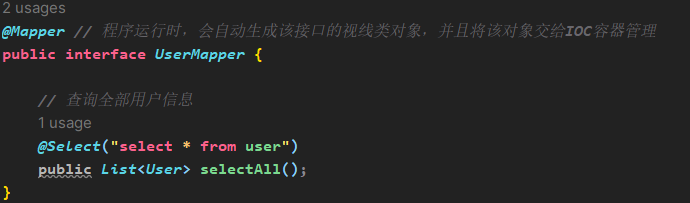
- 在Mapper包下编写接口UserMapper,在接口下写selectAll()方法,使用@Select注解编写SQL语法
- 在test包下的测试主体类下编写测试方法,依赖注入UserMapper对象调用selectAll方法,输出user对象集合
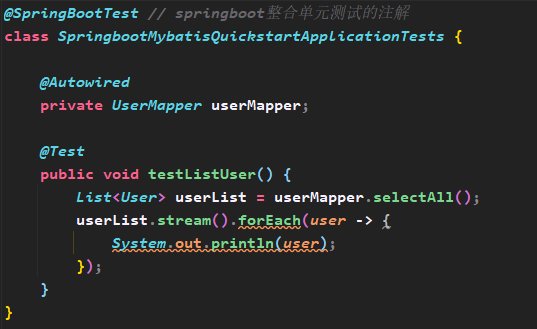
- 运行测试方法testListUser(),user对象打印在输出窗口
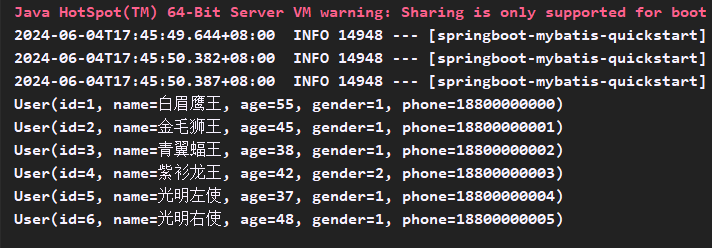
解决Mapper层编写sql语句不显示提示的问题:
语言类型选择mysql

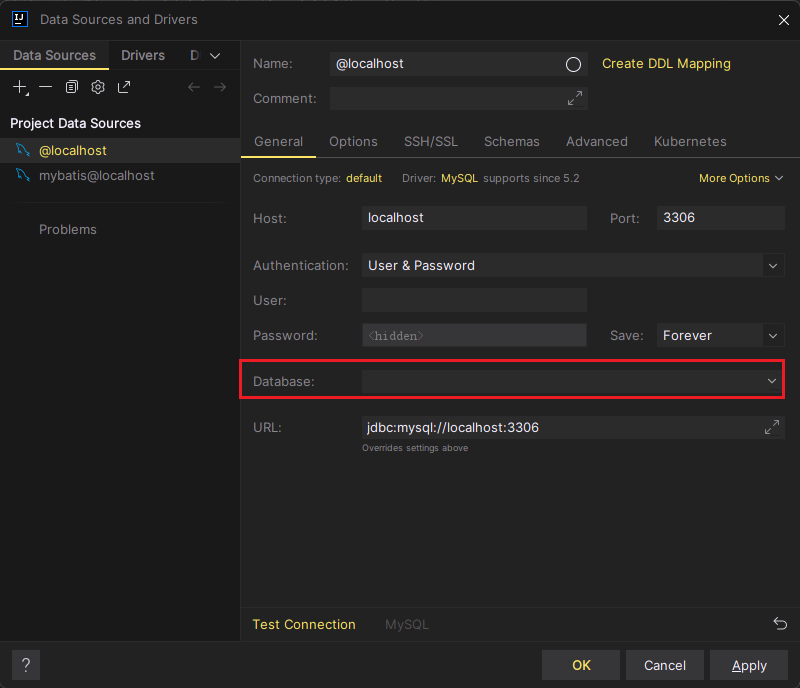
配置完以后记得配置数据库驱动的database,这样sql才会提示该数据库下的所有表,否则sql查询不到表会报错
2、JDBC(了解)
JDBC: ( Java DataBase Connectivity ),就是使用Java语言操作关系型数据库的一套API。
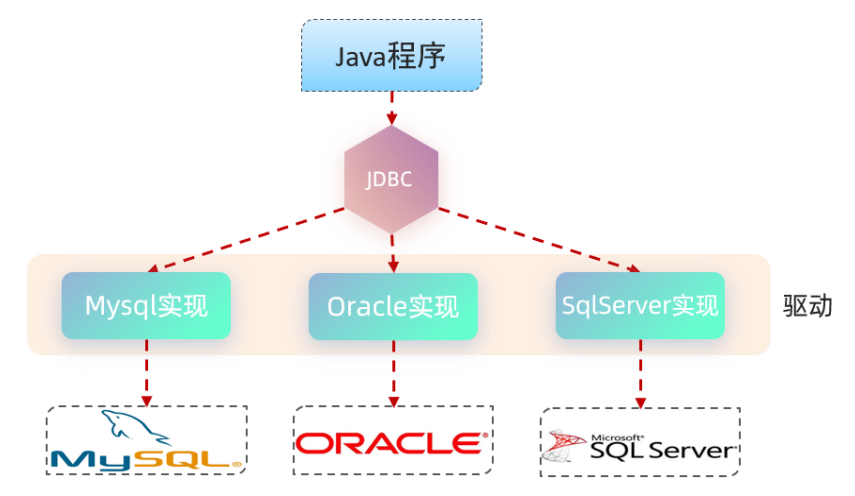
JDBC本质上是sun公司提供的一套操作所有关系型数据库的接口规范,由各个具体的厂商去实现这套接口,提供数据库驱动的jar包,我们程序真正执行的代码是驱动jar包中的实现类。
JDBC原始代码步骤
- 注册驱动
- 获取连接对象
- 执行SQL语句,返回执行结果
- 处理执行结果
- 释放资源
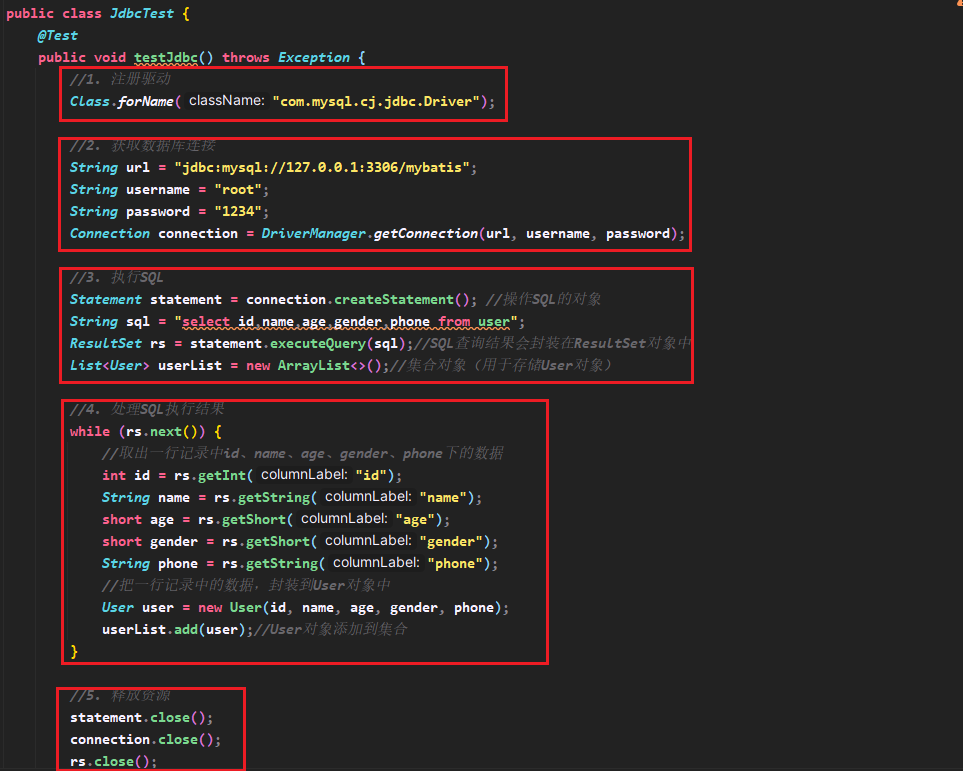
通过上述代码,我们看到直接基于JDBC程序来操作数据库,代码实现非常繁琐,所以在项目开发中,我们很少使用。 在项目开发中,通常会使用Mybatis这类的高级技术来操作数据库,从而简化数据库操作、提高开发效率。
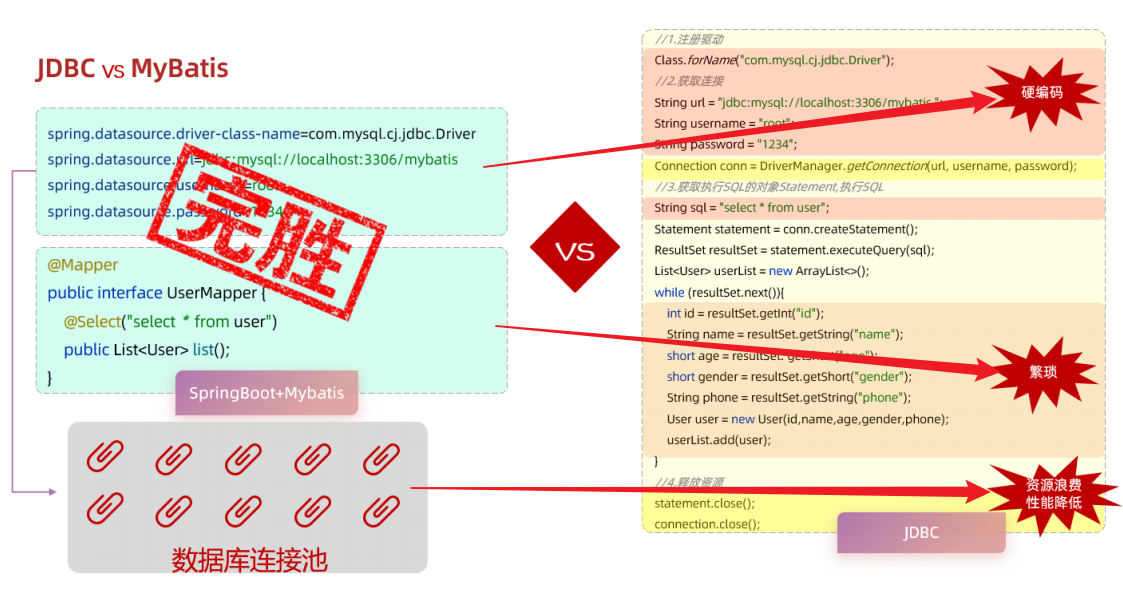
- 定义mybatis配置文件解决JDBC注册驱动的硬编码问题
- Mapper层自动将数据存放在实体类对象中,比JDBC的手动解析更简洁
- 数据库连接池技术相比于JDBC用完资源就释放,大大降低了资源浪费,提升性能
而对于Mybatis来说,我们在开发持久层程序操作数据库时,只需要重点关注以下两个方面:
- application.properties
#驱动类名称spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver#数据库连接的urlspring.datasource.url=jdbc:mysql://localhost:3306/mybatis#连接数据库的用户名spring.datasource.username=root#连接数据库的密码spring.datasource.password=1234 - Mapper接口(编写SQL语句)
@Mapperpublic interface UserMapper { @Select("select id, name, age, gender, phone from user") public List<User> list();}
3、数据库连接池
在前面我们所讲解的mybatis中,使用了数据库连接池技术,避免频繁的创建连接、销毁连接而带来的资源浪费。
当没有使用数据库连接池时,客户端执行SQL语句:要先创建一个新的连接对象,然后执行SQL语句,SQL语句执行后又需要关闭连接对象从而释放资源,每次执行SQL时都需要创建连接、销毁链接,这种频繁的重复创建销毁的过程是比较耗费计算机的性能。

数据库连接池是个容器,负责分配、管理数据库连接(Connection)
- 程序在启动时,会在数据库连接池(容器)中,创建一定数量的Connection对象。
- 当需要连接数据库时,允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
- 当用户占用连接对象到释放空闲时间超过
最大空闲时间的连接,数据库连接池会自动收回数据库连接对象
数据库连接池的好处:
- 资源重用
- 提升响应速度
- 避免数据库连接遗漏
常见的数据库连接池
- Druid(德鲁伊)阿里巴巴开源的数据库连接池项目
- Hikari(追光者)springboot默认的数据库连接池
如果我们想把数据库连接池切换成Druid,只需要两部操作:
引入druid依赖
<dependency> <!-- Druid连接池依赖 --> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.8</version> </dependency>在application.properties中引入数据库连接配置
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis spring.datasource.druid.username=root spring.datasource.druid.password=12344、Lombok
Lombok是一个实用的Java类库,可以通过简单的注解来简化和消除一些必须有但显得很臃肿的Java代码

Lombok通过注解的形式自动生成构造器、getter/setter、equals、hashcode、toString等方法,并可以自动化生成日志变量,简化java开发、提高效率。
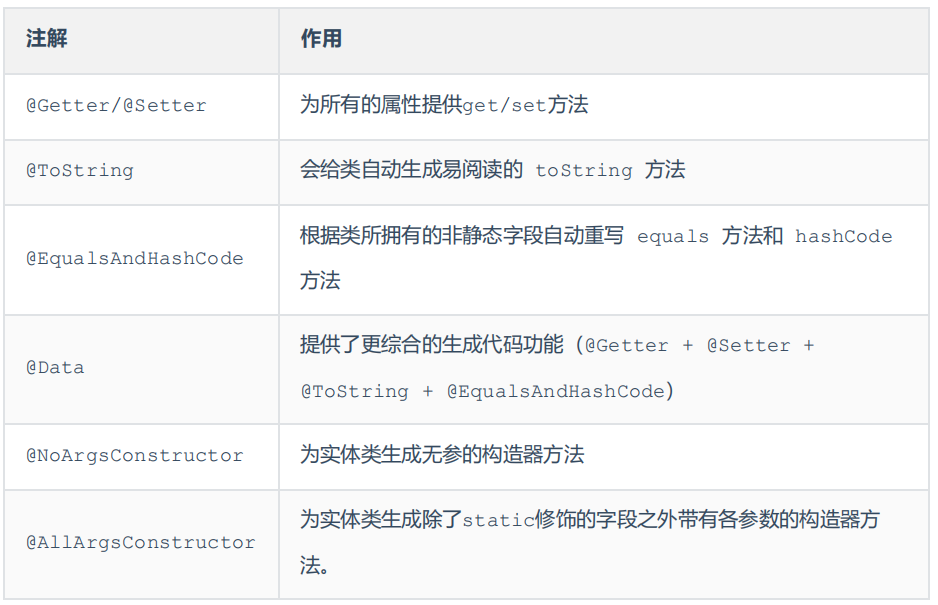
Lombok的使用
- 引入lombok依赖
<!-- 在springboot的父工程中,已经集成了lombok并指定了版本号,故当前引入依赖时不需要指定version --><dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId></dependency> - 在实体类上添加注解
package com.itheima.pojo;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data //Getter + Setter + ToString + EqualsAndHashCode@NoArgsConstructor // 无参构造@AllArgsConstructor // 全参构造public class User { private Integer id; private String name; private Short age; private Short gender; private String phone; // public User() { // } // // public User(Integer id, String name, Short age, Short gender, String phone) { // this.id = id; // this.name = name; // this.age = age; // this.gender = gender; // this.phone = phone; // } // // public Integer getId() { // return id; // } // // public void setId(Integer id) { // this.id = id; // } // // public String getName() { // return name; // } // // public void setName(String name) { // this.name = name; // } // // public Short getAge() { // return age; // } // // public void setAge(Short age) { // this.age = age; // } // // public Short getGender() { // return gender; // } // // public void setGender(Short gender) { // this.gender = gender; // } // // public String getPhone() { // return phone; // } // // public void setPhone(String phone) { // this.phone = phone; // }}
5、删除操作
1.实现功能
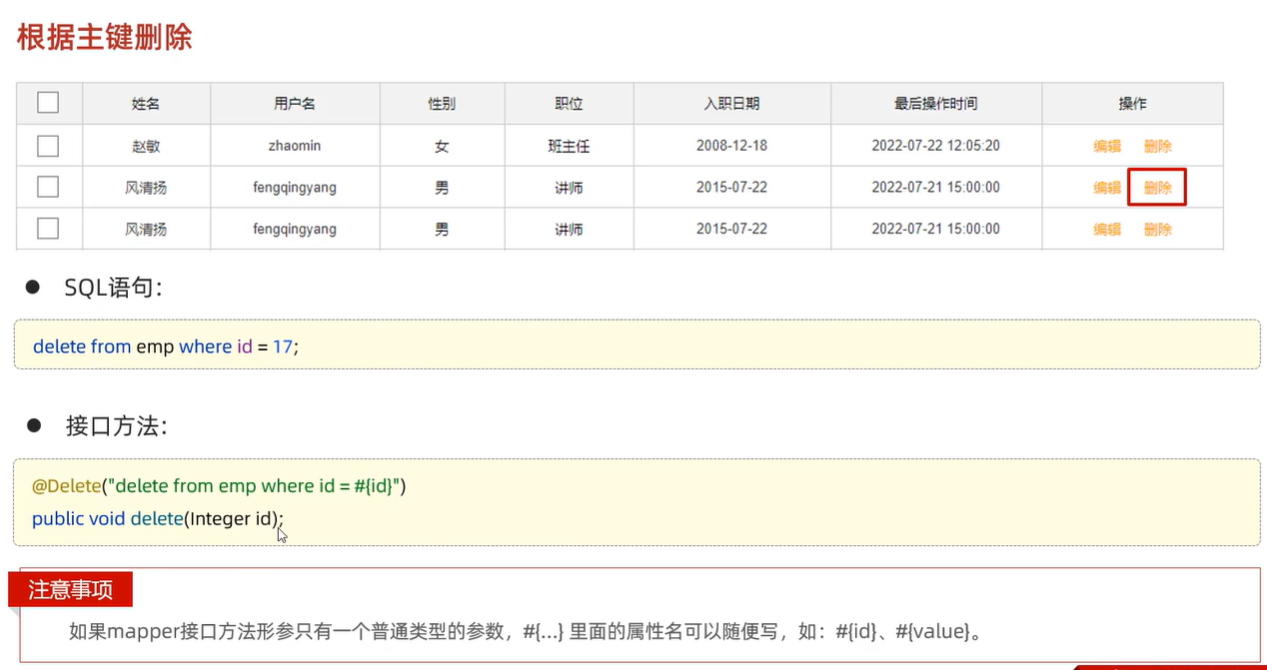
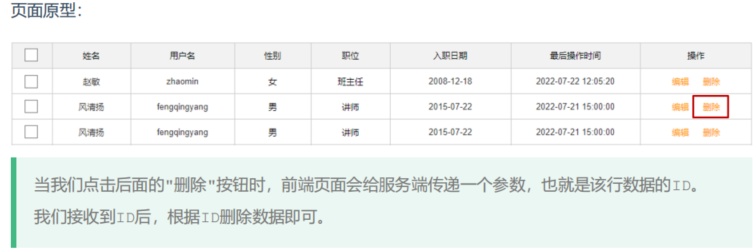
首先创建一个员工实体类Emp
/** * 员工实体类 **/ @Data @AllArgsConstructor @NoArgsConstructor public class Emp { private Integer id; private String username; private String passowrd; private String name; private Short gender; private String imge; private Short job; private LocalDate entrydate; private Integer deptId; private LocalDate createTime; private LocalDate updateTime; }创建一个Mapper接口
public interface EmpMapper { @Delete("delete from emp where id = #{id}") // /使用#{key}方式获取方法中的参数值 public Integer deleteById(Integer id); }打开mybatis日志输出
修改配置文件application.properties
# 配置mybatis日志输出到控制台 mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl创建根据id删除的测试方法
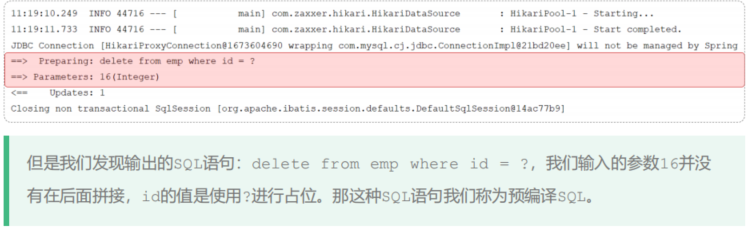
@SpringBootTest class MybatisLearmingApplicationTests { @Autowired private EmpMapper empMapper; @Test public void testDel() { Integer delNum = empMapper.deleteById(16); System.out.println(delNum); } }执行测试方法,查看控制台打印信息如下

2.预编译
预编译SQL,编译一次之后会将编译后的SQL语句缓存起来,后面再次执行这条语句时,不会再次编译。(只是输入的参数不同)

当数据库执行一条sql后,首先会在缓存中查找有没有存在相同的sql语句,如果有则直接执行sql,如果没有,就会依次经历 SQL语法检查->优化sql->编译sql操作后再执行sql
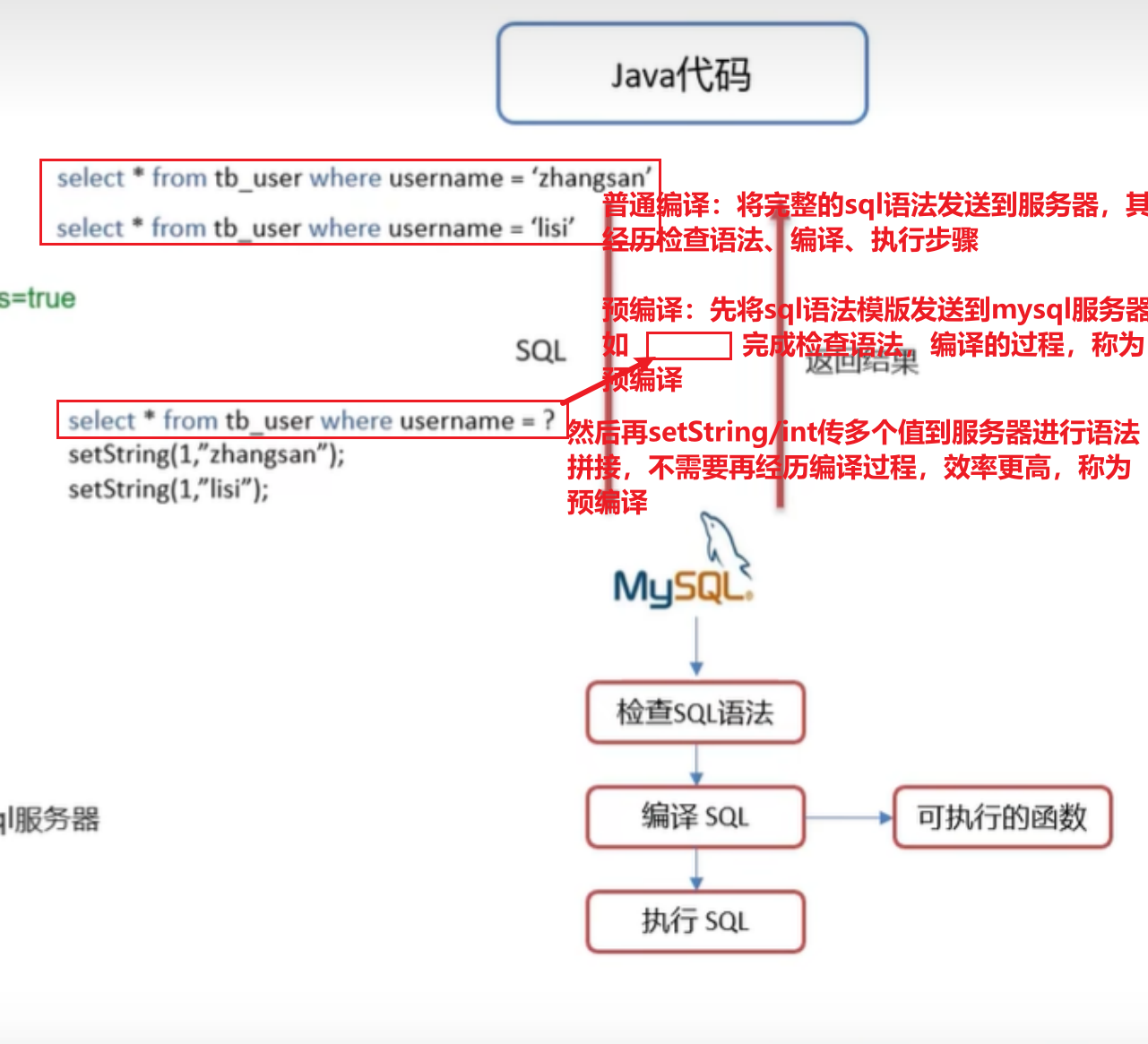
当实现预编译sql之后,会首先将sql语法框架存放在缓存当中,然后数据库接收到后面的参数直接拼接参数就可以执行sql,效率更高,且可以防止语法错误和sql注入。
3.sql占位符
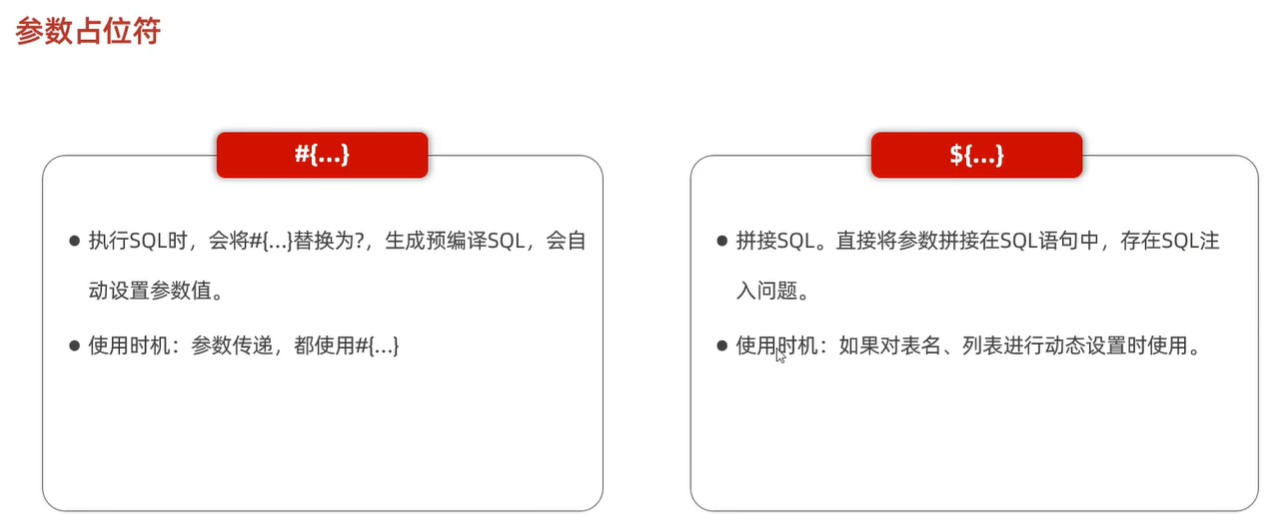
预防sql注入实现预编译的操作就是使用#{}占位符,以下是两种sql占位符的区别。
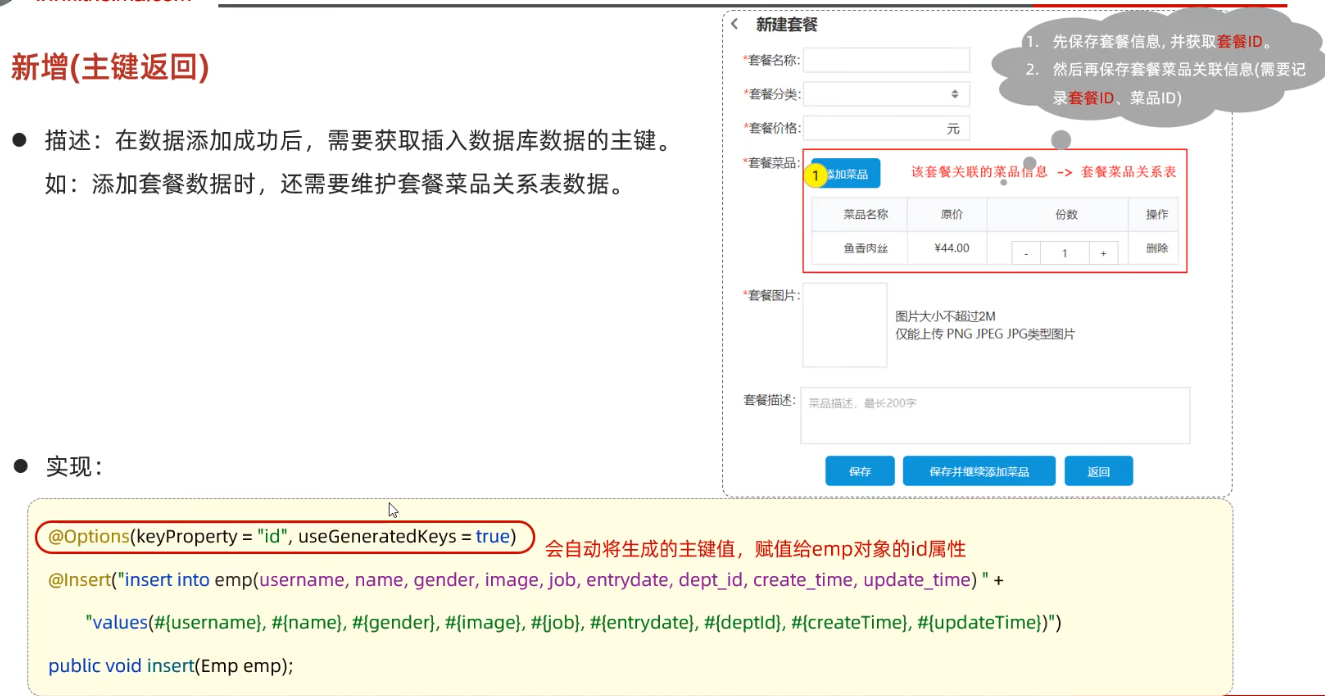
6、新增操作
新增数据sql语句
insert into emp(username, name, gender, image, job, entrydate,dept_id, create_time, update_time) values('songyuanqiao','宋远桥',1,'1.jpg',2,'2012-10-09',2,'2022-10-01 10:00:00','2022-10-01 10:00:00');新增操作mapper接口
// 插入员工信息,并返回id @Options(keyProperty = "id", useGeneratedKeys = true) // 获取返回的主键,封装到Emp对象的id属性内 @Insert("insert into emp(username,name,gender,image,job,entrydate,dept_id,create_time,update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})") Integer insert(Emp emp);新增操作测试类
@Test public void testInsert() { Emp emp = new Emp(); emp.setUsername("Tom1"); emp.setName("汤姆1"); emp.setImage("1.jpg"); emp.setGender((short) 1); emp.setJob((short) 1); emp.setEntrydate(LocalDate.of(2000, 1, 1)); emp.setCreateTime(LocalDate.now()); emp.setUpdateTime(LocalDate.now()); emp.setDeptId(1); empMapper.insert(emp); System.out.println("insert id=" + emp.getId()); }默认情况下,执行插入操作时,是不会主键值返回的。如果我们需要获取新增数据的id值,在mapper方法上使用注解
@Options(keyProperty = "id", useGeneratedKeys = true),表示打开获取主键,并将主键存放在Emp对象的id属性内。

7、更新操作
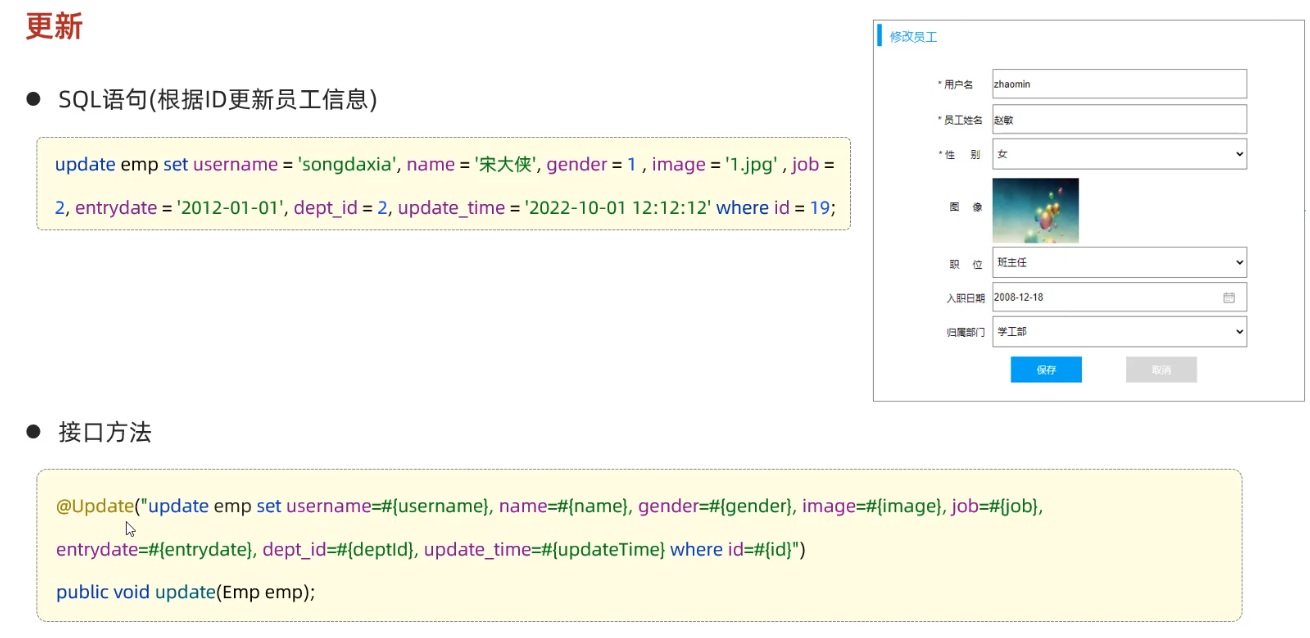
sql语句
update emp set username = 'linghushaoxia', name = '令狐少侠', gender =1 , image = '1.jpg' , job = 2, entrydate = '2012-01-01', dept_id = 2,update_time = '2022-10-01 12:12:12' where id = 18;Mapper接口
// 更新id对应的信息 @Update("update emp set username=#{username}, name = #{name}, gender = #{gender}, image = #{image}, job = #{job}, entrydate = #{entrydate}, dept_id = #{deptId}, update_time = #{updateTime} where id = #{id}") Integer update(Emp emp);测试方法
@Test public void testUpdate() { Emp emp = new Emp(); emp.setId(20); emp.setUsername("Tom2"); emp.setName("汤姆2"); emp.setImage("1.jpg"); emp.setGender((short) 1); emp.setJob((short) 1); emp.setEntrydate(LocalDate.of(2000, 1, 1)); emp.setCreateTime(LocalDate.now()); emp.setUpdateTime(LocalDate.now()); emp.setDeptId(1); emp.setUpdateTime(LocalDate.now()); empMapper.update(emp); System.out.println("update id=" + emp.getId()); }8、查询操作
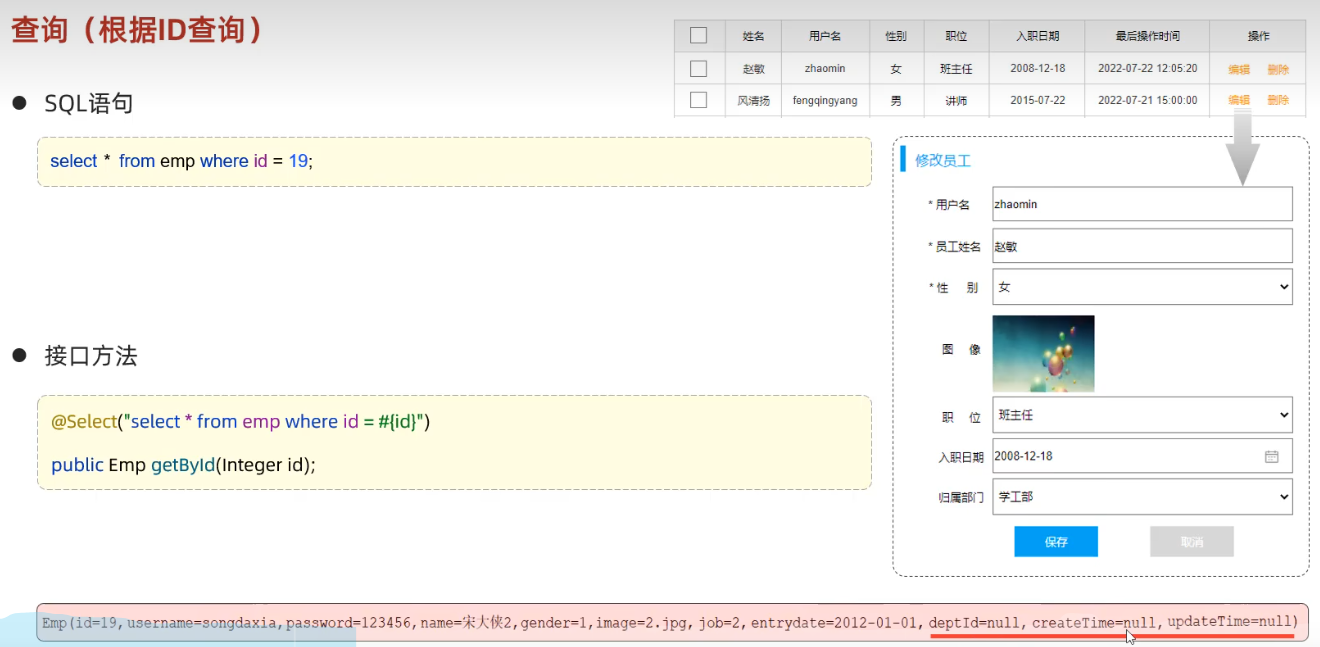
sql语句
select * from emp where name like '%张%' and gender = '1' and entrydate between '2010-01-01' and '2020-01-01';Mapper接口
@Select("select * from emp where id = #{id}") List<Emp> selectById3(Integer id);当执行以上语句时,我们发现会有几个字段获取不到数据
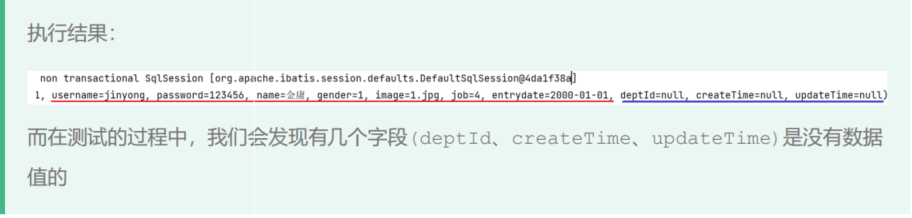
其原因是因为实体类属性名与数据库表查询返回的字段名不一样时,导致数据不能自动封装到类里面。
dept_id不能封装到emp.deptId属性内

为了解决以上问题,我们有三种方法可以实现
// 查询对应id所有信息 // 方案1:给字段起别名,让别名与实体类属性一致 @Select("select id, username, password, name, gender, image, job, entrydate, dept_id deptId, create_time createTime, update_time updateTime from emp where id = #{id}") List<Emp> selectById(Integer id); // 方案2:通过@Results,@Result注解手动映射封装(了解即可) @Results({ @Result(column = "dept_id", property = "deptId"), @Result(column = "create_time", property = "createTime"), @Result(column = "update_time", property = "updateTime") }) @Select("select * from emp where id = #{id}") List<Emp> selectByI2(Integer id); // 方案3:mybatis下划线自动映射驼峰命名开关,修改配置文件 // mybatis.configuration.map-underscore-to-camel-case=true @Select("select * from emp where id = #{id}") List<Emp> selectById3(Integer id);最常用的方法还是开启mybatis自动映射驼峰命名的开关
# 开启mybatis驼峰命名自动映射开关 mybatis.configuration.map-underscore-to-camel-case=true测试方法
@Test public void testGetById() { List<Emp> empList = empMapper.selectById(15); System.out.println(empList); }此时数据已经可以正确拿到了

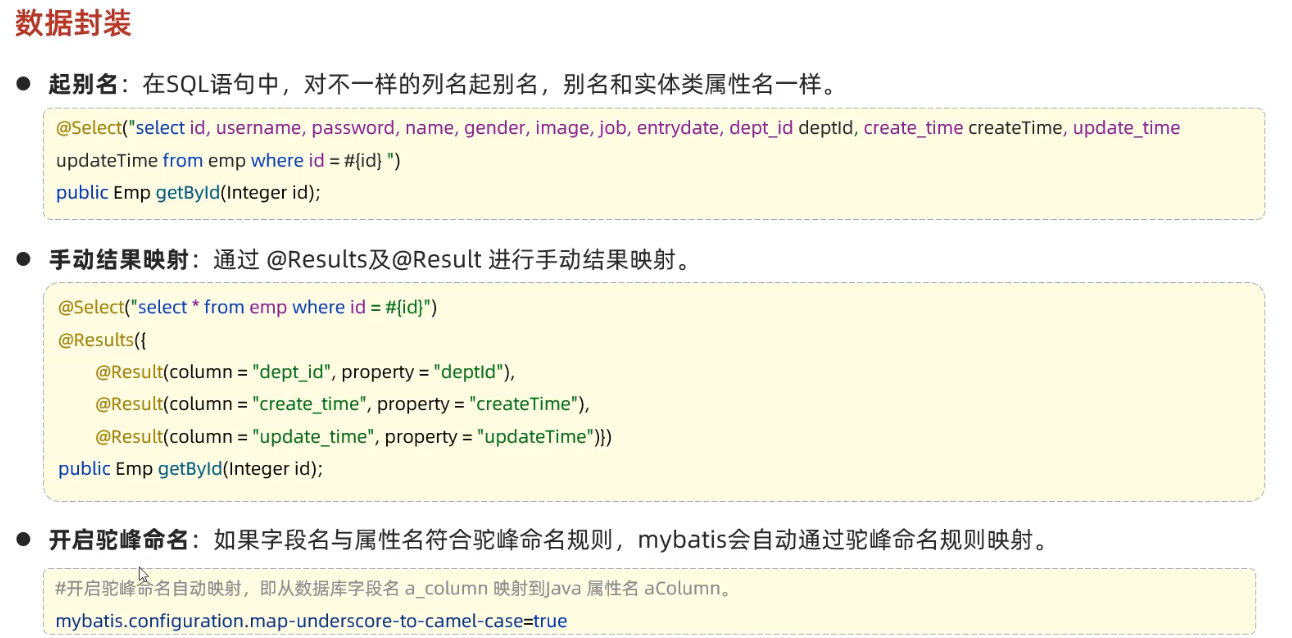
9、案例
条件查询,实现以下案例
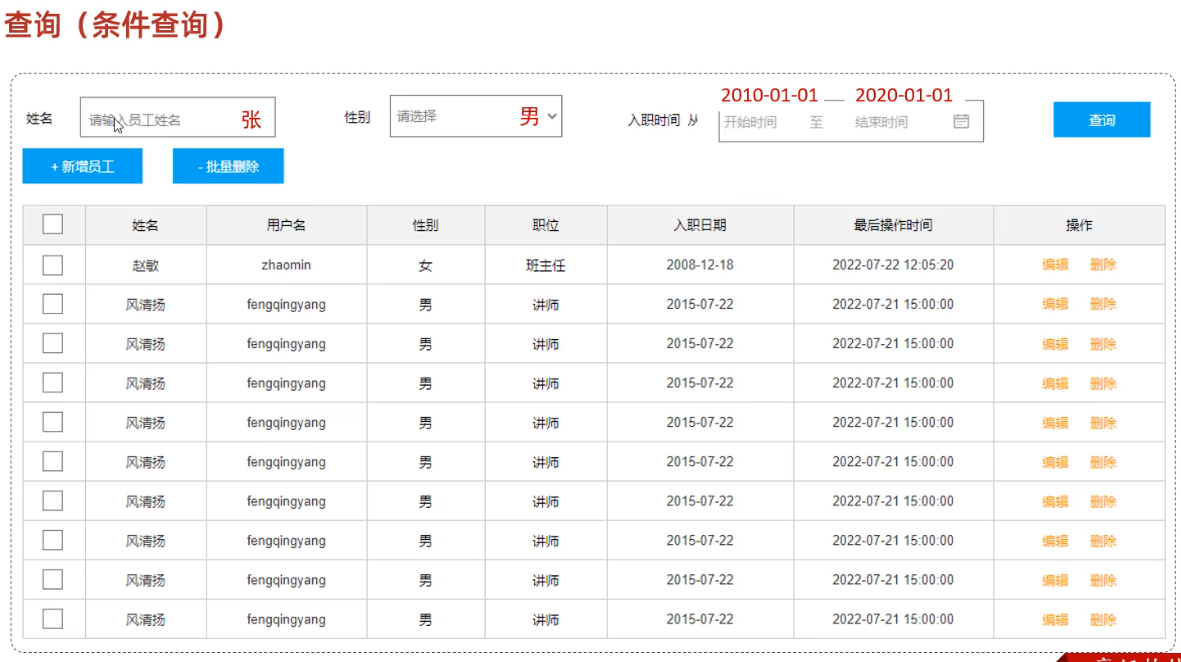
首先编写sql语句
select * from emp where name like '%张%' and gender = '1' and entrydate between '2010-01-01' and '2020-01-01';有个问题,如果采用预编译的写法,当使用#{}替代'%张%'里的条件查询时,就会是这样'%#{name}%',会被当成字符窜,因此不能直接查询,可以借助函数concat连接'%张%'字符串
select concat('hello','mysql','world'); # 输出hellomysqlworld # 为了防止sql注入,mysql提供了一个函数用来连接字符串concat select * from emp where name like concat('%','张','%') and gender = '1' and entrydate between '2010-01-01' and '2020-01-01';mapper接口
@Select("select * from emp where name like concat('%',#{name},'%') and gender = #{gender} and entrydate between #{begin} and #{end}") // 采用concat解决实现预编译sql List<Emp> select(String name, Short gender, LocalDate begin, LocalDate end);测试方法
// 条件查询 @Test public void testSelect() { List<Emp> empList = empMapper.select("张", (short) 1, LocalDate.of(2010, 1, 1), LocalDate.of(2020, 1, 1)); System.out.println(empList); }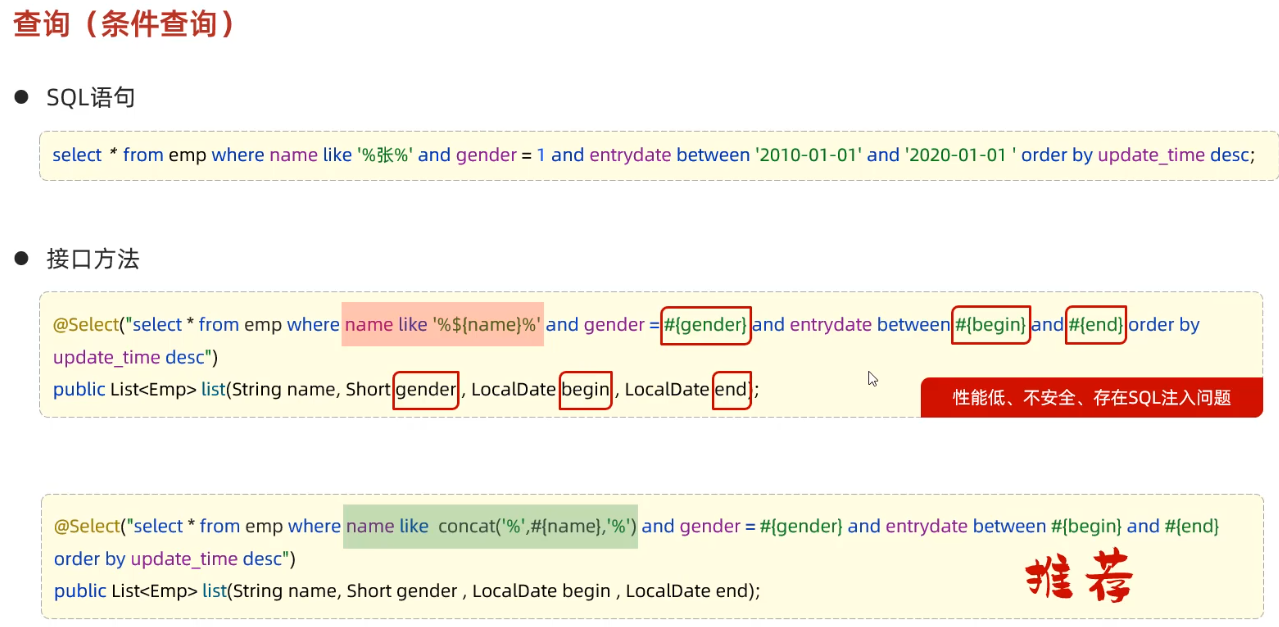
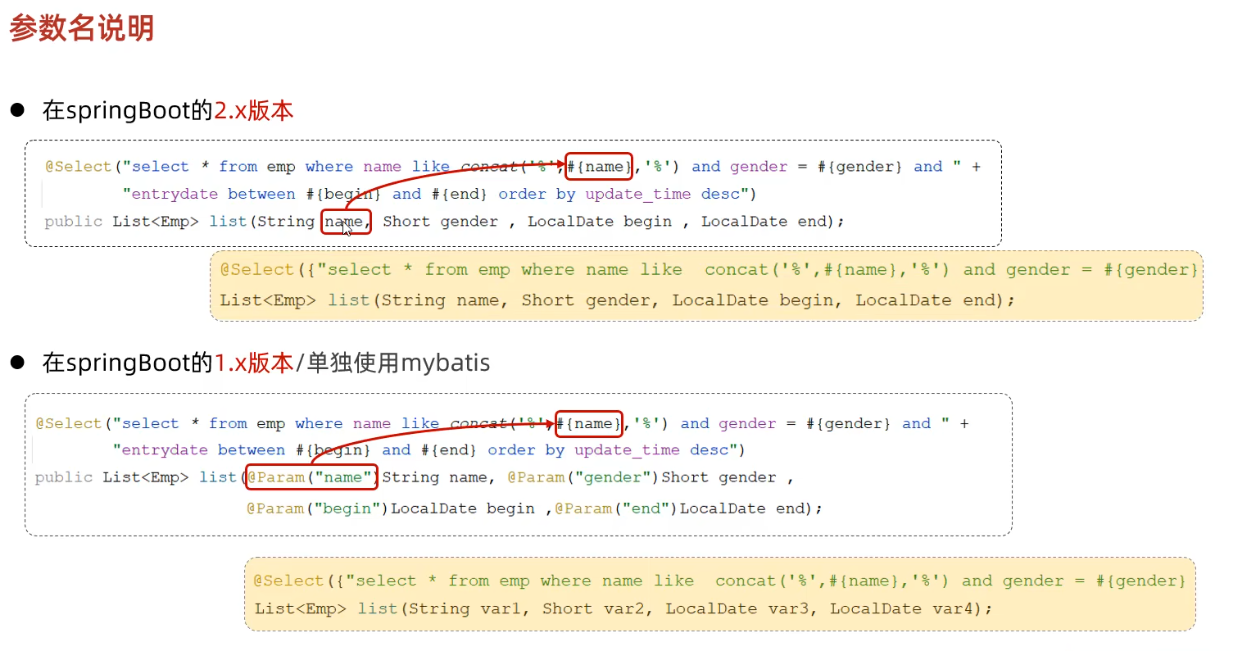
springboot不同版本参数名处理方式
10、Mybatis映射文件
Mybatis官方文档说明:入门_MyBatis中文网
使用mybatis开发方式有两种
- 注解开发
- xml文件开发
使用Mybatis的注解,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句。

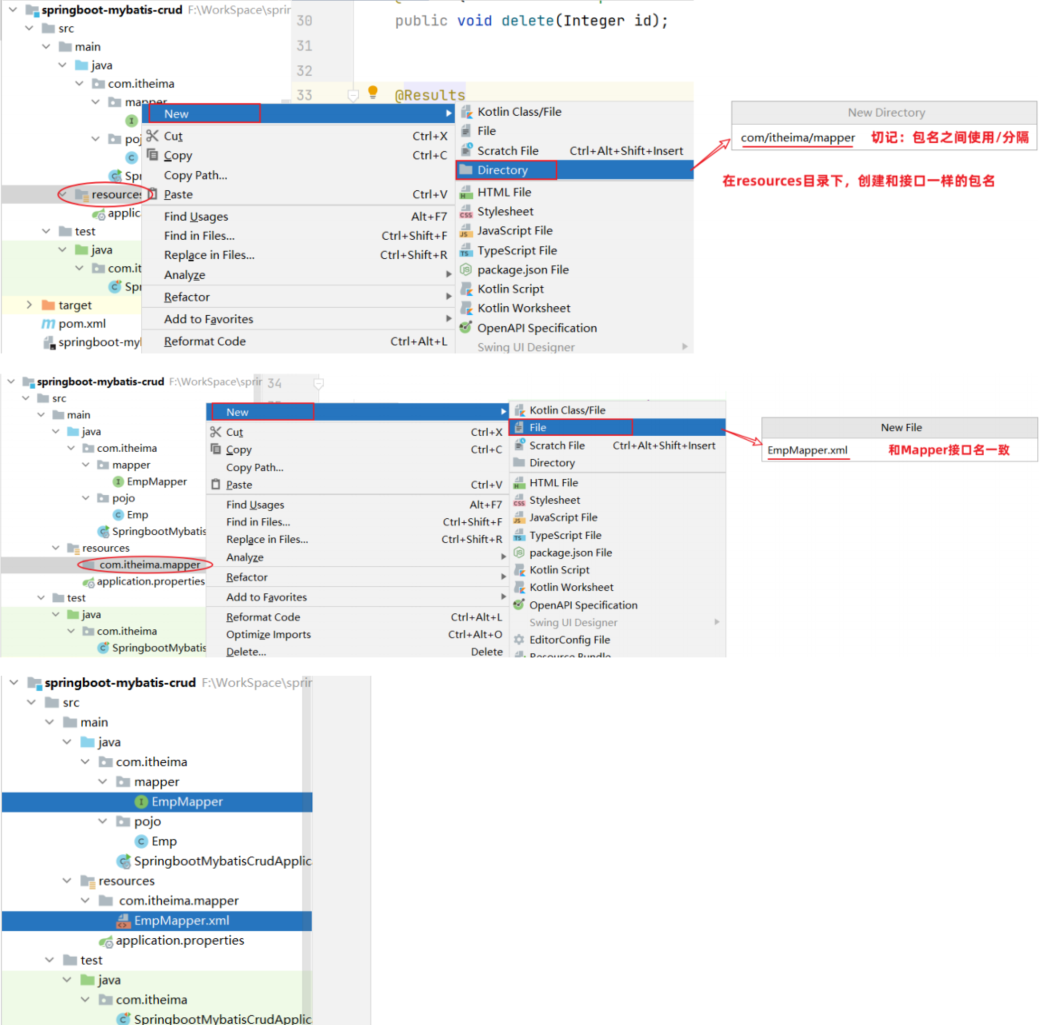
- xml映射文件的名称与Mapper文件名称,文件所在包名相同(同包同名)
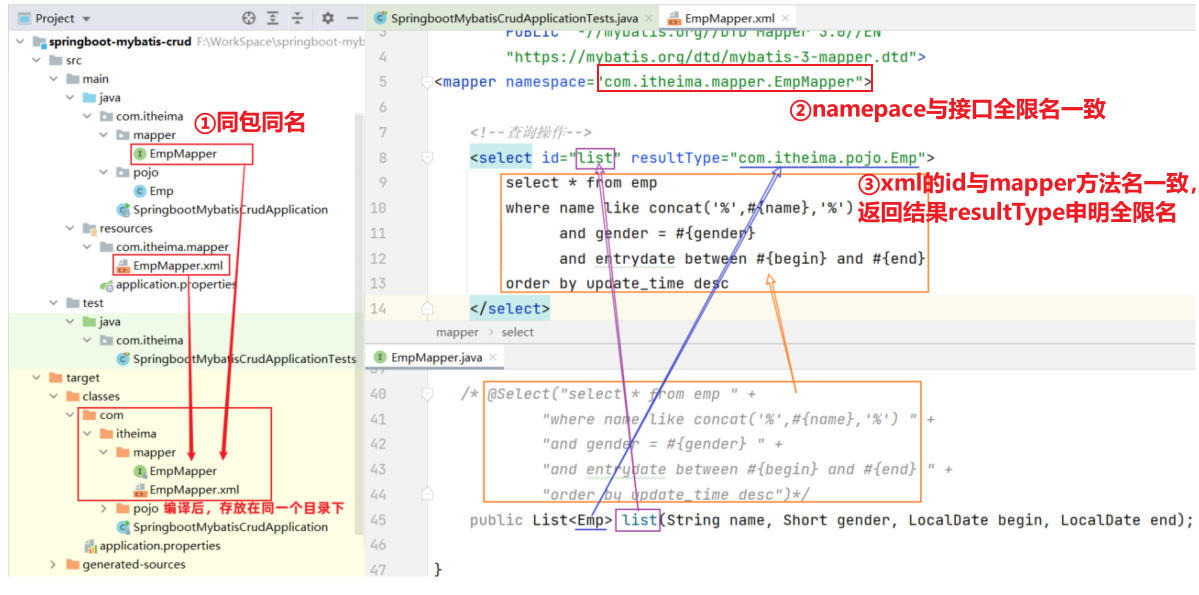
- xml映射文件的
namespqce属性与mapper接口的全限名相同(带有包名的接口名) - xml映射文件的sql语句的
id与mapper接口方法名相同,如果方法存在返回值,返回值的类型resultType需写返回的全限名(如果返回的是个列表,需要写列表内存储值的全限名)
为什么使用mybatis的xml映射文件如此繁琐呢?
- Mapper 接口与 XML 文件必须同包同名,以便 MyBatis 能正确找到对应的 XML 文件。
- XML 文件的
namespace属性需要与 Mapper 接口类名一致,确保接口和 XML 文件关联起来。 - XML 文件中的 SQL 语句的
id属性应与接口方法名一致,使用resultType定义返回类型,将 SQL 语句与接口方法和返回类型正确映射。
那么创建一个mybatis的xml映射文件开发的步骤
- 首先在resource文件夹下创建一个同包同名的xml映射文件
- 编写mapper接口对应的xml映射文件
mybatis映射文件模版
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.itheima.mapper.EmpMapper"> <update id="update1"> update emp <set> <if test="username != null"> username = #{username}, </if> <if test="name != null"> name = #{name}, </if> <if test="gender != null"> gender = #{gender}, </if> <if test="image != null"> image = #{image}, </if> <if test="job != null"> job = #{job}, </if> <if test="entrydate != null"> entrydate = #{entrydate}, </if> <!-- 注意 if标签内的属性名要填java小驼峰属性名--> <if test="updateTime != null"> update_time = #{updateTime}, </if> </set> where id = #{id} </update> <!-- foreach标签 collection 集合名称 item 集合遍历的元素名称 separator 每个元素之间的分隔符 open/close 遍历开始或结尾拼接的片段 delete from emp where id in (1,2,3); --> <delete id="deleteByIds"> delete from emp where id in <foreach collection="ids" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete> <sql id="commentSelect"> select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp </sql> <select id="select1" resultType="com.itheima.pojo.Emp"> <include refid="commentSelect"/> <where> <if test="name != null"> and name like concat('%',#{name},'%') </if> <if test="gender != null"> and gender = #{gender} </if> <if test="begin != null and end != null"> and entrydate between #{begin} and #{end} </if> </where> </select> </mapper>11、Mybatis动态sql
学习mybatis动态sql,其实就是学习mybatis提供的动态标签

1.动态sql-if
- if
- where
- set
<if test="条件表达式"> 要拼接的sql语句 </if>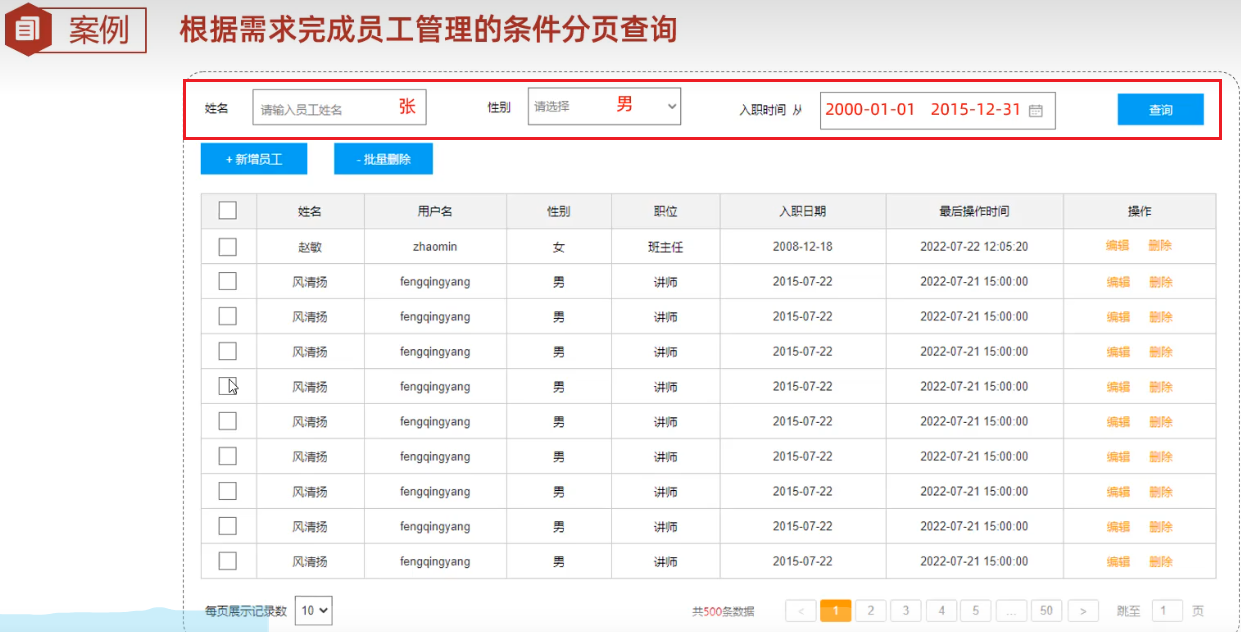
@Select("select * from emp where name like concat('%',#{name},'%') and gender = #{gender} and entrydate between #{begin} and #{end}") List<Emp> select(String name, Short gender, LocalDate begin, LocalDate end);我们发现原有的查询有个问题,必须得name、gender、begin和end字段全部存在才可以正确查询,当为null时则出现查询结果不正确。我们需要实现只有当字段不为空,才执行查询条件,当所有查询条件为空时,where子句也为空

<select id="select1" resultType="com.itheima.pojo.Emp"> <!-- 这里填写你的 SQL 语句 --> <!-- where可以删除多余的and或者or关键字,也能通过动态sql执行条件判断(如果where内的条件都不满足,甚至不会生成where子句)--> <!-- if可以过滤掉查询条件字段为空的情况,当字段为空或者未传入时,sql语句不会出现该查询条件 --> select * from emp <where> <if test="name != null"> and name like concat('%',#{name},'%') </if> <if test="gender != null"> and gender = #{gender} </if> <if test="begin != null and end != null"> and entrydate between #{begin} and #{end} </if> </where> </select>通过动态sql实现更新操作

我们查看最初的更新操作的update方法
@Update("update emp set username=#{username}, name = #{name}, gender = #{gender}, image = #{image}, job = #{job}, entrydate = #{entrydate}, dept_id = #{deptId}, update_time = #{updateTime} where id = #{id}") Integer update(Emp emp);当我们只需要更新部分字段时,这时候便需要用到动态sql,也需要用到
set关键字
// 动态更新 Integer update1(Emp emp);<mapper namespace="com.itheima.mapper.EmpMapper"> <update id="update1"> update emp <set> <if test="username != null"> username = #{username}, </if> <if test="name != null"> name = #{name}, </if> <if test="gender != null"> gender = #{gender}, </if> <if test="image != null"> image = #{image}, </if> <if test="job != null"> job = #{job}, </if> <if test="entrydate != null"> entrydate = #{entrydate}, </if> <!-- 注意 if标签内的属性名要填java小驼峰属性名--> <if test="updateTime != null"> update_time = #{updateTime}, </if> </set> where id = #{id} </update>小结

2.动态sql-foreach
foreach一般用来实现批量操作的动态sql
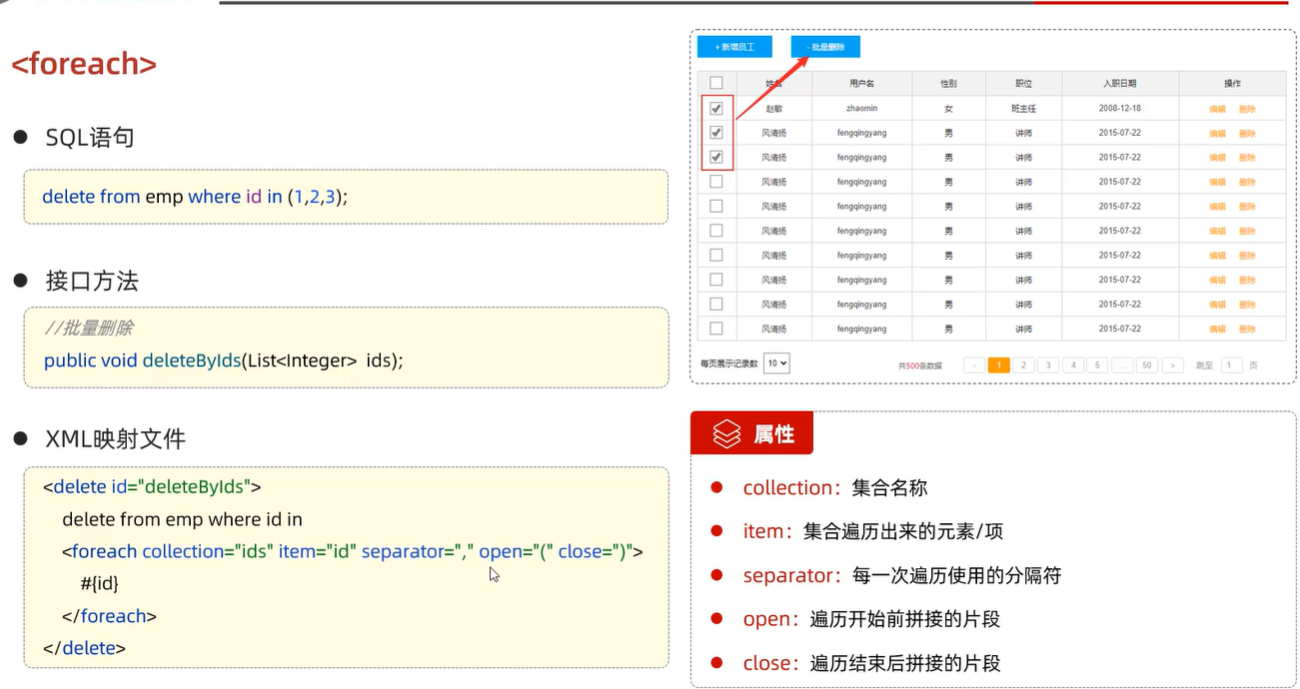
首先我们有个案例
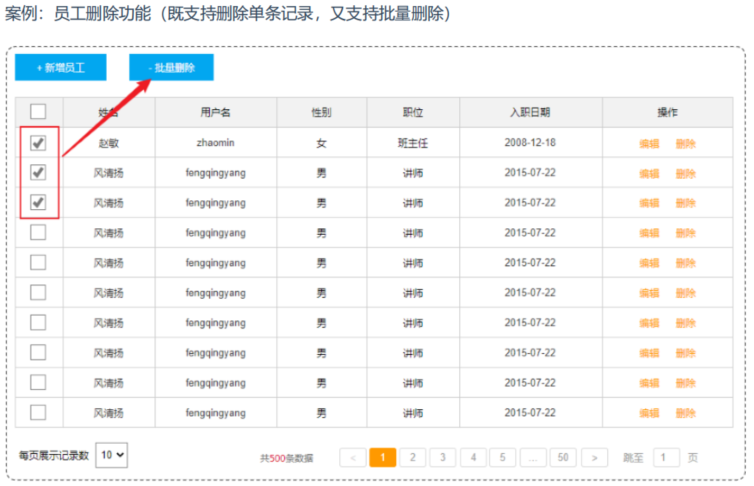
使用mysql语法如下
delete from emp where id in (1,2,3);使用foreach标签遍历删除的集合id
// 批量删除 void deleteByIds(List<Integer> id);delete from emp where id in (1,2,3); <!-- foreach标签 collection 集合名称 item 集合遍历的元素名称 separator 每个元素之间的分隔符 open/close 遍历开始或结尾拼接的片段 delete from emp where id in (1,2,3); --> <delete id="deleteByIds"> delete from emp where id in <foreach collection="ids" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete>3.动态sql-include
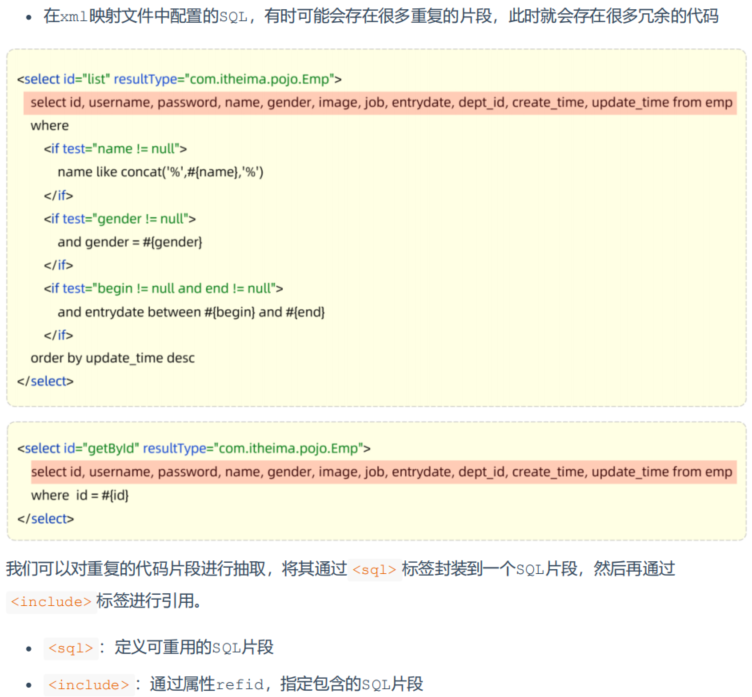

例如以下代码
select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp过于冗余,我们把它们抽象出来放在<sql>标签内,并使用<include>标签指定id实现代码重用
<select id="select1" resultType="com.itheima.pojo.Emp"> select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp <where> <if test="name != null"> and name like concat('%',#{name},'%') </if> <if test="gender != null"> and gender = #{gender} </if> <if test="begin != null and end != null"> and entrydate between #{begin} and #{end} </if> </where> </select>代码优化如下
<sql id="commentSelect"> select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp </sql> <select id="select1" resultType="com.itheima.pojo.Emp"> <include refid="commentSelect"/> # 代码复用,用单标签执行id <where> <if test="name != null"> and name like concat('%',#{name},'%') </if> <if test="gender != null"> and gender = #{gender} </if> <if test="begin != null and end != null"> and entrydate between #{begin} and #{end} </if> </where> </select>4.动态sql实现新增数据
<insert id="insert" parameterType="com.itheima.pojo.Dept">parameterType表示输入的数据类型为Dept<trim prefix="(" suffix=")" suffixOverrides=",">``````prefix="(" suffix=")"表示在 SQL 片段的开头和结尾添加括号;suffixOverrides=","表示去掉末尾多余的逗号
insert into dept(name,create_time,update_time) valus(#{name},#{createTime},#{updateTime}) <insert id="insert" parameterType="com.itheima.pojo.Dept"> insert into dept <trim prefix="(" suffix=")" suffixOverrides=","> <if test="name != null">name,</if> <if test="createTime != null">create_time,</if> <if test="updateTime != null">update_time,</if> </trim> <trim prefix="values(" suffix=")" suffixOverrides=","> <if test="name != null">#{name},</if> <if test="createTime != null">#{createTime},</if> <if test="updateTime != null">#{updateTime},</if> </trim> </insert>5.动态sql实现删除和批量删除数据
删除数据
DELETE FROM dept where id=1 and name=null and create_time=2000.01.01 <!-- 动态删除部门信息 --> <delete id="deleteDept" parameterType="com.example.model.Dept"> DELETE FROM dept <where> <if test="id != null">AND id = #{id}</if> <if test="name != null">AND name = #{name}</if> <if test="createTime != null">AND create_time = #{createTime}</if> </where> </delete>批量删除数据
delete from emp where id in (1,2,3); <!-- foreach标签 collection 集合名称 item 集合遍历的元素名称 separator 每个元素之间的分隔符 open/close 遍历开始或结尾拼接的片段 delete from emp where id in (1,2,3); --> <delete id="deleteByIds"> delete from emp where id in <foreach collection="ids" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete>6.动态sql实现修改数据
update emp set username=#{username}, name = #{name}, gender = #{gender}, image = #{image}, job = #{job}, entrydate = #{entrydate}, dept_id = #{deptId}, update_time = #{updateTime} where id = #{id} <mapper namespace="com.itheima.mapper.EmpMapper"> <update id="update1"> update emp <set> <if test="username != null"> username = #{username}, </if> <if test="name != null"> name = #{name}, </if> <if test="gender != null"> gender = #{gender}, </if> <if test="image != null"> image = #{image}, </if> <if test="job != null"> job = #{job}, </if> <if test="entrydate != null"> entrydate = #{entrydate}, </if> <!-- 注意 if标签内的属性名要填java小驼峰属性名--> <if test="updateTime != null"> update_time = #{updateTime}, </if> </set> where id = #{id} </update>7.动态sql实现查询数据
<select id="select1" resultType="com.itheima.pojo.Emp"> <!-- 这里填写你的 SQL 语句 --> <!-- where可以删除多余的and或者or关键字,也能通过动态sql执行条件判断(如果where内的条件都不满足,甚至不会生成where子句)--> <!-- if可以过滤掉查询条件字段为空的情况,当字段为空或者未传入时,sql语句不会出现该查询条件 --> select * from emp <where> <if test="name != null"> and name like concat('%',#{name},'%') </if> <if test="gender != null"> and gender = #{gender} </if> <if test="begin != null and end != null"> and entrydate between #{begin} and #{end} </if> </where> </select>七、Maven
超级详细的 Maven 教程(基础+高级)_maven教程-CSDN博客
Maven详细安装配置(图文)+使用方法 速通教程_maven安装及配置教程-CSDN博客
官方maven中央仓库:https://mvnrepository.com/
maven是一个java项目管理和构建工具,可以自定义项目结构、项目依赖,并使用统一的方式进行自动化构建,是java项目不可缺少的工具。
1、maven作用
- 提供了一套标准的项目结构,约定目录的文件类型1. 不同的开发工具的项目结构不同2. maven规范了项目的结构,使得开发人员更易上手项目,变得更加简单
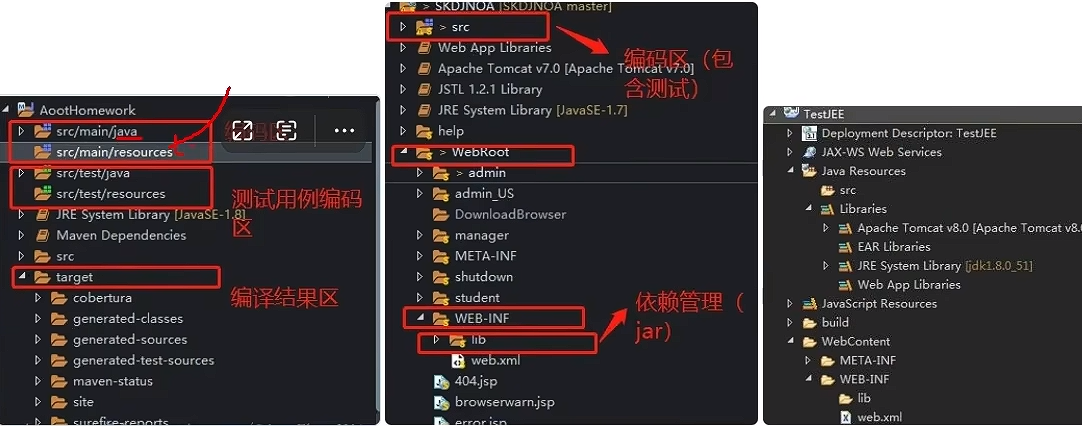
- 提供了一套标准化的构建流程(编译-测试-打包-部署)可以一键自动化流程部署项目

- 提供了一套依赖管理机制(管理项目中的所有jar包)利用仓库统一管理所有的jar包解决jar包版本冲突问题(依赖传递,可以引入不同版本的jar包)
maven依赖管理机制工作,首先maven会通过pom.xml里引入的坐标信息在本地仓库里查找对应的jar包,如果没有则会在镜像网址内查找并下载保存到本地仓库,这样就能够在本地引入对应的坐标依赖了。
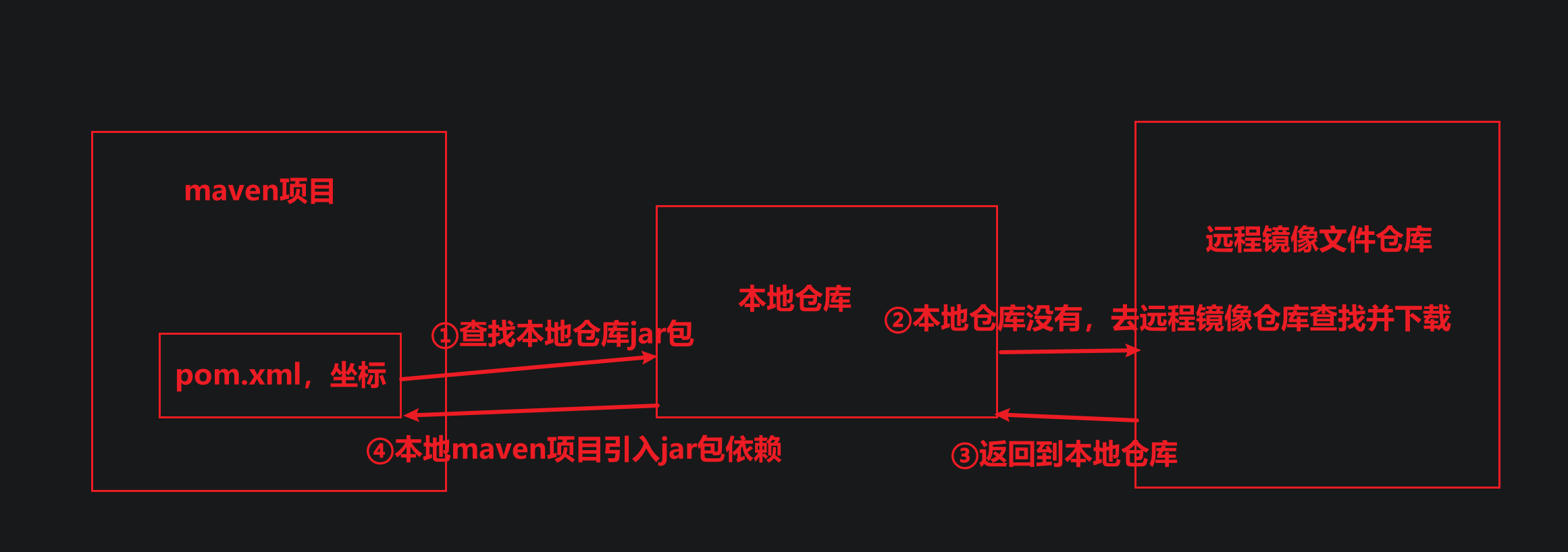
2、创建maven项目
1.使用mvn命令创建项目
使用命令生成maven项目脚手架
mvn archetype:generate配置maven项目基本信息

groupId: 项目包 artifactId: 项目名称 version: 项目版本(默认为1.0-SNAPSHOT)2.使用ideal创建maven项目

maven项目脚手架项目结构:
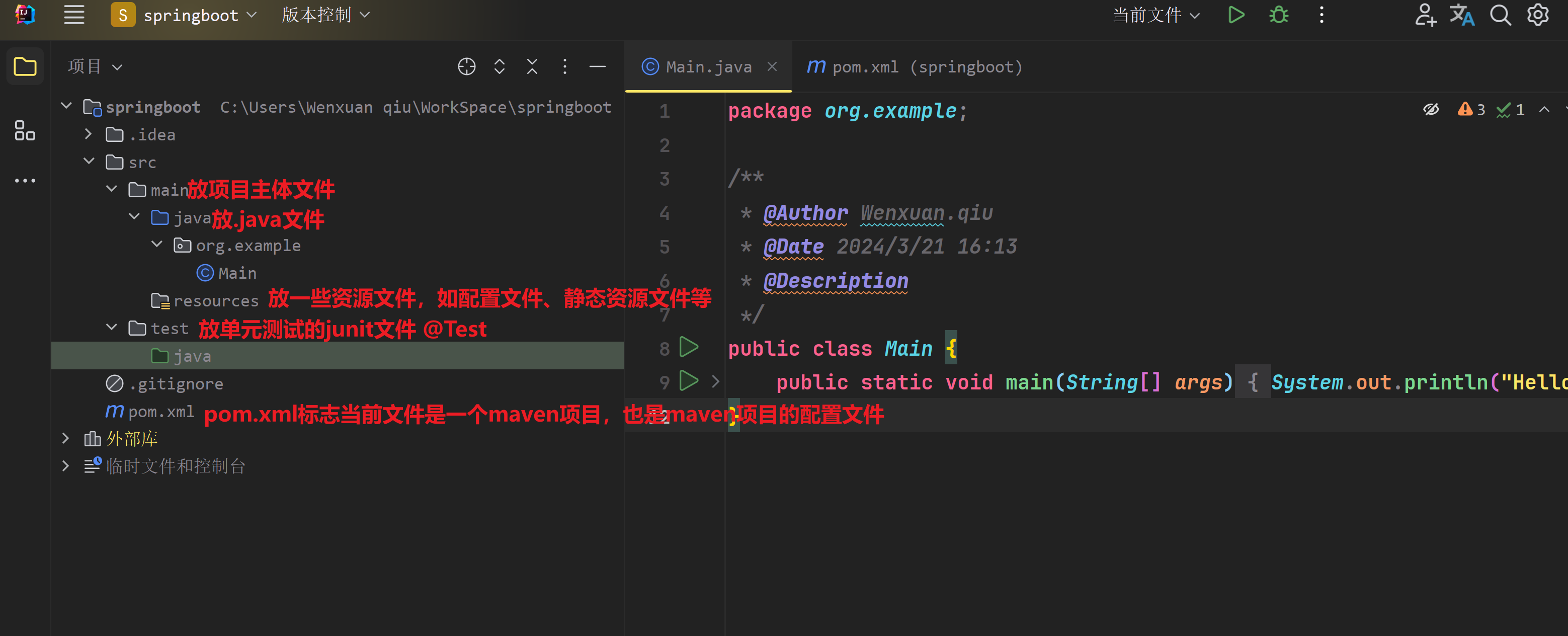
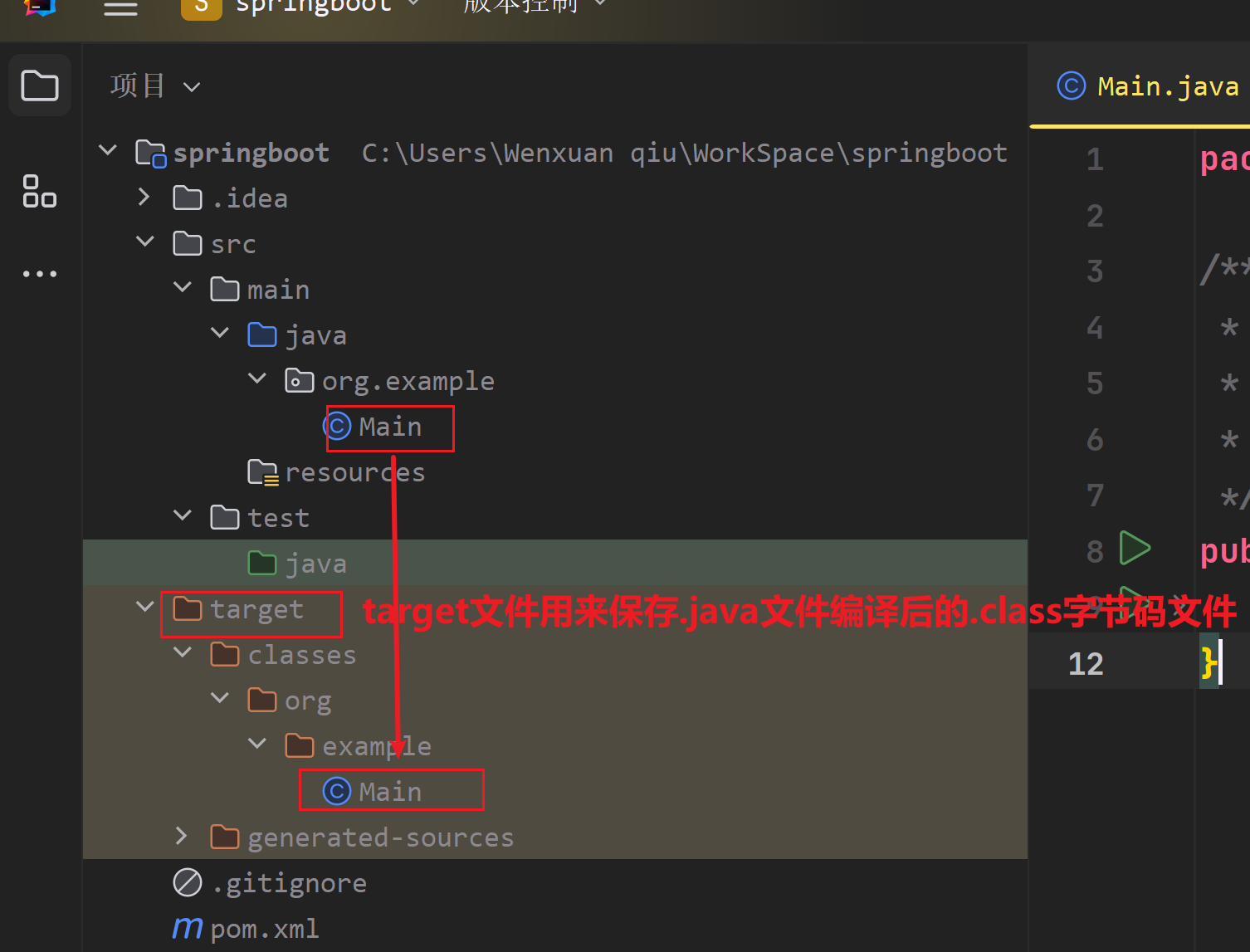
3.pom配置文件
1.文件坐标信息
唯一标识当前文件生成的jar包的坐标,因为maven不仅需要引入其他jar包,自己也可能会构建成jar包被其他包引入,因此需要定义当前包的唯一坐标
<!-- maven文件坐标信息,每个maven都会有一个唯一的坐标信息--> <!--maven配置文件坐标信息: maven文件有两种类型,一种是一整个项目(如淘宝,百度),一种是一个项目模块(用户前台模块,管理员后台模块) groupId: 域名反过来、项目包 artifactId: 项目/模块名、 version: 版本名,SNAPSHOT表示未上线快照等等 --> <groupId>org.example</groupId> <artifactId>springboot</artifactId> <version>1.0-SNAPSHOT</version>2.依赖信息配置
使用dependencies包括的坐标信息,用来引入本地仓库的依赖
- 坐标:唯一标识一个依赖(包括本地依赖jar包,远程依赖jar包)
- 依赖:依赖通常指的是其他库或框架,你的项目需要使用这些库或框架中的类、方法或其他资源。这些依赖项可以是本地项目中的Jar包,也可以是远程仓库中的库
<dependencies> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>4.0.1</version> <scope>provided</scope> </dependency> </dependencies>3.变量公共区
用于定义一些公共的变量,依赖版本变量等,方便统一管理
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <javax.servlet.version>4.0.1</javax.servlet.version> 定义servlet依赖版本变量 </properties> <dependencies> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>${javax.servlet.version}</version> 引用依赖版本变量 <scope>provided</scope> </dependency> </dependencies>4.打包方式
项目打包就是使用maven构建之后,会将项目先编译为字节码target文件,然后将项目打包为.jar或.war包,
<packaging>pom</packaging> jar 将文件打包为jar包,jar包可以install放入本地或远程仓库被其他maven项目引入 war war包一般是web项目打包的文件,不能被引入 pom 当项目本身不包含任何代码或资源需要编译和打包时,你可以将其打包类型设置为pom(由于父项目或者聚合项目)3、maven命令
clean: 清理项目,删除target文件夹及其内容 validate: 验证项目,检查项目配置和结构是否有错误 compile 编译项目源代码,将源代码转为可执行的字节码文件 test 运行test目录下的单元测试 package 编译后的代码打包成为特定的格式:war,jar verify 对集成测试结果进行检验 install 将项目的构建结果安装到本地仓库,以便其他项目依赖它 site 生成项目站点文档和报告 deploy 将项目的构建结构部署到远程仓库,以便其他开发人员可以访问和使用maven命令主键是按照顺序一次执行的,如果你执行的是test命令,他会把test命令前的clean->validate->compile->test命令全部依次执行一遍
4、依赖范围
我们可以看到,所有的dependency依赖都有一个scope选项,表示坐标的依赖范围(
scope)
如下图所示给
junit依赖通过
scope标签指定依赖的作用范围。 那么这个依赖就只能作用在测试环境,其他环境下不能使用。
<dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>${javax.servlet.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-api</artifactId> <version>5.10.2</version> <scope>test</scope> 只能作用在测试环境 </dependency>scope范围取值
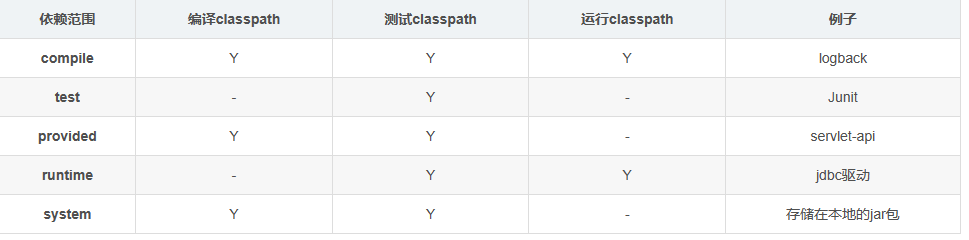
- compile:作用于编译环境,测试环境,运行环境
- test:只在测试环境可用,如junit依赖
- provided:作用于编译环境,测试环境
- runtime:作用于测试环境,运行环境
scope不指定默认为compile 全局范围
5、依赖传递
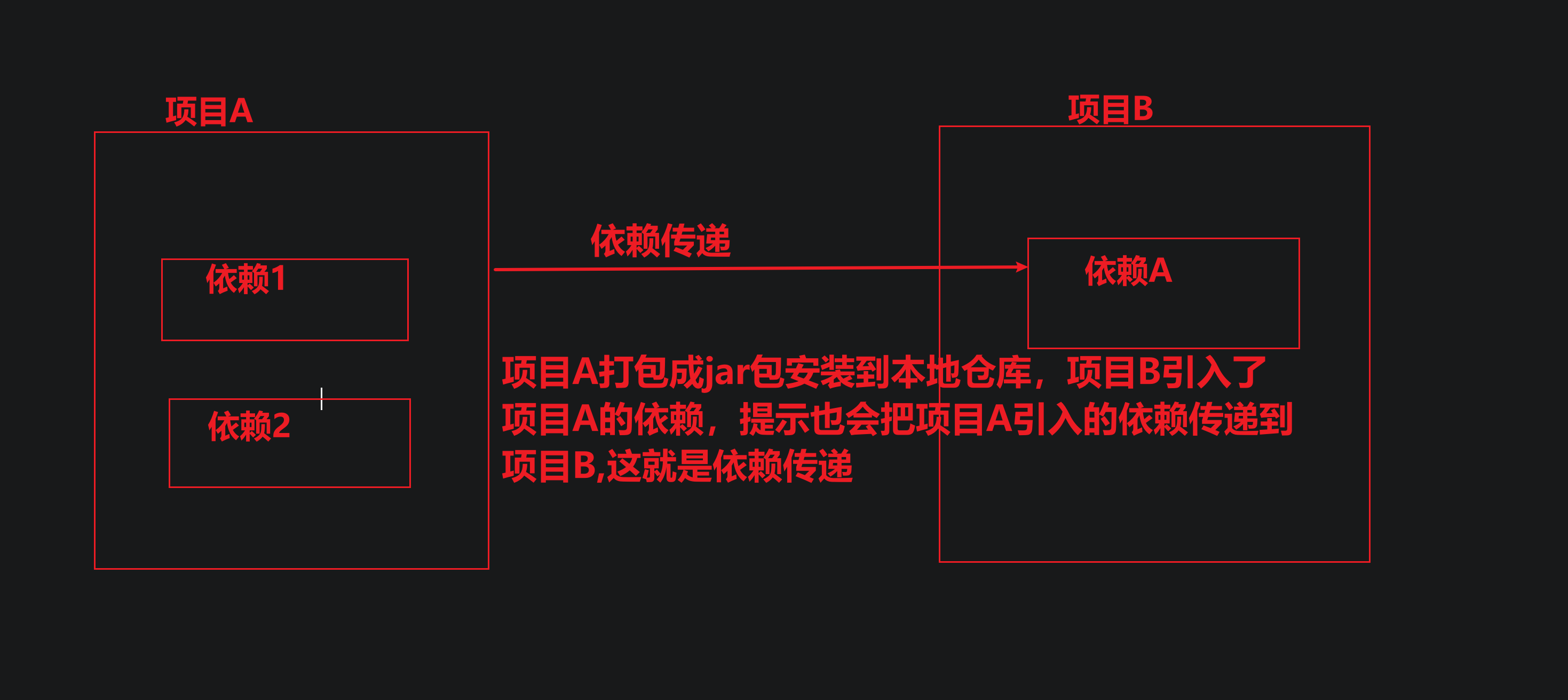
创建一个A项目,包含mysql依赖
项目A pom.xml,其中包含两条依赖junit、mysql,将其打包为jar包install到本地仓库
<groupId>org.example</groupId> <artifactId>springboot</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-api</artifactId> <version>5.10.2</version> <scope>test</scope> </dependency> <dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> <version>8.3.0</version> </dependency> </dependencies>现在,创建项目B,引入项目A的坐标,如下
<dependency> <groupId>org.example</groupId> <artifactId>springboot</artifactId> <version>1.0-SNAPSHOT</version> </dependency>此时发现项目B含有项目A含有的junit,mysql依赖,因此发现依赖具有传递性
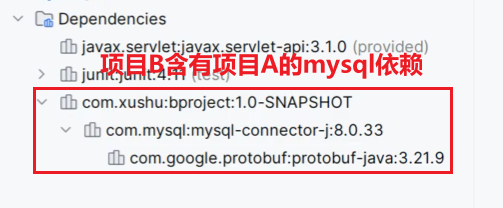
如果不希望依赖被其他引入的依赖传递,可以将依赖设置作用范围为
test,provided,也可以设置选项
<optional>为true,表示依赖不传递
项目A
<dependency> <groupId>org.example</groupId> <artifactId>springboot</artifactId> <version>1.0-SNAPSHOT</version> <scope>provided</scope> 设置作用范围为provided,不可用作运行环境,因此不传递依赖 <optional>true</optional> 默认为false表示依赖会被传递,设置为true表示阻止该依赖传递 </dependency>6、依赖排除
如果依赖B引入了依赖A,而我们并不想使用依赖A传递过来的其他依赖,虽然我们可以设置项目A所属依赖的optional选项,但大多数的时候我们是不能更改依赖A的,因此我们可以再依赖B当中设置依赖排除来阻止依赖传递
1.exclusion排除依赖A的mysql传递依赖
使用
<exclusion>排除不需要的依赖,不需要指定依赖的版本(因为引入的依赖只有一个版本)
<dependency> <groupId>org.example</groupId> <artifactId>springboot</artifactId> <version>1.0-SNAPSHOT</version> <scope>provided</scope> 设置作用范围为provided,不可用作运行环境,因此不传递依赖 <optional>true</optional> 默认为false表示依赖会被传递,设置为true表示阻止该依赖传递 <exclusions> <exclusion> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> </exclusion> </exclusions> </dependency>2.依赖覆盖
如果不想使用传递依赖版本的依赖,可以引入一个同名依赖但是不同版本来覆盖传递依赖
<dependency> <groupId>org.example</groupId> <artifactId>springboot</artifactId> <version>1.0-SNAPSHOT</version> <!-- <exclusions>--> <!-- <exclusion>--> <!-- <groupId>com.mysql</groupId>--> <!-- <artifactId>mysql-connector-j</artifactId>--> <!-- </exclusion>--> <!-- </exclusions>--> </dependency> <dependency> 项目A传递的mysql依赖为8.3.0,我们引入mysql依赖为8.4.0覆盖到原本的8.3.0依赖 <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> <version>8.4.0</version> </dependency>如果引入的依赖过多,我们可以通过依赖视图来清晰的查找依赖的来源
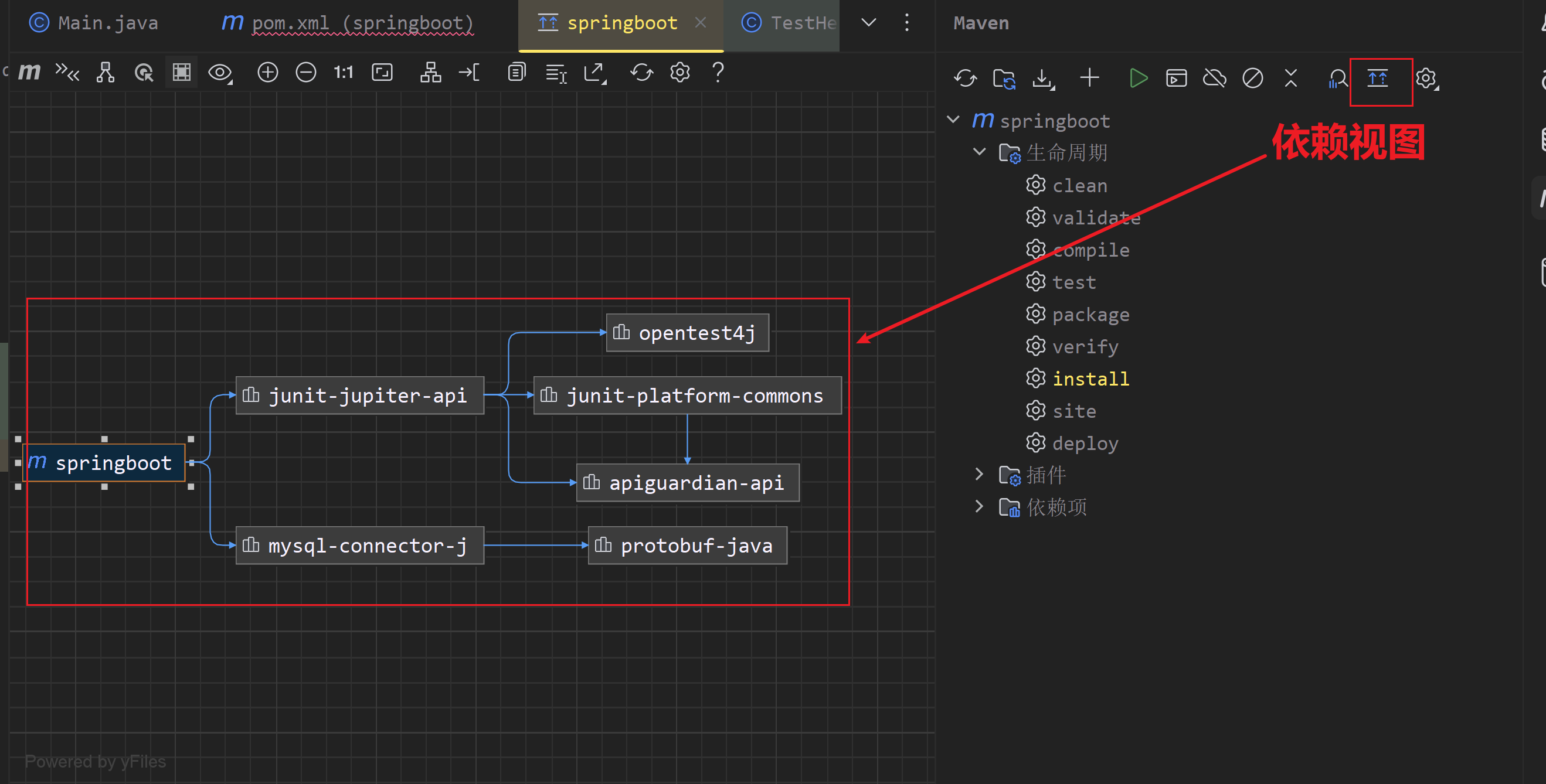
7、聚合依赖
还是假如我们有两个项目,项目A和项目B,现在我们把项目A打包成jar包传递给项目B,此时项目B页提示拥有了项目A的依赖,但是如果项目A的依赖发生了变更,我们需要再去给项目A重新安装打包,然后项目B也需要变更,会造成编译过于麻烦,是否有一种方法只要一改变项目A的依赖,项目B能立马感知到不需要重复编译呢
我们可以采用聚合编译的方法,创建一个聚合项目用以管理项目A和项目B
1.聚合项目的创建
创建一个聚合项目Count,Count由于只需要管理子项目,因此src文件夹可以删除
然后创建两个字模块,分别为maven模块项目
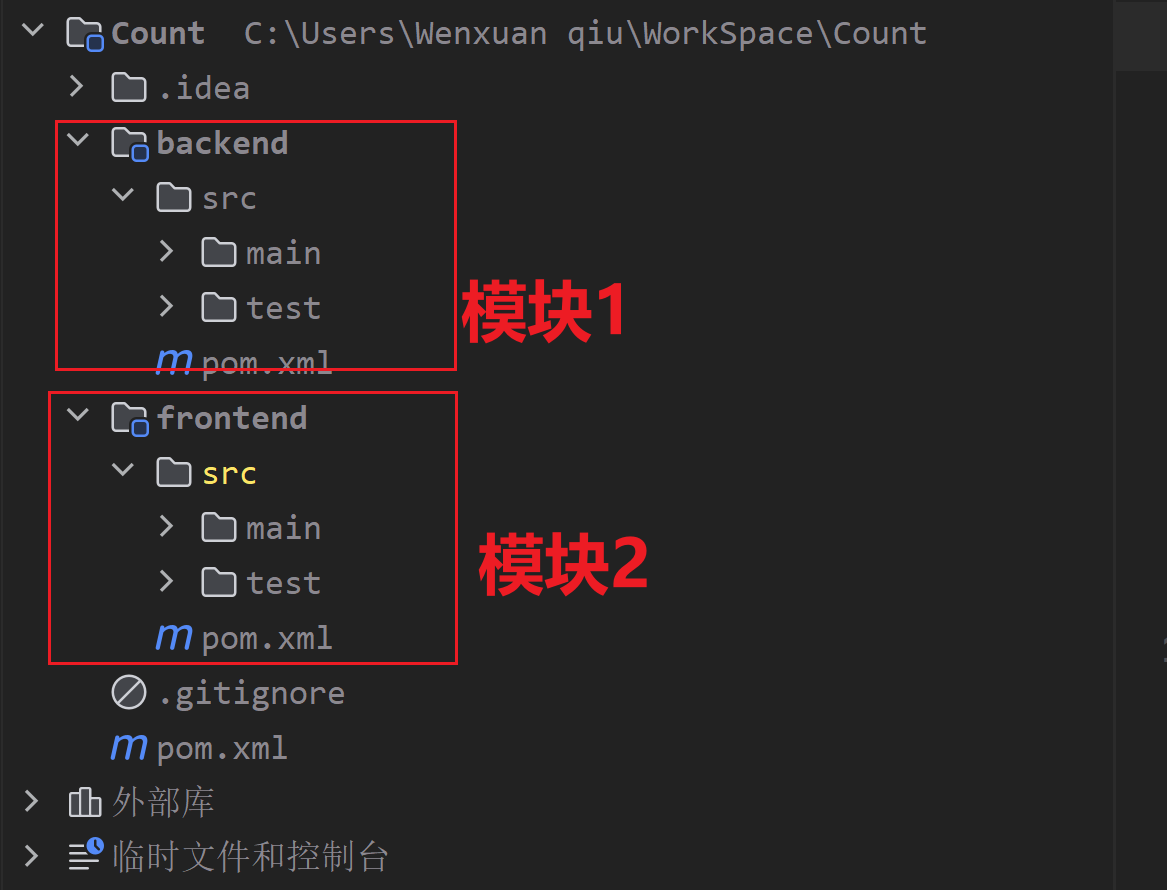
在聚合项目count的pom.xml添加两个子模块,修改打包类型为pom
<groupId>org.example</groupId> <artifactId>Count</artifactId> <version>1.0-SNAPSHOT</version> <packaging>pom</packaging> 由于聚合项目不需要打包为jar或者war包,因此packaging类型为pom类型 <modules> 添加子模块为backend和frontend <module>backend</module> <module>frontend</module> </modules>在项目B的pom.xml引入项目A的坐标
此时我们发现当在A模块修改依赖时,B模块能立马能感知A模块的变更并传递依赖
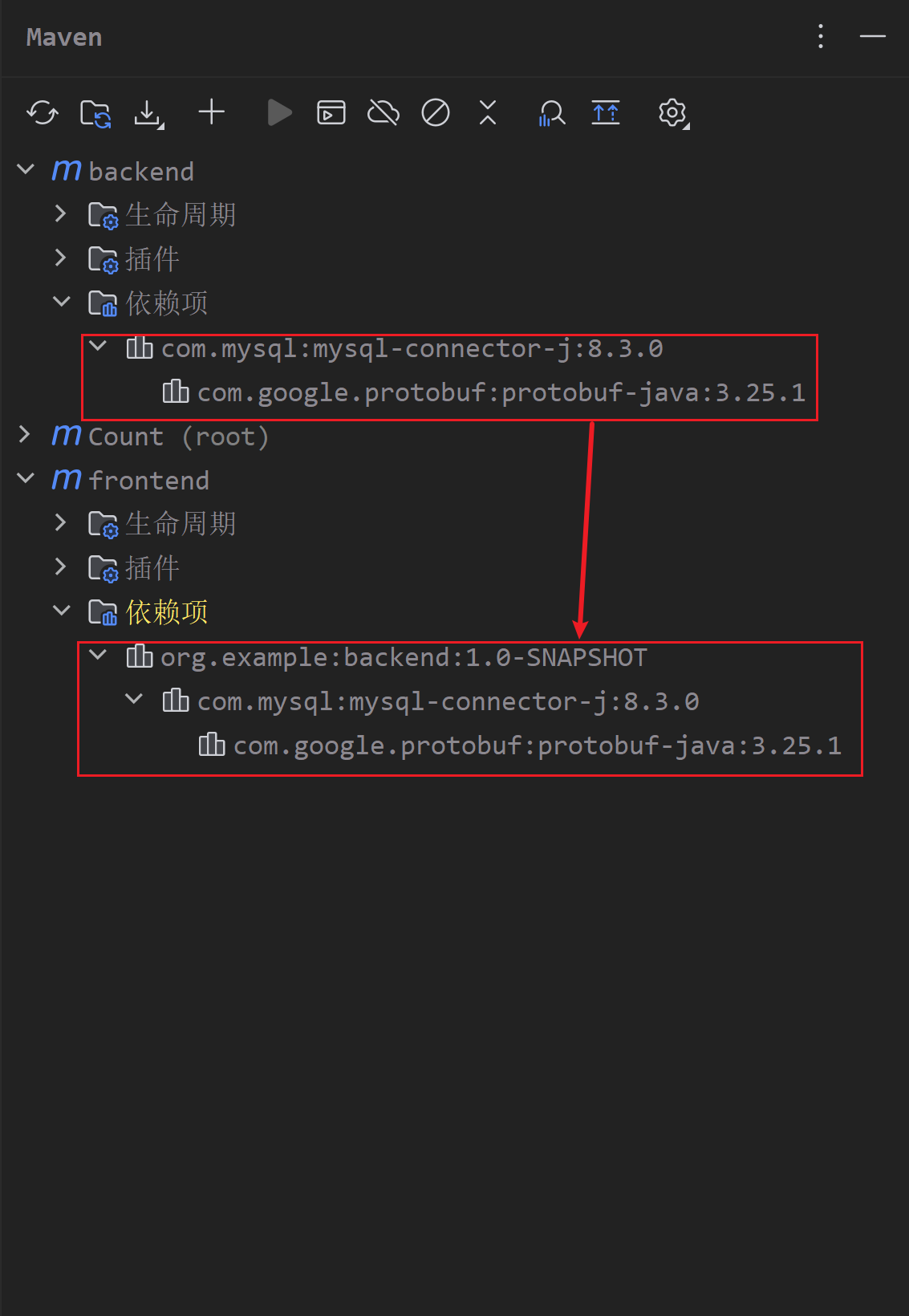
且我们可以一键编译聚合项目,而不用同时更新两个子项目
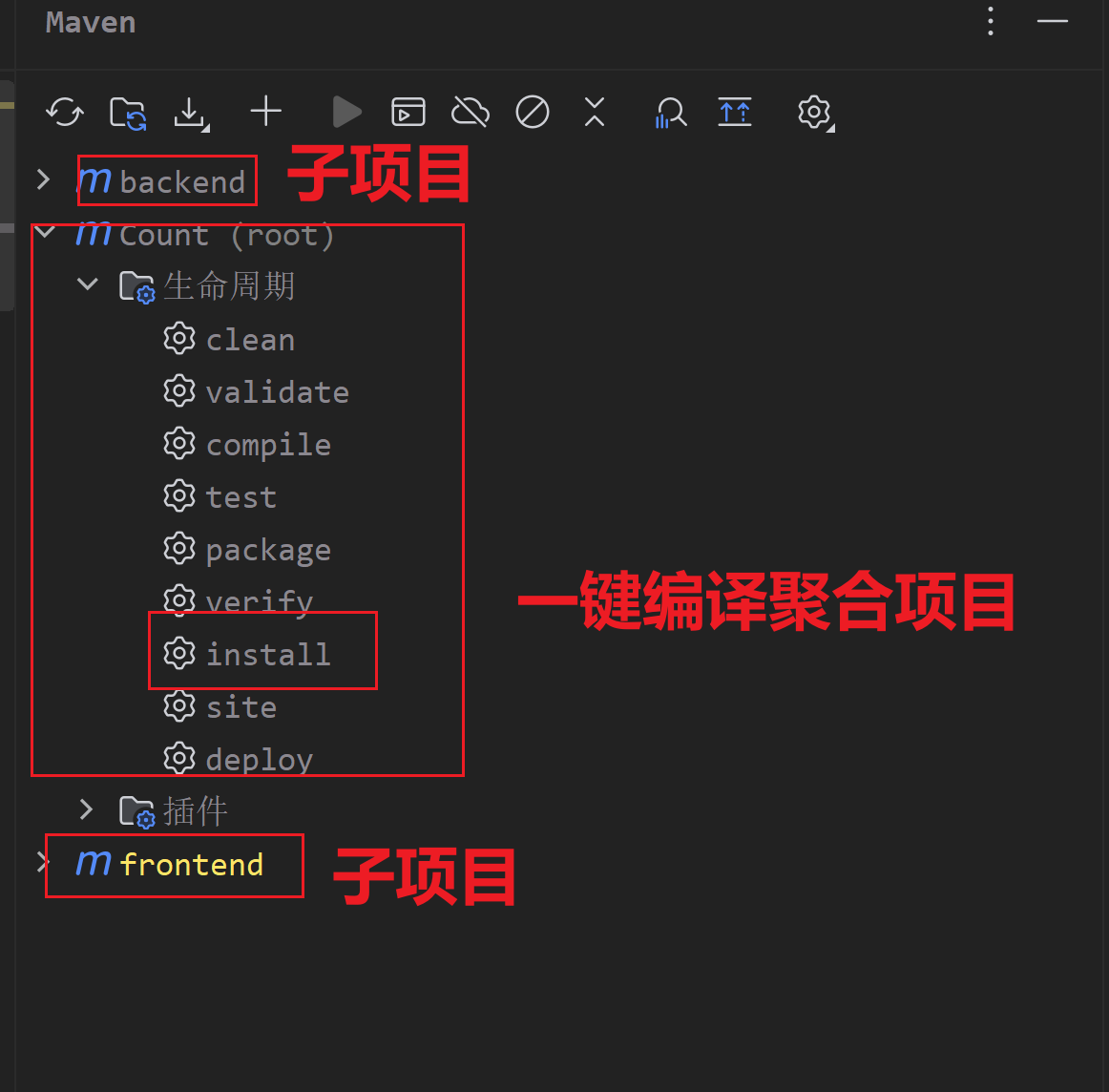
8、maven继承
maven继承原理
假如项目A和B都继承了很大一部分相同的依赖,我们可以将相同的依赖都放在父项目当中,然后两个子项目分别继承父项目

项目继承示意图如下:
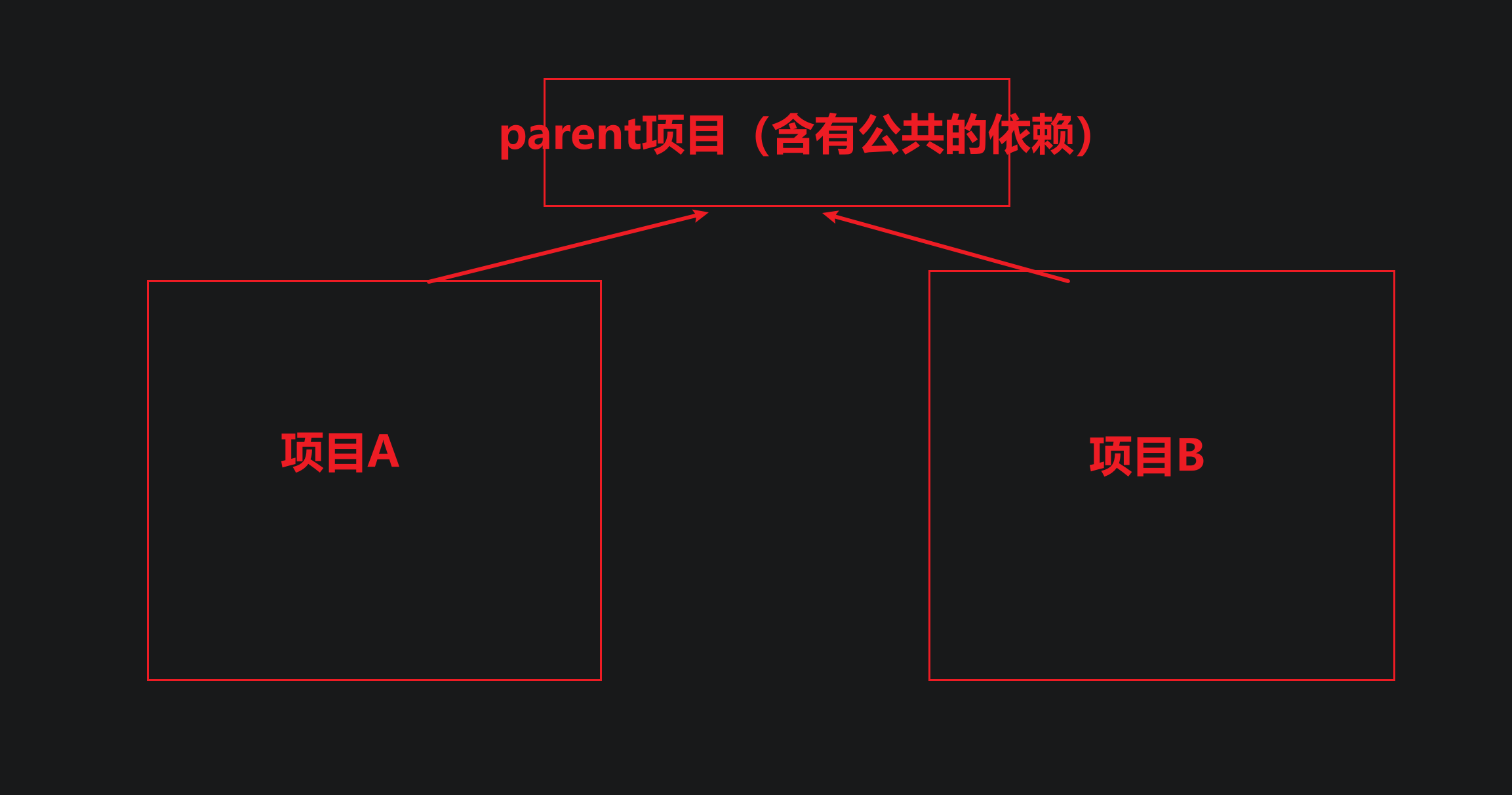
1.创建父项目
父项目pom.xml文件
正常引入坐标即可 <groupId>org.example</groupId> <artifactId>Count</artifactId> <version>1.0-SNAPSHOT</version> 如果父项目不含任何代码或者不需要编译,设置为pom打包类型 <packaging>pom</packaging> 父项目的公共依赖 <dependencies> <dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> <version>8.3.0</version> </dependency> ... </dependencies>子项目继承父项目,需要在parent内引入父项目坐标,且groupId继承自父项目
子项目继承父项目,将父项目坐标放在parent内 <parent> <groupId>org.example</groupId> <artifactId>Count</artifactId> <version>1.0-SNAPSHOT</version> </parent> 子项目只需要项目名即可,项目groupId继承自父项目 <artifactId>frontend</artifactId> <version>1.0-SNAPSHOT</version>然后我们发现父项目的依赖都被子项目继承到了,子项目也可以有自己的专属依赖
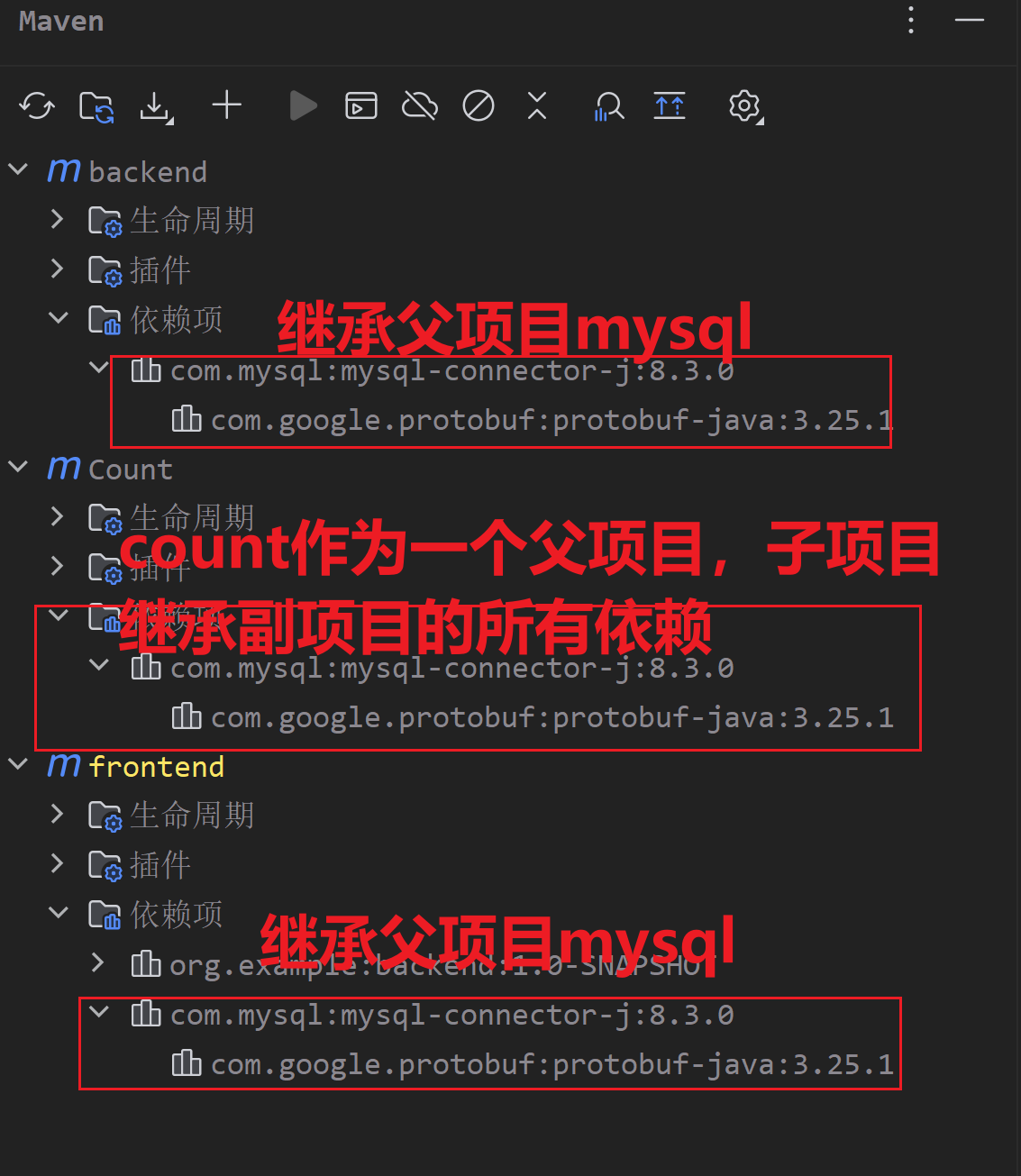
2.子项目选择性引入父项目依赖
由于父项目依赖子项目会无条件的全部继承,如果对于一些子项目不需要的依赖,我们怎么设置可选择性的引入父项目依赖呢?
我们可以将子项目不必须的依赖定义在dependencyManagement当中
<dependencyManagement> <dependencies> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>4.0.0</version> <scope>provided</scope> </dependency> </dependencies> </dependencyManagement>3.子项目默认依赖版本
假设子项目A是一个jar包项目,不显示的声明是不会引入到父项目的dependencyManagement内的依赖的,当项目B是一个web项目,需要显示引入父项目的servlet依赖
<dependencies> <dependency> <groupId>org.example</groupId> <artifactId>backend</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> 因为父项目中已经声明了servlet的版本了,所以声明引入父依赖可以不用申明版本 </dependency> </dependencies>八、SpringBoot Web案例
我们通过一个案例,来将前端开发、后端开发、数据库整合起来。 而这个案例呢,就是我们前面提到的Tlias智能学习辅助系统。
在这个案例中,前端开发人员已经将前端工程开发完毕了。 我们需要做的,就是参考接口文档完成后端功能的开发,然后结合前端工程进行联调测试即可。
1、准备工作
- 创建一个数据库tlias,并准备两张sql表 dept和emp
-- 部门管理create table dept( id int unsigned primary key auto_increment comment '主键ID', name varchar(10) not null unique comment '部门名称', create_time datetime not null comment '创建时间', update_time datetime not null comment '修改时间') comment '部门表';insert into dept (id, name, create_time, update_time) values(1,'学工部',now(),now()),(2,'教研部',now(),now()),(3,'咨询部',now(),now()), (4,'就业部',now(),now()),(5,'人事部',now(),now());-- 员工管理(带约束)create table emp ( id int unsigned primary key auto_increment comment 'ID', username varchar(20) not null unique comment '用户名', password varchar(32) default '123456' comment '密码', name varchar(10) not null comment '姓名', gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女', image varchar(300) comment '图像', job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师', entrydate date comment '入职时间', dept_id int unsigned comment '部门ID', create_time datetime not null comment '创建时间', update_time datetime not null comment '修改时间') comment '员工表';INSERT INTO emp (id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time) VALUES (1,'jinyong','123456','金庸',1,'1.jpg',4,'2000-01-01',2,now(),now()), (2,'zhangwuji','123456','张无忌',1,'2.jpg',2,'2015-01-01',2,now(),now()), (3,'yangxiao','123456','杨逍',1,'3.jpg',2,'2008-05-01',2,now(),now()), (4,'weiyixiao','123456','韦一笑',1,'4.jpg',2,'2007-01-01',2,now(),now()), (5,'changyuchun','123456','常遇春',1,'5.jpg',2,'2012-12-05',2,now(),now()), (6,'xiaozhao','123456','小昭',2,'6.jpg',3,'2013-09-05',1,now(),now()), (7,'jixiaofu','123456','纪晓芙',2,'7.jpg',1,'2005-08-01',1,now(),now()), (8,'zhouzhiruo','123456','周芷若',2,'8.jpg',1,'2014-11-09',1,now(),now()), (9,'dingminjun','123456','丁敏君',2,'9.jpg',1,'2011-03-11',1,now(),now()), (10,'zhaomin','123456','赵敏',2,'10.jpg',1,'2013-09-05',1,now(),now()), (11,'luzhangke','123456','鹿杖客',1,'11.jpg',5,'2007-02-01',3,now(),now()), (12,'hebiweng','123456','鹤笔翁',1,'12.jpg',5,'2008-08-18',3,now(),now()), (13,'fangdongbai','123456','方东白',1,'13.jpg',5,'2012-11-01',3,now(),now()), (14,'zhangsanfeng','123456','张三丰',1,'14.jpg',2,'2002-08-01',2,now(),now()), (15,'yulianzhou','123456','俞莲舟',1,'15.jpg',2,'2011-05-01',2,now(),now()), (16,'songyuanqiao','123456','宋远桥',1,'16.jpg',2,'2007-01-01',2,now(),now()), (17,'chenyouliang','123456','陈友谅',1,'17.jpg',NULL,'2015-03-21',NULL,now(),now()); - 创建SpringBoot工程,引入对应的起步依赖(web、mybatis、mysql驱动、lombok),并创建项目工程结构
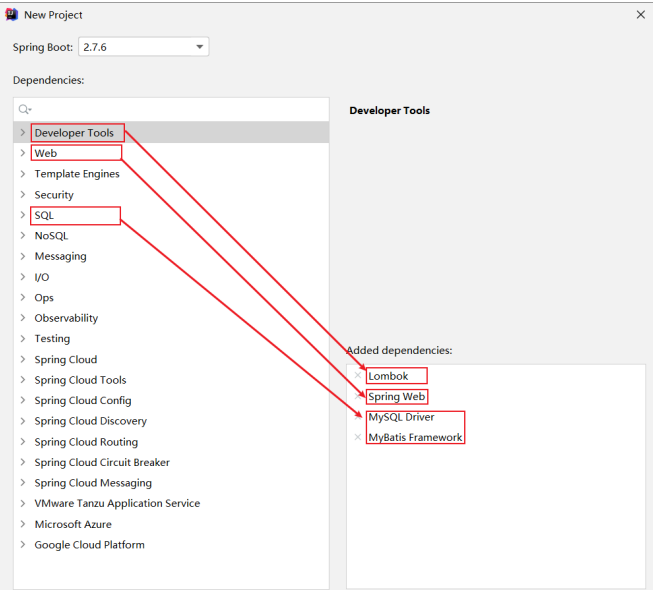
- 配置文件application.properties引入mybatis 数据库连接信息,mybatis开启驼峰映射,开启mybatis日志控制台打印
spring.application.name=tlias-web-management # 配置数据库连接信息(四要素)# 驱动类名称spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver# 数据库连接的urlspring.datasource.url=jdbc:mysql://localhost:3306/tlias# 连接数据库的用户名spring.datasource.username=root# 连接数据库的密码spring.datasource.password=root# 配置mybatis日志输出到控制台mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl# 开启mybatis驼峰命名自动映射开关mybatis.configuration.map-underscore-to-camel-case=true - 引入实体类Emp和Dept和统一响应结果Result

/** * 员工实体类 */@Data@NoArgsConstructor@AllArgsConstructorpublic class Emp { private Integer id; //ID private String username; //用户名 private String password; //密码 private String name; //姓名 private Short gender; //性别 , 1 男, 2 女 private String image; //图像url private Short job; //职位 , 1 班主任 , 2 讲师 , 3 学工主管 , 4 教研主管 , 5 咨询师 private LocalDate entrydate; //入职日期 private Integer deptId; //部门ID private LocalDateTime createTime; //创建时间 private LocalDateTime updateTime; //修改时间}/** * 部门实体类 */@Data@NoArgsConstructor@AllArgsConstructorpublic class Dept { private Integer id; //ID private String name; //部门名称 private LocalDateTime createTime; //创建时间 private LocalDateTime updateTime; //修改时间}@Data@NoArgsConstructor@AllArgsConstructorpublic class Result { private Integer code;//响应码,1 代表成功; 0 代表失败 private String msg; //响应信息 描述字符串 private Object data; //返回的数据 //增删改 成功响应 public static Result success() { return new Result(1, "success", null); } //查询 成功响应 public static Result success(Object data) { return new Result(1, "success", data); } //失败响应 public static Result error(String msg) { return new Result(0, msg, null); }} - 项目工程不同层级添加对应注解,标识其为spring组件
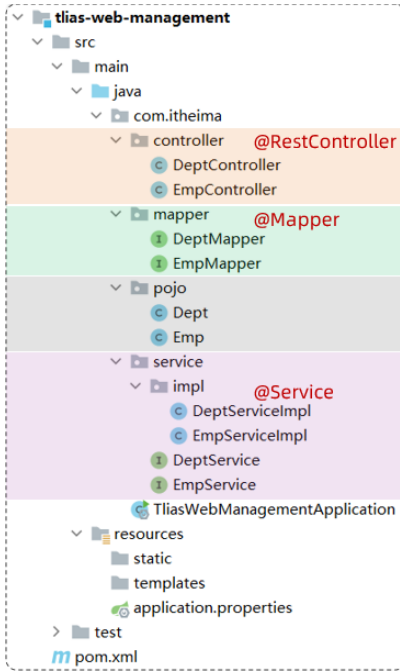 环境搭建总结
环境搭建总结

2、开发规范Restful
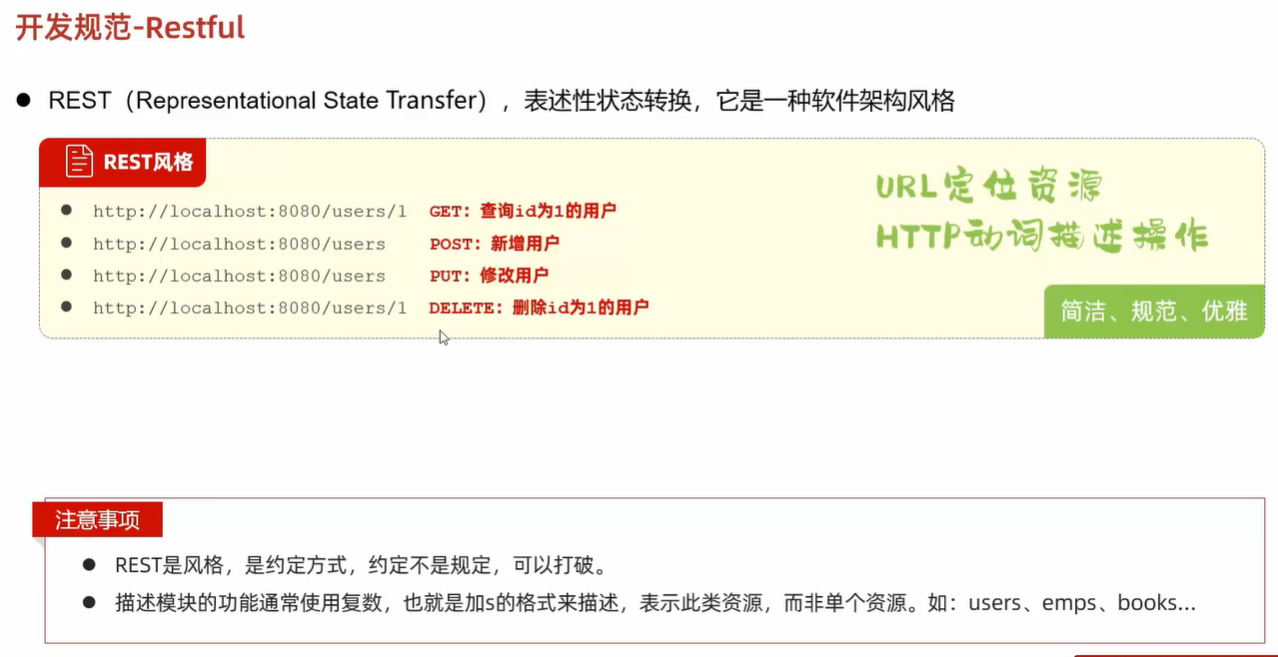
- Rest 表述性状态转换,是一种软件架构风格

在Restful风格的url当中,通过四种请求方式来操作数据的增删改查
- Get 查询
- Post 新增
- Put 修改
- Delete 删除
3、开发部门管理
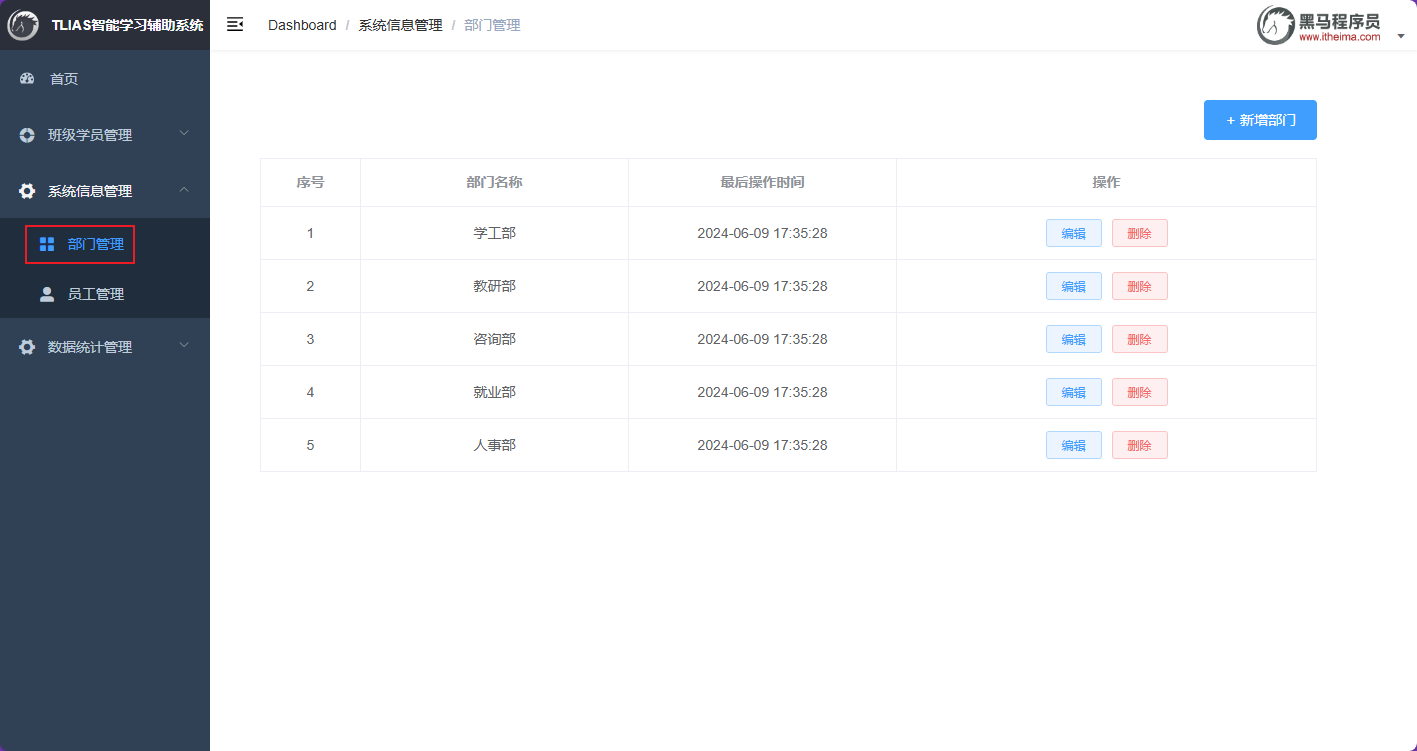
开发部门管理功能包含
- 查询部门
- 删除部门
- 新增部门
- 更新部门
1.查询部门
首先实现的功能是查询部门,接口文档如下
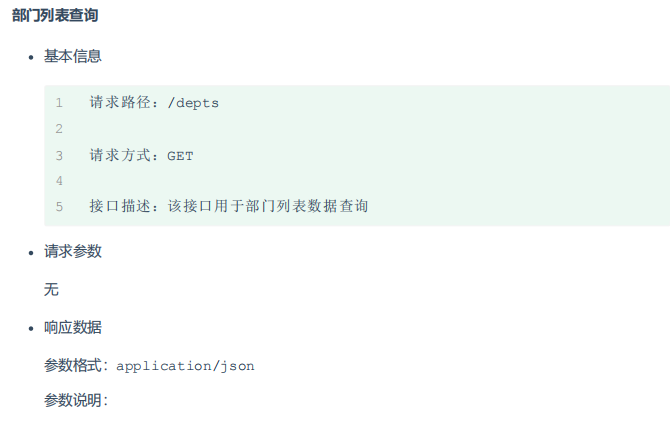

思路如下
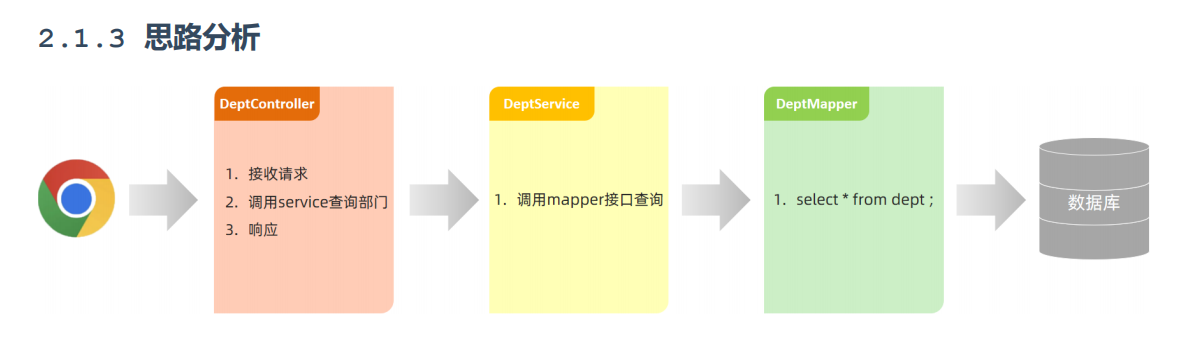
首先DeptController层
@Slf4jlombok工具包内的生成日志对象标签,可以直接使用log.info打印日志信息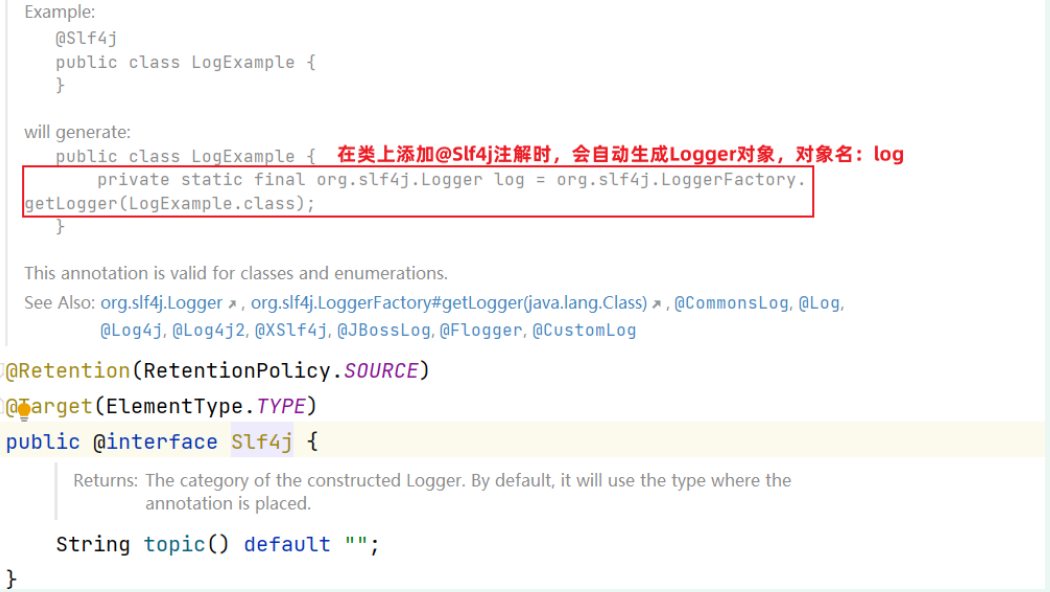
@GetMapping("/depts")是@RequestMapping的衍生注解,相当于get方式的RequestMapping,等价于@RequestMapping(value = "/depts",method = RequestMethod.GET),可以通过@RequestMapping将子路径重复的部分统一起来,简化代码
/** * 部门管理Controller **/ @Slf4j // lombok工具包内的生成日志对象标签 相当于代码 private static Logger log = LoggerFactory.getLogger(DeptController.class); @RestController public class DeptController { @Autowired private DeptService deptService; // 查询全部部门数据 // @RequestMapping(value = "/depts",method = RequestMethod.GET) @GetMapping("/depts") // @RequestMapping的衍生注解,相当于get方式的RequestMapping public Result list() { log.info("==================== 查询全部部门数据 ===================="); List<Dept> deptList = deptService.list(); return Result.success(deptList); } }DeptService接口层
public interface DeptService { List<Dept> list(); }DeptServiceImpl实现类
@Service public class DeptServiceImpl implements DeptService { @Autowired private DeptMapper deptMapper; @Override public List<Dept> list() { return deptMapper.list(); } }DeptMapper层实现类
@Mapper public interface DeptMapper { @Select("select * from dept") List<Dept> list(); }以上后端接口代码开发完毕,打开前端开发好的代码,双击ngnix.exe项目运行前端项目,nginx默认端口是90
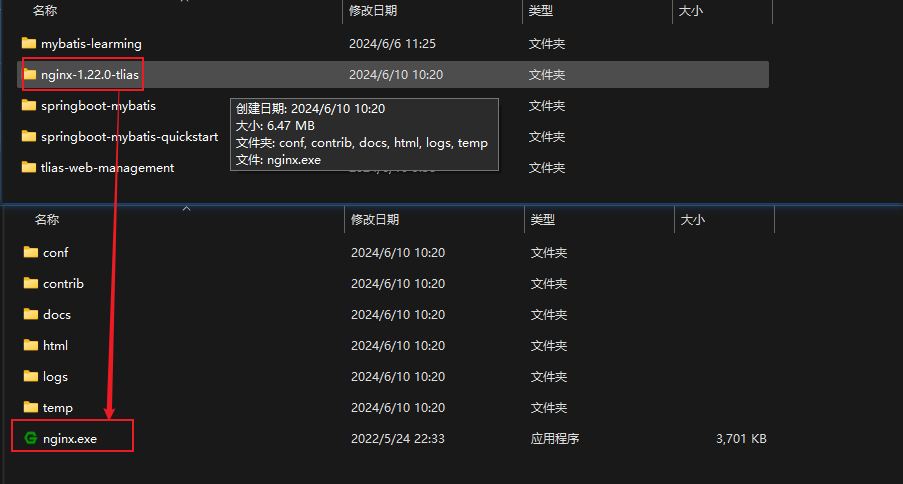
访问前端路径http://localhost:90/ 打开前端页面调用查询接口展示如下
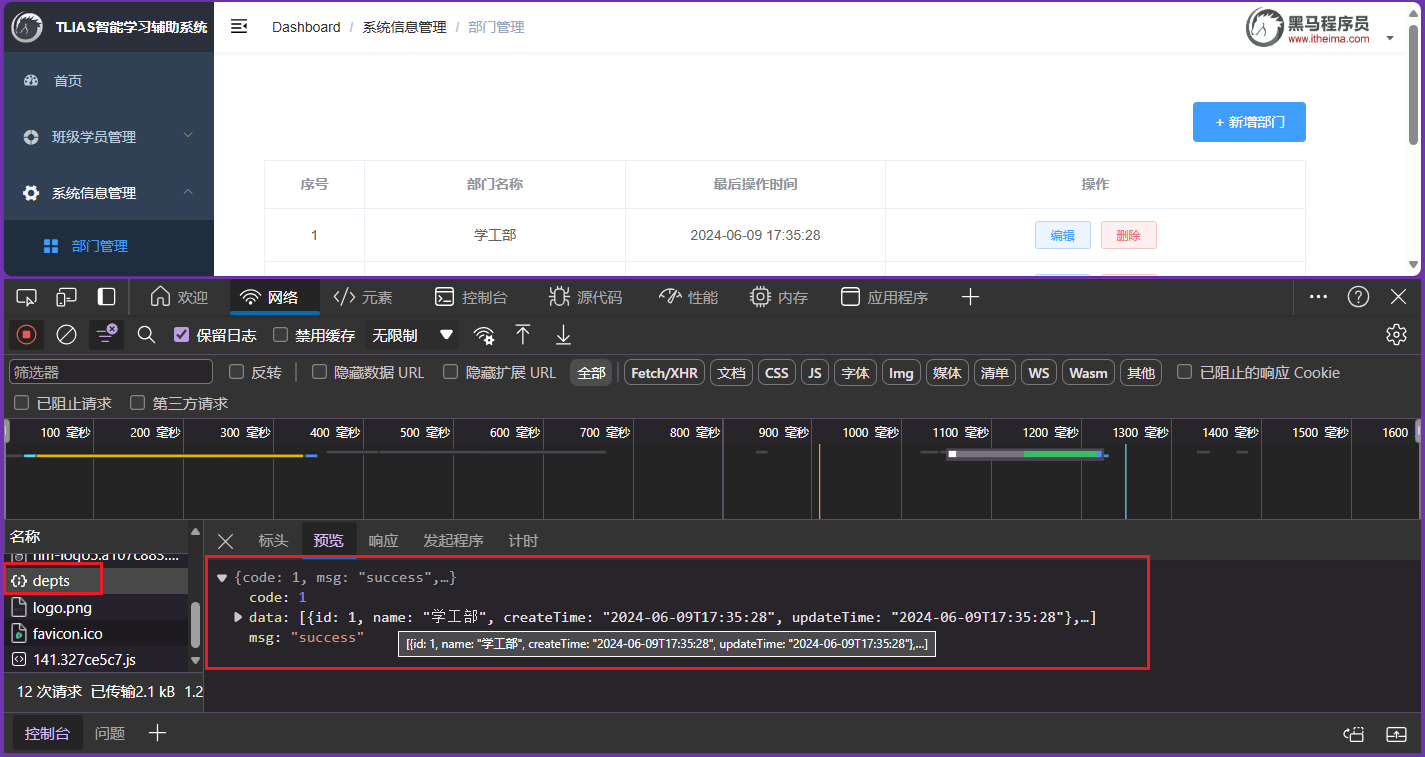
2.删除部门
需求:点击部门列表后面操作栏的 "删除" 按钮,就可以删除该部门信息。 此时,前端只需要给服务端传递一个ID参数就可以了。
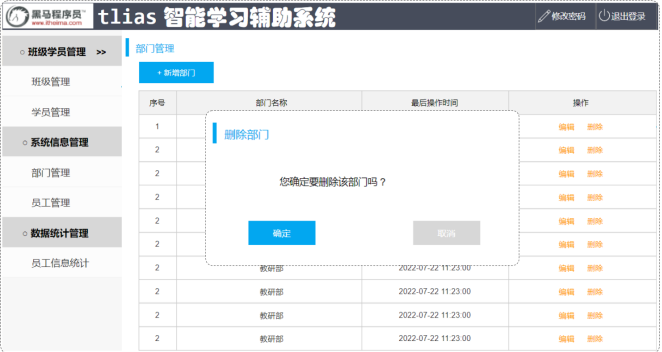
接口文档

响应数据案例
{ "code":1, "msg":"success", "data":null }思路分析
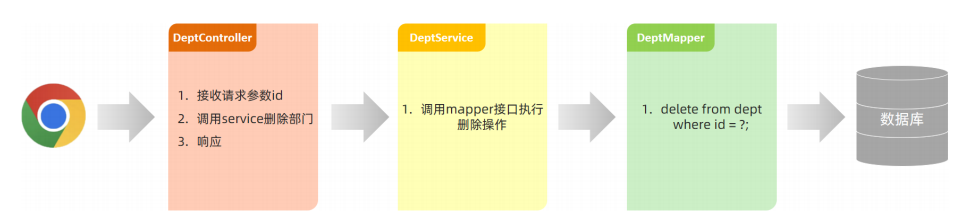
功能开发
- DeptController层
// 删除部门接口 @DeleteMapping("/{id}") public Result delete(@PathVariable Integer id) { log.info("==================== 根据ID删除部门数据id:{}====================", id); deptService.deleteById(id); return Result.success(); }- DeptService层和DeptServiceImpl实现类
// DeptService层 void deleteById(Integer id); // DeptServiceImpl实现类 @Override public void deleteById(Integer id) { deptMapper.deleteById(id); }- DeptMapper层
@Delete("delete from dept where id = #{id} ") void deleteById(Integer id);3.新增部门
需求:点击 "新增部门" 按钮,弹出新增部门对话框,输入部门名称,点击 "保存" ,将部门信息保存到数据库
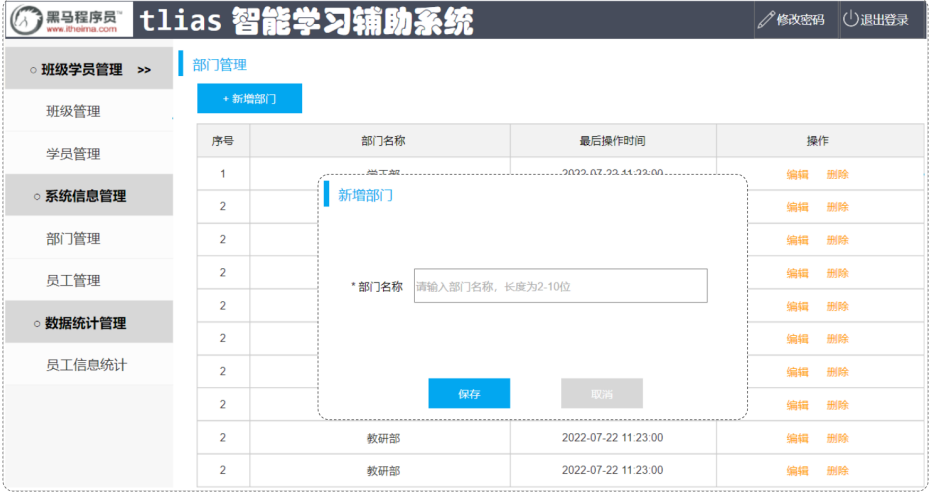
接口文档
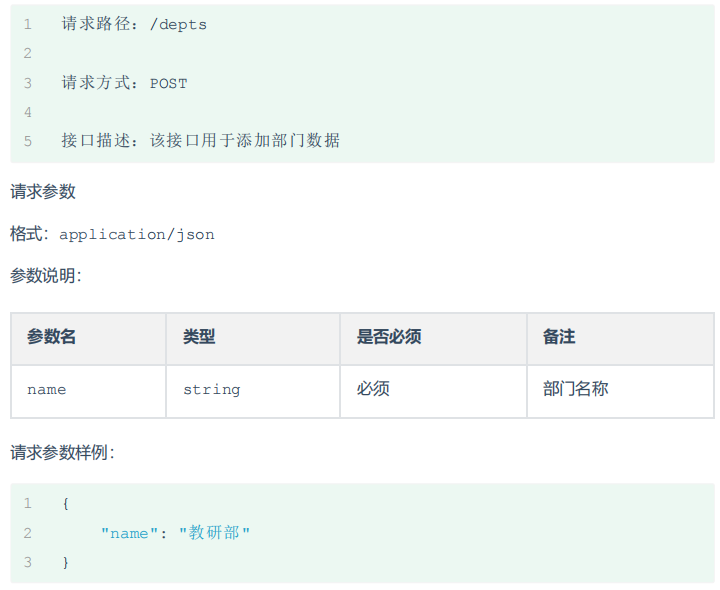
思路分析
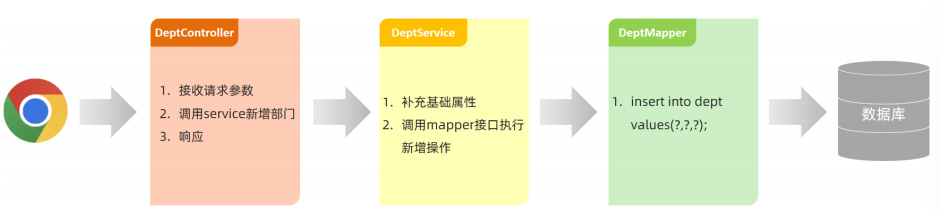
功能开发
- DeptController层
// 添加部门 @PostMapping public Result add(@RequestBody Dept dept) { log.info("==================== 新增部门 ===================="); deptService.add(dept); return Result.success(); }- DeptService层和DeptServiceImpl实现类
// DeptService层 void add(Dept dept); // DeptServiceImpl实现类 @Override public void add(Dept dept) { dept.setCreateTime(LocalDateTime.now()); dept.setUpdateTime(LocalDateTime.now()); deptMapper.insert(dept); }- DeptMapper层
void insert(Dept dept);<!-- 插入部门--> <!-- insert into dept(name,create_time,update_time) valus(#{name},#{createTime},#{updateTime})--> <insert id="insert" parameterType="com.itheima.pojo.Dept"> insert into dept <trim prefix="(" suffix=")" suffixOverrides=","> <if test="name != null">name,</if> <if test="createTime != null">create_time,</if> <if test="updateTime != null">update_time,</if> </trim> <trim prefix="values(" suffix=")" suffixOverrides=","> <if test="name != null">#{name},</if> <if test="createTime != null">#{createTime},</if> <if test="updateTime != null">#{updateTime},</if> </trim> </insert>4、开发员工管理
我们之前做的查询功能,是将数据库中所有的数据查询出来并展示到页面上,试想如果数据库中的数据有很多(假设有十几万条)的时候,将数据全部展示出来肯定不现实,那如何解决这个问题呢?
可以使用分页解决这个问题。每次只展示一页的数据,比如:一页展示10条数据,如果还想看其他的数据,可以通过点击页码进行查询。
员工管理由于数据量比较大,因此需要使用分页查询。
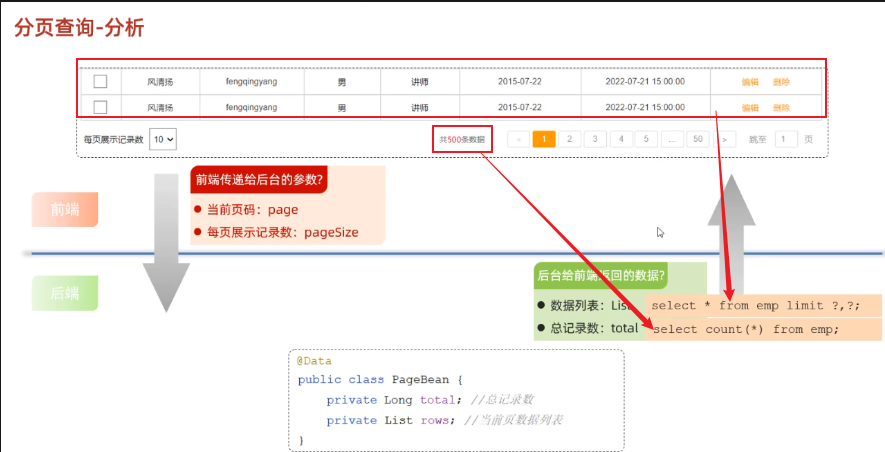
且基于页面原型分析,前端点击页码向后端传递的参数为
- page 当前显示的页码
- pageSize 每页显示条数
后端需要向前端传递的参数为
- 当前页面查询到的数据列表 rows
- 所有数据条数 total
由于后端向前端传递的参数由两个类型不同的参数,因此我们需要创建一个分页查询结果封装类PageBean将rows和total参数封装起来返回给前端。
/** * 分页查询结果封装类 */ @Data @NoArgsConstructor @AllArgsConstructor public class PageBean { private Long total; //总记录数 private List rows; //数据列表 }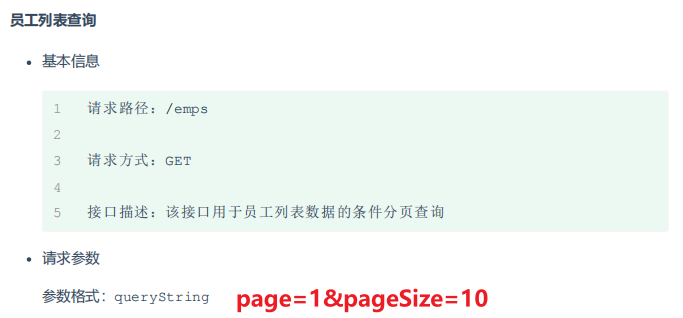
实现思路
1.普通方法实现分页查询
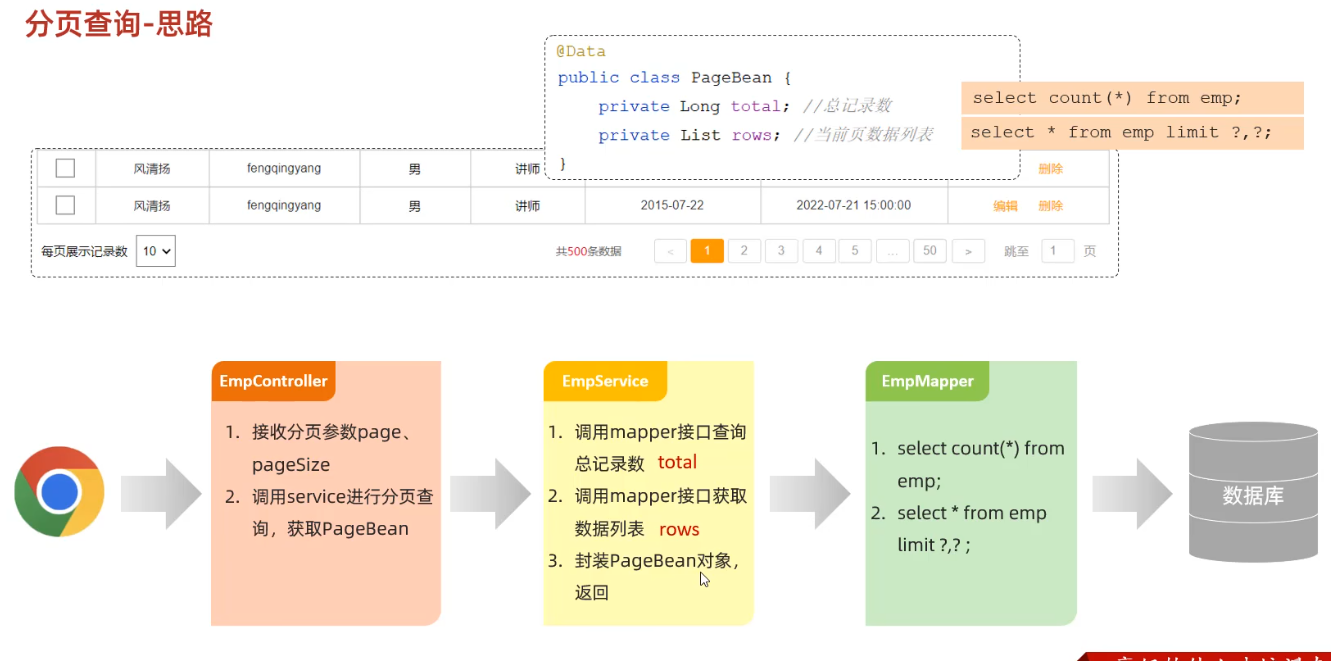
EmpController
- 需要接受两个参数page(页码)和pageSize(每页展示条数)
- 返回结果封装到PageBean内返回到前端
@Slf4j @RestController @RequestMapping("/emps") public class EmpController { @Autowired private EmpService empService; /** * 分页查询 * * @param page 查询页码 * @param pageSize 每页展示数据条数 * @return */ @GetMapping public Result page(@RequestParam(defaultValue = "1") Integer page, @RequestParam(defaultValue = "10") Integer pageSize) { log.info("==================== 分页查询对应页码{}下的{}条员工数据 ====================", page, pageSize); PageBean pageBean = empService.page(page, pageSize); return Result.success(pageBean); } }EmpService和EmpServiceImpl
- 将调用mapper层得到的两个参数row(指定页展示的数据列表)和total(总共数据条数)结果封装到PageBean对象返回给Controller层
- 首先我们观察分页查询的sql语句

- 通过页码page和每页展示个数pageSize计算出分页查询的起始索引index
index = (page - 1) * pageSize
// EmpService public interface EmpService { PageBean page(Integer page, Integer pageSize); } // EmpServiceImpl /** * @param page 查询页码 * @param pageSize 每页查询个数 * @return */ @Override public PageBean page(Integer page, Integer pageSize) { // 1.获取查询的总记录数 Long total = empMapper.count(); // 2.获取查询到的数据列表 Integer index = (page - 1) * pageSize; List<Emp> rows = empMapper.page(index, pageSize); // 3.封装到PageBean对象并返回 PageBean pageBean = new PageBean(total, rows); return pageBean; }EmpMapper
- mapper层需要两个查询语句,一条计算全部数据的个数,另一个计算分页查询返回的数据列表
@Select("select count(*) from emp") Long count(); @Select("select * from emp limit #{index},#{pageSize}") List<Emp> page(Integer index,Integer pageSize);全部实现如下
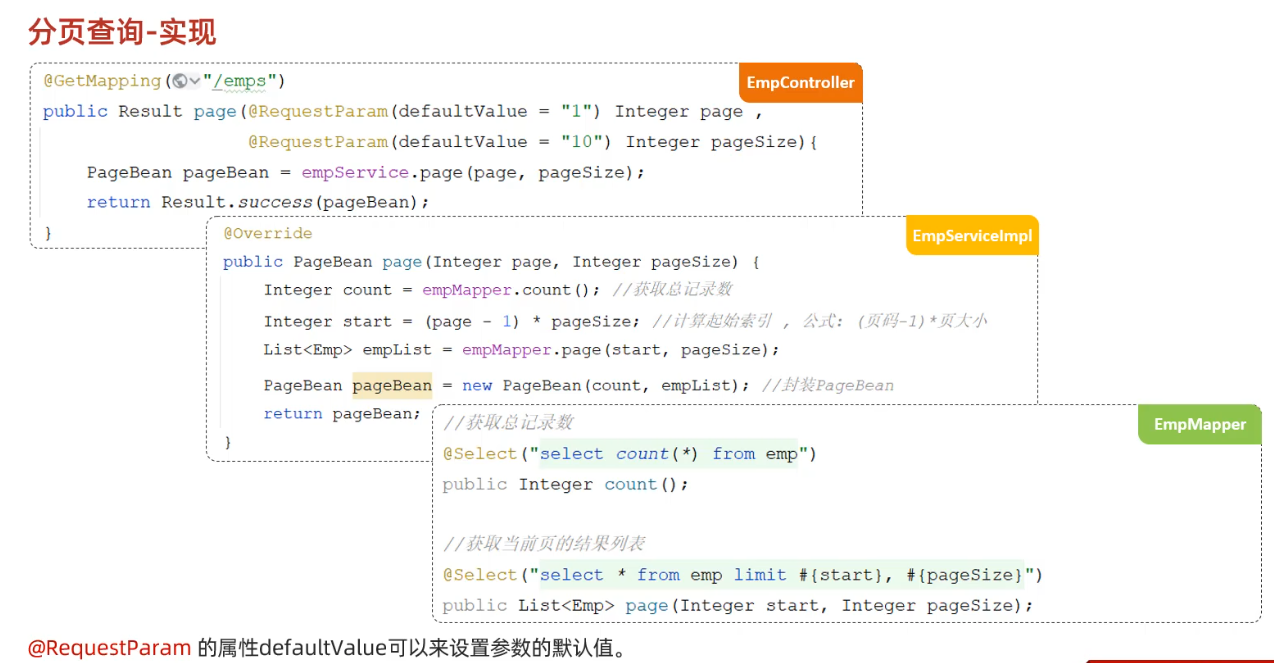
2.PageHelper实现分页查询
原始方式的分页查询,存在着"步骤固定"、"代码频繁"的问题,我们可以使用一些现成的分页插件完成。对于Mybatis来讲现在最主流的就是PageHelper。
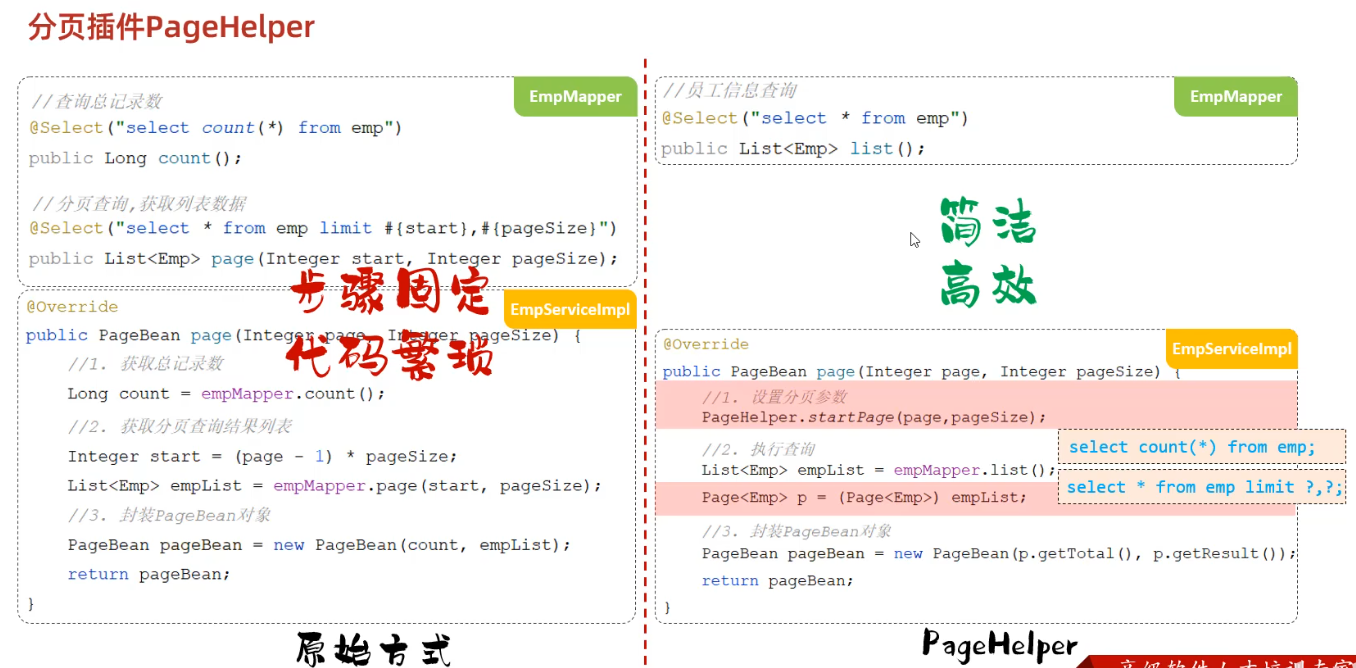
当使用了PageHelper分页插件进行分页,就无需再Mapper中进行手动分页了。
在Mapper中我们只需要进行正常的全部查询即可。在Service层中,调用Mapper的方法之前设置分页参数,在调用Mapper方法执行查询之后,解析分页结果,并将结果封装到PageBean对象中返回。
首先引入PageHelper插件依赖
<!-- pageHelper分页插件--> <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper-spring-boot-starter</artifactId> <version>1.4.6</version> </dependency>EmpController与前端交互代码不变
EmpService、EmpServiceImpl层
- 首先调用PageHelper.startPage(page, pageSize)设置显示页码和页面大小
- 执行普通的查询所有mapper方法,并将其转为
Page<Emp>对象 - 直接通过
Page<Emp>对象的getTotal()和getResult()返回数据总量total和页面显示结果rows 封装结果并返回
// EmpService public interface EmpService { PageBean page(Integer page, Integer pageSize); } // EmpServiceImpl @Override public PageBean page(Integer page, Integer pageSize) { // 1.设置分页参数 PageHelper.startPage(page, pageSize); // 2.执行分页查询,并获取分页结果 List<Emp> empList = empMapper.list(); Page<Emp> p = (Page<Emp>) empList; // 3.获取total和rows封装到PageBean对象并返回 PageBean pageBean = new PageBean(p.getTotal(), p.getResult()); return pageBean; }EmpMapper 只需要执行普通的查询所有方法即可
@Select("select * from emp") List<Emp> list();我们可以发现使用PageHelper插件与普通的视线分页查询方法一样,都会对数据库库进行两次查询并返回结果。
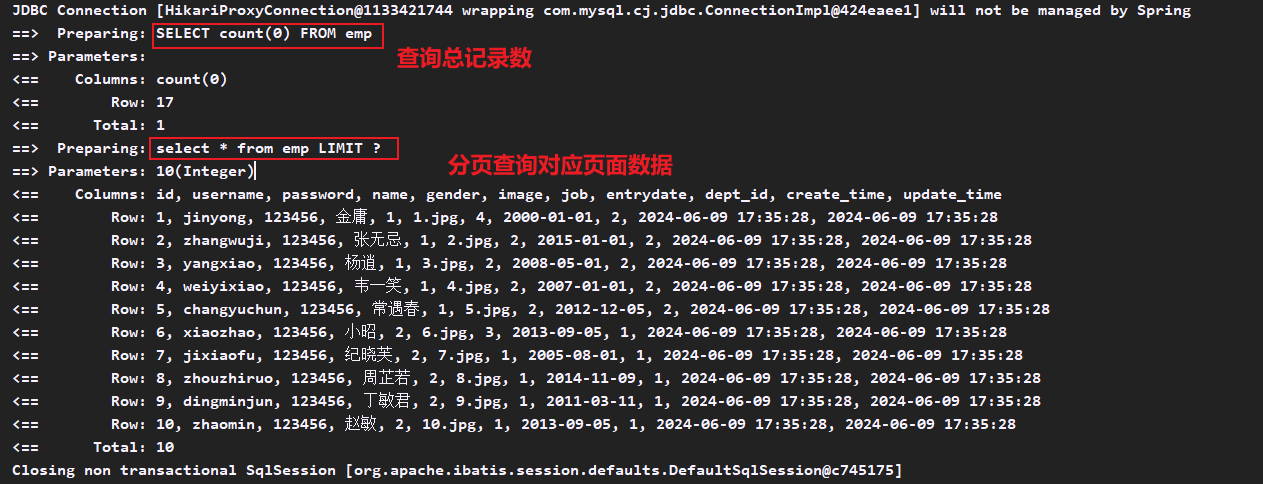
综上所述,分页查询就是通过设置PageHelper.startPage(page, pageSize);将查询所有的结果以及总数,每页显示数据都通过插件计算并封装到Page<Emp>对象内,直接通过get方法获得Page<Emp>对象内数据
3.PageHelper实现条件分页查询
完了分页查询后,下面我们需要在分页查询的基础上,添加条件。
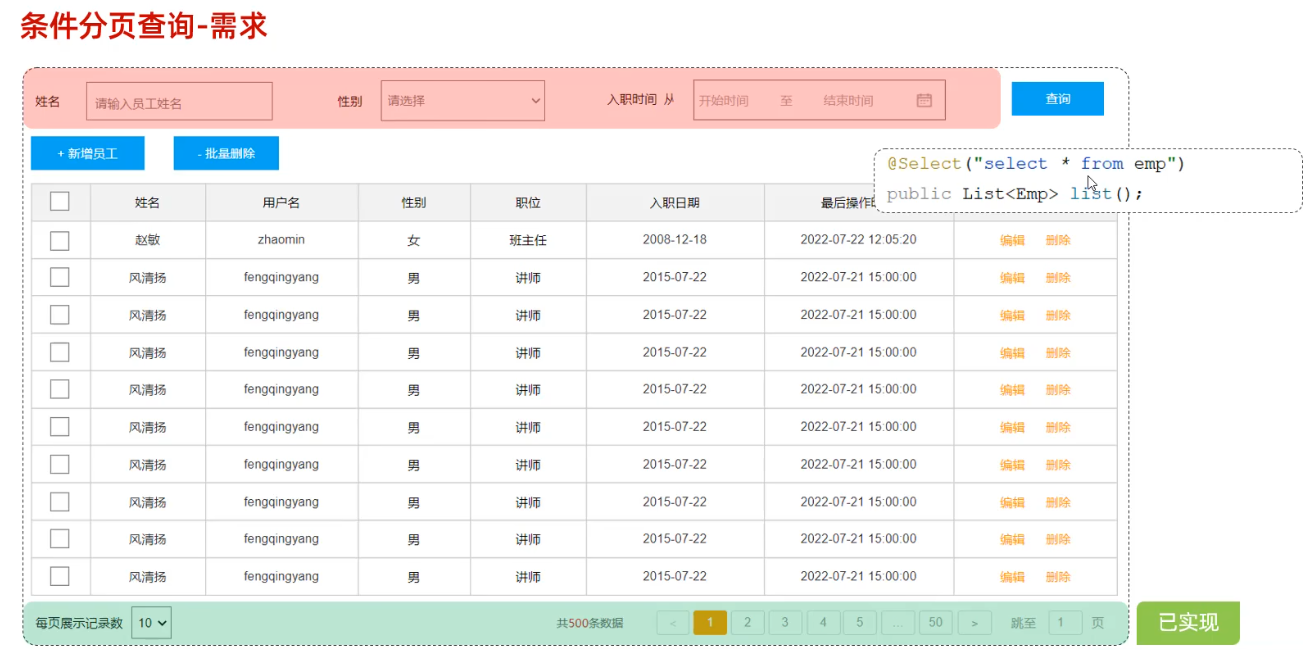
通过员工管理的页面原型我们可以看到,员工列表页面的查询,不仅仅需要考虑分页,还需要考虑查询条件。 分页查询我们已经实现了,接下来,我们需要考虑在分页查询的基础上,再加上查询条件。
我们看到页面原型及需求中描述,搜索栏的搜索条件有三个,分别是:
- 姓名:模糊查询
- 性别:精确查询
- 入职日期:范围查询
sql语句如下:
select * from emp where name like concat('%','张','%') -- 条件1:根据姓名模糊匹配 and gender = 1 -- 条件2:根据性别精确匹配 and entrydate = between '2000-01-01' and '2010-01-01' -- 条件3:根据入职日期范围匹配 order by update_time desc;而且上述的三个条件,都是可以传递,也可以不传递的,也就是动态的。 我们需要使用前面学习的Mybatis中的
动态SQL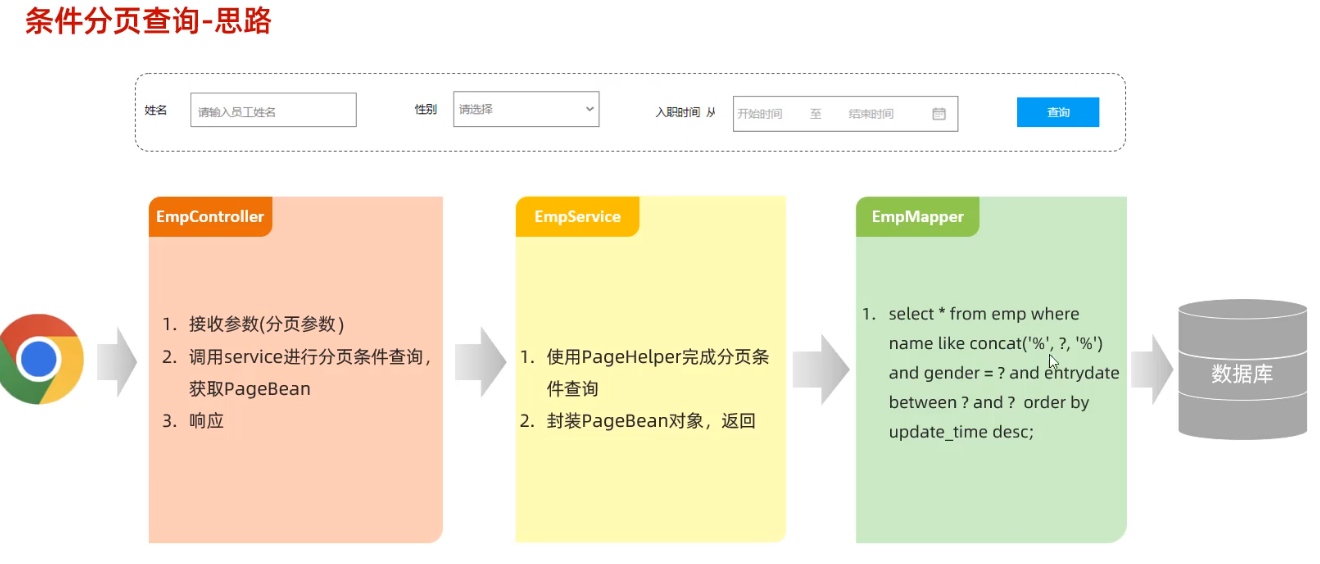
接口文档,我们发现条件分页查询无非是传入后端的参数多了四个,为String name, Short gender, LocalDate begin, LocalDate end,因此只需要在原有的分页查询基础上稍微修改即可。
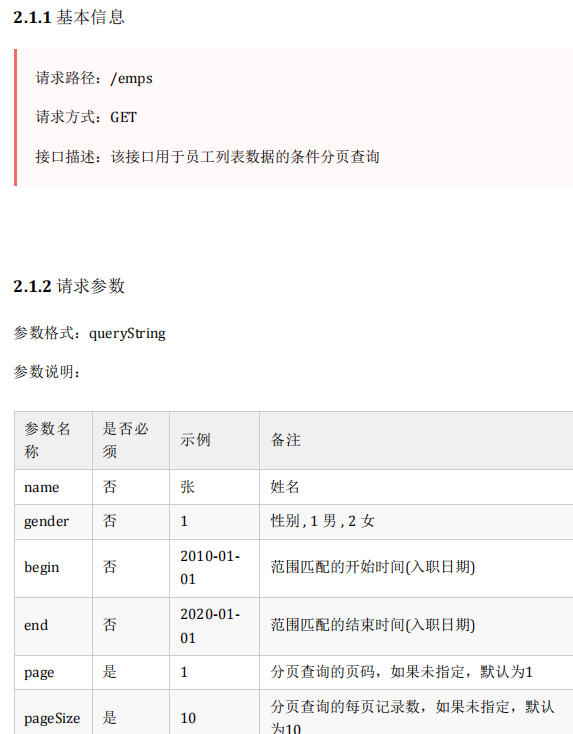
功能实现
EmpController层
- 原来的只传入两参数改为传入六个参数
/** * * @param page 页码 * @param pageSize 页面大小 * @param name 姓名 * @param gender 性别 * @param begin 开始时间 * @param end 结束时间 * @return */ @GetMapping public Result page(@RequestParam(defaultValue = "1") Integer page, @RequestParam(defaultValue = "10") Integer pageSize, String name, Short gender, @DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin, @DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate end) { log.info("==================== 分页查询,参数:{},{},{},{} ====================", page, pageSize, name, gender, begin, end); PageBean pageBean = empService.page(page, pageSize, name, gender, begin, end); return Result.success(pageBean); }EmpService层和EmpServiceImpl
- 只需要将四个查询条件传入 mapper层 进行条件查询即可:List<Emp> empList = empMapper.list(name, gender, begin, end);
//EmpService PageBean page(Integer page, Integer pageSize, String name, Short gender, LocalDate begin, LocalDate end); //EmpServiceImpl /** * @param page 页码 * @param pageSize 每页展示记录数 * @param name 姓名 * @param gender 性别 * @param begin 开始时间 * @param end 结束时间 * @return pageBean */ @Override public PageBean page(Integer page, Integer pageSize, String name, Short gender, LocalDate begin, LocalDate end) { // 1.设置分页参数 PageHelper.startPage(page, pageSize); // 2.执行分页查询,并获取分页结果 List<Emp> empList = empMapper.list(name, gender, begin, end); Page<Emp> p = (Page<Emp>) empList; // 3.获取total和rows封装到PageBean对象并返回 PageBean pageBean = new PageBean(p.getTotal(), p.getResult()); return pageBean; }EmpMapper
- name采用模糊查询,使用concat拼接
- 全部字段采用<sql> <column>字段消除冗余
- 这里存在一个问题,当刷新页面前端自动调用分页查询方法,此时name属性由于是String默认没有传入时为”“空,拼接sql字符串为name like %%,导致错误,因此我们添加一个动态查询限制
<if test="name != null and name != ''">当name为”“不显示该语句。 
List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);<sql id="allColumn"> id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time </sql> <!-- select * from emp where name like concat('%',?,'%') and gender = #{gender} and entrydate between #{begin} and #{end} limit #{index},#{pageSize} order by update_time desc--> <select id="list" resultType="com.itheima.pojo.Emp"> select <include refid="allColumn"/> from emp <where> <!-- 用于name是String类型,当前端未传入name值时,name值默认为''(空);--> <if test="name != null and name != ''"> name like concat('%',#{name},'%') </if> <if test="gender != null"> and gender = #{gender} </if> <if test="begin != null and end != null"> and entrydate between #{begin} and #{end} </if> </where> order by update_time desc </select>相比于普通的分页,条件分页修改如下
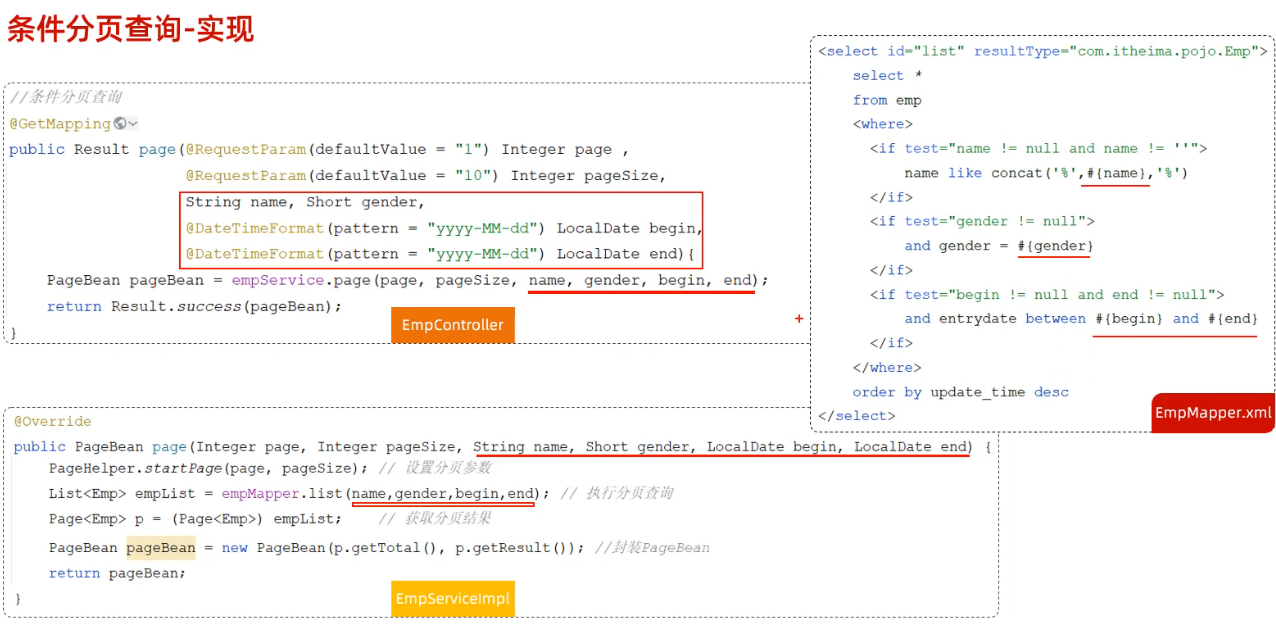
4.删除员工(批量)
本删除接口能够实现删除单个员工以及批量删除员工
接口文档

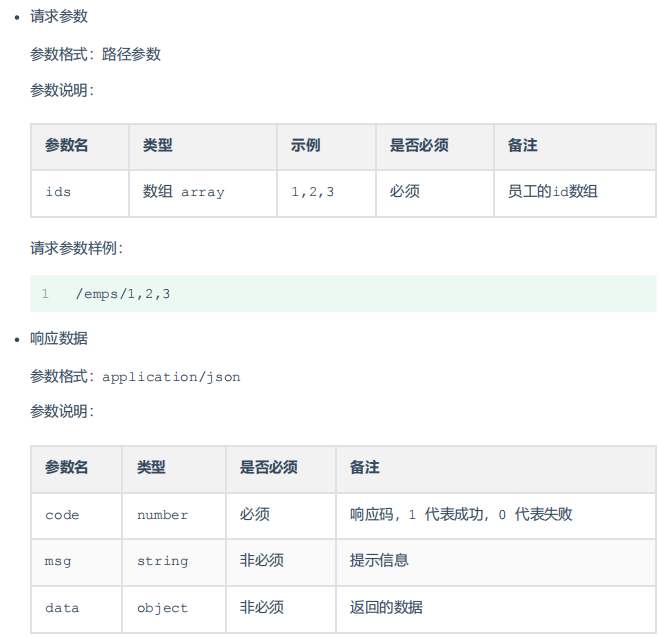
思路分析
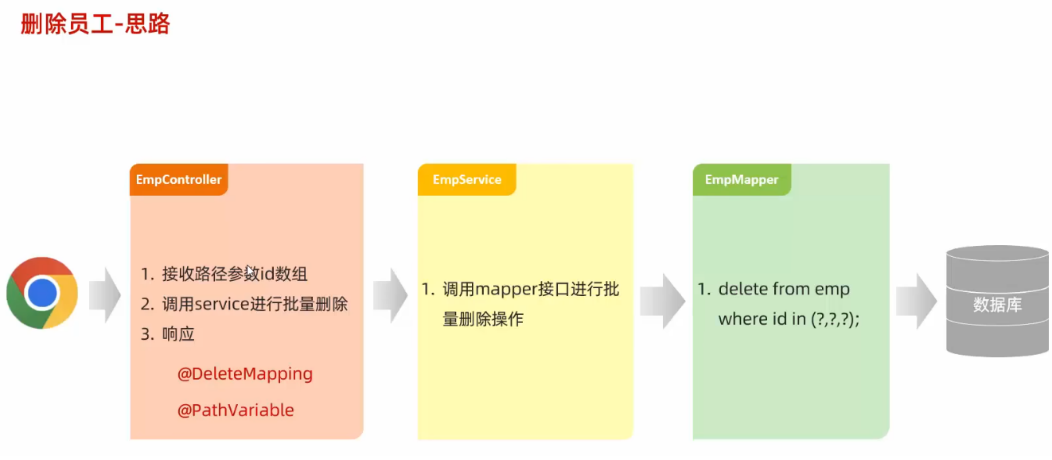
前端通过传入多个路径参数实现批量删除,如/emp/1,2,3
因此使用PathVariable接受多个Integer id列表
功能实现
EmpController
/** * 删除员工 * * @param ids 员工id号,可以为数组表示批量删除员工 * @return */ @DeleteMapping("/{ids}") public Result delete(@PathVariable List<Integer> ids) { log.info("==================== 删除员工id为:{} ====================", ids); empService.delete(ids); return Result.success();EmpService和EmpServiceImpl
// EmpService void delete(List<Integer> ids); // EmpServiceImpl @Override public void delete(List<Integer> ids) { empMapper.delete(ids); }EmpMapper
- 通过foreach实现批量 in子句删除多个数据
void delete(List<Integer> ids);<!-- delete from emp where id in (1,2,3)--> <delete id="delete"> delete from emp where id in <foreach collection="ids" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete>调用接口输出如下

5.新增员工
实现思路
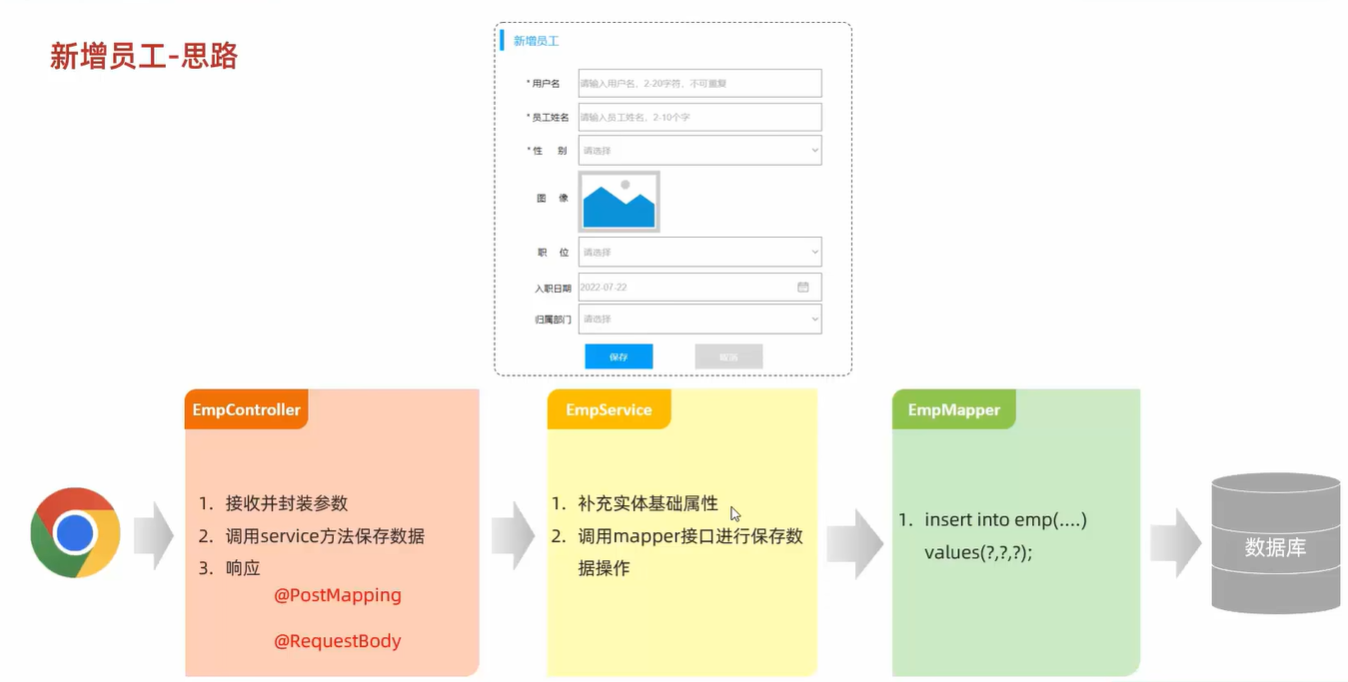
接口文档
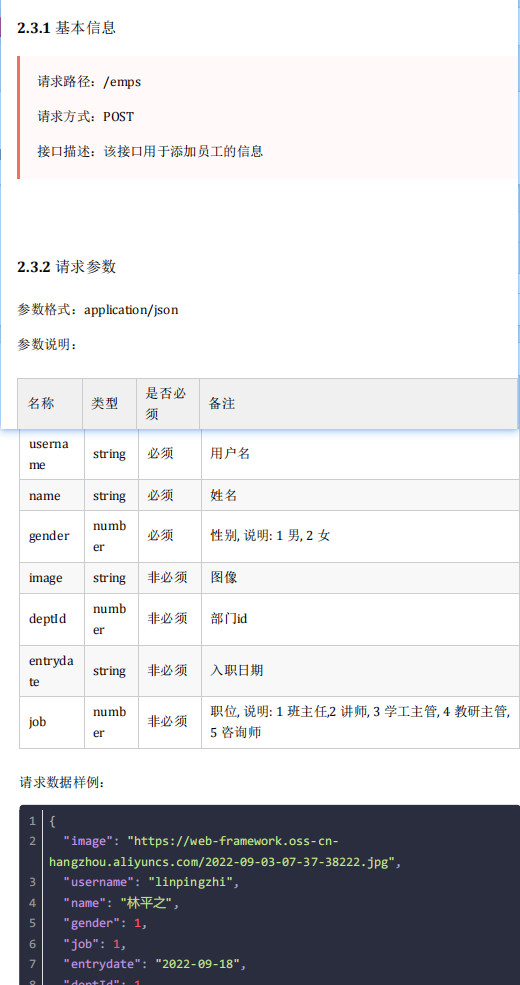
功能实现
EmpController层
@PostMapping public Result insert(@RequestBody Emp emp) { log.info("==================== 新增员工emp:{} ====================", emp); empService.insert(emp); return Result.success(); }EmpService层和EmpServiceImpl
//EmpService void insert(Emp emp); //EmpServiceImpl @Override public void insert(Emp emp) { emp.setCreateTime(LocalDateTime.now()); emp.setUpdateTime(LocalDateTime.now()); empMapper.insert(emp); }EmpMapper
- <trim prefix="(" suffix=")" suffixOverrides=","> 采用trim实现插入数据
suffixOverrides=","表示删除末尾多余的, - <if test="deptId != null">dept_id,</if> <if test="deptId != null">#{deptId},</if> 尖括号内的
test="deptId != null"写java属性;两尖括号内的写mysql字段;#{deptId}#{} 内的写java属性
void insert(Emp emp);<!-- insert into Emp(username , password, name, gender, image, job, entrydate, dept_id, create_time, update_time)--> <!-- values(#{username},#{password},#{name},#{gender},#{image},#{job},#{entrydate},#{deptId},#{createTime},#{updateTime})--> <insert id="insert" parameterType="com.itheima.pojo.Emp"> insert into Emp <trim prefix="(" suffix=")" suffixOverrides=","> <if test="username != null">username,</if> <if test="password != null">password,</if> <if test="name != null">name,</if> <if test="gender != null">gender,</if> <if test="image != null and image != ''">image,</if> <if test="job != null">job,</if> <if test="deptId != null">dept_id,</if> <if test="createTime != null">create_time,</if> <if test="updateTime != null">update_time,</if> </trim> <trim prefix="values(" suffix=")" suffixOverrides=","> <if test="username != null">#{username},</if> <if test="password != null">#{password},</if> <if test="name != null">#{name},</if> <if test="gender != null">#{gender},</if> <if test="image != null and image != ''">#{image},</if> <if test="job != null">#{job},</if> <if test="deptId != null">#{deptId},</if> <if test="createTime != null">#{createTime},</if> <if test="updateTime != null">#{updateTime},</if> </trim> </insert>5、文件上传
文件上传,是指将本地图片、视频、音频等文件上传到服务器,供其他用户浏览或下载的过程。
在我们的案例中,在新增员工的时候,要上传员工的头像,此时就会涉及到文件上传的功能。
文件上传需要设计到两个部分
- 前端程序
- 服务端(后端)程序
首先前端程序
前端程序要实现文件上传的功能,需要实现三要素
- 表单的提交方式为post,相比于get适用于提交大文件
method=“post” - 文件上传的格式
enctype="multipart/form-data会上传文件名和文件内容(默认为 application/x-www-form-urlencoded 仅上传文件名) - 表单类型
type=”file”
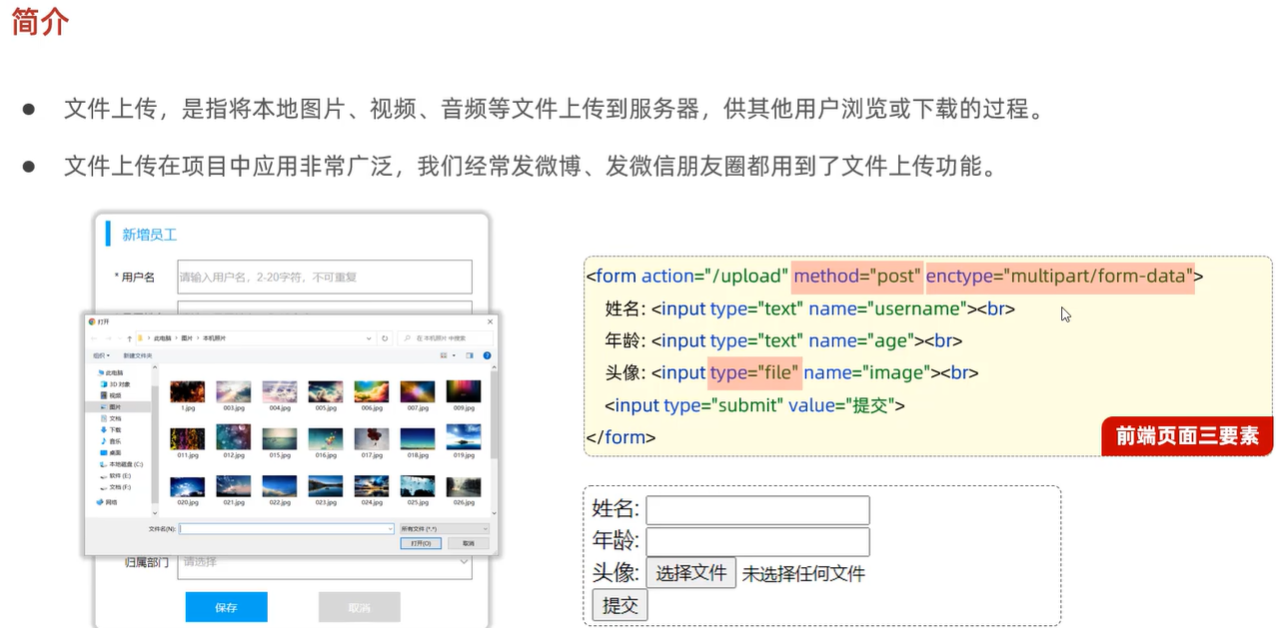
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>上传文件</title> </head> <body> <form action="/upload" method="post" enctype="multipart/form-data"> 姓名: <input type="text" name="username"><br> 年龄: <input type="text" name="age"><br> 头像: <input type="file" name="image"><br> <input type="submit" value="提交"> </form> </body> </html>后端程序接收
MultipartFile是springboot提供的接受上传文件的封装类
public class FileController { public Result upload(String username, Integer age, MultipartFile image) { log.info("==================== 文件上传{},{},{} ====================", username, age, image); return Result.success(); } }文件上传采用
MultipartFile file参数就可以接受,现在我们需要将上传的文件储存起来,有两种存储方法
- 本地存储
- 云端存储
1.本地存储

本地存储的话,我们可以调用MultipartFile的API将临时文件转存到本地磁盘目录下
- String getOriginalFilename() 获取上传文件的原始文件名
- String UUID.randomUUID().toString() 获取唯一的UUID码用于生成拼接上传后的文件名
- void transferTo(new File(“上传文件名”)) 用于将上传的文件存储在该路径下
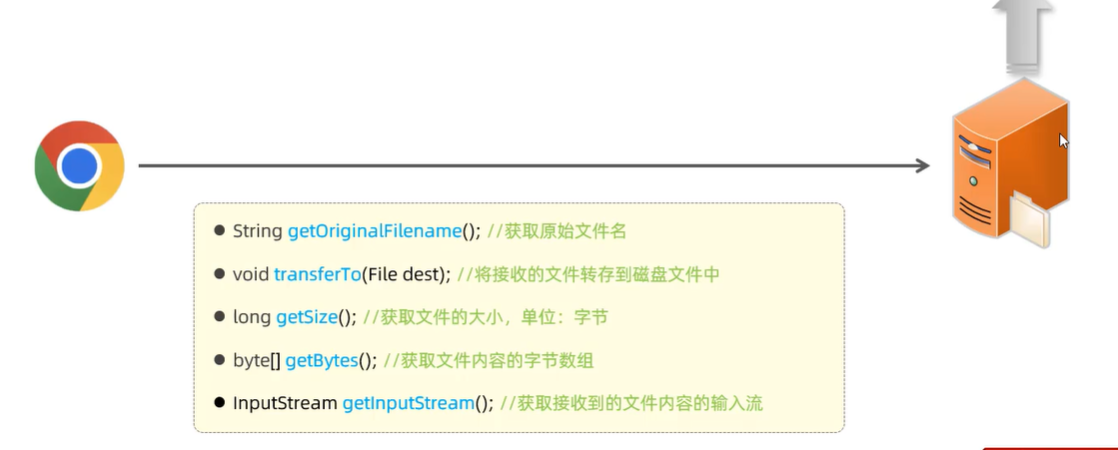
@PostMapping public Result upload(String username, Integer age, MultipartFile image) throws Exception { log.info("==================== 文件上传{},{},{} ====================", username, age, image); // 获取原始的文件名 1.jpg String originalFilename = image.getOriginalFilename(); // 构造唯一的文件名 -uuid(通用唯一识别码) 93cd7a58-faa6-4559-b5d0-a259fdcab448.jpg (采用时间戳的方式也有可能导致相同时间文件重复) int index = originalFilename.lastIndexOf("."); // 原始文件名最后后缀.的位置 String extName = originalFilename.substring(index); // 截取原始文件名的后缀名 .jpg String newFileName = UUID.randomUUID().toString() + extName; // 拼接新的文件名 // 存储文件名在服务器磁盘目录当中 E:\image image.transferTo(new File("E:\\image\\" + newFileName)); return Result.success(); }在进行文件上传的过程中,如果遇到需要上传大文件时,需要设置文件上传的大小(已知单个文件上传大小限制是1MB、单次请求多个文件上传最大限制为10MB)
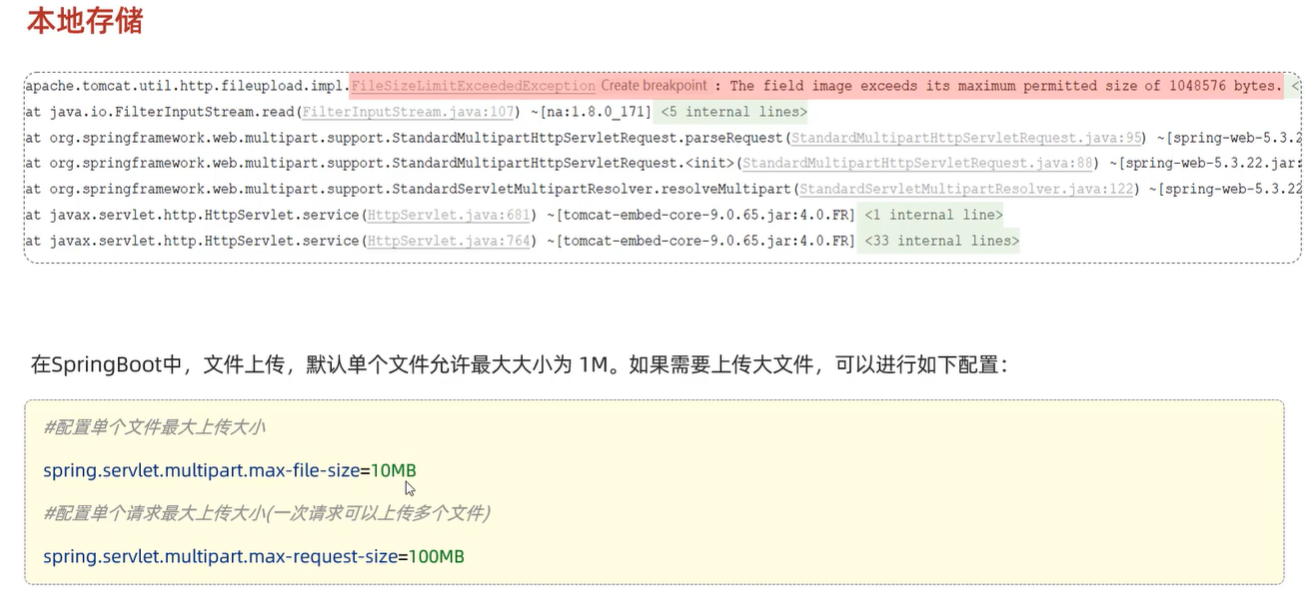
# 文件上传配置 # 配置单个文件上传大小限制 spring.servlet.multipart.max-file-size=10MB # 配置单个请求最大大小限制(一次请求允许上传多个文件) spring.servlet.multipart.max-request-size=100MB利用postman测试文件上传功能
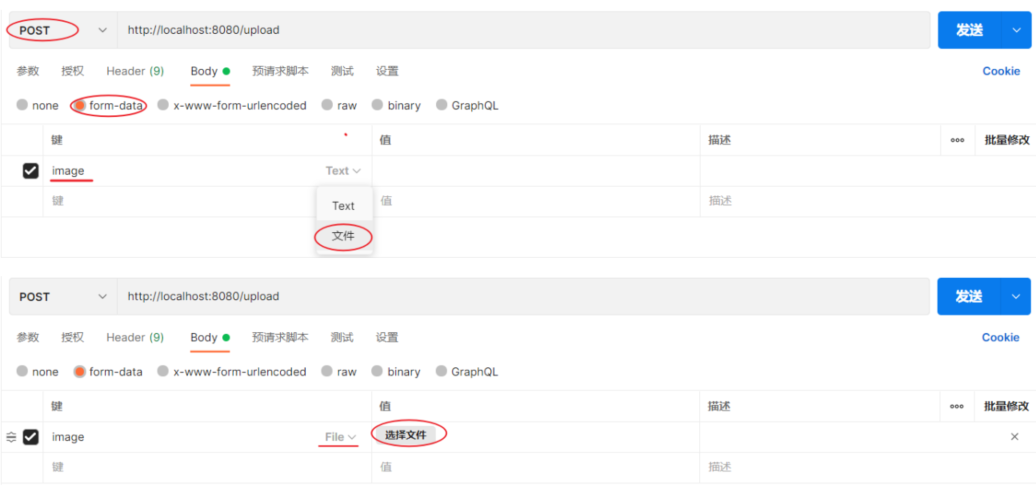
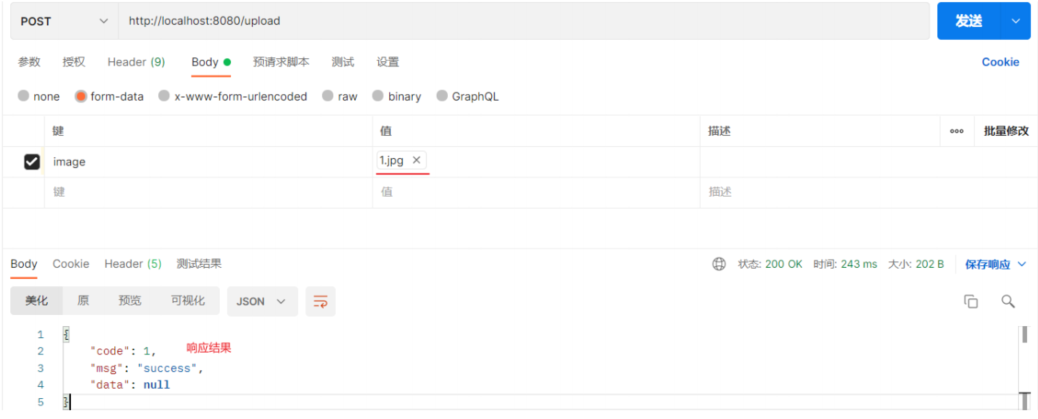
文件上传成功
在使用本地存储的过程中存在一系列问题,如下所示:
- 不安全:磁盘损坏,所有的文件会丢失
- 容量有限:存储大量图片,会导致磁盘空间有限
- 无法直接访问
为了解决以上问题,我们可以采用两种方法
- 搭建存储服务器 fastDFS、MinIO
- 使用现成的云服务器:阿里云、腾讯云、华为云
2.阿里云对象存储OSS
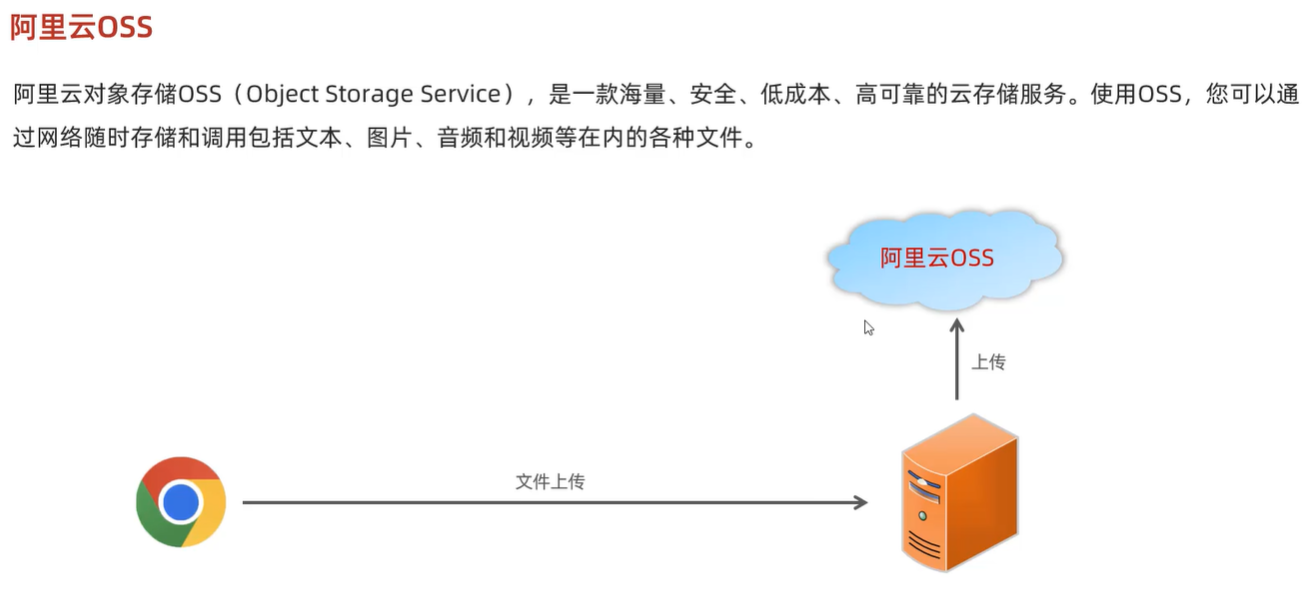
当我们在前端页面选择上传图片时,调用文件上传接口upload,图片被上传到阿里云OSS服务器内并返回图片的访问路径url到前端,前端代码可以通过
标签将url代表的图片展示到页面(如果直接访问则是下载该图片)
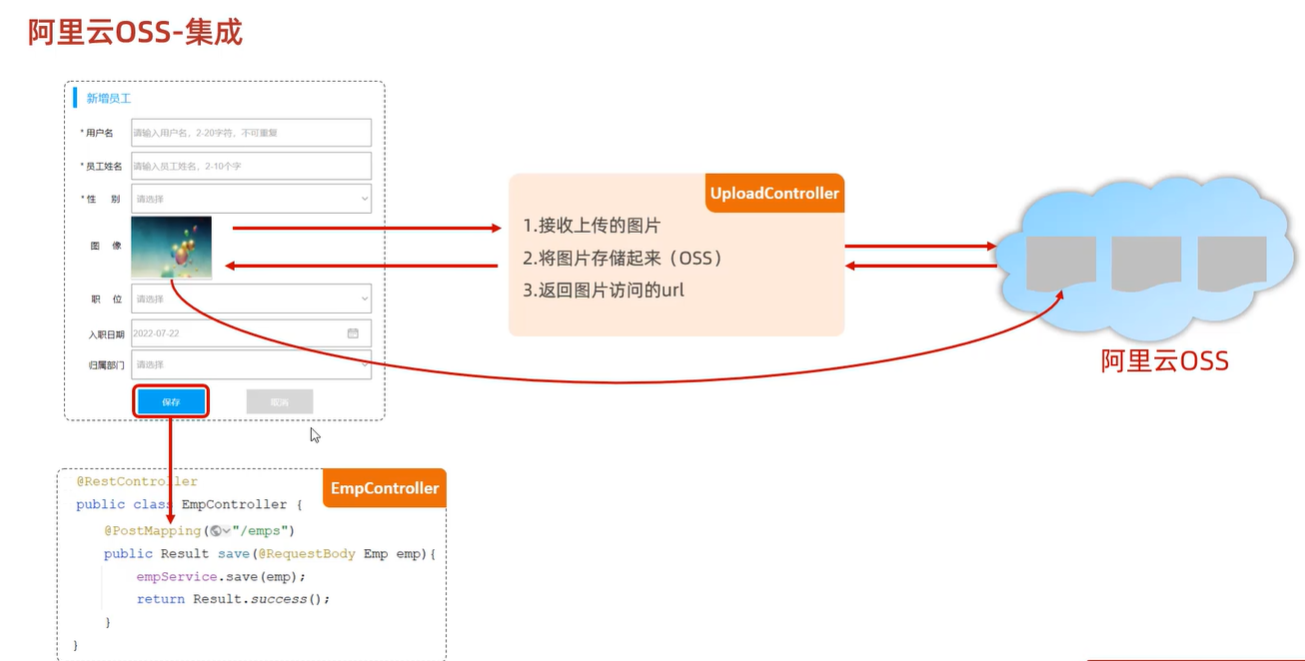
为了实现阿里云集成文件上传功能,首先我们需要创建阿里云OSS对象存储的Bucket,并获取AccessKey Secret和AccessKey ID
集成OSS对象存储
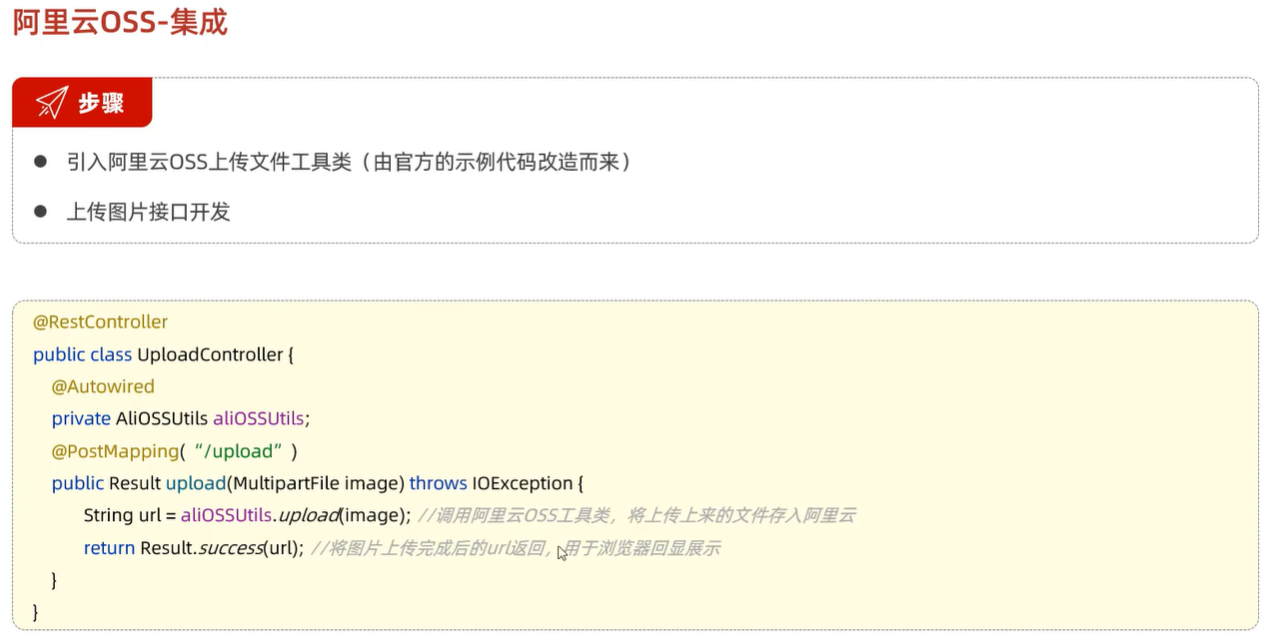
创建完之后引入AliOSSUtils.java工具包如下
/** * 阿里云 OSS 工具类 */ @Component public class AliOSSUtils { // 对象存储https private String endpoint = "https://oss-cn-nanjing.aliyuncs.com"; // 对象存储accessKeyId private String accessKeyId = "LTAI5t75aho9HZ3Yhpq6ECHU"; // 对象存储accessKeySecret private String accessKeySecret = "FOx618MZxQPl9Ixs8dA7IDDLLIXhpc"; // 对象存储bucketName private String bucketName = "web-tlias-xuanchen"; /** * 实现上传图片到OSS */ public String upload(MultipartFile file) throws IOException { // 获取上传的文件的输入流 InputStream inputStream = file.getInputStream(); // 创建新的文件名字,避免文件覆盖 String originalFilename = file.getOriginalFilename(); String fileName = UUID.randomUUID().toString() + originalFilename.substring(originalFilename.lastIndexOf(".")); // UUID+文件名后缀 //上传文件到 OSS OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret); ossClient.putObject(bucketName, fileName, inputStream); //拼接服务器文件访问路径 String url = endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + fileName; // 关闭ossClient ossClient.shutdown(); return url;// 把上传到oss的路径返回 } }编写上传文件接口/upload
// 文件上传到OSS阿里云服务器接口 @PostMapping public Result upload(MultipartFile image) throws Exception { // MultipartFile是Spring用来获取上传文件信息的封装类 log.info("==================== 文件上传,原始文件名{} ====================", image.getOriginalFilename()); // 调用阿里云OSS工具类进行文件上传 String url = aliOSSUtils.upload(image); log.info("==================== 文件上传,上传服务器文件名{} ====================", url); return Result.success(url); }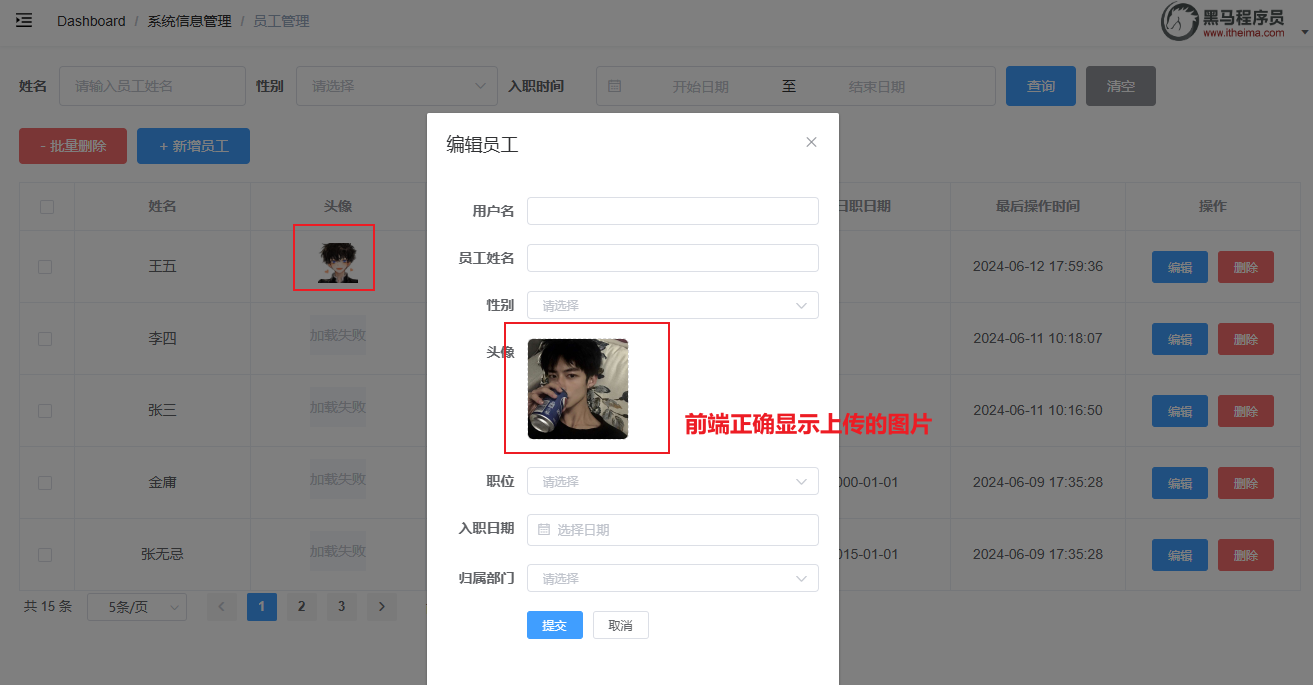
3.文件上传小结

九、配置文件
1、参数配置化
在我们之前编写的程序进行文件上传时,需要调用AliOSSUtils工具类,将文件上传到阿里云的对象存储中。
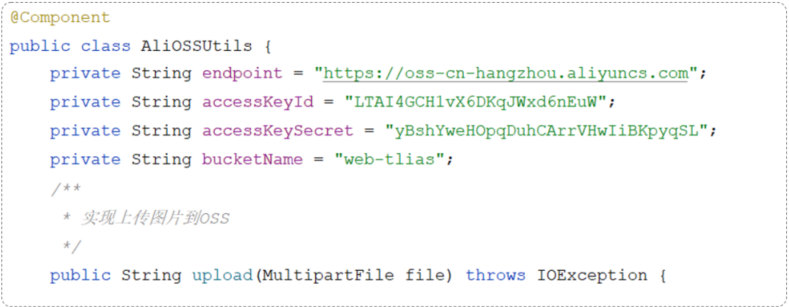
以上需要的一些参数,我们如果将其硬编码到类当中,会不利于维护和管理
为了解决以上分析的问题,我们可以将参数配置在配置文件中。
# 阿里云对象存储配置信息 aliyun.oss.endpoint=https://oss-cn-nanjing.aliyuncs.com aliyun.oss.accessKeyId=LTAI5t75aho9HZ3Yhpq6ECHU aliyun.oss.accessKeySecret=FOx618MZxQPl9Ixs8dA7IDDLLIXhpc aliyun.oss.bucketName=web-tlias-xuanchen然后将AliOSSUtils工具类变为以下形式

而我们可以使用一个现成的注解:@Value将配置文件当中所配置的属性值读取出来,并分别赋值给AliOSSUtils工具类当中的各个属性

- @Value(“${配置文件变量名key}”) 指定java变量应该获取配置文件中的哪个变量的key
@Value("${aliyun.oss.endpoint}") private String endpoint; // 对象存储https https://oss-cn-nanjing.aliyuncs.com @Value("${aliyun.oss.accessKeyId}") private String accessKeyId; // 对象存储accessKeyId LTAI5t75aho9HZ3Yhpq6ECHU @Value("${aliyun.oss.accessKeySecret}") private String accessKeySecret; // 对象存储accessKeySecret FOx618MZxQPl9Ixs8dA7IDDLLIXhpc @Value("${aliyun.oss.bucketName}") private String bucketName; // 对象存储bucketName web-tlias-xuanchen代码优化如下:
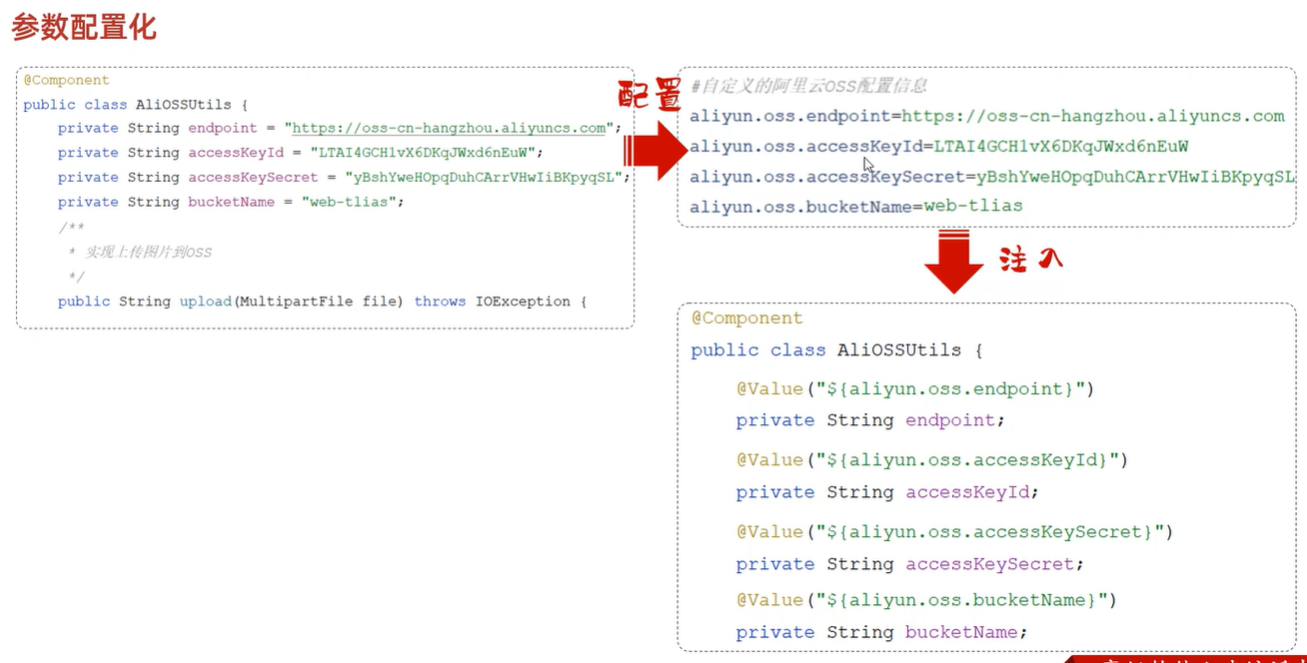
以上通过将原编码的变量值放在一个配置文件中的方式叫做
参数配置化2、yml配置文件

已知java当中配置文件的格式有三种
- XML springboot当中不再使用
- properties springboot默认配置文件
- yml/yaml 更简洁的配置文件格式
2.1 基本语法
2.2 数据格式
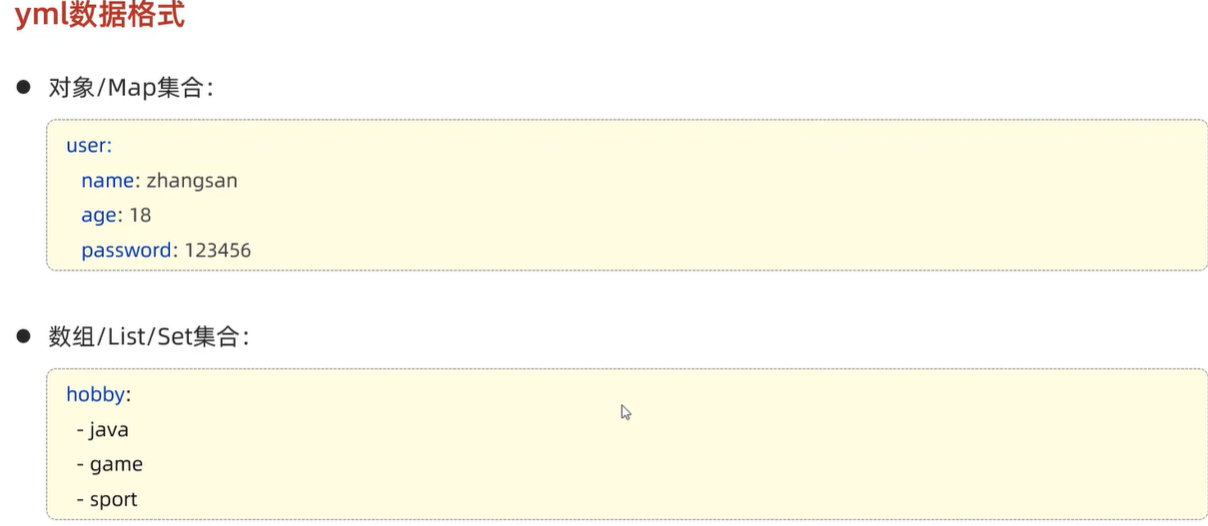
- 对象、map格式
- 数组、集合格式
将项目默认的application.properties配置文件更改为application.yml
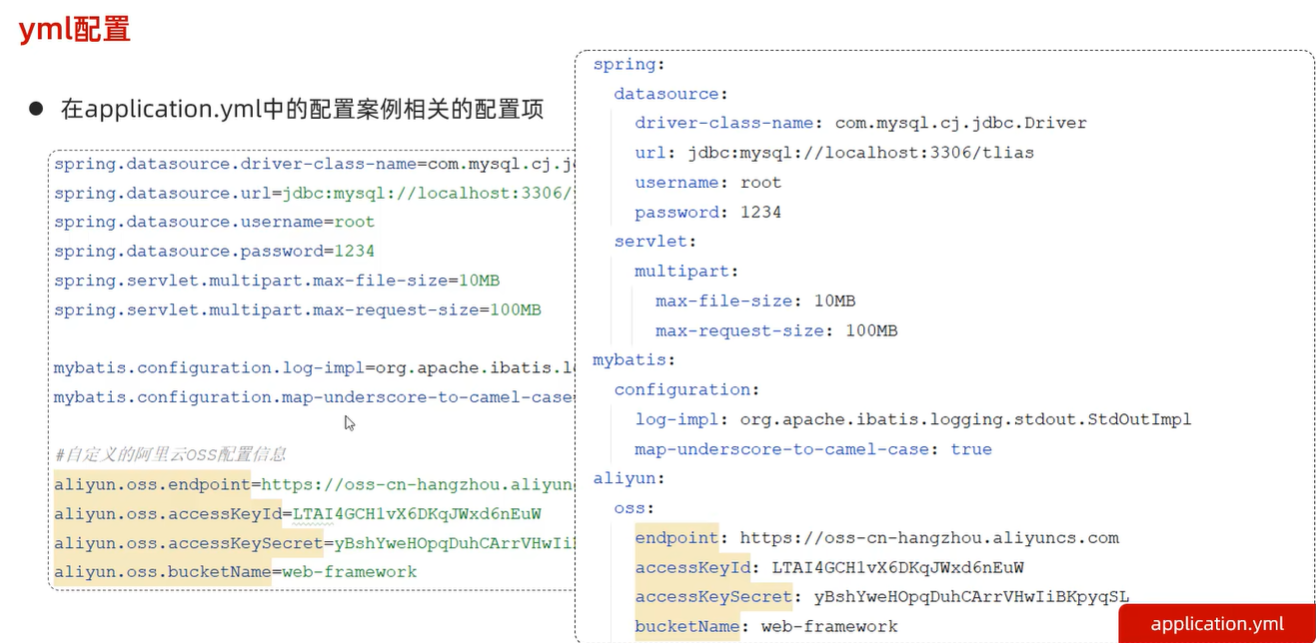
原本application.properties配置文件
spring.application.name=tlias-web-management # 配置数据库连接信息(四要素) # 驱动类名称 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver # 数据库连接的url spring.datasource.url=jdbc:mysql://localhost:3306/tlias # 连接数据库的用户名 spring.datasource.username=root # 连接数据库的密码 spring.datasource.password=root # 配置mybatis日志输出到控制台 mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl # 开启mybatis驼峰命名自动映射开关 mybatis.configuration.map-underscore-to-camel-case=true # 文件上传配置 # 配置单个文件上传大小限制 spring.servlet.multipart.max-file-size=10MB # 配置单个请求最大大小限制(一次请求允许上传多个文件) spring.servlet.multipart.max-request-size=100MB # 阿里云对象存储配置信息 aliyun.oss.endpoint=https://oss-cn-nanjing.aliyuncs.com aliyun.oss.accessKeyId=LTAI5t75aho9HZ3Yhpq6ECHU aliyun.oss.accessKeySecret=FOx618MZxQPl9Ixs8dA7IDDLLIXhpc aliyun.oss.bucketName=web-tlias-xuanchen更改为application.yml配置文件
spring: application: name: tlias-web-management # 数据库连接信息(四要素) datasource: # 驱动类名称 driver-class-name: com.mysql.cj.jdbc.Driver # 数据库连接的url url: jdbc:mysql://localhost:3306/tlias username: root password: root servlet: # 文件上传限制 multipart: # 配置单个文件上传大小限制 max-file-size: 10MB # 配置单个请求最大大小限制(一次请求允许上传多个文件) max-request-size: 100MB # mybatis配置 mybatis: configuration: # 配置mybatis日志输出到控制台 log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 开启mybatis驼峰命名自动映射开关 map-underscore-to-camel-case: true #aliyun: # oss: # endpoint: https://oss-cn-nanjing.aliyuncs.com # accessKeyId: LTAI5t75aho9HZ3Yhpq6ECHU # accessKeySecret: FOx618MZxQPl9Ixs8dA7IDDLLIXhpc # bucketName: web-tlias-xuanchen # aliyun配置变量 aliyun: oss: endpoint: https://oss-cn-nanjing.aliyuncs.com access-key-id: LTAI5t75aho9HZ3Yhpq6ECHU access-key-secret: FOx618MZxQPl9Ixs8dA7IDDLLIXhpc bucket-name: web-tlias-xuanchen3、@ConfigurationProperties
我们在application.properties或者application.yml中配置了阿里云OSS的四项参数之后,如果java程序中需要这四项参数数据,我们直接通过@Value注解来进行注入。这种方式本身没有什么问题问题,但是如果说需要注入的属性较多(例:需要20多个参数数据),我们写起来就会比较繁琐。
在Spring中给我们提供了一种简化方式,可以直接将配置文件中配置项的值自动的注入到对象的属性中。这就是**@ConfigurationProperties**注解,用于批量注入配置项
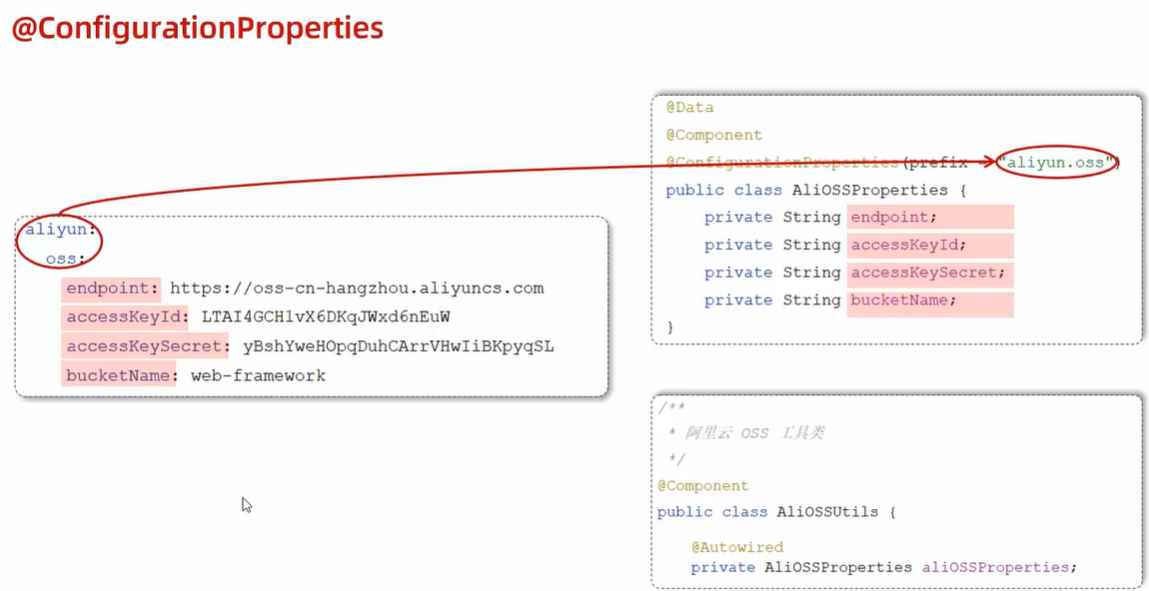
实现批量配置项注入的方式如下:
- 我们创建一个类AliOProperties.java实体类(含get/set方法且由IOC容器管理),且实体类中的属性名和配置文件当中key的名字必须要一致
/** * 阿里云 OSS 配置项封装类 */@Data@Component@ConfigurationProperties(prefix = "aliyun.oss") //自动注入配置信息public class AliOProperties { private String endpoint; private String accessKeyId; private String accessKeySecret; private String bucketName;} - 在AliOSSUtils工具类当中采用依赖注入的方式声明AliOProperties.java实体类对象
- 使用get获取配置项的参数属性
@AutowiredAliOProperties aliOProperties; // 依赖注入/** * 实现上传图片到OSS */public String upload(MultipartFile file) throws IOException { String endpoint = aliOProperties.getEndpoint(); String accessKeyId = aliOProperties.getAccessKeyId(); String accessKeySecret = aliOProperties.getAccessKeySecret(); String bucketName = aliOProperties.getBucketName(); ...}

这个警告提示是告知我们还需要引入一个依赖(不引入也没事):
<!--spring boot配置文件提示依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> </dependency>引入这个依赖之后,在声明@ConfigurationProperties注解之后,在配置文件中会自动提示批量注入的配置项
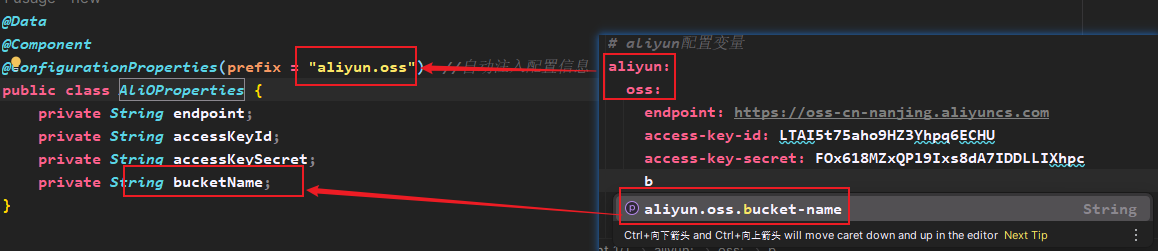
现在来比较一下两个参数配置化注解的异同点
相同点:都是用来注入外部配置的属性的。
不同点:
- @Value注解只能一个一个的进行外部属性的注入
- @ConfigurationProperties可以批量的将外部的属性配置注入到bean对象的属性中
如果要注入的属性非常的多,并且还想做到复用,就可以定义这么一个bean对象。通过configuration properties 批量的将外部的属性配置直接注入到 bean对象的属性当中。在其他的类当中,我要想获取到注入进来的属性,我直接注入 bean 对象,然后调用 get 方法,就可以获取到对应的属性值了。
本文转载自: https://blog.csdn.net/xuanfather/article/details/139678611
版权归原作者 轩辰q 所有, 如有侵权,请联系我们删除。发表评论
“JavaWeb 企业级项目开发(前端+后端)”的评论:
还没有评论 - 代码实现:1. 首先创建文件,提前准备基础代码,包括表格以及vue.js和axios.js文件的引入
