
第二章 Scala基础
一.scala的特性
(1)面向对象
Seala是一种纯释的面向对象语言。一个对象的类型和行为是由类和特征描迷的。类通过子类化和灵活的混合类进行扩展,成为多重继承的可靠解快方案。
(2)函数式编程
Scala 提供了轻量级语法来定义匿名函数,支持高阶函数,允许函数嵌套,并支持函数柯里化。Scala 的样例类与模式匹配支持两数式编程语言中的代数类型。Scala 的单例对象提供了方便的方法来组合不属于类的函数。用户还可以使用 Seala 的模式匹配,编写类似正则表达式的代码处理可扩展标记语言(Extensible Markup Language, XML)格式的数据。
(3)静态类型
Scala 配备了表现型的系统,以静态的方式进行抽象,以安全和连贯的方式进行使用。
系统支持将通用类、内部类、抽象类和复合类作为对象成员,也支持隐式参数、转换和多态方法等,这为抽象编程的安全重用和软件类型的安全扩展提供了强大的支持。
(4)可扩展
在实践中,专用领域的应用程序开发往往需要特定的语言扩展。Scala 提供了许多独特
的语言机制,可以以库的形式无缝添加新的语言结构。
二.定义与使用数组
方式一

方式二

操作数组
查看数组z的长度
z.length
查看数组z的第一个元素
z.head
查看数组z中除了第一个元素外的其他元素
Z.tai1
判断数组z是否为空
z.isEmpty
判断数组z是否包含元素"baidu"
z.contains ("baidu")

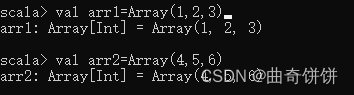
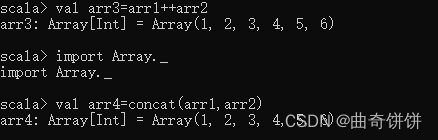
连接两个数组既可以使用操作符“+”、也可以使用 concat)方法。使用 cncal)方法需要先通过“import Array_”命令导入包。定义数组ar1 和ar2, 并分别便用操作符和 concato 方法连接两个数组,结果如图
Scala 可以使用 range0方法创建区间数组。使用 range0方法前同样需要先通过命令“import Array_”导入包。创建区间为1~10且步长为2的数组,如图

第三章 Spark编程基础
RDD简介
RDD 是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合。RDD有3种不同的创建方法。第一种是将程序中已存在的 Sea 集合(如集合、列表、数组)转换成RDD,第二种是对已有RDD 进行转换得到新的RDD,这两种方法都是通过内存中已有的数据创建RDD 的。第三种是直接读取外部存储系统的数据创建 RDD。
1. parallelize()
parallelize0方法有两个输人参数,说明如下。
(1)要转化的集合:必须是 Scg 集合。Seg 表示序列,指的是一类具有一定长度的、
可送代访问的对象,其中每个数据元素均带有一个从0开始的、固定的索引。
(2)分区数。若不设分区数,则RDD的分区数默认为该程序分配到的资源的 CPU 核心数。通过 parallelize()方法用一个数组的数据创建 RDD,并设置分区数为4,创建后查看该RDD的分区数
使用 makeRDD()方法创建 RDD 并查看各分区的值
#定义一个数组
val data = Array(1, 2, 3,4, 5)
使用parallelize ()方法创建 RDD
val distData = sc, parallelize (data)
查看 RDD默认分区个数
distData.partitions.size
设置分区个数为4后创建 RDD
val distData = sc, parallelize (data, 4)
再次查看 RDD分区个数
distData.partitions, size
2. makeRDD()
makeRDDO方法有两种使用方式,第一种使用方式与 parallelize)方法一致;第二种方式是通过接收一个 Seq[(T, Seq[String])]参数类型创建 RDD。第二种方式生成的 RDD 中保存的是T的值,Seq[String]部分的数据会按照 Seg[(T, Seq[String)]的顺序存放到各个分区中,一个 Seq[String]对应存放至一个分区,并为数据提供位置信息,通过preferredLocations0方法可以根据位置信息查看每一个分区的值。调用 makeRDDO时不可以直接指定 RDD的分区个数,分区的个数与 Seq[String)参数的个数是保持一致的。使用 makeRDDO方法创建 RDD,并根据位置信息查看每一个分区的值。
使用 makeRDD()方法创建 RDD 并查看各分区的值
#定义一个序列 seg
val seq = Seg((1, Seq("iteblog.com", "sparkhostl.com")),
(3, Seq("itebolg.com", "sparkhost2.com")), (2,Seq("iteblog.com", "sparkhost3.com")))# 使用 makeRDD()方法创建RDD
val iteblog = sc.makeRDD(seg)
查看 RDD的值iteblog.collect # 查看分区个数
iteblog.partitioner
iteblog.partitions.size
根据位置信息查看每一个分区的值
iteblog.preferredLocations (iteblog.partitions (0))iteblog.preferredLocations (iteblog.partitions (1))iteblog.preferredLocations(iteblog.partitions(2))
3.使用 union()方法合并多个 RDD
union()方法是一种转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两
个RDD 中每个元素中的值的个数、数据类型需要保持一致。创建两个存放二元组的 RDD, 通过 umion)方法合并两个RDD,不处理重复数据,并且每个二元组的值的个数、数据类型都是一致的。
4.使用 filter()方法进行过滤
fiter)方法是一种转换操作,用于过滤 RDD 中的元素。filter()方法需要一个参数,这个参数是一个用于过源的函数,该丽数的返回值为 Boolean 类型。filter()方法将返回值为 true 的元素保留,将返回值为 false的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新RDD。
创建一个RDD,并且过滤掉每个元组第二个值小于等于1的元素,如代码 3-14所示。其中第一个 ilter0方法中使用了“.2”,第一个“”与第二个 filter)方法中的“x”一样,均表示RDD 的每一个元素。
5.使用 distinct()方法进行去重
distinct)方法是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,没
有参数。创建一个带有重复数据的RDD,并使用 distinct)方法去重,如代码3-15 所示,通过 collect0方法查看结果。
6.使用map()方法转换数据
map()方法是一种基础的 RDD 转换操作,可以对RDD中的每一个数据元素通过某种丽数进行转换并返回新的RDD。map0方法是懒操作,不会立即进行计算。
转换操作是创建RDD 的第二种方法,通过转换已有 RDD生成新的 RDD。因为 RDD -个不可变的集合,所以如果对RDD 数据进行了某种转换,那么会生成一个新的 RDD。
例如,通过一个存放了5个 Int类型的数据元素的列表创建一个RDD,可通过map()方法对每一个元素进行平方运算,结果会生成一个新的RDD,如代码3-6所示。
map()方法示例
创建 RDD
val distData = sc.parallelize (List(I;,3, 45,3,76
map)方法求平方值
val sq_dist = distData.nap(x=>x*x)
7.使用 sortBy)方法进行排序
sortBy()方法用于对标准RDD进行排序,有3个可输人参数,说明如下。
(1)第1个参数是一个函数(T)=>K,左边是要被排序对象中的每一个元素,右边返
回的值是元素中要进行排序的值。
(2)第2个参数是ascending, 决定排序后 RDD中的元素是升序的还是降序的,默认
是tue,即升序排序,如果需要降序排序则需要将参数的值设置为 falseo
(3)第3个参数是 wunPartitons, 块定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的分区个数相等,即 this,partitions.size.
第一个参数是必须输人的,而后面的两个参数可以不输人。例如,通过一个存放了3
个二元组的列表创建一个 RDD,对元组的第二个值进行降序排序,分区个数设置为1。
#.创建 RDD
val data = sc.parallelize(List((1, 3), (45,3), (7,6)))
#使用SoxtBy()方法对元组的第二个值进行降序排序,分区个数没置为1
val sort data - data.sortBy(x m> x.2, false,1)
8.使用 collect()方法查询数据
collect(方法是一种行动操作,可以将RDD 中所有元萦转换成数组并返回到 Dive端,
适用于返回处理后的少量数据。因为需要从集群各个节点收集数据到本地,经过网络传当并目加裁到 Driver内存中,所以如果数据量比较大,会给网络传输造成很大的压力。因此数据量较大时,尽量不使用collct0方法,否则可能导致Driver端出现内存益出问题。collegn 方法有以下两种操作方式。
(1)collect:直接调用collect 返回该RDD中的所有元索,返回类型是一个 Array[T]数组,这是较为常用的一种方式。
使用 collect()方法查看在sq_dist 和 sort_data的结果,分别返回了经过平方运算后的 Int类型的数组和对元组第二个值进行降序排列后的数组。
collect()方法示例
#查看 sq_dist 和 sort_data 的结果
sq_dist.collect
sort_data.collect
(2) collect[U: ClassTag](f: PartialFunction[T, U]): RDD[U。这种方式需要提供一个标准的偏函数,将元素保存至一个RDD中。首先定义一个函数 one,用于将 collect 方法得到的数组中数值为1的值替换为“one",将其他值替换为“other”。创建一个只有3个 Iot 类型数据的RDD,在使用collec1()方法时将one 两数作为参数。
collecl(PartialFunction)方法示例
定义一个函数 one
val one:PartialrunctionlInt, stringl - (caso I > "one":case - -> "othe,
创建RDD
val data = sc, parallelize (List(2,3, 1))
#使用collect()方法,将 one 两数作为参数
data.collect (one).collect
9.使用 flatMap)方法转换数据
fatMap()方法将函数参数应用于RDD之中的每一个元素,将返回的迭代器(如数组、列表等)中的所有元素构成新的 RDD。使用 flatMap0方法时先进行 map(映射)再进行 flat (扁平化)操作,数据会先经过跟 map()方法一样的操作,为每一条输人返回一个迭代器(可迭代的数据类型),然后将所得到的不同级别的送代器中的元素全部当成同级别的元素,返回一个元素级别全部相同的RDD。这个转换操作通常用来切分单词。
例如,分别用 map()方法和 flatMap()方法分割字符串。用map()方法分割后,每个元素
对应返回一个迭代器,即数组。flatMapO方法在进行同 map()方法一样的操作后,将3个迭代器的元素扁平化(压成同一级别),保存在新 RDD 中。
flatMap()方法示例
创建 RDD
val. test = sc.parallelize (List ("How are you", "I am fine", "what about you"))
查看 RDD
test.collect
#使用map分割字符电后,再查看 RDD
test.map(x=> x,split("")).collect
#使用latMap分割字符串后,再查看 RDD
test.flatMap(x => x.split("")).collect
第四章 Spark编程进阶
在集群环境中运行 Spark
直接在开发环境中运行 Spark 程序时通常选择的是本地模式。如果数据的规模比较庞大,更常用的方式还是在 Spark 程序开发测试完成后编译打包为Java 归档(Java Archive, JAR)包,并通过 spark-submit 命令提交到 Spark集群环境中运行。
spark-submit的脚本在 Spark安装目录的bin 目录下,spark-submit 是 Spark 为所有支特
的集群管理器提供的一个提交作业的工具。Spark 在/example 目录下有 Scala、Java、 Pyithon 和R的示例程序,都可以通过 spark-submit运行。
sporik-subomit 提交JAR 包到集群有一定的格式要求,需要设置一些参数,语法如下,
./bin/spark-submit --class <main-class>
--master <master-url>
--deploy-mode <deploy-mode>
--conf <"key=value">
...# other options
<appli.cat.ion-jar> )
[application-argaments」
如果除了设置运行的脚本名称之外不设置其他参数,那么 Spark 程序默认在本地
运行。
--class:应用程序的入口,指主程序。
--master:指定要连接的集群URL。
-deploy-mode:是否将驱动程序部署在工作节点(cluster)或本地作为外部客户端
(client)。
--conf:设置任意 Spark 配登属性,允许使用"key=value WordCount"的格式设置任意的SparkConf 配置属性。
application-jar:包含应用程序和所有依赖关系的JAR包的路径。
application-arguments:传递给main)方法的参数。
将代码 4-3 所示的程序运行模式更改为打包到集样中运行。程序中无须设置 master 地址、Hadoop 安装包位置。输人、输出路径可通过 spark-submit 指定。
spark-submit常用项配置
ndme Name 设置程序名
--jars JARS 添加依赖包
-driver-memory MEM Driver 程序使用的内存大小
-executor-memory MEM Executor使用的内存大小
-total-executor-cores NUM Executor使用的总内核数
--executor-cores NUM 每个Bxecutor使用的内核数
-num-executors NUM 启动的Executor数量
spark.eventLog.dir
保存日志相关信息的路径,可以是“hdfs://” 开头的 HDES 路径,也可以
是“e:// 开头的本地路径,路径均需要提前创建
spark.eventLog.enabled 是否开启日志记录
spark.cores.max
当应用程序运行在 Standalone 集群或粗粒度共享模式 Mesos 集群时,应用
程序向集群(不是每台机器,而是整个集群)请求的最大 CPU内核总数。如果不设置,那么对于 Standalone 集群将使用 spark,deploy. defaultCores 指定的数值,而 Mesos 集群将使用集群中可用的内核
第五章 Spark SQL——结构化数据文件处理
一.DataFrame简介
Spark SQL使用的数据抽象并非是RDD,而是DataFrame。
在Spark 1.3.0版本之前,DataFrame被称为SchemaRDD。
DataFrame使Spark具备处理大规模结构化数据的能力。
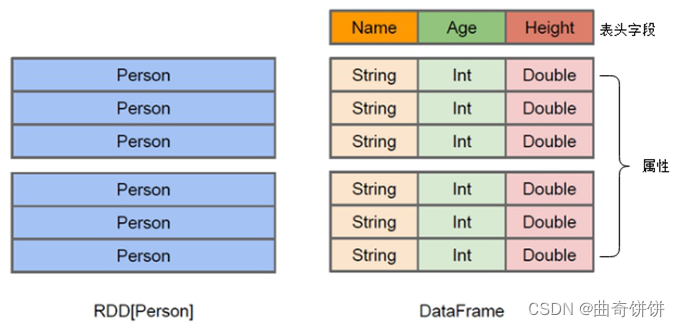
在Spark中,DataFrame是一种以RDD为基础的分布式数据集。
DataFrame的结构类似传统数据库的二维表格,可以从很多数据源中创建,如结构化文件、外部数据库、Hive表等数据源。
DataFrame可以看作是分布式的Row对象的集合,在二维表数据集的每一列都带有名称和类型,这就是Schema元信息,这使得Spark框架可获取更多数据结构信息,从而对在DataFrame背后的数据源以及作用于DataFrame之上数据变换进行针对性的优化,最终达到提升计算效率。
二.DataFrame的创建
1.数据准备
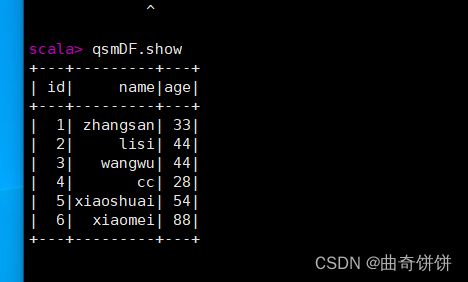
在HDFS文件系统中的/spark目录中有一个ff.txt文件,内容如下:
1 zhangsan 33
2 lisi 44
3 wangwu 44
4 cc 28
5 xiaoshuai 54
6 xiaomei 88
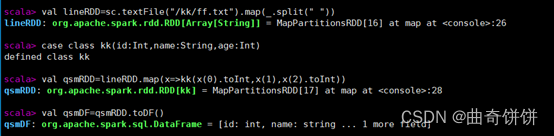
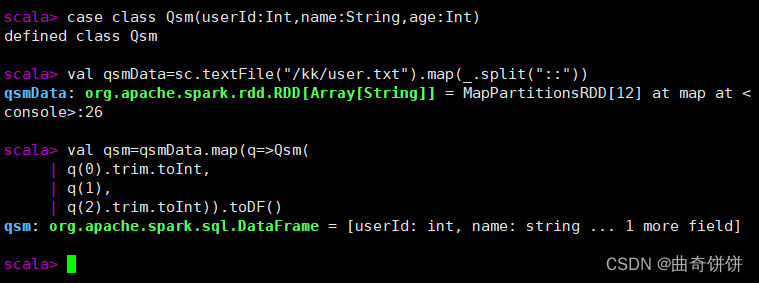
2.RDD直接转换为DataFrame
3.DataFrame的常用操作

示例:
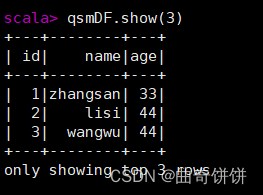
展示前三条
对列名进行重命名

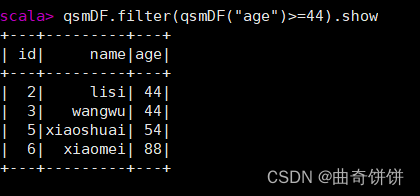
过滤年龄大于或等于44的数据
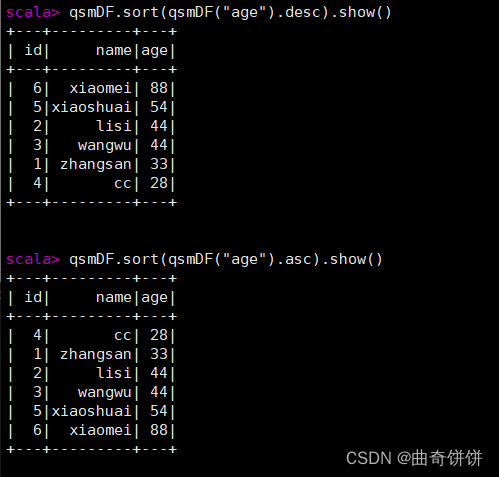
根据年龄进行升序或降序排列
按年龄进行分组并统计人数
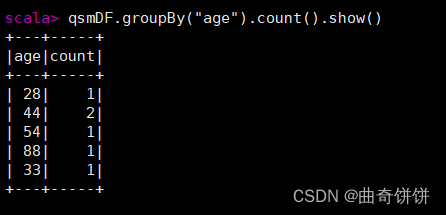
创建DataFrame对象qsm
版权归原作者 曲奇饼饼 所有, 如有侵权,请联系我们删除。